Você também pode gostar
- Monografia Las Enzimas y Los Acidos NucleicosDocumento25 páginasMonografia Las Enzimas y Los Acidos NucleicosJesus Mendez RodriguezAinda não há avaliações
- 6th Central Pay Commission Salary CalculatorDocumento15 páginas6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Mutaciones GeneticasDocumento29 páginasMutaciones Geneticaspetrolache100% (4)
- Recombinación GenéticaDocumento20 páginasRecombinación GenéticaLino Moreno Salcedo33% (6)
- Proyecto Del Genoma y Proteoma Humano-GenéticaDocumento29 páginasProyecto Del Genoma y Proteoma Humano-GenéticaGlenn García0% (1)
- Manual Espectrofotómetro Smart Spectro - LaMotte (Español)Documento89 páginasManual Espectrofotómetro Smart Spectro - LaMotte (Español)Romulo Aycachi Inga100% (1)
- Manual de Medios de CultivoDocumento267 páginasManual de Medios de CultivoQUIMICO CLINICO WILLIANS SANCHEZ95% (150)
- El Genoma Humano. TrabajoDocumento29 páginasEl Genoma Humano. TrabajoJavier Dario Guerrero PalaciosAinda não há avaliações
- Linea Del Tiempo Bioquimica 2Documento10 páginasLinea Del Tiempo Bioquimica 2Rosaura Sántiz67% (3)
- Proyecto Del Genoma HumanoDocumento6 páginasProyecto Del Genoma HumanoAmada LopezAinda não há avaliações
- MutaciónDocumento4 páginasMutaciónDiana VillaAinda não há avaliações
- Recombinación GenéticaDocumento6 páginasRecombinación GenéticaAve FenixAinda não há avaliações
- Clase 18 Herencia Ligada Al Sexo y GenealogíasDocumento26 páginasClase 18 Herencia Ligada Al Sexo y GenealogíasbinguisAinda não há avaliações
- El Genoma Humano y Las Bases Cromosòmicas de La HerenciaDocumento4 páginasEl Genoma Humano y Las Bases Cromosòmicas de La HerenciaMaybe Carolina Altamirano Fonseca100% (2)
- Genética Mendeliana y No MendelianaDocumento8 páginasGenética Mendeliana y No MendelianaYANETH PEREZ PABON0% (1)
- Biologia MutacionDocumento13 páginasBiologia MutacionClara CuevaAinda não há avaliações
- Importancia de La MeiosisDocumento2 páginasImportancia de La MeiosisMoisésAinda não há avaliações
- Meiosis PDFDocumento22 páginasMeiosis PDFDeyfer Steven Cortes Castrillon100% (1)
- Biotecnología VegetalDocumento42 páginasBiotecnología VegetalYOSELINAinda não há avaliações
- GenEtica y Sus RamasDocumento6 páginasGenEtica y Sus RamasMiguel Angel Rodas Herrera89% (9)
- Leyes de MendelDocumento13 páginasLeyes de MendelJaime AdrianAinda não há avaliações
- Proyecto Genoma HumanoDocumento7 páginasProyecto Genoma Humanoleon1771Ainda não há avaliações
- MutacionesDocumento9 páginasMutacionesSantos Peñaloza RigelAinda não há avaliações
- Monografia GeneticaDocumento17 páginasMonografia GeneticaEduardo Avalos Palacios0% (1)
- CROMOSOMASDocumento9 páginasCROMOSOMASPatricia PerezAinda não há avaliações
- Conceptos Basicos de La GeneticaDocumento14 páginasConceptos Basicos de La GeneticaEstefany MartinezAinda não há avaliações
- Formula RojaDocumento6 páginasFormula RojaLorena SaldañaAinda não há avaliações
- El Genoma HumanoDocumento5 páginasEl Genoma HumanoSebas AckermanAinda não há avaliações
- Soluciones Problemas de Genética II (20-21)Documento9 páginasSoluciones Problemas de Genética II (20-21)alex mAinda não há avaliações
- Recombinación GenéticaDocumento9 páginasRecombinación GenéticavaneAinda não há avaliações
- Fotosíntesis Oxigénica y AnoxigénicaDocumento2 páginasFotosíntesis Oxigénica y Anoxigénicajose francico Sanchez Hernandez100% (1)
- Estudio GenealógicoDocumento9 páginasEstudio GenealógicoDavid OjedaAinda não há avaliações
- Adn MonografiaDocumento18 páginasAdn MonografiaEfrain Einer Condori NestasAinda não há avaliações
- Taller 1 de Acuatica (4 y 5)Documento5 páginasTaller 1 de Acuatica (4 y 5)José CortésAinda não há avaliações
