Escolar Documentos
Profissional Documentos
Cultura Documentos
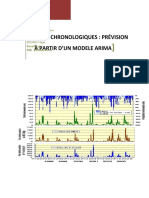
Modèles de Prévision Séries Temporelles Arthur Charpentier
Enviado por
DirumilTítulo original
Direitos autorais
Formatos disponíveis
Compartilhar este documento
Compartilhar ou incorporar documento
Você considera este documento útil?
Este conteúdo é inapropriado?
Denunciar este documentoDireitos autorais:
Formatos disponíveis
Modèles de Prévision Séries Temporelles Arthur Charpentier
Enviado por
DirumilDireitos autorais:
Formatos disponíveis
Modles de prvision
Sries temporelles
Arthur Charpentier
1
UQAM, ACT6420, Hiver 2011
15 mai 2012
1
charpentier.arthur@uqam.ca, url : http://freakonometrics.blog.free.fr/
1
Contents
1 Introduction gnrale et notations 7
1.1 Approches temps/frquences : un peu dhistoire . . . . . . . . . . . . . . . 7
1.1.1 Analyse harmonique . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.1.2 Modles autoregressifs et moyennes mobiles . . . . . . . . . . . . . 9
1.1.3 Lapproche temporelle : concept de corrlation srielle . . . . . . . 10
1.1.4 Lquivalence entre les deux approches temps/frquence . . . . . . . 11
1.2 Les dveloppements rcents . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.2.1 Les modles ARMA, ARIMA et SARIMA : modles linaires . . 11
1.2.2 Modles ARCH - volatilit stochastique . . . . . . . . . . . . . . . 13
1.2.3 Les processus mmoire longue . . . . . . . . . . . . . . . . . . . . 13
1.2.4 Les processus multivaris . . . . . . . . . . . . . . . . . . . . . . . . 14
1.2.5 Exemple : histoire de la prvision des modles conomiques
(macroconomiques) . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.2.6 Remarque sur les donnes hautes frquences . . . . . . . . . . . . . 16
1.3 Thorie des processus temps discret . . . . . . . . . . . . . . . . . . . . . 17
1.3.1 Stationnarit des processus . . . . . . . . . . . . . . . . . . . . . . . 17
1.3.2 Proprit de Markov en temps discret . . . . . . . . . . . . . . . . . 18
1.4 Objectifs de ltudes des sries temporelles . . . . . . . . . . . . . . . . . . 19
1.4.1 Description et modlisation . . . . . . . . . . . . . . . . . . . . . . 19
1.4.2 Prvision . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
1.4.3 Filtrage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
1.5 Conseils bibliographiques (en franais, et en anglais) . . . . . . . . . . . . . 20
2 Proprits des processus univaris en temps discret 22
2.1 Rappels sur les martingales temps discret . . . . . . . . . . . . . . . . . . 22
2.2 Rappels sur les Chanes de Markov . . . . . . . . . . . . . . . . . . . . . . 23
2.3 Notions de stationnairit . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.4 Fonction dautocovariance et densit spectrale . . . . . . . . . . . . . . . . 26
2.4.1 Autocovariance et autocorrlation . . . . . . . . . . . . . . . . . . . 26
2.4.2 Densit spectrale . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.4.3 Estimation de la fonction dautocorrlation . . . . . . . . . . . . . . 28
2.4.4 Estimation de la densit spectrale . . . . . . . . . . . . . . . . 30
2.5 Lien entre temps continu et temps discret . . . . . . . . . . . . . . . . 31
3 Dsaisonnalisation par regression linaire 37
3.1 Prsentation des donnes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.2 Le modle linaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.2.1 Hypothses sur les erreurs . . . . . . . . . . . . . . . . . . . . . . . 38
3.2.2 Composante saisonnire du modles . . . . . . . . . . . . . . . . . . 38
3.2.3 Composante tendancielle . . . . . . . . . . . . . . . . . . . . . . . . 38
3.2.4 Modle trimestriel de Buys-Ballot (1847) . . . . . . . . . . . . . . . 39
2
3.3 Estimateur des moindres carrs ordinaires (mco) . . . . . . . . . . . . . . . 41
3.3.1 Solutions gnrales . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.3.2 Cas particulier : le modle trimestriel de Buys-Ballot . . . . . . . . 42
3.3.3 Gnralisation des formules de Buys-Ballot (tendance linaire) . . . 42
3.4 Application au trac voyageur . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.4.1 Srie agrge par trimestre . . . . . . . . . . . . . . . . . . . . . . . 43
3.4.2 Analyse sur donnes mensuelles . . . . . . . . . . . . . . . . . . . . 47
3.5 Proprits statistiques des estimateurs . . . . . . . . . . . . . . . . . . . . 48
3.6 Application au trac sur lautoroute A7 . . . . . . . . . . . . . . . . . . . 49
3.7 Prvision un horizon h . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4 Dsaisonnalisation par moyennes mobiles 52
4.1 Gnralits sur les moyennes mobiles . . . . . . . . . . . . . . . . . . . . . 52
4.1.1 Notion doprateur retard L . . . . . . . . . . . . . . . . . . . . . . 52
4.1.2 Les moyennes mobiles . . . . . . . . . . . . . . . . . . . . . . . . . 53
4.1.3 Lespace des oprateurs moyenne-mobile . . . . . . . . . . . . . . . 57
4.2 Vecteurs propres associs une moyenne mobile . . . . . . . . . . . . . . . 57
4.2.1 Les sries absorbes : = 0 . . . . . . . . . . . . . . . . . . . . . . 58
4.2.2 Absorbtion de la composante saisonnire . . . . . . . . . . . . . . . 58
4.2.3 Les sries invariantes : = 1 . . . . . . . . . . . . . . . . . . . . . . 59
4.2.4 Transformation de suites gomtriques (r
t
) . . . . . . . . . . . . . . 59
4.2.5 Moyenne mobile dirence
p
= (I L)
p
. . . . . . . . . . . . . . . 60
4.2.6 Moyenne mobile dirence saisonnire
p,s
= (I L
s
)
p
. . . . . . . 61
4.2.7 Moyenne mobile impaire . . . . . . . . . . . . . . . . . . . . . . . . 62
4.2.8 Moyenne mobile paire . . . . . . . . . . . . . . . . . . . . . . . . . 62
4.3 Notions de bruit blanc . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
4.3.1 Transformation dun bruit blanc . . . . . . . . . . . . . . . . . . . . 63
4.4 Les procdures X11 et X12 . . . . . . . . . . . . . . . . . . . . . . . 64
4.4.1 Un algorithme simple de dsaisonnalisation . . . . . . . . . . . . . . 64
4.4.2 Lalgorithme de base de la mthode X11 . . . . . . . . . . . . . . . 64
5 La prvision par lissage exponentiel 67
5.1 Principe du lissage exponentiel simple . . . . . . . . . . . . . . . . . . . . . 67
5.1.1 Mthode adaptative de mise jour (ordre 1) . . . . . . . . . . . . . 67
5.1.2 Choix de la constante de lissage . . . . . . . . . . . . . . . . . . . . 68
5.1.3 Lien entre robustesse de la prvision et choix de . . . . . . . . . . 69
5.1.4 Exemple dapplication . . . . . . . . . . . . . . . . . . . . . . . . . 70
5.2 Principe de lissage exponentiel double . . . . . . . . . . . . . . . . . . . . . 72
5.2.1 Mthode adaptative de mise jour (ordre 1) . . . . . . . . . . . . . 73
5.2.2 Application de la mthode de lissage exponentiel double . . . . . . 73
5.3 Application au trac sur lautoroute A7 . . . . . . . . . . . . . . . . . . . 75
5.4 Lissage exponentiel multiple, ou gnralis . . . . . . . . . . . . . . . . . . 77
5.4.1 Mthode adaptative de mise jour (ordre 1) . . . . . . . . . . . . . 79
3
5.5 Les mthodes de Holt-Winters (1960) . . . . . . . . . . . . . . . . . . . . . 79
5.5.1 Mthode non saisonnire . . . . . . . . . . . . . . . . . . . . . . . . 79
5.5.2 La mthode saisonnire additive . . . . . . . . . . . . . . . . . . . . 80
5.6 Exemple de mise en pratique des mthodes de lissage . . . . . . . . . . . . 81
5.6.1 Prsentation des donnes . . . . . . . . . . . . . . . . . . . . . . . . 81
5.6.2 Lissage linaire . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
5.6.3 Lissage exponentiel simple . . . . . . . . . . . . . . . . . . . . . . . 83
5.6.4 Lissage exponentiel double . . . . . . . . . . . . . . . . . . . . . . . 83
6 Introduction aux modles linaires ARIMA 84
6.1 A quoi ressemblent les processus (S)ARIMA ? . . . . . . . . . . . . . . . . 84
6.2 Rappels sur les espaces L
2
. . . . . . . . . . . . . . . . . . . . . . . . . . . 84
6.2.1 Proprits topologiques . . . . . . . . . . . . . . . . . . . . . . . . . 84
6.2.2 Rappel sur les vecteurs et processus gaussiens . . . . . . . . . . . . 85
6.2.3 Rgression ane dans L
2
. . . . . . . . . . . . . . . . . . . . . . . . 85
6.2.4 La notion dinnovation . . . . . . . . . . . . . . . . . . . . . . . . . 87
6.3 Polynmes doprateurs retard L et avance F . . . . . . . . . . . . . . . . 89
6.3.1 Rappels sur les oprateurs retards . . . . . . . . . . . . . . . . . . . 89
6.3.2 Inversibilit des polynmes P (L) . . . . . . . . . . . . . . . . 89
6.4 Fonction et matrices autocorrlations . . . . . . . . . . . . . . . . . . . . . 92
6.4.1 Autocovariance et autocorrlation . . . . . . . . . . . . . . . . . . . 92
6.4.2 Autocorrlations partielles . . . . . . . . . . . . . . . . . . . . . . . 93
6.4.3 Densit spectrale . . . . . . . . . . . . . . . . . . . . . . . . . 96
6.4.4 Autocorrlations inverses . . . . . . . . . . . . . . . . . . . . . 99
6.4.5 Complment : autocorrlogrammes de fonctions dterministes . . . 100
6.5 Les processus autorgressifs : AR(p) . . . . . . . . . . . . . . . . . . . . . 101
6.5.1 Rcriture de la forme AR(p) . . . . . . . . . . . . . . . . . . . . . 102
6.5.2 Proprits des autocorrlations - les quations de Yule-Walker . . . 104
6.5.3 Le processus AR(1) . . . . . . . . . . . . . . . . . . . . . . . . . . 106
6.5.4 Le processus AR(2) . . . . . . . . . . . . . . . . . . . . . . . . . . 111
6.6 Les processus moyenne-mobile : MA(q) . . . . . . . . . . . . . . . . . . . 113
6.6.1 Proprits des autocorrlations . . . . . . . . . . . . . . . . . . . . 114
6.6.2 Le processus MA(1) . . . . . . . . . . . . . . . . . . . . . . . . . . 116
6.6.3 Le processus MA(2) . . . . . . . . . . . . . . . . . . . . . . . . . . 118
6.7 Les processus ARMA(p, q) . . . . . . . . . . . . . . . . . . . . . . . . . . . 119
6.7.1 Proprits des autocorrlations . . . . . . . . . . . . . . . . . . . . 120
6.7.2 Densit spectrale des processus ARMA(p, q) . . . . . . . . . . . . . 121
6.7.3 Les processus ARMA(1, 1) . . . . . . . . . . . . . . . . . . . . . . 121
6.8 Introduction aux modles linaires non-stationnaires . . . . . . . . . . . . . 122
6.9 Les processus ARIMA(p, d, q) . . . . . . . . . . . . . . . . . . . . . . . . . 124
6.9.1 Processus ARIMA et formes AR ou MA . . . . . . . . . . . . . . . 125
6.10 Les modles SARIMA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 126
6.11 Thorme de Wold . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
4
6.12 Thorie spectrale et processus ARIMA . . . . . . . . . . . . . . . . . 130
6.12.1 Thorie spectrale et notion de ltre . . . . . . . . . . . . . . . . . . 131
6.12.2 Le spectre dun processus ARMA . . . . . . . . . . . . . . . . . . . 132
6.12.3 Estimation de la densit spectrale dun processus . . . . . . . . . . 133
7 Estimation des modles ARIMA : Box-Jenkins 137
7.1 Estimation du paramtre dintgration d . . . . . . . . . . . . . . . . . . . 137
7.1.1 Approche empirique par lautocorrlogramme . . . . . . . . . . . . 137
7.1.2 Tests de racine unit . . . . . . . . . . . . . . . . . . . . . . . . . . 137
7.1.3 Tests de racines unitaires saisonnires . . . . . . . . . . . . . . . . . 142
7.1.4 Complment sur la notion de sur-direntiation . . . . . . . . . . . 144
7.2 Estimation des ordres p et q dun modle ARMA(p, q) . . . . . . . . . . . 144
7.2.1 Problmes dunicit de la reprsentation ARMA . . . . . . . . . . . 144
7.2.2 Comportement asymptotique des moments empiriques . . . . . . . 146
7.2.3 Mthode pratique destimation des ordres p et q . . . . . . . . . . . 147
7.2.4 Cas dun processus MA(q) . . . . . . . . . . . . . . . . . . . . . . . 148
7.2.5 Cas dun processus ARMA(p, q) . . . . . . . . . . . . . . . . . . . 148
7.2.6 Proprit des estimateurs . . . . . . . . . . . . . . . . . . . . . . . 152
7.3 Test de bruit blanc et de stationnarit . . . . . . . . . . . . . . . . . . . . 152
7.3.1 Analyse des fonctions dautocorrlation . . . . . . . . . . . . . . . . 152
7.3.2 Statistique de Box-Pierce, ou test de portmanteau . . . . . . . . . 153
7.3.3 Complments : les tests de normalit . . . . . . . . . . . . . . . . . 155
7.3.4 Complment : Test de rupture et de changement de tendance . . . 156
7.4 Estimation des paramtres dun modle ARMA(p, q) . . . . . . . . . . . . 161
7.4.1 Attention la constante . . . . . . . . . . . . . . . . . . . . . . . . 161
7.4.2 Estimation pour les modles AR(p) par la m thode des moindres
carrs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164
7.4.3 Vraissemblance dun processus ARMA(p, q) . . . . . . . . . . . . . 165
7.4.4 Rsolution du programme doptimisation . . . . . . . . . . . . . . . 167
7.4.5 Comparaison des direntes mthodes dinfrence . . . . . . . . . . 172
7.4.6 Tests statistiques de validation du modle . . . . . . . . . . . . . . 173
7.5 Choix dun modle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 174
7.5.1 Critre de pouvoir prdicitf . . . . . . . . . . . . . . . . . . . . . . 174
7.5.2 Critre dinformation . . . . . . . . . . . . . . . . . . . . . . . . . . 174
7.6 Application . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175
7.6.1 Identication du modle : recherche des paramtres d, p et q . . . . 175
7.6.2 Estimation du modle ARIMA . . . . . . . . . . . . . . . . . . . . 176
7.6.3 Vrication . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 176
8 Prvisions laide des modles ARIMA : Box-Jenkins 177
8.1 Prvisions laide dun modle AR(p) . . . . . . . . . . . . . . . . . . . . 177
8.2 Prvisions laide dun modle MA(q) . . . . . . . . . . . . . . . . . . . . 178
8.2.1 Utilisation de lcriture AR() du processus MA(q) . . . . . . . . 178
5
8.2.2 Utilisation de la formule de mise jour des rsultats . . . . . . . . 179
8.3 Prvisions laide dun modle ARMA(p, q) . . . . . . . . . . . . . . . . . 179
8.3.1 Utilisation de la forme AR() pu processus ARMA(p, q) . . . . . 179
8.3.2 Utilisation de la forme MA() pu processus ARMA(p, q) et des
formules de mise jour . . . . . . . . . . . . . . . . . . . . . . . . . 180
8.4 Prvisions dans le cas dun processus ARIMA(p, d, q) . . . . . . . . . . . . 180
8.4.1 Utilisation de lapproximation AR . . . . . . . . . . . . . . . . . . . 181
8.4.2 Utilisation de lapproximation MA . . . . . . . . . . . . . . . . . . 182
8.5 Intervalle de conance de la prvision . . . . . . . . . . . . . . . . . . . . . 182
8.6 Prvision pour certains processus AR et MA . . . . . . . . . . . . . . . . . 183
8.6.1 Prvision pour un processus AR(1) . . . . . . . . . . . . . . . . . . 183
8.6.2 Prvision pour un processus MA(1) . . . . . . . . . . . . . . . . . 184
8.6.3 Prvision pour un processus ARIMA(1, 1, 0) . . . . . . . . . . . . 186
8.7 Application . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 187
8.7.1 Example de prvision : cas dcole . . . . . . . . . . . . . . . . . . 187
8.7.2 Exemple dapplication : cas pratique . . . . . . . . . . . . . . . . . 189
9 Mise en oeuvre de la mthode de Box & Jenkins 190
9.1 Application de la srie des taux dintrt 3 mois . . . . . . . . . . . . . . 190
9.1.1 Modlisation de la srie . . . . . . . . . . . . . . . . . . . . . . . . . 191
9.1.2 Estimation des paramtres dune modlisation ARIMA(1, 1, 1) . . 192
9.1.3 Estimation des paramtres dune modlisation ARIMA(2, 1, 2) . . 193
9.1.4 Estimation des paramtres dune modlisation ARIMA(4, 1, 4) . . 193
9.1.5 Estimation des paramtres dune modlisation ARIMA(8, 1, 2) . . 194
9.1.6 Estimation des paramtres dune modlisation ARIMA(8, 1, 4) . . 194
9.1.7 Choix du modle . . . . . . . . . . . . . . . . . . . . . . . . . . . . 194
9.2 Modlisation du taux de croissance du PIB amricain . . . . . . . . . . . 195
6
Remarque 1. Ces notes de cours sont bases sur de vieilles notes de cours datant de
2005, utilises lUniversit Paris 9 Dauphine. Les notes taient alors bases sur des
codes SAS, mais elles sont ajourdhui en R.
1 Introduction gnrale et notations
Ltude des sries temporelles, ou sries chronologiques, correspond lanalyse statistique
dobservations rgulirement espaces dans le temps. Elles ont t utilises en astronomie
(on the periodicity of sunspots, 1906), en mtorologie (time-series regression of sea
level on weather, 1968), en thorie du signal (Noise in FM receivers, 1963), en biolo-
gie (the autocorrelation curves of schizophrenic brain waves and the power spectrum,
1960), en conomie (time-series analysis of imports, exports and other economic vari-
ables, 1971)...etc.
1.1 Approches temps/frquences : un peu dhistoire
De faon gnrale, quand on parle de sries stationnaires, on a en tte une reprsentation
de la forme X
t
, o t Z, reprsentant les observations (potentielles) du processus, dont on
peut dnir un ensemble dautocovariance (t, s) = E([X
t
] [X
s
]) qui ne dpend
que la distance entre t et s, (t, s) = (t + h, s + h) pour tout h Z (notion faible de
stationnarit). On demande gnralement cette autocovariance (t, s) de tendre vers
0 quand la dirence entre t et s tend vers linni : la covariance entre des lments trs
loigns dans la srie tend vers 0.
Cette approche, base sur lutilisation des corrlations, correspond lanalyse de type
temporelle : elle consiste tudier les corrlations croises de fonctions de la srie (X
t
).
Ces mthodes sont gnralement paramtriques de type moyenne-mobiles (moving average
MA) ou autorgressives (AR) - voire les deux (ARMA). Toutes ces mthodes consistants
estimer des paramtres peuvent gnralement tre vus comme des gnralisations de la
rgression linaire.
Lautre approche galement utilise est celle base sur ltude des frquences. Cette
vision est une gnralisation des mthodes utilises en analyse de Fourier. Lide est
ici dapproximer une fonction analytique par une somme pondre de fonctions sinus ou
cosinus.
Historiquement, ce sont les astonomes qui les premiers ont travaill sur des sries
chronologiques. La reproduction ci-dessous est tir dun manuscrit du X
e
sicle, reprsen-
tant linclinaison des orbites des plantes en fonction du temps. Cest en particulier grce
ce genre de donnes que Kepler a pu noncer ses lois sur le mouvement des plantes.
7
Ces visualisations graphiques ont permis, grce aux dirents outils mathmatiques
mis en place au XV III
e
et XIX
e
sicles, de mettre en place les premires techniques
dtude des sries chronologiques
2
, parmi lesquelles, lanalyse harmonique.
1.1.1 Analyse harmonique
Les astronomes ont t les premiers utiliser lanalyse de Fourier pour des sries
chronologiques. Leur but tait de dtecter des saisonalits caches au sein de leurs don-
nes. Ainsi, Lagrange a utilis ces mthodes pour dtecter de la priodicit cache en
1772 et en 1778. Un demi-sicle plus tard, en 1847, Buys et Ballot, dans Les change-
ments priodiques de tempratures ont propos des mthodes pour tudier la priodicit
de donnes astronomiques. Toutefois, il a fallu attendre 1889 pour que Sir Arthur Shuster
introduise le priodogramme, qui constitue la base des mthodes spectrales danalyse de
sries chronologiques.
Lide est la suivante : on recherche un modle sous-jacent de la forme
Y
t
=
j
cos [
j
t
j
] +
t
=
[
j
cos (
j
t) +
j
sin (
j
t)] +
t
,
o (
t
) est une suite de variables alatoires indpendantes identiquement distribues, qui
correspondront un bruit blanc (cette notion serait longuement dveloppe par la suite).
Le facteur
j
(ou
_
2
j
+
2
j
) correspond lamplitude de la j-me composante pri-
odique, et indique le poids de cette composante au sein de la somme.
2
En fait, comme le note Bernstein dans Against the Gods (the remarkable story of risk), les grecs ou
les hbreux ont observs des phnomnes cycliques (par exemple), mais ils nont jamais pens faire de
la prvision. Il a fallu attendre la Renaissance pour que lavenir ne soit plus quune question de chance
ou un fruit du hasard.Y compris au XV IIIme sicle, prvoir des phnomne futurs pouvait faire croire
une tentative de rivaliser avec les dieux : Halley remarqua que la mme comte fut aperue en 1531,
en 1607 et en 1682 (cette comte avait t observe dailleurs depuis 240 avant J.C.), et il prvoit quon
la reverra en 1758 (ce fut eectivement le cas, au grand moi de toute lEurope, puisque tous les 76 ans,
la comte, dite de Halley, arrive en vue de la terre).
8
A partir dun chantillon Y
0
, ..., Y
T1
, et en considrant les frquences
j
= 2j/T, le
priodogramme est dni par
I (
j
) =
2
T
_
_
Y
t
cos (
j
)
_
2
+
_
Y
t
sin (
j
)
_
2
_
=
T
2
_
a
2
(
j
) + b
2
(
j
)
_
.
Il est alors possible de montrer que 2I (
j
) /T est un estimateur consistant de
2
j
(au
sens o cet estimateur converge en probabilit quand le nombre dobservations augmente).
Cette convergence t longuement tudie par Yule en 1927.
En 1924, Whittaker et Robinson ont utilis cette thorie sur la brillance de ltoile T-
Ursa Major, observe sur 600 jours, et ont montr que la brillance pouvait tre modlise
(presque parfaitement) laide de 2 fonctions harmoniques, de priodes respectives 24 et
29 jours.
Si cette thorie a donn de trs bons rsultats en astronomie, son application en
conomie a conduit des rsultats nettement moins concluants. En 1921 et 1922, Bev-
eridge a utilis cette thorie sur le prix du bl (wheat prices and rainfall in western
europe). La srie prsentait tellement de pics quau moins 20 priodicits taient possi-
bles... et plus encore si lon commenait prendre en compte de facteurs conomiques ou
mtorologiques.
Si les phnomnes astronomiques permettent dutiliser cette thorie, cest parce que
des cycles parfaitement rguliers sont observs. Toutefois, cette mthode sest rvle plus
complique mettre en oeuvre en sciences humaines.
1.1.2 Modles autoregressifs et moyennes mobiles
Deux articles en 1927 ont ouvert une autre voie : larticle de Yule (on the method of
investigating periodicities in disturbated series with sepcial reference to Wolfers sunspot
numbers) et celui de Slutsky (the summation of random causes as the source of cyclical
processes).
Yule a introduit dans la littrature les modles autorgressifs, en considrant des mod-
les de la forme
Y
t
= Y
t1
+ Y
t2
.
Etant donnes deux valeurs initiales, cette suite prsente un comportement saisonnier,
fonction des paramtres et . Yule remarque quen fait, le comportement dpend des
racines (complexes) de lquation z
2
z = 0, et plus particulirement de leur
position par rapport au disque unit. Si leur module est infrieur 1, alors on observe un
comportement sinusodal amorti. En fait, la forme gnrale des solutions sera
Y
t
= A
t
cos (t ) , lorsque 0 < < 1.
Le modle autorgressif propos par Yule est le suivant
Y
t
=
1
Y
t1
+
2
Y
t2
+
t
, (1)
9
o (
t
) correspond un bruit blanc : un bruit blanc correspond un processus indpen-
dant (ou, plus faiblement, non corrl avec son pass). Nanmoins, des hypothses plus
fortes doivent parfois tre faites : on veut que ce bruit soit galement indpendant du
pass de la variable Y
t
, i.e.
t
indpendant de Y
th
pour tout h 1, et on parle alors
dinnovation du processus (Y
t
) .
Remarque 2. Le terme bruit blanc vient de la thorie du signal. Comme pour la lumire
blanche (qui est un mlange de toutes les couleurs), le bruit blanc est compos de toutes
les frquences, o la densit spectrale de puissance est la mme pour toutes les frquences.
Ce bruit ressemble un soue.
Slutsky a introduit les moyennes mobiles la mme anne que Yule a introduit les
processus autorgressifs... mais son article, crit en 1927 en russe na t traduit quen
1937 en anglais. Pour cela, il a utilis des nombres gnrs par la lotterie ocielle, et a
russit gnrer une srie dcrivant le cycle conomique en Angleterre, de 1855 1877.
La forme gnrale tait la suivante,
Y
t
=
0
t
+
1
t1
+ ... +
q
tq
, (2)
o (
t
) est un bruit blanc, correspondant ces nombres gnrs par la lotterie ocielle :
on obtient des variables indpendantes entre elles (cf tables de nombres alatoires), mais
surtout indpendantes du cycle conomique. Cette criture a suggr dlargir la relation
(1) sous une forme proche de (2), savoir
0
Y
t
+
1
Y
t1
+ ... +
p
Y
tp
=
t
.
Les processus introduits par Yule deviendront les processus AR(p) et ceux introduits par
Slutsky les processus MA(q). Lanalogie entre les deux processus sera mme pousse
plus loin lorsquil sera montr que les processus AR(p) et MA(q) sont respectivement
des processus MA() et AR(), sous certaines conditions.
1.1.3 Lapproche temporelle : concept de corrlation srielle
Si lapproche spectrale repose sur lutilisation du spectre (ou du priodogramme),
lapproche temporelle repose sur lautocorrlogramme, ou plus gnralement sur
lutilisation de la corrlation srielle. Poynting est le premier a introduire cette ide,
en 1884, en tudiant la relation entre le mouvement du prix du bl, et les importations
de coton et de soie. Le coecient de corrlation srielle a t dnit par Hooker en 1901,
dans une tude sur le taux de mariage en Angleterre, et lindice du commerce. Etant don-
nes deux sries temporelles, (X
t
) et (Y
t
), la covariance srielle est dnie par c
k
(X, Y ) =
cov (X
t
, Y
t+k
) et la corrlation srielle sera alors r
k
(X, Y ) = c
k
(X, Y ) /c
0
(X, Y ).
Le coecient dautocorrlation est alors obtenu en considrant
k
= corr (X
t
, X
t+k
) =
r
k
(X, X). Les annes 30 ont alors vu lclosion des rsultats de base dans le domaine
des sries chronologiques, sous limpulsion de Khintchine, Cramer, Wold, Kolmogorov,
Wiener...etc. Ces auteurs ont dvelopp une thorie des sries temporelles, en considrant
quune srie chronologique est une ralisation dun processus alatoire.
10
1.1.4 Lquivalence entre les deux approches temps/frquence
Dans un premier temps, lanalyse harmonique a t gnralise pour passer dune somme
de Fourier une intgrale de Fourier
Y
t
=
_
0
[cos (t) dA() + sin (t) dB()] .
Cette simple ide de lissage du priodogramme a permis de contourner les problmes
quavait pu observer Beveridge lorsquil cherchait des priodicits caches dans des disci-
plines autres que lastronomie.
La synthse entre ces deux branches (la premire travaillant en temps, avec des au-
tocorrlations, et la seconde travaillant sur le spectre de la srie) a t faite dans les
annes 30, en parallle aux Etats-Unis par Norbert Wiener (generalised harmonic anal-
ysis, 1930) et en Union Sovitique par Khintchine (korrelationstheorie der stationaren
stochastichen prozesse, 1934). Leur rsultat est de mettre en avant une relation bijective
entre la fonction dautocovariance dun processus stationnaire, et sa densit spectrale :
g () =
1
2
+
h=
(h) cos (h) ou (h) =
_
0
cos (h) g () d, o (h) = cov (X
t
, X
th
) .
Et si lanalogie entre autocorrlogramme et densit spectrale existe dun point de vue
thorique, il est possible de mettre en avant le mme genre de relation entre les autocor-
rlations empiriques et le priodogramme empirique.
1.2 Les dveloppements rcents
Ltude des sries temporelles semble avoir atteint sa maturit au cours des annes 70 o
des dveloppements signicatifs sont apparus. En 1965, Cooley et Tukey ont beaucoup
aid ltude spectrale des sries grce leur article an algorithm for the machine cal-
culation of complex Fourier series, introduisant la Fast Fourier Transform (FFT). Cet
algorithme a permis de calculer rapidement des priodogrammes. A la mme poque,
en 1970, Box et Jenkins ont publi leur ouvrage Time series analysis, forecasting and
control , montrant que ltude des sries temporelles laide de processus de type ARMA
(obtenus en associant les critures (1) et (2) des processus AR et MA) pouvait sappliquer
de nombreux domaines, et pouvait tre facilement implmente informatiquement
3
.
1.2.1 Les modles ARMA, ARIMA et SARIMA : modles linaires
Les modles ARMA sont un mlange des modles (1) et (2) proposs par Yule et Slutsky.
Un processus (X
t
) est un processus ARMA(p, q) sil existe un bruit blanc (
t
) (cest
3
Sur les mthodes de prvision en conomie, il peut tre intressant de se reporter The past, present
and future of macroeconomic forecasting de Francis Diebold (1997).
11
dire un processus stationnaire tel que
t
et
tk
soient indpendants, pour tout k, pour
tout t) tel que
X
t
=
1
X
t1
+ ... +
p
X
tp
+
t
+
1
t1
+ ... +
q
tq
, pour tout t.
Sous certaines conditions, ces processus sont stationnaires. Comme nous le verrons par
la suite, ces processus peuvent scrire sous la forme
(L) X
t
= (L)
t
, o (L) = I
1
L ...
p
L
p
et (L) = I +
1
L + ... +
q
L
q
,
L reprsentant loprateur retard, au sens o LX
t
= X
t1
, et avec la convention L
p
=
L L
p1
, soit L
p
X
t
= X
tp
: la srie (Y
t
) telle que Y
t
= L
p
X
t
est alors la srie (X
t
)
retarde de p priodes.
Paralllement, on dira quun processus non-stationnaire est intgr dordre 1, si en le
direnciant une fois, on obtient un processus stationnaire : (X
t
) (non-stationnaire) sera
dit intgr dordre 1 si le processus (Y
t
) dnit Y
t
= X
t
= X
t
X
t1
= (1 L) X
t
est stationnaire. On dira, par extension, que (X
t
) est intgr dordre d si (X
t
) est
non-stationnaire, ..., (Y
t
) o Y
t
= (1 L)
d1
X
t
, est non-stationnaire, et (Z
t
) o Z
t
=
(1 L)
d
X
t
, est stationnaire. On appelera alors processus ARIMA(p, d, q) un processus
(X
t
) pouvant se mettre sous la forme
(L) X
t
= (L) (1 L)
d
X
t
= (L)
t
, o (
t
) est un bruit blanc.
Pour les donnes relles, on notera que d = 1, 2 ou 3 (au maximum). Cela signie que
(Y
t
) dnit comme dirence dordre d du processus (X
t
), soit Y
t
= (1 L)
d
X
t
, suit un
processus ARMA(p, q)
4
.
On parlera dailleurs de prsence de racine unit : 1 est alors racine du polynme
autorgressif (z). Par gnralisation, on peut considrer le cas o exp (2i/s) est racine
du polynme autorgressif : cest dire que (L) = (1 L
s
) (L). On dira alors que
lon est prsence dune racine unit saisonnire, qui engendreront les modles SARIMA.
Les modles intgrs sont trs prsents dans les sries conomiques, par exemple
les sries dindices boursiers, dindice de production, dindice de prix.... Les modles
SARIMA sont galement trs prsents ds lors que les sries sont trs saisonnires (avec
une forte pridicit trimestrielle, annuelle...etc).
Remarque 3. Parmi les transformations usuelles des variables, la transformation par
(1 L) est parmi les plus utilises : on ne considre alors plus la srie brute (X
t
) mais la
variation (brute) Y
t
= X
t
X
t1
. Dans le cas o X
t
est un prix (par exemple un indice
boursier, CAC40 ou SP500), on considre galement souvent la variable obtenue comme
dirence des logarithmes des prix Z
t
= log X
t
log X
t1
, qui est alors le rendement ou
le taux de croissance (return ).
4
Ceci nest quune notation : comme nous le verrons par la suite, les processus ARIMA sont un peu
plus compliqus que les processus ARMA puisquil faut prendre en compte des conditions initiales : (Y
t
)
ne suit quasymptotiquement un processus ARMA(p, q).
12
1.2.2 Modles ARCH - volatilit stochastique
Dans les annes 80, des dveloppements ont t apports dans ltude de la non-linarit
de certaines sries, et sur leur modlisation. En 1982, Engle a introduit la classe des
modles ARCH (autorgressifs conditionnellement htroscdastiques
5
). Ces modles ont
t introduits pour palier une observation empirique qui ntait pas prise en compte par
les modles : la volatilit conditionelle dune srie (Y
t
) na aucune raison dtre constante.
Dans les modles AR(1), la variance conditionnelle de X
t
sachant X
t1
est constante :
V (X
t
[X
t1
) =
2
o V (
t
) =
2
(notion dhomoscdasticit). Engle a cherch un modle
dans lequel la variance conditionnelle de X
t
sachant X
t1
dpendrait de X
t1
, et plus
particulirement, V (X
t
[X
t1
) =
_
+ X
2
t1
2
. Pour cela, il a considr les modles de
la forme
X
t
=
t
_
h
t
, o h
t
=
0
+
1
X
2
t1
.
Cette classe de modle, appele ARCH (1) a t gnralise sous la forme ARCH (p),
X
t
=
t
_
h
t
, o h
t
=
0
+
1
X
2
t1
+ ... +
p
X
2
tp
.
Cette forme pour h
t
a permis lanalogie entre les modles AR et les modles ARCH. De
plus, cette classe de modles ARCH a t gnralise de la mme faon que les ARMA
gnralisent les AR, en considrant des fonctions h
t
de la forme
h
t
=
0
+
p
i=1
i
X
2
ti
+
q
j=1
tj
,
gnrant ainsi les modles GARCH.
1.2.3 Les processus mmoire longue
Dautres avances ont t faites sur la mmoire longue de certaines sries. Les pro-
cessus stationnaires de type AR ont un autocorrlogramme qui converge vers 0 de faon
exponentielle ( (h) =
h
). Les processus mmoire longue seront caractriss par une
dcroissance de leur autocorrlogramme suivant une fonction puissance ( (h) = h
).
Plusieurs classes de processus appartiennent cette srie,
(i) les processus self-similaires, introduits par Kolmogorov en 1958 et dvelopps par
Mandelbrot (1965) : ces processus sont caractriss par lexistence dune constante H
(dite de self-similarit) telle que, pour tout constante c, la distribution de Y
ct
soit gale
celle de c
H
Y
t
. On retrouve dans cette classe les processus de Levy.
(ii) les processus FARMA, gnralisation des modles ARIMA dcrits par Box et
Jenkins. Ces modles ARIMA taient obtenus en considrant que les dirences premires
5
Pour rappel, un modle conomtrique est dit homoscdatique si la variance des erreurs (cen-
tres) E
_
2
t
_
est constante - quelque soit la priode dtude. Dans le cas contraire, on parlera
dhtroscdasticit. Les modles sont ici conditionnellement htroscdatistique car E
_
2
t
[
t1
_
dpend
de t.
13
d
X
t
(o X
t
= X
t
X
t1
,
2
X
t
= (X
t
)...etc) suivent un processus ARMA(p, q).
On parle alors de processus ARMA intgr. Les processus FARIMA ont t obtenus
en considrant, formellement, les cas o d nest pas entier, compris entre 1/2 et 1/2.
Cette gnralisation, propose par Granger en 1980, repose sur la manipulation des sries
doprateurs retard (L), et sur le dveloppement en srie entire de (1 L)
d
.
(iii) laggrgation de processus AR(1) a galement t propose par Granger en 1980
et cette classe de processus a t tudie par Gourieroux et Gonalves en 1988. On
considre des processus vriant, pour tout t 0,
X
i,t
=
i
X
i,t1
+ C
i
t
+
i,t
pour i = 1, 2, ...
1.2.4 Les processus multivaris
Enn, dautres dveloppements ont t fait dans ltude des processus multivaris. Si lon
se place uniquement en dimension 2, on comprend que la gnralisation des processus
univaris une dimension suprieur est relativement complique.
(i) les modles V AR - vecteurs autorgressifs - sont une gnralisation des modles
AR en dimension n. Si lon considre par exemple un couple Z
t
de deux variables (X
t
, Y
t
)
que lon souhaite expliquer par leur pass, on obtient un modle de la forme
_
X
t
Y
t
_
=
_
1
1
1
1
_ _
X
t1
Y
t1
_
+
_
t
t
_
, soit Z
t
= A
1
Z
t1
+ U
t
,
o la matrice A
t
est compose des coecients autoregressifs usuels (
1
et
1
) mais aussi
des notions relatives la notion de causalit, X
t
dpendant de Y
t1
, et Y
t
dpendant de
X
t1
.
(ii) la cointgration est une notion relative au comportement des plusieurs variables
intgres, et la relation qui les unit long terme : on considre (X
t
) et (Y
t
) non-
stationnaires, et intgres dordre d, satisfaisant une relation du type
X
t
= + Y
t
+
t
.
Plus formellement, si le vecteur (Z
t
) est intgr dordre d, on dira que les sries
Z
1
t
, Z
2
t
, ..., Z
n
t
sont cointgres si et seulement sil existe une relation linaire non-nulle
des composantes qui soient intgres dordre strictement infrieur d
(iii) le modle ltre de Kalman. Ce modle est un cas particulier dune classe plus
large de modles, les modles espace dtats, de la forme
_
Z
t+1
= A
t
Z
t
+
t
Y
t
= C
t
Z
t
+
t
,
o (Y
t
) est le vecteur que lon tudie, (Z
t
) est un vecteur alatoire (=tat) inconnu, A
t
et C
t
sont des matrices dterministes, et (
t
,
t
) est un bruit blanc normal. Lide est
destimer rcursivement Z
t
en fonction de Y
0
, ..., Y
t
.
14
1.2.5 Exemple : histoire de la prvision des modles conomiques (macro-
conomiques)
La thorie conomique inspire de Keynes reposait sur lutilisation de prvisions condi-
tionnelles : sous certaines hypothses, les prvisions dune ou plusieurs variables taient
faites conditionellement des comportements, au sein de modles structurels. Plus partic-
ulirement, ds 1936, Keynes proposait par exemple de lier la consommation C
t
au revenu
disponible R
t
, sous la forme C
t
= R
t
+ : une prvision de R
t
permettait de prvoir
C
t
. Brown avait propos un modle lgrement dirent ds 1952, en intgrant le fait
que les individus ont des habitudes de consommation, entrainant une inertie importante :
C
t
= R
t
+ +C
t1
. Ces prvisions structurelles ont toutefois cess de faire rfrence
partir des annes 70.
Les prvisions non-structurelles ont alors pu prendre en compte les dirents cycles
observs en conomie (1977 : Business cycle modeling without pretending to have too
much a priori theory de Sargent et Sims) : des prvisions de sries conomiques peuvent
se faire sans ncessairement avoir de modle structurel derrire. Les modles utiliss sont
toutefois relativement anciens puisquils sont inspirs des modles de Slutsky et Yule,
tous deux datant de 1927, bass sur la notion de modle autorgressif. La publication de
louvrage de Box et Jenkins en 1970 permettra une avance rapide avec lutilisation des
modles ARMA.
Toutefois, le lacune de la thorie de Box et Jenkins est quelle ne prend pas en compte
des eets croiss de dpendance entre variables. Pour eectuer de la prvision dun en-
semble de variables, a priori lies, il convient deectuer une prvision globale : la thorie
des modles V AR (modles autorgressifs vectoriels) a t introduite en conomie sous
limpulsion de Sims en 1980, qui a travaill sur des systmes dquations o toutes les vari-
ables sont alors endognes (contrairement aux quations structurelles de Keynes). Cette
thorie avait toutefois t tudie ds les annes 70 par Granger par exemple, qui avait
travaill sur la notion simple de causalit entre variables.
Toutefois, la prsence dun certain nombre de variables non-stationnaires a pos un
certain nombre de problmes : Granger a alors introduit la notion de cointgration en 1981
: cette notion dit que deux variables X et Y peuvent suivre une tendance stochastique,
mais la dirence (ou le spread) XY peut tre stationnaire. Cette notion sera lorigine
des modles tendance commune, permettant de travailler sur des systmes dquations
o certaines variables sont cointgres. En particulier, ds 1978, Hall se posait la question
de savoir si la consommation par habitant ntait pas une martingale, ce qui conduirait
crire C
t
= C
t1
+
t
o
t
est un ala. Nelson et Plosser ont dailleurs not, en 1982
quun grand nombre de sries macroconomiques taient caractrises par la prsence
dune racine unitaire (cest dire une criture de la forme C
t
= C
t1
+ X
t
). Et cest
nallement en 1987 que Campbell a propos un modle V AR sur la consommation C et
le revenu R, puis un modle V AR intgrant dans chaque quation un modle correction
derreur.
Une autre piste qui a t explore la mme poque est celle des modles non-linaires.
Cette voie a t ouverte ds 1982 par Engle, qui introduisi de la dynamique dans la
15
volatilit, laide des modles ARCH. Ces modles ont t trs utiliss en nance, mais
aussi pour des modles dination.
Parmi des amliorations apportes dans les annes 90, on peut noter les modles avec
cycles, avec rupture de tendance, changement de rgime...etc. La thorie des modles
changement de rgime repose sur lide que derrire les variables observes existent des
variables caches, non observes.
Pour rsumer lhistoire des applications conomiques des sries temporelles, on peut
retenir le schma suivant
- annes 20 : macroconomie descriptive : description des cycles (courts = Slutsky,
longs = Kondratie )
- annes 50 : dbut de la thorie des sries temporelles, avec comme objectif principal,
la prvision
- annes 60 : application en macroconomie, avec des modles structurels : une
vingtaine de variables, et 200 observations (maximum)
- annes 70 : thorie de Box et Jenkins, sappuyant sur un logiciel (modle linaire)
: on considre les variables une une, sur 200 observations (dbut, la mme poque, de
la thorie des panels en microconomie : 3000 individus suivis sur 3 ou 4 priodes)
- annes 80 : en marcronomie, modles multivaris (causalit, cointgration,
codpendance). Dbut de lutilisation des modles de sries temporelles sur donnes nan-
cires : beaucoup de variables, 2000 observations. Dbut des modles temps continu.
- annes 90 : donnes hautes frquences sur les marchs nanciers (de 4000 plus
de 2000000 observations).
Des complments peuvent se trouver dans larticle de Chris Chateld (1997) intitul
Forecasting in the 1990s.
Remarque 4. Les modles que nous allons tudier dans ce cours sont bass sont bass sur
ltude de processus (X
t
) o les variables observes sur supposes valeurs relles
: X
1
, X
2
, ..., X
t
, .... R. On observera ainsi des prix, des variations de prix, des taux, des
montants...etc. Des nombres de voyageurs seront, a la rigueur, considrs comme une
variable relle, mais deux cas seront exclus de notre tude, a priori :
les processus de comptage (ex : nombre daccident pour un conducteur lanne t)
les processus valeurs dans un espace dtat ni
1.2.6 Remarque sur les donnes hautes frquences
Remarque 5. Les modles que nous allons tudier dans ce cours sont bass sont bass
sur ltude de processus (X
t
), observs des dates rgulires : X
1
, X
2
, ..., X
t
, .... Il peut
sagir, par exemple, de la version discrre dun processus en temps continu : on observe
X
t
1
, X
t
2
, ..., X
tn
, ... o les dates t
i
sont telles que t
i
t
i1
soit constante pour tout i.
Dans le cas des donnes hautes frquences, lanalyse est relativement dirente,
puisque laspect temporel doit tre pris en compte. Par exemple, pour tudier la liq-
uidit des marchs nanciers, on considre les triplets de variables suivants : (T
i
, V
i
, P
i
),
16
o T
i
est la date de la ime transaction, V
i
le volume chang lors de la transaction, et P
i
le prix de cette transaction. Cette tude permet de changer lchelle des temps : on ne
considre plus le temps calendaire mais le temps des transactions.
La notion de base pour tudier ce genre de donnes est la thorie des modles de
dures. On considre (T
i
), la suite des dates de transaction, et
i
la date coule entre la
ime et la i 1me transaction :
i
= T
i
T
i1
.
Toutefois, dans ce cours, nous ne traiterons pas de ces aspects, mais nous considrerons
plutt des agrgations, ou des observations ponctuelles : P
t
sera le prix observ la date
t (par exemple tous les jours, ou toutes les heures) et V
t
le volume total chang pendant
la priode (en une journe, ou une heure). Toutefois, il est noter que mme dans ce cas,
o les volumes de donnes sont trs importants, ltude peut savrer plus complexe que
dans le cas o lon considre des sries conomiques observes 200 dates, en particulier
cause de la prsence de multiples cycles (un cycle dune journe sera observe sur des
donnes horaires par exemple, puis des cycles mensuels, ou trimestriels (publication de
comptes), ou encore annuels...).
1.3 Thorie des processus temps discret
Deux types de processus sont utiliss dans la thorie des sries stationnaires
(i) les processus stationnaires
(ii) les processus markoviens
1.3.1 Stationnarit des processus
La stationnarit joue un rle central dans la thorie des processus, car elle remplace
(de faon naturelle) lhypothse dobservation i.i.d. en statistique. Deux notions sont
gnralement considres. La premire notion de stationnarit peut se dnir de faon
forte par une stabilit en loi du processus : quels que soient n, t
1
, ..., t
n
et h, on a lgalit
entre les lois jointes
L(Y
t
1
, ..., Y
tn
) = L(Y
t
1
+h
, ..., Y
tn+h
)
Cette dnition toutefois peut tre aaiblie : le processus est dit stationnaire au second
ordre si
- la moyenne du processus est constante : E(Y
t
) = m pour tout t Z
- les autocovariances ne dpendent que de la dirence entre les observations :
cov (X
t
, X
s
) = ([t s[)
Cette dernire proprit implique en particulier que la variance de Y
t
est constante :
V (Y
t
) =
2
.
Remarque 6. Si lon considre les lois marginales ( t x) du processus, la stationnarit
(forte) signie une stabilit de la loi marginale : la loi de Y
t
et la loi de Y
s
sont identiques
pour t ,= s. La stationnarit du second ordre correspond uniquement une stabilit des
deux premiers moments : E(Y
t
) = E(Y
s
) et V (Y
t
) = V (Y
s
) pour t ,= s. Dans ce cas,
rien nempche davoir des skewness et des kurtosis variables en fonction du temps.
17
Remarque 7. Si lon considre la dpendance temporelle, la stationnarit du second ordre
suppose uniquement une stabilit de la corrlation (moment dordre 2) : cov (X
t
, X
t+h
) =
cov (X
s
, X
s+h
). La stationnarit au sens fort est beaucoup plus forte que cette condition
sur le moment dordre 2, puisquelle suppose une stabilit de toutes les lois jointes
6
: en
particulier, cette condition implique lgalit en loi des couples (X
t
, X
t+h
) et (X
s
, X
s+h
).
La notion de stationnarit au second ordre, qui sera utilise dans la premire partie
de ce cours, suppose uniquement une stabilit des deux premiers moments :
- la stationnarit au second ordre nempche pas une variation des moments dordres
plus levs (asymtrie de la loi ou paisseur des queue fonctions du temps),
- la stabilit de la structure de dpendence entre X
t
et X
t+h
se rsume une stabilit
du coecient de corrlation (ou de covariance).
Lexemple le plus simple de processus stationnaire est le bruit blanc. Toutefois, de la
mme faon quil est possible de dnir deux notions de stationnarit, il existe deux sorte
de bruit blanc. Le processus (
t
) est un bruit blanc faible sil existe
2
telle que
_
_
_
E(
t
) = 0 pour tout t
V (
t
) = E(
2
t
) =
2
pour tout t
cov (
t
,
th
) = E(
t
th
) = 0 pour tout t, et pour tout h ,= 0.
Aucune hypothse dindpendance nest faite dans cette dnition. Les variables aux dif-
frentes dates sont uniquement non corrles (ce qui fera une dirence importante, comme
nous le verrons dans la partie sur les modles ARCH). Cette hypothse dindpendance
permet toutefois de dnir un bruit blanc fort, i.e.
_
_
_
E(
t
) = 0 et V (
t
) = E(
2
t
) =
2
(nie) pour tout t
L(
t
) = L(
th
) pour tout t, h
t
et
th
sont indpendantes pour tout t, et pour tout h ,= 0.
On peut simuler un bruit blanc gaussien en utilisant
> epsilon=rnrom(100)
1.3.2 Proprit de Markov en temps discret
La thorie sur les chanes de Markov (en temps discret) est galement un lment impor-
tant.
6
Rappel : soient X
1
et X
2
de mme loi, Y
1
et Y
2
de mme loi, tels que cov (X
1
, Y
1
) = cov (X
2
, Y
2
),
alors on na pas galit des lois jointes : L(X
1
, Y
1
) ,= L(X
2
, Y
2
). En particulier, si X et Y suivent des
lois normales A
_
X
,
2
X
_
et A
_
Y
,
2
Y
_
avec corr (X, Y ) = , alors on na pas ncessairement
_
X
Y
_
A
__
X
Y
_
,
_
2
X
X
Y
2
Y
__
Un vecteur gaussien nest pas uniquement un vecteur dont les lois marginales sont uniformes (cf cours
de probabilit).
18
Cette proprit correspond lide que lon souhaite rsumer linformation contenue
dans les variables passes du processus par un nombre ni de variables (les variables
dtat). Dans le cas le plus simple, on souhaite que les variables dtat soient des valeurs
retardes du processus : toute linformation est contenue dans les k valeurs les plus
rcentes
L(X
t
[X
t1
, X
t2
, X
t3
, ...) = L(X
t
[X
t1
, ..., X
tk
) ,
qui peut se rcrire, lordre 1,
(X
t
[X
t1
, X
t2
, X
t3
, ...)
d
= (X
t
[X
t1
) .
Il est possible de montrer que cette relation est quivalente
X
t
= g (X
t1
,
t
) , o (
t
) est un bruit blanc.
Toutefois, cette thorie, visant chercher une fonction f telle que X
t
= f (X
t1
,
t
)
peut tre dicile implmenter. En conomtrie, on cherche une relation du type
Y = g (X
1
, ..., X
n
, ), permant dexpliquer une variable Y laide de variables exognes
X
1
, .., X
n
. Cette fonction g tant a priori dicile exhiber, la mthode la plus simple est
de considrer le cas linaire. De la mme faon, la thorie des modles ARIMA vise
expliquer X
t
en fonction de son pass (et ventuellement dun bruit), de manire linaire.
