Você também pode gostar
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNo EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNota: 4 de 5 estrelas4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNo EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNota: 4 de 5 estrelas4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItNo EverandNever Split the Difference: Negotiating As If Your Life Depended On ItNota: 4.5 de 5 estrelas4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNo EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNota: 4 de 5 estrelas4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNo EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNota: 4.5 de 5 estrelas4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNo EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNota: 4.5 de 5 estrelas4.5/5 (474)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)No EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Nota: 4.5 de 5 estrelas4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerNo EverandThe Emperor of All Maladies: A Biography of CancerNota: 4.5 de 5 estrelas4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingNo EverandThe Little Book of Hygge: Danish Secrets to Happy LivingNota: 3.5 de 5 estrelas3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyNo EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyNota: 3.5 de 5 estrelas3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)No EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Nota: 4 de 5 estrelas4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNo EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNota: 4.5 de 5 estrelas4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNo EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNota: 3.5 de 5 estrelas3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnNo EverandTeam of Rivals: The Political Genius of Abraham LincolnNota: 4.5 de 5 estrelas4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaNo EverandThe Unwinding: An Inner History of the New AmericaNota: 4 de 5 estrelas4/5 (45)
- 6th Central Pay Commission Salary CalculatorDocumento15 páginas6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Clock of Destiny Book-1Documento46 páginasClock of Destiny Book-1Bass Mcm87% (15)
- Piston Master PumpsDocumento14 páginasPiston Master PumpsMauricio Ariel H. OrellanaAinda não há avaliações
- Research ProposalDocumento6 páginasResearch ProposalApam BenjaminAinda não há avaliações
- Lecture8 Module2 Anova 1Documento13 páginasLecture8 Module2 Anova 1Apam BenjaminAinda não há avaliações
- Oxygen Cycle: PlantsDocumento3 páginasOxygen Cycle: PlantsApam BenjaminAinda não há avaliações
- Nitrogen Cycle: Ecological FunctionDocumento8 páginasNitrogen Cycle: Ecological FunctionApam BenjaminAinda não há avaliações
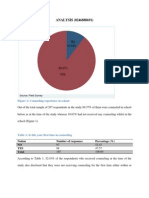
- ANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolDocumento8 páginasANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolApam BenjaminAinda não há avaliações
- Lecture7 Module2 Anova 1Documento10 páginasLecture7 Module2 Anova 1Apam BenjaminAinda não há avaliações
- Cocoa (Theobroma Cacao L.) : Theobroma Cacao Also Cacao Tree and Cocoa Tree, Is A Small (4-8 M or 15-26 FT Tall) EvergreenDocumento12 páginasCocoa (Theobroma Cacao L.) : Theobroma Cacao Also Cacao Tree and Cocoa Tree, Is A Small (4-8 M or 15-26 FT Tall) EvergreenApam BenjaminAinda não há avaliações
- Multivariate Analysis of Variance (MANOVA) : (Copy This Section To Methodology)Documento8 páginasMultivariate Analysis of Variance (MANOVA) : (Copy This Section To Methodology)Apam BenjaminAinda não há avaliações
- PLMDocumento5 páginasPLMApam BenjaminAinda não há avaliações
- Lecture4 Module2 Anova 1Documento9 páginasLecture4 Module2 Anova 1Apam BenjaminAinda não há avaliações
- Lecture5 Module2 Anova 1Documento9 páginasLecture5 Module2 Anova 1Apam BenjaminAinda não há avaliações
- Lecture6 Module2 Anova 1Documento10 páginasLecture6 Module2 Anova 1Apam BenjaminAinda não há avaliações
- Hosmer On Survival With StataDocumento21 páginasHosmer On Survival With StataApam BenjaminAinda não há avaliações
- PLM IiDocumento3 páginasPLM IiApam BenjaminAinda não há avaliações
- Trial Questions (PLM)Documento3 páginasTrial Questions (PLM)Apam BenjaminAinda não há avaliações
- Personal Information: Curriculum VitaeDocumento6 páginasPersonal Information: Curriculum VitaeApam BenjaminAinda não há avaliações
- ARIMA (Autoregressive Integrated Moving Average) Approach To Predicting Inflation in GhanaDocumento9 páginasARIMA (Autoregressive Integrated Moving Average) Approach To Predicting Inflation in GhanaApam BenjaminAinda não há avaliações
- Finish WorkDocumento116 páginasFinish WorkApam BenjaminAinda não há avaliações
- How Does Information Technology Impact On Business Relationships? The Need For Personal MeetingsDocumento14 páginasHow Does Information Technology Impact On Business Relationships? The Need For Personal MeetingsApam BenjaminAinda não há avaliações
