Você também pode gostar
- Base SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo EverandBase SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesAinda não há avaliações
- Load Utility: by Swapan Banerjee: ... Courtesy IBM Utility Guide & Reference ManualDocumento20 páginasLoad Utility: by Swapan Banerjee: ... Courtesy IBM Utility Guide & Reference ManualSreenivas RaoAinda não há avaliações
- SAS Programming Guidelines Interview Questions You'll Most Likely Be AskedNo EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be AskedAinda não há avaliações
- DB2 L2Documento2 páginasDB2 L2kushagraAinda não há avaliações
- SAP interface programming with RFC and VBA: Edit SAP data with MS AccessNo EverandSAP interface programming with RFC and VBA: Edit SAP data with MS AccessAinda não há avaliações
- Advanced SAS Interview Questions and AnswersDocumento11 páginasAdvanced SAS Interview Questions and Answersdinesh441981Ainda não há avaliações
- MySQL Replication FormatsDocumento17 páginasMySQL Replication FormatsSaeed MeethalAinda não há avaliações
- Advanced SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo EverandAdvanced SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesAinda não há avaliações
- ABAP Performance GuidelinesDocumento17 páginasABAP Performance GuidelinesraylinscribdAinda não há avaliações
- VSAMDocumento19 páginasVSAMApurva Kapoor100% (1)
- Oracle Database 12c Backup and Recovery Survival GuideNo EverandOracle Database 12c Backup and Recovery Survival GuideNota: 4.5 de 5 estrelas4.5/5 (3)
- Oracle Database Performance and TuningDocumento69 páginasOracle Database Performance and Tuningankur singhAinda não há avaliações
- Oracle Performance Improvement by Tuning Disk Input OutputDocumento4 páginasOracle Performance Improvement by Tuning Disk Input OutputsyetginerAinda não há avaliações
- Limitations On FastloadDocumento6 páginasLimitations On FastloadjvnkrAinda não há avaliações
- Sas Interview QuestionsDocumento15 páginasSas Interview QuestionsamcucAinda não há avaliações
- Oracle Database Performance and TuningDocumento69 páginasOracle Database Performance and TuningSraVanKuMarThadakamalla100% (1)
- Teradata Fast Load UtilityDocumento6 páginasTeradata Fast Load UtilityPainAinda não há avaliações
- 9i and 10 G New FeaturesDocumento54 páginas9i and 10 G New FeaturesabderrazzakhAinda não há avaliações
- Performance Tuning Addedinfo OracleDocumento49 páginasPerformance Tuning Addedinfo OraclesridkasAinda não há avaliações
- SAP BW Performance OptimizationDocumento11 páginasSAP BW Performance OptimizationHemanth JanyavulaAinda não há avaliações
- Teradata UtilitiesDocumento4 páginasTeradata UtilitiesSubasiniKathirvelAinda não há avaliações
- RMAN & SMR (Server-Managed Recovery)Documento21 páginasRMAN & SMR (Server-Managed Recovery)Printesh PatelAinda não há avaliações
- 57 PaperDocumento5 páginas57 PaperLit How ThanAinda não há avaliações
- Arthur Xuejun Li, City of Hope National Medical Center, Duarte, CADocumento12 páginasArthur Xuejun Li, City of Hope National Medical Center, Duarte, CAsasdoc2010Ainda não há avaliações
- SAS Programming 2: Data Manipulation Techniques - Syntax: Course NotesDocumento20 páginasSAS Programming 2: Data Manipulation Techniques - Syntax: Course Noteso0 niceAinda não há avaliações
- Basics of MainframesDocumento36 páginasBasics of MainframesneelianilkumarAinda não há avaliações
- SAP Database Performance ProblemsDocumento5 páginasSAP Database Performance ProblemsTakeo GotoAinda não há avaliações
- Abinitio IntroductionDocumento9 páginasAbinitio IntroductionAyush nemaAinda não há avaliações