Remarque 8. Nous ne nous intresserons, dans ce cours, que dans le cas o lespace
dtat E est R, cest dire que nous ne traiterons pas le cas des chanes de Markov (o
X
t
prend ces valeurs dans un espace dtat ni ou dnombrable)
t discret t continu
E = i
1
, ..., i
n
, ... Chanes de Markov Processus de Poisson
E = R Sries Temporelles Calcul Stochastique (Brownien)
Les chanes de Markov correspondent par exemple au cas o X
t
est valeurs dans un en-
semble ni (i
1
, ..., i
n
, ...) o dnombrable (N) : par exemple les variables dichotomiques,
o X
t
vaut soit 0, soit 1.. Le calcul stochastique correspond au mouvement brownien, et
aux processus de diusion obtenus partir du mouvement brownien. Le cas o le temps est
continu et o les variables sont valeurs dans N (par exemple) correspond aux processus
de comptage, aux processus de Poisson, la thorie des les dattente...etc.
1.4 Objectifs de ltudes des sries temporelles
1.4.1 Description et modlisation
Le but est ici de dterminer les direntes composantes dune srie (X
t
), en particulier,
obtenir la srie corrige des variations saisonnires (mthodes de dsaisonnalisation). Pour
les sries stationnaires, on peut aussi chercher modliser la srie laide dun modle
ARMA, par exemple dans le but de faire de la prvision.
19
1.4.2 Prvision
Sur la base dobservation X
1
, ..., X
T
le but est de faire une prvision, la date T, de la
ralisation en T +h, note
X
T
(h). Une premire mthode est le lissage exponentiel, bas
sur une formule de rcurrence de la forme
X
T
(1) = X
t
+(1 )
X
T1
(h), o , compris
entre 0 et 1, est gnralement choisi de faon minimiser la somme des carrs des erreurs
de prvision.
Dans le cas des modles ARMA, de nombreuses relations existent an de faire de
la prvision, avec un intervalle de conance. Nous verrons comment ces intervalles de
conance sont modis si une modlisation ARCH est retenue, ou du type mmoire
longue.
1.4.3 Filtrage
Le lissage consiste transformer une srie de faon dtecter (pour liminer ou au
contraire conserver) certaines caractrisques (composante saisonnire, points abrants...).
Cette mthode permet galement de dtecter des ruptures au sein dune srie.
1.5 Conseils bibliographiques (en franais, et en anglais)
Les principaux ouvrages servant de rfrence ce cours sont les suivants,
DROESBEKE,J.J., FICHET,B. & TASSI,P. (1995). Sries chronologiques - thorie
et pratique des modles ARIMA, Economica
GOURIEROUX,C. & MONFORT,A. (1995) Sries temporelles et modles dy-
namiques, Economica
Des complments dinformations sur dirents points abords peuvent tre trouvs
galement dans
BOURBONNAIS,R. & TERRAZA,M. (1998). Analyse des sries temporelles en
conomie, PUF
BOX,G. & JENKINS,G.. (1970). Time Series analysis : forecasting and control ,
Holden-Day
BROCKWELL, P.J. (1987) Time series : theory and methods Springer-Verlag
COUTROT, B & DROESBEKE,J.J. (1995) Les Mthodes de prvision Presses
Universitaires de France (Que sais-je ? 2157)
DACUNHA-CASTELLE,D. & DUFLO,M. (1985). Probabilits et Statistiques -
Tome 2 : Problmes temps mobile Masson
HAMILTON,J. (1994). Time series analysis, Princeton University Press
20
HARVEY,A.C. (1993) Time Series Models Cambridge: MIT Press
HYLLEBERG S. (1992), Modeling Seasonality Oxford University Press
LUTKEPOHL,H. (1991). Introduction to multiple time series analysis Springer-
Verlag
MELARD, G. (1990) Mthodes de prvision court terme. Ellipses
NERLOVE M, GRETHER D.M, CARVALHO J.L. (1995). Analysis of Economic
Time Series Academic Press.
PINDYCK,R.S & RUBINFELD,L.D. (1984) Econometric models and economic
forecasts McGraw-Hill
21
2 Proprits des processus univaris en temps discret
La pratique de lanalyse des sries temporelles vise modliser une srie dobservations
x
1
, ..., x
n
par un processus alatoire temps discret, cest dire une suite (X
n
) de variables
alatoires dnies sur un espace de probabilit (, /, P), tel que lon puisse penser que
la srie observe soit une ralisation du processus. En dautres termes, x
1
, ..., x
n
doit tre
obtenu comme tirage alatoire de X
1
, ..., X
n
suivant la probabilit P, cest dire que se
ralise un vnement tel que x
i
= X
i
() pour i = 1, ..., n. Le but est alors, tant donne
une trajectoire x
1
, ..., x
n
de reconstruire la dynamique du modle sous-jacent, cest dire
de comprendre la liaison entre X
i
et son pass X
i1
, X
i2
, ..., X
1
.
2.1 Rappels sur les martingales temps discret
Un processus ( temps discret) sur un espace (, /, P) est une suite de variables alatoires
(X
t
, t N), valeurs dans un espace mesur (E, c) (dans le cas qui nous intresse, E =
R). On peut considrer le processus comme la variable alatoire X (t, ), dni sur lespace
produit N muni de la tribu produit.
Dnition 9. Une ltration T
t
, t N est la donne dune suite croissante (au sens de
linclusion) de sous-tribus de /. On posera T
= sup T
t
, t N : il sagit de la plus
petit tribu qui contienne toutes les T
t
.
La ltration la plus usuelle est obtenue de la faon suivante : on observe une suite (X
t
)
de variables alatoires, et on considre T
t
= (X
0
, ..., X
t
), qui est la plus petite tribu qui
rende mesurable les variables (X
0
, ..., X
n
). On appellera ltration naturelle cette ltration,
et on la notera
_
T
X
t
_
.
On dira que (X
t
) est adapte la ltration (T
t
) si pour tout t, X
t
est T
t
-mesurable.
La ltration naturelle est la plus petite ltration par rapport laquelle le processus soit
adapt. On dira que le processus (X
t
) est prvisible si pour tout t 1, X
t
est T
X
t1
-
mesurable.
Dnition 10. Le processus X
t
, t N muni de la ltration T
t
, t N tel que pour
tout t, X
t
soit intgrable. On dira que (X
t
) est une martingale si et seulement si, pour
tout t, E(X
t+1
[T
t
) = X
t
presque srement.
Remarque 11. Si pour tout t, E(X
t+1
[T
t
) X
t
presque srement, on dira que (X
t
) est
une sous-martingale, et si pour tout t, E(X
t+1
[T
t
) X
t
presque srement, on dira que
(X
t
) est une sur-martingale.
Si (X
t
) est une (T
t
)-martingale, alors pour tout h 0, E(X
t+h
[T
t
) = X
t
. De
plus, si la martingale est de carr intgrable, les accroissements sont orthogonaux : si
X
t
= X
t
X
t1
, pour s ,= t, E(X
t
X
s
) = 0. Une des consquences est que, pour tout
h 0
E
_
[X
t+h
X
t
]
2
_
=
h
i=1
E
_
X
2
t+i
_
.
22
2.2 Rappels sur les Chanes de Markov
Dnition 12. Le processus X
t
, t N est une chane de Markov dordre 1 si et seule-
ment si, pour tout t,
L(X
t
[X
t1
, X
t2
, X
t3
, ...) = L(X
t
[X
t1
) .
Autrement dit, compte tenu de la trajectoire (X
T1
= x
T1
, X
T2
= x
T2
, ...) dun
processus (X
t
), la loi de X
T
linstant T est entirement dtermine par le fait que la
valeur en T 1 soit x
T1
.
Thorme 13. Le processus X
t
, t N est une chane de Markov dordre 1 si et seule-
ment sil existe une fonction g (.) mesurable et un processus
t
tel que X
t
= g (X
t1
,
t
) -
avec (
t
) une suite de variables alatoires, indpendantes et de mme loi.
Lorsque lapplication g ne dpend par de t, la chane de Markov est dite homogne.
Exemple 14. Les processus AR(1) : X
t
= + X
t1
+
t
, o (
t
) est un bruit blanc
independant du pass du processus, sont markoviens.
Exemple 15. En particulier, les processus de la forme X
t
= X
t1
+
t
correspond une
marche alatoire :
- si X
0
Z et P(
t
= 1) = P(
t
= +1) = 1/2, on obtient la marche alatoire
symtrique sur Z (jeu du pile ou face),
- si
t
suit une loi normale centre, on obtient une discrtisation du mouvement brown-
ien, ou un processus ARIMA(0,1,0) comme nous lappelerons ici.
On notera que si lon a parl de chane dordre 1, cest quil doit tre possible
dintroduire une chane dordre suprieur,
Dnition 16. Le processus X
t
, t N est une chane de Markov dordre p si et seule-
ment si, pour tout t,
L(X
t
[X
t1
, X
t2
, X
t3
, ...) = L(X
t
[X
t1
, ..., X
tp
) .
2.3 Notions de stationnairit
Dnition 17. Un processus (X
t
) est stationnaire au second ordre si
(i) pour tout t, E(X
2
t
) < +,
(ii) pour tout t, E(X
t
) = , constante indpendante de t,
(iii) pour tout t et pour tout h, cov (X
t
, X
t+h
) = E([X
t
] [X
t+h
]) = (h),
indpendante de t.
Dnition 18. La fonction (.) sera appele fonction dautocovariance
On peut montrer aisment que (.) est une fonction paire, au sens o (h) = (h)
pour tout h
23
Remarque 19. Une des consquences est que variance V (X
t
) est constante, indpendante
de t, V (X
t
) = (0) .
Proposition 20. Si (X
t
, t Z) est un processus stationnaire, et si (a
i
, i Z) est une
suite de rels absolument convergente, i.e.
iZ
[a
i
[ < +, alors, le processus (Y
t
) dni
par
Y
t
=
iZ
a
i
X
ti
, pour tout t Z,
est un processus stationnaire.
Corollaire 21. En particulier, si (a
i
, i Z) est une suite de rels nie, la suite Y
t
est
stationnaire. Par exemple, si a
0
= a
1
= 1/2, et a
i
= 0 pour i / 0, 1 :
Y
t
=
1
2
(X
t
+ X
t1
) ,
est stationnaire ds lors que (X
t
) est stationnaire. De mme pour Y
t
= X
t
X
t1
.
Dnition 22. Un processus (X
t
) est stationnaire au sens fort si pour tous t
1
, ..., t
n
et h
on a lgalit en loi
(X
t
1
, ..., X
tn
)
L
= (X
t
1
+h
, ..., X
tn+h
) .
Remarque 23. Cette notion revient dire que la loi temporelle est invariante en temps.
Cette stationnarit est beaucoup plus forte que la stationnarit du second ordre, puisquon
ne recherche pas la stabilit de la loi, mais seulement la stabilit des deux premiers mo-
ments.
Dnition 24. On appelle bruit blanc (parfois appel bruit blanc faible) un processus (
t
)
stationnaire dont les autocovariance sont toutes nulles : (h) = 0 pour h ,= 0.
Remarque 25. Nous avons vu dans la partie prcdante que (X
t
) est une martingale
si et seulement si, pour tout t, E(X
t+1
[X
t
, X
t1
, ....) = X
t
pour tout t, ou, de faon
quivalente, cela signie que X
t+1
= X
t
+
t
avec E(
t+1
[
t
,
t1
, ....) = 0 pour tout t.
Cette notion est plus contraignante que celle de marche alatoire : en eet, la proprit
de martingale implique lindpendance des accroissements (
t
) alors que la dnition de
la marche alatoire nimplique que la nullit des corrlations des accroissements.
Dnition 26. Un processus stationnaire (X
t
) sera dit ergodique si pour tout p N
, et
pour tout fonction borlienne de R
p
valeurs dans R, on a
1
N
N
i=1
f (X
i+1
, X
i+2
, ..., X
i+p
) E(f (X
1
, X
2
..., X
p
)) , quand N ,
qui peut tre vu simplement comme une gnralisation de la loi de grand nombre.
24
La notion de stationnarit (faible, ou au second ordre) se dnie par une invariance
des moments dordre 1 et 2 au cours du temps. Par opposition, on dira quune srie est
non-stationnaire si elle nest pas stationnaire. On peut noter que la classe des processus
non-stationnaire est alors relativement vaste, et surtout htrogne : il existe direntes
sources de non-stationnarit, et chaque origine de non-stationnarit est associe une
mthode propre de stationnarisation. Nelson et Plosser ont retenu, en 1982, deux classes
de processus non-stationnaires : les processus TS (trend stationary) et les processus DS
(dierence stationary) Les premiers correspondent une non-stationnarit de type dter-
ministe, alors que les seconds correspondent une non-stationnarit de type stochastique.
Dnition 27. (X
t
) est un processus non-stationnaire TS sil peut scrire sous la forme
X
t
= f (t) +Z
t
o f (t) est une fonction (dterministe) du temps, et (Z
t
) est un processus
stationnaire.
Lexemple le plus simple est celui de la tendance linaire bruite : X
t
= + t +
t
.
Ce processus est en eet non-stationnaire puisque son esprance vaut + t la date t,
et donc, dpend de t. Une des proprits importantes de ce type de processus est quil
ny a pas persistance des chocs : linuence dun choc subit un instant aura tendance
sestomper au cours du temps, et la variable rejoint alors sa dynamique de long-terme,
dtermine par f (t).
Dnition 28. (X
t
) est un processus non-stationnaire DS - ou intgr dordre d, not
I (d) - si le processus obtenu aprs d direnciation est stationnaire : Z
t
=
d
X
t
=
(1 L)
d
X
t
est stationnaire
Comme nous le verrons par la suite, le fait quil faille direncier d fois, cest dire
multplier par (1 L)
d
, polynme de loprateur retard L, revient chercher la prsence de
racines unit : si le processus (L) X
t
est stationnaire, si 1 est une racine du polynme
, alors (X
t
) sera non-stationnaire. Cest pour cela que la plupart des tests de non-
stationnarit sont des tests de dtection de racine unit.
Pour obtenir les racines dun polynme, on peut utiliser la commande suivante, par
exemple pour (L) = (1 + 0.7L 0.5L
2
) ou (L) = (1 + 0.7L 0.2L
2
),
> library(polynom)
> Mod(polyroot(c(1,.7,-.5)))
[1] 0.8779734 2.2779734
> Mod(polyroot(c(1,.7,-.2)))
[1] 1.089454 4.589454
Il est aussi possible de visualiser les racines units dans C, par exemple pour (L) =
(1 + 0.5L 0.4L
2
0.3L
4
) ou (L) = (1 + 0.5L 0.4L
2
+ 0.3L
4
),
> PM=c(1,.5,-.4,0,-.3)
> plot(Re(polyroot(PM)),Im(polyroot(PM)),pch=19,col="blue",xlim=c(-2,2),ylim=c(-2,2))
> u=seq(-1,1,by=.01)
> lines(u,sqrt(1-u^2),col="red")
> lines(u,-sqrt(1-u^2),col="red")
25
> abline(h=0,col="grey")
> abline(v=0,col="grey")
> PM=c(1,.5,-.4,0,.3)
> plot(Re(polyroot(PM)),Im(polyroot(PM)),pch=19,col="purple",xlim=c(-2,2),ylim=c(-2,2))
2.4 Fonction dautocovariance et densit spectrale
2.4.1 Autocovariance et autocorrlation
Dnition 29. Pour une srie stationnaire (X
t
) , on dnit la fonction dautocovariance,
pour tout t, par
h
X
(h) = cov (X
t
, X
th
) = E(X
t
X
th
) E(X
t
) .E(X
th
) .
Dnition 30. Pour une srie stationnaire (X
t
) , on dnit la fonction dautocorrlation,
pour tout t, par
h
X
(h) = corr (X
t
, X
th
) =
cov (X
t
, X
th
)
_
V (X
t
)
_
V (X
th
)
=
X
(h)
X
(0)
.
Cette fonction
X
(.) est valeurs dans [1, +1], et
X
(0) = 1.
Dnition 31. Un processus (
t
) sera appel bruit blanc (faible) sil est stationnaire,
centr et non-autocorrl :
E(
t
) = 0, V (
t
) =
2
et
(h) = 0 pour h ,= 0.
On parlera de bruit blanc fort sil est indpendant et identiquement distribu (i.i.d.)
: la notion dindpendance est plus forte que la nullit des autocorrlations, et le fait que
le processus soit identiquement distribu est plus fort que la stabilit des deux premiers
moments.
Exemple 32. Processus MA(1) : X
t
=
t
+
t1
o (
t
) est un bruit blanc centr de
variance
2
,
_
_
_
(0) = [1 +
2
]
2
(1) =
2
(h) = 0 si [h[ 2
, soit (1) =
1 +
2
et (h) = 0 pour [h[ 2.
26
2.4.2 Densit spectrale
Lide ici est que les coecients dautocovariance dune srie stationnaire correspondent
aux coecients de Fourier dune mesure positive, appele mesure spectrale du processus.
Il est possible de montrer que cette mesure spectrale admet une densit, dite spectrale,
par rapport la mesure de Lebesgue sur [, ], que nous noterons f
X
. Dans le cas
o la srie des autocovariance est absolument convergente, la densit spectrale est alors
dnie comme la transforme de Fourier des coecients dautocovariance (dans le cas o
la somme des [
X
(h)[ tend vers linni, la somme est prendre au sens de L
2
) : comme
lont montr Cramr, Kolmogorov, ou encore Wiener, on les rsultats suivants,
(i) la suite des fonctions dautocovariance
X
(h) dun processus stationnaire peut tre
crit sous la forme
X
(h) =
_
+
exp (ih) dF
X
() ,
o F
X
() /
X
(0) est une fonction de rpartition,
(ii) tout processus stationnaire peut se mettre sous la forme X
t
=
_
+
exp (it) dz ()
o z () est une fonction alatoire, complexe, accroissements non corrls. Cette
reprsentation est appele reprsentation de Cramr.
Dnition 33. Soit (X
t
) un processus stationnaire de fonction dautocovariance
X
(.),
la densit spectrale de (X
t
) scrit
f
X
() =
1
2
hZ
X
(h) exp (ih) .
Proposition 34. Rciproquement, si f
X
(.) est la densit spectrale de (X
t
) alors
X
(h) =
_
+
f
X
() exp (ih) d.
Exemple 35. Un bruit blanc (
t
) est caractris par
_
(0) = V (
t
) =
2
(h) = 0, pour h ,= 0,
Alors sa densit spectrale est donne par
f
() =
2
2
(= constante).
Proposition 36. Si la densit spectrale dune srie (Z
t
) est constante, alors (Z
t
) est un
bruit blanc.
Proof. En eet
Z
(h) =
_
+
f
Z
() exp (ih) d = K
_
+
exp (ih) d
. .
=0 sauf si h=0
27
Cette nullit de la fonction dautocorrlation est donc une charactristique du bruit
blanc.
Proposition 37. Si X
t
est une moyenne mobile,
X
t
=
kZ
a
k
tk
, o (
t
) est un bruit blanc BB
_
0,
2
_
,
avec
[a
j
[ < +. Si on considre Y
t
=
jZ
j
X
tj
alors, on a la relation suivante
f
Y
() = f
X
() .
jZ
j
e
ij
2
.
Exemple 38. Y
t
= X
t
X
t1
o [[ < 1, alors f
Y
() = f
X
() [1 + e
i
[
2
.
2.4.3 Estimation de la fonction dautocorrlation
Considrons un ensemble dobservations X
1
, ..., X
T
.
La moyenne empirique est donne par
X
T
=
1
T
T
t=1
X
t
.
La fonction dautocovariance empirique est donne par
T
(h) =
1
T h
Th
t=1
_
X
t
X
T
_ _
X
th
X
T
_
,
et la fonction dautocorrlation empirique est donne par
T
(h) =
T
(h)
T
(0)
.
Si ces estimateurs sont biaiss ( distance nie), ils sont malgr tout asymptotiquement
sans biais.
Proposition 39. Les moments empiriques convergent vers les moments thoriques :
X
T
m,
T
(h) (h) et
T
(h) (h) quand T .
En fait, comme nous le verrons par la suite, nous avons mme normalit asymptotique
des moments empiriques.
Remarque 40. Bien que ces fonctions soient dnies pour tout h tel que T < h < T, la
fonction dautocovariance empirique fournit un estimateur trs pauvre de (h) pour des
valeurs h proches de n. A titre indicatif, Box et Jenkins recommandent de nutiliser ces
quantits que si T > 50 et h T/4. In pratice, to obtain usefull estimate of the auto-
correlation function, we need at least 50 obsevations, and the estimated autocorrelations
r
k
could be calculated for k = 1, ..., K where K was not larger than, say, T/4.
28
An, par exemple, de faire de la selection de modles, il est important de pouvoir dire
si les autocovariances empiriques sont signicativement non nulles. Il est alors possible
dutiliser le rsultat suivant
Proposition 41. Si (X
t
) est un processus linaire, au sens o il satisfait X
t
=
jZ
tj
o (
t
) est une suite de variables i.i.d. centres, telle que E(
4
t
) = E(
2
t
)
2
<
+, o les
j
dnissent une srie absolument convergente, et o est une constante
positive, alors, on a la formule dite de Bartlett,
lim
T
Tcov (
T
(h) ,
T
(k)) = (h) (k) +
+
i=
(i) (i + k h) + (i + k) (i h) .
Proof. Brockwell et Davis (1991) page 226.
Ce thorme nest, en thorie, valable que pour un bruit blanc fort. On peut galement
montrer que ces autocorrlation vrient une proprit encore plus forte,
Proposition 42. Si (X
t
) est un processus linaire, au sens o il satisfait X
t
=
jZ
tj
o (
t
) est une suite de variables i.i.d. centres, telle que E(
4
t
) = E(
2
t
)
2
<
+, et
t
A (0,
2
), et o les
j
dnissent une srie absolument convergente, et o
est une constante positive, alors, on a, pour tout p 0,
n
_
_
_
T
(0)
.
.
.
T
(p)
_
_
_
A
_
_
_
_
_
_
(0)
.
.
.
(p)
_
_
_
, V
_
_
_
,
o V est la matrice de variance-covariance dnie par
V =
_
(h) (k) +
+
i=
(i) (i + k h) + (i + k) (i h)
_
h,k=0,...,p
.
Proof. Brockwell et Davis (1991) page 227.
> X=rnorm(100)
> as.vector(acf(X))
Autocorrelations of series X, by lag
0 1 2 3 4 5 6 7 8 9
1.000 -0.089 0.063 0.054 0.016 0.169 0.008 0.166 -0.179 0.244
> plot(acf(X))
29
2.4.4 Estimation de la densit spectrale
Le priodogramme est observations est dni comme le module au carr de la transform
de Fourier discrte des observations, i.e.
I
T
(x) =
1
2T
t=1
X
t
exp (itx)
2
=
1
2
hZ
T
(h) exp (ix) .
Le plus souvent, on estime le priodogramme aux frquences de Fourier, i.e. x
k
= 2k/T
pour k = 1, ..., T, not I
T,k
. Sous des hypothses de rgularit de la densit spectrale, le
priodogramme est un estimateur asymptotiquement sans biais de la densit spectrale.
Mais il nest pas consistant (on ne peut estimer que les T premier (h) intervenant dans
la dnition du priodogramme partir de T observations).
Exemple 43. Dans le cas dun processus i.i.d. gaussien, valu aux frquences de Fouri-
erde ]0, [ forme une suite de variables indpendantes, et identiquement distribues, suiv-
ant une loi du
2
, centr, deux degrs de libert.
Exemple 44. Pour les processus dit mmoire longue, la densit spectrale sexprime
sous la forme
f (x) = [1 exp (ix)[
2d
f
(x) ,
o f
est une fonction positive. Les valeurs du priodogramme sont asymptotiquement
biaises, et asymptotiquement corrles. Le fait que cette fonction ait un ple (ici en 0)
est dailleurs une caractrisation de la mmoire longue.
Cette densit spectrale permet dobtenir un grand nombre de rsultat. Par exemple,
il est possible destimer directement la variance du processus dinnovation
7
, en utilisant
la formule dite de Kolmogorov,
2
= 2 exp
_
1
2
_
2
0
log f
X
(x) dx
_
.
7
Cette notion sera dnie en dtails par la suite.
30
Un estimateur de cette variance est alors
2
=
1
T
T
t=1
log I
T,k
.
Dans le cas des processus mmoire longue, la densit spectrale est de la forme f
X
(x)
Cx
2d
. Un estimateur non paramtrique de d peut tre obtenu en rgressant localement le
log-priodogramme dans un voisinage de la frquence nulle. On appelle alors estimateur
GPH
d =
_
m
T
k=1
L
2
T,k
_
1
m
T
k=0
L
T,n
. log L
T,k
o L
T,k
= 2 log [x
k
[ +
2
m
T
m
T
j=1
log I
T,j
,
et o m
T
est une suite dentiers positifs telle que m
T
0 = et m
T
/T 0 quand
T .
> spec.pgram(X)
2.5 Lien entre temps continu et temps discret
Dnition 45. Un mouvement brownien W
t
est un processus stochastique, dnit pour
t R
+
, tel que W
0
= 0 et tel que, quelles que soient les dates t
1
< t
2
< ... < t
k
, les
variations du processus W
t
2
W
t
1
, W
t
3
W
t
2
, ..., W
t
k
W
t
k1
sont indpendantes, avec
E
_
W
t
i
W
t
j
_
= 0 et V
_
W
t
i
W
t
j
_
=
2
(t
i
t
j
). De plus, les variations du processus
entre deux dates t
i
et t
j
(telles que t
i
< t
j
) sont normalement distribues W
t
i
W
t
j
A (0,
2
(t
i
t
j
)).
Dans le cas o
2
= 1, on parlera de mouvement brownien standard. De plus, W
t
est continu en t, sans tre drivable : bien que le processus soit continu, les variations
ne sont pas bornes. Pour visualiser un mouvement browien il sut de considrer une
31
marche alatoire continue : on considre une marche alatoire discrte (X
t
= X
t1
+
t
o
t
A (0, 1)), pour laquelle on diminue les intervalles temporels entre deux dates
conscutives,
Proposition 46. Soit X
1
, X
2
, ..., X
T
un chantillon i.i.d., centr, de variance
2
. Soit [.]
la partie entire au sens o [x] x < [x] + 1 et [x] Z, alors pour tout 0 < r < 1,
1
_
[rT]
[rT]
t=1
X
t
L
A
_
0,
2
_
Ce rsultat est parfois appel Thorme Centrale Limite Fonctionnel . Notons X
(r)
T
la variable construite partir des [rT] premires observations par
X
(r)
T
=
1
T
[rT]
t=1
X
t
,
du rsultat prcdant, il en dcoule que
TX
(r)
T
L
A (0, r) ou encore
T
_
X
(r
2
)
T
X
(r
1
)
T
_
L
A (0, r
2
r
1
) ,
pour r
1
< r
2
. Ceci permet de montrer que la suite des
T.X
(.)
T
/ est asymptotiquement
distribue comme un mouvement brownien, au sens o
TX
(.)
T
L
W
.
Ce type de rsultat est alors trs utile pour obtenir des rsultats analytiques sur les
processus intgrs.
Considrons par exemple, une marche alatoire dnie par X
t
= X
t1
+
t
o
t
est
un bruit blanc de variance
2
, soit X
t
=
1
+
2
+ ... +
t
pour tout t, avec la convention
X
0
= 0. Notons X
(r)
T
la variable construite partir des [rT] premires observations par
X
(r)
T
==
1
T
[rT]
t=1
X
t
=
1
T
(
1
+
2
+ ... +
i
) , o
i 1
T
r <
i
T
,
on a alors
T
_
1
0
X
(r)
T
dr = T
3/2
T
t=1
x
t1
,
et daprs le thorme central limite fonctionnel,
T.X
(.)
T
L
W
.
. On obtient alors le
rsultat suivant
T
3/2
T
t=1
X
t1
T
_
1
0
W
s
ds.
32
De faon analogue, on peut montrer que
T
2
T
t=1
(X
t1
)
2 T
2
_
1
0
(W
s
)
2
ds.
Ces rsultats seront utiliss en particulier pour la dtermination des proprits asympto-
tiques des estimateurs obtenus partir de sries intgres.
La construction de lintgrale stochastique sobtient dailleurs comme passage la
limite sur des processus temps discret
8
. Considrons un dcoupage en T subdivisions
de lintervalle de temps [0, 1] : soit s
t
= t/T pour t = 0, 1, ..., T. Considrons ici (X
st
),
not (Y
t
), un processus dni pour t = 0, 1, ..., T. On appelera variation quadratique de
la srie chronologique (Y ) la srie chronologique dnie par
< Y >
t
=
t
j=1
[Y
j
Y
j1
]
2
pour t = 0, 1, ..., T
La variation quadratique du mouvement bronwien standard (W
t
) est obtenu comme pas-
sage la limite
< W >
t
= lim
T
t
j=1
[W
j
W
j1
]
2
= t
De la mme faon, lintgrale stochastique se dnit en temps discret par
Z
t
=
_
t
0
X
s
dW
s
=
t
i=1
A
i
[W
j
W
j1
]
o (X
s
) est un processus discret : X
s
= A
i
pour (i 1) /T s < i/T, puis par passage
la limite, stend aux processus en temps continu.
Aussi, tous les modles nanciers en temps continu ont un analogue en temps discret.
Mais si les modles en temps continu sont autant utiliss, cest principalement parce que
le calcul stochastique et la formule dIto permet danalyser les problmes de faon lgante
et relativement rapide.
Un processus suivant lquation stochastique
dY
t
= f (t, Y
t
) dt + g (t, Y
t
) dW
t
ou Y
t
= Y
0
+
_
t
0
f (s, Y
s
) ds +
_
t
0
g (s, Y
s
) dW
s
8
De faon plus simple, lintgrale dune fonction alatoire par rapport une mesure dterministe de
dnie dj comme une limite : soit A
t
un processus en temps continu, et considrons un dcoupage en
T subdivisions de lintervalle de temps [0, 1] : soit
s
= s/T pour s = 0, 1, ..., T. Considrons ici X
s
,
not Y
s
, le processus dni pour s = 0, 1, ..., T, par Y
s
= A
t
I (Tt s < T (t + 1)), alors
_
t
0
A
s
ds = lim
T
1
T
s
j=1
Y
s
33
peut tre assimil un processus en temps discret vriant lquation (approximation
dEuler)
Y
t+1
Y
t
= f (t, Y
t
) + g (t, Y
t
) [W
t+1
W
t
] = f (t, Y
t
) + g (t, Y
t
)
t
o (
t
) est un bruit blanc gaussien, de variance 1.
Remarque 47. Rciproquement, en reprenant un exemple de Nelson (1990), un modle
temps discret de type GARCH (1, 1) M (multivari), dni par
_
Y
t
= Y
t1
+ f (
2
t
) +
t
2
t+1
= +
2
t
( +
t
)
o (
t
) est un bruit blanc gaussien, est lanalogue en temps discret de lquation de diu-
sion
_
dY
t
= f (
2
t
) dt +
t
dW
1
t
d
2
t
= (
2
t
) dt +
2
t
dW
2
t
o (W
1
t
) et (W
2
t
) sont deux mouvements browniens centrs, rduits et indpendants.
34
La dcomposition tendance-cycle
Lanalyse des sries temporelles (conomiques par exemple) repose le plus souvent sur
une dcomposition tendance-cycle de la srie. Toutefois, cette dcomposition, si elle est
trs utilise en pratique, ne repose pas sur une construction thorique unique. Il est alors
souvent admis que la tendance correspond lquilibre de long terme, alors que le cycle
correspond la dynamique de court terme. Mais cette distinction ne sut pas pour
identier clairement les deux composantes, et des hypothses supplmentaires sont alors
ncessaires.
Deux approches sont alors gnrallement utilises : la premire consiste utiliser une
thorie conomique (cest dire un modle structurel dont les composantes auront des
interprtations conomiques), alors que la seconde tend utiliser des outils statistiques
neutres. Nous allons nous intresser ici cette seconde approche. Nanmoins, nous
pouvons ds prsent noter que cette neutralit est dicile mettre en oeuvre : il existe
une innit de faon de construire la tendance moyenne, par exemple. Il existe alors de
nombreuses mthodes pour valuer la croissance tendancielle.
Nous allons nous concentrer ici sur des dcompositions additives de la forme (X
t
) =
(T
t
)+(C
t
). Un modle multiplicatif peut en eet se ramener un modle additif en passant
au logarithme. Les mthodes traditionelles reposent sur deux techniques : lestimation
dune tendance dterministe et le lissage. Des mthodes plus rcentes se basent sur la
notion de tendance stochastique, avec en particulier la mthode de Beveridge et Nelson,
et les modles composantes inobservables.
Parmi les mthodes de lissage, lapproche la plus simple consiste utiliser des moyennes
mobiles on utilise alors une moyenne (pondre) de la srie (X
t
) dont la dure correspond
au cycle, qui conserve la tendance et limine le cycle. La moyenne symtrique arithmtique
est lexemple le plus simple : on considre alors la srie (Y
t
) dnie par
Y
t
= M(X
t
) =
1
2m + 1
(X
tm
+ X
tm+1
+ ... + Y
t1
+ Y
t
+ Y
t+1
+ ... + Y
t+m
) (3)
Ce type de lre, comme nous le verrons par la suite, conserve les tendances linaires, et
ltre (ou annule) les sries priodiques de priode 2m + 1. Toutefois, deux problmes
apparaissent dans lutilisation des ltres moyennes-mobiles
- les points extrmes de la srie ne peuvent tre traits de la mme faon que les autres
points (eet de bord)
- les sries lisses sont souvent autocorrles, non pas cause de la structure de la
srie initiale, mais il sagit dune consquence du processus de lissage (eet Slutsky-Yule).
Dautre mthodes de lissage existent, par exemple en utilisant la mthode PAT (phase
average trend) ou le ltre de Hodrick-Prescott (1980).
Lestimation dun trend dterministe repose sur lutilisation de fonctions simples, par
exemple linaires,
X
t
= T
t
+ C
t
= a + bt + C
t
(4)
Ces modles apparaissent parfois dans la littrature sous le terme TS (trend stationary), et
le cycle (suppos stationnaire) apparat alors comme lcart la tendance. Cette tendance
35
est alors estime par rgression. Cette mthode sera celle developpe dans la premire
partie, mme si elle a t fortement critique : la croissance long terme est alors xe
de faon mcanique. Des modles avec rupture de tendance ont ainsi t introduits.
> autoroute=read.table(
+ "http://freakonometrics.blog.free.fr/public/data/autoroute.csv",
+ header=TRUE,sep=";")
> a7=autoroute$a007
> X=ts(a7,start = c(1989, 9), frequency = 12)
> plot(decompose(X))
Il convient toutefois de noter que cette dcomposition tendance-cycle ne sont pas adap-
tes pour les sries non-stationnaires, et il convient dintgrer une composante stochastique
dans la tendance. Le modle de Beveridge et Nelson propose dexprimer les composantes
laide dune reprsentation ARIMA de la srie. Les modles composantes inobservables
repose surlutilisation de modles espace-tat (e.g. ltre de Kalman). Ces deux mthodes
sont prsentes dans larticle de Doz, Rabault et Sobczack Dcomposition tendance-cycle
: estimations par des mthodes statistiques univaries (1995).
36
3 Dsaisonnalisation par regression linaire
3.1 Prsentation des donnes
Nous considrons ici une srie chronologique, mensuelle, comportant une forte saisonalit,
le trac voyageur de la SNCF en France ( Gouriroux & Monfort (1995)),
JAN FEB MAR APR MAY JUN JUL AUG SEP OCT NOV DEC
1963 1750 1560 1820 2090 1910 2410 3140 2850 2090 1850 1630 2420
1964 1710 1600 1800 2120 2100 2460 3200 2960 2190 1870 1770 2270
1965 1670 1640 1770 2190 2020 2610 3190 2860 2140 1870 1760 2360
1966 1810 1640 1860 1990 2110 2500 3030 2900 2160 1940 1750 2330
1967 1850 1590 1880 2210 2110 2480 2880 2670 2100 1920 1670 2520
1968 1834 1792 1860 2138 2115 2485 2581 2639 2038 1936 1784 2391
1969 1798 1850 1981 2085 2120 2491 2834 2725 1932 2085 1856 2553
1970 1854 1823 2005 2418 2219 2722 2912 2771 2153 2136 1910 2537
1971 2008 1835 2120 2304 2264 2175 2928 2738 2178 2137 2009 2546
1972 2084 2034 2152 2522 2318 2684 2971 2759 2267 2152 1978 2723
1973 2081 2112 2279 2661 2281 2929 3089 2803 2296 2210 2135 2862
1974 2223 2248 2421 2710 2505 3021 3327 3044 2607 2525 2160 2876
1975 2481 2428 2596 2923 2795 3287 3598 3118 2875 2754 2588 3266
1976 2667 2668 2804 2806 2976 3430 3705 3053 2764 2802 2707 3307
1977 2706 2586 2796 2978 3053 3463 3649 3095 2839 2966 2863 3375
1978 2820 2857 3306 3333 3141 3512 3744 3179 2984 2950 2896 3611
1979 3313 2644 2872 3267 3391 3682 3937 3284 2849 3085 3043 3541
1980 2848 2913 3248 3250 3375 3640 3771 3259 3206 3269 3181 4008
> sncf=read.table(
+ "http://freakonometrics.blog.free.fr/public/data/sncf.csv",
+ header=TRUE,sep=";")
> SNCF=ts(as.vector(t(as.matrix(sncf[,2:13]))),
+ ,start = c(1963, 1), frequency = 12)
> plot(SNCF,lwd=2,col="purple")
37
3.2 Le modle linaire
La srie X
t
est la somme de 2 composantes dterministes : une tendance Z
t
, dune saison-
nalit S
t
et dune composante alatoire
t
X
t
= Z
t
+ S
t
+
t
.
On suppose que Z
t
et S
t
sont des combinaisons linaires de fonctions connues dans le
temps, Z
i
t
et S
j
t
, i.e.
_
Z
t
= Z
1
t
1
+ Z
2
t
2
+ ... + Z
m
t
m
S
t
= S
1
t
1
+ S
2
t
2
+ ... + S
n
t
n
.
Le but est destimer les
1
, ...,
m
et
1
, ...,
n
partir des T observations.
X
t
=
m
i=1
Z
i
t
i
+
n
j=1
S
j
t
j
+
t
pour t = 1, ..., T.
3.2.1 Hypothses sur les erreurs
On supposera lhypothse suivante vrie, savoir que les erreurs sont centres : E(
t
) =
0, de mme variance V (
t
) =
2
et non-corrles cov (
t
,
th
) = 0 pour tout h > 0.
3.2.2 Composante saisonnire du modles
La forme de S
t
dpend du type de donnes, et de la forme de la saisonnalit. On consid-
rera ici des fonctions S
i
t
indicatrices,
S
i
t
=
_
0 si t = mois i
1 si t ,= mois i
ou S
i
t
=
_
0 si t = 0 [modulo i]
1 si t ,= 0 [modulo i] .
Exemple 48. Pour des donnes trimestrielles, on a S
t
= S
1
t
1
+ S
2
t
2
+ S
3
t
3
+ S
4
t
4
o
S
j
t
est la fonction indicatrice du trimestre j.
3.2.3 Composante tendancielle
Cette composante a gnralement une forme simple, retant la croissance moyenne.
Exemple 49. Pour une tendance linaire, Z
t
=
1
+
2
t on pose Z
1
t
= 1 et Z
2
t
= t.
Plusieurs types de composantes tendancielles existent :
(i) linaire : Z
t
=
0
+
1
t,
(ii) exponentielle : Z
t
=
t
, ou Z
t
= (1 + r)
t
ou encore Z
t
= exp (rt) ,
(iii) quadratique Z
t
=
0
+
1
t +
2
t
2
,
(iv) de Gompertz Z
t
= exp (
t
+ ) ,
(v) logistique Z
t
= [
t
]
1
.
38
Le cas (i) se traite par rgression simple (cf partie suivante), le cas (ii) se ramne au
cas (i) par transformation logarithmique, et le cas (iii) se traite par rgression multiple.
Il est galement possible dutiliser des modles avec des ruptures :
Z
t
=
_
0
+
1
t pour t t
0
0
+
1
t pour t > t
0
.
Cette tendance est une des composante les plus complique modliser car il nexiste
pas vraiment de mthode
3.2.4 Modle trimestriel de Buys-Ballot (1847)
La dsaisonnalisation par rgression linaire, dans le cas o la tendance est suppose
linaire, et les donnes sont trimestrielles, quivaut tester le modle linaire
X
t
= a + t
. .
Zt
+
1
S
1
t
+
2
S
2
t
+
3
S
3
t
+
4
S
4
t
. .
St
+
t
,
o Z
t
est la tendance (linaire) et o S
t
est la composante saisonnire. Supposons que les
donnes commencent au 1er trimestre. Le modle scrit alors, pour lexemple du trac
SNCF
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
5130
6410
8080
5900
5110
6680
8350
5910
5080
.
.
.
X
t
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
=
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
1
1
1
1
1
1
1
1
1
.
.
.
1
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
+
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
1
2
3
4
5
6
7
8
9
.
.
.
t
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
+
1
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
1
0
0
0
1
0
0
0
1
.
.
.
S
1
t
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
+
2
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
0
1
0
0
0
1
0
0
0
.
.
.
S
2
t
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
+
3
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
0
0
1
0
0
0
1
0
0
.
.
.
S
3
t
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
+
4
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
0
0
0
1
0
0
0
1
0
.
.
.
S
4
t
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
+
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
9
.
.
.
t
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
,
qui peut se rcrire, de faon matricielle,
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
5130
6410
8080
5900
5110
6680
8350
5910
5080
.
.
.
X
t
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
=
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
1
1
1
1
1
1
1
1
1
.
.
.
1
1
2
3
4
5
6
7
8
9
.
.
.
t
1
0
0
0
1
0
0
0
1
.
.
.
S
1
t
0
1
0
0
0
1
0
0
0
.
.
.
S
2
t
0
0
1
0
0
0
1
0
0
.
.
.
S
3
t
0
0
0
1
0
0
0
1
0
.
.
.
S
4
t
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
4
_
_
_
_
_
_
_
_
+
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
9
.
.
.
t
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
_
soit X = Y +
39
Lcriture de lestimateur des moindres carrs ordinaires scrit
= (Y
Y )
1
Y
X. Toute-
fos, cette criture nest possible que si Y
Y est inversible, ce qui nest pas le cas ici car la
premire colonne (correspondant la constante) est gale la somme des 4 dernires (les
composantes trimestrielles). Deux mthodes sont alors possibles pour faire malgr tout
lidentication du modle.
ne pas tenir compte de la constante, et identier le modle
X
t
= t +
1
S
1
t
+
2
S
2
t
+
3
S
3
t
+
4
S
4
t
+
t
, (5)
rajouter une contrainte, et identier le modle
_
X
t
= + t +
1
S
1
t
+
2
S
2
t
+
3
S
3
t
+
4
S
4
t
+
t
sous contrainte
1
+
2
+
3
+
4
= 0,
(6)
Cette dernire contrainte est arbitraire, mais correspond une interprtation bien pr-
cise. Considrons la srie reprsente ci dessous, avec une saisonnalit dordre 4 (donnes
trimestrielles)
> SNCFQ= ts(apply(matrix(as.numeric(SNCF),3,length(SNCF)/3),2,sum),
+ start = c(1963, 1), frequency = 4)
> plot(SNCFQ,col="red")
> SNCFQ
Qtr1 Qtr2 Qtr3 Qtr4
1963 5130 6410 8080 5900
1964 5110 6680 8350 5910
1965 5080 6820 8190 5990
1966 5310 6600 8090 6020
... etc. Le graphique des donnes trimestrielles est le suivant
40
3.3 Estimateur des moindres carrs ordinaires (mco)
3.3.1 Solutions gnrales
On considre un modle de la forme
X
t
=
m
i=1
Z
i
t
i
+
n
j=1
S
j
t
j
+
t
pour t = 1, ..., T.
La mthode des mco consiste choisir les
i
et
j
de faon minimiser le carr des erreurs
_
i
,
j
_
= arg min
_
t=1
2
t
_
= arg min
_
_
_
t=1
_
X
t
i=1
Z
i
t
i
+
n
j=1
S
j
t
j
_
2
_
_
_
.
Notations : = (
1
, ...,
m
)
, = (
1
, ...,
n
)
,
Z =
_
_
[ [
Z
1
... Z
m
[ [
_
_
=
_
Z
i
t
i=1,...,n
t=1,...,T
et S =
_
_
[ [
S
1
... S
n
[ [
_
_
=
_
S
j
t
j=1,...,n
t=1,...,T
Le modle scrit
X = Z + S + = [Z[S]
_
_
+ = Y b + ,
et
b =
_
,
_
vrie alors lquation
Y
b = Y
X soit [Z S]
_
Z
b =
_
Z
_
X,
et donc
_
_
=
_
Z
Z Z
S
S
Z S
S
_
1
_
Z
X
S
X
_
,
ce qui donne les coecients
_
=
_
Z
Z Z
S (S
S)
1
S
1
_
Z
X Z
S (S
S)
1
S
=
_
S
S S
Z (Z
Z)
1
Z
1
_
S
X S
Z (Z
Z)
1
Z
.
Remarque 50. Sil ny a pas deet saisonnier, X = Z + , et on retrouve le modle
linaire usuel, avec pour estimateur mco
= [Z
Z]
1
Z
X.
41
3.3.2 Cas particulier : le modle trimestriel de Buys-Ballot
Pour le modle
X
t
=
1
+
2
t + S
1
t
1
+ S
2
t
2
+ S
3
t
3
+ S
4
t
4
+
t
,
il est possible dexpliciter les dirents coecients. Lquation
_
min
,
T
t=1
_
X
t
2
t
4
j=1
S
j
t
j
_
2
sous contrainte ()
1
+
2
+
3
+
4
= 0,
peut se rcrire
_
_
_
min
,
T
t=1
_
X
t
2
t
4
j=1
S
j
t
j
_
2
o
_
1
= [
1
+
2
+
3
+
4
] /4
j
=
j
1
,
En notant N le nombre dannes entires (N = T/4), on pose
x
n
: moyenne des X
t
relatives lanne n
x
j
: moyenne des X
t
relatives au trimestre j
x : moyenne de toutes les observations X
t
On a alors les estimateurs suivant
2
= 3
N
n=1
n x
n
N(N+1)
2
x
N (N
2
1)
(7)
j
= x
j
[j + 2 (N 1)]
2
pour j = 1, 2, 3, 4 (8)
do nallement
_
1
=
_
1
+
2
+
3
+
4
_
/4
j
=
1
(9)
3.3.3 Gnralisation des formules de Buys-Ballot (tendance linaire)
Les relations obtenues dans le cas prcdant peuvent en fait tre gnralises dans le cas
dune priodicit m, et en notant (de la mme faon que prcdemment) N le nombre
dannes entures. L modle scrit alors
X
t
=
1
+
2
t + S
1
t
1
+ S
2
t
2
+ S
3
t
3
+ ... + S
m
t
m
+
t
.
Lquation
_
min
,
T
t=1
_
X
t
2
t
m
j=1
S
j
t
j
_
2
sous contrainte ()
1
+
2
+
3
+ ... +
m
= 0,
admet alors pour solution, en notant
2
=
12
m
N
n=1
n x
n
N(N+1)
2
x
N (N
2
1)
42
1
= x
2
Nm + 1
2
j
= x
j
x
2
_
j
m + 1
2
_
3.4 Application au trac voyageur
3.4.1 Srie agrge par trimestre
Considrons la srie du traic SNCF agrge par trimestre, reprsente ci-dessous, avec
en ligne les annes, et en colonne les trimestres,
nj 1 2 3 4 x
n
1 5130 6410 8080 5900 6380
2 5110 6680 8350 5910 6513
3 5080 6820 8190 5990 6520
4 5310 6600 8090 6020 6505
5 5320 6800 7650 6110 6470
6 5486 6738 7258 6111 6398
7 5629 6696 7491 6494 6578
8 5682 7359 7836 6583 6865
9 5963 6743 7844 6692 6811
10 6270 7524 7997 6853 7161
11 6472 7871 8188 7207 7435
12 6892 8236 8978 7561 7917
13 7505 9005 9591 8608 8677
14 8139 9212 9522 8816 8922
15 8088 9494 9583 9204 9092
16 8983 9986 9907 9457 9583
17 8829 10340 10070 9669 9727
18 9009 10265 10236 10458 9992
x
j
6605 7932 8603 7425 7641
Considrons alors un modle de la forme suivante, avec une saisonnalit en 4 com-
posantes (les donnes tant trimestrielles : chaque composante correspondant un
trimestre), et une tendance suppose linaire (Z
t
=
1
+
2
t),
X
t
=
1
+
2
t + S
1
t
1
+ S
2
t
2
+ S
3
t
3
+ S
4
t
4
+
t
,
Compte tenu de la sur-identication de ce modle, on rajoute la contrainte que la somme
des
j
soit nulle (cest dire que la composante saionnire soit centre : E(S
t
) = 0). On
peut alors faire lestimation de la faon suivante :
(i) on estime le modle (5), cest dire sans contrainte, et sans constante
1
(ii) et on se ramne au modle (6) en utilisant les relations.
43
Pour ltape (i) deux mthodes analogues sont possibles : soit en utilisant les expres-
sions des estimateurs, soit en eectuant la rgression sous EViews
Calcul direct des estimateurs
nj T1 T2 T3 T4 x
n
n x
n
1963 1 5 130 6 410 8 080 5 900 6 380,00 6 380,00
1964 2 5 110 6 680 8 350 5 910 6 512,50 13 025,00
1965 3 5 080 6 820 8 190 5 990 6 520,00 19 560,00
1966 4 5 310 6 600 8 090 6 020 6 505,00 26 020,00
1967 5 5 320 6 800 7 650 6 110 6 470,00 32 350,00
1968 6 5 486 6 738 7 258 6 111 6 398,25 38 389,50
1969 7 5 629 6 696 7 491 6 494 6 577,50 46 042,50
1970 8 5 682 7 359 7 836 6 583 6 865,00 54 920,00
1971 9 5 963 6 743 7 844 6 692 6 810,50 61 294,50
1972 10 6 270 7 524 7 997 6 853 7 161,00 71 610,00
1973 11 6 472 7 871 8 188 7 207 7 434,50 81 779,50
1974 12 6 892 8 236 8 978 7 561 7 916,75 95 001,00
1975 13 7 505 9 005 9 591 8 608 8 677,25 112 804,25
1976 14 8 139 9 212 9 522 8 816 8 922,25 124 911,50
1977 15 8 088 9 494 9 583 9 204 9 092,25 136 383,75
1978 16 8 983 9 986 9 907 9 457 9 583,25 153 332,00
1979 17 8 829 10 340 10 070 9 669 9 727,00 165 359,00
1980 18 9 009 10 265 10 236 10 458 9 992,00 179 856,00
x
j
6 605 7 932 8 603 7 425 7641, 39
Pour chacune des annes et chacun des trimestre, il est possible de calculer des moyennes
: aussi, la moyenne pour 1963 tait de 6380, et de 7435 pour 1973, et de faon analogue,
la moyenne pour le premier trimestre est de 6605, et de 8603 pour le troisime. La
moyenne totale est alors de 7641, pour ces 72 observations. Aussi, N = 18 (on a 18
annes dobservations), et la pente de la droite de la tendance est donne par
2
=
3
N (N
2
1)
_
N
n=1
n x
n
N (N + 1)
2
x
_
=
3
18 (18
2
1)
[1 419 019-1 306 678] 57.97
en utilisant les moyennes par trimestre, et par anne, donnes dans le tableau ci-dessus,
et
j
= x
j
[j + 2 (N 1)]
2
et donc
_
1
= 6605 35 57.97 4577
2
= 7932 36 57.97 5845
3
= 8603 37 57.97 6459
4
= 7425 38 57.97 5222
44
do nallement
_
1
=
_
1
+
2
+
3
+
4
_
/4 5526
j
=
1
soit
_
1
= 4577 5526 949
2
= 5845 5526 +320
3
= 6459 5526 +933
4
= 5222 5526 304
Aussi, le modle scrit
X
t
= 5526 + 58t 949S
1
t
+ 320S
2
t
+ 933S
3
t
304S
4
t
.
