Você também pode gostar
- 4503 Rc158 010d Machinelearning 1Documento6 páginas4503 Rc158 010d Machinelearning 1AhsanAnisAinda não há avaliações
- A Short Introduction To The Caret Package: Max Kuhn June 20, 2013Documento10 páginasA Short Introduction To The Caret Package: Max Kuhn June 20, 2013Renukha PannalaAinda não há avaliações
- B Ridge - and - Lasso - RegressionDocumento5 páginasB Ridge - and - Lasso - RegressionGabriel GheorgheAinda não há avaliações
- A Short Introduction To CaretDocumento10 páginasA Short Introduction To CaretblacngAinda não há avaliações
- Logistic RegressionDocumento10 páginasLogistic RegressionParth MehtaAinda não há avaliações
- Diabetes Machine Learning Case StudyDocumento10 páginasDiabetes Machine Learning Case StudyAbhising100% (1)
- Procedure GLMDocumento37 páginasProcedure GLMMauricio González PalacioAinda não há avaliações
- Maxbox - Starter67 Machine LearningDocumento7 páginasMaxbox - Starter67 Machine LearningMax KleinerAinda não há avaliações
- Week 7 Laboratory ActivityDocumento12 páginasWeek 7 Laboratory ActivityGar NoobAinda não há avaliações
- Gradient Descent and Regularization for Neural Network OptimizationDocumento37 páginasGradient Descent and Regularization for Neural Network OptimizationKamakshi SubramaniamAinda não há avaliações
- Functions and PackagesDocumento7 páginasFunctions and PackagesNur SyazlianaAinda não há avaliações
- Benchmarking MLDocumento9 páginasBenchmarking MLYentl HendrickxAinda não há avaliações
- R AssignmentDocumento8 páginasR AssignmentTunaAinda não há avaliações
- P05 The Regression Pipeline - Training and Testing AnsDocumento13 páginasP05 The Regression Pipeline - Training and Testing AnsYONG LONG KHAWAinda não há avaliações
- 41 Perusse Alexander Aperusse PDFDocumento7 páginas41 Perusse Alexander Aperusse PDFAnurita MathurAinda não há avaliações
- Homework Assignment 3 Homework Assignment 3Documento10 páginasHomework Assignment 3 Homework Assignment 3Ido AkovAinda não há avaliações
- Whole ML PDF 1614408656Documento214 páginasWhole ML PDF 1614408656Kshatrapati Singh100% (1)
- Factor Analysis Source Code AppendixDocumento20 páginasFactor Analysis Source Code Appendixpratik zankeAinda não há avaliações
- Salinan Dari Untitled0.Ipynb - ColaboratoryDocumento3 páginasSalinan Dari Untitled0.Ipynb - ColaboratoryDandi Rifa'i TariganAinda não há avaliações
- Lab 3. Linear Regression 230223Documento7 páginasLab 3. Linear Regression 230223ruso100% (1)
- Problem Set 1: Introduction To R - Solutions With R Output: 1 Install PackagesDocumento24 páginasProblem Set 1: Introduction To R - Solutions With R Output: 1 Install PackagesDarnell LarsenAinda não há avaliações
- Machine Learning Random Forest Algorithm - JavatpointDocumento14 páginasMachine Learning Random Forest Algorithm - JavatpointRAMZI AzeddineAinda não há avaliações
- Bda AssignDocumento15 páginasBda AssignAishwarya BiradarAinda não há avaliações
- A1Documento8 páginasA1DASHPAGALAinda não há avaliações
- Linear Regression Using RDocumento24 páginasLinear Regression Using ROrtodoxieAinda não há avaliações
- Simple Statistics Functions in RDocumento41 páginasSimple Statistics Functions in RTonyAinda não há avaliações
- Labpractice 2Documento29 páginasLabpractice 2Rajashree Das100% (1)
- zerox readyDocumento21 páginaszerox readygowrishankar nayanaAinda não há avaliações
- R Unit 4th and 5thDocumento17 páginasR Unit 4th and 5thArshad BegAinda não há avaliações
- Logistic RegressionDocumento10 páginasLogistic RegressionChichi Jnr100% (1)
- Machine Learning Lab Manual 06Documento8 páginasMachine Learning Lab Manual 06Raheel Aslam100% (1)
- Machine Learning: Engr. Ejaz AhmadDocumento54 páginasMachine Learning: Engr. Ejaz AhmadejazAinda não há avaliações