- SSIS Performance TunningDocumento3 páginasSSIS Performance TunningArvindAinda não há avaliações
- Twenty Ways To Run Your SAS® Program Faster and Use Less SpaceDocumento6 páginasTwenty Ways To Run Your SAS® Program Faster and Use Less SpaceKimondo KingAinda não há avaliações
- Getting Vsam InformationDocumento6 páginasGetting Vsam InformationAtthulaiAinda não há avaliações
- Alter Table Space AdministrationDocumento5 páginasAlter Table Space AdministrationMurali Krishna PullareAinda não há avaliações
- What Is TeradataDocumento7 páginasWhat Is TeradataJayachandra JcAinda não há avaliações
- SSIS FrameworkDocumento53 páginasSSIS FrameworkMurali0% (1)
- Check Whether Archiving Has Been Enabled or Disabled, As FollowsDocumento8 páginasCheck Whether Archiving Has Been Enabled or Disabled, As FollowsrlamtilaaAinda não há avaliações
- Avoid SELECT : SSIS Performance ImprovementDocumento7 páginasAvoid SELECT : SSIS Performance ImprovementabhinavakAinda não há avaliações
- Exam 1z0 060 Upgrade To Oracle Database 12c v2Documento74 páginasExam 1z0 060 Upgrade To Oracle Database 12c v2sidd_aish@yahoo.comAinda não há avaliações
- DBA Interview Questions With Answers Part8Documento13 páginasDBA Interview Questions With Answers Part8anu224149Ainda não há avaliações
- Option 1 Option 2 Option 3 Option 4 Correct AnswerDocumento68 páginasOption 1 Option 2 Option 3 Option 4 Correct AnswerSayan GuptaAinda não há avaliações
- Very Good Examples SAS Before InterviewDocumento22 páginasVery Good Examples SAS Before InterviewMrigank TayalAinda não há avaliações
- 9i How To Setup Oracle Streams Replication. (Doc ID 224255.1)Documento9 páginas9i How To Setup Oracle Streams Replication. (Doc ID 224255.1)Nick SantosAinda não há avaliações
- Interview Questions HarshaDocumento4 páginasInterview Questions HarshaHarsha VardhanAinda não há avaliações
- ODI SubjectDocumento6 páginasODI SubjectNarayana AnkireddypalliAinda não há avaliações
- Data Guard - ThrusdayDocumento10 páginasData Guard - ThrusdayRrohit SawneyAinda não há avaliações
- Very BasicDocumento5 páginasVery BasicSweta SinghAinda não há avaliações
- Gather Schema Stats Archives - Bright DBADocumento1 páginaGather Schema Stats Archives - Bright DBArichiet2009Ainda não há avaliações
- Working With Database Tables Student VersionDocumento12 páginasWorking With Database Tables Student VersionSuresh babuAinda não há avaliações
- ABAP Dictionary NotesDocumento11 páginasABAP Dictionary NotesYousif AhmedAinda não há avaliações
- MigmonDocumento6 páginasMigmonRahul BansalAinda não há avaliações
- Ocean Technologies, Hyderabad.: SAS Interview Questions:Base SASDocumento5 páginasOcean Technologies, Hyderabad.: SAS Interview Questions:Base SASreyAinda não há avaliações
- Error Stack PsaDocumento9 páginasError Stack PsaAsitAinda não há avaliações
- SAP ABAP BEST PracticesDocumento6 páginasSAP ABAP BEST PracticesVivek V NairAinda não há avaliações
- Configuring For Recoverability: Certification ObjectivesDocumento33 páginasConfiguring For Recoverability: Certification Objectivesdongsongquengoai4829Ainda não há avaliações
- Sapabapmaterial 140803141350 Phpapp02 PDFDocumento454 páginasSapabapmaterial 140803141350 Phpapp02 PDFSrinivasDukkaAinda não há avaliações
- Oci Tuning DsDocumento37 páginasOci Tuning DsNaresh KumarAinda não há avaliações
- SQL SERVER Database Coding Standards and Guidelines Part 2Documento5 páginasSQL SERVER Database Coding Standards and Guidelines Part 2testoooAinda não há avaliações
- Debug and Development StagesDocumento5 páginasDebug and Development StagesAnkur VirmaniAinda não há avaliações