La rgression se fait sur le modle non-contraint, en ne prenant pas en compte la
constante,
> T = seq(from=1963,to=1980.75,by=.25)
> Q = rep(1:4,18)
> reg=lm(SNCFQ~0+T+as.factor(Q))
> summary(reg)
Call:
lm(formula = SNCFQ ~ 0 + T + as.factor(Q))
Residuals:
Min 1Q Median 3Q Max
-1073.2 -425.5 -106.8 404.4 1485.6
Coefficients:
Estimate Std. Error t value Pr(>|t|)
T 231.87 12.55 18.47 <2e-16 ***
as.factor(Q)1 -450526.26 24752.39 -18.20 <2e-16 ***
as.factor(Q)2 -449257.44 24755.53 -18.15 <2e-16 ***
as.factor(Q)3 -448644.19 24758.67 -18.12 <2e-16 ***
as.factor(Q)4 -449880.94 24761.81 -18.17 <2e-16 ***
---
Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 . 0.1 1
Residual standard error: 552.7 on 67 degrees of freedom
Multiple R-squared: 0.9953, Adjusted R-squared: 0.995
F-statistic: 2846 on 5 and 67 DF, p-value: < 2.2e-16
> plot(T,residuals(reg),type="l")
45
Lerreur de modlisation (les rsidus) est, en moyenne, beaucoup trop importante au
dbut, ainsi quau milieu (dbut des annees 70), mais lerreur se faisant ici dans lautre
sens (sur-estimation versus sous-estimation). Le caractre non-i.i.d. des rsidus pouvait
tre devine la lecture des sorties de la rgression, grce au test de Durbin Watson, qui
valide le caractre AR(1) des rsidus.
La srie ajuste (ci-dessous gauche) correspond la srie
X
t
= X
t
t
=
m
i=1
Z
i
t
i
+
n
j=1
S
j
t
j
,
avec (Z
t
) en trait plein, et
_
X
t
_
en pointills. Cette srie pourra tre prolonge an
de faire de la prvision. La srie corrige des corrections saisonnires (CVS-ci-dessous
droite) correspond la srie
Y
t
= X
t
S
t
=
m
i=1
Z
i
t
i
+
t
.
Remarque 51. La composante saisonnire S
t
correspond
n
j=1
S
j
t
j
, telle quelle ap-
parat dans le modle contraint. Elle vrie alors E(S
t
) = 0. Cette proprit nest pas
vrie dans le modle sans constante.
46
3.4.2 Analyse sur donnes mensuelles
La mthode dcrite ci-dessus donne les rsultats suivants
JAN FEB MAR APR MAY JUN JUL AUG SEP OCT NOV DEC x
n
1963 1750 1560 1820 2090 1910 2410 3140 2850 2090 1850 1630 2420 2127
1964 1710 1600 1800 2120 2100 2460 3200 2960 2190 1870 1770 2270 2171
1965 1670 1640 1770 2190 2020 2610 3190 2860 2140 1870 1760 2360 2173
1966 1810 1640 1860 1990 2110 2500 3030 2900 2160 1940 1750 2330 2168
1967 1850 1590 1880 2210 2110 2480 2880 2670 2100 1920 1670 2520 2157
1968 1834 1792 1860 2138 2115 2485 2581 2639 2038 1936 1784 2391 2133
1969 1798 1850 1981 2085 2120 2491 2834 2725 1932 2085 1856 2553 2192
1970 1854 1823 2005 2418 2219 2722 2912 2771 2153 2136 1910 2537 2288
1971 2008 1835 2120 2304 2264 2175 2928 2738 2178 2137 2009 2546 2270
1972 2084 2034 2152 2522 2318 2684 2971 2759 2267 2152 1978 2723 2387
1973 2081 2112 2279 2661 2281 2929 3089 2803 2296 2210 2135 2862 2478
1974 2223 2248 2421 2710 2505 3021 3327 3044 2607 2525 2160 2876 2639
1975 2481 2428 2596 2923 2795 3287 3598 3118 2875 2754 2588 3266 2892
1976 2667 2668 2804 2806 2976 3430 3705 3053 2764 2802 2707 3307 2974
1977 2706 2586 2796 2978 3053 3463 3649 3095 2839 2966 2863 3375 3031
1978 2820 2857 3306 3333 3141 3512 3744 3179 2984 2950 2896 3611 3194
1979 3313 2644 2872 3267 3391 3682 3937 3284 2849 3085 3043 3541 3242
1980 2848 2913 3248 3250 3375 3640 3771 3259 3206 3269 3181 4008 3331
x
j
2195 2101 2309 2555 2489 2888 3249 2928 2426 2359 2205 2861 2547
qui donne les coecients suivants
10
11
12
9.82 1038 943 1156 1380 1293 1667 1938 1517 1135 1123 975 1618
Ce qui donne la srie ajuste ( gauche) et la srie corrige des variations
saisonnires ( droite)
> T = seq(from=1963,to=1980+11/12,by=1/12)
> M = as.factor(rep(1:12,18))
> reg=lm(SNCF~0+T+M)
> summary(reg)
Call:
lm(formula = SNCF ~ 0 + T + M)
Residuals:
Min 1Q Median 3Q Max
-674.19 -154.53 -12.16 125.74 611.51
Coefficients:
Estimate Std. Error t value Pr(>|t|)
47
T 77.29 2.68 28.84 <2e-16 ***
M1 -150182.38 5283.13 -28.43 <2e-16 ***
M2 -150282.54 5283.35 -28.45 <2e-16 ***
M3 -150080.65 5283.58 -28.41 <2e-16 ***
M4 -149841.26 5283.80 -28.36 <2e-16 ***
M5 -149913.92 5284.02 -28.37 <2e-16 ***
M6 -149521.58 5284.25 -28.30 <2e-16 ***
M7 -149166.64 5284.47 -28.23 <2e-16 ***
M8 -149494.13 5284.69 -28.29 <2e-16 ***
M9 -150002.74 5284.92 -28.38 <2e-16 ***
M10 -150076.46 5285.14 -28.40 <2e-16 ***
M11 -150236.62 5285.36 -28.43 <2e-16 ***
M12 -149587.17 5285.59 -28.30 <2e-16 ***
---
Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 . 0.1 1
Residual standard error: 204.3 on 203 degrees of freedom
Multiple R-squared: 0.9942, Adjusted R-squared: 0.9939
F-statistic: 2693 on 13 and 203 DF, p-value: < 2.2e-16
3.5 Proprits statistiques des estimateurs
Sous lhypothse E(
t
) = 0 les estimateurs mco sont sans biais :
E
_
i
_
=
i
et E(
j
) =
j
.
La variance des estimateurs peut tre estime par
V
_
_
= s
2
_
Z
Z Z
S
S
Z S
S
1
_
, o s
2
=
1
T n m
T
t=1
2
t
,
ce qui permet dobtenir des intervalles de conance sur les estimateurs.
48
3.6 Application au trac sur lautoroute A7
Sur les donnes de trac sur lautoroute A7, on obtient la dcomposition suivante
> autoroute=read.table(
+ "http://freakonometrics.blog.free.fr/public/data/autoroute.csv",
+ header=TRUE,sep=";")
> a7=autoroute$a007
> X=ts(a7,start = c(1989, 9), frequency = 12)
> T=time(X)
> S=cycle(X)
> B=data.frame(x=as.vector(X),T=as.vector(T),S=as.vector(S))
> regT=lm(x~T,data=B)
> plot(X)
> abline(regT,col="red",lwd=2)
> summary(regT)
Call:
lm(formula = x ~ T, data = B)
Residuals:
Min 1Q Median 3Q Max
-20161 -10568 -2615 4390 35017
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2872401.7 1545258.4 -1.859 0.0666 .
T 1460.7 775.3 1.884 0.0631 .
---
Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 . 0.1 1
Residual standard error: 14610 on 83 degrees of freedom
Multiple R-squared: 0.04101, Adjusted R-squared: 0.02946
F-statistic: 3.55 on 1 and 83 DF, p-value: 0.06306
49
> B$res1=X-X1
> regS=lm(res1~0+as.factor(S),data=B)
> B$X2=predict(regS)
> plot(B$S,B$res1,xlab="saisonnalit")
3.7 Prvision un horizon h
Soit h 1. On suppose que le modle reste valide en T + h cest dire que
X
T+h
=
m
i=1
Z
i
T+h
i
+
n
j=1
S
j
T+h
j
+
T+h
,
avec E(
T+h
) = 0, V (
T+h
) =
2
et cov (
t
,
T+h
) = 0 pour t = 1, ..., T. La variable X
T+h
peut tre approche par
X
T
(h) =
m
i=1
Z
i
T+h
i
+
n
j=1
S
j
T+h
j
.
Cette prvision est la meilleur (au sens de lerreur quadratique moyenne) prvision,
linaire en X
1
, ..., X
T
et sans biais. Un intervalle de conance de cette prvision est de la
forme
_
X
T
(h)
1/2
_
e
h
;
X
T
(h) +
1/2
_
e
h
_
,
50
o
1/2
est le quantile dordre de la loi de Student T mn degrs de libert, et
o
e
h
=
E
_
_
X
T
(h) X
T+h
_
2
_
=
V
_
m
i=1
Z
i
T+h
i
+
n
j=1
S
j
T+h
j
T+h
_
=
_
_
_
V
_
__
_
_
+ s
2
.
51
4 Dsaisonnalisation par moyennes mobiles
On considre une srie temporelle (X
t
) admettant une dcomposition
X
t
= Z
t
+ S
t
+
t
pour t = 1, ..., T
Le but est de trouver une transformation du processus X
t
qui annule la composante
saisonnire S
t
: on cherche un ltre tel que Y
t
= (X
t
) = Z
t
+
t
.
Lutilisation des moyennes mobiles est relativement ancienne puisquelle remonte
Poynting (1884) puis Hooker (1901) qui, les premiers, ont tent doter (et de distinguer)
la tendance et la composante cyclique pour des sries de prix en considrant des moyennes
glissantes. En 1930, Macauley a introduit une mthode pour dsaisonnaliser les sries au
sein de la Rserve Fdrale amricaine, base sur lutilisation de moyennes mobiles centres
dordre 12, pour obtenir une estimation de la tendance. Dans les annes 50, le bureau du
Census aux Etats Unis a commenc developper des modles bass sur lutilisation de
moyennes mobiles, modles qui ont abouti la mthode X11 en 1965.
Cette mthode a pu tre dveloppe grce aux dveloppements informatiques impor-
tants qui ont eu lieu cette poque. Une des implications est que des dcisions, faisant
habituellement appel au jugement de lutilisateur, ont pu tre en grande partie automa-
tises. De plus, linformatique a facilit lutilisation de rgressions visant corriger les
eets de jours ouvrables (nombre de jours travaills dans le mois).
En 1975, suite au dveloppement des modles ARIMA (conscutif la publication des
travaux de Box et Jenkins dans les annes 70), le modle X11 a pu voluer vers le modle
dit X11-ARIMA.
La mthode de Buys-Ballot, bas sur une regression globale du modle a t prsent
dans la partie prcdante. Nous allons prsenter dans cette partie les mthodes bases
sur des rgressions locales. Les rgressions locales consistent ajuster des polynmes, en
gnral par les moindres carrs, sur des intervalles glissants (se dcallant chaque fois
dun point). Au centre de cette intervalle, la donne lisse est la valeur, cette date, du
polynme ajust. Ces rgressions locales reviennent appliquer des moyennes mobiles.
4.1 Gnralits sur les moyennes mobiles
4.1.1 Notion doprateur retard L
Dnition 52. On appelera oprateur retard L (=lag, ou B =backward) loprateur
linaire dni par
L : X
t
L(X
t
) = LX
t
= X
t1
,
et oprateur avance F (=forward)
F : X
t
F (X
t
) = FX
t
= X
t+1
,
Remarque 53. L F = F L = I (oprateur identit) et on notera par la suite F = L
1
et L = F
1
.
52
(i) Il est possible de composer les oprateurs : L
2
= L L, et plus gnrallement,
L
p
= L L ... L
. .
p fois
o p N
avec la convention L
0
= I. On notera que L
p
(X
t
) = X
tp
.
(ii) Soit A le polynme, A(z) = a
0
+a
1
z+a
2
z
2
+...+a
p
z
p
. On notera A(L) loprateur
A(L) = a
0
I + a
1
L + a
2
L
2
+ ... + a
p
L
p
=
p
k=0
a
k
L
k
.
Soit (X
t
) une srie temporelle. La srie (Y
t
) dnie par Y
t
= A(L) X
t
vrie
Y
t
= A(L) X
t
=
p
k=0
a
k
X
tk
.
Par passage la limite, on peut aussi dnir des sries formelles
A(z) =
k=0
a
k
z
k
et A(L) =
k=0
a
k
L
k
.
Proposition 54. Pour toutes moyennes mobiles A et B, alors
_
_
_
A(L) + B(L) = (A + B) (L)
R, A(L) = (A) (L)
A(L) B(L) = (AB) (L) = B(L) A(L) .
La moyenne mobile C = AB = BA vrie alors
_
k=0
a
k
L
k
_
k=0
b
k
L
k
_
=
_
i=0
c
i
L
i
_
o c
i
=
i
k=0
a
k
b
ik
.
4.1.2 Les moyennes mobiles
Dnition 55. Une moyenne mobile est un oprateur linaire, combinaison linaire
doprateurs retard
M =
m
2
i=m
1
i
L
i
, o m
1
, m
2
N,
qui peut scrire
M = L
m
1
m
1
+m
2
i=0
im
1
L
i
= L
m
1
m
1
+m
2
i=0
im
1
F
i
= L
m
1
(F) , (10)
o (.) est un polynme appel polynme caractristique de M, de degr m
1
+ m
2
, et
m
1
+ m
2
+ 1 sera appel ordre de M (correspondant au nombre (thorique) de terme de
M).
53
Dnition 56. Si m
1
= m
2
= m, la moyenne mobile sera dite centre. De plus, si M
est centre, et que pour tout i,
i
=
i
alors la moyenne mobile est dite symtrique.
Exemple 57. La moyenne mobile M
1
(X
t
) = (X
t
+ X
t1
) /2, soit M
1
= (L +I) /2 =
L[I + F] /2 est de degr 1, dordre 2 et nest pas centre (ni symtrique).
Exemple 58. La moyenne mobile M
2
(X
t
) = (X
t+1
+ 2X
t
+ X
t1
) /4, soit M
2
=
(L
1
+ 2I + L) /4 = L[I + 2F + F
2
] /4 est de degr 2, dordre 3, est centre et symtrique.
On peut dj noter, pour les moyennes centres symtriques, sont ncessairement
dordre impair (pour tre centres). Pour m impair, on considrera les moyennes mobiles
dordre m = 2p + 1 dnie par
M
m
(X
t
) =
1
m
[X
tp
+ X
tp+1
+ ... + X
t1
+ X
t
+ X
t+1
+ ... + X
t+p1
+ X
t+p
] .
Exemple 59. La moyenne mobile dordre 3 - Cette moyenne mobile a pour coecients
1/3, 1/3, 1/3,
M
3
(X
t
) =
1
3
[X
t1
+ X
t
+ X
t+1
] .
Exemple 60. La moyenne mobile dordre 9 - Cette moyenne mobile a pour coecients
1/9, 1/9, ..., 1/9,
M
9
(X
t
) =
1
9
[X
t4
+ X
t3
+ ... + X
t
+ ... + X
t+4
] .
De manire gnrale, le ltre
M
2p+1
(X
t
) =
1
2p + 1
[X
tp
+ X
tp+1
+ ... + X
t1
+ X
t
+ X
t+1
+ ... + X
t+p1
+ X
t+p
] .
scrit, pour p = 3
> library(ts)
> Y=filter(X,filter=rep(1/(2*p+1),2*p+1))
Par exemple, sur la srie a7
> autoroute=read.table(
+ "http://freakonometrics.blog.free.fr/public/data/autoroute.csv",
+ header=TRUE,sep=";")
> a7=autoroute$a007
> X=ts(a7,start = c(1989, 9), frequency = 12)
> plot(X)
> p=3
> Y=filter(X,filter=rep(1/p,p))
> lines(Y,col="red",lwd=2)
> p=6
> Y=filter(X,filter=rep(1/p,p))
> lines(Y,col="blue",lwd=2)
> p=12
> Y=filter(X,filter=rep(1/p,p))
> lines(Y,col="green",lwd=2)
54
Toutefois, il est possible de construire des moyennes mobiles centres et symtriques
dordre pair, de faon articielle. Pour cela, pour m = 2p on considrera les moyennes
mobiles dnies par
M
m
(X
t
) =
1
m
_
X
tp+1/2
+ ... + X
t1/2
+ X
t+1/2
+ ... + X
t+p1/2
,
o X
t1/2
est obtenue comme valeur intermdiaire entre X
t1
et X
t
. Cette moyenne
mobile peut donc se rcrire
M
m
(X
t
) =
1
m
_
1
2
(X
tp
+ X
tp+1
) + ... +
1
2
(X
t1
+ X
t
) +
1
2
(X
t
+ X
t+1
) + ... +
1
2
(X
t+p1
+ X
t+p
)
_
=
1
m
_
1
2
X
tp
+ X
tp+1
+ ... + X
t1
+ X
t
+ X
t+1
+ ... + X
t+p1
+
1
2
X
t+p
_
.
Cette moyenne mobile dordre pair est en fait une moyenne mobile dordre impair, que
lon notera M
2p
, dnie par
M
2p
(X
t
) =
1
2m
[X
tp
+ 2X
tp+1
+ ... + 2X
t1
+ 2X
t
+ 2X
t+1
+ ... + 2X
t+p1
+ X
t+p
] .
Exemple 61. La moyenne mobile 24 - Cette moyenne mobile permet permet destimer
des tendances dans le cas de donnes trimestrielles, elle est dordre 5 et de coecients
1/8, 1/4, 1/4, 1/4, 1/8
M
24
(X
t
) =
1
8
[X
t2
+ 2X
t1
+ 2X
t
+ 2X
t+1
+ X
t+2
] .
Comme nous le verrons par la suite, elle limine les saisonnalits trimestrielles des sries
trimestrielles, elle conserve les tendances linaires, et elle rduit de 75% la variance dun
bruit blanc.
Exemple 62. La moyenne mobile 212 - Cette moyenne mobile permet permet destimer
des tendances dans le cas de donnes mensuelles, elle est dordre 13 et de coecients
1/24, 1/12, 1/12, ..., 1/12, 1/24
M
24
(X
t
) =
1
24
[X
t6
+ 2X
t5
+ 2X
t4
+ ... + 2X
t+5
+ X
t+6
] .
55
Comme nous le verrons par la suite, elle limine les saisonnalits annuelles des sries
mensuelles, elle conserve les tendances linaires, et elle rduit de plus de 90% la variance
dun bruit blanc.
L encore, sur la srie a7
> autoroute=read.table(
+ "http://freakonometrics.blog.free.fr/public/data/autoroute.csv",
+ header=TRUE,sep=";")
> a7=autoroute$a007
> X=ts(a7,start = c(1989, 9), frequency = 12)
> plot(X)
> p=3
> Y=filter(X,filter=c(1/(2*p),rep(1/p,p-1),1/(2*p)))
> lines(Y,col="red",lwd=2)
> p=6
> Y=filter(X,filter=c(1/(2*p),rep(1/p,p-1),1/(2*p)))
> lines(Y,col="blue",lwd=2)
> p=12
> Y=filter(X,filter=c(1/(2*p),rep(1/p,p-1),1/(2*p)))
> lines(Y,col="green",lwd=2)
Exemple 63. La moyenne mobile 3 3 - Cette moyenne mobile est dordre 5 et de
coecients 1/9, 2/9, 3/9, 2/9, 1/9
M
33
(X
t
) =
1
9
[X
t2
+ 2X
t1
+ 3X
t
+ 2X
t+1
+ X
t+2
] .
Exemple 64. La moyenne mobile 3 9 - Cette moyenne mobile est dordre 11 et de
coecients 1/27, 2/27, 3/27, 3/27, ..., 3/27, 2/27, 1/27
M
39
(X
t
) =
1
27
[X
t5
+ 2X
t4
+ 3X
t3
+ 3X
t2
+ 3X
t1
+ ... + 3X
t+4
+ 2X
t+4
+ X
t+5
] .
Ces deux moyennes mobiles conservent les droites, et rduisent respectivement de 75% et
de 90% la variance dun bruit blanc.
56
Exemple 65. Les moyennes mobiles dHenderson - Ces moyennes mobiles sont util-
ises dans la mthode X11 pour extraire la tendance dune estimation de la srie corrige
des variations saisonnires (partie (4.4.2)). Ces moyennes reposent sur lutilisation de
loprateur H =
[
3
i
]
2
o est loprateur dirence premire (X
t
= X
t
X
t1
).
Cette quantit est nulle dans le cas o les
i
se retrouvent sur une parabole : H mesure la
distance entre la forme parabolique et la forme de la fonction dnissant les
i
. Hender-
sen a cherch les moyennes mobiles centres, dordre impair, conservant les polynmes de
degr 2, et minimisant la fonction H :
min
2
sous constraintes
+p
i=p
i
= 1,
+p
i=p
i
i
= 0 et
+p
i=p
i
2
i
= 0,
ce qui donne les expressions explicites de
i
, en posant n = p + 2
i
=
315
_
(n 1)
2
i
2
[n
2
i
2
]
_
(n + 1)
2
i
2
[3n
2
16 11i
2
]
8n(n
2
1) (4n
2
1) (4n
2
9) (4n
2
25)
.
Cette relation permet dobtenir un certain nombre de moyennes mobiles
5 termes : M
5
(X
t
) =
1
286
[21X
t2
+ 84X
t1
+ 160X
t
+ 84X
t+1
21X
t+2
] ,
7 termes : M
7
(X
t
) =
1
715
[42X
t3
+ 42X
t2
+ 210X
t1
+ 295X
t
+ 210X
t+1
+ 42X
t+2
42X
t+3
] .
4.1.3 Lespace des oprateurs moyenne-mobile
Dnition 66. Soient M
1
et M
2
deux moyennes mobiles. Le produit de M
1
et M
2
est
obtenu par composition des moyennes mobiles
M
1
M
2
(X
t
) = M
1
M
2
(X
t
) .
Proposition 67. Ce produit est commutatif et associatif
M
1
M
2
= M
2
M
1
et M
1
(M
2
M
3
) = (M
1
M
2
) M
3
.
De plus, le produit est distributif par rapport laddition.
Proposition 68. Lensemble des moyennes mobiles constitue un espace vectoriel.
Proposition 69. La compose de deux moyennes mobiles symtriques est symtrique.
4.2 Vecteurs propres associs une moyenne mobile
Dnition 70. Soit M une moyenne mobile. Sil existe et (X
t
) non nul tels que
M (X
t
) = X
t
, (X
t
) sera vecteur propre associ la valeur propre .
57
4.2.1 Les sries absorbes : = 0
Dnition 71. Une suite (X
t
) est dite absorbe par M si et seulement si M (X
t
) = 0
pour tout t.
Exemple 72. Soit M la moyenne mobile dnie par M (X
t
) = X
t
+ X
t1
+ X
t2
. La
srie chronologique dnie rcursivement par Y
t
= [Y
t1
+ Y
t2
] est absorbe par M.
Proposition 73. Les vecteurs propres associs la valeur propre = 0 forment un
espace vectoriel de dimension m
1
+m
2
, dont une base est constitue des Z
k
t
= (
k
r
t
) pour
k = 0, 1, ..., p 1, o r est racine non nulle du polynme .
Exemple 74. Dans lexemple (72), on peut chercher construire une base de la forme
Z
t
= r
t
, qui devra satisfaire
r
t
+ r
t1
+ r
t2
= 0 pour tout t
cest dire r
2
+ r + 1 = 0. Aussi, r est une racine du polynme caractristique de M si
et seulement si
r =
1 i
3
2
soient r
1
= exp
_
2i
3
_
et r
2
= exp
_
2i
3
_
Aussi, les suites absorbes sont ncessairement de la forme
X
t
= r
t
1
+ r
t
2
, pour tout t.
Or
_
r
t
1
= cos (2t/3) + i sin (2t/3)
r
t
2
= cos (2t/3) i sin (2t/3) .
Et donc, lespace vectoriel des suites absorbes par M admet pour base relle
B =
_
cos
_
2t
3
_
, sin
_
2t
3
__
,
ce qui correspond des sries chronologiques de la forme
X
t
= cos
_
2t
3
_
+ sin
_
2t
3
_
pour tout t.
4.2.2 Absorbtion de la composante saisonnire
Thorme 75. Une moyenne mobile M absorbe la composante saisonnire de priode T
si et seulement si son polynme caractristique est divisible par 1 + z + ... + z
T1
.
Proof. Par dnition de la priodicit des composantes saisonnires, si T est la priode,
les S
t
sont les suites solutions de
S
t+1
+ ... + S
t+T
= 0 pour tout t Z
Lespace vectoriel des solutions est engendr par les suites (r
t
) o r satisfait
1 + r + r
2
+ ... + r
T1
= 0, cest dire r = exp
_
2ik
T
_
o k = 1, ..., T 1
58
4.2.3 Les sries invariantes : = 1
Dnition 76. Une suite (X
t
) est dite invariante par M si et seulement si M (X
t
) = 0
pour tout t
Une suite (X
t
) est dite invariante par M si elle est absorbe par (M I) .
Proposition 77. (i) Les suites constantes sont invariantes par M si et seulement si la
somme de ses coecients vaut 1,
(ii) Les polynmes de degr k sont invariantes par M si et seulement si 1 est racine
dordre au moins k + 1 de = (z) z
m
1
,, o M = L
m
1
(F) ,
(iii) Si M est symtrique et conserve les constantes, alors M conserve les polynmes
de degr 1.
Proof. En reprenant (10) , on peut crire
M =
m
2
i=m
1
i
L
i
= L
m
1
(F) .
(i) Si x
t
= k ,= 0 pour tout t, alors Mx
t
= x
t
(suite invariante) se rcrit
m
2
i=m
1
i
i
k = k,
avec k non nul, donc la somme des coecients vaut 1.
(iii) Soit X
t
la suite telle que X
t
= t. Alors
MX
t
=
m
1
(t m
1
) + ... +
m
1
(t + m
1
) = t (
m
1
+ ... +
m
1
) + m
1
(
m
1
+
m
1
)
+(m
1
1) (
m
1
+1
+
m
1
1
) + ... + 1. (
1
+
1
) + 0.
0
,
soit MX
t
= t.1 + 0 = t = X
t
par symtrie (
k
=
k
).
Les proprits (i) et (iii) montrent dans quel cas la tendance de la srie reste invariante
: ces sries peuvent servir enlever la composante saisonnire, pour rcuprer la tendance
linaire.
4.2.4 Transformation de suites gomtriques (r
t
)
Proposition 78. Soit M = L
m
1
(F) une moyenne mobile de polynme caractristique
. Alors toute suite (r
t
) est vecteur propre de M associ la valeur propre = r
m
1
(r) .
Proof. De (10) , on peut crire
M
_
r
t
_
=
m
2
i=m
1
i
r
t+i
= r
tm
1
m
2
i=m
1
i
r
i+m
1
= r
t
r
m
1
(r) ,
et donc M (r
t
) = r
m
1
(r) r
t
pour tout t, ce qui correspond la dnition dlments
propres.
59
Suites gometriques relles Si r est rel alors lapplication dune moyenne mobile
la suite gomtrique (r
t
) revient faire une homothtie de rapport r
m
1
(r).
Suites gomtriques complexes Si r = e
i
alors appliquer M revient multiplier
r
t
par le nombre complexe r
m
1
(r) = () e
i()
,
_
r
t
=
t
e
it
Mr
t
=
t
e
it
() e
i()
= [()
t
] e
i[t+()]
,
ce qui correspond un eet dchelle (le module faisant intervenir le coecient ())
comme dans le cas rel, mais aussi un eet de phase puisque largument se voit ajouter
un lment ().
Exemple 79. Une suite de la forme
t
sin t sera transforme par M en
[()
t
] sin [t + ()], xxx
Proposition 80. Si M est symtrique, alors leet de phase sur la suite gomtrique
(e
it
) est soit = 0 soit = .
Proof. Ce rsultat se montre en explicitant M (e
it
) et en notant que
m
k=m
|j|
e
ik
est
rel. Si ce rel est positif, alors = 0 et sil est ngatif = .
Remarque 81. Ce rsultat ne marche que pour la suite gomtrique (e
it
) et devient faux
pour ,= 1, mme pour une moyenne mobile symtrique.
4.2.5 Moyenne mobile dirence
p
= (I L)
p
Considrons comme moyenne mobile loprateur dirence
p
= (I L)
p
pour p > 0.
Cette moyenne mobile transforme un polynme de degr k p en une constante. En eet,
appliquer
1
revient abaisser le degr du polynme de 1, car
1
_
t
k
_
= t
k
(t 1)
k
,
polynme de degr k 1, et recursivement, appliquer
p
=
p
1
revient abaisser le degr
du polynme de p.
Une telle moyenne mobile permet dliminer une tendance qui serait un plynome de
bas degr. Nous allons tudier ici son eet sur une suite de la forme (e
it
).
Cas p = 1
(I L)
_
e
it
_
= e
it
e
i(t1)
= e
it
_
1 e
i
= e
i
.2 sin
2
.e
i[]/2
soit () =
1
() = 2 sin (/2) et () =
1
() = [ ] /2.
Cas p 1
p
= (I L)
p
=
p
j=0
_
j
p
_
(1)
j
L
j
60
donc
p
_
e
it
_
=
p
j=0
_
j
p
_
(1)
j
e
ij
= e
it
_
1 e
i
p
= e
it
.2
p
_
sin
2
_
p
e
ip[]/2
soit () =
p
() = [2 sin (/2)]
p
et () =
p
() = p [ ] /2 o [0, ]
Exemple 82. Considrons la srie de cycle /3
X
t
2 1 1 2 1 1 2 1 1 2 1 1
1
X
t
1 1 2 1 1 2 1 1 2 1 1 2
2
X
t
1 2 1 1 2 1 1 2 1 1 2 1
3
X
t
2 1 1 2 1 1 2 1 1 2 1 1
4
X
t
1 1 2 1 1 2 1 1 2 1 1 2
5
X
t
1 2 1 1 2 1 1 2 1 1 2 1
Comme on peut le noter, suite ne change pas damplitude, elle est juste dphase.
Exemple 83. Considrons la srie de cycle /2
X
t
1 0 1 0 1 0 1 0 1 0 1 0
1
X
t
1 1 1 1 1 1 1 1 1 1 1 1
2
X
t
0 2 0 2 0 2 0 2 0 2 0 2
3
X
t
2 2 2 2 2 2 2 2 2 2 2 2
4
X
t
4 0 4 0 4 0 4 0 4 0 4 0
5
X
t
4 4 4 4 4 4 4 4 4 4 4 4
On retrouve l aussi un dphage, avec un coecient damplitude qui augmente avec p.
On peut ainsi noter que
4
X
t
correspond 4 fois la srie initiale X
t
, avec un dphasage
puisque les valeurs positives deviennent ngatives, et inversement.
4.2.6 Moyenne mobile dirence saisonnire
p,s
= (I L
s
)
p
Cette moyenne mobile permet dabsorber les composantes saisonnires de priode s.
p,s
_
e
it
_
= e
it
_
1 e
isp
,
alors
_
p,s
() = 2
p
[sin s/2]
p
p,s
() = p [ s] /2.
En considrant des donnes mensuelles, et une composante saisonnire annuelle (priode
12) et s = 12, alors
p,12
(2/12) = 0. On retrouve ainsi le fait que cette moyenne mobile
p,12
limine une composante saisonnire de priode 12. Toutefois, les saisonnalits de
priodes 8 mois, ou 24 mois sont amplies.
61
4.2.7 Moyenne mobile impaire
Une moyenne mobile dordre impair peut scrire
M =
q
j=q
j
L
j
o q N0 et
j
=
1
2q + 1
.
On peut montrer que
M
_
e
it
_
= e
it
sin [(q + 1/2) ]
(2q + 1) sin [/2]
,
(dmonstration en exercice) do
() =
sin [(q + 1/2) ]
(2q + 1) sin [/2]
.
La moyenne mobile tant symtrique, le dphasage est 0 ou (selon les valeurs de ).
4.2.8 Moyenne mobile paire
Une moyenne mobile dite dordre impair peut scrire
M =
q
j=q
j
L
j
o q N0 et
j
=
_
1/2q pour [j[ , = q
1/4q sinon.
On peut montrer que
M
_
e
it
_
= e
it
sin [q]
2q
cotan
_
2
_
,
(dmonstration en exercice) do
() =
sin [q]
2q
cotan
_
2
_
.
Pour des donnes mensuelles, par example, on prend q = 6, et
() =
sin [6]
12
cotan
_
2
_
,
qui sannule en /6, 2/6, 3/6, 4/6, 5/6... correspondant des priodes 12, 6, ....
Remarque 84. La moyenne mobile dordre pair avec q = 6 absorbe les composantes
saisonnires priodiques de priodes 12 (et les harmoniques), tout en conservant les basses
frquences (correspondant la tendance). Cette moyenne mobile est appele M
212
dans
la partie (4.4.2) sur la mthode X11.
62
4.3 Notions de bruit blanc
De la mme faon que pour la notion de stabilit, il existe deux faon de dnir le bruit
blanc,
Dnition 85. On appelera bruit blanc faible toute suite (
t
, t Z) telle que E(
t
) = 0
et V (
t
) =
2
pour tout t Z et tel que
(h) = cov (
t
,
th
) = 0 pour h ,= 0.
Dnition 86. On appelera bruit blanc fort toute suite (
t
, t Z) telle que (
t
) soit
i.i.d.
Remarque 87. On notera par la suite (
t
) BB(0,
2
) pour bruit blanc faible.
4.3.1 Transformation dun bruit blanc
Proposition 88. Soit M la moyenne mobile dnie par (10) et (
t
) BB(0,
2
) pour
t Z. Le processus X
t
= M (
t
) est stationnaire, centr (E(X
t
) = 0), tel que
X
(h) z
h
=
2
M (z) M
_
1
z
_
o M (z) =
m
2
i=m
1
i
z
i
pour z ,= 0.
Proof. Le caractre centr dcoule de lcriture
X
t
=
m
2
j=m
1
t+j
, o (
t
) est centr.
Il est possible de prolonger cette somme sur Z en posant
j
= 0 pour j < m
1
ou j > m
2
.
Aussi
X
t
X
t+h
=
+
j=
t+j
+
k=
t+h+k
=
2
+
j,k=
t+j
t+h+k
,
et donc
E(X
t
X
t+h
) =
2
+
k+h=j
k
=
2
+
j=
j
j h.
Ainsi E(X
t
X
t+h
) = cov (
t
,
t+h
) qui ne dpend que de h.
On peut alors crire
X
(h) z
h
=
2
+
h=
+
j=
jh
z
h
=
2
+
h=
+
j=
jh
z
j
z
hj
=
2
+
j=
j
z
j
+
h=
jh
z
hj
=
2
+
j=
j
z
j
+
i=
i
1
z
i
,
en eectuant le changement dindice i = j h.
63
A retenir 89. Le but des moyennes mobiles est
(i) dabsorber les composantes saisonnires en laissant invariantes les tendances,
(ii) de rduire la variance des perturbations.
Dnition 90. Lindice de rduction de la moyenne mobile M est donn par
=
E(MX
2
t
)
E(X
2
t
)
=
2
j
.
Exemple 91. Dans le cas dune moyenne mobile dnie par M (X
t
) = [X
t
+ X
t1
] /2,
alors = 1/2.
4.4 Les procdures X11 et X12
4.4.1 Un algorithme simple de dsaisonnalisation
Considrons une srie mensuelle X
t
compose dune tendance Z
t
, dun cycle saisonnier
S
t
, et dune perturbation
t
, de faon additive X
t
= Z
t
+S
t
+
t
.Lalgorithme suivant, en
4 tapes, permet de dsaisonnaliser la srie X
t
(1) Estimation de la tendance par moyenne mobile Z
(1)
t
= M (X
t
) ,o la moyenne
mobile M est choisie de faon reproduire au mieux la tendance, tout en liminant la
composante saisonnire, et en rduisant la perturbation au maximum
(2) Estimation de la composante saisonnire et de la perturbation
t
= S
t
+
t
:
(1)
t
= X
t
Z
(1)
t
,
(3) Estimation de la composante saisonnire par moyenne mobile S
(1)
t
= M
(1)
t
_
et
(1)
t
=
(1)
t
S
(1)
t
. Il sagit ici de lisser les valeurs de la composante
t
de chaque mois
pour extraire lvolution du coecient saisonnier du mois concern. La moyenne mobile
M
utilise ici devra reproduire la composante saisonnire de chaque mois en rduisant
au maximum la composante irrgulire. Une contrainte de normalisation des coecients
devra tre impose (somme nulle).
(4) Estimation de la srie corrige des variations saisonnires
X
t
=
_
Z
(1)
t
+
(1)
t
_
=
X
t
S
(1)
t
.
La dicult ici est donc de bien choisir les deux moyennes mobiles utiliser M et M
.
4.4.2 Lalgorithme de base de la mthode X11
Cette mthode propose deux moyennes mobiles dans le cas de donnes mensuelles.
Lalgorithme devient
(1) Estimation de la tendance-par moyenne mobile 2 12
Z
(1)
t
= M
212
(X
t
) ,
Cette moyenne mobile est paire, avec q = 6. Aussi, les 13 coecients sont
1/24, 1/12, 1/12, ..., 1/12, 1/24. Cette moyenne mobile conserve les tendances linaires,
limine les saisonnalits dordre 12 et minimise la variance de la perturbation.
64
(2) Estimation de la composante saisonnire et de la perturbation
t
= S
t
+
t
(1)
t
= X
t
Z
(1)
t
,
(3) Estimation de la composante saisonnire par moyenne mobile 3 3 sur chaque
mois
S
(1)
t
= M
33
_
(1)
t
_
et
(1)
t
=
(1)
t
S
(1)
t
.
La moyenne mobile utilise ici est une moyenne mobile sur 5 termes, dite 3 3, dont
les coecients sont 1/9, 2/9, 3/9, 2/9, 1/9, qui conserve les composantes linaires. Les
coecients sont alors normaliss de telle sorte que leur somme, sur toute une priode de
12 mois, soit nulle.
S
(1)
t
= S
(1)
t
M
212
_
S
(1)
t
_
,
(4) Estimation de la srie corrige des variations saisonnires
X
(1)
t
= X
t
S
(1)
t
.
Cette premire estimation de la srie corrige des variations saisonnires doit, par con-
struction, contenir moins de saisonnalit.
(5) Estimation de la tendance par moyenne mobile de Henderson sur 13 termes
Z
(2)
t
= M
13
_
X
t
_
.
Si les moyennes mobiles dHenderson nont pas de proprits spciales quant
llimination de la saisonnalit, mais elles lissent relativement bien, tout en conservant
(localement) les polynmes dordre 2.
(6) Estimation de la composante saisonnire et de la perturbation
t
(2)
t
= X
t
Z
(2)
t
,
(7) Estimation de la composante saisonnire par moyenne mobile 3 5 sur chaque
mois
S
(2)
t
= M
35
_
(2)
t
_
et
(2)
t
=
(2)
t
S
(2)
t
.
La moyenne mobile utilise ici est une moyenne mobile sur 7 termes, dite 3 5, dont
les coecients sont 1/15, 2/15, 3/15, 3/15, 3/15, 2/15, 1/15, qui conserve les composantes
linaires. Les coecients sont alors normaliss de telle sorte que leur somme, sur toute
une priode de 12 mois, soit nulle.
S
(2)
t
= S
(2)
t
M
212
_
S
(2)
t
_
,
(8) Estimation de la srie corrige des variations saisonnires
X
(2)
t
= X
t
S
(2)
t
.
65
Remarque 92. Cette mthode permet de reprer les points abrants dune srie.
Comme lont montr Gouriroux et Monfort (1990), cet algorithme peut se rsumer
lapplication dun unique moyenne mobile qui peut tre explicite matriciellement. Les 8
points de lalgorithme scrivent
(1) Z
(1)
t
= M
212
(X
t
)
(2)
(1)
t
= X
t
Z
(1)
t
= (I M
212
) (X
t
)
(3) S
(1)
t
= M
33
_
(1)
t
_
= M
(3)
(I M
212
) (X
t
)
S
(1)
t
= S
(1)
t
M
212
_
S
(1)
t
_
= M
(3)
(I M
212
)
2
(X
t
)
(4)
X
(1)
t
= X
t
S
(1)
t
=
_
I M
(3)
(I M
212
)
2
_
(X
t
)
(5) Z
(2)
t
= M
13
_
X
t
_
= M
13
_
I M
(3)
(I M
212
)
2
_
(X
t
)
(6)
(2)
t
= X
t
Z
(2)
t
=
_
I
_
I M
(3)
(I M
212
)
2
__
(X
t
)
(7)
S
(2)
t
= S
(2)
t
M
212
_
S
(2)
t
_
= (I M
212
) M
(5)
_
I M
(3)
(I M
212
)
2
_
(X
t
)
(8)
X
(2)
t
= X
t
S
(2)
t
=
_
I(I M
212
) M
(5)
_
I M
(3)
(I M
212
)
2
__
(X
t
)
o M
(3)
est la moyenne mobile dnie sur 49 mois, dont les coecients sont
1/9, 0, 0, ..., 0, 2/9, 0, ...., 0, 3/9
et M
(5)
est la moyenne mobile dnie sur 73 mois, dont les coecients sont
1/27, 0, 0, ..., 0, 2/27, 0, ...., 0, 3/27, 0, 0, ..., 0, 3/27
La moyenne mobile ainsi dnie est dordre 169, cest dire quen toute rigueur, il
faudrait 84 observations, soit 7 ans de part et dautre pour pouvoir estimer ce ltre.
Remarque 93. Un algorithme similaire existe pour des donnes trimestrielles, qui peut
l aussi scrire sous la forme dune seule moyenne mobile, portant sur 28 trimestres de
part et dautre (7 ans l aussi).
66
5 La prvision par lissage exponentiel
Les mthodes de lissages consistent extrapoler une srie en vue de faire de la prvi-
sion. Or comme on le voit sur lexemple ci-dessous, une extrapolation simple (linaire en
loccurence) dpend fortement du type de rsultats que lon cherche avoir : prvision
court, moyen, ou long terme Ces trois mthodes dirent suivant le poids que lon accorde
aux observations passes.
5.1 Principe du lissage exponentiel simple
On dispose de N observations X
1
, ..., X
N
. On souhaite prvoir, la date T = 1, ..., N, la
valeur un horizon 1, ou un horizon quelconque h.
Dnition 94. La prvision
X
T
(h) fournie par la mthode de lissage exponentiel simple,
avec la constante de lissage , 0 < < 1 est
X
T
(h) = (1 )
T1
j=0
j
X
Tj
On donne un poids dautant moins important que les observations sont loins (dans le
pass), avec une dcroissance exponentielle :
- proche de 1 : prise en compte de tout le pass
- proche de 0 : prise en compte davantage des valeurs rcentes (plus sensible aux
uctuations)
Remarque 95. Si ne dpend pas de h,
X
T
(h) ne dpend pas de h, dont
X
T
(h) =
X
T
.
Cette valeur
X
T
est la prvision faite en T de la valeur en T + 1. Nous appelerons cette
srie
X
T
(srie lisse la date t) ou F
T+1
(valeur prdite pour la date T + 1).
Remarque 96. Pour certains logiciels permettant de faire du lissage exponentiel, la con-
stante de lissage nest pas mais = 1 .
5.1.1 Mthode adaptative de mise jour (ordre 1)
Proposition 97. Mthode adaptative de mise jour (ordre 1)
X
T
=
X
T1
+ [1 ]
_
X
T
X
T1
_
(11)
= [1 ] X
T
+
X
T1
= X
T
+ [1 ]
X
T1
Cette relation scrit galement
F
T+1
= X
T
+ (1 ) F
T
Proposition 98.
X
T
peut tre vu comme une rgression sur une constante, avec des
pondrations exponentielles
67
Proof. Le programme de minimisation
min
c
_
T1
j=0
j
(X
tj
c)
2
_
(12)
admet pour solution
c =
1
1
T
T1
j=0
j
X
Tj
(13)
et pour T assez grand
X
T
= c.
5.1.2 Choix de la constante de lissage
Au del des mthodes qualitative de rigidit ou de souplesse du modle aux uctuations
conjoncturelles, il est possible dutiliser des mthodes de type minimisation de la somme
des carrs des erreurs de prvison :
= arg min
_
_
_
T
t=1
_
X
t+1
(1 )
t1
j=0
j
X
tj
_
2
_
_
_
Numiquement, il est possible de calculer cette quantit en utilisant
> V=function(a){
+ T=length(X)
+ L=erreur=rep(NA,T)
+ erreur[1]=0
+ L[1]=X[1]
+ for(t in 2:T){
+ L[t]=a*X[t]+(1-a)*L[t-1]
+ erreur[t]=X[t]-L[t-1] }
+ return(sum(erreur^2))
+ }
> optimize(V,c(0,.5))$minimum
Par exemple, sur la srie Nile on aurait
> optimize(V,c(0,.5))$minimum
[1] 0.246581
> A=seq(0,1,by=.02)
> Ax=Vectorize(V)(A)
> plot(A,Ax,ylim=c(min(Ax),min(Ax)*1.05))
68
> hw=HoltWinters(X,beta=FALSE,gamma=FALSE,l.start=X[1])
> hw
Holt-Winters exponential smoothing without trend an seasonal comp.
Call:
HoltWinters(x = X, beta = FALSE, gamma = FALSE, l.start = X[1])
Smoothing parameters:
alpha: 0.2465579
beta : FALSE
gamma: FALSE
Coefficients:
[,1]
a 805.0389
> plot(hw)
> points(2:(length(X)+1),Vectorize(Lissage)(.2465),col="blue")
5.1.3 Lien entre robustesse de la prvision et choix de
Il nexiste pas de relation a priori entre lerreur de prvision et le paramtre .
Exemple 99. Soit (X
t
) un processus AR(1) de corrlation , de variance 1, X
t
= X
t1
+
t
. Lerreur de prvision horizon h est
(, , h) = E
_
_
X
T+h
X
T
(h)
_
2
_
avec
X
T
(h) = (1 )
T1
j=0
j
X
Tj
On peut montrer que
(, , h) =
2
1 +
+
2 (1 )
_
h
h
_
(1 + ) (1 )
Lerreur de prvision varie de la faon suivante en fonction de
xx
pour < 1/3, lerreur de prvision dcroit avec , et pour > 1/3, lerreur crot avec
.
69
5.1.4 Exemple dapplication
Considrons ici une srie de ventes dune entreprise, sur 18 mois
JAN FEB MAR APR MAY JUN JUL AUG SEP OCT NOV DEC
C.A. 98 1293 1209 1205 1273 1220 1290 1243 1203 1390 1360 1353 1343
C.A. 99 1364 1330 1377 1332
En septembre, une modication structurelle (nouvelle unit de production) a provoqu un
saut des ventes. Les mthodes de lissage permettent defectuer de la prvision en intgrant
ce genre de rupture. Une moyenne arithmtique (non-pondre, note y) conduirait sous-
estimer les valeurs futures : il est alors naturel dintroduire des poids plus importants pour
les valeurs rcentes. La prvision horizon 1 est alors
y
T
(1) =
1
T
T1
i=0
y
Ti
et y
T
(1) =
T1
i=0
[1 ]
i
y
Ti
=
T1
i=0
[1 ]
i
y
Ti
pour , ]0, 1[ et = 1
cette dernire valeur tant obtenue par lissage exponentiel (simple). Nous noterons ici
y
1
, ..., y
T
la srie lisse, et F
1
, ..., F
T
la srie des valeurs prdites.
Mise en place de lalgorithme ( x) Pour la premire valeur (T = 0), on considre
comme valeur initiale une moyenne des premires valeurs observes. EViews considre une
moyenne sur les 8 premiers mois,
F
1
= y
0
=
1
8
(1293 + ... + 1203) = 1242
Pour construire la srie lisse, x, on utilise la relation de mise jour
y
j
= y
j
+ (1 ) y
j1
ou F
j+1
= y
j
+ (1 ) F
j
Avec comme constante de lissage = 0.3, on obtient
F
2
= y
1
= y
1
+ (1 ) F
1
= 0.3 1293 + 0.7 1242 = 1257.3
puis
F
3
= y
2
+ (1 ) F
2
= 0.3 1209 + 0.7 1257.3 = 1242.81
Comme on peut le voir, nous estimation pour la date 2 tait de 1257.3. Or la vraie valeur
tait plus faible, savoir 1209. Aussi, pour la date 3, la prvision sera une correction de
ce 1257.3 en prenant en compte (avec un poids correspondant la valeur ) lerreur qui
avait t faite : en loccurence, F
3
sera plus faible que F
2
(la dirence tant [F
2
y
2
])
y
j1
F
j1
F
j
1 1293 1242.00
2 1209 1242.00 1257.30
3 1205 1257.30 1242.81
4 1273 1242.81 1231.47
5 1220 1231.47 1243.93
70
(puisque F
j
= y
j1
+(1 ) F
j1
) do nallement la srie lisse exponentiellement pour
1998
JAN FEB MAR APR MAY JUN JUL AUG SEP OCT NOV DEC
y
j
1293 1209 1205 1273 1220 1290 1243 1203 1390 1360 1353 1343
y
j
( = 0.3) 1242 1257 1243 1231 1244 1237 1253 1250 1236 1282 1305 1320
y
j
( = 0.7) 1242 1278 1230 1212 1255 1230 1272 1252 1218 1338 1353 1353
On peut noter que plus est proche de 1, plus la courbe lisse colle aux donnes ( y
j
est proche de y
j
) : pour = 1, la prvision F
j+1
sera la dernire valeur observe (y
j
).
Un coecient de lissage plus faible (par exemple = 0.3) permet en revanche de bien
lisser les alas importants de la srie. La srie lisse sadapte galement au changement de
niveau observ en septembre. Toutefois, cette adaptation se fait dautant plus lentement
que est faible : les prvisions sont alors biaises (sous-estimation dans cet exemple)
pendant la priode dadaptation, comme on peut le voir sur le graphique ci-dessous : ds
octobre 1998, la prvision faite avec un coecient de 0.7 avait atteint un niveau correct,
alors que la prvision avec une pondration de 0.3 est plus lente (ce qui rend la prvision
moins sensible un choc exogne : si cette variation en septembre navait t quun choc,
une faible pondration aurait permis de ne pas le prendre en compte).
On peut noter que le lissage dpend non seulement de mais aussi de la valeur
initale choisie. Comme le montre le graphique de gauche, on observe une convergence
(asymptotique), avec des valeurs trs proches pour T proche de 16. En choissant une
valeur intiale proche des premires valeurs de la srie ( y
0
= y
1
ou y
0
moyenne des 2 ou
3 premires observations), on saperoit que la courbe observe et les courbes lisse sont
quasiment confondues au bout de 10 mois (cette valeur dpendant de : la convergence
est dautant plus rapide que est grand). Le graphique ci-dessous correspond plusieurs
initialisations : F
1
= y
1
(prvision parfaite - (1)), F
1
= (y
1
+ y
2
) /2 (moyenne des deux
premires valeurs - (2)), F
1
= (y
1
+ y
2
+ y
3
) /2 (moyenne des trois premires valeurs -
(3)) et F
1
= (y
1
+ ... + y
n
) /n (moyenne de lchantillon - (4))
Remarque 100. Il convient de faire attention : dans la littrature, les courbes lisses sont
soit F
t
, soit y
t1
. Certains auteurs dcallent ainsi (dans les tableaux ou les graphiques) la
courbe lisse.
