Model Answers for Chapter 6: Multiple Linear Regression Problem 6.1 (5.
1 in 1st edition)
Answer to 6.1.a: 1. The data should be partitioned into training and validation sets because we need two sets of data: one to build the model that depicts the relationship between the predictor variables and the predicted variable, and another to validate the models predictive accuracy. 2. The training data set is used to build the model. The algorithm discovers the model using this data set. 3. The validation data is used to validate the model. In this process, the model (built using the training data set) is used to make predictions with the validation data - data that were not used to fit the model. In this way we get an unbiased estimate of how well the model performs. We compute measures of error, which reflect the prediction accuracy. Refer to Data_Partition1 excel sheet in 6.1_Boston_Housing.
Refer to MLR_Output1 excel sheet in 6.1_Boston_Housing.
Answer to 6.1.b: Output of XLMiner: The Regression Model
Input variables Constant term CRIM CHAS RM Coefficient -23.6071014 -0.2611129 2.88669062 7.50815392 Std. Error 3.41045761 0.04066138 1.46451461 0.53549951 p-value SS
0 159255.8125 0 3756.925537 0.04963245 767.8793335 0 7997.099121
Regression equation is MEDV = -23.6071014 +(-0.2611129 * CRIM) +(2.88669062 * CHAS) +(7.50815392 * RM)
[Correction in book: average number of rooms =6. Drop the question What is the prediction error?] Answer to 6.1.c: Regression equation is MEDV = -23.6071014 + (-0.2611129 * CRIM) + (2.88669062 * CHAS) + (7.50815392 * RM)
MEDV = -23.6071014 + (-0.2611129 * 0.1) + (2.88669062 * 0) + (7.50815392 * 6) MEDV = 21.41571
Median house price is $21,415.71
Answer to 6.1.d: There are several variables that measure levels of industrialization, which are expected to be positively correlated. These include INDUS, NOX (pollution), and TAX. We expect a positive relationship between NOX (nitric oxides concentration, a pollutant), INDUS (proportion of non-retail business acres per town) and TAX (tax rate), because areas that have a high proportion of non-retail businesses tend to have higher taxes and more pollution.
Answer to 6.1.d.ii: Refer to the CorrelationTable sheet in 6.1_Boston_Housing.xls Highly correlated pairs are as follows: 1) 2) 3) 4) 5) 6) NOX and INDUS: Correlation coefficient = 0.76365 TAX and INDUS: Correlation coefficient = 0.72076 AGE and NOX: Correlation coefficient = 0.73147 DIS and NOX: Correlation coefficient = -0.76923 DIS and AGE: Correlation coefficient = -0.74788 TAX and RAD: Correlation coefficient = 0.91022
According to the correlation table, we might be able to remove some variables that do not add much information to others that we keep. We might remove INDUS, AGE and TAX.
Answer to 6.1.d.iii: Refer to the MLR_Output2 sheet in 6.1_Boston_Housing.xls for exhaustive search. To find the top three models, the criteria used is as follows: a) Find the 3 highest values of adjusted R-squared. b) Find the 3 values of Cp such that Cp value is near to # coefficients = # variables +1. Summary of top three models to choose the best model: Model 1 is designed using the following 8 variables: CRIM, ZN, NOX, RM, DIS, PTRATIO, B, LSTAT. Model 2 is designed using the following 9 variables: CRIM, ZN, NOX, RM, DIS, RAD, PTRATIO, B, LSTAT. Model 3 is designed using the following 10 variables: CRIM, ZN, CHAS, NOX, RM, DIS, RAD, PTRATIO, B, LSTAT
Note that as we add more variables, the error goes down (but the lower error comes at the cost of a more complex model).