- Biologia Mapas GeneticosDocumento24 páginasBiologia Mapas GeneticosPerla Liliana100% (1)
- Tercer Parcial Microbiologia 2017Documento4 páginasTercer Parcial Microbiologia 2017kevin flores bascopeAinda não há avaliações
- Morfología y Fisiología de Las BacteriasDocumento26 páginasMorfología y Fisiología de Las BacteriasCuartoASantaMaríadePaine100% (1)
- Microbiologia Ambiental - MonografiaDocumento21 páginasMicrobiologia Ambiental - MonografiaLeydi Lisbet ParedesAinda não há avaliações
- MONOGRAFIA DE Genetica MVZDocumento15 páginasMONOGRAFIA DE Genetica MVZJavier Manrique SalamancaAinda não há avaliações
- Herencia PoligenicaDocumento73 páginasHerencia PoligenicavbdgddgfdfgAinda não há avaliações
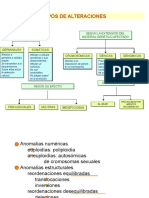
- Alteraciones CromosomicasDocumento22 páginasAlteraciones CromosomicasYordy Guzman Bermudez100% (1)
- Silabos de Microbiologia y Parasitologia (Obstetricia)Documento7 páginasSilabos de Microbiologia y Parasitologia (Obstetricia)Diana VillaltaAinda não há avaliações
- Taller Reproduccion Celular BiologiaDocumento6 páginasTaller Reproduccion Celular BiologiaDilan JiménezAinda não há avaliações
- La Herencia Ligada Al SexoDocumento3 páginasLa Herencia Ligada Al Sexoariana peñaAinda não há avaliações
- Mecanismos de Resistencia de Las Plantas A Los HerbicidasDocumento14 páginasMecanismos de Resistencia de Las Plantas A Los HerbicidasLuis AlejoAinda não há avaliações
- CLONACIÓNDocumento2 páginasCLONACIÓNraulAinda não há avaliações
- Replicación de ADN en Células EucariotasDocumento16 páginasReplicación de ADN en Células EucariotasAbigail MerazAinda não há avaliações
- Recombinación Genética PDFDocumento5 páginasRecombinación Genética PDFJavan ZaldivarAinda não há avaliações
- Anomalías CromosómicasDocumento14 páginasAnomalías Cromosómicaspipidel82Ainda não há avaliações
- Taller #2 El Genoma Humano: Melanogaster) Cuyas Mutaciones Estaban Siendo Estudiadas Por El LaboratorioDocumento9 páginasTaller #2 El Genoma Humano: Melanogaster) Cuyas Mutaciones Estaban Siendo Estudiadas Por El LaboratorioValeria GómezAinda não há avaliações
- El Proyecto Genoma HumanoDocumento35 páginasEl Proyecto Genoma HumanoFredy Alexander MeloAinda não há avaliações
- Proyecto Genoma HumanoDocumento23 páginasProyecto Genoma HumanoDiana EstupiñanAinda não há avaliações
- Resumen - Proyecto Genoma HumanoDocumento8 páginasResumen - Proyecto Genoma HumanoHaroltAlexisLeonTripul100% (1)
- Proyecto Del Genoma HumanoDocumento5 páginasProyecto Del Genoma HumanoAlexandra TenjouAinda não há avaliações
- Taller Codigo GeneticoDocumento9 páginasTaller Codigo GeneticoKevin Stiwar Mosqura MosqueraAinda não há avaliações
- BiologiaDocumento4 páginasBiologiazarattyAinda não há avaliações
- Modificacion Del Genoma HumanoDocumento13 páginasModificacion Del Genoma HumanoEsdran LindemannAinda não há avaliações
- Genoma Humano - BiologíaDocumento12 páginasGenoma Humano - BiologíaR,Ainda não há avaliações
- BIOETICA Y El Proyecto Genoma HumanoDocumento2 páginasBIOETICA Y El Proyecto Genoma HumanoDiana Alba SanguinoAinda não há avaliações
- Metodologia Del Genoma HumanoDocumento5 páginasMetodologia Del Genoma Humanoubi_rAinda não há avaliações
- Ficha 06-Ivb-Ct 4º - Genoma Humano-Ivb-2022Documento7 páginasFicha 06-Ivb-Ct 4º - Genoma Humano-Ivb-2022fiorella denegri abrilAinda não há avaliações
- Genoma HumanoDocumento6 páginasGenoma HumanoAlejandra LopezAinda não há avaliações
- Ensayo Genoma HumanoDocumento23 páginasEnsayo Genoma HumanoDamianAinda não há avaliações
- 3 Tema de Análisis-Proyecto Del Genoma HumanoDocumento2 páginas3 Tema de Análisis-Proyecto Del Genoma Humanovaldera198Ainda não há avaliações
