Você também pode gostar
- Manual de Oasis MontajDocumento12 páginasManual de Oasis MontajDavid GarciaAinda não há avaliações
- Hampson Russell View3D GuideDocumento49 páginasHampson Russell View3D Guidepoojad03100% (1)
- Leapfrog Geo TutorialsDocumento99 páginasLeapfrog Geo TutorialsJhony Wilson Vargas BarbozaAinda não há avaliações
- 4 Key Aspects To VariographyDocumento14 páginas4 Key Aspects To Variographysupri100% (2)
- 4 Key Aspects To Variography - Snowden Group - Mining and Technology ConsultantsDocumento8 páginas4 Key Aspects To Variography - Snowden Group - Mining and Technology ConsultantshAinda não há avaliações
- Leapfrog Geo TutorialsDocumento90 páginasLeapfrog Geo TutorialsRuben Di Ruggiero MarioAinda não há avaliações
- LeapfrogGeoTutorials PDFDocumento92 páginasLeapfrogGeoTutorials PDFRicardo Cesar100% (3)
- Vizex Hot Keys GuideDocumento3 páginasVizex Hot Keys Guidekemalll50% (2)
- Chapter 01 - GeomodelingDocumento10 páginasChapter 01 - Geomodelingbella_dsAinda não há avaliações
- SCM Create Fault Polygons and Map Petrel 2010Documento14 páginasSCM Create Fault Polygons and Map Petrel 2010Oluwafemi OlominuAinda não há avaliações
- Deswik Suite Patch 2016.1 fixes performance issuesDocumento18 páginasDeswik Suite Patch 2016.1 fixes performance issuesInvader SteveAinda não há avaliações
- Leapfrog Geo TutorialsDocumento102 páginasLeapfrog Geo TutorialsHernan flores ramirezAinda não há avaliações
- Geomodelling, Resource & Reserve Estimation and Pit OptimizationDocumento19 páginasGeomodelling, Resource & Reserve Estimation and Pit OptimizationAziz Fathiry RahmanAinda não há avaliações
- Leapfrog Geo User ManualDocumento532 páginasLeapfrog Geo User ManualAnonymous FZEvbblr6Ainda não há avaliações
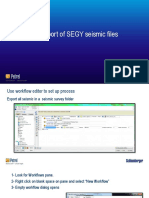
- Petrel Multi Export of SEGY Files - 6975975 - 03Documento9 páginasPetrel Multi Export of SEGY Files - 6975975 - 03Med Madrilèn100% (1)
- Geological ModelingDocumento6 páginasGeological ModelingCristian RuizAinda não há avaliações
- Petrel TrainingDocumento36 páginasPetrel TrainingFarah Taha AbdullahAinda não há avaliações
- Advanced Underground Design Reporting PDFDocumento89 páginasAdvanced Underground Design Reporting PDFjuan carlosAinda não há avaliações
- DataMine Studio Geological Modeling TutorialDocumento23 páginasDataMine Studio Geological Modeling TutorialDhabith100% (4)
- Gemcom Surpac: Issues FixedDocumento10 páginasGemcom Surpac: Issues Fixedalejandrogomez1976Ainda não há avaliações
- Leapfrog Hydro PDFDocumento159 páginasLeapfrog Hydro PDFJessica BlackwellAinda não há avaliações
- Automatic Fault Polygon ExtractionDocumento7 páginasAutomatic Fault Polygon ExtractionAiwarikiaarAinda não há avaliações
- Initial Velocity Model CreationDocumento26 páginasInitial Velocity Model CreationKonul AlizadehAinda não há avaliações
- Metric To Field Unit!!!!!! Which Is FT!Documento23 páginasMetric To Field Unit!!!!!! Which Is FT!jiachenAinda não há avaliações
- GF To PetrelDocumento22 páginasGF To PetrelAnonymous iZx83pFsOrAinda não há avaliações
- (2009) Petrel Data Import - Petrofaq (2009)Documento6 páginas(2009) Petrel Data Import - Petrofaq (2009)SaeidAinda não há avaliações
- Manual Del Gemcom Surpac - Underground Ring DesignDocumento43 páginasManual Del Gemcom Surpac - Underground Ring DesignDavid GarciaAinda não há avaliações