- Logistic Regression Implementation in R: The DatasetDocumento8 páginasLogistic Regression Implementation in R: The DatasetsuprabhattAinda não há avaliações
- Jeffrey Williams (20221013) 3Documento21 páginasJeffrey Williams (20221013) 3JEFFREY WILLIAMS P M 20221013Ainda não há avaliações
- ML0101EN Clas Logistic Reg Churn Py v1Documento13 páginasML0101EN Clas Logistic Reg Churn Py v1banicx100% (1)
- Detect credit card fraud with machine learning modelsDocumento20 páginasDetect credit card fraud with machine learning modelsVishal Sharma100% (1)
- Machine LearningDocumento56 páginasMachine LearningMani Vrs100% (3)
- Multinomial Logit Models in RDocumento8 páginasMultinomial Logit Models in RPáblo DiasAinda não há avaliações
- SC Lab File Fayiz PDFDocumento29 páginasSC Lab File Fayiz PDFfayizpAinda não há avaliações
- Estiven - Hurtado.Santos - Regresión Con Varios AlgoritmosDocumento16 páginasEstiven - Hurtado.Santos - Regresión Con Varios AlgoritmosEstiven Hurtado SantosAinda não há avaliações
- 9805 MBAex PredAnalBigDataMar22Documento11 páginas9805 MBAex PredAnalBigDataMar22harishcoolanandAinda não há avaliações
- TD2345Documento3 páginasTD2345ashitaka667Ainda não há avaliações
- 3 Cluster Customer Analysis Using K-MeansDocumento5 páginas3 Cluster Customer Analysis Using K-MeansXuanli XiongAinda não há avaliações
- Charmi Shah 20bcp299 Lab2Documento7 páginasCharmi Shah 20bcp299 Lab2Princy100% (1)
- Regresion Logistic - Odt 1Documento8 páginasRegresion Logistic - Odt 1Geofrey Julius ZellahAinda não há avaliações
- Assignment R New 1Documento26 páginasAssignment R New 1Sohel RanaAinda não há avaliações
- Solution 3.1Documento4 páginasSolution 3.1Adnan KianiAinda não há avaliações
- Import As Import As From Import As Import As Import AsDocumento3 páginasImport As Import As From Import As Import As Import AsDeepesh YadavAinda não há avaliações
- KVA Anusha - PGP12021 - BADocumento8 páginasKVA Anusha - PGP12021 - BAAditi Pareek100% (1)
- Advanced Statistics-ProjectDocumento16 páginasAdvanced Statistics-Projectvivek rAinda não há avaliações
- Using MaxlikDocumento20 páginasUsing MaxlikJames HotnielAinda não há avaliações
- Chapter - 5 ArrayDocumento23 páginasChapter - 5 Arraybeshahashenafe20Ainda não há avaliações
- Georglm: A Package For Generalised Linear Spatial Models Introductory SessionDocumento10 páginasGeorglm: A Package For Generalised Linear Spatial Models Introductory SessionAlvaro Ernesto Garzon GarzonAinda não há avaliações
- 1 - An Introduction To Machine Learning With Scikit-LearnDocumento9 páginas1 - An Introduction To Machine Learning With Scikit-Learnyati kumariAinda não há avaliações
- Data Analysis and Evaluation Methods ComparisonDocumento11 páginasData Analysis and Evaluation Methods ComparisonJelena NađAinda não há avaliações
- ML0101EN Clas K Nearest Neighbors CustCat Py v1Documento11 páginasML0101EN Clas K Nearest Neighbors CustCat Py v1banicx100% (1)
- Jeffrey Williams (20221013) 4Documento27 páginasJeffrey Williams (20221013) 4JEFFREY WILLIAMS P M 20221013Ainda não há avaliações
- Maxbox Starter60 Machine LearningDocumento8 páginasMaxbox Starter60 Machine LearningMax KleinerAinda não há avaliações
- Efficient Python Tricks and Tools For Data Scientists - by Khuyen TranDocumento20 páginasEfficient Python Tricks and Tools For Data Scientists - by Khuyen TranKhagenAinda não há avaliações
- Lick de John ColtraneDocumento21 páginasLick de John Coltranebastosgtr86% (7)
- Top 10 Interview Questions PDFDocumento20 páginasTop 10 Interview Questions PDFSaket SinhaAinda não há avaliações
- Craftsman Shop Vac ManualDocumento16 páginasCraftsman Shop Vac ManualRandy MarmerAinda não há avaliações