A retenir 101. La formule itrative pour construire la srie lisse de X
t
pour t = 1, ..., N
est la suivante
_
_
_
F
0
= X
1
ou [X
1
+ ... + X
p
] /p
F
t+1
= X
t
+ (1 ) F
t
pour 0 t N
F
t
= F
N+1
pour t N + 1
Choix de la constante de lissage Ce choix peut relever de considrations empiriques :
des fortes pondrations pour les valeurs rcentes ( lev) donne de meilleures prvisions
court terme qu long terme. Toutefois, une des mthodes les plus utilise est la minisation
des moindres carrs des erreurs (prvision/ralisation) un horizon h = 1. Lalgorithme
(13) donne ici un paramtre = 0.418, qui correspond une somme des erreurs de
prvision de 48178, cest dire un cart type de lerreur valant 54.874.
71
Remarque 102. Lintervalle de conance de la prvision est alors de la forme
X
T
(h)1.96
X
C
h
o C
2
h
= 1+
1
(1 + )
3
__
1 + 4 + 5
2
_
+ 2h(1 ) (1 + 3) + 2h
2
(1 )
2
5.2 Principe de lissage exponentiel double
Le lissage exponentiel simple est adapt des sries pouvant tre ajuste par une constante
au voisnage de T. Le principe de lissage exponentiel double permet de faire un ajustement
par une droite, savoir approcher X
t
par Y
t
o
Y
t
= A + (t T) B
La prvision horizon h scrit
F
T+h
=
X
T
(h) =
A(T) + h
B(T)
De mme que pour (12) le programme doptimisation pour estimer A et B scrit
min
A,B
_
T1
j=0
j
(X
Tj
[A + (T j) B])
2
_
(14)
Thorme 103. La solution de (14) est donne par
A(T) = 2S
1
(T) S
2
(T) et
B(T) =
1
[S
1
(T) S
2
(T)]
en posant
S
1
(t) = (1 )
t1
k=0
k
X
tk
= (1 ) X
t
+ S
1
(t 1) (srie lisse)
S
2
(t) = (1 )
t1
k=0
k
S
1
(t k) = (1 ) S
1
(t) + S
2
(t 1) (srie lisse 2 fois)
= (1 )
2
t1
k=0
tk1
i=0
i+k
X
t(k+i)
Proof. Gouriroux et Monfort (1995) pages 110-111
72
5.2.1 Mthode adaptative de mise jour (ordre 1)
Pour obtenir la formule de mise jour ( lordre 1) permettant de passer de T T + 1,
on peut utiliser le rsultat suivant
Proposition 104. Si la date T, F
T+1
=
X
T
(1) =
A(T) +
B(T), alors, en T + 1
_
_
_
A(T + 1) = (1
2
)
_
X
T+1
X
T
(1)
_
+
A(T) +
B(T)
B(T + 1) =
B(T) + (1
2
)
_
X
T+1
X
T
(1)
_
(15)
Proof. Gouriroux et Monfort (1995) pages 112-113
Dans le cas dune prvision parfaite, i.e. X
T+1
=
X
T
(1), on aurait
A(T + 1) =
A(T) +
B(T) et
B(T + 1) =
B(T)
Dans ce cas, les droites de prvision en T et en T + 1 sont les mmes, et la pente, en
particulier, est inchange (
B(T + 1) =
B(T)).
Remarque 105. Lintervalle de conance de la prvision est alors de la forme
X
T
(h) 1.96
X
2
2 1
5.2.2 Application de la mthode de lissage exponentiel double
Considrons la srie suivante, correspondant un indice dactivit
Trim 1 Trim 2 Trim 3 Trim 4
1982 9050 9380 9378
1983 9680 10100 10160 10469
1984 10738 10910 11058 11016
1985 10869 11034 11135 10845
1986 11108 11115 11424 10895
1987 11437 11352 11381 11401
1988 11507 11453 11561
Le lissage exponentiel double est trs proche du lissage exponentiel simple, sauf que lon
fait un ajustement au voisinage de T non plus par une constante, mais par une droite.
En fait, la srie (correspondant un indice) est une srie croissante : lajustement par
lissage exponentiel simple sous-estimerait les valeurs ralises (graphique page ??) . Le
programme de minimisation scrit ici
min
A,B
_
T1
j=0
j
(X
tj
[A
T
+ B
T
(T j)])
2
_
73
La prvision horizon h est alors y
T
(h) = A
T
+ B
T
h. Trois formulations sont possibles
pour crire la srie lisse
Formulation classique - Les coecients A
j
et B
j
sont donns par
A
j
= 2 y
1
j
y
2
j
et B
j
=
1
_
y
1
j
y
2
j
o les y
1
j
et y
2
j
sont obtenus rcursivement par deux lissages conscutifs,
_
y
1
j
= y
j
+ (1 ) y
1
j1
: lissage exponentiel simple de y
i
y
2
j
= y
1
j
+ (1 ) y
2
j1
: lissage exponentiel simple de y
1
i
Formules de lissage direct - lerreur de lissage e
j
est donne par e
j
= y
j
y
j
=
y
j
[A
j1
+ B
j1
], et donc
_
A
j
= A
j1
+ B
j1
+
_
1 (1 )
2
e
j
B
j
= B
j1
+
2
e
j
ce qui donne une relation permettant dobtenir rcursivement les A
i
et les B
i
.
Formules de mise jour - cette expression est en fait la mme que la prcdente,
sauf que lon remplace lerreur de prvision par la dernire observation y
j
,
_
A
j
= y
j
+ (1 ) [A
j1
+ B
j1
]
B
j
= [A
j
A
j1
] + (1 ) B
j1
o = 1 (1 )
2
et =
2
(16)
Remarque 106. A
j
et B
j
sont unitiliss pour calculer y
j
, prvision horizon 1 faite
la date j, soit F
j+1
.
Encore une fois, linitialisation de lalgorithme est important. Une mthode possible
est de considrer comme valeur initiale pour A
1
la premire valeur y
1
. La pente B
1
peut alors tre choisie comme la pente moyenne entre la date 1 et une date t
0
, telle que
B
1
= [y
t
0
y
1
] /t
0
.
Dans le cas qui nous intresse on obtient la srie lisse suivante, en prenant comme
constante de lissage = 0.384, et comme valeurs initiales de A
0
= y
1
et B
0
la pente
sur une priode de 10 observations (soient 9050 et 177) - laide de la relation (16) , et
= 0.6205 et = 0.2376
y
j
A
j
B
j
F
j+1
1982 2 9050 9050.00 165.30 9215.30
1982 3 9380 9112.73 140.93 9253.66
1982 4 9378 9332.05 159.56 9491.61
1983 1 9680 9421.11 142.81 9563.92
74
Srie observe Srie lisse
Trim 1 Trim 2 Trim 3 Trim 4
1982 9050 9380 9378
1983 9680 10100 10160 10469
1984 10738 10910 11058 11016
1985 10869 11034 11135 10845
1986 11108 11115 11424 10895
1987 11437 11352 11381 11401
1988 11507 11453 11561
Trim 1 Trim 2 Trim 3 Trim 4
1982 9215 9254 9492
1983 9564 9796 10189 10372
1984 10646 10932 11143 11303
1985 11295 11138 11166 11234
1986 11023 11118 11159 11405
1987 11095 11364 11412 11443
1988 11461 11541 11524
A titre de comparaison, nous avons ajout droite le lissage exponentiel simple optimal
qui aurait t obtenu sur les mmes donnes. Ce lissage simple est relativement mal
adapat ce type de donnes (croissantes) puisque nous allons continuellement sous-
valuer la vraie valeur en priode de croissance forte.
Supposons que la srie ait t observe jusquau troisime trimestre de 1987. La srie
lisse jusqu cette date reste la mme, et les prvisions pour les trimestres suivant aurait
t obtenus en utilisant A = A
19873
= 11412, B = B
19873
= 47.02, et y
T
(h) = A + Bh
ralisation prvision (double) prvision (simple)
1987-4 11401 11459 11352
1988-1 11507 11506 11352
1988-2 11453 11553 11352
1988-3 11561 11600 11352
5.3 Application au trac sur lautoroute A7
> autoroute=read.table(
+ "http://freakonometrics.blog.free.fr/public/data/autoroute.csv",
+ header=TRUE,sep=";")
> a7=autoroute$a007
> X=ts(a7,start = c(1989, 9), frequency = 12)
> T=time(X)
> S=cycle(X)
> B=data.frame(x=as.vector(X),T=as.vector(T),S=as.vector(S))
> regT=lm(x~T,data=B)
> plot(X)
> abline(regT,col="red",lwd=2)
> summary(regT)
Call:
lm(formula = x ~ T, data = B)
Residuals:
Min 1Q Median 3Q Max
-20161 -10568 -2615 4390 35017
Coefficients:
Estimate Std. Error t value Pr(>|t|)
75
(Intercept) -2872401.7 1545258.4 -1.859 0.0666 .
T 1460.7 775.3 1.884 0.0631 .
---
Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 . 0.1 1
Residual standard error: 14610 on 83 degrees of freedom
Multiple R-squared: 0.04101, Adjusted R-squared: 0.02946
F-statistic: 3.55 on 1 and 83 DF, p-value: 0.06306
> B$res1=X-X1
> regS=lm(res1~0+as.factor(S),data=B)
> B$X2=predict(regS)
> plot(B$S,B$res1,xlab="saisonnalit")
76
A retenir 107. La formule itrative pour construire la srie lisse de X
t
pour t = 1, ..., N
est la suivante
_
_
S
1
0
= X
1
ou [X
1
+ ... + X
p
] /p
S
2
0
= 0
S
1
t+1
= X
t
+ (1 ) S
1
t
pour 0 t N
S
2
t+1
= S
1
t
+ (1 ) S
2
t
pour 0 t N
A
t+1
= 2S
1
t+1
S
2
t+1
pour 0 t N
B
t+1
=
_
S
1
t+1
S
2
t+1
/ (1 )
F
t+1
= A
t+1
+ B
t+1
pour 0 t N
F
t
= A
N+1
+ (t N 1) B
N+1
pour t N + 1
5.4 Lissage exponentiel multiple, ou gnralis
Cette gnralisation a t propose par Brown en 1962, permettant dajuster au voisinage
de T une fonction plus complexe quune fonction ane. La rsolution de ce problme
repose sur la notion de vecteurs de fonctions matrice de transition xe.
Dnition 108. Le vecteur f (t) = [f
1
(t) , ..., f
n
(t)]
, o t Z est dit matrice de
transition xe sil existe une matrice A rgulire telle que
f (t) = Af (t 1) pour tout t Z
La mthode du lissage exponentiel gnralis consiste ajuster au voisinage de T de
la srie X
t
une fonction (t T) de la forme
(t) =
n
i=1
i
f
i
(t) o f (.) est matrice de transition xe
Cette classe de fonction (.) comprend la plupart des fonctions usuelles.
(1) Les fonctions constantes - (t) = c, obtenues avec f (t) = 1 et A = 1. Dans ce
cas, on retrouve le principe de lissage exponentiel simple,
(2) Les fonctions linaires - (t) = + t, obtenues avec f (t) = [1, t]
de matrice
de transition
A =
_
1 0
1 1
_
puisque
_
1
t
_
=
_
1 0
1 1
_ _
1
t 1
_
Dans ce cas, on retrouve le principe de lissage exponentiel double,
(3) Les fonctions polynmiales de degr p - Cette famille est obtenue en prenant
comme base une base de R
p
(X) (espace des polynmes de degr infrieur ou gal p).
En particulier, on peut choisir la base
B
p
=
_
P
k
(t) =
1
k!
t (t 1) ... (t k + 1) , k = 1, ..., p + 1
_
obtenue laide du triangle de Pascal, et dnie par rcurence par
P
k
(t) = P
k1
(t 1) + P
k
(t 1) pour k > 1
77
Le vecteur f (t) = [P
1
(t) , ..., P
p+1
(t)] est alors de matrice de transition (xe)
A =
_
_
1 0 0 0 0
1 1 0 0 0
0 1 1 0 0
.
.
.
.
.
.
0 0 0
.
.
. 1 0
0 0 0 1 1
_
_
(4) Les fonctions sinusodales - Les fonctions (t) = sin t+ sin t sont obtenues
en prenant f (t) = [sin t, cos t]
, et dans ce cas
A =
_
cos sin
sin cos
_
(6) Les fonctions exponentielles - Les fonctions (t) = exp (t) sont obtenues
en prenant f (t) = exp (t) et dans ce cas A = exp ().
Cette mthode de lissage se met en place de la faon suivante.
De la mme faon que (14), le programme doptimisation scrit
min
a
_
T1
j=0
j
(X
tj
f
(j) a)
2
_
(17)
o la notation f
dsigne la transpose de f. Posons
x =
_
_
X
T
.
.
.
X
1
_
_
, F =
_
_
f
1
(0) f
n
(0)
.
.
.
.
.
.
f
1
(T + 1) f
n
(T + 1)
_
_
=
_
_
f
(0)
.
.
.
f
(T + 1)
_
_
et = diag
_
1, 1/, ..., 1/
T1
_
Le programme (17) correspond la regression (linaire) de x sur les colonnes de F,
associe la matrice de covariance . On en dduit que la solution (17) est unique, et
est donne par
a (T) =
_
F
1
F
_
1
F
y = [M (T)]
1
Z (T)
o
M (T) = F
1
F =
T1
j=0
j
f (j) f
(j) et Z (T) = F
y =
T1
j=0
j
f (j) X
Tj
La matrice M (T) converge vers une matrice nie M quand T + : on peut estimer
a (T) en utilisant cette matrice limite,
a (T) = M
1
Z (T) avec M (T) =
j=0
j
f (j) f
(j)
Et la prvision horizon h faite la date T est
X
T
(h) = f
(h) a (T)
78
5.4.1 Mthode adaptative de mise jour (ordre 1)
Pour cela, notons que
Z (T + 1) = X
T+1
f (0) + A
1
Z (T)
et on peut alors crire
a (T + 1) = X
T+1
M
1
f (0) + M
1
A
1
Ma (T)
que lon peut encore noter
a (T + 1) = X
T+1
+ a (T) o
_
= M
1
f (0)
= M
1
A
1
M
o les matrices et sont indpendantes de T. Cette relation peut se mettre sous la
forme suivante, proche de (11),
a (T + 1) = A
a (T) +
_
X
T+1
X
T
(1)
_
5.5 Les mthodes de Holt-Winters (1960)
5.5.1 Mthode non saisonnire
Cette mthode est une gnralisation de la mthode de lissage exponentiel mais avec un
point de vue dirent de celui introduit dans le lissage exponentiel gnralis. De la
mme faon que pour le lissage exponentiel double, lajustement se fait de faon linaire
au voinage de T, la nuance se faisant au niveau de formules de mise jour, direntes de
(15) :
_
_
_
A(T + 1) = (1 ) X
T+1
+
_
A(T) +
B(T)
_
o 0 < < 1
B(T + 1) = (1 )
_
A(T + 1)
A(T)
_
+
B(T) o 0 < < 1
(18)
La premire relation est une moyenne pondre de deux informations sur A(T), corre-
spondant au niveau de la srie la date T : lobservation X
T+1
et la prvision faite en T
(
A(T) +
B(T)). La seconde relation sinterprte comme une moyenne pondre de deux
informations sur B(T), correspondant la pente de la srie la date T : la dirence
entre les niveaux estims en T et T + 1, et la pente estime en T.
Toutefois, ces deux relations ne peuvent tre utilise quaprs initialisation, que lon
fera gnralement de la faon suivante :
A(2) = X
2
et
B(2) = X
2
X
1
. La prvision
horizon h faite la date T est donne par
X
T
(h) =
A(T) + h
B(T)
79
Cette mthode peut tre vue comme une gnralisation du lissage exponentiel double,
qui ne faisait intervenir quun coecient, (ou ). Cette dernire mthode correspond
au cas particulier
=
2
et = 1
(1 )
2
1
2
=
2
1 +
Sur lexemple prcdant, on obtient
> HW=HoltWinters(X,alpha=.2,beta=0)
> P=predict(HW,24,prediction.interval=TRUE)
> plot(HW,xlim=range(c(time(X),time(P))))
> polygon(c(time(P),rev(time(P))),c(P[,2],rev(P[,3])),
+ col="yellow",border=NA)
> lines(P[,1],col="red",lwd=3)
5.5.2 La mthode saisonnire additive
On suppose ici que la srie (X
t
) peut tre approche au voisinage de T par la srie
Y
t
= A + (t T) B + S
t
o S
t
est un facteur saisonnier. Les formules de mise jour scrire de la faon suivante,
o s est le facteur de saisonnalisation (ou le nombre de saisons : s = 4 pour des donnes
trimestrielles ou s = 12 pour des donnes mensuelles)
_
A(T + 1) = (1 ) [X
T+1
S
T+1s
] +
_
A(T) +
B(T)
_
o 0 < < 1 (lissage de la moyenne)
B(T + 1) = (1 )
_
A(T + 1)
A(T)
_
+
B(T) o 0 < < 1 (lissage de la tedance)
S
T+1
= (1 )
_
X
T+1
A(T + 1)
_
+ S
T+1s
o 0 < < 1 (lissage de la saisonnalit)
et la prvision horizon h (1 h s) scrit
X
T
(h) =
A(T) + h
B(T) +
S
T+k+s
80
La encore, le problme dinitialisation va se poser, et on peut prendre
_
A(s) = M
s
(X
1
, ..., X
s
) o M
s
est une moyenne pondre
A(s + 1) = M
s
(X
2
, ..., X
s+1
)
B(s + 1) =
A(s + 1)
A(s)
S
i
= X
i
A(i)
5.6 Exemple de mise en pratique des mthodes de lissage
Comme nous allons le voir ici, les mthodes de lissage, an de faire de la prvision,
peuvent trs facilement tre mises en oeuvre, en particulier sur des tableurs (Excel par
exemple). Nous allons voir comment faire de la prvision sur des donnes comportant de
la saisonnalit, laide des mthodes de lissage exponentiel.
5.6.1 Prsentation des donnes
Les donnes sont mensuelles, et comportent une saisonnalit annuelle,
Pour lisser cette srie, nous avons utilis une moyenne mobile permettant dannuler
une saisonnalit annuelle (priode 12) : M
212
. En particulier
MX
t
=
1
12
_
1
2
X
t6
+ X
t5
+ X
t4
+ ... + X
t
+ ... + X
t+4
+ X
t+5
+
1
2
X
t+6
_
et ainsi, sur lexemple ci-dessus, on peut noter que
2 864 431 =
1
12
_
2 797 469
2
+ 2 773 701 + 2 735 895 + ... + 2 795 698 + ... + 3 032 833 + 3 075 696 +
3 047 187
2
_
La composante saisonnire est alors obtenue comme dirence entre la srie brute X
t
et la srie dsaisonnalise MX
t
. Cette srie correspond dans le tableau ci-dessus la
variable DIFFERENCE. Par exemple,
92 401 = 3 047 187 2 954 786
On considre alors la dirence moyenne pour chaque mois :
JAN
1
=
1
2
[(X
JAN00
MX
JAN00
) + (X
JAN01
MX
JAN01
)]
FEV
2
=
1
2
[(X
FEV 00
MX
FEV 00
) + (X
FEV 01
MX
FEV 01
)]
Par exemple, la dirence moyenne pour Septembre est
9
=
1
2
(69 692 + 71 120) = 70 406
On peut noter que la somme de ces dirences moyennes
i
ne vaut pas 0 : on va alors
normaliser les
i
de faon ce que leur somme soit nulle. On considre alors
i
=
i
1
12
12
j=1
j
81
Dans lexemple considre, la somme des
i
valait 20 865 : aussi, on va dnir
i
=
i
20
865/12. Cette srie
i
va alors constituer la composante saisonnire de la srie (X
t
). Par
exemple, la saisonnalit pour le mois de mars est 62 580. Et partir de l, on construit
la srie corrige des variations saisonnires (CV S) comme dirence entre (X
t
) et la
composante saisonnire du mois correspondant.
Cest partir de cette srie corrige des variations saisonnires que lon va faire de la
prvision. La mthodologie est alors la suivante. On spare la srie initiale (X
t
) de la
faon suivante :
X
t
= Z
t
+
t
= srie CV S + composante saisonnire
et la prvision sera alors faite en considrant
X
t
=
Z
t
+
t
On extrapole la srie corrige des variations saisonnires (par lissage), et on rajoute ensuite
la composante saisonnire.
5.6.2 Lissage linaire
La mthode la plus simple pour faire de la prvision sur une srie dsaisonnalise est
dutiliser une rgression linaire,
Pour cela, on part des sries de base X
t
(srie brute) et Z
t
(srie corrige des variations
saisonnires). Les sries sur la gauche donne lapproximation linaire. Pour cela, on
rgresse la srie Z
t
sur les sries I (cest dire la constante) et t (la srie temps), et lon
obtient
APPROX. LINEAIRE : Z
t
= A + Bt +
t
avec A = 209.98, B = 4772213
et o
t
est la sries des erreurs (ERREUR)
9
. En particulier
_
2 858 914 = 4 772 213 + 209.98 36 342 (t = 36 342correspond au 1er juillet 1999)
38 382 = 2 929 423 2 891 041
La composante saisonnire (COMPOSANTE SAISONNIERE) est alors la srie
obtenue dans la partie prcdante, et combine la srie
Z
t
= A + Bt : on obtient
la premire prvision de X
t
:
X
t
= A + Bt +
t
. (colonne PREVISION (droite)). Une
mthode encore plus simple est de considrer comme ajustement de Z
t
non pas une droite
quelconque mais une constante, Z
t
= C +
t
, et la prvision de X
t
devient
X
t
= C +
t
.
(colonne PREVISION (constante)). On pourra ainsi obtenir
_
2 940 601 = 2 871 933 + 68 668 = (4 772 213 + 209.98 36 404) + 68 668
2 870 061 = 2 932 641 62 580
9
Le temps t est exprim, comme sous Excel, en nombre de jours par rapport au 1er janvier 1900.
82
5.6.3 Lissage exponentiel simple
Le lissage exponentiel simple est prsent ci dessous, appliqu la srie corrige des
variations saisonnires. Pour cela, on se xe au pralable une constante de lissage, par
exemple = 0.7. La srie lisse est alors dnie parde la faon suivante
_
_
_
S
t
= Z
t1
= 2 726 843 pour t = Feb99
S
t
= Z
t1
+ (1 ) S
t1
= 0.7 3 005 108 + (1 0.7) 2 953 724 = 2 969 139 pour t > Feb99
S
t
= S
T
pour t > T = Dec01
Lerreur saisonnire est alors toujours la srie (
t
) et la prvision est alors donne par
X
t
= S
t
+
t
, soit dans lexemple ci-dessous
3 051 423 = 2 925 143 + 126 280
5.6.4 Lissage exponentiel double
Les sries (S) et (S
) sont dnies rcursivement de la faon suivante
_
S
t
= X
t1
+ (1 ) S
t1
pour t = 2, ..., n + 1
S
t
= S
t1
+ (1 ) S
t1
pour t = 2, ..., n + 1
Les coecients A et B sont dnie par
A
t
= 2S
t
S
t
et B
t
=
1
[S
t
S
t
]
soit sur lexemple ci-dessous
A
t
= 2 2 771 987 2 746 504 = 2 797 469 et B
t
=
0.7
1 0.7
(2 882 758 2 842 769)
La srie lissage brut est donne par
A
t
+ B
t
= 2 877 040 + 18 480 = 2 895 520
La srie de la prvision est alors donne, lorsquil y a n observations, par
_
X
P
t
= A
t
+ B
t
pour t = 2, ..., n + 1
X
P
n+h
= A
n+1
+ h.B
n+1
pour h 1
83
6 Introduction aux modles linaires ARIMA
6.1 A quoi ressemblent les processus (S)ARIMA ?
6.2 Rappels sur les espaces L
2
6.2.1 Proprits topologiques
On considre le processus (X
t
) dnit sur lespace de probabilit (, /, P), valeurs dans
R.
Dnition 109. LespaceL
2
(, /, P) est lespace des variables de carr intgrable
(variances-covariances nies).
De faon plus gnrale (et plus formelle), on dsigne par L
p
lespace de Banach des
classes dquivalence (pour lgalit P-presque sre) des fonctions mesurables telles que
|f|
p
=
__
[f[
p
dP
1/p
soit nie.
Proposition 110. L
2
est un espace de Hilbert, muni du produit scalaire , et la norme
associe||
_
X, Y = E(XY )
|X|
2
= X, X = E(X
2
) = V (X) +E(X)
2
.
Par dnition de la covariance, on peut noter que, si X et Y sont centre, X, Y =
E(XY ) = cov (X, Y ).
Thorme 111. Thorme de projection Si 1 est un sous espace ferm de L
2
, pour toute
variable Y L
2
, il existe une unique variable alatoire
Y 1 tel que
_
_
_Y
Y
_
_
_ = min
HH
|Y H| ,
caractris par
Y 1 et Y
Y 1
. On notera aussi
H
(Y ).
Remarque 112. X
n
converge vers X au sens de L
2
si
lim
n
|X
n
X| = 0, cest dire
_
limEX
n
= EX
limV (X
n
X) = 0
On peut alors dnir la variable alatoire Y =
nZ
a
n
X
n
comme limite, dans L
2
de Y
p,q
Y
p,q
=
q
n=p
a
n
X
n
et Y = lim
p,q+
Y
p,q
=
nZ
a
n
X
n
.
84
6.2.2 Rappel sur les vecteurs et processus gaussiens
Pour un vecteur alatoire Z = (Z
1
, ..., Z
d
)
, on dnit son esprance par E(Z) =
(E(Z
1
) , ..., E(Z
d
))
et sa matrice de variance-covariance (si elles existent) par V (Z) =
E
_
(Z E(Z)) (Z E(Z))
_
. Cette matrice est hermitienne positive. De plus, si A est
la matrice dun application linaire de R
d
dans R
p
, le vecteur AZ admet pour esprance
AE(Z) et pour matrice de variance-covariance AV (Z) A
.
Dnition 113. Le vecteur X = (X
1
, ..., X
d
) est un vecteur gaussien si toute combinaison
des X
i
est une variable gaussienne, i.e. pour tout a R
d
, aX est une variable gaussienne.
Sa densit scrit alors
f (x) =
1
(2)
d/2
det
exp
_
1
2
(x )
1
(x )
_
,
o R
d
et est une matrice hermitienne positive d d.
Si X est un vecteur gaussien, son moment lordre p existe et de plus, E(X) = et
V (X) = .
Dnition 114. Le processus (X
t
) est un processus gaussien si tout systme ni extrait
est un vecteur alatoire gaussien, i.e. pour tout n, pour tout t
1
, ..., t
n
, (X
t
1
, ..., X
tn
) est un
vecteur gaussien.
6.2.3 Rgression ane dans L
2
Rgression sur un nombre ni de variables
La rgression linaire thorique de Y sur X
1
, ..., X
n
est la projection orthogonale dans
L
2
(, /, P) de X sur 1
= V ect(X
1
, ..., X
n
), et la rgression ane thorique de Y sur
X
1
, ..., X
n
est la projection orthogonale dans L
2
(, /, P) de Y sur 1 = V ect(I, X
1
, ..., X
n
).
On note alors
Y = EL(Y [I, X
1
, ..., X
n
) =
H
(Y )
o EL(.[.) dsigne lesprance linaire. Cette variable est la meilleure approximation (au
sens de L
2
) de Y par une combinaison linaire de I, X
1
, ..., X
n
,
Proposition 115. Soit le vecteur [cov (X, X
i
)]
i=0,1,...,n
et la matrice
[cov (X
i
, X
j
)]
i,j=0,1,...,n
. Alors
X = EL(X[I, X
1
, ..., X
n
) = a
0
+ a
1
X
1
+ ... + a
n
X
n
,
o a = (a
0
, a
1
, ..., a
n
) vrie a =
1
.
Proof.
X peut scrire
0
+
1
X
1
+ ... +
n
X
n
car
X 1, et vrie
_
_
_
_
X
X, I
_
= 0
_
X
X, X
i
_
= 0 pour i = 1, ..., n,
85
car X
X 1
, cest dire
_
_
_
E
_
X
X
_
= 0 soit E(X) = E
_
X
_
E
__
X
X
_
X
i
_
= 0 pour i = 1, ..., n.
Do
_
_
_
E(X) = E
_
X
_
=
0
+
1
E(X
1
) + ... +
n
E(X
n
) (1)
E(XX
i
) = E
_
XX
i
_
=
0
E(X
i
) +
1
E(X
1
X
i
) + ... +
n
E(X
n
X
i
) (2)
(1) donne
0
= E(X)
1
E(X
1
) ...
n
E(X
n
) et par substitution dans (2),
E(XX
i
) = E(X) E(X
i
) (
1
E(X
1
) + ... +
n
E(X
n
)) E(X
i
)
+
1
E(X
1
X
i
) + ... +
n
E(X
n
X
i
)
donc, pour i = 1, ..., n
cov (XX
i
) =
1
cov (X
1
X
i
) + ... +
n
cov (X
n
X
i
) ,
ce qui donne le systme
_
_
cov (XX
1
) =
1
cov (X
1
X
1
) + ... +
n
cov (X
n
X
1
)
cov (XX
2
) =
1
cov (X
1
X
2
) + ... +
n
cov (X
n
X
2
)
...
cov (XX
n
) =
1
cov (X
1
X
n
) + ... +
n
cov (X
n
X
n
) ,
qui scrit sous forme matricielle
= .
Remarque 116. On peut noter que EL(X[I, X
1
, ..., X
n
) = EL(X[X
1
, ..., X
n
) si et seule-
ment si E(X) = 0 et E(X
j
) = 0 pour j = 1, 2, ..., n.
Rgression sur un nombre inni de variables
On considre cette fois ci X
1
, ..., X
n
, ... des variables de L
2
, et X
0
= I L
2
.
Soit 1 ladhrance de lespace engendr par les combinaisons linaires des X
i
:
1 =L(I, X
1
, ..., X
n
, ...).
On considre alors
X
n
= EL(X[I, X
1
, ..., X
n
). La projection sur 1 est alors la limite
(dans L
2
) des variables
X
n
X = lim
n
EL(X[I, X
1
, ..., X
n
) .
86
6.2.4 La notion dinnovation
Oprateur de projection linaire
Etant donnes une variable alatoire Y et une famille de variables alatoires
X
1
, ..., X
n
, on dnit loprateur de projection linaire de la faon suivante :
(Y [ X
1
, ..., X
n
) =
1
X
1
+ ... +
n
X
n
,
o les
i
sont les solutions du programme doptimisation
(
1
, ...,
n
) = arg min
a
1
,...,an
V ar [Y (a
1
X
1
+ ... + a
n
X
n
)] .
En dautres termes, (Y [ X
1
, ..., X
n
) est la meilleure prvision linaire de Y base sur
X
1
, ..., X
n
, au sens o la variance de lerreur sera minimale. On peut noter que cet
oprateur est linaire, au sens o
(.Y + .Z[ X
1
, ..., X
n
) = .(Y [ X
1
, ..., X
n
) + .(Z[ X
1
, ..., X
n
) .
De plus, lerreur de prvision Y (Y [ X
1
, ..., X
n
) est non corrle avec toute fonction
linaire des X
1
, ..., X
n
. Enn, si cov (X
1
, X
2
) = 0, alors (Y [ X
1
, X
2
) = (Y [ X
1
) +
(Y [ X
2
).
Il est possible de projeter sur une suite innie de variables alatoires X
1
, ..., X
n
, ...,
en notant
(Y [ X
1
, ..., X
n
, ...) = lim
k
(Y [ X
1
, ..., X
k
) .
Cette limite existant pour toute suite de variables alatoires [ X
1
, ..., X
n
, ... .
Prvision linaire
Dnition 117. Soit (X
t
)
tZ
un processus de L
2
. On appelle meilleur prvision
linaire de X
t
sachant son pass la regression linaire (thorique) de X
t
sur son pass
1 =V ect (I, X
t1
, X
t2
, ...), et sera note EL(X
t
[I, X
t1
, X
t2
, ...).
Dnition 118. Le processus dinnovation du processus (X
t
) est le processus (
t
) dni
par
t
= X
t
EL(X
t
[I, X
t1
, X
t2
, ...) .
Proposition 119. Soit (Y
t
) un bruit blanc BB(0,
2
), le processus stationnaire (X
t
)
dnit par
10
X
t
= Y
t
Y
t1
pour [[ < 1,
alors
EL(X
t
[I, X
t1
, X
t2
, ...) =
i=1
i
X
ti
et le processus dinnovation est (Y
t
) .
10
Ceci correspond un processus MA(1), dont la racine est lintrieur du cercle unit.
87
Proof. Le processus (X
t
) est stationnaire en tant que moyenne mobile de bruit blanc.
Dnissons alors
S
t,n
=
n
i=1
i
X
ti
.
A t x, la suite (S
t,n
) est une suite de Cauchy dans L
2
puisque
|S
t,n
S
t,m
| =
_
_
_
_
_
n
i=m+1
i
X
ti
_
_
_
_
_
|X
t
|
n
i=m+1
,
qui tend vers 0 quand m et n tendent vers linni. (S
t,n
) converge donc dans L
2
vers
S
t
=
i=1
i
X
ti
, lment de V ect (I, X
t1
, X
t2
, ...).
Or X
t
= Y
t
Y
t1
, donc X
t
+ S
n,t
= Y
t
+
n+1
Y
tn1
et donc
X
t
+
i=1
i
X
ti
= Y
t
,
puisque |
n+1
Y
tn1
|
2
[[
n+1
0 quand n , do X
t
= S
t
+ Y
t
.
Or X
s
, Y
t
= 0 pour tout s < t, I, Y
t
= 0 et S
t
V ect (I, X
t1
, X
t2
, ...), donc
S
t
= EL(X
t
[I, X
t1
, X
t2
, ...) et (
t
) est le processus dinnovation.
Remarque 120. Soit (Y
t
) un bruit blanc BB(0,
2
), le processus stationnaire (X
t
) sat-
isfaisant
X
t
X
t1
= Y
t
, avec [[ > 1,
Comme nous le verrons par la suite (proprit (??)) le processus Y
t
ainsi dni ne cor-
respond pas linnovation du processus X
t
. Il est possible de montrer (en utilisant la
densit spectrale) que le processus
t
dnit par
t
= X
t
1
X
t1
est eectivement un
bruit blanc. En fait, (
t
) correspond au processus dinnovation associ au processus (X
t
).
Du fait de cette dnition, linnovation possde un certain nombre de proprits
Comme on peut le voir sur le schma ci-dessus, si
t
est linnovation, alors elle est
orthogonale au pass de X
t
cest dire que
_
E(
t
X
t1
) = E(
t
X
t2
) = ... = E(
t
X
th
) = ... = 0
mais E(
t
X
t
) ,= 0.
De plus, on aura galement que
t+k
sera galement orthonogonale au pass de X
t
, pour
k 0,
E(
t+k
X
t1
) = E(
t+k
X
t2
) = ... = E(
t+k
X
th
) = ... = 0.
Remarque 121. De faon rigoureuse, il conviendrait dintroduite la notion de proces-
sus rgulier : on dira que le processus stationnaire (X
t
), centr, est rgulier sil ex-
iste un bruit blanc (
t
) tel que, pour tout t Z, ladhrance des passs (linaires)
1
t
X
= V ect (I, X
t1
, X
t2
, ...) et 1
t
= V ect (I,
t1
,
t2
, ...) concident : 1
t
X
= 1
t
. On
88
peut alors montrer si (X
t
) est un processus stationnaire rgulier, et si (
t
) est un bruit
blanc tel que, chaque date t les passs concident, alors on a la dcomposition
1
t
X
= 1
t1
X
R
t
, pour tout t,
o dsigne une somme directe orthogonale, et le processus bruit blanc est alors unique :
il est appel innovation du processus (X
t
) . Le fait que les deux espaces concident implique,
en particulier, que si (
t
) est linnovation du processus (X
t
) alors
EL(X
T+k
[X
T
, X
T1
, ....) = EL(X
T+h
[
T
,
T1
, ...) .
Complments laide des espaces 1 Etant donn un processus (X
t
), on notera
1(X) le sous-espace de Hilbert de L
2
correspondant ladhrance, dans L
2
, de lespace
des combinaisons linaires nies dlments de (X
t
). On notera 1
T
(X) le sous-espace de
Hilbert de L
2
correspondant ladhrance, dans L
2
, de lespace des combinaisons linaires
nies dlments de (X
t
) avec t T.
Dnition 122. On appelle processus dinnovation la suite
t
= X
t
H
t1
(X)
(X
t
).
Ce processus est alors une suite orthogonale (pour le produit scalaire , ), et on a
linclusion 1
t1
() 1
t1
(X).
6.3 Polynmes doprateurs retard L et avance F
6.3.1 Rappels sur les oprateurs retards
Nous avions dni prcdemment loprateur retard L par L : X
t
L(X
t
) = LX
t
=
X
t1
et loprateur avance F par F : X
t
F (X
t
) = FX
t
= X
t+1
. On notera alors
L
p
= L L ... L
. .
p fois
o p N,
avec la convention L
0
= I et L
1
= F. Et de faon analogue, L
p
= F
p
pour p N.
6.3.2 Inversibilit des polynmes P (L)
Soit A() un polynme, on cherche B() tel que A() B() = B() A() = 1.
inversibilit de P (L) = 1 L
Proposition 123. (i) Si [[ < 1 alors 1 L est inversible, et de plus,
(1 L)
1
=
k=0
k
L
k
.
(ii) Si [[ > 1 alors 1 L est inversible, et de plus,
(1 L)
1
=
k=1
1
k
F
k
.
(iii) Si [[ = 1, alors 1 L nest pas inversible.
89
Proof. (i) Si [[ < 1 alors
(1 )
1
=
+
k=0
k
=
1
1
< +,
donc A(L) =
+
k=0
k
L
k
est bien dni. De plus:
(1 L)A(L) = lim
k+
(1 L)
_
k
j=0
j
L
j
_
= lim
k+
1
k+1
L
k+1
= 1,
ce qui signie que A est le polynme inverse associ (1 L).
(ii) De faon analogue, si [[ > 1 alors 1 L =
_
L
1
_
= L
_
1
F
_
. On a
alors :
(L)
1
=
1
F et
_
1
F
_
1
=
+
k=0
1
k
F
k
car
< 1
En combinant ces deux rsultats :
(1 L)
1
= (L)
1
_
1
F
_
1
=
1
F
_
+
k=0
1
k
F
k
_
=
+
k=1
1
k
F
k
=
1
k=
k
L
k
,
ce qui correspond au rsultat souhait.
(iii) En eet, il nexiste par de polynme A(L) =
kZ
a
k
L
k
,
kZ
[a
k
[ < + tel
que (1 L)A(L) = 1. En eet, s un tel polynme existait,
(1 L)A(L) = 1 [a
k
[ = [a
k1
[ 0 quand k ,
et donc
kZ
[a
k
[ = +.
Exemple 124. Soit (X
t
) et (Y
t
) deux processus stationnaires tels que Y
t
= X
t
X
t1
=
(1 L) X
t
, o < 1. Cette relation sinverse en
X
t
= (1 L)
1
Y
t
= Y
t
+ Y
t1
+ ... +
k
Y
tk
+ ...
Exemple 125. Dans le cas o = 1 (racine unit) on se retrouve en prsnce dune
marche alatoire Y
t
= X
t
X
t1
(non stationnaire).
inversibilit des polynmes en L
Tout polynme A(L) = 1+a
1
L+... +a
n
L
n
(normalis tel que A(0) = 1), peut scrire
A(z) = a
n
(z z
1
) (z z
2
) ... (z z
n
) ,
correspondant la dcomposition en lments simples (z
i
= racines du polynme). On
peut crire
A(L) =
n
i=1
(1
i
L) o
i
=
1
z
i
90
Proposition 126. Si pour tout i, [
i
[ , = 1, alors A(L) est inversible. Pour cela, notons
A(L) =
(1
i
L) =
|
i
|<1
(1
i
L)
. .
A
1
(L)
|
i
|>1
_
1
1
i
F
_
. .
A
2
(L)
|
i
|>1
(
i
L)
. .
A
3
(L)
,
puisque (1
i
L) =
i
L(1 F/
i
), et alors, linverse de A(L) est donn par A(L)
1
A(L)
1
=
(1
i
L)
1
= A
1
(L)
1
A
2
(L)
1
A
3
(L)
1
i.e.
A(L)
1
=
|
i
|<1
(1
i
L)
1
. .
k
L
k
|
i
|>1
_
1
1
i
F
_
1
. .
k
F
k
_
_
|
i
|>1
i
_
_
F
n
,
o n = card i, [
i
[ > 1.
Proof. En eet, i, (1
i
L)
1
est bien dni, de la forme
kZ
a
i,k
L
k
et A(L)
1
=
p
i=1
(1
i
L)
1
est donc aussi dni. Toutefois, A(L)
1
peut contenir des termes en
L
k
, k > 0 qui sont des termes concernant le futur
Si [
i
[ < 1 pour tout i alors (1
i
L)
1
=
+
k=0
k
i
L
k
et :
A(L)
1
=
p
i=1
(1
i
L)
1
=
+
k=0
a
k
L
k
o
+
k=0
[a
k
[ < +.
Par ailleurs,
A(z) =
p
i=1
(1
i
z) et A(z)A(z)
1
= 1
p
i=1
(1
i
z)
_
+
k=0
a
k
z
k
_
= 1,
de telle sorte que A(0)A(0)
1
= 1 a
0
= 1 a
0
= 1. Sil existe i tel que
i
CR alors
A(L) = (1
i
)(1
i
)P(L) et
(1
i
)
1
(1
i
)
1
=
_
+
k=0
k
i
L
k
__
+
k=0
k
i
L
k
_
=
+
k=0
k
L
k
k
R,
0
= 1,
+
k=0
[a
k
[ < +.
Remarque 127. Si des racines sont infrieures 1 (en module), cette dcomposition fait
intervenir le futur de la variable.
Pour dterminer, en pratique, linverse dun polynme A(L), supposons quil scrive
A(L) =
p
j=1
(1
j
L), de telle sorte que
A(L)
1
=
p
j=1
_
+
k=0
k
j
L
k
_
91
On peut utiliser directement cette mthode de calcul pour p petit (p = 1, 2) mais elle
savre fastidieuse en gnral. On note,
A(L)
_
+
k=0
a
k
L
k
_
= (1 +
1
L + +
p
L
p
)
_
+
k=0
a
k
L
k
_
= 1
Les a
k
sont obtenus par rcurrence puis identication.
(L)
1
=
p
j=1
1
1
j
L
On dcompose alors cette fraction rationnelle en lments simples, 1 = (z)Q
r
(z) +
z
r+1
R
r
(z) avec lim
r+
Q
r
(z) = A
1
(z).
6.4 Fonction et matrices autocorrlations
Pour rappels, un processus (X
t
) est stationnaire (au second ordre) si pour tout t, E(X
2
t
) <
+, pour tout t, E(X
t
) = , constante indpendante de t et, pour tout t et pour tout h,
cov (X
t
, X
t+h
) = (h), indpendante de t.
6.4.1 Autocovariance et autocorrlation
Pour une srie stationnaire (X
t
), on dni la fonction dautocovariance h
X
(h) =
cov (X
t
X
th
) pour tout t, et on dni la fonction dautocorrlation h
X
(h) =
X
(h) /
X
(0) pour tout t, soit
X
(h) = corr (X
t
, X
th
) =
cov (X
t
, X
th
)
_
V (X
t
)
_
V (X
th
)
=
X
(h)
X
(0)
Dnition 128. On appelera matrice dautocorrlation du vecteur (X
t
, X
t1
, ..., X
th+1
)
1(h) =
_
_
1 (1) (2) (h 1)
(1) 1 (1) (h 2)
(2) (1) 1
.
.
. (h 3)
.
.
.
.
.
.
.
.
.
.
.
. 1 (1)
(h 1) (h 2) (h 3) (1) 1
_
_
i.e.
1(h) =
_
_
1(h 1)
_
_
(h 1)
.
.
.
(1)
_
_
_
(h 1) (1)
1
_
_
92
On peut noter que det 1(h) 0 pour tout h N 0. Cette proprit implique
un certain nombre de contraintes sur les
X
(i). Par example, la relation det 1(2) 0
implique la contrainte suivante sur le couple ( (1) , (2)) :
[1 (2)]
_
1 + (2) 2 (1)
2
0,
ce qui fait quil ne peut y avoir de chute brutale de (1) (2) : il est impossible davoir
(2) = 0 si (1) 1/
2.
Ces fonctions sont estimes, pour un chantillon X
1
, ..., X
T
, de la faon suivante :
(h) =
1
T h
Th
t=1
X
t
X
th
et (h) =
(h)
(0)
,
(quand le processus est centr, sinon, il faut considrer (X
t
) (X
th
)).
> X=rnrom(100)
> as.vector(acf(X))
Autocorrelations of series X, by lag
0 1 2 3 4 5 6 7 8 9
1.000 -0.004 -0.027 -0.107 -0.113 -0.093 -0.125 0.065 0.043 0.026
6.4.2 Autocorrlations partielles
Les deux prcdentes mesures de dpendence entre X
t
et X
t+h
ne faisaient intervenir
que les variables X
t
et X
t+h
. Nous allons introduire ici une notion faisant intervenir les
variables intermdiaires. Nous supposerons, sans perte de gnralit que le processus (X
t
)
est centr : E(X
t
) = 0 pour tout t.
Dnition 129. Pour une srie stationnaire (X
t
), on dni la fonction dautocorrlation
partielle h
X
(h) par
X
(h) = corr
_
X
t
,
X
th
_
,
o
_
X
th
= X
th
EL(X
th
[X
t1
, ..., X
th+1
)
X
t
= X
t
EL(X
t
[X
t1
, ..., X
th+1
) .
On regarde ici la projection (ou lesprance linaire) les deux valeurs extrmes X
t
et
X
th
sur lensemble des valeurs intermdiaires
t1
h1
= X
t1
, ..., X
th+1
. Cette projec-
tion peut scrire, dans le cas de X
t
EL(X
t
[X
t1
, ..., X
th+1
) = a
1
(h 1) X
t1
+ a
2
(h 1) X
t2
+ ... + a
h1
(h 1) X
th+1
.
On peut aussi crire, en rajoutant X
th
, et en projetant ainsi sur
t1
h
,
EL(X
t
[X
t1
, ..., X
th
) = a
1
(h) X
t1
+ a
2
(h) X
t2
+ ... + a
h1
(h) X
th+1
+ a
h
(h) X
th
.
(19)
93
Il est alors possible de montrer que
EL(X
t
[X
t1
, ..., X
th+1
) = a
1
(h 1) X
t1
+ a
2
(h 1) X
t2
+ ...
+a
h1
(h 1) EL(X
th
[X
t1
, ..., X
th+1
) .
On a alors
h1
i=1
a
i
(h 1) X
ti
=
h1
i=1
a
i
(h) X
ti
+ a
h
(h)
h1
i=1
a
hi
(h 1) X
ti
.
Aussi, on a le rsultat suivant, permettant dobtenir les coecients de faon rcursive
Proposition 130. Pour j = 1, ..., h 1
a
j
(h) = a
j
(h 1) a
h
(h) + a
hj
(h 1) (20)
Toutefois, cette mthode rcursive nest possible qu condition de connatre a
h
(h).
Pour cela, on peut utiliser le rsultat suivant,
Lemme 131. En notant
i
le coecient dautocorrlation,
i
= corr (X
t
, X
ti
), alors
a
h
(h) =
(h)
h1
i=1
(h i) a
i
(h 1)
1
h1
i=1
(i) a
i
(h 1)
. (21)
Proof. De (19), on peut dduire
(h) = (h 1) a
1
(h) + ... + (1) a
h1
(h) + a
h
(h) , puisque (0) = 0,
cest dire
a
h
(h) = (h) [ (h 1) a
1
(h) + ... + (1) a
h1
(h)] = (h)
h1
i=1
(h i) a
i
(h) .
En utilisant (20), on peut crire
a
h
(h) = (h)
_
h1
i=1
(h i) a
i
(h 1) a
h
(h) .
h1
i=1
(i) a
i
(h 1)
_
.
On peut dailleurs noter que lon a la relation suivante
a (h) =
_
_
a
1
(h)
.
.
.
a
h
(h)
_
_
= 1(h)
1
_
_
(1)
.
.
.
(h)
_
_
.
94
Dnition 132. Lalgorithme rcursif bas sur (20), (21) et la condition initiale a
1
(1) =
(1) est appel algorithme de Durbin.
De (20) on peut en dduire en particulier que
a
1
(h) = a
1
(h 1) + a
h
(h) a
h1
(h 1) ,
et de (21) , que pour h 2,
a
h
(h) =
(1) a
h1
(h 1)
1 (1) a
1
(h 1)
.
Ces deux quation permettent dobtenir rcursivement les deux coecients extrmes a
1
(h)
et a
h
(h) pour tout h.
Proposition 133. Soit (X
t
) un processus stationnaire, alors
X
(0) = 1, et, pour h 1,
X
(h) est le coecient relatif X
th
dans la projection de X
t
sur X
t1
, ..., X
th+1
, X
th
,
soit a
h
(h).
Proof. Cette proprit sobtient en notant que
EL(X
t
[X
t1
, ..., X
th
)EL(X
t
[X
t1
, ..., X
th+1
) = a
h
(h) [X
th
EL(X
th
[X
t1
, ..., X
th+1
)] .
Thorme 134. Il est quivalent de connatre la fonction dautocorrlation (
X
(h)) ou
la fonction dautocorrlation partielle (
X
(h)).
Proof. (i) Lalgorithme de Durbin a montr que la connaissance des
X
(h) permet de
construire de faon rcursive les fonctions
X
(h).
(ii) Rciproquement, la relation inverse sobtient par rcurence, en notant que a
1
(1) =
X
(1) =
X
(1), et que
1(h 1)
_
_
a
1
(h)
.
.
.
a
h1
(h)
_
_
+
_
_
(h 1)
.
.
.
(1)
_
_
a
h
(h) =
_
_
(1)
.
.
.
(h 1)
_
_
,
et
_
(h 1) (1)
_
a
1
(h)
.
.
.
a
h1
(h)
_
_
+ a
h
(h) = (h) .
Exemple 135. En particulier, on peut noter que
X
(1) =
X
(1) et
X
(2) =
_
X
(2)
X
(1)
2
_
1
X
(1)
2
95
Une autre formulation consiste dire que la fonction dautocorrlation partielle mesure
la corrlation entre X
t
et X
th
une fois retire linuence des variables antrieures X
th
.
En reprenant les notations de la partie prcdante,
1(h) =
_
_
1 (1) (2) (h 3) (h 2) (h 1)
(1) 1 (1) (h 4) (h 3) (h 2)
(2) (1) 1
.
.
. (h 5) (h 4) (h 3)
.
.
.
.
.
.
.
.
.
(h 3) (h 4) (h 5)
.
.
. 1 (1) (2)
(h 2) (h 3) (h 4) (1) 1 (1)
(h 1) (h 2) (h 3) (2) (1) 1
_
_
et on introduit de faon analogue la matrice 1
(h) obtenue en remplaant la dernire
colonne de 1(h) par le vecteur [ (1) , ..., (h)]
,
1
(h) =
_
_
1 (1) (2) (h 3) (h 2) (1)
(1) 1 (1) (h 4) (h 3) (2)
(2) (1) 1
.
.
. (h 5) (h 4) (3)
.
.
.
.
.
.
.
.
.
(h 3) (h 4) (h 5)
.
.
. 1 (1) (h 2)
(h 2) (h 3) (h 4) (1) 1 (h 1)
(h 1) (h 2) (h 3) (2) (1) (h)
_
_
Il est alors possible de montrer simplement que
X
(h) =
[1
(h)[
[1(h)[
pour tout h.
> X=rnorm(100)
> as.vector(pacf(X))
Partial autocorrelations of series X, by lag
1 2 3 4 5 6 7 8 9
-0.004 -0.027 -0.108 -0.116 -0.105 -0.153 0.023 -0.002 -0.025
6.4.3 Densit spectrale
Comme nous lavon dj mentionn, il est quivalent de connatre la fonction
dautocorrlation et la densit spectrale du processus.