- Petrel 2013 5 Whats NewDocumento194 páginasPetrel 2013 5 Whats NewLAZUARDHY VOZIKA FUTUR100% (2)
- Interpreting and Modelling FaultsDocumento19 páginasInterpreting and Modelling FaultsYair Galindo VegaAinda não há avaliações
- Geovia Surpac 6.6.2 x64 Bit Whats NewDocumento2 páginasGeovia Surpac 6.6.2 x64 Bit Whats NewEdward van MartinoAinda não há avaliações
- Drill Hole Spacing Analysis 2015Documento21 páginasDrill Hole Spacing Analysis 2015Hardiyanto HardiyantoAinda não há avaliações
- Petrel Manual: Load Well HeaderDocumento9 páginasPetrel Manual: Load Well Headerredwanasis50% (4)
- Pit DesignDocumento94 páginasPit Designminguejacobo2Ainda não há avaliações
- Build A 3d Velocity Model From Checkshots Schlumberger Petrel PDFDocumento1 páginaBuild A 3d Velocity Model From Checkshots Schlumberger Petrel PDFzztannguyenzzAinda não há avaliações
- Block ModellingDocumento108 páginasBlock ModellingjunaifaAinda não há avaliações
- Geolog Image To Techlog - 6851383 - 01Documento7 páginasGeolog Image To Techlog - 6851383 - 01krackku kAinda não há avaliações
- Compositing: CompositeDocumento2 páginasCompositing: Compositezigrik2010Ainda não há avaliações
- Appendix 2. Sub-Bottom ProfileDocumento37 páginasAppendix 2. Sub-Bottom ProfileDik LanaAinda não há avaliações
- Petrel Day1Documento56 páginasPetrel Day1Anonymous qaI31H100% (2)
- Shortcut Keys in PetrelDocumento7 páginasShortcut Keys in PetrelTanaskumarKanesanAinda não há avaliações
- Online event: Block modeling basicsDocumento30 páginasOnline event: Block modeling basicsOsman Faiz A MominAinda não há avaliações
- Creating A Drill Hole Database in VulcanDocumento16 páginasCreating A Drill Hole Database in VulcanAj Kumar100% (1)
- Surpac Geological - Database Tutorial - 2 PDFDocumento79 páginasSurpac Geological - Database Tutorial - 2 PDFRakesh Vyas67% (3)
- Petrel Ibooks Jan 2017 PDFDocumento86 páginasPetrel Ibooks Jan 2017 PDFaidaAinda não há avaliações
- Build A 3d Velocity Model From Checkshots Schlumberger PetrelDocumento1 páginaBuild A 3d Velocity Model From Checkshots Schlumberger PetrelIbrahim Abdallah100% (4)
- View and manipulate well log data in GeologDocumento2 páginasView and manipulate well log data in Geologjimmymorelos100% (1)
- Introduction To Geological Data AnalysisDocumento116 páginasIntroduction To Geological Data AnalysisFrancoPaúlTafoyaGurtzAinda não há avaliações
- Petrel Isopach MapsDocumento15 páginasPetrel Isopach MapsChristabel Antenero100% (1)
- Reference Manual LeapfrogDocumento107 páginasReference Manual LeapfrogBoris Alarcón HasanAinda não há avaliações
- Polygons and OutlinesDocumento95 páginasPolygons and OutlinesTessfaye Wolde GebretsadikAinda não há avaliações
- Advanced Statistics VulcanDocumento10 páginasAdvanced Statistics Vulcanpduranp18018Ainda não há avaliações
- Petrel Well Tie ManualDocumento228 páginasPetrel Well Tie Manualkabeh1100% (13)
- User's Guide and Tutorials Leapfrog PDFDocumento258 páginasUser's Guide and Tutorials Leapfrog PDFsoda1206Ainda não há avaliações
- VariogramaDocumento16 páginasVariogramaIvan Ramirez CaqueoAinda não há avaliações
- Structural Geology and Personal ComputersNo EverandStructural Geology and Personal ComputersNota: 5 de 5 estrelas5/5 (3)