Model I Total sum of squared errors RMS Error Average Error
Model II
Model III
4441.41523
4384.03216
4240.39099
4.68905 -0.3508979
4.65866177 -0.2195216
4.5817065 -0.223719429
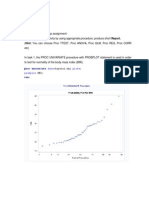
Lift chart (validation dataset) 5000 4500 4000 3500 3000 2500 2000 1500 1000 500 0 0 200 # cases 400 5000 4500 4000 3500 3000 2500 2000 1500 1000 500 0
Lift chart (validation dataset)
Lift chart (validation dataset) 5000 4500 4000 3500 3000 2500 2000 1500 1000 500 0 0 200 # cases 400
Cumulative
Lift chart
Cumulative
Cumulative MEDV using average
Cumulative MEDV using average
Cumulative
Cumulative MEDV when sorted using predicted values
Cumulative MEDV when sorted using predicted values
Cumulative MEDV when sorted using predicted values Cumulative MEDV using average
200 # cases
400
From the above table we see that Model III has the smallest value for Total sum of squared errors and RMSE. Model II has the smallest value for average error. Lift Chart for Model I Decile mean / Global mean Lift Chart for Model II Decile mean / Global mean Lift Chart for Model III Decile mean / Global mean
Deciles 1 2 3 4 5 6 7 8 9 10
Cumulative
Cumulative
Cumulative
1.906763 1.90676253 1.86835 1.86834999 1.955631 1.95563057 1.416264 3.32302638 1.45604 3.32439013 1.36876 3.32439013 1.083507 4.40653299 1.086007 4.41039698 1.086007 4.41039698 1.013273 5.41980601 1.046685 5.4570821 1.051913 5.46230984 0.957359 6.37716491 0.93713 6.3942119 0.941221 6.40353092 7.301339 0.927356 7.30452111 0.909173 7.30338464 0.897808
0.835984 8.14050545 0.804618 8.10800252 0.82462 8.12595868 0.737112 8.87761725 0.803027 8.91102935 0.781434 8.90739265 0.694835 9.57245252 0.654832 9.56586101 0.658468 9.56586101 0.479589 10.0520411 0.485581 10.0514419 0.485581 10.0514419
From the initial cumulative values it appears that the cumulative decile mean is greater for model III. In summary, Model III with the variables CRIM, ZN, CHAS, NOX, RM, DIS, RAD, PTRATIO, B, LSTAT is the best model for predicting Boston Housing prices.
Você também pode gostar
- Profit Driven Business Analytics: A Practitioner's Guide to Transforming Big Data into Added ValueNo EverandProfit Driven Business Analytics: A Practitioner's Guide to Transforming Big Data into Added ValueAinda não há avaliações
- This Study Resource Was: 8.1 Financial Condition of Banks: The File Banks - Xls Includes Data On A Sample of 20 BanksDocumento3 páginasThis Study Resource Was: 8.1 Financial Condition of Banks: The File Banks - Xls Includes Data On A Sample of 20 BanksSaurabh SharmaAinda não há avaliações
- The Boston Housing DatasetDocumento4 páginasThe Boston Housing DatasetSwastik Mishra100% (1)
- Lab Session 6Documento3 páginasLab Session 6howardnguyen7140% (2)
- Int AI TW-PW 03Documento4 páginasInt AI TW-PW 03khalilkhalilb9Ainda não há avaliações
- ML0101EN Reg Simple Linear Regression Co2 Py v1Documento4 páginasML0101EN Reg Simple Linear Regression Co2 Py v1Muhammad RaflyAinda não há avaliações
- Sajjad DSDocumento97 páginasSajjad DSHey Buddy100% (2)
- Logistic RegressionDocumento10 páginasLogistic RegressionParth MehtaAinda não há avaliações
- Solution 1Documento6 páginasSolution 1prakshiAinda não há avaliações
- Benchmarking MLDocumento9 páginasBenchmarking MLYentl HendrickxAinda não há avaliações
- CustomerChurn AssignmentDocumento15 páginasCustomerChurn AssignmentMalavika R Kumar100% (3)
- Objective: Data CollectionDocumento11 páginasObjective: Data CollectionakhilaAinda não há avaliações
- Multiple Linear RegressionDocumento25 páginasMultiple Linear Regression3432meesala100% (1)
- Programming With R Test 2Documento5 páginasProgramming With R Test 2KamranKhan50% (2)
- 2023 Tutorial 11Documento7 páginas2023 Tutorial 11Đinh Thanh TrúcAinda não há avaliações
