Você também pode gostar
- Joint Pricing and Resource Allocation For OFDMA-Based Cognitive Radio SystemsDocumento5 páginasJoint Pricing and Resource Allocation For OFDMA-Based Cognitive Radio SystemsAnonymous uspYoqEAinda não há avaliações
- Subchannel and Power Allocation For OFDMA-based Mobile Cognitive Radio NetworksDocumento6 páginasSubchannel and Power Allocation For OFDMA-based Mobile Cognitive Radio NetworksAnonymous uspYoqEAinda não há avaliações
- Subchannel and Power Allocation in OFDMA-Based Cognitive Radio NetworksDocumento5 páginasSubchannel and Power Allocation in OFDMA-Based Cognitive Radio NetworksAnonymous uspYoqEAinda não há avaliações
- Imp - 2-3-1402058090-Network-IJCNWMC-ITERATIVE WATER FILLING - Samiksha - 1 - 1Documento10 páginasImp - 2-3-1402058090-Network-IJCNWMC-ITERATIVE WATER FILLING - Samiksha - 1 - 1Anonymous uspYoqEAinda não há avaliações
- New Algorithm For Joint Subchannel and Power Allocation in Multi-Cell OFDMA-based Cognitive Radio NetworksDocumento8 páginasNew Algorithm For Joint Subchannel and Power Allocation in Multi-Cell OFDMA-based Cognitive Radio NetworksAnonymous uspYoqEAinda não há avaliações
- Adaptive Subcarrier and Bit Allocation For Downlink OFDMA System With Proportional FairnessDocumento16 páginasAdaptive Subcarrier and Bit Allocation For Downlink OFDMA System With Proportional FairnessJohn BergAinda não há avaliações
- Python Iteration and LoopsDocumento53 páginasPython Iteration and LoopsQuan ZhouAinda não há avaliações
- Gnss Ofdm PDFDocumento4 páginasGnss Ofdm PDFAnonymous uspYoqEAinda não há avaliações
- WWRF SIG1 Panel E3Documento7 páginasWWRF SIG1 Panel E3Anonymous uspYoqEAinda não há avaliações
- How To Get Started With PythonDocumento8 páginasHow To Get Started With PythonAnonymous uspYoqEAinda não há avaliações
- CMOS Analog Design Lecture Notes Rev 1.5L - 02!06!11Documento371 páginasCMOS Analog Design Lecture Notes Rev 1.5L - 02!06!11Anonymous uspYoqEAinda não há avaliações
- Intercarrier On OfdmDocumento8 páginasIntercarrier On OfdmAnonymous uspYoqEAinda não há avaliações
- Python Lesson 1Documento45 páginasPython Lesson 1DM TimaneAinda não há avaliações
- Intercarrier On OfdmDocumento8 páginasIntercarrier On OfdmAnonymous uspYoqEAinda não há avaliações
- Installation Sheet Spoken Tutorial Team Iit Bombay 1 The Procedure To Install Esim in Ubuntu Linux 16.04 or 14.04Documento2 páginasInstallation Sheet Spoken Tutorial Team Iit Bombay 1 The Procedure To Install Esim in Ubuntu Linux 16.04 or 14.04Anonymous uspYoqEAinda não há avaliações
- How To Get Started With PythonDocumento8 páginasHow To Get Started With PythonAnonymous uspYoqEAinda não há avaliações
- Dams in India PDFDocumento11 páginasDams in India PDFRagaviAinda não há avaliações
- ECE3111 BJTTransistorsDocumento103 páginasECE3111 BJTTransistorsAnonymous uspYoqEAinda não há avaliações
- Cognitive Multi-Antenna T PDFDocumento4 páginasCognitive Multi-Antenna T PDFAnonymous uspYoqEAinda não há avaliações
- CMOS Analog Design Lecture Notes Rev 1.5L - 02!06!11Documento371 páginasCMOS Analog Design Lecture Notes Rev 1.5L - 02!06!11Anonymous uspYoqEAinda não há avaliações
- Electronic Circuit AnalysisDocumento23 páginasElectronic Circuit AnalysisAnonymous uspYoqEAinda não há avaliações
- Circuit Simulation Project: Name of The ParticipantDocumento5 páginasCircuit Simulation Project: Name of The ParticipantAnonymous uspYoqEAinda não há avaliações
- The Future of SDR: OMG WorkshopDocumento13 páginasThe Future of SDR: OMG WorkshopAnonymous uspYoqEAinda não há avaliações
- Design IssuesDocumento12 páginasDesign IssuesAnonymous uspYoqEAinda não há avaliações
- Cochlear RadioDocumento4 páginasCochlear RadioAnonymous uspYoqEAinda não há avaliações
- (Kevin Gurney) An Introduction To Neural Networks (B-Ok - Xyz)Documento22 páginas(Kevin Gurney) An Introduction To Neural Networks (B-Ok - Xyz)Anonymous uspYoqEAinda não há avaliações
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNo EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNota: 4 de 5 estrelas4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)No EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Nota: 4 de 5 estrelas4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNo EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNota: 4 de 5 estrelas4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNo EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNota: 4.5 de 5 estrelas4.5/5 (344)
- The Little Book of Hygge: Danish Secrets to Happy LivingNo EverandThe Little Book of Hygge: Danish Secrets to Happy LivingNota: 3.5 de 5 estrelas3.5/5 (399)
