Você também pode gostar
- Consumer Price IndexDocumento12 páginasConsumer Price IndexShayan AhmedAinda não há avaliações
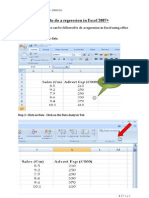
- How To Do A Regression in Excel 2007Documento10 páginasHow To Do A Regression in Excel 2007Minh ThangAinda não há avaliações
- Re Cursive NewDocumento10 páginasRe Cursive NewJames DelAinda não há avaliações
- ExamsDocumento74 páginasExamsSuraj SinghAinda não há avaliações
- Assignment of Regression AnalysisDocumento4 páginasAssignment of Regression AnalysisLaraib Khan0% (1)
- CH 4 4-35 SpreadsheetDocumento34 páginasCH 4 4-35 Spreadsheetcherishwisdom_997598Ainda não há avaliações
- Forecasting Using An Additive Model (From Last Week) Additive Model A T S RDocumento10 páginasForecasting Using An Additive Model (From Last Week) Additive Model A T S RsansagithAinda não há avaliações
- BB0010 Quantitative Techniques in Business 2Documento18 páginasBB0010 Quantitative Techniques in Business 2Ashraf HussainAinda não há avaliações
- Percentages Short Cut MethodsDocumento17 páginasPercentages Short Cut Methodsshaan02040% (2)
- Mathematics of Finance Concepts ExplainedDocumento105 páginasMathematics of Finance Concepts Explainedak s50% (2)
- Cal State Econ 340 Research Project Model US Trade DeficitDocumento7 páginasCal State Econ 340 Research Project Model US Trade DeficitVinay KhandelwalAinda não há avaliações
- Forecasting With Seasonality: Dr. Ron Tibben-Lembke Sept 9, 2003Documento10 páginasForecasting With Seasonality: Dr. Ron Tibben-Lembke Sept 9, 2003kaushalsingh2Ainda não há avaliações
- CHAPTER 4-5 Cashless Policy Data AnalysisDocumento22 páginasCHAPTER 4-5 Cashless Policy Data AnalysisDiiyor LawsonAinda não há avaliações
- QMT 3001 Business Forecasting Group ProjectDocumento30 páginasQMT 3001 Business Forecasting Group ProjectEKREM ÇAMURLUAinda não há avaliações
- Additonal Mathematics Project Work 2013 Selangor (Project 2)Documento15 páginasAdditonal Mathematics Project Work 2013 Selangor (Project 2)farhana_hana_982% (11)
- SolutionsDocumento30 páginasSolutionsNitesh AgrawalAinda não há avaliações
- Chap 6 Notes To Accompany The PP TransparenciesDocumento8 páginasChap 6 Notes To Accompany The PP TransparenciesChantal AouadAinda não há avaliações
- Data-Driven Marketing Strategy OptimizationDocumento13 páginasData-Driven Marketing Strategy Optimizationtiger_71100% (2)
- Halima Shahid, Sp19-Baf-024 - UsaDocumento13 páginasHalima Shahid, Sp19-Baf-024 - UsaMoeez KhanAinda não há avaliações
- BBA 4002 BUDGETING AND CONTROL (INDUSTRIAL PROJECT PAPAERDocumento14 páginasBBA 4002 BUDGETING AND CONTROL (INDUSTRIAL PROJECT PAPAERWindy TanAinda não há avaliações
- CAPM: Assess risk and return with the capital asset pricing modelDocumento26 páginasCAPM: Assess risk and return with the capital asset pricing modellogreturnAinda não há avaliações
- Economics of Health and Health Care 7th Edition Folland Solutions ManualDocumento16 páginasEconomics of Health and Health Care 7th Edition Folland Solutions Manuallisafloydropyebigcf100% (9)
- FM11 CH 11 Mini CaseDocumento13 páginasFM11 CH 11 Mini CasesushmanthqrewrerAinda não há avaliações
- AnswersDocumento19 páginasAnswersjayaniAinda não há avaliações
- Results and FindingsDocumento8 páginasResults and FindingsAisyah Mohd KhairAinda não há avaliações
- How To Perform Monte Carlo SimulationDocumento13 páginasHow To Perform Monte Carlo SimulationsarabjeethanspalAinda não há avaliações
- What Is The Zone of Economic Production?: and How Can You Get There? Donald J. WheelerDocumento7 páginasWhat Is The Zone of Economic Production?: and How Can You Get There? Donald J. Wheelertehky63Ainda não há avaliações
- Chapter 5Documento24 páginasChapter 5vimalvijayan89Ainda não há avaliações