- Instructions for Using Vaginal DilatorsDocumento2 páginasInstructions for Using Vaginal DilatorsRandy MarmerAinda não há avaliações
- Anesthesia Q&A - CPT Exam PrepDocumento15 páginasAnesthesia Q&A - CPT Exam PrepRandy Marmer82% (22)
- What Is The Patient S RightDocumento1 páginaWhat Is The Patient S RightRandy MarmerAinda não há avaliações
- Is That Paper Really Due Today?'': Differences in First-Generation and Traditional College Students' Understandings of Faculty ExpectationsDocumento22 páginasIs That Paper Really Due Today?'': Differences in First-Generation and Traditional College Students' Understandings of Faculty ExpectationsRandy MarmerAinda não há avaliações
- Analyzing Data Measured by Individual Likert-Type ItemsDocumento5 páginasAnalyzing Data Measured by Individual Likert-Type ItemsCheNad NadiaAinda não há avaliações
- ADHD Rating Scales and CPT Tools Predict Reading FluencyDocumento29 páginasADHD Rating Scales and CPT Tools Predict Reading FluencyRandy MarmerAinda não há avaliações
- The Differences Between Modifiers 51 and 59Documento5 páginasThe Differences Between Modifiers 51 and 59Randy MarmerAinda não há avaliações
- Delay in Treatment Intensification Increases The Risks of Cardiovascular Events in Patients With Type 2 DiabetesDocumento17 páginasDelay in Treatment Intensification Increases The Risks of Cardiovascular Events in Patients With Type 2 DiabetesRandy MarmerAinda não há avaliações
- Lister Drug Protocol InstructionsDocumento3 páginasLister Drug Protocol InstructionsRandy MarmerAinda não há avaliações
- Rails 3 Cheat SheetsDocumento6 páginasRails 3 Cheat SheetsdrouchyAinda não há avaliações
- Cellular Patterns BBDocumento3 páginasCellular Patterns BBRandy MarmerAinda não há avaliações
- CPT E&M Level 4 Reference CardDocumento2 páginasCPT E&M Level 4 Reference CardRandy MarmerAinda não há avaliações
- Reduce Household Emissions by 30Documento1.010 páginasReduce Household Emissions by 30James Albert BarreraAinda não há avaliações
- E&M Time-Based Coding GuidelinesDocumento2 páginasE&M Time-Based Coding GuidelinesRandy MarmerAinda não há avaliações
- Nextgen Healthcare Ebook Data Analytics Healthcare Edu35Documento28 páginasNextgen Healthcare Ebook Data Analytics Healthcare Edu35Randy Marmer100% (1)
- EM StepbyStep 2013 1 PDFDocumento9 páginasEM StepbyStep 2013 1 PDFRandy MarmerAinda não há avaliações
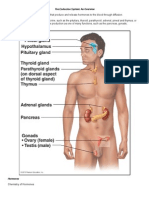
- Hormones Endocrine SystemDocumento35 páginasHormones Endocrine SystemRandy MarmerAinda não há avaliações
- Picture - Adh Hormone - Photo Gallery SearchDocumento8 páginasPicture - Adh Hormone - Photo Gallery SearchRandy MarmerAinda não há avaliações
- IO Acronyms and Glossary BasicsDocumento6 páginasIO Acronyms and Glossary BasicsRandy MarmerAinda não há avaliações
- Endocrine Disorder ChartDocumento4 páginasEndocrine Disorder ChartRandy MarmerAinda não há avaliações
- The Endocrine System: An OverviewDocumento27 páginasThe Endocrine System: An OverviewRandy MarmerAinda não há avaliações
- An Evaluation of Holden Arboretum's Shade Tree CollectionDocumento3 páginasAn Evaluation of Holden Arboretum's Shade Tree CollectionRandy MarmerAinda não há avaliações
- Unbiased Review of Digital Diagnostic Images in Practice - Informatics Prototype and Pilot StudyDocumento10 páginasUnbiased Review of Digital Diagnostic Images in Practice - Informatics Prototype and Pilot StudyRandy MarmerAinda não há avaliações
- Endocrine SystemDocumento24 páginasEndocrine Systemfrowee23Ainda não há avaliações
- NI Tutorial 4937 enDocumento1 páginaNI Tutorial 4937 enRandy MarmerAinda não há avaliações
- CassandraQueryLanguage Quick Reference CardDocumento2 páginasCassandraQueryLanguage Quick Reference CardRandy Marmer100% (1)