- Module 18 - Database TuningDocumento9 páginasModule 18 - Database TuningGautam TrivediAinda não há avaliações
- Sysprog: Redefine and Initialize The Local and Global CatalogsDocumento8 páginasSysprog: Redefine and Initialize The Local and Global CatalogsPendyala SrinivasAinda não há avaliações
- DP 200 - LA Practice TestDocumento27 páginasDP 200 - LA Practice TestPendyala SrinivasAinda não há avaliações
- Stock To Watch:: Nifty ChartDocumento3 páginasStock To Watch:: Nifty ChartPendyala SrinivasAinda não há avaliações
- December 2021Documento26 páginasDecember 2021Pendyala SrinivasAinda não há avaliações
- Owasp Api Security Top 10 Cheat Sheet A4Documento3 páginasOwasp Api Security Top 10 Cheat Sheet A4Pendyala SrinivasAinda não há avaliações
- Leeds 2018 Atmasambandha PDFDocumento51 páginasLeeds 2018 Atmasambandha PDFPendyala Srinivas100% (1)
- Azure: Creating A Hybrid Cloud Expressroute SlidesDocumento16 páginasAzure: Creating A Hybrid Cloud Expressroute SlidesPendyala SrinivasAinda não há avaliações
- Cloud Azure ConnectivityDocumento9 páginasCloud Azure ConnectivityPendyala SrinivasAinda não há avaliações
- Implementing Traffic Control in A Microsoft Azure Virtual Network SlidesDocumento15 páginasImplementing Traffic Control in A Microsoft Azure Virtual Network SlidesPendyala SrinivasAinda não há avaliações
- Ansible On AzureDocumento141 páginasAnsible On AzurePendyala SrinivasAinda não há avaliações
- Creating and Configuring An Azure Virtual Network SlidesDocumento21 páginasCreating and Configuring An Azure Virtual Network SlidesPendyala SrinivasAinda não há avaliações
- AWS Serverless Applications LensDocumento60 páginasAWS Serverless Applications LensPendyala SrinivasAinda não há avaliações
- Deploying Azure Virtual Machine Scale Sets SlidesDocumento13 páginasDeploying Azure Virtual Machine Scale Sets SlidesPendyala SrinivasAinda não há avaliações
- Infrastructure As CodeDocumento39 páginasInfrastructure As CodePendyala SrinivasAinda não há avaliações
- Elasticsearch When To Host On-Prem and When To Turn To SaaSDocumento42 páginasElasticsearch When To Host On-Prem and When To Turn To SaaSPendyala SrinivasAinda não há avaliações
- Azure MigrationDocumento539 páginasAzure MigrationPendyala Srinivas100% (2)
- Aws Best Practices For Ddos Resiliency: June 2018Documento30 páginasAws Best Practices For Ddos Resiliency: June 2018Pendyala SrinivasAinda não há avaliações
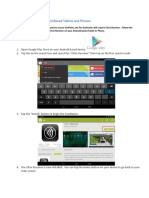
- Citrix Installation For Android Based Tablets and PhonesDocumento3 páginasCitrix Installation For Android Based Tablets and PhonesPendyala SrinivasAinda não há avaliações
- Servicenow Sys Admin Exam Specs KingstonDocumento6 páginasServicenow Sys Admin Exam Specs KingstonPendyala SrinivasAinda não há avaliações
- Anjaneya AstraDocumento4 páginasAnjaneya AstraPendyala SrinivasAinda não há avaliações
- Optimal Control Development System For ElectricalDocumento7 páginasOptimal Control Development System For ElectricalCRISTIAN CAMILO MORALES SOLISAinda não há avaliações
- BFC+43103. 1213 SEM1pdfDocumento19 páginasBFC+43103. 1213 SEM1pdfAdibah Azimat100% (1)
- Internship Report PDFDocumento11 páginasInternship Report PDFASWIN KUMARAinda não há avaliações
- Winsome Hin-Shin LEE CV (Feb 2017)Documento5 páginasWinsome Hin-Shin LEE CV (Feb 2017)Winsome LeeAinda não há avaliações
- Pilot Implementation of The Limited Face-to-Face Class Program at Librada Avelino Elementary SchoolDocumento10 páginasPilot Implementation of The Limited Face-to-Face Class Program at Librada Avelino Elementary SchoolCher GeriAinda não há avaliações