- Present value financial modeling examplesDocumento20 páginasPresent value financial modeling examplessachin_chawlaAinda não há avaliações
- Module 5 - Forecasting Demand ComponentsDocumento13 páginasModule 5 - Forecasting Demand ComponentsAshima AggarwalAinda não há avaliações
- Majestic Mulch and Compost Co. Capital Budgeting AnalysisDocumento68 páginasMajestic Mulch and Compost Co. Capital Budgeting AnalysisMnar Abu-ShliebaAinda não há avaliações
- TVM Formulas Guide: Calculate Present, Future Values & AnnuitiesDocumento56 páginasTVM Formulas Guide: Calculate Present, Future Values & AnnuitiesSaptorshi BagchiAinda não há avaliações
- Answers To Section Six Exercises A Review of Chapters 15 and 16Documento4 páginasAnswers To Section Six Exercises A Review of Chapters 15 and 16Jennifer WijayaAinda não há avaliações
- The Answer of 2nd Assignment Eco 104-EditDocumento12 páginasThe Answer of 2nd Assignment Eco 104-EditWery Astuti100% (1)
- Introduction To Spreadsheets - FDP 2013Documento24 páginasIntroduction To Spreadsheets - FDP 2013thayumanavarkannanAinda não há avaliações
- Macsg09: The Government and Fiscal PolicyDocumento24 páginasMacsg09: The Government and Fiscal PolicyJudith100% (1)
- Bapp 01Documento20 páginasBapp 01MaybellineTorresAinda não há avaliações
- CF Chapter 11 Excel Master StudentDocumento40 páginasCF Chapter 11 Excel Master Studentjulita08Ainda não há avaliações
- ANalyse Budget ClassDocumento14 páginasANalyse Budget ClassMonkey2111Ainda não há avaliações
- Build a Model ChapterDocumento17 páginasBuild a Model ChapterAbhishek Surana100% (2)
- Jun18l1-Ep04 QaDocumento23 páginasJun18l1-Ep04 Qajuan100% (1)
- 2011 Aug Tutorial 2 Time Value of Money (Financial Calculator)Documento16 páginas2011 Aug Tutorial 2 Time Value of Money (Financial Calculator)Harmony TeeAinda não há avaliações
- Decomposition MethodDocumento73 páginasDecomposition MethodAbdirahman DeereAinda não há avaliações
- Econ 546 Project Final ReportDocumento22 páginasEcon 546 Project Final ReportMonica CMAinda não há avaliações
- FAT 2 - Sample SolutionsDocumento4 páginasFAT 2 - Sample SolutionsQuynh NgoAinda não há avaliações
- AJ Department StoreDocumento6 páginasAJ Department StoresoftstixAinda não há avaliações
- eDocumento16 páginasesampritcAinda não há avaliações
- Case Analysis Pilgrim BankDocumento3 páginasCase Analysis Pilgrim BankVigneshAinda não há avaliações
- BB0010 - Quantitative Techniques in BusinessDocumento15 páginasBB0010 - Quantitative Techniques in BusinessYoubarajsharmaAinda não há avaliações
- Practical Q Bcom Programme III YrDocumento11 páginasPractical Q Bcom Programme III YrPhung Huyen NgaAinda não há avaliações
- ECON 550 Updated ResultsDocumento9 páginasECON 550 Updated ResultsTahmeed JawadAinda não há avaliações
- Solutiontothe Regression Case StudyDocumento5 páginasSolutiontothe Regression Case StudyAdhamAinda não há avaliações
- Equity Trading The Trouble With ValueDocumento15 páginasEquity Trading The Trouble With Valueangelcomputer2Ainda não há avaliações
- How To Perform Monte Carlo SimulationDocumento13 páginasHow To Perform Monte Carlo SimulationsarabjeethanspalAinda não há avaliações
- Tutorial Questions: Quantitative Methods IDocumento5 páginasTutorial Questions: Quantitative Methods IBenneth YankeyAinda não há avaliações
- Averaging and Exponential Smoothing MethodsDocumento21 páginasAveraging and Exponential Smoothing MethodsMillenAinda não há avaliações
- Assignment 4 SolutionDocumento7 páginasAssignment 4 SolutionGustavTillmanAinda não há avaliações
- Financial Plans for Successful Wealth Management In Retirement: An Easy Guide to Selecting Portfolio Withdrawal StrategiesNo EverandFinancial Plans for Successful Wealth Management In Retirement: An Easy Guide to Selecting Portfolio Withdrawal StrategiesAinda não há avaliações