- Lecture Notes - Linear RegressionDocumento26 páginasLecture Notes - Linear RegressionAmandeep Kaur GahirAinda não há avaliações
- Ch26 ExercisesDocumento14 páginasCh26 Exercisesamisha2562585Ainda não há avaliações
- Probabilistic Engineering DesignDocumento7 páginasProbabilistic Engineering DesignAnonymous NyeLgJPMbAinda não há avaliações
- ML0101EN Reg Mulitple Linear Regression Co2 Py v1Documento5 páginasML0101EN Reg Mulitple Linear Regression Co2 Py v1Rajat SolankiAinda não há avaliações
- Computer-Ided Design of Experiments For Formulations: Explore The Feasible RegionDocumento6 páginasComputer-Ided Design of Experiments For Formulations: Explore The Feasible Regionvijay2101Ainda não há avaliações
- Tutorial 1 - RegressionDocumento6 páginasTutorial 1 - RegressionAnwar ZainuddinAinda não há avaliações
- Week 6 - Model Assumptions in Linear RegressionDocumento17 páginasWeek 6 - Model Assumptions in Linear RegressionThanh Mai PhamAinda não há avaliações
- BSChem-Statistics in Chemical Analysis PDFDocumento6 páginasBSChem-Statistics in Chemical Analysis PDFKENT BENEDICT PERALESAinda não há avaliações
- Model SelectionDocumento11 páginasModel Selection徐天辰Ainda não há avaliações
- 9805 MBAex PredAnalBigDataMar22Documento11 páginas9805 MBAex PredAnalBigDataMar22harishcoolanandAinda não há avaliações
- Group 8 - Business Stats Project - Installment IDocumento16 páginasGroup 8 - Business Stats Project - Installment IAbhee RajAinda não há avaliações
- 1 RegressionDocumento4 páginas1 RegressionAgustin AgustinAinda não há avaliações
- Tutorial 4Documento8 páginasTutorial 4POEASOAinda não há avaliações
- 1 Dear Reader. - .: Appendix For "Are Variations in Term Premia Related To The Macroeconomy?"Documento9 páginas1 Dear Reader. - .: Appendix For "Are Variations in Term Premia Related To The Macroeconomy?"boucharebAinda não há avaliações
- Data Analysis For Accountants Assessment 2Documento14 páginasData Analysis For Accountants Assessment 2gatunemosesAinda não há avaliações
- Stats ProjectDocumento9 páginasStats ProjectHari Atharsh100% (1)
- Telecom Customer Churn Project ReportDocumento25 páginasTelecom Customer Churn Project ReportSravanthi Ammu50% (2)
- CaseStudy ClassificationandEvaluationDocumento4 páginasCaseStudy ClassificationandEvaluationvettithalaAinda não há avaliações
- Data Mining Project DSBA PCA Report FinalDocumento21 páginasData Mining Project DSBA PCA Report Finalindraneel120Ainda não há avaliações
- Bayesian Analysis of Spatially Autocorrelated Data Spatial Data Analysis in Ecology and Agriculture Using RDocumento18 páginasBayesian Analysis of Spatially Autocorrelated Data Spatial Data Analysis in Ecology and Agriculture Using Raletheia_aiehtelaAinda não há avaliações
- BAUDM Assignment Predicting Boston Housing PricesDocumento6 páginasBAUDM Assignment Predicting Boston Housing PricesSurajAinda não há avaliações
- Cell2Cell The Churn GameDocumento13 páginasCell2Cell The Churn GameParthsarthi Sinha50% (2)
- Exercises For Chapter 6 of Vinod's " Hands-On Intermediate Econometrics Using R"Documento25 páginasExercises For Chapter 6 of Vinod's " Hands-On Intermediate Econometrics Using R"damian camargoAinda não há avaliações
- Treatment of Uncertainty in Long-Term PlanningDocumento30 páginasTreatment of Uncertainty in Long-Term PlanningTrevor ClineAinda não há avaliações
- 2012Documento9 páginas2012Akshay JainAinda não há avaliações
- 1 Module 3: Peer Reviewed AssignmentDocumento22 páginas1 Module 3: Peer Reviewed AssignmentAshutosh KumarAinda não há avaliações
- Zerox ReadyDocumento21 páginasZerox Readygowrishankar nayanaAinda não há avaliações
- Task 1Documento7 páginasTask 1Ikhram JohariAinda não há avaliações
- Project +Sweta+Kumari+ +FRA+Milestone+2 July+2021Documento18 páginasProject +Sweta+Kumari+ +FRA+Milestone+2 July+2021sweta kumari100% (1)