- Quien CodificoDocumento21 páginasQuien Codificosergio Art palmerosAinda não há avaliações
- PFC SEDAPAR SRL Actualizacion Al 2018Documento97 páginasPFC SEDAPAR SRL Actualizacion Al 2018Romulo Aycachi Inga0% (1)
- Programa para El Aseguramiento de La Calidad Analítica en Laboratorio Rev 2015Documento56 páginasPrograma para El Aseguramiento de La Calidad Analítica en Laboratorio Rev 2015Romulo Aycachi IngaAinda não há avaliações
- Programa de Monitoreo y Control de Calidad Del Agua 2016Documento23 páginasPrograma de Monitoreo y Control de Calidad Del Agua 2016Romulo Aycachi IngaAinda não há avaliações
- Presentacion PCC para Gerente Gral y Jefes de AreaDocumento38 páginasPresentacion PCC para Gerente Gral y Jefes de AreaRomulo Aycachi IngaAinda não há avaliações
- Exposicion Mecanismos RSEH para SEDAPAR SRLDocumento32 páginasExposicion Mecanismos RSEH para SEDAPAR SRLRomulo Aycachi IngaAinda não há avaliações
- 6 Charla Tec PTFR - Desinfeccion Del Agua - Cloro NARDocumento25 páginas6 Charla Tec PTFR - Desinfeccion Del Agua - Cloro NARRomulo Aycachi IngaAinda não há avaliações
- 7 Charla Tec PTFR - Trabajos Diarios de Operacion y Mantenimiento en PTAP NARDocumento47 páginas7 Charla Tec PTFR - Trabajos Diarios de Operacion y Mantenimiento en PTAP NARRomulo Aycachi IngaAinda não há avaliações
- Proyecto de Tesis - Version Final - Rómulo AycachiDocumento54 páginasProyecto de Tesis - Version Final - Rómulo AycachiRomulo Aycachi Inga100% (5)
- Plan de Control de Calidad PCC SEDAPAR SRL v.02-2016Documento327 páginasPlan de Control de Calidad PCC SEDAPAR SRL v.02-2016Romulo Aycachi Inga100% (4)
- Marco Normativo Vigente en Vertimiento y Uso de Aguas ResidualesDocumento44 páginasMarco Normativo Vigente en Vertimiento y Uso de Aguas ResidualesRomulo Aycachi IngaAinda não há avaliações
- D.S. 031-2010-Sa PDFDocumento33 páginasD.S. 031-2010-Sa PDFcarlu158Ainda não há avaliações
- Planes de Seguridad Del Agua - Capacitacion para SEDAPAR SRLDocumento64 páginasPlanes de Seguridad Del Agua - Capacitacion para SEDAPAR SRLRomulo Aycachi IngaAinda não há avaliações
- Reglamento de Los Requisitos Oficiales Que Deben Reunir Las Aguas para Ser Consideradas Como Potables - 1946/perúDocumento11 páginasReglamento de Los Requisitos Oficiales Que Deben Reunir Las Aguas para Ser Consideradas Como Potables - 1946/perúRomulo Aycachi Inga100% (1)
- Guias para La Calidad Del Agua Potable OMSDocumento408 páginasGuias para La Calidad Del Agua Potable OMSRomulo Aycachi Inga80% (5)
- Manual para El Desarrollo de Planes de Seguridad Del Agua (PSA)Documento116 páginasManual para El Desarrollo de Planes de Seguridad Del Agua (PSA)Romulo Aycachi Inga100% (2)
- El Cuaderno 117 - La MetagenomicaDocumento13 páginasEl Cuaderno 117 - La MetagenomicaRomulo Aycachi Inga100% (1)
- Normas Sobre La Calidad Del Agua para Consumo Humano en El Perú - Estudio JurídicoDocumento51 páginasNormas Sobre La Calidad Del Agua para Consumo Humano en El Perú - Estudio JurídicoRomulo Aycachi IngaAinda não há avaliações
- Monografía - Producción de Bioetanol - XV Curso de TitulaciónDocumento96 páginasMonografía - Producción de Bioetanol - XV Curso de TitulaciónRomulo Aycachi Inga100% (5)
- Normas Oficiales para La Calidad Del Agua en El PerúDocumento55 páginasNormas Oficiales para La Calidad Del Agua en El PerúRomulo Aycachi Inga0% (1)
- Neospora CaninumDocumento19 páginasNeospora CaninumRomulo Aycachi Inga100% (2)
- Estatuto Colegio de Biólogos Del PerúDocumento11 páginasEstatuto Colegio de Biólogos Del PerúRomulo Aycachi IngaAinda não há avaliações