- Case Study Imaging Informatics Pinehurst RadiologyDocumento2 páginasCase Study Imaging Informatics Pinehurst RadiologyRick SmithAinda não há avaliações
- CE Model Question Paper 2019 - 16ME72Documento3 páginasCE Model Question Paper 2019 - 16ME72ashitaAinda não há avaliações
- Builtin Com Artificial IntelligenceDocumento20 páginasBuiltin Com Artificial Intelligencemahima dilsaraAinda não há avaliações
- Nfa To ReDocumento5 páginasNfa To Reprateek lilhareAinda não há avaliações
- Algorithmic Game Theory - Problem Set 1Documento3 páginasAlgorithmic Game Theory - Problem Set 1Jacob GreenfieldAinda não há avaliações
- Introduction to Control SystemsDocumento26 páginasIntroduction to Control SystemsNicole HyominAinda não há avaliações
- Introduction To Soft ComputingDocumento3 páginasIntroduction To Soft ComputingRahul RoyAinda não há avaliações
- 18AI742Documento1 página18AI742siddhanth shettyAinda não há avaliações
- Types of Encryption Ciphers ExplainedDocumento9 páginasTypes of Encryption Ciphers ExplainedEng-Mushtaq HejairaAinda não há avaliações
- TTDSDocumento5 páginasTTDSAhmed HassanAinda não há avaliações
- 21CS53 DBMS Iat3 QBDocumento2 páginas21CS53 DBMS Iat3 QBKunaljitAinda não há avaliações
- Multiple Sequence Alignment: Sumbitted To: DR - Navneet ChoudharyDocumento23 páginasMultiple Sequence Alignment: Sumbitted To: DR - Navneet ChoudharyAnkita SharmaAinda não há avaliações
- Regressao Linear Simples - Ipynb - ColaboratoryDocumento2 páginasRegressao Linear Simples - Ipynb - ColaboratoryGestão Financeira Fatec Bragança100% (1)
- COMP3357 - 2023-Lec 2Documento53 páginasCOMP3357 - 2023-Lec 2Joshua HoAinda não há avaliações
- Extracting Spread-Spectrum Hidden Data From Digital MediaDocumento35 páginasExtracting Spread-Spectrum Hidden Data From Digital MediaVamsi Krishna KazaAinda não há avaliações
- Basics of OptimisationDocumento9 páginasBasics of OptimisationKunal BhargudeAinda não há avaliações
- Reporting Uncertainty: Dr. C. H. Meyers, Reporting On His Measurements of The Heat Capacity of AmmoniaDocumento2 páginasReporting Uncertainty: Dr. C. H. Meyers, Reporting On His Measurements of The Heat Capacity of AmmoniaKalidasAinda não há avaliações
- Deep Learning TensorFlow and KerasDocumento454 páginasDeep Learning TensorFlow and KerasZakaria AllitoAinda não há avaliações
- Algorithm Exam HelpDocumento5 páginasAlgorithm Exam HelpProgramming Exam HelpAinda não há avaliações
- Student Copy of Module1 TestDocumento2 páginasStudent Copy of Module1 TestRanjana B JadekarAinda não há avaliações
- Floating Horizon AlgorithmDocumento2 páginasFloating Horizon Algorithmkoolnash8784Ainda não há avaliações
- Lecture 1Documento14 páginasLecture 1Quan LaiAinda não há avaliações
- Reading 4 Backtesting VaR - AnswersDocumento5 páginasReading 4 Backtesting VaR - AnswersDivyansh ChandakAinda não há avaliações
- Facebook - LeetCodeDocumento20 páginasFacebook - LeetCodeNishit Attrey100% (2)
- Reliability Study On A Fire Detection SystemDocumento35 páginasReliability Study On A Fire Detection SystemNelso BedinAinda não há avaliações
- Feedforward ControlDocumento73 páginasFeedforward ControlsathyaAinda não há avaliações
- Central Limit Theorem simulation with uniform distributionDocumento162 páginasCentral Limit Theorem simulation with uniform distributionCamiloArenasBonillaAinda não há avaliações
- EncryptionDocumento49 páginasEncryptionJacky VajwaAinda não há avaliações
- Sakurai 3.1Documento1 páginaSakurai 3.1Pedro HerreraAinda não há avaliações
- Chapter 1.2 - Equilibria and StabilityDocumento8 páginasChapter 1.2 - Equilibria and StabilityMatt SguegliaAinda não há avaliações
- BCA Term-End Practical Exam Algorithm Design LabDocumento16 páginasBCA Term-End Practical Exam Algorithm Design LabjasirAinda não há avaliações