- Bollard Pull Calculations For Towing OperationsDocumento8 páginasBollard Pull Calculations For Towing OperationsDiegoAinda não há avaliações
- SAP EHSM - Risk Assessment - User Guide - Help FilesDocumento15 páginasSAP EHSM - Risk Assessment - User Guide - Help FilesKishor Kolhe50% (2)
- APCO CSAA ANS2 101 1webfinalDocumento38 páginasAPCO CSAA ANS2 101 1webfinalJUAN CAMILO VALENCIA VALENCIAAinda não há avaliações
- Alpha 20 TDS (EN) 100063006 1Documento5 páginasAlpha 20 TDS (EN) 100063006 1Ariel Gallardo Galaz100% (1)
- English 4 Q.2 Module 2Documento6 páginasEnglish 4 Q.2 Module 2RjVValdezAinda não há avaliações
- PCI Express Test Spec Platform 3.0 06182013 TSDocumento383 páginasPCI Express Test Spec Platform 3.0 06182013 TSDeng XinAinda não há avaliações
- Manual of Avionics PDFDocumento300 páginasManual of Avionics PDFJhony BhatAinda não há avaliações
- Digital Album On Prominent Social ScientistsDocumento10 páginasDigital Album On Prominent Social ScientistsOliver Antony ThomasAinda não há avaliações
- Ai R16 - Unit-6Documento36 páginasAi R16 - Unit-6RakeshAinda não há avaliações
- Modul MarketingDocumento5 páginasModul MarketingDeni IrvandaAinda não há avaliações
- PE1 Introduction To MovementsDocumento4 páginasPE1 Introduction To MovementsDaniela AnsayAinda não há avaliações
- International Journal of Agricultural ExtensionDocumento6 páginasInternational Journal of Agricultural Extensionacasushi ginzagaAinda não há avaliações
- SVC200Documento5 páginasSVC200fransiskus_ricky3329Ainda não há avaliações
- Star WarsDocumento28 páginasStar Warsalex1971Ainda não há avaliações
- Fragility Curves For Mixed Concrete-Steel Frames Subjected To SeismicDocumento5 páginasFragility Curves For Mixed Concrete-Steel Frames Subjected To SeismicJulián PovedaAinda não há avaliações
- Word Formation ListDocumento8 páginasWord Formation ListpaticiaAinda não há avaliações
- Classical Electromagnetism 1st Edition Franklin Solutions ManualDocumento21 páginasClassical Electromagnetism 1st Edition Franklin Solutions ManualBrianYorktnqsw100% (15)
- External Gear Pumps For Open Loop Hydraulic SystemsDocumento2 páginasExternal Gear Pumps For Open Loop Hydraulic SystemsBlashko GjorgjievAinda não há avaliações
- Erp Case StudyDocumento19 páginasErp Case StudyMøÑïkå Shàrmå100% (1)
- Science - Sound DiffractionDocumento12 páginasScience - Sound DiffractionElissah S PabilonaAinda não há avaliações
- Adiba Final Activity CousellingDocumento29 páginasAdiba Final Activity Cousellingadiba KhanAinda não há avaliações
- Post Covid StrategyDocumento12 páginasPost Covid Strategyadei667062Ainda não há avaliações
- Activity Diagram Airline Reservation System PDFDocumento4 páginasActivity Diagram Airline Reservation System PDFAnonymous zSn6IALuabAinda não há avaliações
- AOC TFT-LCD Color Monitor 931Fwz Service ManualDocumento54 páginasAOC TFT-LCD Color Monitor 931Fwz Service ManualtecnosomAinda não há avaliações
- Algorithms to Live By: The Computer Science of Human DecisionsNo EverandAlgorithms to Live By: The Computer Science of Human DecisionsNota: 4.5 de 5 estrelas4.5/5 (722)
- Defensive Cyber Mastery: Expert Strategies for Unbeatable Personal and Business SecurityNo EverandDefensive Cyber Mastery: Expert Strategies for Unbeatable Personal and Business SecurityNota: 5 de 5 estrelas5/5 (1)
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldNo EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldNota: 4.5 de 5 estrelas4.5/5 (55)
- Chaos Monkeys: Obscene Fortune and Random Failure in Silicon ValleyNo EverandChaos Monkeys: Obscene Fortune and Random Failure in Silicon ValleyNota: 3.5 de 5 estrelas3.5/5 (111)