- Revised Clustering Business ReportDocumento5 páginasRevised Clustering Business ReportPratigya pathakAinda não há avaliações
- FRA Business ReportDocumento21 páginasFRA Business ReportSurabhi KulkarniAinda não há avaliações
- Approximation of Large-Scale Dynamical Systems: An Overview: A.C. Antoulas and D.C. Sorensen August 31, 2001Documento22 páginasApproximation of Large-Scale Dynamical Systems: An Overview: A.C. Antoulas and D.C. Sorensen August 31, 2001Anonymous lEBdswQXmxAinda não há avaliações
- Discrete-Event Simulation: Figure 1.3: Simple Digital Logic CircuitDocumento8 páginasDiscrete-Event Simulation: Figure 1.3: Simple Digital Logic CircuitkingkabhiAinda não há avaliações
- Diagnostics For Hedonic ModelsDocumento34 páginasDiagnostics For Hedonic Modelsshan4600Ainda não há avaliações
- Real Estate Value Prediction Using Multivariate Regression ModelsDocumento8 páginasReal Estate Value Prediction Using Multivariate Regression ModelsAimane CAFAinda não há avaliações
- Project 2 - Advanced StatisticsDocumento21 páginasProject 2 - Advanced StatisticsDevanshi DaulatAinda não há avaliações
- P1.T2. Quantitative AnalysisDocumento13 páginasP1.T2. Quantitative AnalysisChristian Rey MagtibayAinda não há avaliações
- DA R Assignment2Documento9 páginasDA R Assignment2Shruti PandeyAinda não há avaliações
- Exercises PDFDocumento30 páginasExercises PDFmylisertaAinda não há avaliações
- Students Tutorial Answers Week12Documento8 páginasStudents Tutorial Answers Week12HeoHamHố100% (1)
- MASII Sample QuestionsDocumento14 páginasMASII Sample QuestionsLau MerchanAinda não há avaliações
- Conquest Tutorial 7 MultidimensionalModelsDocumento20 páginasConquest Tutorial 7 MultidimensionalModelsfafume100% (1)
- Reservoir Characterisation 2012Documento7 páginasReservoir Characterisation 2012T C0% (1)
- ExercisIe CollectionDocumento111 páginasExercisIe Collectionkh5892Ainda não há avaliações
- Logistic RegressionDocumento10 páginasLogistic RegressionChichi Jnr100% (1)
- 1 Ladder/Manhole Access DesignDocumento6 páginas1 Ladder/Manhole Access DesignGanesh AdityaAinda não há avaliações
- Rect Plates: Enter Pipe Length in Inches Enter Schedule From The FollowingDocumento19 páginasRect Plates: Enter Pipe Length in Inches Enter Schedule From The FollowingGanesh AdityaAinda não há avaliações
- Piping Wall Thickness / ScheduleDocumento3 páginasPiping Wall Thickness / ScheduleGanesh AdityaAinda não há avaliações
- AWWA Standards Presentation BrandedDocumento22 páginasAWWA Standards Presentation Branded050678Ainda não há avaliações
- Rect Plates Circular Plate: Enter Pipe Length in Inches Enter Schedule From The FollowingDocumento11 páginasRect Plates Circular Plate: Enter Pipe Length in Inches Enter Schedule From The FollowingGanesh AdityaAinda não há avaliações
- WeightsDocumento11 páginasWeightsGanesh AdityaAinda não há avaliações
- Penetration Into The Base Metal: If You'Ve Ever Asked Yourself "Why?"Documento2 páginasPenetration Into The Base Metal: If You'Ve Ever Asked Yourself "Why?"Ganesh AdityaAinda não há avaliações
- 2011 Ky Drivers ManualDocumento101 páginas2011 Ky Drivers ManualGanesh AdityaAinda não há avaliações
- SDM Example 3 Steel SMF PDFDocumento30 páginasSDM Example 3 Steel SMF PDFRicardoMallmaAinda não há avaliações
- Tank Manual2 Of2Documento195 páginasTank Manual2 Of2AlbertAinda não há avaliações
- Bin and Hopper Design LectureDocumento73 páginasBin and Hopper Design LectureGanesh Aditya100% (4)
- Bin and Hopper Design LectureDocumento73 páginasBin and Hopper Design LectureGanesh Aditya100% (4)
- All As 525 v2Documento10 páginasAll As 525 v2Al-amin AlexAinda não há avaliações
- 1Documento3 páginas1Ronil JainAinda não há avaliações