Proposition 136. Soit (X
t
) un processus stationnaire de la forme X
t
= m +
+
j=0
a
j
tj
o (
t
) est un bruit blanc et
+
j=0
[a
j
[ < +, alors
hZ
[
X
(h)[ < +.
96
Proof.
hZ
[
X
(h)[ =
hZ
j,k
a
j
a
k
(h + j k)
.
Or, comme (
t
) est un bruit blanc,
(h + j k) =
_
0 si h + j k ,= 0
si h + j k = 0,
et donc,
hZ
[
X
(h)[ =
hZ
j
a
j
a
h+j
h,j
[a
j
[ [a
h+j
[ =
2
j
a
j
_
2
< +.
Proposition 137. La densit spectrale du processus (X
t
) est dnie par
f
X
() =
1
2
hZ
X
(h) exp(ih) =
1
2
hZ
X
(h) cos(h).
Proof. En eet,
f
X
() =
1
2
_
X
(0) +
h>0
X
(h)e
ih
+
h<0
X
(h)e
ih
_
=
1
2
_
X
(0) +
h>0
X
(h)e
ih
+
h>0
X
(h)
. .
=
X
(h)
e
ih
_
_
=
1
2
_
X
(0) +
h>0
X
(h) (e
ih
+ e
ih
)
. .
=2 cos(h)
_
_
=
1
2
_
X
(0) +
h=0
X
(h) cos(h)
_
=
1
2
hZ
X
(h) cos(h).
On peut dailleurs noter que si (
t
) est un bruit blanc de variance
2
, on a alors
(
t
) BB(0,
2
) f
() =
2
.
Proposition 138. Avec les notations prcdentes, on a le thorme dinjectivit suivant,
h Z,
X
(h) =
_
[;]
f
X
()e
ih
d =
_
[;]
f
X
() cos(h)d.
97
Proof. En eet,
_
[;]
f
X
()e
ih
d =
1
2
_
[;]
_
kZ
X
(k)e
ik
_
e
ih
d
=
1
2
kZ
X
(k)
__
[;]
e
i(kh)
d
_
. .
=
_
_
_
0 si k ,= h
2 si k = h
(daprs Fubini)
=
X
(h).
Proposition 139. Soient (
t
) un bruit blanc, et considrons les processus (X
t
) et (Y
t
)
dnis par
X
t
=
jZ
a
j
tj
et Y
t
=
kZ
b
k
X
tk
o
j
[a
j
[ ,
j
[b
j
[ < +,
alors Y
t
=
kZ
c
k
tk
, et de plus,
f
Y
() = f
X
()
kZ
b
k
e
ik
2
.
Proof. Il sut de noter que
Y
t
=
kZ
b
k
X
tk
=
kZ
b
k
_
jZ
a
j
tkj
_
=
j,kZ
a
j
b
k
t(k+j)
=
j,hZ
a
j
b
hj
th
=
hZ
_
jZ
a
j
b
hj
_
. .
=c
k
th
.
et de plus, la densit spectrale scrit
f
Y
() =
1
2
hZ
Y
(h)e
ih
=
1
2
hZ
_
j,kZ
b
j
b
k
X
(h + j k)
_
e
ih
=
1
2
h,j,kZ
b
j
b
k
X
(h + j k)e
i(h+jk)
e
ij
e
ik
=
1
2
_
lZ
X
(l)e
il
__
jZ
b
j
e
ij
__
kZ
b
k
e
ik
_
= f
X
()
kZ
b
k
e
ik
2
.
98
6.4.4 Autocorrlations inverses
Cette notion a t introduite en 1972 par Cleveland, et Chateld en a prcis les princi-
pales charactristiques en 1979. Etant donn un processus (X
t
) stationnaire, de fonction
dautocovariance
X
et de densit spectrale f
X
, il se peut que 1/f
X
soit interprtable
comme une densit spectrale (par exemple ds lors que 1/f
X
est continue).
Dnition 140. La fonction dautocovariance inverse i
X
est la fonction
dautocovariance associe au spectre inverse 1/f,
i
X
(h) =
_
+
1
f
X
()
exp (ih) d ou
1
f
X
()
=
1
2
hZ
i
X
(h) exp (ih) .
De la mme faon que prcdement, on peut alors dnir une autocorrlation inverse,
Dnition 141. La fonction dautocorrlation inverse i
X
est dnie par,
i (h) =
i
X
(h)
i
X
(0)
.
Considrons une srie (X
t
) stationnaire, de processus dautocovariance (h) pour
h Z. On dnit alors la fonction gnratrice dautocovariance comme le polynme
(doprateurs retards) suivant
(L) = ... + (1) L
1
+ (0) I + (1) L + (2) L
2
+ ... =
+
k=
(k) L
k
,
et de faon similaire, on peut dnir la fonction gnratrice dautocorrlation. La fonction
gnratrice dautocovariance inverse, note i (L) est dni par i (L) (L) = I et est telle
que
i (L) = ... + i (1) L
1
+ i (0) I + i (1) L + i (2) L
2
+ ... =
+
k=
i (k) L
k
= (L)
1
Exemple 142. Dans le cas dun processus dit ARMA(p, q) (voir partie (6.7)), dnit par
une relation de la forme (L) X
t
= (L)
t
o
t
est un bruit blanc, et o et sont
respectivement des polynmes de degr p et q. La fonction gnratrice dautocovariance
inverse est donne par
i (L) =
(L) (L
1
)
(L) (L
1
)
.
1
2
o
2
est la variance du bruit blanc
t
Dans le cas o la composante moyenne mobile nexiste pas ( = I, on parle alors de
processus AR(p)),on peut alors en dduire simplement que lautocovariance inverse est
donne par
i (h) =
ph
j=0
j
j+h
p
j=0
2
j
pour h p et
i
(h) = 0 pour h p
99
avec la convention
0
= 1. Aussi, pour les processus AR(p), les autocorrlations inverses
sannulent au del du retard p (de la mme faon que les autocorrlations partielles).
Bhansali a montr en 1980 que pour un bruit blanc, les autocorrlations inverses em-
piriques suivent un bruit blanc de loi normale de moyenne nulle et de variance 1/n.
Ainsi, la signicativit des coecients dautocorrlation inverse peut tre teste, au seuil
de 5%, en la comparant avec 1.96/
n.
Il est galement possible de dnir les autocorrlations partielles inverses (en utilisant
une construction analogue celle dveloppe dans la partie prcdante, en remplaant les
par les i). Comme la montr Bhansali (1980 1983) et Cleveland et Parzen, les
autocorrlations partielles inverses peuvent tre obtenus laide de mthodes rcursives
(proches de celle de Durbin).
Remarque 143. On peut noter la correspondance suivante
autocorrlations
autocorrlations
partielles
autocorrlations
partielles inverses
autocorrlations
inverses
En fait, comme nous le verrons par la suite, sur lidentication des modles ARMA, les
autocorrlations permettent de dtecter (entre autres) si une srie est intgre, et sil faut
la direncier, alors que les autocorrlations partielles permettent de vrier que la srie
na pas t surdirencie.
Les autocorrlations et les autocorrlations inverses i sont identiques si et seulement
si X est un bruit blanc
6.4.5 Complment : autocorrlogrammes de fonctions dterministes
Nous allons rappeler ici les formes des autocorrlogrammes, et des autocorrlogrammes
partiels de sries non-stationnaires, et dterministes.
Exemple 144. Fonction linaire X
t
= a + bt
Exemple 145. Fonction puissance X
t
= (1 + r)
t
100
Exemple 146. Fonction logarithmique X
t
= log (t)
Exemple 147. Fonction sinusodale X
t
= sin (t/12)
6.5 Les processus autorgressifs : AR(p)
Dnition 148. On appelle processus autoregressif dordre p, not AR(p), un processus
stationnaire (X
t
) vriant une relation du type
X
t
i=1
i
X
ti
=
t
pour tout t Z, (22)
o les
i
sont des rels et (
t
) est un bruit blanc de variance
2
. (22) est quivalent
lcriture
(L) X
t
=
t
o (L) = I
1
L ...
p
L
p
Il convient de faire toutefois attention aux signes, certains ouvrages ou logiciels con-
sidrant des polynmes de la forme I +
1
L + ... +
p
L
p
.
101
Remarque 149. En toute gnralit, un processus AR(p) vrie une relation de la forme
(L) X
t
= +
t
o est un terme constant. De cette forme gnrale, il est possible
de se ramener (22) par une simple translation : il sut de consider non pas X
t
mais
Y
t
= X
t
m o m = /(1). En eet, (L) (Y
t
+ m) = +
t
peut se rcire (L) Y
t
+
(1) m = +
t
cest dire (L) Y
t
=
t
. m correspond ici lesprance de (X
t
).
6.5.1 Rcriture de la forme AR(p)
Comme nous lavons vu dans la partie (6.3.2), si lon souhaite inverser un polynme (en
loccurence, prsenter X
t
comme une fonction des
t
), il convient de regarder les racines
du polynme , en particulier leur position par rapport 1 (en module). Comme nous
allons le voir dans cette partie, il est possible, lorsque les racines de sont de module
dirent de 1, quil est toujours possible de supposer les racines de module suprieur 1,
quitte changer la forme du bruit blanc.
Ecriture sous la forme MA() quand les racines de sont de module stricte-
ment suprieur 1 On suppose (L)X
t
= +
t
o (L) = 1 (
1
L + +
p
L)
et aussi que [z[ 1 (z) ,= 0 (de telle sorte que les racines de sont de module
strictement suprieur 1). Daprs les rsultats noncs dans la partie sur les polynmes
doprateurs retards, (X
t
) admet une reprsentation MA() i.e.
X
t
= m +
+
k=0
a
k
tk
o a
0
= 1, a
k
R,
+
k=0
[a
k
[ < +.
On sait que (L)(X
t
m) =
t
, donc X
t
m = (L)
1
(
t
).
Proposition 150. Sous ces hypothses, L(X
t
) = L(
t
), o L(X
t
) =
L(1, X
t
, X
t1
, . . . , X
tp
, . . . ) et L(
t
) = L(1,
t
,
t1
, . . . ,
tp
, . . . ), et de plus (
t
)
est linnovation de (X
t
) .
Proof. (i) X
t
= +
1
X
t1
+ +
p
X
tp
+
t
, qui peut se rcrire X
t
= +
+
k=0
a
t
tk
donc X
t
L(
t
) = L(1,
t
,
t1
, . . . ,
tk
, . . . ). Donc k 0, X
tk
L(
tk
) L(
t
) On
en dduit que L(1, X
t
, X
t1
, . . . , X
tk
, . . . ) L(
t
) et donc L(X
t
) L(
t
). Le second
espace tant ferm, on en dduit que L(X
t
) L(
t
).
De la mme faon et comme
t
= X
t
(+
1
X
t1
+ +
p
X
tp
), in obtient linclusion
rciproque et nalement L(X
t
) = L(
t
).
(ii) Linnovation de (X
t
) vaut, par dnition, X
t
X
t
, o
X
t
= EL(X
t
[X
t1
) = EL(X
t
[1, X
t1
, . . . , X
tk
, . . . )
= EL( +
1
X
t1
+ +
p
X
tp
. .
L(X
t1
)
+
t
[X
t1
) = +
1
X
t1
+ +
p
X
tp
+ EL(
t
[X
t1
).
Comme L(X
t1
) = L(
t1
), on a EL(
t
[X
t1
) = EL(
t
[
t1
) = 0 car (
t
) est un bruit
blanc. Finalement
X
t
= +
1
X
t1
+ +
p
X
tp
et X
t
X
t
=
t
: (
t
) est bien
linnovation de (X
t
).
102
Si (X
t
) est un processus AR(p), (L)X
t
= +
t
o les racines de sont lextrieur
du disque unit, on dit que la reprsentation (L)X
t
= +
t
est la reprsentation
canonique de (X
t
).
Ecriture sous la forme MA() quand certaines racines de sont de module
strictement infrieur 1 On suppose que le processus (X
t
) scrit (L)X
t
= +
t
avec
(L) =
p
j=1
(1
j
L) =
_
_
j/ |
j
|<1
(1
j
L)
_
_
_
_
j/ |
j
|>1
(1
j
L)
_
_
On peut alors montrer que lon naura pas L(X
t
) = L(
t
), et donc (
t
) nest pas
linnovation.
Pour obtenir la reprsentation canonique il faut changer le polynme et le bruit
blanc. On pose
(z) =
_
_
j/ |
j
|<1
(1
j
z)
_
_
_
_
j/ |
j
|>1
(1
z
j
)
_
_
de telle sorte que
a toutes ses racines de module strictement suprieur 1.
Proposition 151. Soit (
t
) le processus tel que
t
=
(L)X
t
. Alors (
t
) est un bruit
blanc.
Proof. En eet, la densit spectrale de (
t
) est f
() = f
X
() [
(e
i
)[
2
. Et comme
(L)X
t
=
t
, on a aussi :
f
X
()
(e
i
)
2
= f
() =
2
2
On peut alors crire
f
() =
2
2
1
[(e
i
)[
2
(e
i
)
2
=
2
2
_
j/ |
j
|<1
[1
j
e
i
[
2
_
_
j/ |
j
|>1
1
e
i
2
_
_
j/ |
j
|<1
[1
j
e
i
[
2
_ _
j/ |
j
|>1
[1
j
e
i
[
2
_
=
2
j, |
j
|>1
1
[
j
[
2
[
j
e
i
[
2
[1
j
e
i
[
2
. .
=1
=
2
j, |
j
|>1
1
[
j
[
2
On a donc
f
() =
2
2
=
2
avec =
j, |
j
|>1
1
[
j
[
2
< 1
et nalement (
t
) est un bruit blanc.
La reprsentation
(L)X
t
=
t
est alors la reprsentation canonique de (X
t
) et (
t
)
est linnovation de (X
t
).
103
6.5.2 Proprits des autocorrlations - les quations de Yule-Walker
Le processus (X
t
) scrit
X
t
=
1
X
t1
+
2
X
t2
+ ... +
p
X
tp
+
t
. (23)
En multipliant par X
t
, on obtient
X
2
t
=
1
X
t1
X
t
+
2
X
t2
X
t
+ ... +
p
X
tp
X
t
+
t
X
t
=
1
X
t1
X
t
+
2
X
t2
X
t
+ ... +
p
X
tp
X
t
+
t
(
1
X
t1
+
2
X
t2
+ ... +
p
X
tp
+
t
)
=
1
X
t1
X
t
+
2
X
t2
X
t
+ ... +
p
X
tp
X
t
+
2
t
+ [
1
X
t1
+
2
X
t2
+ ... +
p
X
tp
]
t
,
do, en prenant lesprance
(0) =
1
(1) +
2
(2) + ... +
p
(p) +
2
+ 0,
le dernire terme tant nul car
t
est suppos indpendant du pass de X
t
,
X
t1
, X
t2
, ..., X
tp
, .... De plus, en multipliant (23) par X
th
, en prenant lesprance
et en divisant par (0), on obtient
(h)
p
i=1
i
(h i) = 0 pour tout h > 0.
Cette suite dquations dnit le systme dquation dit de Yule-Walker :
Proposition 152. Soit (X
t
) un processus AR(p) dautocorrlation (h). Alors
_
_
(1)
(2)
(3)
.
.
.
(p 1)
(p)
_
_
=
_
_
1 (1) (2)
.
.
. (p 1)
(1) 1 (1)
.
.
. (p 2)
(2) (1) 1
.
.
. (p 3)
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
. 1 (1)
(p 1) (p 2) (p 3) (1) 1
_
_
_
3
.
.
.
p1
p
_
_
De plus les (h) dcroissent exponentiellement vers 0.
Proof. En eet, h > 0, (h)
1
(h 1)
p
(h p) = 0. Le polynme
caractristique de cette relation de rcurrence est :
z
p
1
z
p1
p1
z
p
= z
p
_
1
1
z
p1
z
p1
p
z
p
_
= z
p
(
1
z
),
avec (L)X
t
=
t
et(L) = 1
1
L
p
L
p
. Les racines du polynme caractristique
sont les
i
=
1
z
i
(les z
i
tant les racines de ) avec [
i
[ < 1. La forme gnrale de
la solution est, si z
1
, . . . , z
n
sont des racines distinctes de de multiplicits respectives
m
1
, . . . , m
n
(h) =
n
i=1
m
i
1
k=0
ik
k
i
h
k
cest dire que (h) dcroit vers 0 exponentiellement avec h.
104
Par inversion, il est possible dexprimer les
i
en fonction des (h). La mthodologie
dveloppe dans la partie (6.4.2) permet dobtenir les autocorrlations partielles (h). Il
est possible de montrer le rsultat suivant
Proposition 153. (i) Pour un processus AR(p) les autocorrlations partielles sont nulles
au del de rang p, (h) = 0 pour h > p.
(ii) Pour un processus AR(p) les autocorrlations inverses sont nulles au del de rang
p, i (h) = 0 pour h > p.
Proof. (i) Si (X
t
) est un processusAR(p) et si (L)X
t
= +
t
est sa reprsentation
canonique, en notant (h) le coecient de X
th
dans EL(X
t
[X
t1
, . . . , X
th
) alors,
X
t
= +
1
X
t1
+ +
p
X
tp
. .
L(1,Xt,...,X
tp
)L(1,Xt,...,X
th
)
+
t
de telle sorte que
EL(X
t
[X
t1
, . . . , X
th
) = +
1
X
t1
+ +
p
X
tp
+ EL(
t
[X
t1
, . . . , X
th
)
= +
1
X
t1
+ +
p
X
tp
+ 0
Aussi, si h > p, le coecient de X
th
est 0. et si h = p, le coecient de X
tp
est
p
,= 0.
(ii) Les autocorrlation inverses sont dnies par
i
(h) =
i
(h)/
i
(0) o
i
(h) =
_
1
f
X
()
e
ih
d.
Si (L)X
t
=
t
la densit spectrale de (X
t
) vrie
f
X
()
(e
i
)
2
= f
() =
2
2
donc f
X
() =
2
2
1
[(e
i
)[
2
.
Par consquent,
1
f
X
()
=
2
(e
i
)
2
Aussi, si (z) = 1 + z + ... +
p
z
p
(i.e.
0
= 1 et
k
=
k
),
1
f
X
()
=
2
_
p
k=0
k
e
ik
__
p
k=0k
e
ik
_
=
2
0k,lp
l
e
i(kl)
,
et donc, les autocovariances inverses sont dnies par
i
(h) =
2
0k,lp
l
_
e
i(kl+h)
d
. .
=0 sauf si kl+h=0
.
Or k l [p; p] donc si h > p,
i
(h) = 0. En revanche si h = p,
i
(p) =
4
2
p
=
4
2
p
,= 0.
Cette mthode pourra tre utilise pour identier les processus AR(p) .
105
6.5.3 Le processus AR(1)
La forme gnral des processus de type AR(1) est
X
t
X
t1
=
t
pour tout t Z,
o (
t
) est un bruit blanc de variance
2
.
(i) si = 1, le processus (X
t
) nest pas stationnaire. Par exemple, pour = 1,
X
t
= X
t1
+
t
peut scrire
X
t
X
th
=
t
+
t1
+ ... +
th+1
,
et donc E(X
t
X
th
)
2
= h
2
. Or pour un processus stationnaire, il est possible de
montrer que E(X
t
X
th
)
2
4V (X
t
). Puisquil est impossible que pour tout h, h
2
4V (X
t
), le processus nest pas stationnaire.
Si [[ ,= 1, il existe un unique processus stationnaire tel que X
t
X
t1
=
t
pour
tout t Z, ou
(1 L) X
t
=
t
.
(ii) si [[ < 1 alors on peut inverser le polynme, et
X
t
= (1 L)
1
t
=
i=0
ti
(en fonction du pass de (
t
) ). (24)
(iii) si [[ > 1 alors on peut inverser le polynme, et
X
t
=
1
F
_
1
1
F
_
1
t
=
i=1
t+i
(en fonction du futur de (
t
) ).
La reprsentation canonique est alors
X
t
X
t1
=
t
,
o
t
= (1 F) (1 L)
1
t
=
t+1
+
_
1
2
_
i=0
ti
.
Proposition 154. La fonction dautocorrlation est donne par (h) =
h
.
Proof. Cette expression sobtient partir des relations du type (24) , ou en notant que
(h) = (h 1).
On peut visualiser cette autocorrlation sur les nuages de points (X
t1
, X
t
), (X
t2
, X
t
),
etc, pour un processus AR(1) avec > 0
106
> X=arima.sim(n = 240, list(ar = 0.8),sd = 1)
> plot(X)
> n=240; h=1
> plot(X[1:(n-h)],X[(1+h):n])
> library(ellipse)
> lines(ellipse(0.8^h), type = l,col="red")
ou un processus AR(1) avec < 0
> X=arima.sim(n = 240, list(ar = -0.8),sd = 1)
107
La densit spectrale dun processus AR(1) est de la forme
f () =
2
2
1
1 +
2
2cos
,
qui correspond au graphique ci-dessous, avec > 0 (les courbes sont ici prsentes dans
la mme base 1 : f (0) = 1),
Les valeurs les plus importantes sont obtenues aux basses frquences, les fonctions
108
tant dcroissantes sur [0, ]. Dans les trois exemples ci-dessous, les
t
seront pris
gaussiens,
t
A (0, 1)
A retenir 155. Un processus AR(1) : X
t
= X
t1
+
t
sera auto-corrl positivement
si 0 < < 1, et autocorrl ngativement si 1 < < 0. Cette srie va osciller autour
de 0, en sen cartant suivant la valeur
t
du processus dinnovation (si 1 < < +1).
Si = +1, on obtient une marche alatoire, et si > +1 ou < 1 le processus nest
par stationnaire, et on obtient un modle qui explosera ( moyen terme). La valeur ,
dans le cas o le processus est stationnaire, est la corrlation entre deux dates conscutives
= corr (X
t
, X
t1
).
AR(1) :
_
_
Fonction dautocorrlation
_
> 0 dcroissance exponentielle
< 0 sinusode amortie
Fonction dautocorrlation partielle
_
premire non nulle (signe = signe de )
toutes nulles aprs
Considrons un processus AR(1) stationnaire avec
1
= 0.6.
> X=arima.sim(n = 2400, list(ar = 0.6),sd = 1)
> plot(X)
> plot(acf(X),lwd=5,col="red")
> plot(pacf(X),lwd=5,col="red")
Considrons un processus AR(1) stationnaire avec
1
= 0.6.
> X=arima.sim(n = 2400, list(ar = -0.6),sd = 1)
> plot(X)
109
> plot(acf(X),lwd=5,col="red")
> plot(pacf(X),lwd=5,col="red")
Considrons un processus AR(1) presque plus stationnaire avec
1
= 0.999.
> X=arima.sim(n = 2400, list(ar = 0.999),sd = 1)
> plot(X)
> plot(acf(X),lwd=5,col="red")
> plot(pacf(X),lwd=5,col="red")
110
6.5.4 Le processus AR(2)
Ces processus sont galement appels modles de Yule, dont la forme gnrale est
_
1
1
L
2
L
2
_
X
t
=
t
,
o les racines du polynme caractristique (z) = 1
1
z
2
z
2
sont supposes
lextrieur du disque unit (de telle sorte que le processus
t
corresponde linnovation).
Cette condition scrit
_
_
_
1
1
+
2
> 0
1 +
1
2
> 0
2
1
+ 4
2
> 0,
cest dire que le couple (
1
,
2
) doit se trouver dans une des 4 parties ci-dessous,
La fonction dautocorrlation satisfait lquation de rcurence
(h) =
1
(h 1) +
2
(h 2) pour h 2,
et la fonction dautocorrlation partielle vrie
a (h) =
_
_
_
(1) pour h = 1
_
(2) (1)
2
/
_
1 (1)
2
pour h = 2
0 pour h 3.
Exemple 156. Processus AR(0.5, 0.3) - cas 1 -
Exemple 157. Processus AR(0.5, 0.3) - cas 2 -
Exemple 158. Processus AR(0.5, 0.7) - cas 3 -
Exemple 159. Processus AR(0.5, 0.7) - cas 4 -
Dans le cas dun modle AR(2) avec constante, de la forme (1
1
L
2
L
2
) X
t
=
0
+
t
on peut alors noter que lesprance de X
t
est
E(X
t
) =
0
1
1
2
ds lors que
1
+
2
,= 1.
En utilisant les quations de Yule Walker, nous avions not que la fonction
dautocorrlation vriait la relation de rcurence suivante,
_
(0) = 1 et (1) =
1
/ (1
2
) ,
(h) =
1
(h 1) +
2
(h 2) pour h 2,
cest dire que le comportement de cette suite peut tre dcrit en tudiant le polynme
caractristique associ, x
2
1
x
2
= 0. Dans le cas o le polynme admet deux
racines relles,
1
et
2
o =
_
2
1
+ 4
2
_
/2, alors le polynme autorgressif
peut scrire (1
1
L
2
L
2
) = (1
1
L) (1
2
L) : le modle AR(1) peut tre vu
alors comme un modle AR(1) appliqu un processus AR(1). Lautocorrlogramme
prsente une dcroissante suivant un mlange dexponentielles. Quand les racines sont
complexes (conjugues), alors les (h) prsentent une volution sinusodale amortie. On
obtient alors des cycles stochastiques, de longueur moyenne 2/ cos
1
_
1
/2
2
_
.
111
(tir de Box, Jenkins & Reinsel (1994))
A retenir 160. Le comportement dun processus AR(2) : X
t
=
1
X
t1
+
2
X
t2
+
t
dpendra fortement des racines de son quation charactristique 1
1
.z
2
.z
2
= 0. Le
cas le plus intressant est celui o lquation charactristique a deux racines complexes
conjugues r exp (i) pour r < 1 : le processus est alors stationnaire (et oscille alors
autour de 0, sans exploser, de la mme faon que les processus AR(1) dans le cas o
[[ < 1). Le processus est alors quasi-cyclique, de frquence , avec un bruit alatoire.
AR(2) :
_
_
_
Fonction dautocorrlation dcroissance exponentielle ou sinusode amortie
Fonction dautocorrlation partielle
_
deux premires non nulles
toutes nulles aprs
> X=arima.sim(n = 2400, list(ar = c(0.6,0.4)),sd = 1)
> plot(acf(X),lwd=5,col="red")
> plot(pacf(X),lwd=5,col="red")
> X=arima.sim(n = 2400, list(ar = c(0.6,-0.4)),sd = 1)
> plot(acf(X),lwd=5,col="red")
> plot(pacf(X),lwd=5,col="red")
112
> X=arima.sim(n = 2400, list(ar = c(-0.6,0.4)),sd = 1)
> plot(acf(X),lwd=5,col="red")
> plot(pacf(X),lwd=5,col="red")
> X=arima.sim(n = 2400, list(ar = c(-0.6,-0.4)),sd = 1)
> plot(acf(X),lwd=5,col="red")
> plot(pacf(X),lwd=5,col="red")
6.6 Les processus moyenne-mobile : MA(q)
Dnition 161. On appelle processus moyenne mobile (moving average) dordre q, not
MA(q), un processus stationnaire (X
t
) vriant une relation du type
X
t
=
t
+
q
i=1
ti
pour tout t Z, (25)
o les
i
sont des rels et (
t
) est un bruit blanc de variance
2
. (25) est quivalent
lcriture
X
t
= (L)
t
o (L) = I +
1
L + ... +
q
L
q
.
Remarque 162. Encore une fois, nous allons utiliser dans cette partie des modles de la
forme (25), toutefois, dans certains ouvrages, la convention est dcrire ces modles sous
la forme (L) = I
1
L ...
q
L
q
. En particulier pour les logiciels dconomtrie, il
convient de vrier le signe attribu aux coecients de la forme MA (cf exercice 15 de
lexamen de 2002/2003).
Contrairement aux processus AR(p), les processus MA(q) sont toujours des processus
stationnaires. Les processus MA() sont stationnaires si et seulement si
i=1
2
i
est nie.
Pour rappel, un processus AR(p) est stationnaire si les racines du polynme retard sont
lextrieur du cercle unit.
De la mme faon que pour les AR(p), il est possible dinverser le polynme dans le
cas o ses racines sont de module dirent de 1 (quitte changer des bruit blanc, comme
pour les processus AR). Supposons que nait pas de racines de module gal 1, et
113
considrons le polynme
obtenu en remplaant les racines de de module infrieur
1 par leur inverse. Le processus (
t
) dni par la relation X
t
=
(L)
t
est l aussi un
bruit blanc, dont la variance
2
est dnie par
2
=
2
_
p
i=r+1
[
i
[
2
_
1
,
o
i
sont les racines de module infrieur 1. Aussi, la variance de (
t
) est ici suprieure
celle de (
t
). Par le suite, on supposera que le processus MA est sous forme canonique,
cest dire que toutes les racines de sont de module suprieur 1.
6.6.1 Proprits des autocorrlations
La fonction dautocovarariance est donne par
(h) = E(X
t
X
th
)
= E([
t
+
1
t1
+ ... +
q
tq
] [
th
+
1
th1
+ ... +
q
thq
])
=
_
[
h
+
h+1
1
+ ... +
q
qh
]
2
si 1 h q
0 si h > q,
avec, pour h = 0, la relation
(0) =
_
1 +
2
1
+
2
2
+ ... +
2
q
2
.
Cette dernire relation peut se rcrire
(k) =
2
q
j=0
j+k
avec la convention
0
= 1.
Do la fonction dautocovariance,
(h) =
h
+
h+1
1
+ ... +
q
qh
1 +
2
1
+
2
2
+ ... +
2
q
si 1 h q,
et (h) = 0 pour h > q.
On peut noter en particulier que (q) =
2
q
,= 0, alors que (q + 1) = 0. Cette
proprit sera relativement pratique pour faire lestimation de lordre de processus MA.
On peut calculer les autocorrlations la main
> rho=function(h,theta){
+ theta=c(1,theta)
+ q=length(theta)
+ if(h>=q) ACF=0 else{sn=0;sd=0
+ for(i in 1:(q-h)) sn=sn+theta[i]*theta[i+h]
+ for(i in 1:(q)) sd=sd+theta[i]^2
+ ACF=sn/sd}
114
+ return(ACF)}
>
> THETA=c(-.6,.7,-.4,0,.9)
> X=arima.sim(list(ma = THETA),n=240)
> acf(X,col="red",lwd=5)
>
> R=function(h) rho(h,THETA)
> points(1:24,Vectorize(R)(1:24),pch=19,cex=2,col="blue")
Exemple 163. Le graphique ci-dessous montre lvolution dun processus MA(5), avec
un bruit blanc gaussien, de variance 1, avec droite, lautocorrlogramme associ, pour
X
t
=
t
0.7
t1
+ 0.8
t2
+ 0.3
t3
0.1
t4
+ 0.7
t5
,
On retrouve bien sur cette simulation de processus MA(5) le fait que les autocorrla-
tions sannulent pour h > 5.
A retenir 164. Les processus MA sont toujours stationnaire, mais ils ne sont inversibles
que si les racines du polynme charactristiques sont lextrieur du disque unit.
On peut noter que sil ny a pas de rsultat particulier pour les autocorrlations par-
tielles, on a malgr tout le rsultat suivant
Proposition 165. Si (X
t
) suit un processus MA(q), X
t
= (L)
t
=
t
+
1
t1
+ ... +
tq
, alors les autocorrlations inverves i (h) satisfont les quations de Yule-Walker
inverse,
i (h) +
1
i (h 1) + ... +
q
i (h q) = 0 pour h = 1, 2, ..., q.
En particulier, i(h) dcroit exponentiellement avec h.
Proof. Par dnition i(h) =
i
(h)/
i
(0) avec
i
(h) =
_
1
f
X
()
e
ih
d. On peut alors
crire, si X
t
= (L)
t
f
X
() =
2
(e
i
)
2
et donc
1
f
X
()
=
2
[(e
i
)[
2
.
115
Soit (Y
t
)
tZ
un processus tel que (L)Y
t
=
t
i.e. (Y
t
) suit un processus AR(q), et
2
= f
Y
()
(e
i
)
2
.
Donc :
f
Y
() =
2
1
[(e
i
)[
2
,
de telle sorte que
f
Y
() =
1
f
X
()
2
2
2
=
4
2
.
6.6.2 Le processus MA(1)
La forme gnrale des processus de type MA(1) est
X
t
=
t
+
t1
, pour tout t Z,
o (
t
) est un bruit blanc de variance
2
. Les autocorrlations sont donnes par
(1) =
1 +
2
, et (h) = 0, pour h 2.
On peut noter que 1/2 (1) 1/2 : les modles MA(1) ne peuvent avoir de fortes
autocorrlations lordre 1.
Lautocorrlation partielle lordre h est donne par
(h) =
(1)
h
h
(
2
1)
1
2(h+1)
,
et plus gnrallement, les coecients de rgression sont donns par
a
i
(h) =
(1)
i
i
1
2h+2
+
(1)
i
2h+2i
1
2h+2
,
dans le cas o ,= 1.
On peut visualiser cette autocorrlation sur les nuages de points (X
t1
, X
t
), (X
t2
, X
t
),
etc, pour un processus MA(1) avec > 0
> X=arima.sim(n = 240, list(ma = 0.8),sd = 1)
> plot(X)
> n=240;h=1
> plot(X[1:(n-h)],X[(1+h):n])
> library(ellipse)
> lines(ellipse(.8/(1+.8^2)), type = l,col="red")
116
La densit spectrale dun processus MA(1) est de la forme
f
X
() =
2
2
__
1 +
2
_
+ 2 cos
,
correspondant un trend dterministe, auquel vient sajouter une constante. De cette
dernire expression, on peut en dduire aisment que les autocorrlations inverses, dans
117
le cas dun processus MA(1) vrient
i (h) =
_
1 +
2
_
h
pour tout h 1.
> X=arima.sim(n = 2400, list(ma = .7),sd = 1)
> plot(acf(X),lwd=5,col="red")
> plot(pacf(X),lwd=5,col="red")
> X=arima.sim(n = 2400, list(ma = -0.7),sd = 1)
> plot(acf(X),lwd=5,col="red")
> plot(pacf(X),lwd=5,col="red")
Remarque 166. Les graphiques ci-dessous reprsentent des simulations de processus
MA(1), avec dirents coecients , repectivement, de gauche droite 0, 1, 2, 5,1
et 2
Comme on peut le voir, ces processus sont toujours stationnaires, quel que soit .
A retenir 167.
MA(1) :
_
_
Fonction dautocorrlation
_
premire non nulle (signe = signe de )
toutes nulles aprs
Fonction dautocorrlation partielle
_
> 0 dcroissance exponentielle
< 0 sinusode amortie
6.6.3 Le processus MA(2)
La forme gnrale de (X
t
) suivant un processus MA(2) est
X
t
=
t
+
1
t1
+
2
t2
.
La fonction dautocorrlation est donne par lexpression suivante
(h) =
_
_
_
1
[1 +
2
] / [1 +
2
1
+
2
2
] pour h = 1
2
/ [1 +
2
1
+
2
2
] pour h = 2
0 pour h 3,
118
et la densit spectrale est donne par
f
X
() =
1 +
1
e
i
+
2
e
2i
2
.
Les congurations possibles sont donnes dans les 2 exemples ci-dessous
> X=arima.sim(n = 2400, list(ma = c(0.7,0.9)),sd = 1)
> plot(acf(X),lwd=5,col="red")
> plot(pacf(X),lwd=5,col="red")
> X=arima.sim(n = 2400, list(ma = c(0.7,-0.9)),sd = 1)
> plot(acf(X),lwd=5,col="red")
> plot(pacf(X),lwd=5,col="red")
> X=arima.sim(n = 2400, list(ma = c(0.7,-0.9)),sd = 1)
> plot(acf(X),lwd=5,col="red")
> plot(pacf(X),lwd=5,col="red")
6.7 Les processus ARMA(p, q)
Cette classe de processus gnralise les processus AR(p) et MA(q) .
Dnition 168. On appelle processus ARMA(p, q), un processus stationnaire (X
t
) vri-
ant une relation du type
X
t
i=1
i
X
ti
=
t
+
q
j=1
ti
pour tout t Z, (26)
119
o les
i
sont des rels et (
t
) est un bruit blanc de variance
2
. (22) est quivalent
lcriture
(L) X
t
= (L)
t
o
_
(L) = I +
1
L + ... +
q
L
q
(L) = I
1
L ...
p
L
p
On supposera de plus de les polymes et nont pas de racines en module strictement
suprieures 1 (criture sous forme canonique), et nont pas de racine commune. On
supposera de plus que les degrs de et sont respectivement q et p, au sens o
q
,= 0
et
p
,= 0. On dira dans ce cas que cette criture est la forme minimale.
Les processus ARMA(p, q) peuvent donc se mettre
(i) sous la forme MA() en crivant X
t
= (L)
1
(L)
t
, si toutes les racines de
sont lextrieur du disque unit.
(ii) ou sous forme AR() en crivant (L) (L)
1
X
t
=
t
, si toutes les racines de
sont lextrieur du disque unit.
Remarque 169. Un processus AR(p) est un processus ARMA(p, 0) et un processus
MA(q) est un processus ARMA(0, q) .
6.7.1 Proprits des autocorrlations
Proposition 170. Soit (X
t
) un processus ARMA(p, q), alors les autocovariances (h)
satisfont
(h)
p
i=1
i
(h i) = 0 pour h q + 1. (27)
Proof. La forme ARMA(p, q) de (X
t
) est
X
t
j=1
j
X
tj
=
t
+
q
j=1
tj
En multipliant par X
th
, o h q + 1, et en prenant lesprance, on obtient (27).
De plus, on a la relation suivante
Proposition 171. Soit (X
t
) un processus ARMA(p, q), alors les autocorrlations (h)
satisfont
(h)
p
i=1
i
(h i) =
2
[
h
+ h
1
h+1
+ ... + h
qh
q
] pour 0 h q, (28)
o les h
i
correspondent aux coecients de la forme MA() de (X
t
),
X
t
=
+
j=0
h
j
tj
.
120
Exemple 172. Les sorties ci-dessous correspondent aux autocorrlogrammes de processus
ARMA(2, 1), ARMA(1, 2) et ARMA(2, 2) respectivement de gauche droite
Pour tablir une rgle quant au comportement de la fonction dautocorrlation, deux
cas sont envisager,
Si p > q, la fonction dautocorrlation se comporte comme un mlange de fonctions
exponentielles/sinusodales amorties
Si q p, le qp+1 premires valeurs de lautocorrlogramme ont un comportement
propre, et pour k q p + 1, lautocorrlogramme tend vers 0.
Des proprits symtriques existent pour lautocorrlogramme partiel.
Remarque 173. Avec les notations (26), la variance de X
t
est donne par
V (X
t
) = (0) =
1 +
2
1
+ ... +
2
q
+ 2
1
1
+ ... +
h
h
1
2
1
...
2
p
2
o h = min (p, q) .
6.7.2 Densit spectrale des processus ARMA(p, q)
Proposition 174. La densit spectrale du processus ARMA (X
t
) stationnaire est une
fraction rationnelle en exp (i), et est donne par
f
X
() =
2
2
[(exp [i])[
2
[(exp [i])[
2
.
6.7.3 Les processus ARMA(1, 1)
Soit (X
t
) un processus ARMA(1, 1) dni par
X
t
X
t1
=
t
+
t1
, pour tout t,
o ,= 0, ,= 0, [[ < 1 et [[ < 1. Ce processus peut de mettre sous forme AR(),
puisque
(1 L) (1 + L)
1
X
t
= (L) X
t
=
t
,
o
(L) = (1 L)
_
1 L +
2
L
2
+ ... + (1)
h
h
L
h
+ ..
_
,
aussi
(L) =
+
i=0
i
L
i
o
_
0
= 1
i
= (1)
i
[ + ]
i1
pour i 1.
La fonction dautocorrlation scrit
_
(1) = (1 + ) ( + ) / [1 +
2
+ 2]
(h) =
h
(1) pour h 2,
et la fonction dautocorrlations partielles a le mme comportement quune moyenne mo-
bile, avec comme valeur initiale a (1) (1). La sortie ci-dessous montre lvolution de
lautocorrlogramme dans le cas dun ARMA(1, 1)
121
> X=arima.sim(n = 2400, list(ar=0.6, ma = 0.7),sd = 1)
> plot(acf(X),lwd=5,col="red")
> plot(pacf(X),lwd=5,col="red")
A retenir 175.
ARMA(1, 1) :
_
Fonction dautocorrlation dcroissance aprs le premier retard
Fonction dautocorrlation partielle dcroissance exponentielle ou sinusode amortie
6.8 Introduction aux modles linaires non-stationnaires
Tous les processus dcrits dans les parties prcdantes sont des processus stationnaires
(X
t
). En fait, la plupart des rsultats obtenus dans les parties prcdantes reposent sur
lhypothse (trs forte) de stationnarit. Cest le cas par exemple de la loi des grands
nombres telle quelle est formule dans le thorme ergodique. On peut toutefois noter
quun certain nombre de processus, trs simples, sont non-stationnaires.
Exemple 176. Marche alatoire - La marche alatoire est dnie de la faon suivante
: soit
1
, ...,
t
, ... une suite de variables i.i.d. et on supposera que
t
ademet une variance
nie, note
2
. On supposera galement les
t
centrs. Une marche alatoire Y
t
vrie
Y
t
= Y
t1
+
t
, pour tout t,
avec la convention Y
0
= 0. On peut noter que Y
t
= Y
0
+ Y
1
+ ... + Y
t1
. On a alors
_
E(Y
t
) = 0
V (Y
t
) =
2
t
, cov (Y
s
; Y
t
) =
2
(s t) et corr (Y
s
, Y
t
) =
s t
st
pour s, t 0.
En notant T
t
la ltration gnre par les Y
0
, ..., Y
t
, cest dire T
t
= Y
0
, ..., Y
t
, on peut
montrer que
E(Y
s
[T
t
) = Y
t
pour tout s t 0.
Aussi, le processus (Y
t
), muni de sa ltration naturelle, est une martingale. La marche
alatoire est stationnaire en moyenne, mais pas en variance. La non stationnarit de
cette srie pose de gros problme statistique : considrons par exemple la moyenne dnie
sur les n premires observations, soit
Y
n
=
1
n
n
t=1
Y
t
,
alors, de faon triviale, E
_
Y
n
_
= 0 mais V
_
Y
n
_
= O(n) . Plus prcisment, la variance
de cette moyenne est
V
_
Y
n
_
=
2
n(n + 1) (2n + 1)
6n
2
.
122
Exemple 177. Tendance linaire -Un processus tendance linaire est dni de la
faon suivante : soit
1
, ...,
t
, ... une suite de variables i.i.d. et on supposera que
t
ademet
une variance nie, note
2
. On supposera galement les
t
centrs. Une tendance linaire
Y
t
vrie
Y
t
= t +
t
pour tout t, o R.
Ce processus vrie
_
E(Y
t
) = t
V (Y
t
) =
2
cov (Y
s
; Y
t
) = corr (Y
s
, Y
t
) = 0 pour s, t 0,
et E(Y
s
[T
t
) = s pour tout s t 0. Cest dire que ce processus nest pas une
martingale, et les variables du processus sont indpendantes (au sens non-corrles). En
notant comme prcdemment Y
n
.la moyenne des n premires observations, on a
E
_
Y
n
_
=
n + 1
2
et V
_
Y
n
_
=
2
n
0 quand n .
Exemple 178. March alatoire avec drift - Ce processus est dni comme mlange
des deux prcdants : soit X
t
une marche alatoire, soit X
t
= X
t1
+
t
, alors Y
t
, marche
alatoire avec drift, est dni par
Y
t
= t + X
t
pour tout t, o R
= [ +
1
] + [ +
2
] + ... + [ +
t
] .
On a alors les proprits suivantes
_
E(Y
t
) = t
V (Y
t
) =
2
t
cov (Y
s
; Y
t
) =
2
(s t) et corr (Y
s
, Y
t
) =
s t
st
pour s, t 0,
et E(Y
s
[T
t
) = s + X
t
= [s t] + Y
t
pour tout s t 0.
Les processus stationnaires ayant beaucoup de proprits, il peut apparaitre intressant
de trouver une transformation simple du processus non-stationnaire que le rendrait
stationnaire. La mthode la plus courament utilise est de prendre des dirences :
Exemple 179. Marche alatoire - Soit (Y
t
) une marche alatoire,
Y
t
= Y
t1
+
t
, pour tout t,
alors Z
t
= Y
t
Y
t1
est stationnaire (et Z
t
=
t
).
Exemple 180. Tendance linaire - Une tendance linaire Y
t
vrie
Y
t
= t +
t
, pour tout t, o R,
alors Z
t
= Y
t
Y
t1
= +
t
t1
: il sagit dun processus MA(1) (non inversible,
mais stationnaire comme tout processus MA).
Exemple 181. March alatoire avec drift - Soit Y
t
, marche alatoire avec drift,
Y
t
= t + X
t
= [ +
1
] + [ +
2
] + ... + [ +
t
] ,
alors Z
t
= Y
t
Y
t1
= + X
t
X
t1
= +
t
est stationnaire.
Cest cette importance de la direnciation (dont lintgration est lopration duale)
qui a permis de passer des modles ARMA aux modles ARIMA.
123
6.9 Les processus ARIMA(p, d, q)
Lhypothse de stationnarit, prsente - sous certaines conditions - dans les modles
ARMA, nest que rarement vrie pour des sries conomiques. En revanche, on peut
considrer les dirences premires X
t
= X
t
X
t1
, ou des dirences des ordres plus
levs
_
X
t
= X
t
X
t1
= (1 L) X
t
d
X
t
= (1 L)
d
X
t
Dnition 182. Un processus (X
t
) est un processus ARIMA(p, d, q) - autorgressif
moyenne mobile intgr - sil vrie une quation du type
(L) (1 L)
d
X
t
= (L)
t
pour tout t 0
o
_
(L) = I
1
L
2
L
2
+ ...
p
L
p
o
p
,= 0
(L) = I +
1
L +
2
L
2
+ ... +
q
L
q
o
q
,= 0
sont des polynmes dont les racines sont de module suprieur 1, et o les conditions
initiales
Z
1
= X
1
, ..., X
p
,
1
, ...,
q
sont non-corrles avec
0
, ...,
t
, ... et o le processus (
t
) est un bruit blanc de variance
2
.
Remarque 183. Si les processus ARMA peuvent tre dnis sur Z, il nen est pas
de mme pour les processus ARIMA qui doivent commencer une certaine date
(t = 0 par convention), avec des valeurs initiales (q valeurs pour les
t
, et p + d pour
X
t
). En eet, si lon considre un processus X
t
, ARIMA(0, 1, 0) (= marche alatoire),
soit (1 L) X
t
=
t
. On peut crire
X
t
= X
0
+
t
k=1
k
mais pas X
t
=
t
k=
k
car cette somme ne converge pas dans L
2
. Cette importance de linitialisation peut se
comprendre sur les graphique ci-dessous : considrer un processus AR(1) simul (ou un
processus ARMA de faon plus gnrale), partir de la date t = 0 : on peut noter qu
relativement court terme les processus (X
t
) et (Y
t
) simuls respectivement partir de x et
y sont indentiques : L(X
t
) = L(Y
t
), les deux processus ont la mme loi, quelle que soit
la valeur initiale (i.e. une loi normale dans le cas dun bruit blanc gaussien).
En revanche, pour un processus ARIMA(1, 1, 0) - cest dire un processus AR(1)
intgr, la valeur initiale est trs importante : pour deux valeurs initiales direntes, les
deux processus nont pas la mme loi L(X
t
) ,= L(Y
t
),
Les deux processus intgrs, droite, ont sensiblement des lois direntes la date t.
124
Remarque 184. Soit Y
t
un processus intgr dordre d, au sens o il existe (X
t
) station-
naire tel que Y
t
= (1 L)
d
X
t
satisfaisant (L) Y
t
= +(L)
t
Alors, (Y
t
) nest pas un
processus ARMA car il ne commence pas en . En fait, (Y
t
) est asymptotiquement
quivalent un processus stationnaire ARMA.
Proposition 185. Soit (X
t
) un processus ARIMA(p, d, q) alors le processus
_
d
X
t
_
converge vers un processus ARMA(p, q) stationnaire.
6.9.1 Processus ARIMA et formes AR ou MA
Proposition 186. Soit (X
t
) un processus ARIMA(p, d, q) de valeurs initiales Z
1
, alors
(i) (X
t
) peut scrire sous la forme suivante, fonction du pass du bruit,
X
t
=
t
j=1
h
j
tj
+ h
(t) Z
1
,
o les h
j
sont les coecients de la division selon les puissances croissantes de par ,
et h
(t) est un vecteur (ligne) de fonctions de t
(ii) (X
t
) peut scrire sous la forme suivante, fonction du pass de X
t
X
t
=
t
j=1
j
X
tj
+ h
(t) Z
1
+
t
,
o les
j
sont les coecients (pour j 1) de la division selon les puissances croissantes
de par , et h
(t) est un vecteur (ligne) de fonctions de t quand tend vers 0 quand
t .
Proof. (ii) La division selon les puissances croissantes de I par scrit, lordre t,
I =Q
t
(Z) (Z) + Z
t+1
R
t
(Z) o deg (Q
t
) = t et deg (R
t
) q 1.
Posons (L) = (1 L)
d
(L). Alors lquation (L) X
t
= (L)
t
peut scrire, en
multipliant par Q
t
(Z),
Q
t
(Z) (L) X
t
= Q
t
(Z) (L)
t
=
_
IL
t+1
R
t
(L)
t
=
t
R
t
(L)
1
.
En posant
t
(L) = Q
t
(Z) (L) (de degr p + d + t ni ) on peut crire
t
(L) X
t
=
t
R
t
(L)
1
, soit
p+d+t
j=0
j
X
tj
=
t
q1
j=0
r
j
1j
,
cest dire, en coupant la premire somme,
t
j=0
j
X
tj
=
t
t+p+d
j=t+1
j
X
tj
q1
j=0
r
j
1j
. .
h
(t)Z
1
.
125
6.10 Les modles SARIMA
Les modles SARIMA peuvent vus comme une gnralisation des modles ARIMA,
contenant une partie saisonnire.
Dnition 187. De faon gnrale, soient s
1
, ..., s
n
n entiers, alors un processus (X
t
)
est un processus SARIMA(p, d, q) - autorgressif moyenne mobile intgr saisonnier -
sil vrie une quation du type
(L) (1 L
s
1
) ... (1 L
sn
) X
t
= (L)
t
pour tout t 0
o (L) = I
1
L
2
L
2
+ ...
p
L
p
o
p
,= 0 et (L) = I +
1
L +
2
L
2
+ ... +
q
L
q
o
q
,= 0.sont des polynmes dont les racines sont de module suprieur 1, et o les
conditions initiales
Z
1
= X
1
, ..., X
p
,
1
, ...,
q
sont non-corrles avec
0
, ...,
t
, ... et o le processus (
t
) est un bruit blanc de variance
2
.
Cette forme inclue les modles ARIMA puisquil sut de prendre n = d et s
1
= ... =
s
n
= 1. Toutefois, les deux formes les plus utilises sont les suivantes,
(L) (1 L
s
) X
t
= (L)
t
pour tout t 0
(L) (1 L
s
) (1 L)
d
X
t
= (L)
t
pour tout t 0
o un seul facteur saisonnier s intervient, soit appliqu un processus ARMA dans le
premier cas, soit appliqu un processus ARIMA dans le second cas.
Exemple 188. Soit S N0 correspondant la saisonnalit, et considrons le proces-
sus dni par
X
t
= (1 L)
_
1 L
S
_
t
=
t
t1
tS
+
tS1
.
Les autocorrlations sont donnes par
(1) =
(1 +
2
)
(1 +
2
) (1 +
2
)
=
1 +
2
,
(S 1) =
(1 +
2
) (1 +
2
)
,
(S) =
(1 +
2
)
(1 +
2
) (1 +
2
)
=
1 +
2
,
(S + 1) =
(1 +
2
) (1 +
2
)
,
et (h) = 0 ailleurs. On peut noter que (S 1) = (S + 1) = (1) (S) . Le graphique
suivant montre lautocorrlogramme (empirique) dun tel processus simul
Pour les autocorrlations partielles, jusquen S 2 (inclus), la fonction
dautocorrlation partielle est celle dun MA(1) de paramtre , puis la fonction est sig-
nicative en S 1, S et S + 1.
