Você também pode gostar
- The Yellow House: A Memoir (2019 National Book Award Winner)No EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Nota: 4 de 5 estrelas4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNo EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNota: 4 de 5 estrelas4/5 (5795)
- SubjectsDocumento1 páginaSubjectsnivi_09Ainda não há avaliações
- Ease Based STKRR: Predicted YES NO Actual YES 4 0 TP FN NO 1 133 FP TN 3 10 1 207Documento6 páginasEase Based STKRR: Predicted YES NO Actual YES 4 0 TP FN NO 1 133 FP TN 3 10 1 207nivi_09Ainda não há avaliações
- Universal Description Discovery and Integration (UDDI) : A ReviewDocumento34 páginasUniversal Description Discovery and Integration (UDDI) : A Reviewnivi_09Ainda não há avaliações
- KarpagavalliDocumento2 páginasKarpagavallinivi_09Ainda não há avaliações
- Research Directions in UddiDocumento3 páginasResearch Directions in Uddinivi_09Ainda não há avaliações
- Rrects: Representation and Reasoning About Events and Cognitive Actions in Temporal Locality Within Spatial RelationDocumento1 páginaRrects: Representation and Reasoning About Events and Cognitive Actions in Temporal Locality Within Spatial Relationnivi_09Ainda não há avaliações
- Survey EDITDocumento38 páginasSurvey EDITnivi_09Ainda não há avaliações
- Fig 8.1 Sequence DiagramDocumento1 páginaFig 8.1 Sequence Diagramnivi_09Ainda não há avaliações
- Fig 8Documento1 páginaFig 8nivi_09Ainda não há avaliações
- Interaction Diagram - A. Sequence DiagramDocumento1 páginaInteraction Diagram - A. Sequence Diagramnivi_09Ainda não há avaliações
- Cp7201 Theoretical Foundations of Computer Science Unit - Ii Logic and Logic Programming Assignment - I Propositional LogicDocumento1 páginaCp7201 Theoretical Foundations of Computer Science Unit - Ii Logic and Logic Programming Assignment - I Propositional Logicnivi_09Ainda não há avaliações
- Interaction Diagram - A. Sequence DiagramDocumento1 páginaInteraction Diagram - A. Sequence Diagramnivi_09Ainda não há avaliações
- Pondicherry University School of Engineering & Technology: Computer Network ProtocolsDocumento31 páginasPondicherry University School of Engineering & Technology: Computer Network Protocolsnivi_09Ainda não há avaliações
- G Priyadharshini: Professional ExperienceDocumento4 páginasG Priyadharshini: Professional Experiencenivi_09100% (1)
- Career ObjectiveDocumento4 páginasCareer Objectivenivi_09Ainda não há avaliações
- Mrs. G. Jayanthi, B.E (CSE) .,M. Tech (Remote Sensing) .,AP, MSAJCEDocumento1 páginaMrs. G. Jayanthi, B.E (CSE) .,M. Tech (Remote Sensing) .,AP, MSAJCEnivi_09Ainda não há avaliações
- Data StructuresDocumento3 páginasData Structuresnivi_09Ainda não há avaliações
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNo EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNota: 4.5 de 5 estrelas4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNo EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNota: 3.5 de 5 estrelas3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNo EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNota: 4 de 5 estrelas4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItNo EverandNever Split the Difference: Negotiating As If Your Life Depended On ItNota: 4.5 de 5 estrelas4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingNo EverandThe Little Book of Hygge: Danish Secrets to Happy LivingNota: 3.5 de 5 estrelas3.5/5 (400)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNo EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNota: 4.5 de 5 estrelas4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaNo EverandThe Unwinding: An Inner History of the New AmericaNota: 4 de 5 estrelas4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnNo EverandTeam of Rivals: The Political Genius of Abraham LincolnNota: 4.5 de 5 estrelas4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyNo EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyNota: 3.5 de 5 estrelas3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNo EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNota: 4.5 de 5 estrelas4.5/5 (266)
- The Emperor of All Maladies: A Biography of CancerNo EverandThe Emperor of All Maladies: A Biography of CancerNota: 4.5 de 5 estrelas4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNo EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNota: 4 de 5 estrelas4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)No EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Nota: 4.5 de 5 estrelas4.5/5 (121)