- Comparative Analysis of Machine Learning Techniques For Indian Liver Disease PatientsDocumento5 páginasComparative Analysis of Machine Learning Techniques For Indian Liver Disease PatientsM. Talha NadeemAinda não há avaliações
- Multivariate Data AnalysisDocumento7 páginasMultivariate Data AnalysisThùyy VyAinda não há avaliações
- MTH 4130 Final ProjectDocumento14 páginasMTH 4130 Final ProjectJoseph RojasAinda não há avaliações
- 4 Types of ReliabilityDocumento57 páginas4 Types of ReliabilityFloravie OnateAinda não há avaliações
- 3'is REVIEWERDocumento8 páginas3'is REVIEWERNiki YolangcoAinda não há avaliações
- Paper AIMLDocumento5 páginasPaper AIMLNandita Hans0% (1)
- Grade 10 (Quartile)Documento21 páginasGrade 10 (Quartile)Roqui M. Gonzaga100% (2)
- Introduction and Background of The StudyDocumento46 páginasIntroduction and Background of The StudyHannah RioAinda não há avaliações
- An Exploratory Data Analysis For Loan Prediction Based On Nature of The ClientsDocumento4 páginasAn Exploratory Data Analysis For Loan Prediction Based On Nature of The ClientsKanavAinda não há avaliações
- Applied Data Science ModuleDocumento4 páginasApplied Data Science ModuleAkhi DanuAinda não há avaliações
- Unit 8 Research Project InformationDocumento3 páginasUnit 8 Research Project InformationAngel YangAinda não há avaliações
- ASt Asnn3Documento13 páginasASt Asnn3Isha BAinda não há avaliações
- Performance Apprasial ThesisDocumento39 páginasPerformance Apprasial ThesisJunaid Sabri100% (1)
- Using Outreg2 To Report Regression Output, Descriptive Statistics, Frequencies and Basic CrosstabulationsDocumento16 páginasUsing Outreg2 To Report Regression Output, Descriptive Statistics, Frequencies and Basic CrosstabulationsRicardo MedinaAinda não há avaliações
- Organization and Management Student Learning ModuleDocumento7 páginasOrganization and Management Student Learning ModuleJoan Mae Angot - VillegasAinda não há avaliações
- CH 02 Wooldridge 6e PPT UpdatedDocumento39 páginasCH 02 Wooldridge 6e PPT UpdatedMy Tran HaAinda não há avaliações
- Technical Paper 7 Statistical and Experimental Design Considerations in Alley FarmingDocumento23 páginasTechnical Paper 7 Statistical and Experimental Design Considerations in Alley FarmingvmgobinathAinda não há avaliações
- IME 212 Course OrientationDocumento15 páginasIME 212 Course OrientationfuckyoAinda não há avaliações
- Excel WorkDocumento7 páginasExcel WorkaramboooAinda não há avaliações
- Data AnalysisDocumento25 páginasData AnalysisSrinivasan Manavalan100% (1)
- Fuzzy C Means (Overlapping Clustering)Documento13 páginasFuzzy C Means (Overlapping Clustering)Ravi GuptaAinda não há avaliações
- 7.0 Prescriptive AnalyticsDocumento63 páginas7.0 Prescriptive AnalyticsKathryn Joy RamosAinda não há avaliações
- DBA DSP Template - Fall 2022Documento54 páginasDBA DSP Template - Fall 2022Jeffrey O'LearyAinda não há avaliações
- Data Warehousing and Data Mining JNTU Previous Years Question PapersDocumento4 páginasData Warehousing and Data Mining JNTU Previous Years Question PapersRakesh VarmaAinda não há avaliações
- Chapter 8 Simple Linear RegressionDocumento17 páginasChapter 8 Simple Linear RegressionNur Iffatin100% (2)
- Survival Analysis. Techniques For Censored and Truncated Data (2Nd Ed.)Documento3 páginasSurvival Analysis. Techniques For Censored and Truncated Data (2Nd Ed.)irsadAinda não há avaliações
- Principles and Applications of Multilevel Modeling in Human Resource Management ResearchDocumento15 páginasPrinciples and Applications of Multilevel Modeling in Human Resource Management ResearchZairaZaviyarAinda não há avaliações
- Predictive Analytics The Power To Predict Who Will Click, Buy, Lie, or DieDocumento3 páginasPredictive Analytics The Power To Predict Who Will Click, Buy, Lie, or DieFizza ChAinda não há avaliações