126
Exemple 189. Soit S N0 correspondant la saisonnalit, et considrons le proces-
sus dni par
_
1 L
S
_
X
t
= (1 L)
_
1 L
S
_
t
ou X
t
X
t1
=
t
t1
tS
+
tS1
.
Les autocorrlations sont donnes par
(1) =
(1 +
2
)
(1 +
2
) (1 +
2
)
=
1 +
2
,
(S 1) =
_
( )
2
/ (1
2
)
(1 +
2
)
_
1 + ( )
2
/ (1
2
)
,
(S) =
(1 +
2
)
S1
,
avec (h) = 0 pour 2 h S 2, puis (S + 1) = (S 1) et (h) = (h S)
pour h S + 2. En particulier (kS) =
k1
(S) . Le graphique suivant montre
lautocorrlogramme (empirique) dun tel processus simul
Exemple 190. Soit S N0 correspondant la saisonnalit, et considrons le proces-
sus dni par
(1 L)
_
1 L
S
_
X
t
=
t
ou X
t
X
t1
X
tS
+ X
tS1
=
t
.
Les autocorrlations partielles sont non nulles en 1, S et S + 1. De plus la fonction
dautocorrlation vrie lquation de rcurence
(h) (h 1) (h S) + (h S 1) = 0,
qui a pour polynme caractristique (z )
_
z
S
_
, qui a pour racines et les racines
S-imes de . Le graphique suivant montre lautocorrlogramme (empirique) dun tel
processus simul
Exemple 191. Soit S N0 correspondant la saisonnalit, et considrons le proces-
sus dni par
X
t
=
_
1 L L
S
t
=
t
t1
tS
.
On se retrouve dans un cadre assez proche de celui dvelopp dans lexemple (188), et lon
obtient la fonction dautocorrlation suivante
(1) =
1 +
2
+
2
, (S 1) =
1 +
2
+
2
et (S) =
1 +
2
+
2
.
Le graphique suivant montre lautocorrlogramme (empirique) dun tel processus simul
127
Exemple 192. Soit S N0 correspondant la saisonnalit, et considrons le proces-
sus dni par
X
t
=
_
1 L L
S
L
S+1
t
=
t
t1
tS
.
On se retrouve dans un cadre assez proche de celui dvelopp dans lexemple prcdant, et
lon obtient la fonction dautocorrlation suivante
(1) =
+
1 +
2
+
2
+
2
, (S 1) =
1 +
2
+
2
+
2
,
(S) =
1 +
2
+
2
+
2
et (S + 1) =
1 +
2
+
2
+
2
.
Le graphique suivant montre lautocorrlogramme (empirique) dun tel processus simul
Htrsoscdasticit et transformation de la variable X
t
Pour linstant, la non-stationnarit de la srie tait vu en supposant que la srie tait
intgr, ou saisonnire. Mais il est possible davoir une variance qui augemente sans pour
autant avoir supposer la srie comme tant intgre.
Comme pour les modles de rgression sur donnes individuelles, il peut tre intres-
sant de modliser non pas X, mais une transformation de cette variable, e.g. log X. Et
l encore, il est lgitime dessayer des transformations puissances, de type Box-Cox.
Considrons la srie de production dlecticit, par mois, aux Etats-Unis,
> library(Ecdat)
> data(electricity)
> plot(electricity)
Compte tenu de lhtroscdasticit de la srie
> plot(log(electricity))
128
Considrons de manire plus gnrale une transformation de type Box-Cox
g
(x) =
x
avec le cas limite g
0
(x) = log(x).
> BoxCox.ar(electricity)
6.11 Thorme de Wold
Thorme 193. Tout processus (X
t
), centr, et stationnaire au second ordre, peut tre
reprsent sous une forme proche de la forme MA
X
t
=
j=0
tj
+
t
,
o
(1) (
t
) est linnovation, au sens o
t
= X
t
EL(X
t
[X
t1
, X
t2
, ...) ,
129
(2) EL(
t
[X
t1
, X
t2
, ...) = 0, E(
t
X
tj
) = 0, E(
t
) = 0, E(
2
t
) =
2
(indpendant
de t) et E(
t
s
) = 0 pour t ,= s,
(3) toutes les racines de (L) sont lextrieur du cercle unit : le polynome est
inversible,
(4)
j=0
2
j
< et
0
= 1,
(5) les coecients
j
et le processus (
t
) sont uniques,
(6) (
t
) vrie
t
= EL(
t
[X
t1
, X
t2
, ...) .
La proprit (1) signie que (
t
) est lestimation de X
t
comme combinaison linaire
des valeurs passes, et (2) est simplement lcriture des conditions dorthogonalit de la
projection. La proprit (4) est une consquence de la stationnarit du processus Ce
thorme se dmontre avec les direntes proprits des espaces de Hilbert. Ce thorme
dit juste que (X
t
) peut tre crit comme une somme des erreurs de prvision.
Remarque 194. Ce thorme ne dit pas que les
t
suivent une loi normale, ou que les
t
sont i.i.d. (ils ont la mme variance et sont non-corrls).
Remarque 195. La proprit (2) dit que EL(
t
[X
t1
, X
t2
, ...) = 0, ce qui ne sig-
nie pas que E(
t
[X
t1
, X
t2
, ...) = 0. Lcriture EL(Y [X
t1
, X
t2
, ...) signie que
lon recherche la meilleure approximation de Y comme combinaison linaire du
pass de X
t
,
1
X
t1
+
2
X
t2
+ ... +
h
X
th
+ .... Lesprance conditionnelle
E(Y [X
t1
, X
t2
, ...) est elle la meilleure approximation de Y comme fonction du pass
de X
t
, g (X
t1
, X
t2
, ..., X
th
, ..), o g nest pas ncessairement linaire.
Remarque 196. Cette reprsentation nest unique que parce que lon a les direntes
conditions, en particulier (1) et (3). Par exemple, un processus de la forme X
t
=
t
+2
t1
o (
t
) est i.i.d. et de variance 1, est stationnaire. Mais sous cette forme, le polynme
MA nest pas inversible. Pour trouver la reprsentation de Wold de ce processus, on va
chercher et
t
tels que X
t
=
t
+
t1
. On peut alors montrer que V (
t
) = 2/ et que
est ncessairement soit gal 2, soit gal 1/2. Le cas = 2 et V (
t
) = 1 correspond
lcriture initiale. Mais = 1/2 et V (
t
) = 4 marche galement, et le polynme MA est
alors inversible (comme nous lavons vu prcdement, il est toujours possible de rcrire
un processus MA ou AR de faon inversible, condition de changer la variance du bruit).
Cette reprsentation est alors la rpresentation de Wold.
Remarque 197. Ce thorme peut scrire de faon plus simple si lon nest pas intress
par lunicit de lcriture : tout processus (X
t
) stationnaire peut se mettre sous forme
MA(),
X
t
= +
j=0
tj
.
6.12 Thorie spectrale et processus ARIMA
Comme le rappelle Bourbonnais (1998), lanalyse des sries temporelles dans le dommaine
des frquences (ou analyse spectrale) est souvent plus riche en terme dinterprtation,
130
mais ncessite un recours des techniques mathmatiques plus complexes. Le principe
de base de lanalyse de Fourier est que toute fonction analytique dnie sur un intervalle
(ni ) de R peut scrire comme somme pondre de fonctions sinus et cosinus.
6.12.1 Thorie spectrale et notion de ltre
Thorie spectrale Lanalyse spectrale, ou analyse harmonique, est une gnralisation
au cas alatoire de lanalyse de Fourier. Cette analyse sappuie sur deux rsultats de base :
le thorme de Loeve et le thorme de Khintchine. Le premier prsente la dcomposition
harmonique de (X
t
) sous la forme
X
t
=
_
+
exp (i2t) dU
Z
() ,
dans laquelle les dU
Z
() sont des variables alatoires (complexes), alors que le second est
quivalent au prcdant, mais porte sur la fonction dautocovariance de (X
t
),
(h) =
_
+
exp (i2h) E
_
[dU
Z
()[
2
_
.
Thorme 198. (de Khintchine) La densit spectrale de puissance dun processus ala-
toire stationnaire est gale la transforme de Fourier de sa fonction dautocorrlation
On a alors lcriture suivante
f
X
() =
1
2
+
h=
(h) e
ih
ou (h) =
_
0
e
ih
f
X
() d, o (h) = cov (X
t
, X
th
) ,
avec f
X
() densit spectrale du processus (X
t
).
Filtre et processus strochastiques Etant donn un processus (X
t
), un ltre est une
transformation qui associe au processus (X
t
) un autre processus Y
t
= F (X
t
). Par exemple,
on dira quun ltre est linaire si F (X
1
t
+ X
2
t
) = F (X
1
t
) + F (X
2
t
).
De faon gnrale, on pourra considrer les ltres linaires de la forme suivante
F (X
t
) =
iZ
(i) X
t+i
,
o les (i) sont les coecients de pondration, cest dire des ltres moyennes mobiles.
Considrons ainsi une fonction dnie sur Z et valeurs dans R (ou C), appartenant
lespace des fonctions de carr intgrable sur R, alors admet une transforme de Fourier,
note A() appele fonction de rponse en frquence du ltre :
A() =
_
+
(t) e
it
dt ou (t) =
1
2
_
+
A() e
it
d.
On appelera gain du ltre le carr de la norme de la fonction de rponse, T () = [A()[
2
.
131
6.12.2 Le spectre dun processus ARMA
Daprs le thorme de Wold, un processus stationnaire est une combinaison linaire innie
des valeurs passes dun bruit blanc, cest dire quil peut scrire comme un processus
MA() :
X
t
= (L)
t
=
+
k=0
tk
o
0
= 1.
Cest dire que (X
t
) est la rponse un ltre dun processus (
t
), bruit blanc (la stabilit
tant assure par la convergence de la somme des carrs de
i
). Les
i
sont alors la fonction
de rponse impulsionnelle du ltre. La fonction de gain du ltre scrit
T () = [A()[
2
=
k=0
i
e
ik
2
,
avec A() correspondant la fonction de rponse en frquence au ltre. On a alors la
relation suivante entre les spectres des deux processus,
f
X
() = T () f
() .
Or, le spectre du bruit blanc vrie f
() =
2
/2, et donc
f
X
() =
2
k=0
k
e
ik
2
=
2
_
e
ik
_
2
.
De faon gnrale et analogue, on a le rsultat suivant pour les processus ARMA,
Proposition 199. Soit (X
t
) un processus ARMA(p, q), vriant (L) X
t
= (L)
t
,
sous forme canonique minimal, avec les racines de et de lextrieur du disque unit
alors
X
t
=
(L)
(L)
t
et f
X
() =
2
_
e
ik
_
2
[(e
ik
)[
2
.
Cette criture peut scrire sous la forme expense suivante
f
X
() =
2
2
[1 +
1
e
i
+
2
e
2i
+ ... +
q
e
qi
[
2
[1
1
e
i
2
e
2i
...
p
e
qi
[
2
.
Compte tenu du lien entre la densit spectrale et la fonction dautocorrlation, il est
possible dobtenir la densit spectrale dans plusieurs cas simples.
Exemple 200. Considrons le processus MA(1) suivant : X
t
=
t
+
t1
o (
t
) suit un
bruit blanc de variance
2
. Pour mmoire, les autocovariances sont donnes par (0) =
(1 +
2
)
2
, (1) =
2
et (h) = 0 pour h 2. Ainsi,
f () =
1
_
(0) + 2
+
k=1
(k) cos (k)
_
=
2
(1 + 2 cos () +
2
)
.
132
Exemple 201. Considrons le processus AR(1) suivant : X
t
= X
t1
+
t
o (
t
) suit un
bruit blanc de variance
2
. Pour mmoire, les autocovariances sont donnes par (0) =
2
/ [1
2
], et (h) = (h 1) pour h 1. Ainsi, (h) =
h
(0) pour h 1. Cette
criture permet dobtenir la relation suivante
f () =
1
_
(0) + 2
+
k=1
(k) cos (k)
_
=
(0)
_
1 +
+
k=1
k
_
e
ik
+ e
ik
_
=
(0)
_
1 +
e
ik
1 e
ik
+
e
ik
1 e
ik
_
=
2
[1 2cos () +
2
]
.
ce qui donne une fonction dcroissante pour > 0 et croissante pour < 0.
Exemple 202. Considrons le processus AR(2) suivant : X
t
= X
t1
+ X
t2
+
t
o
(
t
) suit un bruit blanc de variance
2
. Le polynme AR scrit (L) = 1LL
2
dont
il faut sassurer que les racines sont lextrieur du disque unit. Le spectre du processus
(X
t
) scrit alors
f
X
() =
2
2
1
1 +
2
+
2
2(1 ) cos 2cos 2
.
Considrons le cas particulier o X
t
= 0.9X
t1
0.4X
t2
+
t
avec
2
= 1,
f
X
() =
1
2
1
1.97 2.52 cos + 0.8 cos 2
,
dont le tableau de variation est
/2 0 0.212 1
f
0 + 0
f 8 11.25 0.38
Les graphiques suivants donnent les volutions de densits spctrales pour dirents
processus ARMA. Les graphiques ci-dessous correspondent des processus AR(1), avec
= 0.8 gauche, puis = 0.2 et 0.5 droite, avec des courbes dcroissantes quand
0 et croissantes quand 0,
6.12.3 Estimation de la densit spectrale dun processus
Supposons que nous ayons T observations dune srie temporelle, avec T impair, soit
T = 2m + 1. On dni les frquences (dites parfois de Fourier)
j
= 2j/T pour
j = 1, ..., m. Considrons alors le modle de rgression
Y
t
=
0
+
m
j=1
j
cos (
j
t) +
m
j=1
j
sin (
j
t) ,
133
qui peut tre crit sous forme de modle linaire Y = X + , avec
Y =
_
_
_
Y
1
.
.
.
Y
T
_
_
_
, X =
_
_
_
1 cos (
1
) sin (
1
) cos (
m
) sin (
m
)
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
1 cos (
1
T) sin (
1
T) cos (
m
T) sin (
m
T)
_
_
_
, =
_
_
_
_
_
_
_
_
_
1
.
.
.
m
_
_
_
_
_
_
_
_
_
et =
_
_
_
1
.
.
.
T
_
_
_
.
Lestimation de par la mthode des moindres carrs donne
= (X
X)
1
X
Y . Compte
tenu des proprits suivantes
T
t=1
cos (
j
t) =
T
t=1
sin (
j
t) = 0,
T
t=1
cos
2
(
j
t) =
T
t=1
sin
2
(
j
t) =
T
2
pour tout j, (29)
et
T
t=1
cos (
j
t) sin (
k
t) =
T
t=1
cos (
j
t) cos (
k
t) =
T
t=1
sin (
j
t) sin (
k
t) = 0 pour j ,= k,
(30)
on peut montrer aisment que
=
_
_
_
_
_
_
_
_
_
0
1
1
.
.
.
m
m
_
_
_
_
_
_
_
_
_
=
_
_
_
_
_
T 0 0
0 T/2 0
.
.
.
.
.
.
.
.
.
0 0 T/2
_
_
_
_
_
1
_
_
_
_
_
Y
t
cos (
1
t) Y
t
.
.
.
sin (
m
t) Y
t
_
_
_
_
_
=
_
_
_
_
_
Y = 1/T.
Y
t
2/T.
cos (
1
t) Y
t
.
.
.
2/T.
sin (
m
t) Y
t
_
_
_
_
_
,
et la variance empirique des observations (Y
t
) est donne ( un facteur 1/T prs) par
T
t=1
_
Y
t
Y
_
2
=
m
j=1
2
T
_
_
_
T
t=1
cos (
j
t) Y
t
_
2
+
_
T
t=1
sin (
j
t) Y
t
_
2
_
_
.
Tout ceci permet de dnir le priodogramme I () de la faon suivante
I () =
1
T
_
_
_
T
t=1
cos (t) Y
t
_
2
+
_
T
t=1
sin (t) Y
t
_
2
_
_
.
Dans cette expression, un facteur 1/2 a t introduit de telle sorte que la variance
empirique, donne par
(0) =
1
T
T
t=1
_
Y
t
Y
_
,
134
soit gale la somme des aires des m rectangles, de hauteur I (
1
) , ..., I (
m
), et de base
2/T. La somme des aires de ces rectangles approxime laire sous la courbe I () pour
0 ,
En utilisant (29) et (30) on peut crire
I (
j
) =
1
(0) +
2
T1
k=1
(k) cos (
j
k) .
Cette fonction I () est alors la version discrte et empirique de la densit spectrale f ().
Proposition 203. Si le processus est stationnaire, et si la densit spectrale existe, alors
I () est un estimateur sans biais de f () .
Supposons que (Y
t
) soit un bruit blanc gaussien, cest dire Y
1
, ..., Y
T
sont i.i.d. et
distribus suivant une loi N (0,
2
). Pour toute frquence de Fourier, = 2j/T,
I () =
1
T
_
A()
2
+
B()
2
_
o
A() =
T
t=1
Y
t
cos (t) et
B() =
T
t=1
Y
t
sin (t) .
Il est facile de montrer que
A() et
B() sont centrs, et dont les variance sont donnes
par
V
_
A()
_
=
2
T
t=1
cos
2
(t) = T
2
2
et V
_
B()
_
=
2
T
t=1
sin
2
(t) = T
2
2
,
et dont la covariance est nulle
cov
_
A() ,
B()
_
= E
_
T
s,t=1
Y
s
Y
t
cos (s) sin (t)
_
=
2
_
T
t=1
cos (t) sin (t)
_
= 0.
De plus,
A() /
2T
2
et
B() /
2T
2
sont indpendant, et asymptotiquement
distribus suivant une la mme loi, normale, centre et rduite. Et donc,
2
_
A()
2
+
B()
2
_
/T
2
est asyptotiquement distribu suivant une loi du chi-deux,
2 degrs de libert. Aussi, I () (
2
/)
2
(2) /2, ce qui montre bien que I ()
est un estimateur sans biais de f () =
2
/, mais il nest pas consistant puisque
V (I ()) =
4
/
2
0 quand T .
Proposition 204. Soit (Y
t
) un processus gaussien , de spectre f () Soit I (.) le pri-
odogramme obtenu partir de lchantillon Y
1
, ..., Y
T
, posons
j
les frquences de Fourier,
au sens o
j
= 2j/T pour j < T/2. Dans ce cas, quand T ,on a les rsultats
suivants;
(i) I (
j
) f (
j
) .
2
(2) /2
(ii) I (
j
) et I (
k
) sont indpendant pour j ,= k.
135
Remarque 205. La mthode de calcul des I (
1
) , ..., I (
m
) prsent dans cette partie
ncessite de lordre de T
2
oprations. La Fast Fourier Transform permet daugmenter les
temps de calcul puisque seulement T log
2
T oprations sont ncessaires (le gain en temps
est alors en T/ log
2
T : pour 100 observations, les calculs sont alors 15 fois plus rapides).
Remarque 206. Considrons la srie (X
t
) dnie par X
t
= 5 cos (t/36)+7 sin (t/12)+
t
o
t
N (0, 1), reprsente ci-dessous gauche. Sa densit spectrale est reprsente ci-
dessous On note deux maximums locaux, aux priodes 110 et 35 (correspondants aux
paramtres 1/36 et 1/12).
136
7 Estimation des modles ARIMA : Box-Jenkins
Louvrage de Box et Jenkins Time series analysis, forecasting and control , publi en 1970
a propos une dmarche de prvision pour les sries univaries, fonde sur lutilisation de
processus ARIMA.
Les tapes pour lestimation des coecients dun processus ARIMA sont les suivantes
(1) identication
(i) choix de d : combien de fois faut-il direncier pour obtenir une srie station-
naire (autocorrlogrammes, tests statistiques...)
(ii) choix de p et q : ordres respectifs des composantes AR et MA
(2) estimation des paramtres
estimation des
i
et des
j
: paramtres respectifs des composantes AR et MA
(3) vrication a posteriori
(i) signicativit des paramtres
(ii) validation de lhypothse de bruit blanc des rsidus
Remarque 207. Il convient de retenir, comme en conomtrie, le modle le plus parci-
monieux, utilisant le moins de paramtres, et ayant le meilleur comportement en prvision.
7.1 Estimation du paramtre dintgration d
7.1.1 Approche empirique par lautocorrlogramme
Comme nous lavons vu dans la partie (2.4.3), les moments empiriques convergent, avec
en plus normalit asymptotique (sous certaines conditions).
En pratique, si (h) est proche de 1 (pour un grand nombre de retards), on a une racine
unit, et le processus nest pas stationnaire. On peut gallement penser direncier si
les premiers (h) sont proches les uns des autres, mme si (1) semble assez dirent de
1. Il est noter que pour des sries conomiques, il est assez rare davoir d 3.
Exemple 208. Les graphiques ci-dessous reprsentent les sries (en haut) et les auto-
corrlogrammes (en bas) de X
t
, de X
t
et de
2
X
t
On peut dailleurs noter que si lon
continue direncier, on a toujours des sries stationnaires
7.1.2 Tests de racine unit
La prsentation sera ici inspire de celle de Hamilton Time Series Analysis (1994).
Le test de Dickey & Fuller simple Ce test permet de tester lhypothse H
0
: le
processus suit une marche alatoire contre lhypothse alternative H
a
: le processus suit
un modle AR(1). Ces tests peuvent tre regroups en 4 cas :
(1) Y
t
= Y
t1
+
t
: on teste H
0
: = 1 (marche alatoire sans drive)
(2) Y
t
= + Y
t1
+
t
: on teste H
0
: = 0 et = 1 (marche alatoire sans drive)
(3) Y
t
= + Y
t1
+
t
: on teste H
0
: ,= 0 et = 1 (marche alatoire avec drive)
137
(4) Y
t
= + t + Y
t1
+
t
: on teste H
0
: = 0, = 0 et = 1 (marche alatoire
sans drive)
Le test de Dickey & Fuller, dans le cas (1), se construit comme un test de Sutdent de
lhypothse = 1, ou plutt 1 = 0. Etant donn lestimateur naturel de , on peut
noter que
1 =
t
Y
t1
Y
t1
Le test de Dickey & Fuller augment Ce test permet de tester lhypothse H
0
: est
intgr dordre au moins 1 H
a
: le processus suit un modle AR(p). Ces tests peuvent
tre regroups en 4 cas :
(1) (L) Y
t
=
t
: on teste H
0
: (1) = 0
(2) (L) Y
t
= +
t
: on teste H
0
: = 0 et (1) = 0
(3) (L) Y
t
= +
t
: on teste H
0
: ,= 0 et (1) = 0
(4) (L) Y
t
= + t +
t
: on teste H
0
: = 0, = 0 et (1) = 0
Ces 4 cas peuvent tre rcrits en introduisant les notations suivantes,
(L) = (1)+(1 L)
(L) = (1)
_
p1
i=0
i
L
i
_
(1 L) o
_
0
= (1) 1
i
=
i1
i
=
i+1
+ ... +
p
pour i = 1, ..., p. En posant = 1 (1), on peut rcrire les 4 cas en
(1) Y
t
= Y
t1
+
i
y
ti
+
t
: on teste H
0
: = 1
(2) Y
t
= + Y
t1
+
i
y
ti
+
t
: on teste H
0
: = 0 et = 1
(3) Y
t
= + Y
t1
+
i
y
ti
+
t
: on teste H
0
: ,= 0 et = 1
(4) Y
t
= + t + Y
t1
+
i
y
ti
+
t
: on teste H
0
: = 0, = 0 et = 1
Les statistiques de tests et leurs lois Pour simplier, on crira
(1) Y
t
= Y
t1
+
i
y
ti
+
t
, avec = 1 appel Modle [1]
(2 3) Y
t
= + Y
t1
+
i
y
ti
+
t
appel Modle [2]
(4) Y
t
= + t + Y
t1
+
i
y
ti
+
t
appel Modle [3]
Les tables ci-aprs, ont t tabules par Dickey & Fuller (1979), et sont analogues aux
tables du t de Student. Dans le cas simple, le paramtre (ou ) est estim par la
mthode des moindres carrs ordinaires. Lestimation des coecients et des cart-types
du modle fournit un t
, analogue la statistique de Student dans les modles linaires
(rapport du coecient sur son cart-type). Si t
est suprieur au t tabul, on accepte H
0
,
hypothse dexistence dune racine unit, et le processus nest alors pas stationnaire.
Il est aussi possible deectuer ce test en utilisant n
n
, o
n
est lestimateur de
obtenu partir de n observations. Si cette valeur (empirique) est suprieure celle tabule
(et donne dans la deuxime table), on accepte lhypothse H
0
.
Mise en place pratique des tests
> library(urca)
> summary(ur.df(y=,lag=1,type="trend"))
138
Il est aussi possible de laisser le logiciel choisir le nombre optimal de retard considrer
( laide du BIC, e.g.)
> library(urca)
> summary(ur.df(y=,lag=6,selectlags="BIC",type="trend"))
On choisit tout dabord un p susement grand pour que (L) X
t
suive peu prs un
bruit blanc. On choisit alors parmi les cas proposs suivant que le graphique de la srie
prsente, ou pas, une tendance linaire.
Exemple 209. Considrons la srie dcrit prcdement,
Le test (simple) de Dickey & Fuller revient estimer les 3 modles suivants,
_
_
_
X
t
X
t1
= X
t1
X
t
X
t1
= + X
t1
X
t
X
t1
= + t + X
t1
et dans le cas du test aumgent, avec p = 2
_
_
_
X
t
X
t1
= X
t1
[
2
X
t1
+
3
X
t2
]
X
t
X
t1
= + X
t1
[
2
X
t1
+
3
X
t2
]
X
t
X
t1
= + t + X
t1
[
2
X
t1
+
3
X
t2
]
Le troisme modle scrit, compte tenu des sorties obtenues ci-dessous,
X
t
= 0.048502
(0.092874)
+ 0.00919
(0.000466)
t 0.000083
(0.0000244)
X
t1
_
1.01516
(0.035561)
X
t1
0.022332
(0.035629)
X
t2
_
avec n = 794. Les valeurs du test de Dickey & Fuller sont donnes par
En rpettant ce test en changeant la forme du modle (ici sans trend + t, et en
changeant lordre p), on conrme ce rejet de H
0
: la srie X
t
possde une racine unitaire et
nest pas stationnaire : la statistique de test ADF Test Statistic est toujours suprieure
aux valeurs critiques :
En faisant le test sur la srie direncie une fois (X
t
),on observe l aussi que lADF
Test Statistic est toujours suprieure aux valeurs critiques : H
0
est encore accepte,
et donc la srie X
t
possde elle aussi une racine unitaire et nest donc pas stationnaire
Le test de Dickey & Fuller appliqu cette fois-ci
2
X
t
donne les rsultats suivants,
Cette fois-ci, le test de Dickey & Fuller permet de rejeter H
0
:
2
X
t
na pas de racine
unitaire, et la srie
2
X
t
est donc stationnaire. Ce test valide les rsultats graphiques de
lexemple (208) : la srie X
t
est intgre dordre 2 : d = 2.
139
Remarque 210. Dans le cas de sries nancires (par exemple), il convient de faire
attention lors de la lecture des rsultats des tests de Dickey & Fuller : les processus
mmoire longue, bien que stationnaires, semblent avoir une racine unit. Avant de dif-
frencier an dobtenir une srie stationnaire, il peut tre intressant de tester lhypothse
de mmoire longue du processus.
A retenir 211. Dans les tests de Dickey Fuller augment, trois (ou quatre) alternatives
sont proposes : avec ou sans tendance et constante. Il vaut mieux choisir lalternative
permettant de mieux dcrire la srie : si la srie (X
t
) nest pas centre, et que lon tente
un test de Dickey Fuller sans constante, il est possible il est possible H
0
soit rejete, non
pas parce quil ny a pas de racine unit, mais parce que le modle test est mal spci
(cf exercice 16 de lexamen 2002/2003).
Complments sur les tests de racine unit Considrons une criture de la forme
(L) X
t
= (L)
t
, o (
t
) est un bruit blanc.
Lhypothse tester est (H
0
) : il existe tel que
_
e
i
_
= 0, cest dire quune racine est
sur le disque unit (racine unit) le reste des racines tant lextrieur du risque unit :
(L) = (1 L)
(L) o
(1) ,= 0, avec les racines de
lextrieur du disque unit.
Alors
X
t
=
(L)
1
(L)
t
=
(L)
t
=
t
ou X
t
= X
t1
+
t
.
Lhypothse alternative (H
1
) scrit alors
_
e
i
_
,= 0 pour tout : na pas de racine
unit, et on suppose de plus que toutes les racines sont lextrieur du disque unit :
X
t
= (L)
1
(L)
t
= (L)
t
=
t
.
Les tests de Dickey-Fuller permet de tester cette hypothse : le test de rgression
scrit alors
X
t
= X
t1
+
t
dont lestimation est X
t
=
X
t1
+
t
.
Il est alors possible de montrer que sous lhypothse (H
0
) : = 1 , la statistique de test
scrit
t
=1
=
1
_
_ o
1 =
X
t1
X
2
t1
, s
2
=
1
T 1
_
X
t
X
t1
_
et
_
_
2
=
s
2
X
2
t1
,
avec
_
_
cart type (par moindre carrs) de lestimateur de , et sa distribution est
donne par
t
=1
=
1
_
_
L
_
1
0
W
t
dW
t
_
_
1
0
W
2
t
dt
_
1/2
,= A (0, 1) o (W
t
) est un brownien standard sur [0, 1] .
Cette distribution nest pas gaussienne, et des tabulations (obtenues par des mthodes de
type Monte-Carlo) sont ncessaire pour tabuler la distribution limite
11
.
11
Le lien entre les processus intgrs et le mouvement brownien est donn page 31.
140
Tests de Phillips et Perron Ces tests non paramtriques ont t introduits en 1988.
La distribution thorique la base des tests de Dickey & Fuller repose sur lhypothse
dhtroscdasticit du bruit. La gnralisation des tests DF aux tests ADF se fait en
considrant
Y
t
= D
t
+ Y
t1
+
t
Y
t
= D
t
+ Y
t1
+
i
y
ti
+
t
,
o (D
t
) est une tendance dterministe. La gnralisation des tests DF propose par
Phillips et Perron consiste ne plus supposer que (
t
) est un bruit blanc, et autoriser
que ce processus soit autocorrle. La gnralisation de ces tests au cas htroscdastique
a t propose par Phillips et Perron, les valeurs critiques correspondant celles des
tests ADF. Ces tests reposent sur des rsultats de la thorie de la convergence faible
fonctionelle (thorme central limite fonctionel (FCLT) par exemple). Lutilisation du
FCLT pour des tests de racines unit a t propos ds 1958 par White.
Si (X
t
) est un processus stationnaire alors les statistiques calcules sur ce proces-
sus vriront le FCLT. Considrons par exemple le cas AR(1), X
t
= X
t1
+
t
pour
t = 1, ..., T, et cherchons tester = 1 (hypothse H
0
). En supposons H
0
vrie, et
considrons la somme partielle du processus dinnovation,
S
t
= X
t
X
0
=
t
i=1
i
.
On prendra comme valeur initiale de (S
t
), S
0
= 0, mais pour le choix de X
0
trois possibil-
its sont gnralement envisages : (i) X
0
= c (constante), (ii) X
0
admet une distribution
spcie a priori, (iii) X
0
= X
T
. Cette dernire condition, dite hypothse de cicularit, a
t propos par Hotelling. Phillips avait suggr la seconde possibilit.
En notant X
T
(r) = S
[Tr]
/
T, il possible de montrer (cd partie prcdante) que X
T
(r)
converge faiblement (not =) vers un mouvement brownien (cf. Billigsley (1968)).
Proposition 212. Si (
t
) vrie lhypothse () et si sup
_
[
t
[
+
_
< pour > 0 et
> 0 alors, quand T , sous lhypothse H
0
: = 1 dans le modle X
t
= X
t1
+
t
on a les rsultats suivants
(i)
1
T
2
T
t=1
X
2
t1
=
2
_
1
0
W
2
s
ds
(ii)
1
T
T
t=1
X
t1
(X
t
X
t1
) =
2
2
_
W
2
1
2
2
_
(iii) T ( 1) =
1
2
W
2
1
2
/
2
_
1
0
W
2
s
ds
(iv)
P
1
141
(v) t
=
1
_
T
t=1
(X
t
X
t1
)
2
=
2
W
2
1
2
/
2
_
_
1
0
W
2
s
ds
Proof. Phillips (1987), Testing for a unit root in a time series regression.
Le point (iv) montre que les moindres carrs ordinaires conservent la proprit de
convergence quand il y a une racine unit.
Exemple 213. En reprenant la srie de lexemple (208), on retrouve que la srie (X
t
)
admet une racine unit, que lon teste un modle simple, sans constante ni tendance (
gauche), ou avec tendance et constante ( droite),
avec les mmes conclusions pour la srie direncie une fois,
En revanche, dans le cas de la srie direncie deux fois, tous les tests valident
lhypothse dabsence de racine unit
Remarques complmentaires Un certains nombres dtudes sur des donnes simules
ont montr que ces tests rejettent dicilement lhypothse H
0
dans le cas de sries d-
saisonnalise. Il est alors parfois intressant dagrger des donnes mensuelles en don-
nes annuelles, et de tester si la srie annuelle prsente une racine unit. Nelson et
Plosser (1992) ont montr que les racines unitaires caractrisent un grand nombre de
sries macroconomiques.
Le test de Schmidt-Philipps repose sur lide que dans le cas du test ADF de type
4 - avec tendance linaire - linterprtation des paramtre nest pas la mme : considrons
le modle Y
t
= + t + Y
t1
+
t
et lhypothse H
0
: = 0 et = 1. Sous H
0
et
lhypothse alternative H
a
, on a respectivement
H
0
: Y
t
= Y
0
+ t +
t
k=0
tk
et H
a
: Y
t
=
_
+
1
_
+ (1 ) +
k=0
tk
.
Autrement dit, sous H
a
, (Y
t
) est stationnaire autour dune tendance dterministe dont la
pente est (1 ), alors que sous H
0
, (Y
t
) est non stationnaire, avec pour tendance .
Aussi, Schmidt et Philipps ont propos de modliser (Y
t
) sous la forme Y
t
= +t +X
t
o (X
t
) est non stationnaire sous H
0
et (X
t
) est stationnaire sous H
a
. On a alors
_
Y
t
= + t + X
t
X
t
= X
t1
+
t
o [[ 1 et (
t
) BB
_
0,
2
_
et on teste
_
H
0
= 1
H
a
< 1
.
7.1.3 Tests de racines unitaires saisonnires
Dans le cas dune modlisation SARIMA, avec une saisonnalit dordre s, il peut tre
intressant de tester lordre s. Un certain nombre de tests on t mis en oeuvre dans les
annes 80 et 90, en particulier pour tester de la saisonnalit lordre 4 et lordre 12.
142
Tests de Hasza et Fuller (1982) et de Osborn, Chui, Smith & Birchenhall
(OCSB, 1988) Hasza et Fuller ont considr le modle
Y
t
=
1
Y
t1
+
s
Y
ts
+
s+1
Y
ts1
+
t
o (
t
) est un bruit blanc. Lhypothse H
0
scrit ici H
0
:
1
=
s
=
s+1
= 1.
Osborn, Chui, Smith et Birchenhall ont alors tendu cette approche sous la forme
(L) (1 L) (1 L
s
) Y
t
=
s
i=1
s
D
s,t
+ (1 L
s
) Y
t1
+ (1 L) Y
ts
+
t
Si lon accepte lhypothse = 0, la dirence lordre s est approprie, et si =
= 0, alors le ltre (1 L) (1 L
s
) est ncessaire.
Test de Hylleberg, Engle, Granger et Yoo (HEGY , 1990) Ce test utilise la
dcomposition des polynmes (1 L
4
) et (1 L
12
), avec respectivement 4 et 12 racines
units : dans le cas dune saisonnalit lordre s = 12, on considre une criture de la
forme
(L) P
8
(L) Y
t
=
t
+
1
P
1
(L) Y
t1
+
2
P
2
(L) Y
t2
+
3
P
3
(L) Y
t1
+
4
P
3
(L) Y
t2
+
5
P
4
(L) Y
t1
+
6
P
4
(L) Y
t2
+
7
P
5
(L) Y
t1
+
8
P
5
(L) Y
t2
+
9
P
6
(L) Y
t1
+
10
P
6
(L) Y
t2
+
11
P
7
(L) Y
t1
+
12
P
7
(L) Y
t2
,
o les polynmes retards P
i
sont dnis par
_
_
P
1
(L) = (1 + L) (1 + L
2
) (1 + L
4
+ L
8
) et P
2
(L) = (1 L) (1 + L
2
) (1 + L
4
+ L
8
) ,
P
3
(L) = (1 L
2
) (1 + L
4
+ L
8
) et P
4
(L) = (1 L
4
)
_
1
3L + L
2
_
(1 + L
2
+ L
4
) ,
P
5
(L) = (1 L
4
)
_
1 +
3L + L
2
_
(1 + L
2
+ L
4
) et P
6
(L) = (1 L
4
) (1 L
2
+ L
4
) (1 L + L
2
) ,
P
7
(L) = (1 L
4
) (1 L
2
+ L
4
) (1 + L + L
2
) et P
8
(L) = (1 L
12
) .
Les variables Z
(i)
t
= P
i
(L) Y
t
sont alors associes aux direntes racines du polynme. On
peut alors considrer les t de Student pour les variables
1
et
2
, ainsi que les F de Fisher
associs aux couples.(
3
,
4
) , (
5
,
6
) , (
7
,
8
) , (
9
,
10
) et (
11
,
12
).
Test de Franses ( 1990) Ce test a t mis en place pour tester une saisonnalit
lordre 12.
Dtection graphique dune racine unitaire saisonnire Considrons les sries
suivantes, (X
t
), (Y
t
) et (Z
t
) comportant respectivement une racine unitaire saisonnire
dordre 2, 4 et 12,
Sur ces trois graphiques, en considrant la srie partielle des autocorrlogrammes
r
s
(h) = [ (sh)[ , on obtient une srie constante, proche de 1, de mme que
lautocorrlogramme dune srie en prsence de racine unitaire.
Toutefois, si ce genre de comportement laisse penser quil y a une racine unitaire
saisonnire, lordre s nest pas ncessairement celui indiqu par lautocorrlogramme : une
srie saionnire dordre 4 peut avoir un autocorrlogramme proche de celui de gauche.
143
7.1.4 Complment sur la notion de sur-direntiation
Considrons la srie suivante, correspondant une marche alatoire (X
t
). On notera alors
Y
t
= (1 L) X
t
et Z
t
= (1 L) Y
t
, autrement dit, on direncie respectivement une fois
et deux fois la marche alatoire. On reprsentera respectivement les autocorrlations et
les autocorrlation inverses, au centre et droite,
Comme nous lavons dj voqu, lautocorrlogramme de la srie (X
t
) permet - a priori
- de conclure la prsence dune racine unit. Le comportement de lautocorrlogramme
inverse de la srie (Z
t
) prsente, de faon moins nette certes, le mme genre de comporte-
ment.
On peut noter galement sur les autocorrlogrammes de (Y
t
), correspondant un bruit
blanc, que les autocorrlations et les autocorrlations inverses sont identiques (ce qui est
une caractrisation des bruits blancs).
[A COMPLETER]
7.2 Estimation des ordres p et q dun modle ARMA(p, q)
Pour lestimation des paramtres p et q, on utilise le fait que si (X
t
) suit un
ARIMA(p, d, q), alors (1 L)
d
X
t
suit asymptotiquement un processus ARMA(p, q).
En pratique, lide est daplliquer la rgle suivante : si (X
t
) ARIMA(p, d, q) alors
(1 L)
d
X
t
ARMA(p, q).
On appelle processus ARMA(p, q), un processus stationnaire (X
t
) vriant une rela-
tion du type
X
t
+
p
i=1
i
X
ti
=
t
+
q
j=1
ti
pour tout t Z, (31)
o les
i
sont des rels et (
t
) est un bruit blanc de variance
2
. (22) est quivalent
lcriture
(L) X
t
= (L)
t
o
_
(L) = I +
1
L + ... +
q
L
q
(L) = I +
1
L + ... +
p
L
p
.
(32)
On supposera de plus que les polymes et nont pas de racines en module strictement
suprieures 1 (criture sous forme canonique), et nont pas de racine commune. On
supposera de plus que les degrs de et sont respectivement q et p, au sens o
q
,= 0
et
p
,= 0.
7.2.1 Problmes dunicit de la reprsentation ARMA
On peut noter que lcriture ARMA (32) nest pas unique. En eet, il sut de multiplier
gauche et droite de (32) par un mme polynme en L, (L). Alors, en posant
(L) =
(L) (L) et
(L) = (L) (L), on peut noter que (L)
X
t
= (L)
t
.
Proposition 214. Soit un polynme dont les racines z C soient toutes lextrieur
du disque unit. Alors lquation (L) X
t
= (L)
t
admet une solution stationnaire
(X
t
) et celle-ci est unique.
144
Dnissons la matrice suivante, partir des autocorrlations (h) du processus sta-
tionnaire (X
t
)
i,j
=
_
_
(i) (i 1) (i 2) (i j + 2) (i j + 1)
(i + 1) (i) (i 1) (i j + 3) (i j + 2)
(i + 2) (i + 1) (i)
.
.
. (i j + 4) (i j + 3)
.
.
.
.
.
.
.
.
.
(i + j 2) (i + j 3) (i + j 4)
.
.
. (i) (i 1)
(i + j 1) (i + j 2) (i + j 3) (i + 1) (i)
_
_
et soit (i, j) son dterminant.
Dnition 215. Un processus (X
t
) est un ARMA(p, q) minimal si (L) X
t
= (L)
t
o (
t
) est un bruit blanc et o et sont de degr respectif p et q (avec
p
,= 0 et
q
,= 0) dont les racines sont de module suprieur 1, et o et nont pas de racines
communes.
Proposition 216. Le processus (X
t
) est un ARMA(p, q) minimal si et seulement si
(i) (i, j) = 0 pour i q + 1 et j p + 1,
(ii) (i, j) ,= 0 pour i q,
(iii) (i, j) ,= 0 pour j p.
Autrement dit, on peut construire le tableau des (i, j), et il aura la forme suivante
pour un processus ARMA(p, q) minimal,
ij 1 2 p p + 1 p + 2
1 (1, 1) (1, 2) (1, p) (1, p + 1) (1, p + 2)
2 (2, 1) (2, 2) (2, p) (2, p + 1) (2, p + 2)
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
q (q, 1) (q, 2) (q, p) (q, p + 1) (q, p + 2)
q + 1 (q + 1, 1) (q + 1, 2) (q + 1, p) 0 0
q + 2 (q + 2, 1) (q + 2, 2) (q + 2, p) 0 0
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
soit
_
D
p,q
D
p
D
q
0
_
o les termes D
p,q
, D
q
et D
p
sont non-nuls.
Remarque 217. Dans le cas dun processus MA(q), le tableau des (i, j) a la forme
145
suivante
_
D
q
0
_
=
ij 1 2
1 (1, 1) (1, 2)
2 (2, 1) (2, 2)
.
.
.
.
.
.
.
.
.
q (q, 1) (q, 2)
q + 1 0 0
q + 2 0 0
.
.
.
.
.
.
.
.
.
Remarque 218. Dans le cas dun processus AR(p), le tableau des (i, j) a la forme
suivante
_
D
p
0
=
ij 1 2 p p + 1 p + 2
1 (1, 1) (1, 2) (1, p) 0 0
2 (2, 1) (2, 2) (2, p) 0 0
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Lautocorrlogramme partiel scrit a (h) = (1)
j1
(1, j) /(0, j) o (0, j) est
strictement positif (comme dterminant dune matrice de corrlation) pour un AR(p),
et donc a (h) = 0 pour h p + 1.
7.2.2 Comportement asymptotique des moments empiriques
Nous avions vu dans la partie (2.4.3) que les moments empiriques ( (h) , (h) , i (h) ...)
convergeaient vers les vraies moments.
Proposition 219. Sous lhypothse o (X
t
) MA(q), et que (
t
) est stationnaire
lordre 4, alors
T
T
(h) (h)
_
1 + 2
q
k=1
2
(k)
L
N (0, 1) pour h > q.
Cette proposition permet en particulier davoir lintervalle de conance 95% des
autocorrlations,
_
T
(h) 1.96
_
1 + 2
q
k=1
2
(k)
T
_
. (33)
Proposition 220. Sous lhypothse o (X
t
) AR(p), et que (
t
) est stationnaire
lordre 4, alors
T [a
T
(h) a (h)]
L
N (0, 1) pour h > q.
Cette proposition permet en particulier davoir lintervalle de conance 95% des
autocorrlations partielles,
_
a
T
(h) 1.96
1
T
_
,
146
(rsultat de Quenouille, 1949).
Sur un processus MA(1) simul, par dfaut, lintervalle de conance est le suivant
> X=arima.sim(list(order=c(0,0,1),ma=.8),n=240)
> acf(X,col="red",lwd=5)
mais il est possible davoir la version MA de lintervalle de conance
> acf(X,col="red",lwd=5, ci.type="ma")
7.2.3 Mthode pratique destimation des ordres p et q
Pour estimer les ordres p ou q, on utilise les proprits vues prcdemment sur les formes
des autocorrlogrammes ( (h)) ou des autocorrlogrammes partiels (a (h)). En particulier
(i) pour les processus AR(p) lautocorrlogramme partiel sannule partir de p (
gauche)
(ii) pour les processus MA(q) lautocorrlogramme sannule partir de q ( droite)
Remarque 221. Sil reste de la saisonnalit, celle-ci apparatra galement dans les au-
tocorrlogrammes
147
7.2.4 Cas dun processus MA(q)
Si (X
t
) suit un processus MA(q), on peut noter que la variance des autocorrlations
empiriques est donne par la relation
V ( (h)) 1 + 2
q
i=1
2
(i) , pour h > q,
et donc, on peut prendre comme estimation de lcart-type
( (h)) =
1
_
1 + 2
q
i=1
2
(i).
En pratique, on identie q, ordre dun processus MA(q) comme la premire valeur
partir de laquelle les (h) sont dans lintervalle dont les extrmits sont dlimites par
1.96
T
_
1 + 2
_
2
(1) +
2
(2) + ... +
2
(h 1)
_
1/2
,
puisque sous lhypothse o le processus est eectivment un MA(q)
T (h)
L
N
_
0, 1 + 2
_
2
(1) + ... +
2
(q 1)
__
pour h > q.
7.2.5 Cas dun processus ARMA(p, q)
La mthode du coin (Beguin, Gourieroux, Monfort) La mthode suivante, dite
mthode du coin permet destimer conjointement p et q lorsque les deux sont non-nuls.
Elle est base sur la proprit (216) . Les valeurs de
ij
o
i,j
=
_
_
(i) (i 1) (i 2) (i j + 2) (i j + 1)
(i + 1) (i) (i 1) (i j + 3) (i j + 2)
(i + 2) (i + 1) (i)
.
.
. (i j + 4) (i j + 3)
.
.
.
.
.
.
.
.
.
(i + j 2) (i + j 3) (i + j 4)
.
.
. (i) (i 1)
(i + j 1) (i + j 2) (i + j 3) (i + 1) (i)
_
_
sont inconnues mais peuvent tre estime par les (h). On pose alors (i, j) = det
ij
,
qui sera, de la mme faon, estim par
(i, j) = det
ij
. Les
(i, j) sont alors des
estimateurs convergents des (i, j) (par continuit du dterminant). Les coecients p et
q sont alors les valeurs pour lesquels sobservent une rupture. La variance asymptotique
de
(i, j)est une fonction direntiable du vecteur des autocorrlations (h), avec une
loi normale asymptotique.
Un test de nullit est bas sur lutilisation de la statistique de Student
(i, j) /
_
V
_
(i, j)
_
, qui doit tre compare 1.96 pour un seuil de 5%.
148
Exemple 222. Considrons le processus simul (sur 250 valeurs) (1 0.5L) X
t
=
(1 + 0.1L 0.7L
2
)
t
o (
t
) est un bruit blanc gaussien de variance 1
Le tableau des
ij
est donn par
ij 1 2 3 4 5
1 0.352 0.420 0.006 0.095 0.003
2 0.296 0.199 0.067 0.022 0.006
3 0.316 0.047 0.006 0.001 0.003
4 0.179 0.021 0.000 0.001 0.001
5 0.036 0.010 0.002 0.001 0.000
ij 1 2 3 4 5
1 0.352 0.420 0.006 0.095 0.003
2 0.296 0.199 0.067 0.022 0.006
3 0.316 0.047 0.000 0.000 0.000
4 0.179 0.021 0.000 0.000 0.000
5 0.036 0.010 0.000 0.000 0.000
En eet, par exemple, le terme
1,2
est donn par
1,2
=
(1) (0)
(2) (1)
0.352 1
0.296 0.352
= 0.352
2
+ 0.296 = 0.420.
Lapproximation indique ci-dessous semble valider lhypothse de modlisation
ARMA(1, 2). Cette intuition est conrme en tudiant le tableau des Student.
Utilisation de la fonction dautocorrlation tendue (Tsay, & Ciao) Cette mth-
ode est appele EACF (Extended Autocorrelation Function). Pour cela, on eectue des
regressions linaires, de faon itrative pour calculer les paramtres AR dun ARMA
(stationnaire ou pas). Ensuite, partir de cette estimation, la srie observe est mod-
lise sous forme MA.
Soit (X
t
) un processus ARMA(p, q) dont on observe n ralisations, suivant le modle
(L) X
t
= (1 L)
d
(L) X
t
= (L)
t
o (
t
) suit un bruit blanc de variance
2
.
Sur la partie autorgressive du processus, on utilise une rgression linaire pour obtenir
des estimateurs (par moindres carrs) des paramtres autorgressifs de la composante
AR. On dnit alors la premire regression
X
t
=
p
i=0
p,1
i
X
ti
+
p,1
i
p,0
t1
. .
Forme autorgressive
+ u
p,1
t
.
Ce modle est estim par les mco. On dnit alors la k-me rgression itrative dun
AR(m) quelconque
X
t
=
m
i=0
m,k
i
X
ti
+
k
j=0
m,k
j
j,k
tj
+ u
m,k
t
,
o les
j,k
t
sont les erreurs du processus AR de la k-ime rgression, et les u
m,k
t
les rsidus
de la rgression. Comme on ignore lordre p de la partie autorgressive, on choisit m
149
variant de 1 p
, et on eectue q
rgressions itratives : on choisira a priori p
et q
susamment grands. Les paramtres peuvent alors tre estims rcursivement par
m,j
i
=
m+1,j1
i
m,j1
i1
m+1,j1
m+1
m,j1
m
.
Ces paramtres sont alors utiliss pour dnir la ESACF, fonction dautocorrlation
tendue, telle que la dnie Tsay et Tia (1984),
Dnition 223. On appelle fonction dautocorrlation tendue la fonction r
j
(m), fonc-
tion dautocorrlation du processus
m
j
= X
t
i=1
m,j
i
X
ti
pour j = 1, 2, ...
Si le processus suit un ARMA(p + d, q) la srie
m
j
suit un processus MA(q) pour
j q, cest dire
_
r
j
(p + d) 0 pour j > q
r
j
(p + q) ,= 0 pour j = q.
(34)
La nullit thorique de (??) est interprte statistiquement par une valeur infrieur
1.96/
n.