- A Study On School DropoutsDocumento6 páginasA Study On School DropoutsApam BenjaminAinda não há avaliações
- Creating STATA DatasetsDocumento4 páginasCreating STATA DatasetsApam BenjaminAinda não há avaliações
- Ajsms 2 4 348 355Documento8 páginasAjsms 2 4 348 355Akolgo PaulinaAinda não há avaliações
- Regression Analysis of Road Traffic Accidents and Population Growth in GhanaDocumento7 páginasRegression Analysis of Road Traffic Accidents and Population Growth in GhanaApam BenjaminAinda não há avaliações
- Banque AtlanticbanDocumento1 páginaBanque AtlanticbanApam BenjaminAinda não há avaliações
- MSC Project Study Guide Jessica Chen-Burger: What You Will WriteDocumento1 páginaMSC Project Study Guide Jessica Chen-Burger: What You Will WriteApam BenjaminAinda não há avaliações
- Asri Stata 2013-FlyerDocumento1 páginaAsri Stata 2013-FlyerAkolgo PaulinaAinda não há avaliações
- How To Write A Paper For A Scientific JournalDocumento10 páginasHow To Write A Paper For A Scientific JournalApam BenjaminAinda não há avaliações
- l.4. Research QuestionsDocumento1 páginal.4. Research QuestionsApam BenjaminAinda não há avaliações
- Project ReportsDocumento31 páginasProject ReportsBilal AliAinda não há avaliações
- James KlotzDocumento2 páginasJames KlotzMargaret ElwellAinda não há avaliações
- Zimbabwe - Youth and Tourism Enhancement Project - National Tourism Masterplan - EOIDocumento1 páginaZimbabwe - Youth and Tourism Enhancement Project - National Tourism Masterplan - EOIcarlton.mamire.gtAinda não há avaliações
- Unix SapDocumento4 páginasUnix SapsatyavaninaiduAinda não há avaliações
- Paper:Introduction To Economics and Finance: Functions of Economic SystemDocumento10 páginasPaper:Introduction To Economics and Finance: Functions of Economic SystemQadirAinda não há avaliações
- Water Flow Meter TypesDocumento2 páginasWater Flow Meter TypesMohamad AsrulAinda não há avaliações
- Angeles City National Trade SchoolDocumento7 páginasAngeles City National Trade Schooljoyceline sarmientoAinda não há avaliações
- Jurnal KORELASI ANTARA STATUS GIZI IBU MENYUSUI DENGAN KECUKUPAN ASIDocumento9 páginasJurnal KORELASI ANTARA STATUS GIZI IBU MENYUSUI DENGAN KECUKUPAN ASIMarsaidAinda não há avaliações
- Madam Shazia PaperDocumento14 páginasMadam Shazia PaperpervaizhejAinda não há avaliações
- Isaiah Chapter 6Documento32 páginasIsaiah Chapter 6pastorbbAinda não há avaliações
- Week1 TutorialsDocumento1 páginaWeek1 TutorialsAhmet Bahadır ŞimşekAinda não há avaliações
- Chapter 3-CP For Armed Conflict SituationDocumento23 páginasChapter 3-CP For Armed Conflict Situationisidro.ganadenAinda não há avaliações
- BSBSTR602 Project PortfolioDocumento16 páginasBSBSTR602 Project Portfoliocruzfabricio0Ainda não há avaliações
- Brianna Pratt - l3stl1 - Dsu Lesson Plan TemplateDocumento5 páginasBrianna Pratt - l3stl1 - Dsu Lesson Plan Templateapi-593886164Ainda não há avaliações
- Machine Tools PDFDocumento57 páginasMachine Tools PDFnikhil tiwariAinda não há avaliações
- Excel Lesson 5 QuizDocumento5 páginasExcel Lesson 5 Quizdeep72Ainda não há avaliações
- Self-Efficacy and Academic Stressors in University StudentsDocumento9 páginasSelf-Efficacy and Academic Stressors in University StudentskskkakleirAinda não há avaliações
- ACTIVITY Design - Nutrition MonthDocumento7 páginasACTIVITY Design - Nutrition MonthMaria Danica89% (9)
- Promoting Services and Educating CustomersDocumento28 páginasPromoting Services and Educating Customershassan mehmoodAinda não há avaliações
- Gender and Patriarchy: Crisis, Negotiation and Development of Identity in Mahesh Dattani'S Selected PlaysDocumento6 páginasGender and Patriarchy: Crisis, Negotiation and Development of Identity in Mahesh Dattani'S Selected Playsতন্ময়Ainda não há avaliações
- Product 97 File1Documento2 páginasProduct 97 File1Stefan StefanAinda não há avaliações
- Lab Activity 5Documento5 páginasLab Activity 5Jasmin CeciliaAinda não há avaliações
- Chapter 8 - Current Electricity - Selina Solutions Concise Physics Class 10 ICSE - KnowledgeBoatDocumento123 páginasChapter 8 - Current Electricity - Selina Solutions Concise Physics Class 10 ICSE - KnowledgeBoatskjAinda não há avaliações
- 4.1.1.6 Packet Tracer - Explore The Smart Home - ILM - 51800835Documento4 páginas4.1.1.6 Packet Tracer - Explore The Smart Home - ILM - 51800835Viet Quoc100% (1)
- 3 HVDC Converter Control PDFDocumento78 páginas3 HVDC Converter Control PDFJanaki BonigalaAinda não há avaliações
- Deictics and Stylistic Function in J.P. Clark-Bekederemo's PoetryDocumento11 páginasDeictics and Stylistic Function in J.P. Clark-Bekederemo's Poetryym_hAinda não há avaliações
- An Analysis of The Cloud Computing Security ProblemDocumento6 páginasAn Analysis of The Cloud Computing Security Problemrmsaqib1Ainda não há avaliações
- Matrix CPP CombineDocumento14 páginasMatrix CPP CombineAbhinav PipalAinda não há avaliações