- S-Gems Tutorial Notes: Hydrogeophysics: Theory, Methods, and ModelingDocumento26 páginasS-Gems Tutorial Notes: Hydrogeophysics: Theory, Methods, and ModelingmarcialcolosAinda não há avaliações
- Step 1: Aster or SRTM?: Downloading and Importing Dem Data From Aster or SRTM ( 30M Resolution) Into ArcmapDocumento6 páginasStep 1: Aster or SRTM?: Downloading and Importing Dem Data From Aster or SRTM ( 30M Resolution) Into ArcmapAmel BoumesseneghAinda não há avaliações
- Tutorial SpatialDocumento19 páginasTutorial SpatialRicardo GomesAinda não há avaliações
- Raster Tutorial ArcgisDocumento21 páginasRaster Tutorial ArcgisMihai MereAinda não há avaliações
- Tufts GIS Tip Sheet Working With Elevation DataDocumento4 páginasTufts GIS Tip Sheet Working With Elevation DataFlor TsukinoAinda não há avaliações
- Mining Magazine - Heading UndergroundDocumento7 páginasMining Magazine - Heading UndergroundEdi SetiawanAinda não há avaliações
- HYDROLOGICAL FREQUENCY ANALYSIS GUIDEDocumento71 páginasHYDROLOGICAL FREQUENCY ANALYSIS GUIDEEdi Setiawan100% (1)
- Cipa FlyerDocumento1 páginaCipa FlyerEdi SetiawanAinda não há avaliações
- Autocad LD 2009Documento7 páginasAutocad LD 2009Edi SetiawanAinda não há avaliações
- 010 Wireline LoggingDocumento23 páginas010 Wireline LoggingKami Oey100% (1)
- What Is Dynamic Search VolumeDocumento1 páginaWhat Is Dynamic Search VolumeEdi SetiawanAinda não há avaliações
- Adisucipto International Airport To Jalan MULIA - Google MapsDocumento1 páginaAdisucipto International Airport To Jalan MULIA - Google MapsEdi SetiawanAinda não há avaliações
- Washed Coal2Documento7 páginasWashed Coal2böhmitAinda não há avaliações
- Optimasi Pencampuran Batubara Beda KualitasDocumento9 páginasOptimasi Pencampuran Batubara Beda KualitasEdi SetiawanAinda não há avaliações
- Understanding Ore Deposits AnswersDocumento5 páginasUnderstanding Ore Deposits AnswersEdi SetiawanAinda não há avaliações
- Linear Interpolation of F(h/a,l/a) Values for a Nickel Mine ProblemDocumento1 páginaLinear Interpolation of F(h/a,l/a) Values for a Nickel Mine ProblemEdi SetiawanAinda não há avaliações
- Lifecycle Cost ToolDocumento3 páginasLifecycle Cost ToolEdi SetiawanAinda não há avaliações
- Coal Cleaning and Benefication in IndiaDocumento5 páginasCoal Cleaning and Benefication in IndiaEdi SetiawanAinda não há avaliações
- Tutorial Software SGeMSDocumento26 páginasTutorial Software SGeMSEdi Setiawan100% (3)
- MAK KEY Office 2013Documento1 páginaMAK KEY Office 2013Edi SetiawanAinda não há avaliações
- First Semester 2010-2011 - Schedue of Classes - As of May 11, 2010Documento54 páginasFirst Semester 2010-2011 - Schedue of Classes - As of May 11, 2010xerexoxAinda não há avaliações
- NetBrain System Setup Guide Distributed DeploymentDocumento108 páginasNetBrain System Setup Guide Distributed Deploymentajrob69_187428023Ainda não há avaliações
- Arabic (101) Keyboard HelpDocumento2 páginasArabic (101) Keyboard Helpmulyadi sutopo100% (1)
- OBIA-FC Ref PDFDocumento618 páginasOBIA-FC Ref PDFahmed_sftAinda não há avaliações
- Variables and Data TypesDocumento27 páginasVariables and Data Typesrajvir.ramdasAinda não há avaliações
- Unit 1: 1.1 Microprocessors and MicrocontrollersDocumento13 páginasUnit 1: 1.1 Microprocessors and Microcontrollerssachin tupeAinda não há avaliações