> library(TSA)
> X=arima.sim(list(ar=c(.8,0,-.5),ma = c(.4,.6)),n=240)
> extacf=eacf(X)
AR/MA
0 1 2 3 4 5 6 7 8 9 10 11 12 13
0 x x x x x x x x x o o x x o
1 x x x x x x x x x o x x x o
2 x x x x o o x x x x x o o o
3 x x x x o o o o o o x o o o
4 x x x x o x o o x o o o o o
5 x x x x o x o o x o o o o o
6 x o x o x o o o x x o o o o
7 o o x o x o o o o x o o o o
> extacf$eacf
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 0.749 0.274 -0.270 -0.544 -0.495 -0.198 0.160 0.358 0.341 0.114
[2,] 0.652 0.291 -0.404 -0.638 -0.494 -0.207 0.231 0.427 0.361 0.125
[3,] -0.576 0.631 -0.301 0.186 0.022 -0.130 0.163 -0.215 0.201 -0.139
[4,] 0.551 0.519 0.134 0.199 0.035 -0.078 -0.022 -0.060 0.102 0.078
[5,] -0.440 0.496 -0.206 0.190 0.034 -0.155 0.054 -0.027 0.182 -0.002
[6,] 0.500 0.302 0.140 0.154 0.042 -0.228 -0.092 -0.034 0.172 0.006
[7,] 0.245 0.058 -0.245 -0.035 0.264 0.066 0.020 0.049 0.180 0.205
[8,] 0.058 0.045 -0.185 -0.035 0.163 0.020 -0.074 0.007 0.049 0.188
On peut visualiser ces valeurs sur la gure suivante
150
Mthode SCAN Cette mthode vise utiliser la plus petite corrlation canonique
(smallest canonical correlation) pour identier les ordres p et q. Considrons une srie X
t
que nous allons centrer, Z
t
= X
t
, dont on observe n ralisations, suivant un processus
ARIMA(p, d, q). Cette mthode analyse les valeurs propres de la matrice de corrlation
du processus.
[A COMPLETER]
Exemple 224. Dans le cas dun processus ARMA(2, 1), les tables ESACF et SCAN
thoriques seront de la forme
Table ESACF Table SCAN
AR-MA 0 1 2 3 4 5 6
0
1
2 0 0 0 0 0 0
3 0 0 0 0 0
4 0 0 0 0
AR-MA 0 1 2 3 4 5 6
0
1
2 0 0 0 0 0 0
3 0 0 0 0 0 0
4 0 0 0 0 0 0
o lordre de lAR se lit gauche, et lordre du MA se lit en haut. Dans lexemple
ci-dessous, nous avons simul 1500 ralisations dun tel processus.
Les sorties ESACF,et SCAN peuvent se rcrire
Table ESACF Table SCAN
AR-MA 0 1 2 3 4 5
0 0.53 0.01 0.32 0.41 0.36 0.21
1 0.52 0.02 0.25 0.16 0.16 0.17
2 0.44 -0.03 -0.08 -0.06 0.00 -0.03
3 0.48 0.11 -0.10 -0.06 0.01 -0.02
4 0.50 0.51 0.40 0.02 0.05 -0.02
AR-MA 0 1 2 3 4 5
0 0.28 0.00 0.10 0.17 0.13 0.05
1 0.14 0.14 0.12 0.02 0.01 0.01
2 0.04 0.00 0.00 0.00 0.00 0.00
3 0.02 0.00 0.00 0.00 0.00 0.00
4 0.03 0.00 0.00 0.00 0.00 0.00
Comme on peut le noter, la mthode SCAN donne de trs bon rsultats, et permet
didentier les ordres 2 et 1.
151
7.2.6 Proprit des estimateurs
En notant = (
1
, ...,
p
,
1
, ...,
q
)
, on a le rsultat suivant
Proposition 225. Lestimateur du maximum de vraissemblance est convergent, et asymp-
totiquement normal,
_
T (
T
)
T (
T
)
_
L
A
__
0
0
_
,
_
0
0 a
__
.
Cette proprit permet de mettre en place des tests sur les paramtres.
7.3 Test de bruit blanc et de stationnarit
Lhypothse (X
t
) ARIMA(p, d, q) peut scrire (1 L)
d
(L) X
t
= (L)
t
, ou encore
t
= (L)
1
(1 L)
d
(L) X
t
.
Une fois estims les paramres d, p, q et lensemble des
i
et
j
, on obtient des polynmes
estims
(L) et
(L), qui permettent dobtenir les rsidus estims,
t
=
(L)
1
(1 L)
d
(L) X
t
.
Pour que les modles obtenus prcdamment soient valides, il convient de vrier que les
rsidus estims suivent bien un bruit blanc H
0
: (
t
) BB.
7.3.1 Analyse des fonctions dautocorrlation
Lautocorrlation peut tre estime par
(h) =
(h)
(0)
o (h) =
1
n h
nk
t=1
_
X
t
X
_ _
X
th
X
_
et X =
1
n
n
t=1
X
t
.
Lintervalle de conance de (h) est, dans le cas dun bruit blanc gaussien
_
t
/2
/
T; t
/2
/
T
_
o t
/2
est le quantile dordre /2 de la loi de Student (1.96
pour = 5%). Pour avoir un bruit blanc, il est ncessaire quaucune valeur de
lautocorrlogramme ne soit signicativement non-nulle.
Exemple 226. Pour la srie (1) gauche, aucune valeur nest signicativement non-
nulle alors que pour la srie (2), droite, certaines le sont, en particulier pour h = 8 ou
h = 16.
152
7.3.2 Statistique de Box-Pierce, ou test de portmanteau
Le test de Box-Pierce permet didentier les processus de bruit blanc (i.e. les processus
alatoires de moyenne nulle, de variance constante et non autocorrls). Cette statistique
permet de tester cov (
t
,
th
) = 0 pour tout h, soit (h) = 0 pour tout h. Ce test scrit
_
H
0
: (1) = (2) = ... = (h) = 0
H
a
: il existe i tel que (i) ,= 0.
Pour eectuer ce test, on utilise la statistique de Box et Pierce (1970) Q, donne par
Q
h
= T
h
k=1
2
k
,
o h est le nombre de retards, T est le nombre dobservations et
k
lautocorrlation
empirique. Asymptotiquement, sous H
0
, Q
h
suit un
2
h degrs de libert. Nous
rejetons lhypothse de bruit blanc au seuil h si Q est suprieure au quantile dordre
(1 ) de la loi du
2
h degrs de libert.
Une statistique ayant de meilleurs proprits asymptotiques peut tre utilise :
Q
h
= T (T + 2)
h
k=1
k
T k
,
qui suit asymptotiquement, sous H
0
une loi du
2
h degrs de libert. Ces tests sont
appels par les anglo-saxons portmanteau tests, soit littralement tests fourre-tout.
Exemple 227. Cette statistique est gnralement fournie avec lautocorrlogramme
(Q-stat). Les deux sorties ci-dessous correspondent aux valeurs pour 2 sries de rsidus
La table du
2
est donne ci-dessous. A titre comparatif, nous obtenons le tableau
suivant
h 1 2 3 4 5 6 7 8 9 10
Srie (1) 0.000 0.102 0.819 4.095 4.476 6.852 9.087 10.676 11.310 11.388
Srie (2) 2.088 2.206 4.059 4.673 7.2646 8.643 10.341 19.234 19.281 19.281
10%
(h) 2.706 4.605 6.251 7.779 9.236 10.645 12.017 13.362 14.684 15.987
5%
(h) 3.841 5.991 7.815 9.488 11.070 12.592 14.067 15.507 16.919 18.307
Si la srie (1) est statistiquement un bruit blanc, il ne semble pas en tre de mme pour
la seconde srie, pour laquelle Q
h
est parfois trop eleve (en particulier partir de h = 8
- ce qui tait conrm par lanalyse graphique des autocorrlogrammes, avec cette valeur
(8) signicativement non nulle).
> library(forecast)
> (modele=auto.arima(X))
Series: X
ARIMA(1,0,1)(2,1,0)[12] with drift
153
Coefficients:
ar1 ma1 sar1 sar2 drift
-0.0344 -0.0686 -0.444 -0.4048 69.1618
s.e. NaN NaN NaN 0.0010 16.9562
sigma^2 estimated as 9819923: log likelihood=-692.24
AIC=1396.48 AICc=1397.75 BIC=1410.22
> plot(modele$residuals)
> acf(modele$residuals,lwd=3,col="red")
Il est possible dutiliser les tests de Box-Pierce ou Ljung-Box
> Box.test(modele$residuals,lag=6,type="Box-Pierce")
Box-Pierce test
data: modele$residuals
X-squared = 1.8304, df = 6, p-value = 0.9346
> Box.test(modele$residuals,lag=6,type="Ljung-Box")
Box-Ljung test
data: modele$residuals
X-squared = 1.9189, df = 6, p-value = 0.927
que lon peut aussi visualiser graphiquement
154
> BP=function(h) Box.test(modele$residuals,lag=h,type="Box-Pierce")$p.value
> LB=function(h) Box.test(modele$residuals,lag=h,type="Ljung-Box")$p.value
> plot(1:24,Vectorize(LB)(1:24),ylim=c(0,1),type="b",col="blue")
> points(1:24,Vectorize(BP)(1:24),ylim=c(0,1),type="b",col="red",pch=2)
> abline(h=.05,lty=2)
> legend(20,.4,
+ c("Box-Pierce", "Ljung-Box"),col=c("blue","red"),lty=1,pch=c(1,2))
7.3.3 Complments : les tests de normalit
Dans le cadre de la prvision, ou lors des tests de Student sur les paramtres, il convient de
vrier la normalit des rsidus. Un test possible est celui de Bera & Jarque (1984), bas
sur le skewness (coecient dasymtrie de la distribution) et la kurtosis (aplatissement -
paisseur des queues).
En notant
k
le moment dordre k de la distribution,
k
= E
_
[X E(X)]
k
_
, on
appelle skewness le coecient s =
3
/
3/2
2
et kurtosis k =
4
/
2
2
. Sous des hypothses de
normalit, on a normalit des estimateurs du skewness et de la kurtosis,
s
L
A
_
0,
_
6/T
_
et k
L
A
_
3,
_
24/T
_
quand T .
Le test de Bera & Jarque repose sur le fait que, si la distribution suit une loi normale,
alors la quantit
BJ =
T
6
s
2
+
T
24
[k 3]
2
,
suit asymptotiquement une loi du
2
2 degrs de libert. Aussi, si BJ
2
1
(2) on
rejette lhypothse H
0
de normalit des rsidus au seuil .
> jarque.bera.test(residuals(modele))
Jarque Bera Test
data: residuals(modele)
X-squared = 81.2819, df = 2, p-value < 2.2e-16
On peut aussi faire des tests graphiques, comme des QQ-plots
155
> library(car)
> qqPlot(modele$residuals)
Parmi les autres tests, il y a la statistique de test propose par Shapiro & Wilk,
W =
(
n
i=1
a
i
X
i:n
)
2
n
i=1
(X
i
X)
2
o X
i:n
dsigne la ime statistique dordre, et o
a = (a
1
, . . . , a
n
) =
m
V
1
(m
V
1
V
1
m)
1/2
o m = (m
1
, . . . , m
n
)
sont les esprances des statistiques dordre dun chantillon de
variables indpendantes et identiquement distribue suivant une loi normale, et V est la
matrice de variance-covariance de ces statistiques dordre.
> shapiro.test(residuals(modele))
Shapiro-Wilk normality test
data: residuals(modele)
W = 0.8659, p-value = 3.023e-07
7.3.4 Complment : Test de rupture et de changement de tendance
Perron a propos dintroduire, ds 1989, dans la rgression de Dickey & Fuller une variable
indicatrice spciant lexistence dune rupture. La date de rupture peut dailleurs tre
156
connue ou inconnue. Dans le cas o elle est inconnue, une procdure squentielle permet de
la localiser. Ce lien entre les tests de racine unit et les changements de structure ont donn
lieu de nombreuses publications depuis une dizaine dannes. Direntes formes de
changement de structure ont dailleurs t tudies : changement de niveau, changement
du coecient de tendance linaire, changement sur les coecients des variables de la
modlisation... etc.
> library("strucchange")
> library(datasets)
> plot(Nile)
> breakpoints(Nile~1,breaks=1)
Optimal 2-segment partition:
Call:
breakpoints.formula(formula = Nile ~ 1, breaks = 1)
Breakpoints at observation number:
28
Corresponding to breakdates:
1898
> abline(v=time(Nile)[breakpoints(Nile~1,breaks=1)$breakpoints],col="red")
breakpoint-Nile.png
Les tests de racine unit Plusieurs tests ont t implments an de tester lhypothse
nulle que la srie stationnaire (Y
t
) possde une racine unit et une constante, ventuelle-
ment nulle, avec une rupture au temps o 1 < < T, contre lhypothse alternative
que la srie soit stationnaire autour dune tendance linaire avec rupture en sur cette
tendance. Une distinction est alors gnralement apporte entre deux cas :
AO - additive outliers - eet instantann
157
IO - innovational outliser - eet avec transition
Pour chacun des eets, trois modles sont alors considrs : dans la version AO
_
_
_
(1) X
t
= + t + DU
t
() + Y
t
pour t = 1, ..., T,
(2) X
t
= + t + DT
t
() + Y
t
pour t = 1, ..., T,
(3) X
t
= + t + DU
t
() + DT
t
() + Y
t
pour t = 1, ..., T,
o (Y
t
) est la srie (X
t
) laquelle on a retir la tendance dterministe, avec DU
t
() = 1
si t > et 0 sinon (DU
t
() = I (t > )) et DT
t
() = (t ) si t > , 0 sinon (DT
t
() =
[t ] .I (t > )). La mise en oeuvre du test se fait en deux tapes ;
(i) estimation (par une mthode de type moindre carrs) de la tendance avec les mod-
les de rgression (1), (2) et (3), et calcul de la srie rsiduelle obtenue en retranchant
la srie observe la tendance estime
(ii) pour les modles (1) et (3), le test est bas sur la valeur de la t-statistique relative
= 0, not t
() et correspond au test de racine unit dans la rgression ADF
Y
t
= Y
t1
+
k
j=0
d
j
DTB
tj
() +
k
i=1
i
Y
ti
+
t
o DTB
tj
() = I (t = + 1) .
Pour le modle (2), la seconde tape consiste eectuer la rgression
Y
t
= Y
t1
+
k
i=1
i
Y
ti
+
t
,
et utiliser la t-statistique t
() pour eectuer les tests classiques ADF.
Dans la version IO, les quations de rgression scrivent
_
_
(1) X
t
= + t + DU
t
() + DTB
t
() +
_
X
t1
+
k
i=1
c
i
X
ti
+
t
_
pour t = 1, ..., T,
(2) X
t
= + t + DT
t
() +
_
X
t1
+
k
i=1
c
i
X
ti
+
t
_
pour t = 1, ..., T,
(3) X
t
= + t + DU
t
() + DTB
t
() + DT
t
() +
_
X
t1
+
k
i=1
c
i
X
ti
+
t
_
pour t = 1, ..., T,
o, encore une fois, DTB
t
() = I (t = + 1). Le test de Zivot et Andrews (1992) con-
sidre seulement les modles de type IO, sans introduire lindicatrice DTB
tj
() (la
justication tant que ce coecient est asymptotiquement ngligeable)
12
.
Toutefois, dans le cas gnral, la date de rupture est inconnue, ainsi que le paramtre
k, permettant dapprocher le processus ARMA(p, q) par un processus AR(k + 1). Dif-
frentes mthodes pour slectionner k ont t propose par Perron (1989et 1993) pour
les trois modles et les deux types deets, AO et IO. Les procdures squentielles
didentication de Zivot et Andrews (1992) et de Perron (1993) permettent de dterminer
, ou plutt = /T. Cette mthode consiste estimer les modles de rgressions (A),
12
Ce test est voqu ici car il existe des codes tlchargeables sur internet, en EV iews, SAS ou Gauss.
158
(B) et (C) dans les deux cas AO et IO, et retenir le cas o t
() = t
() est minimal.
Les auteurs ont tudi la disctribution asymptotique de inf t
() quand appartient
un intervalle ferm de ]0, 1[, = [3/20, 17/20] dans ltude de Zivot et Andrews. On
rejette alors lhypothse nulle de prsence de racine unit si inf t
() , est plus
petit que le fractile correspondant une probabilit xe de la distribution asymptotique
de inf t
() , .
Les tests de Gregory et Hansen (1996) Ces tests sont une gnralisation des tests
de Zivot et Andrews dans le cas mutlivari, o X
t
= (X
1
t
, X
2
t
).
Les tests du CUSUM Ce test permet dtudier la stabilit dun modle
conomtrique estim au cours du temps. Il existe deux versions de ce test : le CUSUM
fond sur la somme cumule des rsidus rcursifs, et le CUSUMSQ (SQ pour square )
fond sur la somme cumule des carrs des rsidus rrursifs. Pour cela, on note (
t
) le
rsidu normalis par rapport lcart-type, cest dire
t
=
t
/
, et on note k le nom-
bre de paramtres estimer dans le modles. Les statistiques S
t
du CUSUM et S
t
du
CUSUMSQ sont dnies par
S
t
= (T k)
t
i=k+1
i
t
i=k+1
2
i
pour t = k + 1, ..., T,
et
S
t
=
t
i=k+1
2
i
T
i=k+1
2
i
pour t = k + 1, ..., T.
Si les coecients sont variables au cours du temps, alors les rsidus rcursifs S
t
doivent
rester dans lintervalle dni par
S
t
_
(2t + T 3k)
T k
, +
(2t + T 3k)
T k
_
,
o = 1.143, 0.918 ou 0.850 suivant que le seuil est 1%, 5% ou 10%. De la mme faon,
les rsidus S
t
doivent appartenir lintervalle
S
t
_
t T
T k
C,
t T
T k
+ C
_
,
o C est la constante du Durbin. En fait, on peut montrer que sous lhypothse de
stabilit, lesprance de S
t
est E(S
t
) = (t T) / (T k) allant de 0 1 quand t varie
entre k et T. Plus prcisment, la variable S
t
suit une loi Bta.
> cusum=efp(Nile~1,type="OLS-CUSUM")
> plot(time(Nile),cusum$process[-1],type="b",col="red")
159
> plot(cusum,alt.boundary = TRUE)
Le test de Chow ou test dhomoscdasticit Puisque les bruits blancs doivent tre
homoscdastiques, le test de Chow, visant comparer les variances des rsidus sur des
sous-priodes, peuvent tre utiliss
13
.
> library("strucchange")
> plot(Fstats(Nile~1)$Fstats,col="blue")
13
Ce test nest pas dtaill ici puisquil se trouve dans tous les cours dconomtrie. Pour mmoire, ce
test est un test de Fisher : on considre un premier modle Y = X
m
+
m
obtenu sur m observations,
et un second modle Y = X
n
+
n
obtenu sur n observations. Le test de Chow permet de test lgalit
des coecient :
m
=
n
, ainsi que V (
m
) = V (
n
) .
160
7.4 Estimation des paramtres dun modle ARMA(p, q)
A cette tape, les coecients d, p et q ont t xs. Il convient alors destimer les
paramtres
i
et
j
du processus ARIMA(p, d, q), ainsi que la volatilit
2
du bruit
blanc. Sous lhypothse
t
A (0,
2
), on peut utiliser des mthodes du type maximum
de vraissemblance. On supposera ici que le processus (X
t
) est centr.
7.4.1 Attention la constante
Par dfaut, les modles ARMA ne sont pas ncessairement centrs. Comme nous lavons
not, la forme gnrale serait (pour un AR(1) par exemple)
X
t
= a + X
t1
+
t
Si la srie est stationnaire, de moyenne , alors devrait tre solution de
= a + , i.e. =
a
1
ou a = (1 ).
Si on considre un modle ARMA plus gnral (L)X
t
= a + (L)
t
, alors a = (1).
Simulons un processus AR(1) de moyenne 2,
> X=arima.sim(list(order=c(1,0,0),ar=1/3),n=1000)+2
> mean(X)
[1] 1.931767
ou plus simplement, en utilisant une boucle rcursive
> X=rep(NA,1010)
> X[1]=0
> for(t in 2:1010){X[t]=4/3+X[t-1]/3+rnorm(1)}
> X=X[-(1:10)]
> mean(X)
[1] 2.03397
161
Lestimation avec R donne ici
> arima(X, order = c(1, 0, 0))
Call:
arima(x = X, order = c(1, 0, 0))
Coefficients:
ar1 intercept
0.3738 2.0334
s.e. 0.0294 0.0487
sigma^2 estimated as 0.9318: log likelihood = -1383.68
Autrement dit, le coecient appel intercept nest pas la constante a dans le modle
AR(1), mais la moyenne . Le modle estim est alors
(X
t
) = (X
t1
) +
t
.
Ces deux formes sont (bien entendu) quivalentes. Mais les coecients estims ne sont
pas tout fait ce que lon attendait...
Si on regarde maintenant la version intgre, i.e. un processus ARIMA(1, 1, 0), avec
une constante, on est tent dcrire
(1 L)(1 L)X
t
= a +
t
ou (1 L)X
t
= a + (1 L)X
t1
t
.
Cette criture laisse penser quen intgrant, une tendance linaire apparatra. Posons
alors Y
t
= X
t
t, prcisment pour enlever la tendance. Alors
(1 L)[Y
t
+ t] = a + (1 L)[Y
t1
+ (t 1)] +
t
qui peut se rcrire
(1 L)Y
t
= a + ( 1) + (1 L)Y
t1
+
t
i.e. X
t
a(1 )
1
t sera un processus ARIMA(1, 1, 0) sans constante.
Supposons ici que lon ingre le processus
U
t
= 2 +
1
3
U
t1
+
t
i.e. X
t
= X
t1
+ U
t
,
avec X
0
= 0.
> U=rep(NA,1010)
> U[1]=0
> for(t in 2:1010){U[t]=4/3+U[t-1]/3+rnorm(1)}
> U=U[-(1:10)]
> X=cumsum(U)
162
La simulation (brute) donne ici
> arima(X, order = c(1, 1, 0))
Call:
arima(x = X, order = c(1, 1, 0))
Coefficients:
ar1
0.8616
s.e. 0.0160
sigma^2 estimated as1.343:log likelihood = -1565.63
Mais cet estimation na rien voir avec ce qui a t simul. On peut tenter un processus
AR(1) (avec constante) sur la srie direncie,
> arima(diff(X), order = c(1, 0, 0))
Call:
arima(x = diff(X), order = c(1, 0, 0))
Coefficients:
ar1 intercept
0.3564 2.0200
s.e. 0.0295 0.0486
sigma^2 estimated as 0.9782: log likelihood = -1406.6
Les estimateurs proposs voquent des choses que lon a pu voir, mme si ce nest pas
la constante du modle ARIMA, mais la moyenne du processus direnci. Mais cette
fois, on a un interprtation, cest que la constante est la pente de la tendance ! Si on
estime la pente associe a , on cupre la mme valeur,
> arima(X, order = c(1, 1, 0), xreg=1:length(X))
Call:
arima(x = X, order = c(1, 1, 0), xreg = 1:length(X))
Coefficients:
ar1 1:length(X)
0.3566 2.0519
s.e. 0.0296 0.0487
sigma^2 estimated as 0.9787: log likelihood = -1406.82
Si on fait de la prvision (dtaille plus loin dans ces notes de cours), on obtient dans
le premier cas
163
> ARIMA1=arima(X, order = c(1, 1, 0))
> ARIMA2=arima(X, order = c(1, 1, 0), xreg=1:length(X))
> Xp1=predict(ARIMA1,20)
> Xp2=predict(ARIMA2,20,newxreg=
+ (length(X)+1):(length(X)+20))
> plot(960:1000,X[960:1000],xlim=c(960,1020),type="l")
> polygon(c(1001:1020,rev(1001:1020)),
+ c(Xp1$pred+2*Xp1$se,rev(Xp1$pred-2*Xp1$se)),
+ col=CL[3],border=NA)
> lines(1001:1020,Xp1$pred,col="red",lwd=2)
alors quavec le modle prenant en compte la constante
> lines(1001:1020,Xp2$pred,col="blue",lwd=2)
7.4.2 Estimation pour les modles AR(p) par la m thode des moindres carrs
Un modle AR(p) scrit
X
t
= c +
1
X
t1
+ ... +
p
X
tp
+
t
o (
t
) est un bruit blanc,
= Z
t
+
t
o Z
t
= (1, X
t1
, X
t2
, ..., X
tp
) et
= (c,
1
,
2
, ...,
p
) .
Lestimation des paramtres du modle X = Z
+ par la mthode des moindres carrs
donne
= (ZZ
)
1
ZX et
2
=
1
T (p + 1)
_
X
t
Z
_
2
.
164
Toutefois, les rsultats usuels dconomtries ne sont pas vris ici, en particulier E
_
_
,=
. Il est toutefois possible de montrer le rsultat suivant,
Proposition 228. Si les racines du polynme charactrisque (racines de (z) = 0) sont
lextrieur du disque unit alors
P
et
2
P
2
,
et de plus
T
_
_
L
N
_
0,
2
V
_
o V = p lim
T
1
T
ZZ
.
Remarque 229. Si la mthode des moindres carrs peut tre utilise pour estimer les
paramtres dun modle AR(p), elle ne marche plus ds lors que lon a des termes au-
torgressifs sur les rsidus.
7.4.3 Vraissemblance dun processus ARMA(p, q)
Pour dterminer la vraissemblance, il est ncessaire de supposer connue la loi des erreurs
: nous supposerons les erreurs normalement distribues. Les erreurs tant normalement
distribues et indpendantes (le processus (
t
) est, par hypothse un bruit blanc), le vecteur
(
1
, ...,
n
) est un vecteur gaussien. Les composantes du vecteur (X
1
, ..., X
n
) tant obtenues
par combinaisons linaires des composantes du vecteur (
1
, ...,
n
), (X
1
, ..., X
n
) sera un
vecteur gaussien :
L
_
X = (X
1
, ..., X
n
)
, , ,
2
_
=
1
(2
2
)
n/2
1
[det ]
1/2
exp
_
1
2
2
X
1
X
_
,
o
2
est la matrice (n n) des covariances du vecteur X = (X
1
, ..., X
n
)
.
La maximisation, et mme le calcul de cette vraissemblance taient relativement dif-
cile il y a quelques annes, en particulier cause du calcul de linverse
1
, et du
dterminant, de , surtout lorsque n devenait relativement grand. Newbold a propos
une autre expression de cette vraissemblance, plus facile calculer. Soit H la matrice
triangulaire infrieure, lments positifs sur la diagonale telle que HH
= (dcompo-
sition de Cholesky). Soit alors e le vecteur tel que e = H
1
X. La log-vraissemblance du
modle scrit alors
log L =
n
2
log 2
1
2
log
2
1
2
log [det [
1
2
2
X
1
X,
=
n
2
log 2
n
2
log (e
e) log [det H[ =
n
2
log
_
[det H[
1/n
e
e [det H[
1/n
_
.
La mthode du maximum de vraissemlance revient alors chercher le minimum de =
_
[det H[
1/n
e
e [det H[
1/n
_
.
Une autre criture, relativement proche est possible dans le cas des processus MA(q).
Soit
le vecteur dinnitialisation des erreurs,
= (
1q
, ...,
1
,
0
)
,
165
permettant dengendrer la srie x
1
, ..., x
n
. Considrons alors les vecteurs =
(
1q
, ...,
1
,
0
,
1
, ...,
n
)
et X. On peut alors crire
= NX + M
,
o M est une matrice (n + q) q et N (n + q) n. Linitialisation des erreurs sestimant
par
= (M
M)
1
M
NX, et en notant
S () = (NX + M
(NX + M
) ,
on peut alors montrer que la log-vraissemblance peut scrire
log L =
n
2
log 2
n
2
log
2
1
2
log (det (M
M))
S ()
2
2
.
Et nallement, puisquon peut crire
2
= S () /n, la fonction minimiser scrit
= nlog S () + log (det (M
M)) .
Exemple 230. Dans le cas dun modle AR(1), de la forme X
t
= c + X
t1
+
t
o
t
est i.i.d. et distribu suivant une loi A (0,
2
), avec [[ < 1, alors
X
t
[X
t1
A
_
c + X
t1
,
2
_
.
Aussi, la loi conditionnelle de X
t
est donne par
f
_
x
t
[x
t1
,
_
c, ,
2
__
=
1
2
2
exp
_
1
2
2
(x
t
c x
t1
)
2
_
,
cest dire que
X
t
A (E(X
t
) , V (X
t
)) soit X
t
A
_
c
1
,
2
1
2
_
.
En posant = (c, ,
2
), la vraissemblance conditionelle du modle est alors donne par
L([X
1
, ..., X
T
) =
T
t=2
1
2
2
exp
_
1
2
2
(X
t
c X
t1
)
2
_
,
log L([X
1
, ..., X
T
) =
T 1
2
ln (2)
T 1
2
ln
2
+
1
2
2
T
t=2
(X
t
c X
t1
)
2
.
La vraissemblance marginale scrivant
L(, X
1
) =
_
1
2
2
2
exp
_
(1
2
)
2
2
_
X
1
c
1
_
2
_
,
166
on en dduit la forme de la log-vraissemblance (exacte, et non plus conditionelle),
log L(, X
1
, ..., X
T
) =
1
2
ln (2)
1
2
ln
_
2
1
2
_
(1
2
)
2
2
_
X
1
c
1
_
2
T 1
2
ln (2)
T 1
2
ln
_
2
_
1
2
2
T
t=2
(X
t
c X
t1
)
2
.
On peut noter que la maximisation de la vraissemblance exacte est un problme
doptimisation non-linaire.
7.4.4 Rsolution du programme doptimisation
Une fois crite la vraissemblance, deux mthodes sont alors possibles
(1) des mthodes exactes, visant mininimiser eectivement la log-vraissemblance
log L, de faon numrique
(2) des mthodes de type moindres carrs, visant minimiser la fonction S () dans le
cas MA, le second terme dans log L
n
devenant ngligeable quand n augmente (mthode
utilise sous EViews).
Pour les modles ARMA stationnaires, les mthodes de maximisation de la vraissem-
blance conditionnelle, et de maximisation de la vraissemblance (exacte), sont asympto-
tiquement quivalentes. Lexplication heuristique est que pour les modles stationnaires,
leet des valeurs initiales devient asymptotiquement ngligeable, alors que dans le cas
o des racines du polynme charactristique sont sur le cercle unit, les valeurs initiales
inuencent les chantillons nis.
Critre des moindres carrs conditionnel (MCC)
Exemple 231. Considrons ici un modle de la forme MA(1), X
t
=
t
t1
. Cette
quation peut scrire
t
= x
t
+
t1
, et donc, en supposant
0
= 0,
t
=
t1
i=0
i
x
ti
, pour t 2, (35)
et donc, la somme des carrs, conditionnelle
0
= 0 scrit
S ([
0
= 0) =
T
t=1
2
t
=
T
t=1
_
t1
i=0
i
x
ti
_
2
.
Lquation permettant destimer nest pas linaire.
Dans le cas gnral, pour un processus ARMA(p, q), on suppose que x
1
= ... = x
p
sont xs et connus, et que
p
=
p+1
= ...
p+q
= 0. Alors, par rcurence
t
= x
t
i=1
i
x
ti
+
q
j=1
tj
.
167
La somme des carrs conditionnelle aux valeurs initiales scrit
S ([
0
= 0) =
T
t=1
2
t
=
T
t=1
_
x
t
i=1
i
x
ti
+
q
j=1
tj
_
2
,
o les
tj
peuvent tre crits en fonction des x
tj
, ..., x
tjp
et des
tj1
, ...,
tq
.
Critre des moindres carrs non conditionnel (MCN)
Exemple 232. Considrons ici un modle de la forme MA(1), X
t
=
t
t1
, que
lon notera, en considrant les innovations en temps invers
t
, X
t
=
t
t+1
. On
supposant
T+1
= 0, on dtermine rcurviement
T
= x
T
,
T1
= x
T
+
T
...etc. De faon
rtrospective, on peut ainsi dir x
0
=
1
. De faon anologue (35), on peut crire
x
0
=
T
t=1
t
x
T
.
En posant alors
0
= x
0
, on peut obtenir les
t
en utilisant (35). On obtient alors une
expression (non conditionelle) de la somme des carrs des rsidus
S () =
T
t=1
2
t
==
T
t=1
_
t1
i=0
i
x
ti
t
T
i=1
i
x
i
_
2
.
L encore, lquation permettant destimer nest pas linaire.
Un des problmes de cette mthode est que, dans le cas de processus comprenant une
part autorgressive, les valeurs initiales doivent tre obtenues, thoriquement, en .
Ceci impose de faire une approximantion sur la base dun critre darrt portant sur la
convergence numrique de la rcurrence.
Critre du maximum de vraissemblance conditionelle (MV ) Pour utiliser la
mthode du maximumum de vraissemblance, il est ncessaire de faire des hypothses
sur la loi des
t
: ce sont des variables indpendantes, et de mme loi A (0,
2
). La
vraissemblance conditionnelle est obtenue de la faon suivante :
La densit de = (
1
, ...,
T
)
est donne par
f (
1
, ...,
T
) =
1
(2
2
)
T/2
exp
_
1
2
2
T
t=1
2
t
_
.
On supposera connues les valeurs initiales x
et
. La densit de x peut sexprimer
conditionellement
et x
.
168
Programme doptimisation Nous allons ici nous limiter un cas simple, dun modle
MA(1), avec un critre de type MCC. On part dune valeur initiale
0
, et on va mettre
en place un algorithme convergent vers la vraie valeur . A la i + 1-me tape, on estime
i+1
en fonction de
i
en utilisant
S (
i+1
) = S (
i
) + [
i+1
i
] g (
) o g (
) =
S ()
,
o
est compris entre
i
et
i+1
. Aussi, on minimise la fonction S () en choisant
i+1
de telle sorte que
i
soit de signe oppos au gradient de S () en
. Mais comme
est
inconnu, on choisit
i+1
=
i
g (
i
) avec > 0
et ainsi, S (
i+1
) < S (
i
). Le gradient, sil est dicile valuer peut tre remplac par
une dirence de la forme [S (
i
+ ) S (
i
)] / avec petit. Ces deux constantes
et , propres lalgorithme, peuvent tre xe initialement, par exemple = 0.001 et
= 0.01.
Exemple 233. Considrons un cas relativement simple avec 6 observations
(5, 6, 3, 2, 7, 6), et cherchons tel que X
t
=
t
+
t1
.
0
= 0 et
0
+ = 0.01. Alors S (
0
) = 5
2
+ 6
2
+ ... + 7
2
+ 6
2
= 159. Alors X
(i)
1
= 5,
X
(i)
2
= X
2
+ (
0
+ ) X
(i)
1
= 6 + 5 0.01 = 6.05, X
(i)
3
= X
3
+ (
0
+ ) X
(i)
2
=
3 + 6.05 0.01 = 3.06, ...etc. Do la somme S (
0
+ ) = 161.225. Aussi, on obtient
g (
0
) = 222.458 do nallement
1
= 0.222.
Cet algorithme se rpte ltape suivante, et les rsultats sont alors
itration i
i
1 2 3 4 5 6 S (
i
) g (
i
)
i+1
0
i
0.000 5.000 6.000 3.000 2.000 7.000 6.000 159.00 222.46 0.222
i
+ 0.010 5.000 6.050 3.061 2.031 7.020 6.070 161.22
1
i
0.222 5.000 4.888 1.913 1.575 6.650 4.521 119.68 302.02 0.524
i
+ 0.212 5.000 4.988 2.001 1.606 6.679 4.651 122.70
2
i
0.524 5.000 3.378 1.229 1.356 6.289 2.702 86.61 181.06 0.706
i
+ 0.514 5.000 3.478 1.271 1.377 6.312 2.823 88.42
3
i
0.706 5.000 2.472 1.256 1.114 6.214 1.616 75.16 115.23 0.821
i
0.696 5.000 2.572 1.271 1.146 6.223 1.742 76.31
4
i
0.821 5.000 1.896 1.444 0.815 6.331 0.804 72.07 59.32 0.880
i
0.811 5.000 1.996 1.442 0.861 6.322 0.945 72.66
5
i
0.880 5.000 1.600 1.592 0.599 6.473 0.303 72.44 19.73 0.900
i
0.870 5.000 1.700 1.582 0.654 6.451 0.457 72.64
6
i
0.900 5.000 1.501 1.649 0.516 6.536 0.119 72.97 4.01 0.905
i
0.890 5.000 1.601 1.636 0.575 6.509 0.279 73.01
En allant jusqu ltape 10, on obtient = 0.905.
Dans le cas des modles moyennes mobiles (MA), lalgorithme du ltre de Kalman
peut tre utilis, en considrant que
t
(ou
t1
) est inobservable. La mthode destimation
169
est alors la suivante : (Y
t
) suit un modle de la forme Y
t
= +
t
+
t1
o
t
est i.i.d. et
suit une loi A (0,
2
), avec [[ < 1. La fonction de vraissemblance conditionnelle est
Y
t
[
t1
N ( +
t1
,
2
) et
f
_
y
t
[
t1
, , ,
2
_
=
1
2
2
exp
_
1
2
[Y
t
t1
]
2
_
Le problme est que
t1
est inobservable. Le raisonnement est alors le suivant :
- on suppose que
0
= 0, alors Y
1
[
0
A (,
2
)
- Y
1
= +
1
+
0
= +
1
donc
1
= Y
1
- Y
2
= +
2
+
1
donc
2
= Y
2
(Y
1
)
- ...
- Y
t
= +
t
+
t1
et donc
t
= (Y
t
) (Y
t1
) + ... + ()
t1
(Y
1
) (36)
(on peut reconnatre la version tronque de la reprsentation AR() du processus
MA(1)) La log vraissemblance conditionelle est
T
2
ln (2)
T
2
ln
_
2
_
1
2
2
T
t=1
2
t
o
t
est donne par (36)
Complments : introduction au ltre de Kalman Un modle espace-tat est
dni par le systme dquation
_
Z
t+1
= A
t
Z
t
+
t
: quation dtat
Y
t
= C
t
Z
t
+
t
: quation de mesure
o (
t
,
t
)
est un bruit blanc normal
o A
t
et C
t
sont dterministes, o Z
0
A (m, p) est indpendant des (
t
,
t
)
. Les
variables peuvent ici tre de dimension suprieure 1. La matrice de variance-covariance
V
_
t
t
_
= =
_
V (
t
) cov (
t
,
t
)
cov (
t
,
t
) V (
t
)
_
On dira alors
_
_
(Z
t
) : tat du systme la date t : inobservable
(Y
t
) : observations du systme la date t : observable
(
t
) : innovations du systme la date t : inobservable
(
t
) : erreurs de mesure (ou bruit) en t : inobservable
(A
t
) : matrice de transition
(C
t
) : matrice de mesure
(C
t
Z
t
) : signal la date t
170
Le ltre de Kalman permet de calculer
t
Z
t
= E(Z
t
[Y
0
, ..., Y
t
) la prvision de Z
t
. On
notera
_
_
t
t
= E
_
_
Z
t
t
Z
t
__
Z
t
t
Z
t
_
_
: erreur quadratique du ltre sur Z
t
en t
t1
Z
t
= E(Z
t
[Y
0
, ..., Y
t1
) : prvision de Z
t
faite en t 1
t1
t
= E
_
_
Z
t
t1
Z
t
__
Z
t
t1
Z
t
_
_
: erreur quadratique moyenne de prvision
Dans le cas o cov (
t
,
t
) = 0, alors, pour tout t 0, le ltre de covariance,
_
(a)
t
Z
t
=
t1
Z
t
+ K
t
_
Y
t
C
t
.
t1
Z
t
_
(b)
t
Z
t+1
= A
t
.
t
Z
t
et
_
(a
)
t
t
= [I K
t
C
t
]
t1
t
(b
)
t
t+1
= A
t
.
t
t
.A
t
+ Q
o
K
t
=
t1
t
.C
t
(C
t
.
t1
t
.C
t
+ R)
1
: matrice de gain du ltre la date t
On peut alors en dduire directement les formules de calcul de prvisions de la variable
observe : soit
t1
Y
t
= E(Y
t
[Y
0
, ..., Y
t1
) et
t1
M
t
= V
_
Y
t
t1
Y
t
_
alors
(c)
t
Y
t+1
= C
t+1
.
t
Z
t+1
(c
)
t
M
t+1
= C
t+1
.
t
t+1
.C
t+1
+ R
Dans le cas dit stationnaire, cest dire quand A
t
= A et C
t
= C alors le modle se
rcrit
_
Z
t+1
= AZ
t
+
t
Y
t
= CZ
t
+
t
Le ltre doit tre initialis, et on prend gnralement
1
Z
0
= E(Z
0
) = m et
1
0
=
V (Z
0
) = P. De faon rcursive, on peut alors calculer les
t
Z
t
laide de (a) et (a
) , puis
t
t
et
t
Y
t+1
laide de (b) et (b
), ainsi que de (c) et (c
).
Remarque 234. Dans le cas o les bruits sont corrls, des mthodes similaires peuvent
tre utilises, en introduisant le rsidu de la rgression de (
t
) sur (
t
).
Pour une prvision lordre h, on introduit une seconde itration : on cherche
_
t
Y
t+h
= E(Y
t+h
[Y
0
, ..., Y
t
)
t
Z
t+h
= E(Z
t+h
[Y
0
, ..., Y
t
)
et
_
_
_
t
M
t+h
= V
_
t
Y
t+h
Y
t+h
_
t
t+h
= V
_
t
Z
t+h
Z
t+h
_
(pour h = 1 on retrouve le ltre de covariance). Dans le cas o cov (
t
,
t
) = 0, on a les
formules de rcurrence
_
t
Y
t+h
= C
t+h
.
t
Z
t+h
t
Z
t+h
= A
t+h1
.
t
Z
t+h1
et
_
t
M
t+h
= C
t+h
.
t
t+h
.C
t+h
+ R
t
t+h
= A
t+h+1
.
t
t+h1
.A
t+h1
+ Q
171
La procdure itratif prend alors la forme suivante :
(i) initialisation : t = 0, h = 1, on pose
1
Z
0
= E(Z
0
) = m et
1
0
= V (Z
0
) = P
(ii) formules (a) et (a
)
(iii) formules (b) et (b
), et (c) et (c
)
(iv) si h < H (horizon de prvision), alors h = h + 1 et (iii) , sinon (v)
(v) si t < T alors t = t + 1 et h = 1, observation de Y
t+1
, et (ii), sinon n
Remarque 235. De faon analogue, on peut utiliser le ltre dinformation, bas sur
t
U
t
=
t
1
t
.
t
Z
t
et
t
U
t+1
=
t
1
t+1
.
t
Z
t+1
, et on alors les relations
_
()
t
U
t
=
t1
U
t
+ C
t
R
1
Y
t
()
t
U
t+1
= [I M
t
] A
1
t
.
t
U
t
et
_
(
)
t
1
t
=
t1
1
t
+ C
t
R
1
C
t
(
)
t
1
t+1
= [I M
t
] N
t
o M
t
= N
t
(N
t
+ Q
1
)
1
et N
t
= A
1
t
.
t
1
t
.A
1
t
.
7.4.5 Comparaison des direntes mthodes dinfrence
Commenons par tudier (sur des simulations) lestimation des paramtres =
(
1
,
2
,
3
) pour un modle AR(3),
X
t
= 0.8X
t1
0.5X
t3
+
t
, i.e. = (
1
,
2
,
3
) = (0.8, 0, 0.5).
> CFYL= CFOLS= CFMLE=matrix(NA,5000,3)
> for(s in 1:5000){
+ X=arima.sim(list(ar=c(.8,0,-.5)),n=240)
+ CFYL[s,]=ar(X,order.max=3,method="yw")$ar
+ CFOLS[s,]=ar(X,order.max=3,method="ols")$ar[1:3]
+ CFMLE[s,]=ar(X,order.max=3,method="mle")$ar
+ }
> plot(density(CFYL[,k]),lwd=2,col="red",main="Composante 1 AR")
> lines(density(CFOLS[,k]),lwd=2,col="blue")
> lines(density(CFMLE[,k]),lwd=2,col="purple")
i.e. la distribution de
k
par Yule-Walker est en rouge, par moindre carrs en bleu, et
par maximum de vraisemblance est en mauve,
172
Si le bruit nest plus un bruit blanc, mais que le vrai processus simul est un processus
ARMA(3,2)
X
t
= 0.8X
t1
0.5X
t3
+
t
+ 0.4
t1
+ 0.6
t2
,
la distribution des coecients AR est alors biaise
> CFYL= CFOLS= CFMLE=matrix(NA,5000,3)
> for(s in 1:5000){
+ X=arima.sim(list(ar=c(.8,0,-.5),ma = c(.4,.6)),n=240)
+ CFYL[s,]=ar(X,order.max=3,method="yw")$ar
+ CFOLS[s,]=ar(X,order.max=3,method="ols")$ar[1:3]
+ CFMLE[s,]=ar(X,order.max=3,method="mle")$ar
+ }
7.4.6 Tests statistiques de validation du modle
Aprs avoir estim les paramtres p et q dun modle ARMA, il convient de vrier que
les polynmes AR et MA ne possdent pas de racine commune. Lorsque cest le cas, il
y a redondance, ce qui peut conduire des erreurs lors des prvisions. Il convient alors
destimer les paramtres processus ARMA avec moins de retards (ou dautres types de
retards).
Comme lors dune regression linaire, un certain nombre dindicateurs sont intres-
sants. Par exemple le test de Student des paramtres permet de vrier que les paramtres
sont bien signicatifs.
Il convient ensuite de vrier que le processus
t
est eectivement un bruit blanc.
Par exemple, pour vrier que la moyenne est nulle, on compare la moyenne
t
/2
/
n p q dans le cas dun processus p+q. Pour tester labsence dautocorrlation
de
t
, il est possible dutiliser la statistique de Box & Pierce (Q) ou la statistique de Ljung
& Box (Q
) dnies par
Q(k) = n
k
i=1
r
2
i
et Q
(k) = n(n + 2)
k
i=1
r
2
i
n i
,
qui sont comparer aux quantiles du chi-deux k (p + q) degrs de libert (lhypothse
H
0
teste tant (1) = ... = (h) = 0).
173
7.5 Choix dun modle
7.5.1 Critre de pouvoir prdicitf
Comme nous le verrons par la suite, dans un modle ARMA, lerreur de prvision
horizon 1 dpend de la variance du rsidu. On peut alors choisir le modle conduisant
la plus petite erreur de prvision. Plusieurs indicateurs sont alors possibles :
(i) la variance du rsidu
2
, ou la somme des carrs des rsidus SCR
(ii) le coecient de dtermination R
2
, correspondant une normalisation de la vari-
ance
(iii) le coevient de dtermination modi R
2
(iv) la statistique de Fisher (comme dans le cas du modle linaire)
Le but est alors de minimiser (i), ou de maximiser (ii) , (iii) ou (iv).
Exemple 236. Dans lexemple ci-dessous, considrons les 2 modles suivants : un modle
ARMA(1, 1) gauche, ou un modle AR(4), droite
soit
_
_
_
[1] : X
t
= 0.767
(0.019)
X
t1
+
t
0.463
(0.026)
t1
[2] : X
t
= 0.303
(0.014)
X
t1
+ 0.226
(0.014)
X
t1
+0.162
(0.014)
X
t1
+ 0.116
(0.014)
X
t1
Nous obtenons les indicateurs suivants
2
R
2
R
2
F-stat
[1] 1.01737 0.18304 0.18287 1119.579
[2] 1.02751 0.17505 0.17455 353.3722
Le modle [1] semble meilleur que le modle [2] : la variance du rsidu est plus faible,
mais de plus, les trois autres indicateurs sont plus levs dans le premier cas que dans le
second.
7.5.2 Critre dinformation
Cette approche a t introduite par Akake en 1969. Cette mesure de lcart entre le
modle propos et la vraie loie peut tre obtenue laide de la quantit dinformation de
Kullback.
Dnition 237. Soit f
0
la densit inconnue dobservations, et f (.) , f T la famille
des densits parmi lesquelles ont fait lestimation. Lcart entre la vraie loi et le modle
est donn par
I (f
0
, T) = min
fF
_
log
f
0
(x)
f (x)
.f
0
(x) dx
Cette quantit est toujours positive, et ne sannule que si f
0
appartient T. Cette
mesure tant inconnue puisque f
0
est inconnue, on essaiera de minimiser un estimateur
de I,
I. Plusieurs estimateur de la quantit dinformation ont t propos, dans le cas de
modles ARMA(p, q), partir de T observations,
174
(i) Aikake (1969) :
AIC (p, q) = log
2
+ 2
p + q
T
(ii) Schwarz (1977) :
BIC (p, q) = log
2
+ [p + q]
log T
T
(iii) Hanna-Quinn (1979) :
(p, q) = log
2
+ [p + q] c
log (log T)
T
avec c > 2
Exemple 238. En reprenant lexemple prcdant un critre dAkake (AIC sous EViews)
de 0.017628 pour le modle ARMA(1, 1) contre 0.027968 pour le modle AR(4) . Ici
encore, le modle ARMA est prfr au modle AR.
7.6 Application
Nous allons essayer ici de modliser la srie mensuelle du nombre de voyageurs SNCF.
7.6.1 Identication du modle : recherche des paramtres d, p et q
La srie, compose de 204 observations peut tre reprsente par
Compte tenu de la signicativit des premires autocorrlations (ou tout du moins le
fait quelles sont signicativement non-nulles pour les 40 premiers retards) suggre de
direncier au moins un fois la srie,
La srie Y
t
= (1 L) X
t
prsente alors de fortes corrlations pour les retards multi-
ples de 12 (nous retrouvons ici la saisonnalit annuelle longuement dveloppe dans les
premires parties)
La srie Z
t
= (1 L
12
) Y
t
= (1 L) (1 L
12
) X
t
semble cette fois-ci stationnaire.
Nanmois, la prsence de fortes valeurs pour (1) et (12) suggre dintroduire une
moyenne mobile de la forme (1
1
L) (1
2
L
12
). Ce type de reprsentation est con-
rm par la forme de lautocorrlogramme partiel : une modlisation de type AR n-
cessiterait dintroduire un trop grand nombre de termes (les 5 premires valeurs de
lautocorrlogramme partiel tant signicativement non-nulles). De plus, la moyenne mo-
bile (L) = (1
1
L) (1
2
L
12
) scrit
(L)
t
=
t
t1
t12
+
1
t13
admettant des autocorrlations (h) non nulles pour h = 1, 11, 12, 13 (ce qui est conrm
par le graphique des autocorrlations).
Enn, lhypothse de processus centr (ne ncessitant pas dintroduire - a priori - de
constance ou de tendance linaire) semble galement valide. En eet, la moyenne des Z
t
vaut 0.157, avec un cart-type empirique valant 169.
175
7.6.2 Estimation du modle ARIMA
Le modle retenu est un modle ARIMA, ou SARIMA, de la forme
(1 L)
_
1 L
12
_
X
t
= (1
1
L)
_
1
2
L
12
_
t
o E(
t
) = 0 et V (
t
) =
2
Les trois paramtres estimer sont
1
,
2
et
2
. Une mthode base sur les moindres
carrs permet destimer les 3 paramtres de
t
t1
t12
+
t13
:
Toutefois, cette estimation ( gauche, sous EViews) ne permet pas dintgrer la con-
trainte = .
Do nallement le modle,
(1 L)
_
1 L
12
_
X
t
=
_
1 0.8344
(0.0402)
L
__
1 0.4926
(0.0687)
L
12
_
t
X
t
= X
t1
+ X
t12
X
t13
+
t
0.8344
t1
0.4926
t12
+ 0.4110
t13
7.6.3 Vrication
On peut tout dabord noter que les rapports de Student des 2 paramtres
1
et
2
sont
respectivment 21 et 7 ( 1.96) : ce deux coecients sont signicatifs.
Toutefois, il serait bien sr possible damliorer le modle. En particulier, on peut
noter que les rsidus prsentent des pics au niveau de lautocorrlogramme pour les h
multiples de 6.
176
8 Prvisions laide des modles ARIMA : Box-
Jenkins
Etant donne une srie stationnaire (X
t
), observe entre 1 et T, on cherche faire de la
prvision horizon h, et donc prvoir X
T+1
, ..., X
T+h
. Tous les processus AR, MA et
ARMA seront supposs mis sous forme canonique, et navoir aucune racine unit. Aussi,
toutes les racines des polynmes autorgressifs et des polynmes moyennes-mobiles
auront leurs racines lextrieur du disque unit. Ainsi, pour tous les processus X
t
tels
que (L) X
t
= (L)
t
,
t
sera linnovation du processus X
t
.