- Biotecnologia y Medio Ambiente - ResumenDocumento28 páginasBiotecnologia y Medio Ambiente - ResumenRodrigo Lopez PochAinda não há avaliações
- 1er Año Medicina 2013-EmbriologiaDocumento28 páginas1er Año Medicina 2013-EmbriologiapanchofronterasAinda não há avaliações
- Dr. Bruce H. Lipton Sobre La Creencia 3Documento11 páginasDr. Bruce H. Lipton Sobre La Creencia 3SonyAinda não há avaliações
- Unidad Iii (3) .Documento68 páginasUnidad Iii (3) .Angel YnojosaAinda não há avaliações
- Cómo Escribir Un Artículo de DivulgaciónDocumento39 páginasCómo Escribir Un Artículo de DivulgaciónDiana VanegasAinda não há avaliações
- Unidad III Clase 1 Genética MedicinaDocumento28 páginasUnidad III Clase 1 Genética MedicinaLiz BlackwoodAinda não há avaliações
- Guia 4 Naturales 8°Documento13 páginasGuia 4 Naturales 8°YEIDER ANDRES PACHECO NUÑEZAinda não há avaliações
- Ficha de Aprendizaje Cta 23 08 2021Documento7 páginasFicha de Aprendizaje Cta 23 08 2021Sebastian Martinez QuisocalaAinda não há avaliações
- Ejercicio 1 EpistemologíaDocumento5 páginasEjercicio 1 EpistemologíaBismark CordobaAinda não há avaliações
- Biotechnology SciencedirectDocumento15 páginasBiotechnology SciencedirectMaria LoaizaAinda não há avaliações
- Trabajo Final BiologiaDocumento14 páginasTrabajo Final BiologiaMAILYN YOMIRA MAILYN YOMIRA DUVERGE/PEREZAinda não há avaliações
- Genes y ConductaDocumento16 páginasGenes y ConductaWilliam Alvarez ZentenoAinda não há avaliações
- Los Avances Que Se Han Producido en Los Últimos Años Han Provocado Una Revolución Respecto Al Análisis de Los Genes HumanosDocumento12 páginasLos Avances Que Se Han Producido en Los Últimos Años Han Provocado Una Revolución Respecto Al Análisis de Los Genes Humanosedith arzolaAinda não há avaliações
- s19 - Fundamentamos La Importancia de La Con Dencialidad de La Información Genética de Cada PersonaDocumento3 páginass19 - Fundamentamos La Importancia de La Con Dencialidad de La Información Genética de Cada PersonaRicardo RamírezAinda não há avaliações
- Silabo - DERECHO GENÉTICO - 2019-2Documento4 páginasSilabo - DERECHO GENÉTICO - 2019-2monicaAinda não há avaliações
- Secretos de Nuestra HerenciaDocumento2 páginasSecretos de Nuestra HerenciaSheila ÁlvarezAinda não há avaliações
- BioéticaDocumento5 páginasBioéticaCYBERSPACEAinda não há avaliações
- ADN y ARNDocumento2 páginasADN y ARNJuan Fernandez100% (1)
- 10 Preguntas Sobre BioéticaDocumento7 páginas10 Preguntas Sobre BioéticaLeandro Ariel LongoAinda não há avaliações
- Sem 13 Informacion GeneticaDocumento42 páginasSem 13 Informacion GeneticaKarina Susan D Carlos PerezAinda não há avaliações
- Genoma HumanoDocumento2 páginasGenoma HumanoFua170000Ainda não há avaliações
- Proyecto Del Genoma HumanoDocumento29 páginasProyecto Del Genoma HumanoCaballero ElvisAinda não há avaliações
- Genética de Las Enfermedades MentalesDocumento3 páginasGenética de Las Enfermedades MentalesMoisés Alejandro Campos Díaz100% (1)
- El Debate Sobre Las Implicaciones Cientificas Eticas Sociales y Legales Del Proyecto Genoma Humano Aportaciones EpistemologicasDocumento541 páginasEl Debate Sobre Las Implicaciones Cientificas Eticas Sociales y Legales Del Proyecto Genoma Humano Aportaciones EpistemologicasadvocatuslegoAinda não há avaliações
- La Ingeniería Genética 2cDocumento2 páginasLa Ingeniería Genética 2cAndrea RojasAinda não há avaliações
- Biología 5toDocumento13 páginasBiología 5toSil PeirettiAinda não há avaliações
- Biotegnologia y NanotecnologiaDocumento25 páginasBiotegnologia y NanotecnologiaMonse MarilesAinda não há avaliações
- El Posthumanismo y El TranshumanismoDocumento55 páginasEl Posthumanismo y El TranshumanismoRaphael Loga100% (3)