- WO 2021/158698 Al: (10) International Publication NumberDocumento234 páginasWO 2021/158698 Al: (10) International Publication Numberyoganayagi209Ainda não há avaliações
- City/ The Countryside: VocabularyDocumento2 páginasCity/ The Countryside: VocabularyHương Phạm QuỳnhAinda não há avaliações
- Work Teams and GroupsDocumento6 páginasWork Teams and GroupsFides AvendanAinda não há avaliações
- Advanced Technical Analysis: - Online Live Interactive SessionDocumento4 páginasAdvanced Technical Analysis: - Online Live Interactive SessionmahendarAinda não há avaliações
- The Preparedness of The Data Center College of The Philippines To The Flexible Learning Amidst Covid-19 PandemicDocumento16 páginasThe Preparedness of The Data Center College of The Philippines To The Flexible Learning Amidst Covid-19 PandemicInternational Journal of Innovative Science and Research TechnologyAinda não há avaliações
- Djordje Bubalo BiografijaDocumento12 páginasDjordje Bubalo BiografijaМилан КрстићAinda não há avaliações
- Klabin Reports 2nd Quarter Earnings of R$ 15 Million: HighlightsDocumento10 páginasKlabin Reports 2nd Quarter Earnings of R$ 15 Million: HighlightsKlabin_RIAinda não há avaliações
- Paediatrica Indonesiana: Sumadiono, Cahya Dewi Satria, Nurul Mardhiah, Grace Iva SusantiDocumento6 páginasPaediatrica Indonesiana: Sumadiono, Cahya Dewi Satria, Nurul Mardhiah, Grace Iva SusantiharnizaAinda não há avaliações
- "What Is A Concept Map?" by (Novak & Cañas, 2008)Documento4 páginas"What Is A Concept Map?" by (Novak & Cañas, 2008)WanieAinda não há avaliações
- A Teacher Must Choose Five Monitors From A Class of 12 Students. How Many Different Ways Can The Teacher Choose The Monitors?Documento11 páginasA Teacher Must Choose Five Monitors From A Class of 12 Students. How Many Different Ways Can The Teacher Choose The Monitors?Syed Ali HaiderAinda não há avaliações
- Ghalib TimelineDocumento2 páginasGhalib Timelinemaryam-69Ainda não há avaliações
- Playwriting Pedagogy and The Myth of IntrinsicDocumento17 páginasPlaywriting Pedagogy and The Myth of IntrinsicCaetano BarsoteliAinda não há avaliações
- GB BioDocumento3 páginasGB BiolskerponfblaAinda não há avaliações
- Signalling in Telecom Network &SSTPDocumento39 páginasSignalling in Telecom Network &SSTPDilan TuderAinda não há avaliações
- GRADE 1 To 12 Daily Lesson LOG: TLE6AG-Oc-3-1.3.3Documento7 páginasGRADE 1 To 12 Daily Lesson LOG: TLE6AG-Oc-3-1.3.3Roxanne Pia FlorentinoAinda não há avaliações
- Why Do Firms Do Basic Research With Their Own Money - 1989 - StudentsDocumento10 páginasWhy Do Firms Do Basic Research With Their Own Money - 1989 - StudentsAlvaro Rodríguez RojasAinda não há avaliações
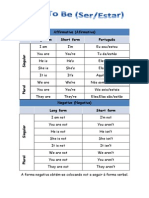
- Affirmative (Afirmativa) Long Form Short Form PortuguêsDocumento3 páginasAffirmative (Afirmativa) Long Form Short Form PortuguêsAnitaYangAinda não há avaliações
- Essay EnglishDocumento4 páginasEssay Englishkiera.kassellAinda não há avaliações
- Long 1988Documento4 páginasLong 1988Ovirus OviAinda não há avaliações
- Nature, and The Human Spirit: A Collection of QuotationsDocumento2 páginasNature, and The Human Spirit: A Collection of QuotationsAxl AlfonsoAinda não há avaliações
- Functions & Role of Community Mental Health Nursing: Srinivasan ADocumento29 páginasFunctions & Role of Community Mental Health Nursing: Srinivasan AsrinivasanaAinda não há avaliações
- Your Free Buyer Persona TemplateDocumento8 páginasYour Free Buyer Persona Templateel_nakdjoAinda não há avaliações
- Prepositions French Worksheet For PracticeDocumento37 páginasPrepositions French Worksheet For Practiceangelamonteiro100% (1)
- War Thesis StatementsDocumento8 páginasWar Thesis StatementsHelpPaperRochester100% (2)
- 221-240 - PMP BankDocumento4 páginas221-240 - PMP BankAdetula Bamidele OpeyemiAinda não há avaliações
- Diode ExercisesDocumento5 páginasDiode ExercisesbruhAinda não há avaliações
- Del Monte Usa Vs CaDocumento3 páginasDel Monte Usa Vs CaChe Poblete CardenasAinda não há avaliações
- Practice Test 4 For Grade 12Documento5 páginasPractice Test 4 For Grade 12MAx IMp BayuAinda não há avaliações
- Reported Speech StatementsDocumento1 páginaReported Speech StatementsEmilijus Bartasevic100% (1)