8.1 Prvisions laide dun modle AR(p)
Le modle scrit, quite recentrer le processus,
X
t
=
1
X
t1
+ ... +
p
X
tp
+
t
ou (L) X
t
=
t
La prvision optimale la date T + 1, faite la date T est
T
X
T+1
=
EL(X
T+1
[X
T
, X
T1
, ...). Aussi,
T
X
T+1
=
1
X
T
+ ... +
p
X
Tp
car (
t
) est linnovation. De faon analogue, X
T+h
=
1
X
T+h1
+ ... +
p
X
T+hp
+
T+h
,
et donc
T
X
T+h
= EL(X
T+h
[X
T
, X
T1
, ...) est donn, de faon rcursive par
T
X
T+h
=
_
1
.
T
X
T+h1
+ ... +
h1
.
T
X
T+1
+
h
X
T
+ ... +
p
X
T+hp
pour h p
1
.
T
X
T+h1
+ ... +
p
.
T
X
T+hp
pour h > p
Exemple 239. Dans le cas dun processus AR(1) tel que X
t
= + X
t1
+
t
alors
(i)
T
X
T+1
= + X
T
,
(ii)
T
X
T+2
= + .
T
X
T+1
= + [ + X
T
] = [1 + ] +
2
X
T
,
(iii)
T
X
T+3
= + .
T
X
T+2
= + [ + [ + X
T
]] = [1 + +
2
] +
3
X
T
,
et rcursivement, on peut obtenir
T
X
T+h
de la forme
T
X
T+h
= + .
T
X
T+h1
=
_
1 + +
2
+ ... +
h1
+
h
X
T
.
Exemple 240. Une mthode alternative est de considrer le processus centr Y
t
= X
t
/, alors Y
t
= Y
t1
+
t
. Alors de faon rcursive
T
Y
T+h
= .
T
Y
1
T+h
, et donc
T
Y
T+h
=
h
Y
T
. Aussi, on peut crire
T
X
T+h
=
+
h
_
X
T
_
=
1
h
1
. .
1++
2
+...+
h1
+
h
X
T
.
177
8.2 Prvisions laide dun modle MA(q)
On supposera l aussi que lon sest ramen un processus centr (X
t
), satisfaisant
X
t
=
t
+
1
t1
+ ... +
q
tq
= (L)
t
.
La prvision optimale la date T + 1, faite la date T est
T
X
T+1
=
EL(X
T+1
[X
T
, X
T1
, ...) = EL(X
T+1
[
T
,
T1
, ...) car (
t
) est le processus dinnovation.
Aussi,
T
X
T+1
= 0 +
1
T
+ ... +
q
T+1q
De faon analogue, X
T+h
est estim par
T
X
T+h
= EL(X
T+h
[X
T
, X
T1
, ...) =
EL(X
T+h
[
T
,
T1
, ...), et donc
T
X
T+h
=
_
h
.
T
X
T
+ ... +
q
X
T+hq
pour h q
0 pour h > q.
(37)
Toutefois, cette mthode prsente le dsavantage destimer X
T+h
partir des rsidus
passs, a priori non observables, et non pas du pass de la variable.
8.2.1 Utilisation de lcriture AR() du processus MA(q)
Lquation X
t
= (L)
t
peut se rcrire
1
(L) X
t
=
t
, soit
X
t
=
k=1
a
k
X
tk
+
t
et donc X
t+h
=
k=1
a
k
X
t+hk
+
t+h
pour tout h 0
Aussi,
T
X
T+h
peut tre crit de faon itrative
T
X
T+h
=
h1
k=1
a
k
.
T
X
T+hk
+
k=h
a
k
X
t+hk
Toutefois, un des problmes est que les (X
t
) ne sont pas observs, en pratique, pour t < 0.
On utilise alors lcriture suivante
X
T+h
=
k=1
a
k
X
T+hk
+
t+h
=
h1
k=1
a
k
X
T+hk
+
k=h
a
k
X
T+hk
. .
Reste dune srie ACV
+
T+h
,
o le reste de la srie absolument convergente tend (au sens de L
2
) vers 0 quand T .
On peut alors considrer, quand T est susement grand que
T
X
T+h
=
h1
k=1
a
k
.
T
X
T+hk
+
T+h
k=h
a
k
X
T+hk
+
k=T+h+1
a
k
X
T+hk
. .
Ngligeable (hyp.)
,
et on approxime
T
X
T+h
par
T
X
T+h
T
X
T+h
=
h1
k=1
a
k
.
T
X
T+hk
+
T+h
k=h
a
k
X
T+hk
.
178
8.2.2 Utilisation de la formule de mise jour des rsultats
Lide est ici de comparer lestimation faite en T de X
T+1
,
T
X
T+1
avec la vraie valeur :
X
T+1
T
X
T+1
=
T+1
.
La relation (37) permet dobtenir une estimation, la date T de X
T+h
. En se plaant
la date T + 1, on peut noter que
T+1
X
T+h
=
T+1
X
(T+1)+(h1)
et donc
T+1
X
T+h
=
_
h1
T+1
+
T
X
T+h
pour h q + 1
0 pour h > q + 1,
et donc, pour h q + 1
T+1
X
T+h
=
T
X
T+h
+
h1
_
X
T+1
T
X
T+1
: Formule de mise jour
8.3 Prvisions laide dun modle ARMA(p, q)
On supposera l aussi que lon sest ramen un processus centr (X
t
), satisfaisant
(L) X
t
= (L)
t
Remarque 241. Dans le cas dun processus non centr, (L) X
t
= +(L)
t
, on peut
noter que EX
t
= /(1) = m, et que (L) (X
t
m) = (L)
t
. Il est donc toujours pos-
sible, en translatant le processus, de se ramener un processus centr (pour des processus
ARMA seulement).
Sous cette forme ARMA, alors
X
t
=
p
i=1
i
X
ti
+
t
+
q
j=1
tj
et donc X
t+h
=
p
i=1
i
X
t+hi
+
t+h
+
q
j=1
t+hj
.
On a alors
T
X
T+h
= EL(X
T+h
[X
T
, X
T1
, ...) = EL(X
T+h
[
T
,
T1
, ...) car
t
est le pro-
cessus dinnovation. On peut noter que pour h > q
T+1
X
T+h
=
_
1
.
T
X
T+h1
+ ... +
h1
.
T
X
T+1
+
h
X
T
+ ... +
p
X
T+hp
pour h p
1
.
T
X
T+h1
+ ... +
p
.
T
X
T+hp
pour h > p.
La forme gnrale des solutions est connue (comme dans le cas des AR(p)). Toutefois, il
y a ici un problme dinitialisation des calculs.
8.3.1 Utilisation de la forme AR() pu processus ARMA(p, q)
Lquation (L) X
t
= (L)
t
peut se rcrire
1
(L) (L) X
t
=
t
, cest dire, comme
dans le cas des processus MA(q),
X
t
=
k=1
a
k
X
tk
+
t
et donc X
t+h
=
k=1
a
k
X
t+hk
+
t+h
pour tout h 0,
179
et de la mme faon que pour la modlisation AR() des processus MA(q), on peut
rcrire
X
T+h
=
k=1
a
k
X
T+hk
+
t+h
=
h1
k=1
a
k
X
T+hk
+
k=h
a
k
X
T+hk
. .
ngligeable dans L
2
+
T+h
,
do la forme itrative, obtenue par approximation, en ne tenant pas compte du second
terme, ngligeable dans L
2
,
T
X
T+h
=
h1
k=1
a
k
.
T
X
T+hk
+
T+h
k=h
a
k
X
T+hk
.
8.3.2 Utilisation de la forme MA() pu processus ARMA(p, q) et des formules
de mise jour
Lquation (L) X
t
= (L)
t
peut se rcrire X
t
= (L)
1
(L)
t
soit encore
X
t
=
t
+
1
t1
+ ... +
q
tq
+ ... =
t
+
j=1
b
j
tj
.
Puisque
14
L
2
(X
t
, X
t1
, ...) = L
2
(
t
,
t1
, ...), on peut crire
T
X
T+h
=
EL(X
T+h
[X
T
, X
T1
, ...) = EL(X
T+h
[
T
,
T1
, ...), soit
T
X
T+h
=
j=h
b
j
t+hj
.
De plus, puisque
T+1
X
T+h
=
T+1
X
(T+1)+(h1)
, on peut crire
T+1
X
T+h
=
T
X
T+h
+ b
h1
_
X
T+1
T
X
T+1
: Formule de mise jour.
8.4 Prvisions dans le cas dun processus ARIMA(p, d, q)
On considrons ici (X
t
) satisfaisant une quation de la forme (L) (1 L)
d
X
t
= (L)
t
avec les conditions initiales
Z = (X
1
, ..., X
pd
,
1
, ..,
q
)
.
Posons alors (L) = (L) (1 L)
d
. La forme ARIMA(p, d, q) peut scrire
X
t
=
p+d
i=1
i
X
ti
+
t
+
q
j=1
tj
et donc X
t+h
=
p+d
i=1
i
X
t+hi
+
t+h
+
q
j=1
t+hj
.
14
Cette proprit L
2
(X
t
, X
t1
, ...) = L
2
(
t
,
t1
, ...) est une caractrisation du fait que
t
est
linnovation du processus X
t
.
180
Notons
T
X
T+h
la prvision faite la date T,
T
X
T+h
= EL(X
T+h
[X
T
, X
T1
, ..., X
0
, Z).
Alors
T
X
T+h
=
p+d
i=1
i
.
T
X
T+hi
+ 0 +
q
j=1
j
.
T
T+hj
o
_
_
_
T
X
T+hi
= X
T+hi
pour i h
T
T+hj
=
_
0 pour j < h
T+hj
pour j h
En particulier, pour h q, on obtient une relation de rcurence de la forme
T
X
T+h
=
p+d
i=1
i
.
T
X
T+hi
.
8.4.1 Utilisation de lapproximation AR
Cette approximation est base sur la proprit (186), rappele ci-dessous,
Proposition 242. Soit (X
t
) un processus ARIMA(p, d, q) de valeurs initiales Z, alors
(X
t
) peut scrire sous la forme AR,
X
t
=
t
j=1
a
j
X
tj
+ f
(t) Z +
t
,
o les a
j
sont les coecients (pour j 1) de la division selon les puissances croissantes
de par , et f
(t) est un vecteur (ligne) de fonctions de t qui tend vers 0 quand t .
On peut alors crire
X
t+h
=
t+h
j=1
a
j
X
t+hj
+ f
(t + h) Z +
t+h
,
et ainsi,
T
X
T+h
= EL(X
t+h
[X
T
, X
T1
, ..., X
0
, Z) =
t+h
j=1
a
j
.
T
X
T+hj
+ f
(T + h) Z + 0,
avec la convention
T
X
T+hj
= X
T+hj
pour j h. Or la limite de f (t) est 0 quand
t , do lapproximation
T
X
T+h
=
h1
k=1
a
k
.
T
X
T+hk
+
T+h
k=h
a
k
X
T+hk
.
181
8.4.2 Utilisation de lapproximation MA
De la mme faon, un processus ARIMA peut tre approxim par un processus MA,
Proposition 243. Soit (X
t
) un processus ARIMA(p, d, q) de valeurs initiales Z, alors
(X
t
) peut scrire sous la forme MA,
X
t
=
t
j=1
b
j
tj
+ g
(t) Z, (38)
o les h
j
sont les coecients de la division selon les puissances croissantes de par ,
et g
(t) est un vecteur (ligne) de fonctions de t.
La relation (38) permet alors dcrire
X
t+h
=
t+h
j=1
b
j
t+hj
+ g
(t + h) Z avec lim
u
g (u) = 0.
Puisque L
2
(X
t
, X
t1
, ...) = L
2
(
t
,
t1
, ...), on peut crire
T
X
T+h
=
EL(X
T+h
[X
T
, X
T1
, ..., X
0
, Z) = EL(X
T+h
[
T
,
T1
, ...,
0
, Z), soit
T
X
T+h
=
T+h
j=h
b
j
T+hj
+ g
(T + h) Z,
do les approximations, compte tenu de la limite de g (.),
T
X
T+h
=
T+h
j=h
b
j
T+hj
et
T+1
X
T+h
=
T+h
j=h1
b
j
T+hj
.
Do la relation
T+1
X
T+h
=
T
X
T+h
+ b
h1
_
X
T+1
T
X
T+1
_
: Formule de mise jour
8.5 Intervalle de conance de la prvision
Cet intervalle est obtenu partir de la forme MA() dans le cas o (X
t
) est stationnaire,
ou de son approximation MA dans le cas non-stationnaire (ARIMA).
(i) dans le cas stationnaire,
X
T+h
=
i=0
b
i
T+hi
=
T+h
i=0
b
i
T+hi
+
i=T+h+1
b
i
T+hi
,
et donc
T
h
= X
t+h
T
X
T+h
h
i=0
b
i
T+hi
.
182
(i) dans le cas non-stationnaire (ARIMA),
X
T+h
=
i=0
b
i
T+hi
+ g
(T + h) Z =
T+h
i=0
b
i
T+hi
+
i=T+h+1
b
i
T+hi
+ g
(T + h) Z,
et donc
T
h
= X
t+h
T
X
T+h
h
i=0
b
i
T+hi
.
Sous lhypothse de normalit des rsidus (
t
), H
0
:
t
i.i.d.,
t
A (0,
2
), alors
T
h
= X
t+h
T
X
T+h
A
_
0,
2
h
i=0
b
2
i
_
,
do lintervalle de conance pour X
T+h
au niveau 1
_
_
T
X
T+h
u
1/2
.s
_
h
i=0
b
2
i
_
_
,
o les
b
i
sont des estimateurs des coecients de la forme moyenne mobile, et s est un
estimateur de la variance du rsidu.
8.6 Prvision pour certains processus AR et MA
8.6.1 Prvision pour un processus AR(1)
Considrons le processus stationnaire (X
t
), sous la forme gnrale X
t
=
1
X
t1
+ +
t
.La prvision horizon 1, fait la date T, scrit
T
X
T+1
= E(X
T+1
[X
T
, X
T1
, ..., X
1
) =
1
X
T
+ ,
et de faon similaire
T
X
T+2
=
1T
X
T+1
+ =
2
1
X
T
+ [
1
+ 1] .
De faon plus gnrale, on obtient rcursivement la prvision horizon h,
T
X
T+h
=
h
1
X
T
+
_
h1
1
+ ... +
1
+ 1
. (39)
On peut noter que quand h ,
T
X
T+h
tend vers / (1
1
), la moyenne du processus
X
t
. Lerreur de prvision horizon h est donne par
T
h
=
T
X
T+h
X
T+h
=
T
X
T+h
[
1
X
T+h1
+ +
T+h
]
= ... =
T
X
T+h
h
1
X
T
+
_
h1
1
+ ... +
1
+ 1
_
+
T+h
+
1
T+h1
+ ... +
h1
1
T+1
,
183
do, en substituant (39), on obtient
T
h
=
T+h
+
1
T+h1
+ ... +
h1
1
T+1
,
qui possde la variance
V =
_
1 +
2
1
+
4
1
+ ... +
2h2
1
2
, o V (
t
) =
2
.
La variance de la prvision croit avec lhorizon.
Exemple 244. Considrons le processus suivant,
X
t
= 5 + 0.5X
t1
+
t
o
t
A (0, 1) ,
dont les dernires observations ont t 11.391, 12.748, 10.653, 9.285 et 10.738. La prvi-
sion pour la date T + 1 est alors
T
X
T+1
= E(X
T+1
[X
T
, X
T1
, ..., X
1
) =
1
X
T
+ = 5 + 0.5 10.738 = 10.369
T
X
T+2
=
_
1
.
T
X
T+1
+
(1 +
1
) +
1
.X
T
= 10.184.
Do nallement les prvisions suivantes, avec la variance, lintervalle de conance, et la
taille relative de lintervalle de conance
horizon 0 1 2 3 4 5 6 7
T
X
T+h
10.738 10.369 10.184 10.092 10.046 10.023 10.012 10.006
V 1.000 1.250 1.313 1.328 1.332 1.333 1.333
B
90%
inf
8.739 8.362 8.225 8.168 8.142 8.130 8.124
B
90%
sup
11.999 12.007 11.960 11.925 11.904 11.893 11.888
IC
90%
15.7% 17.9% 18.5% 18.7% 18.8% 18.8% 18.8%
Graphiquement, on obtient gauche les prvisions suivantes (avec la vraie valeur de
X
t
), et droite la variation relative de lintervalle de conance,
8.6.2 Prvision pour un processus MA(1)
Considrons le processus stationnaire (X
t
), sous la forme gnrale
X
t
= +
t
+
1
t1
La prvision horizon 1, fait la date T, scrit
T
X
T+1
= E(X
T+1
[X
T
, X
T1
, ..., X
1
) = +
1
T
o
T
est lerreur de la dernire observation, la date T. De faon plus gnrale, on
obtient rcursivement la prvision horizon h,
T
X
T+h
= E(X
T+h
[X
T
, X
T1
, ..., X
1
) = E( +
T+h
+
1
T+h1
) = (40)
184
Cest dire qu partir dun horizon 2, la meilleure prvision est la moyenne du processus.
Lerreur de prvision horizon h est donne par
T
h
=
T
X
T+h
X
T+h
=
T+h
+
1
T+h1
dont la variance est
V =
_
1 +
2
1
_
2
o V (
t
) =
2
pour h 2. Sinon, pour h = 1, la variance est
V =
2
1
2
.
Exemple 245. Considrons le processus suivant,
X
t
= 5 +
t
0.5
t1
o
t
A (0, 1)
dont les dernires observations ont t 4.965, 5.247, 4.686 et 5.654. Pour faire de la
prvision, soit on considre la forme AR() du processus, soit on cherche uniquement
exprimer (
t
) en fonction du pass de (X
t
), ou de Y
t
= X
t
5, processus centr
t
= Y
t
+ 0.5
t1
= Y
t
+ 0.5 [Y
t1
+ 0.5
t2
] = Y
t
+ 0.5 [Y
t1
+ 0.5 [Y
t2
+ 0.5
t3
]] = ...
=
i=0
(0.5)
i
Y
ti
=
i=0
(0.5)
i
[X
ti
5]
La prvision pour la date T + 1 est alors
T
X
T+1
= E(X
T+1
[X
T
, X
T1
, ..., X
1
) = +
1
t
= 5 0.5 0.606 = 3.3049
et la prvision un horizon h 2 est alors , la constante du modle,
T
X
T+2
= = 5
Do nallement les prvisions suivantes, avec la variance, lintervalle de conance, et la
taille relative de lintervalle de conance
horizon 0 1 2 3 4 5 6 7
T
X
T+h
5.654 3.304 5.000 5.000 5.000 5.000 5.000 5.000
V 0.250 1.250 1.250 1.250 1.250 1.250 1.250
B
90%
inf
2.489 3.178 3.178 3.178 3.178 3.178 3.178
B
90%
sup
4.119 6.822 6.822 6.822 6.822 6.822 6.822
IC
90%
24.7% 36.4% 36.4% 36.4% 36.4% 36.4% 36.4%
Graphiquement, on obtient gauche les prvisions suivantes (avec la vraie valeur de
X
t
), et droite la variation relative de lintervalle de conance,
185
8.6.3 Prvision pour un processus ARIMA(1, 1, 0)
Il sagit ici dun modle AR(1) pour la variable intgre Y
t
= X
t
X
t1
, Y
t
=
1
Y
t1
+
+
t
. Aussi, la prvision horizon h = 1 est donne par
T
X
T+1
= X
T
+
T
Y
T+1
,
et de faon plus gnrale
T
X
T+h
= X
T
+
T
Y
T+1
+
T
Y
T+2
+ ... +
T
Y
T+h
.
En substituant aux
T
Y
T+i
ce qui a t trouv prcdemment pour les processus AR, on
obtient
T
X
T+1
= (1 +
1
) X
T
1
X
T1
+ ,
et, pour un horizon h = 2,
T
X
T+2
=
_
1 +
1
+
2
1
_
X
T
_
1
+
2
1
_
X
T1
+ (
1
+ 1) + .
Lexpression gnrale de la prvision la date h sobtient rcursivement laide de
_
T
Y
T+h
=
h
1
Y
T
+
_
h1
1
+ ... +
1
+ 1
T
X
T+h
=
T
X
T+1
+
1
.
T
Y
T+h1
+ .
Lerreur faite sur la prvision horizon 1 est donne par
T
1
=
T
X
T+1
X
T+1
=
T
Y
T+1
Y
T+1
=
T+1
, de variance
2
.
A horizon 2, lerreur de prvision est
T
2
=
T
X
T+2
X
T+2
=
_
T
Y
T+1
Y
T+1
_
+
_
T
Y
T+2
Y
T+2
_
= (1 +
1
)
T+1
+
T+2
,
dont la variance est
V =
_
1 + (1 +
1
)
2
2
. De faon plus gnrale, lerreur de prvision
horizion h est
T
h
=
_
T
Y
T+1
Y
T+1
_
+
_
T
Y
T+2
Y
T+2
_
+
_
T
Y
T+1
Y
T+1
_
+ ... +
_
T
Y
T+h
Y
T+h
_
=
T+1
+ (
T+2
+
1
T+1
) + ... +
_
T+h
+
1
T+h1
+ ... +
h2
1
T+2
+
h1
1
T+1
_
=
T+h
+ (1 +
1
)
T+h1
+ ... +
_
1 +
1
+ ... +
h1
1
_
T+1
,
do la variance
V =
_
_
h
i=1
_
i1
j=0
j
1
_
2
_
_
2
.
Lerreur de prvision sur X
T+h
est alors laccumulation des erreurs de prvision de
Y
T+1
, ..., Y
T+h
.
186
Exemple 246. Considrons le processus (X
t
) tel que X
t
X
t1
= Y
t
o (Y
t
) vrie,
Y
t
= 2 + 0.2Y
t1
+
t
o
t
A (0, 1) ,
dont les dernires observations ont t 81.036, 84.074 et 86.586. Le processus (Y
t
) sous-
jacent peut tre obtenu comme dirence entre X
t
et X
t1
. On cherche alors les prvisions
de (Y
t
) et les prvisions de (X
t
) correspondent la somme des (Y
t
) prvus (processus
intgr).
(X
t
) 70.788 73.606 74.937 78.035 81.036 84.074 86.586
(Y
t
) 2.818 1.331 3.098 3.001 3.037 2.512
La prvision pour la date T + 1 est alors
T
X
T+1
= X
T
+
T
Y
T+1
o
T
Y
T+1
= +
1
Y
T
= 2.502,
et donc
T
X
T+1
= 89.088. Lla prvision un horizon h 2 est alors
T
X
T+2
= X
T
+
T
Y
T+1
+
T
Y
T+2
o
_
T
Y
T+1
= +
1
Y
T
= 2.5024
T
Y
T+2
= +
1
.
T
Y
T+1
= 2.5005
Do nallement les prvisions suivantes, avec la variance, lintervalle de conance, et la
taille relative de lintervalle de conance
horizon 0 1 2 3 4 5 6 7
T
Y
T+h
2.512 2.502 2.500 2.500 2.500 2.500 2.500 2.500
T
X
T+h
86.586 89.088 91.589 94.089 96.589 99.089 101.59 104.09
V 1.000 2.440 3.978 5.535 7.097 8.659 10.22
B
90%
inf
87.458 89.043 90.838 92.754 94.747 96.793 98.878
B
90%
sup
90.718 94.135 97.340 100.42 103.43 106.39 109.30
IC
90%
1.8% 2.8% 3.5% 4.0% 4.4% 4.7% 5.0%
Graphiquement, on obtient gauche les prvisions suivantes (avec la vraie valeur de
X
t
), et droite la variation relative de lintervalle de conance,
8.7 Application
8.7.1 Example de prvision : cas dcole
Considrons le modle ARIMA(1, 1, 1) donn par
(1 L) (1 0.5L) X
t
= (1 0.8L)
t
,
o lon suppose que
t
est gaussien, centr, de variance connue
2
= 0.5, avec X
T
= 12 et
T
X
T+1
= EL
_
X
T+1
[X
T
_
= 10, o X
T
= X
1
, ..., X
T
, Z.
La prvision horizon h faite en T est
T
X
T+h
= E
_
X
T+h
[X
T
_
.
187
(i) estimation de
T
X
T+h
: Cette forme ARIMA scrit
X
t
1
X
t1
2
X
t2
=
t
+
1
t1
, avec une racine unit.
Aussi, pour h 2, on peut crire
T
X
T+h
1
.
T
X
T+h1
2
.
T
X
T+h2
= 0. Pour expliciter
les solutions, on se ramne au problme suivant : recherche des suites u
n
telle que u
n
=
u
n1
+u
n2
15
. Les racines du polynme caractristique tant 1 et 1/2, on peut crire
T
X
T+k
= .1
h
+. (1/2)
h
. Compte tenu du fait que X
T
= 12 et
T
X
T+1
= 10 on en dduit
= 8 et = 4. Aussi
T
X
T+h
= 8 +
4
2
k
do les premires valeurs 12, 10, 9, 8.5, 8.25, 8.125, ...
(ii) expression de lintervalle de conance : Lintervalle de conance 95% de la
prvision est de la forme
_
T
X
T+h
1.96
_
V
_
T
X
T+h
_
;
T
X
T+h
+ 1.96
_
V
_
T
X
T+h
_
_
.
Cette variance sobtient en approximant la forme ARIMA par une forme MA(),
X
T+1
X
T
=
T
+ b
1
T1
+ b
2
T2
+ ...
On note alors que
_
_
X
T+1
X
T
=
T+1
+ b
1
T
+ b
2
T1
+ ...
X
T+2
X
T+1
=
T+2
+ b
1
T+1
+ b
2
T
+ ...
...
X
T+h
X
T+h1
=
T+h
+ b
1
T+h1
+ b
2
T+h2
+ ...
do , par sommation, lexpression de X
T+h
X
T
et en considrant la variance (puique
les
t
sont identiquement distribus, de variance
2
, et surtout indpendant),
V
_
T
X
T+h
_
=
2
_
1 + (1 +b
1
)
2
+ (1 + b
1
+ b
2
)
2
+ ... + (1 + b
1
+ ... + b
h
)
2
.
Or lexpression des b
i
est donne par la relation B(L) = (L)
1
(L) =
(1 0.8L) (1 0.5L)
1
B(L) = (1 0.8L)
_
1 + 0.5L + 0.5
2
L
2
+ ...
_
= 1 0.3L 0.3
L
2
2
0.3
L
3
2
2
...
15
Rappel : Pour une relation rcurente u
n
= u
n1
+ u
n2
, la forme gnrale des solutions est
u
n
= r
n
1
+r
n
2
o r
1
et r
2
sont les racines du polynme P (x) = x
2
x , dans le cas o les racines
sont distinctes. Dans le cas o P admet une racine double (r), la forme gnrale est u
n
= ( +r) r
n
.
Dans le cas o la suite est entirement dtermine par les valeurs initiales u
1
et u
2
, alors et sont
entirement dtermins par la rsolution du systme
_
u
1
= r
1
+r
2
u
2
= r
2
1
+r
2
2
188
et donc b
0
= 1 et b
i
= 0.3/2
i1
. Aussi
1 + b
1
+ ...b
j
= 1 0.3
_
1 +
1
2
+
1
4
+ ... +
1
2
j1
_
= 1 0.6
_
1
1
2
j
_
= 0.4 +
0.6
2
j
,
et donc
V
_
T
X
T+h
_
=
2
h1
j=0
_
0.4 +
0.6
2
j
_
2
.
Do nalement les prvisions et les premiers intervalles de conance suivant :
h 0 1 2 3 4 5 6 7 8 9 10
B
95%
inf
8.040 6.444 5.560 5.015 4.639 4.353 4.116 3.906 3.715 3.535
B
90%
inf
8.360 6.862 6.040 5.543 5.209 4.959 4.755 4.577 4.416 4.265
T
X
T+h
12.000 10.000 9.000 8.500 8.250 8.125 8.063 8.031 8.016 8.007 8.004
B
90%
sup
11.640 11.138 10.960 10.957 11.041 11.166 11.307 11.454 11.600 11.743
B
95%
sup
11.960 11.556 11.440 11.485 11.611 11.772 11.947 12.125 12.301 12.473
IC
95%
19.6% 28.4% 34.6% 39.2% 42.9% 46.0% 48.7% 51.3% 53.6% 55.8%
On notera bien sur cet exemple que les prvisions laide dun modle ARIMA
moyen terme sont dj relativement incertaines. Graphiquement, on obtient, gauche, la
prvision suivante (avec les intervalles de conance 90% et 95%), et droite, lvolution
relative de lintervalle de conance en fonction de lhorizon de prvision
8.7.2 Exemple dapplication : cas pratique
Considrons ici la srie du nombre de voyageurs SNCF, et la modlisation ARIMA que
nous avions pu faire,
(1 L)
_
1 L
12
_
X
t
=
_
1 0.8344
(0.0402)
L
__
1 0.4926
(0.0687)
L
12
_
t
. (41)
La srie Z
t
peut alors tre utilise pour faire de la prvision, laide de sa modlisation
MA.
Comme nous le voyons sur cet exemple, la prvision laide dun modliation ARMA
reste relativement oue, mme ici court terme (un exemple analogue sera repris plus en
dtails dans la partie suivante).
189
9 Mise en oeuvre de la mthode de Box & Jenkins
9.1 Application de la srie des taux dintrt 3 mois
Nous allons considrr ici les taux 3 mois du trsor amricain (comme le propose Pindyck
et Rubinfeld (1998)), donnes mensuelles, de Janvier 1960 Mars 1996.
> base=read.table("http://freakonometrics.free.fr/basedata.txt",header=TRUE)
> Y=base[,"R"]
> Y=Y[(base$yr>=1960)&(base$yr<=1996.25)]
> Y=ts(Y,frequency = 4, start = c(1960, 1))
>
> Y
Qtr1 Qtr2 Qtr3 Qtr4
1960 3.873 2.993 2.360 2.307
1961 2.350 2.303 2.303 2.460
1962 2.723 2.717 2.840 2.813
1963 2.907 2.940 3.293 3.497
1964 3.530 3.477 3.497 3.683
...
1993 2.960 2.967 3.003 3.060
1994 3.243 3.987 4.477 5.280
1995 5.737 5.597 5.367 5.260
1996 4.930 5.020
Lautocorrlogramme de la srie bute des taux (X
t
) permet de se rendre compte rapi-
dement que la srie nest pas stationnaire.
> acf(Y,lwd=5,col="red")
> pacf(Y,lwd=5,col="red")
190
La srie direncie Y
t
= X
t
X
t1
a lallure suivante,
> plot(diff(Y))
> acf(diff(Y),lwd=5,col="red")
> pacf(diff(Y),lwd=5,col="red")
La srie ainsi forme semble stationnaire. A titre comparatif, la srie Z
t
obtenue en
direnciant 2 fois donne des rsultats ne semblant pas signicativement dirents
Aussi, direncier 1 fois sut pour obtenir un modle stationnaire.
9.1.1 Modlisation de la srie
Compte tenu de lallure des autocorrlogrammes de Y
t
, nous pouvons penser modliser la
srie X
t
par un processus ARMA(p, q). La mthode du coin, dcrite auparavant, donne
191
le tableau suivant
ij 1 2 3 4 5 6
1 0.272 0.189 0.007 0.024 0.041 0.148
2 0.116 0.041 0.006 0.001 0.003 0.040
3 0.102 0.006 0.003 0.001 0.001 0.011
4 0.042 0.007 0.002 0.002 0.003 0.003
5 0.055 0.004 0.005 0.002 0.001 0.001
6 0.180 0.043 0.012 0.003 0.001 0.000
9.1.2 Estimation des paramtres dune modlisation ARIMA(1, 1, 1)
Lestimation donne les rsultats suivants (la constante tait clairement non signicative),
_
1 + 0.3341
(0.1066)
L
_
Y
t
=
_
1 + 0.7403
(0.0616)
L
_
t
> arima(X,order=c(1,1,1))
Call:
arima(x = X, order = c(1, 1, 1))
Coefficients:
ar1 ma1
-0.3341 0.7403
s.e. 0.1066 0.0616
sigma^2 estimated as 0.6168: log likelihood = -170.89, aic = 347.78
sur la srie brute, ou encore, sur la srie direncie
> arima(diff(X),order=c(1,0,1))
Call:
arima(x = diff(X), order = c(1, 0, 1))
Coefficients:
ar1 ma1 intercept
-0.3342 0.7403 0.0076
s.e. 0.1066 0.0616 0.0850
sigma^2 estimated as 0.6168: log likelihood = -170.88, aic = 349.77
Si les estimations semblent signicative, le rsidu ne semble pas tre un bruit blanc.
Ltape suivante est donc daugmenter le nombre de paramtres.
192
9.1.3 Estimation des paramtres dune modlisation ARIMA(2, 1, 2)
Lestimation donne les rsultats suivants (la constante tant l aussi non signicative),
_
1 + 1.26
(0.095)
L + 0.49
(0.088)
L
2
_
Y
t
=
_
1 + 1.767
(0.067)
L 0.8778
(0.054)
L
2
_
t
o Y
t
= (1 L)X
t
> arima(X,order=c(2,1,2))
Call:
arima(x = X, order = c(2, 1, 2))
Coefficients:
ar1 ar2 ma1 ma2
-1.2655 -0.4945 1.7672 0.8778
s.e. 0.0952 0.0884 0.0675 0.0546
sigma^2 estimated as 0.5435: log likelihood = -162.24, aic = 334.48
A titre dinformation, le modle avec constante scrit
_
1 + 1.26
(0.095)
L + 0.49
(0.088)
L
2
_
Y
t
=
_
1 + 1.767
(0.067)
L 0.8778
(0.054)
L
2
_
t
+ 0.007
(0.08)
> arima(X,order=c(2,1,2),xreg=1:length(Y))
Series: X
ARIMA(2,1,2)
Coefficients:
ar1 ar2 ma1 ma2 xreg
-1.2658 -0.4950 1.7671 0.8779 0.0072
s.e. 0.0953 0.0884 0.0676 0.0547 0.0807
sigma^2 estimated as 0.5434: log likelihood=-162.24
AIC=334.47 AICc=335.08 BIC=352.33
Encore une fois, lhypothse de bruit blanc des rsidus est rejete, de part la prsence
dautocorrlations signicativement non nulles.
9.1.4 Estimation des paramtres dune modlisation ARIMA(4, 1, 4)
Lestimation donne les rsultats suivants
> arima(X,order=c(4,1,4))
Series: X
ARIMA(4,1,4)
Coefficients:
ar1 ar2 ar3 ar4 ma1 ma2 ma3 ma4
-0.3360 0.0409 -0.3508 -0.1562 0.7713 -0.2380 0.3536 0.6052
s.e. 0.3592 0.3459 0.2173 0.1736 0.3406 0.4341 0.2400 0.1916
sigma^2 estimated as 0.5205: log likelihood=-159.2
AIC=334.4 AICc=335.74 BIC=361.19
193
9.1.5 Estimation des paramtres dune modlisation ARIMA(8, 1, 2)
Lestimation donne les rsultats suivants,
> arima(Y,order=c(8,1,2))
Series: Y
ARIMA(8,1,2)
Coefficients:
ar1 ar2 ar3 ar4 ar5 ar6 ar7 ar8 ma1 ma2
0.5309 0.3147 0.1282 0.1482 -0.1449 0.1134 -0.4324 0.2575 -0.1191 -0.8809
s.e. 0.0983 0.1076 0.0931 0.0920 0.0871 0.0859 0.0821 0.0818 0.0737 0.0721
sigma^2 estimated as 0.4826: log likelihood=-154.69
AIC=329.38 AICc=331.36 BIC=362.12
9.1.6 Estimation des paramtres dune modlisation ARIMA(8, 1, 4)
Lestimation donne les rsultats suivants,
> arima(Y,order=c(8,1,4))
Series: Y
ARIMA(8,1,4)
Coefficients:
ar1 ar2 ar3 ar4 ar5 ar6 ar7 ar8 ma1 ma2 ma3 ma4
0.6885 0.2197 0.0672 0.1619 -0.1847 0.1454 -0.4762 0.3106 -0.2908 -0.8308 0.1653 -0.0437
s.e. 0.4166 0.3146 0.2872 0.2922 0.1205 0.1227 0.1132 0.1353 0.4125 0.4678 0.3788 0.4919
sigma^2 estimated as 0.4817: log likelihood=-154.48
AIC=332.97 AICc=335.75 BIC=371.67
9.1.7 Choix du modle
Les dirents critres sont
2
AIC log L
ARIMA(1, 1, 1) 0.6168190 347.7753 170.8877
ARIMA(2, 1, 2) 0.5434549 334.4843 162.2421
ARIMA(4, 1, 4) 0.5204500 336.4037 159.2019
ARIMA(8, 1, 2) 0.4826461 331.3783 154.6892
ARIMA(8, 1, 4) 0.4816530 334.9689 154.4845
> matrix(c(arima111$sigma2,arima212$sigma2,arima414$sigma2,arima812$sigma2,arima814$sigma2,
+ arima111$aic,arima212$aic,arima414$aic,arima812$aic,arima814$aic,
+ arima111$loglik,arima212$loglik,arima414$loglik,arima812$loglik,arima814$loglik),5,3)
[,1] [,2] [,3]
[1,] 0.6168190 347.7753 -170.8877
[2,] 0.5434549 334.4843 -162.2421
[3,] 0.5204500 336.4037 -159.2019
[4,] 0.4826461 331.3783 -154.6892
[5,] 0.4816530 334.9689 -154.4845
194
Aucun modle ne semble vraiment bien modliser la srie. En fait, aucun modle de
type ARMA ne pourra prendre en compte le pic de volatilit au dbut des annes 80. Les
modles ARCH pourraient tre une alternative intressantes, mais au del de lobjectif
du cours.
9.2 Modlisation du taux de croissance du PIB amricain
La srie suivante correspond au PIB amricain, depuis 1947
> base=read.table("http://freakonometrics.free.fr/GDP_United_States2.csv",
+ header=TRUE,sep=",")
> > Y=rev(base[,3])
Y=ts(Y,frequency = 4, start = c(1947, 1))
> plot(Y)
Il est parfois plus simple de travailler sur le taux de croissance trimestriel
> Z=diff(Y)/Y
> plot(Z)
195
> acf(Y,lwd=5,col="red")
> pacf(Y,lwd=5,col="red")
Compte tenu de la forme des autocorrlations, il est possible de tester un modle
AR(3), i.e.
Nous obtenons le modle suivant
X
t
0.35X
t1
0.18X
t2
+ 0.11X
t3
= 0.007 +
t
> (modele=arima(Z,order=c(3,0,0)))
Series: Z
ARIMA(3,0,0) with non-zero mean
Coefficients:
ar1 ar2 ar3 intercept
0.3518 0.1279 -0.1152 0.0078
s.e. 0.0618 0.0651 0.0618 0.0009
sigma^2 estimated as 8.18e-05: log likelihood=847.87
AIC=-1687.73 AICc=-1687.5 BIC=-1669.97
On peut noter que le polynme autorgressif scrit
_
1 0.35L 0.13L
2
+ 0.11L
3
_
= (1 + 0.46L)
_
1 0.87L + 0.27L
2
_
o le second terme a des racines complexes conjugues.
> library(polynom)
> polyroot(c(1,-modele$coef[1:3]))
[1] 1.635739+1.157969i -2.161224-0.000000i 1.635739-1.157969i
> 2*pi/Arg(polyroot(c(1,-modele$coef[1:3])))
[1] 10.19964 -2.00000 -10.19964
On peut alors noter que la longueur moyenne du cycle stochastique est alors de 10.2
trimestres, cest dire entre 2 ans et demi et 3 ans.
196
Você também pode gostar
- Calcul StochastiqueDocumento88 páginasCalcul StochastiqueAli Hachimi Kamali100% (1)
- Arch GarchDocumento17 páginasArch Garchvotrebush100% (2)
- Cours de Series TemporellesDocumento178 páginasCours de Series TemporellesZeroualiBilelAinda não há avaliações
- 1 Com Nat Recueil Exercices IeBC PDFDocumento23 páginas1 Com Nat Recueil Exercices IeBC PDFMohieddine KhailiAinda não há avaliações
- JOEL DE VINTUIT-Tous Les Rituels Alchimiques Du Baron de Tschoudy - (Atramenta - Net)Documento199 páginasJOEL DE VINTUIT-Tous Les Rituels Alchimiques Du Baron de Tschoudy - (Atramenta - Net)Welder Oliveira100% (1)
- Series ChronologiqueDocumento53 páginasSeries ChronologiqueOthmane Aouinatou50% (2)
- Séries Chronologiques Version FinaleDocumento24 páginasSéries Chronologiques Version FinaleSalem MriguaAinda não há avaliações
- Cizia Zyke - FièvresDocumento149 páginasCizia Zyke - Fièvresdigital_doll0% (1)
- 2017 2018 Examen CorrigéDocumento10 páginas2017 2018 Examen CorrigéEl youssfi100% (1)
- Version Finale ARCHDocumento47 páginasVersion Finale ARCHEL MAOULI ZAKARIA100% (3)
- L Inconnu Et Les Problemes Psychiques IDocumento128 páginasL Inconnu Et Les Problemes Psychiques InAinda não há avaliações
- Traité de gestion de portefeuille, 5e édition actualisée: Titres à revenu fixe et produits structurés - Avec applications Excel (Visual Basic)No EverandTraité de gestion de portefeuille, 5e édition actualisée: Titres à revenu fixe et produits structurés - Avec applications Excel (Visual Basic)Ainda não há avaliações
- Théorie Des Jeux Last Version PDFDocumento87 páginasThéorie Des Jeux Last Version PDFHassan AsserrarAinda não há avaliações
- Modele Mathématique de La FinanceDocumento445 páginasModele Mathématique de La FinanceMarouane Belgouzi100% (2)
- Series ChronologiquesDocumento146 páginasSeries Chronologiquessoufianebr67% (3)
- Series ChronologiquesDocumento16 páginasSeries ChronologiquesWalid Fezzani100% (1)
- Cours StochastiqueDocumento125 páginasCours StochastiqueAnass ChertiAinda não há avaliações
- Cours ÉconométrieDocumento45 páginasCours ÉconométrieHayfa ElkadhiAinda não há avaliações
- Poly Cours Monte Carlo m1 ImDocumento55 páginasPoly Cours Monte Carlo m1 ImJoe Castro100% (1)
- Pratique de L'économétrie Des Séries Chronologiques - Partie2Documento64 páginasPratique de L'économétrie Des Séries Chronologiques - Partie2Samuel100% (1)
- Méthodes de Monte Carlo Et Chaînes de Markov Pour La SimulationDocumento122 páginasMéthodes de Monte Carlo Et Chaînes de Markov Pour La SimulationbouhelalAinda não há avaliações
- Poly Econometrie FinanceDocumento171 páginasPoly Econometrie FinanceHatim El OtmaniAinda não há avaliações
- 2003 - Les Séries Temporelles - CoursDocumento34 páginas2003 - Les Séries Temporelles - CoursFranck DernoncourtAinda não há avaliações
- Chapitre 2 Processus StochastiqueDocumento20 páginasChapitre 2 Processus Stochastiqueemna benabdallahAinda não há avaliações
- Guide EviewsDocumento0 páginaGuide EviewsNassiri Mohamed100% (1)
- Calcul Stochastique PDFDocumento115 páginasCalcul Stochastique PDFLarbiBenAllalAinda não há avaliações
- Finance Stochastique PDFDocumento169 páginasFinance Stochastique PDFLarbiBenAllalAinda não há avaliações
- Calcul Stochastique Finance 07 L2Documento23 páginasCalcul Stochastique Finance 07 L2jioloiAinda não há avaliações
- TD 6 Telecoms Communications Par SatellitesDocumento2 páginasTD 6 Telecoms Communications Par SatellitesMohamed ElamriAinda não há avaliações
- Offre Statistique Filière DSDocumento20 páginasOffre Statistique Filière DSamineAinda não há avaliações
- Exposé ARIMADocumento29 páginasExposé ARIMAMourad Ennakhli Dehbi100% (2)
- Master 1 MMD - Séries Temporelles (Paris-Dauphine)Documento196 páginasMaster 1 MMD - Séries Temporelles (Paris-Dauphine)L.CamoAinda não há avaliações
- Ec PanelsDocumento237 páginasEc PanelsMohammed TaamAinda não há avaliações
- Séries Chro InseaDocumento116 páginasSéries Chro InseaEL Hafa AbdellahAinda não há avaliações
- Methodes Delphi Et Box JenkinsDocumento10 páginasMethodes Delphi Et Box JenkinsMartin OlingaAinda não há avaliações
- Lissage ExponentielDocumento52 páginasLissage ExponentielSou Haila100% (1)
- Les Méthodes de Prévitions de La DemandeDocumento8 páginasLes Méthodes de Prévitions de La DemandeSalaheddineAinda não há avaliações
- Econometri PDFDocumento37 páginasEconometri PDFstevy darel100% (1)
- L'Économétrie Des Données Des PanelDocumento6 páginasL'Économétrie Des Données Des PanelHouria HssAinda não há avaliações
- ARIMA ARMA FinalDocumento40 páginasARIMA ARMA FinalWijdane ElouargaAinda não há avaliações
- Modélisation Des Options Asiatiques Sur Le Taux de Change. Auteur: MARIANE Mouhammed, ENSAEDocumento47 páginasModélisation Des Options Asiatiques Sur Le Taux de Change. Auteur: MARIANE Mouhammed, ENSAEmariane75% (4)
- 2016 Economie Publique Corrige TD 9Documento4 páginas2016 Economie Publique Corrige TD 9Mikapanga100% (1)
- Introduction À L'analyse Des Séries TemporellesDocumento42 páginasIntroduction À L'analyse Des Séries TemporellesKediha YassineAinda não há avaliações
- Mouvement Brownien Et Calcul StochastiqueDocumento24 páginasMouvement Brownien Et Calcul StochastiqueGharsalliAinda não há avaliações
- Modelisation Taux de Change EUR USDDocumento40 páginasModelisation Taux de Change EUR USDASSELOKA AmadouAinda não há avaliações
- !!!!!!!!!!!!!!!!!!!!!!!!! 1 A Voir Econometrie Des Serie Temporelle !!!!!!!!!!!!!Documento70 páginas!!!!!!!!!!!!!!!!!!!!!!!!! 1 A Voir Econometrie Des Serie Temporelle !!!!!!!!!!!!!EI Ahmed100% (1)
- 55 Analyse Prevision Box Jenkins DerDocumento43 páginas55 Analyse Prevision Box Jenkins Deranxco100% (2)
- Methodes Quantitatives en FinanceDocumento15 páginasMethodes Quantitatives en FinanceMohamed EladnaniAinda não há avaliações
- L'econométrie - Le Processus Stationnaire PDFDocumento13 páginasL'econométrie - Le Processus Stationnaire PDFTaha Can100% (2)
- Quali M1 PDFDocumento110 páginasQuali M1 PDFLokmaneAinda não há avaliações
- Cointegration de JohansenDocumento27 páginasCointegration de JohansenABDESSAMAD EL YAHYAOUI100% (1)
- Series ChronologiquesDocumento14 páginasSeries ChronologiquesMaria Amina100% (1)
- Exposé Méthode ARMADocumento10 páginasExposé Méthode ARMAGOUAL SaraAinda não há avaliações
- Modèle de PanelDocumento27 páginasModèle de PanelWalid Bouqayes50% (2)
- VaR SONDJODocumento30 páginasVaR SONDJOisiris34Ainda não há avaliações
- Donnéesde Panel 2010Documento183 páginasDonnéesde Panel 2010Amina Badreddine100% (1)
- Chapitre 1Documento45 páginasChapitre 1mokhtarifatimaezzahraAinda não há avaliações
- LES MODELES ARCH ET GARCH (PDFDrive)Documento16 páginasLES MODELES ARCH ET GARCH (PDFDrive)assoudou100% (2)
- La théorie des jeux: Thrillers judiciaires de Katerina Carter, #2No EverandLa théorie des jeux: Thrillers judiciaires de Katerina Carter, #2Ainda não há avaliações
- Probabilités et statistiques: Ce que j'en ai compris, si ça peut aider…No EverandProbabilités et statistiques: Ce que j'en ai compris, si ça peut aider…Ainda não há avaliações
- Cours de Series Temporelles Theorie Et ApplicationsDocumento178 páginasCours de Series Temporelles Theorie Et ApplicationsHelali KamelAinda não há avaliações
- LecturenotesDocumento80 páginasLecturenotesfle92Ainda não há avaliações
- Cours SC PDFDocumento153 páginasCours SC PDFMohamed RdaitAinda não há avaliações
- C01 ExosDocumento2 páginasC01 Exosc_landelAinda não há avaliações
- Astrology DictionaryDocumento5 páginasAstrology DictionaryMohd Wasiuulah KhanAinda não há avaliações
- Annale Bac S2 1 Avril 2013 CDocumento200 páginasAnnale Bac S2 1 Avril 2013 Cbourimn3374Ainda não há avaliações
- Géomatique 1Documento40 páginasGéomatique 1Lamine HddAinda não há avaliações
- Teste 7º Ano - Les LoisirsDocumento4 páginasTeste 7º Ano - Les Loisirssbpaz2197100% (1)
- rakotondrazakaHerihajaniainaN ESPA MAST 14Documento85 páginasrakotondrazakaHerihajaniainaN ESPA MAST 14abfstbmsodAinda não há avaliações
- Cerbère Et PlutonDocumento2 páginasCerbère Et PlutonAdolfAinda não há avaliações
- FreDocumento347 páginasFreAymen HssainiAinda não há avaliações
- Rimbaud x3 2Documento3 páginasRimbaud x3 2Lilyaa1321Ainda não há avaliações
- Poster Effet de SerreDocumento1 páginaPoster Effet de Serreangel6665579Ainda não há avaliações
- Chapitre 2 - Processus Hydraulique en MerDocumento118 páginasChapitre 2 - Processus Hydraulique en MerFati KhAinda não há avaliações
- Agfa Box 50-LangDocumento14 páginasAgfa Box 50-Langpati.gualterosbAinda não há avaliações
- LES AURORES Boréales Et Australes MTUDocumento32 páginasLES AURORES Boréales Et Australes MTUThepasMilandAinda não há avaliações
- Rachedi Proposition Sujet Master Physique 2017 2018Documento2 páginasRachedi Proposition Sujet Master Physique 2017 2018Mohamed Yacine RachediAinda não há avaliações
- LieuxDocumento2 páginasLieuxFabien LeroyAinda não há avaliações
- Conception D'un Capteur Solaire Plan (Métal-Polymère) PDFDocumento60 páginasConception D'un Capteur Solaire Plan (Métal-Polymère) PDFAbdelkader Faklani Dou0% (1)
- Le Pays Des Fourrures by Verne, Jules, 1828-1905Documento303 páginasLe Pays Des Fourrures by Verne, Jules, 1828-1905Gutenberg.orgAinda não há avaliações
- Contrôle de Transfert de chaleur-EMI-exam10 PDFDocumento2 páginasContrôle de Transfert de chaleur-EMI-exam10 PDFfakehiAinda não há avaliações
- MMMemoireDocumento68 páginasMMMemoirehounmenousamsonsedamiAinda não há avaliações
- La Théorie Du ChaosDocumento12 páginasLa Théorie Du ChaosAhmed RomdhaniAinda não há avaliações
- Descraques - Apres L Heure C Est Plus L Heure Le VisDocumento40 páginasDescraques - Apres L Heure C Est Plus L Heure Le VisHerve CarboneAinda não há avaliações
- 2018 ClimrealshortDocumento32 páginas2018 ClimrealshortCécile BerlanAinda não há avaliações
- DM RosettaDocumento2 páginasDM RosettaYoussef MzabiAinda não há avaliações
- Mec6214 - Devoir 01 - 2019-01-07Documento3 páginasMec6214 - Devoir 01 - 2019-01-07FugulusAinda não há avaliações
- Lilia Hassaine: Soleil AmerDocumento21 páginasLilia Hassaine: Soleil AmerLllo OoooAinda não há avaliações