- B WAS40P Part1 MAN2104Documento12 páginasB WAS40P Part1 MAN2104Tsvetan PenevAinda não há avaliações
- Role-based Access Control for E-healthcare WorkflowDocumento95 páginasRole-based Access Control for E-healthcare Workflowsamee530100% (1)
- Ellen Gottesdiener, Mary Gorman - Discover To Deliver - Agile Product Planning and Analysis-EBG Consulting, Inc. (2012)Documento312 páginasEllen Gottesdiener, Mary Gorman - Discover To Deliver - Agile Product Planning and Analysis-EBG Consulting, Inc. (2012)Kiss JánosAinda não há avaliações
- Full Stage Web Developer + MernDocumento3 páginasFull Stage Web Developer + MernkjckjAinda não há avaliações
- Java Tutorial - BalajiDocumento11 páginasJava Tutorial - BalajiBalaji Kumar100% (1)
- TCL TK and SkillDocumento16 páginasTCL TK and SkillGeoff LabuacAinda não há avaliações
- Master Test PlanDocumento15 páginasMaster Test PlanALVARO NICOLAS ZEVALLOS RIOSAinda não há avaliações
- OWASP ZAP Getting Started GuideDocumento10 páginasOWASP ZAP Getting Started GuideNobitaJuniorAinda não há avaliações
- Abdallah NasrallahDocumento4 páginasAbdallah NasrallahHumam ZakariaAinda não há avaliações
- ATILA Finite Element Software Package For The Analysis of 2D and 3D Structures Based On Smart MaterialsDocumento2 páginasATILA Finite Element Software Package For The Analysis of 2D and 3D Structures Based On Smart MaterialsTariq MahmoodAinda não há avaliações
- DP - X510 BrochureDocumento2 páginasDP - X510 BrochureRommel SegismundoAinda não há avaliações
- Statistics with R — A practical guide for beginnersDocumento101 páginasStatistics with R — A practical guide for beginnersPedro PereiraAinda não há avaliações
- March 2015 Accounts Assistant 0Documento2 páginasMarch 2015 Accounts Assistant 0Mariana Claudia PanaitAinda não há avaliações
- IF2 General Insurance Business Mock Exam Questions Taster Set Examinable Year: 2013/14Documento10 páginasIF2 General Insurance Business Mock Exam Questions Taster Set Examinable Year: 2013/14swaathigaAinda não há avaliações
- Chapter 7 pdf-1Documento27 páginasChapter 7 pdf-1Tora SarkarAinda não há avaliações
- Easttom, Chuck. Computer Security Fundamentals. 4th Ed., Pearson, 2020Documento3 páginasEasttom, Chuck. Computer Security Fundamentals. 4th Ed., Pearson, 2020alexander dehlaviAinda não há avaliações
- Digital Marketing Marketing Tools: Franchise AdvertisingDocumento29 páginasDigital Marketing Marketing Tools: Franchise AdvertisingMohammedAlQureshiAinda não há avaliações
- Supplier Survey FormatDocumento4 páginasSupplier Survey FormatŤhåýğųŢjAinda não há avaliações
- Brian C. Houlihan: 1413 SW 11th Street Cape Coral, FL 33991Documento1 páginaBrian C. Houlihan: 1413 SW 11th Street Cape Coral, FL 33991Brian HoulihanAinda não há avaliações
- Tle 6 Ictentrep Module 7Documento23 páginasTle 6 Ictentrep Module 7Be MotivatedAinda não há avaliações
- MNM-10646-01-B ENG, Miura Service Manual Rev BDocumento382 páginasMNM-10646-01-B ENG, Miura Service Manual Rev BВладимир ФилимоновAinda não há avaliações
- Axiocam 105 Color - User GuideDocumento21 páginasAxiocam 105 Color - User GuideSinan ChenAinda não há avaliações
- Switch ABB F60Documento148 páginasSwitch ABB F60MARIO OLIVIERIAinda não há avaliações
- Iwan Lab Guide v1.1 FinalDocumento63 páginasIwan Lab Guide v1.1 FinalRicardo SicheranAinda não há avaliações