- Personal Money Management Made Simple with MS Excel: How to save, invest and borrow wiselyNo EverandPersonal Money Management Made Simple with MS Excel: How to save, invest and borrow wiselyAinda não há avaliações
- Annual Report HighlightsDocumento424 páginasAnnual Report Highlightsborisg3Ainda não há avaliações
- OPE Expense ProcessDocumento3 páginasOPE Expense ProcessCaterina De Luca100% (1)
- A Study On Ratio Analysis at Amararaja BDocumento79 páginasA Study On Ratio Analysis at Amararaja Bsiva100% (1)
- Supreme Court Rules Ramos Must Pay Balance Despite DemandsDocumento6 páginasSupreme Court Rules Ramos Must Pay Balance Despite DemandsfebwinAinda não há avaliações
- AP 59 FinPB - 5.06Documento8 páginasAP 59 FinPB - 5.06Anonymous Lih1laaxAinda não há avaliações
- General AnnuityDocumento21 páginasGeneral AnnuityMark Alconaba GeronimoAinda não há avaliações
- Airtel Zain AcquisitionDocumento14 páginasAirtel Zain AcquisitionAshish Sharma100% (1)
- Black ScholesDocumento57 páginasBlack ScholesAshish DixitAinda não há avaliações
- Book of Prime Entry Returns JournalsDocumento11 páginasBook of Prime Entry Returns JournalsGeorgeAinda não há avaliações
- Syndicate Bank 60Documento62 páginasSyndicate Bank 60kharoteh9402Ainda não há avaliações
- Landlord Tenant Handbok Montgomery County MDDocumento80 páginasLandlord Tenant Handbok Montgomery County MDkitty_chan_19Ainda não há avaliações
- ACC 108 Notes PayableDocumento4 páginasACC 108 Notes Payablemkrisnaharq99Ainda não há avaliações
- Motion To Set Aside - Cancel Sale - Show Cause - PDF Stanford Circuit Court FiledDocumento17 páginasMotion To Set Aside - Cancel Sale - Show Cause - PDF Stanford Circuit Court Filedaprilcharney0% (1)
- Quantitative Problems Chapter 12 Mortgage CalculationsDocumento9 páginasQuantitative Problems Chapter 12 Mortgage Calculationswaqar hattarAinda não há avaliações
- Tan Tiong Tick Vs American Apothecaries Co., Et AlDocumento5 páginasTan Tiong Tick Vs American Apothecaries Co., Et AlJoni Aquino100% (1)
- Property Case DigestsDocumento19 páginasProperty Case DigestsZie Bea0% (1)
- Ratio Used To Gauge Asset Management Efficiency and Liquidity Name Formula SignificanceDocumento9 páginasRatio Used To Gauge Asset Management Efficiency and Liquidity Name Formula SignificanceAko Si JheszaAinda não há avaliações
- FM09-CH 27Documento6 páginasFM09-CH 27Kritika SwaminathanAinda não há avaliações
- Rural bank certification documentsDocumento3 páginasRural bank certification documentsDarwin Solanoy100% (1)
- CA IPCCAuditing & Assurance372722Documento11 páginasCA IPCCAuditing & Assurance372722piyushAinda não há avaliações
- Analiza Cash FlowDocumento3 páginasAnaliza Cash FlowTania BabcinetchiAinda não há avaliações
- Franz ComplaintDocumento4 páginasFranz ComplaintFrederick BartlettAinda não há avaliações
- What Is A MortgageDocumento6 páginasWhat Is A MortgagekrishnaAinda não há avaliações
- Introduction AstralDocumento12 páginasIntroduction AstralMbavhalelo100% (1)
- P.rajeshwary Joining Letter o S MGMDocumento8 páginasP.rajeshwary Joining Letter o S MGMprastacharAinda não há avaliações
- TAI TONG CHUACHE v. Insurance CommissionDocumento2 páginasTAI TONG CHUACHE v. Insurance CommissionAngelette BulacanAinda não há avaliações
- Outline 2006-07Documento196 páginasOutline 2006-07Manish BokdiaAinda não há avaliações
- Introduction of Group Accounts A122 1Documento53 páginasIntroduction of Group Accounts A122 1Mei Chien YapAinda não há avaliações
- DATA MINING LAB MANUALDocumento74 páginasDATA MINING LAB MANUALAakashAinda não há avaliações
- A 1 PDFDocumento7 páginasA 1 PDFChaithanya BorusuAinda não há avaliações