- The Emperor of All Maladies: A Biography of CancerNo EverandThe Emperor of All Maladies: A Biography of CancerNota: 4.5 de 5 estrelas4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNo EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNota: 4.5 de 5 estrelas4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItNo EverandNever Split the Difference: Negotiating As If Your Life Depended On ItNota: 4.5 de 5 estrelas4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNo EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNota: 3.5 de 5 estrelas3.5/5 (231)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNo EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNota: 4.5 de 5 estrelas4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnNo EverandTeam of Rivals: The Political Genius of Abraham LincolnNota: 4.5 de 5 estrelas4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyNo EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyNota: 3.5 de 5 estrelas3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaNo EverandThe Unwinding: An Inner History of the New AmericaNota: 4 de 5 estrelas4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNo EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNota: 4 de 5 estrelas4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)No EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Nota: 4.5 de 5 estrelas4.5/5 (120)
- Digital Video EditingDocumento31 páginasDigital Video EditingCoky Fauzi Alfi67% (3)
- Seminar On Lifi TechnologyDocumento19 páginasSeminar On Lifi TechnologyYugesh ReddyAinda não há avaliações
- Simpledsp: A Fast and Flexible DSP Processor Model: (Extended Abstract)Documento6 páginasSimpledsp: A Fast and Flexible DSP Processor Model: (Extended Abstract)Alex ObrejanAinda não há avaliações
- Iptv STB Manual Zxv10 b720Documento2 páginasIptv STB Manual Zxv10 b720disepyAinda não há avaliações
- Inclined Slotted Waveguide Antenna Design: AbstractDocumento5 páginasInclined Slotted Waveguide Antenna Design: AbstractriyazAinda não há avaliações
- 05 MSOFTX3000 Local Office Data Configuration ISSUE 1.2Documento45 páginas05 MSOFTX3000 Local Office Data Configuration ISSUE 1.2Amin100% (8)
- Sith-Model: CAE in Power-ElectronicsDocumento7 páginasSith-Model: CAE in Power-ElectronicsAbdulAzizAinda não há avaliações
- Instruction Manual Universal Fieldbus-Gateway Unigate CM - ProfibusDocumento62 páginasInstruction Manual Universal Fieldbus-Gateway Unigate CM - ProfibusFakhri GhrairiAinda não há avaliações
- Electronic SymbolDocumento28 páginasElectronic Symbolsponge bobAinda não há avaliações
- Parameter Design For A 6.78-MHz Wireless Power Transfer SystemDocumento12 páginasParameter Design For A 6.78-MHz Wireless Power Transfer Systemagmnm1962Ainda não há avaliações
- Merlin Gerin: Varlogic RT6 Power Factor ControllerDocumento4 páginasMerlin Gerin: Varlogic RT6 Power Factor ControllerCata CatalinAinda não há avaliações
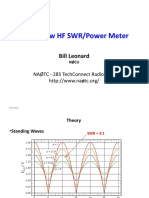
- Homebrew SWR Meter PDFDocumento41 páginasHomebrew SWR Meter PDFaryadiAinda não há avaliações
- Experiment 05Documento6 páginasExperiment 05ZodkingAinda não há avaliações
- Module 1 Lesson 1 Laplace TransformDocumento13 páginasModule 1 Lesson 1 Laplace TransformVictor DoyoganAinda não há avaliações
- Ftserver 2700Documento4 páginasFtserver 2700UncarachaAinda não há avaliações
- Getting Started Wp-8xx7Documento199 páginasGetting Started Wp-8xx7Pedro BortotAinda não há avaliações
- Ten Things To Do With A PCDocumento4 páginasTen Things To Do With A PCYohaira MoscosoAinda não há avaliações
- Triax Satellite Dish LNB 13 14Documento2 páginasTriax Satellite Dish LNB 13 14arnaudmarielAinda não há avaliações
- Mod 5Documento3 páginasMod 5ganesh_karanamAinda não há avaliações
- 10.1 inch Windows rugged tablet 4+64GB+LTE BT616 offer 样版本Documento3 páginas10.1 inch Windows rugged tablet 4+64GB+LTE BT616 offer 样版本yadira hozAinda não há avaliações
- Detection & Distinction of Colors Using Color Sorting Robotic Arm in A Pick & Place MechanismDocumento42 páginasDetection & Distinction of Colors Using Color Sorting Robotic Arm in A Pick & Place MechanismTrinesh GowdaAinda não há avaliações
- Diffrerential Amp. Tut.Documento56 páginasDiffrerential Amp. Tut.Hassan Al BaityAinda não há avaliações
- Eaton Fireman Switch Safety First Sol30x Flyer fl003001 en UsDocumento5 páginasEaton Fireman Switch Safety First Sol30x Flyer fl003001 en UsRadu IonescuAinda não há avaliações
- PDFDocumento2 páginasPDFHassanAhmed100% (1)
- Electronic Circuits: Engr. Denver G. MagtibayDocumento106 páginasElectronic Circuits: Engr. Denver G. MagtibayRealyn Macatangay100% (2)
- Food Quality Monitoring System by Using Arduino: B.Ravi Chander, P.A.Lovina, G.Shiva KumariDocumento6 páginasFood Quality Monitoring System by Using Arduino: B.Ravi Chander, P.A.Lovina, G.Shiva Kumarielsayed zanhomAinda não há avaliações
- Networking AssignmentDocumento37 páginasNetworking AssignmentTerry HalAinda não há avaliações
- Computer Assembly: IT Essentials: PC Hardware and Software v4.0Documento74 páginasComputer Assembly: IT Essentials: PC Hardware and Software v4.0sabry_100Ainda não há avaliações
- Autopilot Computer - Maintenance PracticesDocumento5 páginasAutopilot Computer - Maintenance PracticesEleazarAinda não há avaliações
- ETS1201 Series Fixed Wireless Terminal Maintenance ManualDocumento34 páginasETS1201 Series Fixed Wireless Terminal Maintenance ManualRumesha TharindiAinda não há avaliações