Você também pode gostar
- Never Split the Difference: Negotiating As If Your Life Depended On ItNo EverandNever Split the Difference: Negotiating As If Your Life Depended On ItNota: 4.5 de 5 estrelas4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNo EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNota: 4.5 de 5 estrelas4.5/5 (474)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNo EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNota: 4 de 5 estrelas4/5 (5782)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNo EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNota: 4 de 5 estrelas4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)No EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Nota: 4 de 5 estrelas4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingNo EverandThe Little Book of Hygge: Danish Secrets to Happy LivingNota: 3.5 de 5 estrelas3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNo EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNota: 3.5 de 5 estrelas3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnNo EverandTeam of Rivals: The Political Genius of Abraham LincolnNota: 4.5 de 5 estrelas4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNo EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNota: 4.5 de 5 estrelas4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNo EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNota: 4.5 de 5 estrelas4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerNo EverandThe Emperor of All Maladies: A Biography of CancerNota: 4.5 de 5 estrelas4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyNo EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyNota: 3.5 de 5 estrelas3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaNo EverandThe Unwinding: An Inner History of the New AmericaNota: 4 de 5 estrelas4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNo EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNota: 4 de 5 estrelas4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)No EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Nota: 4.5 de 5 estrelas4.5/5 (119)
- Basic Statistics CalculationDocumento29 páginasBasic Statistics Calculationcostasn100% (4)
- Libro Dyadic Data Analysis PDFDocumento480 páginasLibro Dyadic Data Analysis PDFLu100% (1)
- CSE 447: Digital Signal Processing: Dept. of Computer Science and EngineeringDocumento33 páginasCSE 447: Digital Signal Processing: Dept. of Computer Science and EngineeringKomal BanikAinda não há avaliações
- Trend Analysis-1Documento45 páginasTrend Analysis-1TauseefAinda não há avaliações
- Wind Load CoefficientDocumento11 páginasWind Load CoefficientEdison LuAinda não há avaliações
- 4-Accuracy in Forecasting PDFDocumento43 páginas4-Accuracy in Forecasting PDFAmber KiranAinda não há avaliações
- Motivasi SosialDocumento18 páginasMotivasi SosialAlfiatus SholihahAinda não há avaliações
- Common Method VarianceDocumento32 páginasCommon Method Varianceegi radiansyahAinda não há avaliações
- Economics of Production 11:373:321: Practice Test QuestionsDocumento32 páginasEconomics of Production 11:373:321: Practice Test QuestionsGaby AoudeAinda não há avaliações
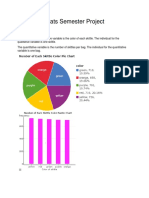
- Stats Semester ProjectDocumento11 páginasStats Semester Projectapi-276989071Ainda não há avaliações
- Tugas - 3a - Motor EducabilityDocumento34 páginasTugas - 3a - Motor EducabilityAnonymous 9j9tsspyBAinda não há avaliações
- Mid-term investment questionsDocumento10 páginasMid-term investment questionsZobia JavaidAinda não há avaliações
- Practical Statistics FOR Medical Research: Douglas G. AltmanDocumento6 páginasPractical Statistics FOR Medical Research: Douglas G. AltmanRogeriano21Ainda não há avaliações
- CHAY, MUNSHI - Black Networks After Emancipation - Evidence From Reconstruction and The Great MigrationDocumento40 páginasCHAY, MUNSHI - Black Networks After Emancipation - Evidence From Reconstruction and The Great MigrationTheCremaAinda não há avaliações
- TURBID: A Routine For Generating Random Turbulent Inflow DataDocumento21 páginasTURBID: A Routine For Generating Random Turbulent Inflow DataPeterAinda não há avaliações
- L2 Learners' Anxiety, Self-Confidence and Oral PerformanceDocumento12 páginasL2 Learners' Anxiety, Self-Confidence and Oral PerformanceRifkiAinda não há avaliações
- Combining Scores Multi Item ScalesDocumento41 páginasCombining Scores Multi Item ScalesKevin CannonAinda não há avaliações
- Expected Price Functionof Price SensitivityDocumento10 páginasExpected Price Functionof Price SensitivityMr PoopAinda não há avaliações
- Oxford University Press - Online Resource Centre - Multiple Choice QuestionsDocumento4 páginasOxford University Press - Online Resource Centre - Multiple Choice Questionsshahid Hussain100% (1)
- Stats: Data and Models Solution Chapter 1-4Documento32 páginasStats: Data and Models Solution Chapter 1-4anon283Ainda não há avaliações
- Econometrics Cheat Sheet Stock and WatsonDocumento2 páginasEconometrics Cheat Sheet Stock and WatsonfabbeAinda não há avaliações
- Partial and Multiple Correlation AnalysisDocumento5 páginasPartial and Multiple Correlation AnalysisIsmith PokhrelAinda não há avaliações
- Regresión y CalibraciónDocumento6 páginasRegresión y CalibraciónAlbertoMartinezAinda não há avaliações
- SFC March 2018 Exam MS - Final PDFDocumento10 páginasSFC March 2018 Exam MS - Final PDFNii DerryAinda não há avaliações
- Flight-to-Quality Order Flow Predicts Economic Growth, Interest RatesDocumento37 páginasFlight-to-Quality Order Flow Predicts Economic Growth, Interest RatesSafuan HalimAinda não há avaliações
- M mMatthewDimensions06paperDocumento15 páginasM mMatthewDimensions06paperCADTDD100% (1)
- The Impact of Web Page Text-Background Colour Combinations On Readability, Retention, Aesthetics and Behavioural IntentionDocumento14 páginasThe Impact of Web Page Text-Background Colour Combinations On Readability, Retention, Aesthetics and Behavioural IntentionDayaAinda não há avaliações
- The Correlation Between Reading Comprehension and Translating Ability of 6 Semester English Literature Students Binus UniversityDocumento15 páginasThe Correlation Between Reading Comprehension and Translating Ability of 6 Semester English Literature Students Binus UniversityRosatri HandayaniAinda não há avaliações
- Measuring Peter Pan Syndrome: Development of a ScaleDocumento14 páginasMeasuring Peter Pan Syndrome: Development of a ScaleAshley WickardAinda não há avaliações
- The Role of Communal NarcissismDocumento14 páginasThe Role of Communal NarcissismMihaela ElaAinda não há avaliações