- Digital Gold: Bitcoin and the Inside Story of the Misfits and Millionaires Trying to Reinvent MoneyNo EverandDigital Gold: Bitcoin and the Inside Story of the Misfits and Millionaires Trying to Reinvent MoneyNota: 4 de 5 estrelas4/5 (51)
- Cyber War: The Next Threat to National Security and What to Do About ItNo EverandCyber War: The Next Threat to National Security and What to Do About ItNota: 3.5 de 5 estrelas3.5/5 (66)
- Generative AI: The Insights You Need from Harvard Business ReviewNo EverandGenerative AI: The Insights You Need from Harvard Business ReviewNota: 4.5 de 5 estrelas4.5/5 (2)
- Chip War: The Quest to Dominate the World's Most Critical TechnologyNo EverandChip War: The Quest to Dominate the World's Most Critical TechnologyNota: 4.5 de 5 estrelas4.5/5 (228)
- AI Superpowers: China, Silicon Valley, and the New World OrderNo EverandAI Superpowers: China, Silicon Valley, and the New World OrderNota: 4.5 de 5 estrelas4.5/5 (398)
- System Error: Where Big Tech Went Wrong and How We Can RebootNo EverandSystem Error: Where Big Tech Went Wrong and How We Can RebootAinda não há avaliações
- The Intel Trinity: How Robert Noyce, Gordon Moore, and Andy Grove Built the World's Most Important CompanyNo EverandThe Intel Trinity: How Robert Noyce, Gordon Moore, and Andy Grove Built the World's Most Important CompanyAinda não há avaliações
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldNo EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldNota: 4.5 de 5 estrelas4.5/5 (107)
- The Future of Geography: How the Competition in Space Will Change Our WorldNo EverandThe Future of Geography: How the Competition in Space Will Change Our WorldNota: 4 de 5 estrelas4/5 (6)
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNo EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveAinda não há avaliações
- Reality+: Virtual Worlds and the Problems of PhilosophyNo EverandReality+: Virtual Worlds and the Problems of PhilosophyNota: 4 de 5 estrelas4/5 (24)
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNo EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindAinda não há avaliações
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNo EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessAinda não há avaliações
- The Infinite Machine: How an Army of Crypto-Hackers Is Building the Next Internet with EthereumNo EverandThe Infinite Machine: How an Army of Crypto-Hackers Is Building the Next Internet with EthereumNota: 3 de 5 estrelas3/5 (12)
- The Manager's Path: A Guide for Tech Leaders Navigating Growth and ChangeNo EverandThe Manager's Path: A Guide for Tech Leaders Navigating Growth and ChangeNota: 4.5 de 5 estrelas4.5/5 (99)
- Broken Money: Why Our Financial System is Failing Us and How We Can Make it BetterNo EverandBroken Money: Why Our Financial System is Failing Us and How We Can Make it BetterNota: 5 de 5 estrelas5/5 (3)
- Solutions Architect's Handbook: Kick-start your career as a solutions architect by learning architecture design principles and strategiesNo EverandSolutions Architect's Handbook: Kick-start your career as a solutions architect by learning architecture design principles and strategiesAinda não há avaliações
- The E-Myth Revisited: Why Most Small Businesses Don't Work andNo EverandThe E-Myth Revisited: Why Most Small Businesses Don't Work andNota: 4.5 de 5 estrelas4.5/5 (709)
- Four Battlegrounds: Power in the Age of Artificial IntelligenceNo EverandFour Battlegrounds: Power in the Age of Artificial IntelligenceNota: 5 de 5 estrelas5/5 (5)