Você também pode gostar
- Ejercicios de Distribución de ProbabilidadDocumento10 páginasEjercicios de Distribución de ProbabilidadEfrain' BallesterosAinda não há avaliações
- Libro 1Documento2 páginasLibro 1Ricardo Centenaro QuintanaAinda não há avaliações
- Perfil de Puesto - FinalDocumento5 páginasPerfil de Puesto - FinalRicardo Centenaro QuintanaAinda não há avaliações
- Diseno Construccion Maquina Gonzalez 2008Documento76 páginasDiseno Construccion Maquina Gonzalez 2008Ricardo Centenaro QuintanaAinda não há avaliações
- Qué Es Un Tratado de Libre ComercioDocumento8 páginasQué Es Un Tratado de Libre ComercioRicardo Centenaro QuintanaAinda não há avaliações
- Mapas de PublicidadDocumento6 páginasMapas de PublicidadRicardo Centenaro QuintanaAinda não há avaliações
- Perfil de EconomistaDocumento3 páginasPerfil de EconomistaRicardo Centenaro QuintanaAinda não há avaliações
- Actividad de Quimica No EntregableDocumento8 páginasActividad de Quimica No EntregableDaniel Santiago Mora PinedaAinda não há avaliações
- Principio de Incertidumbre de HeisenbergDocumento3 páginasPrincipio de Incertidumbre de HeisenbergAlexander Ramirez ContrerasAinda não há avaliações
- Cuestionario El Átomo, Estructura, Modelo AtómicoDocumento3 páginasCuestionario El Átomo, Estructura, Modelo AtómicoYhan CardenasAinda não há avaliações
- Densidad de EstadosDocumento6 páginasDensidad de EstadosFreddy RamirezAinda não há avaliações
- Examen Final M.cuantica Dela Cruz Gonzales Jesus 16130101Documento4 páginasExamen Final M.cuantica Dela Cruz Gonzales Jesus 16130101Worren SuarezAinda não há avaliações
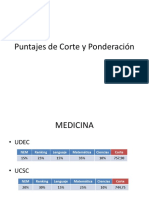
- Puntajes de Corte y PonderaciónDocumento15 páginasPuntajes de Corte y PonderaciónClave MorsaAinda não há avaliações
- Prueba de Kruskal - WallisDocumento7 páginasPrueba de Kruskal - WallisGaby Rocha0% (1)
- Mar de Dirac PDFDocumento2 páginasMar de Dirac PDFNoe Hernandez TorrejonAinda não há avaliações
- 1623350676Documento38 páginas1623350676Oswaldo castromonte solanoAinda não há avaliações
- MFT 32880 Gravitacion 15 16Documento4 páginasMFT 32880 Gravitacion 15 16adri95Ainda não há avaliações
- Ejercicios de Probabilidad y Estadística, 24 de Agosto 2020.Documento9 páginasEjercicios de Probabilidad y Estadística, 24 de Agosto 2020.Geovanni GonzálezAinda não há avaliações
- Uranga Preguntas 2014 PDFDocumento152 páginasUranga Preguntas 2014 PDFAndy SmithAinda não há avaliações
- Mecánica Clásica ResumenDocumento2 páginasMecánica Clásica ResumenCarlaAinda não há avaliações
- Practico 2Documento4 páginasPractico 2anon_911788075Ainda não há avaliações
- Formulario CuánticaDocumento10 páginasFormulario CuánticageneradorsuplenteAinda não há avaliações
- 13 S ANALISIS DE DATosDocumento34 páginas13 S ANALISIS DE DATosAntonella Murillo CorralesAinda não há avaliações
- Exposicion Final Fisica IIIDocumento8 páginasExposicion Final Fisica IIIJhon XdAinda não há avaliações
- Distribucion BinomialDocumento2 páginasDistribucion BinomialSelin Sierra RomeroAinda não há avaliações
- Evaluacion 2 AlexaDocumento5 páginasEvaluacion 2 AlexaDemir YanchaliquinAinda não há avaliações
- Modelo Multivariado y P-ValorDocumento1 páginaModelo Multivariado y P-ValorDaniel SierraAinda não há avaliações
- Variable AleatoriaDocumento7 páginasVariable AleatoriaEmiruAinda não há avaliações
- Practica 15 EstadisticaDocumento7 páginasPractica 15 EstadisticaKathetine Wendy Escobar AlvarezAinda não há avaliações
- Cap 9 Prueba de Hipotesis PDFDocumento22 páginasCap 9 Prueba de Hipotesis PDFcarlos lara0% (1)
- Programa Estadistica AplicadaDocumento7 páginasPrograma Estadistica AplicadaEugenia BasileAinda não há avaliações
- Experimentos FactorialesDocumento6 páginasExperimentos FactorialesCarlos JaimesAinda não há avaliações
- Practica 8Documento3 páginasPractica 8Geovani MincholaAinda não há avaliações
- Orientaciones Curruculares Filosofía Grado NovenoDocumento10 páginasOrientaciones Curruculares Filosofía Grado NovenoThe SniperAinda não há avaliações
- Manual Msa Itesm Mar2017Documento59 páginasManual Msa Itesm Mar2017josebenitezayalaAinda não há avaliações
- Act 9 Quiz 2 Inferencia Estadistica UNADDocumento7 páginasAct 9 Quiz 2 Inferencia Estadistica UNADandrexsos1748180% (1)