Você também pode gostar
- IJDIWC - Volume 7, Issue 1Documento63 páginasIJDIWC - Volume 7, Issue 1IJDIWCAinda não há avaliações
- IJDIWC - Volume 4, Issue 4Documento93 páginasIJDIWC - Volume 4, Issue 4IJDIWCAinda não há avaliações
- IJDIWC - Volume 6, Issue 4Documento84 páginasIJDIWC - Volume 6, Issue 4IJDIWCAinda não há avaliações
- IJDIWC - Volume 6, Issue 2Documento94 páginasIJDIWC - Volume 6, Issue 2IJDIWCAinda não há avaliações
- IJDIWC - Volume 6, Issue 1Documento66 páginasIJDIWC - Volume 6, Issue 1IJDIWCAinda não há avaliações
- IJDIWC - Volume 6, Issue 3Documento70 páginasIJDIWC - Volume 6, Issue 3IJDIWCAinda não há avaliações
- IJDIWC - Volume 3, Issue 3Documento132 páginasIJDIWC - Volume 3, Issue 3IJDIWCAinda não há avaliações
- IJDIWC - Volume 5, Issue 2Documento94 páginasIJDIWC - Volume 5, Issue 2IJDIWCAinda não há avaliações
- IJDIWC - Volume 5, Issue 3Documento60 páginasIJDIWC - Volume 5, Issue 3IJDIWCAinda não há avaliações
- IJDIWC - Volume 3, Issue 4Documento128 páginasIJDIWC - Volume 3, Issue 4IJDIWCAinda não há avaliações
- IJDIWC - Volume 4, Issue 1Documento171 páginasIJDIWC - Volume 4, Issue 1IJDIWCAinda não há avaliações
- IJDIWC - Volume 4, Issue 3Documento144 páginasIJDIWC - Volume 4, Issue 3IJDIWCAinda não há avaliações
- Nnet Based Audio Content Classification and Indexing SystemDocumento13 páginasNnet Based Audio Content Classification and Indexing SystemIJDIWCAinda não há avaliações
- A Practical Proxy Signature SchemeDocumento10 páginasA Practical Proxy Signature SchemeIJDIWCAinda não há avaliações
- IJDIWC - Volume 3, Issue 2Documento67 páginasIJDIWC - Volume 3, Issue 2IJDIWCAinda não há avaliações
- IJDIWC - Volume 3, Issue 1Documento143 páginasIJDIWC - Volume 3, Issue 1IJDIWCAinda não há avaliações
- IJDIWC - Volume 4, Issue 2Documento100 páginasIJDIWC - Volume 4, Issue 2IJDIWCAinda não há avaliações
- Formal Specification For Real-Time Object Oriented Systems With Uml DesignDocumento13 páginasFormal Specification For Real-Time Object Oriented Systems With Uml DesignIJDIWCAinda não há avaliações
- Evaluation and Improvements To Motion Generation in NS2 For Wireless Mobile Network SimulationDocumento9 páginasEvaluation and Improvements To Motion Generation in NS2 For Wireless Mobile Network SimulationIJDIWCAinda não há avaliações
- A Framework For Modeling Medical Diagnosis and Decision Support ServicesDocumento20 páginasA Framework For Modeling Medical Diagnosis and Decision Support ServicesIJDIWCAinda não há avaliações
- Paper Registration To Repository From Researcher DatabaseDocumento6 páginasPaper Registration To Repository From Researcher DatabaseIJDIWCAinda não há avaliações
- Considerations For Social Network Site (SNS) Use in EducationDocumento16 páginasConsiderations For Social Network Site (SNS) Use in EducationIJDIWCAinda não há avaliações
- When Is A Student-Centered, Technology Supported Learning A Success?Documento14 páginasWhen Is A Student-Centered, Technology Supported Learning A Success?IJDIWCAinda não há avaliações
- Remote Monitoring Using Wireless Cellular NetworksDocumento5 páginasRemote Monitoring Using Wireless Cellular NetworksIJDIWCAinda não há avaliações
- Application of Synthetic Instrumentation That Applies The Trend of Software-Based Approach For Measuring On The Field of Modern Wireless Transfer SystemsDocumento14 páginasApplication of Synthetic Instrumentation That Applies The Trend of Software-Based Approach For Measuring On The Field of Modern Wireless Transfer SystemsIJDIWCAinda não há avaliações
- Mobilequiz - A Lecture Survey Tool Using Smartphones and QR TagsDocumento14 páginasMobilequiz - A Lecture Survey Tool Using Smartphones and QR TagsIJDIWCAinda não há avaliações
- Communication Support Needs For Education in A Global Context Based On Suitable Information TechnologiesDocumento11 páginasCommunication Support Needs For Education in A Global Context Based On Suitable Information TechnologiesIJDIWCAinda não há avaliações
- Can A Single Security Framework Address Information Security Risks Adequately?Documento9 páginasCan A Single Security Framework Address Information Security Risks Adequately?IJDIWCAinda não há avaliações
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNo EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNota: 4 de 5 estrelas4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingNo EverandThe Little Book of Hygge: Danish Secrets to Happy LivingNota: 3.5 de 5 estrelas3.5/5 (400)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNo EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNota: 4 de 5 estrelas4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)No EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Nota: 4 de 5 estrelas4/5 (98)
- The Emperor of All Maladies: A Biography of CancerNo EverandThe Emperor of All Maladies: A Biography of CancerNota: 4.5 de 5 estrelas4.5/5 (271)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNo EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNota: 3.5 de 5 estrelas3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItNo EverandNever Split the Difference: Negotiating As If Your Life Depended On ItNota: 4.5 de 5 estrelas4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNo EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNota: 4.5 de 5 estrelas4.5/5 (474)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNo EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNota: 4.5 de 5 estrelas4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaNo EverandThe Unwinding: An Inner History of the New AmericaNota: 4 de 5 estrelas4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnNo EverandTeam of Rivals: The Political Genius of Abraham LincolnNota: 4.5 de 5 estrelas4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyNo EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyNota: 3.5 de 5 estrelas3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNo EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNota: 4 de 5 estrelas4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNo EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNota: 4.5 de 5 estrelas4.5/5 (344)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)No EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Nota: 4.5 de 5 estrelas4.5/5 (121)
- PHP Login Page ExampleDocumento2 páginasPHP Login Page ExampleHawk EyeAinda não há avaliações
- ErpDocumento2 páginasErpHarmanWaliaAinda não há avaliações
- Template LEARNING PLAN-CADD 01Documento4 páginasTemplate LEARNING PLAN-CADD 01Eli BerameAinda não há avaliações
- URTEC-208344-MS 3D Seismic Facies Classification On CPU and GPU HPC ClustersDocumento14 páginasURTEC-208344-MS 3D Seismic Facies Classification On CPU and GPU HPC ClustersFät MãAinda não há avaliações
- PLC s7 AhmadiDocumento59 páginasPLC s7 Ahmadisina20795Ainda não há avaliações
- IoT Business Index 2020 Securing IoTDocumento5 páginasIoT Business Index 2020 Securing IoTFelix VentourasAinda não há avaliações
- A Case Study For Improving The Performance of Web ApplicationDocumento4 páginasA Case Study For Improving The Performance of Web Applicationijbui iirAinda não há avaliações
- 2.1 Project / System DefinitionDocumento3 páginas2.1 Project / System Definitionpankaj patilAinda não há avaliações
- Hannstar J mv-4 94v-0 0823 - Dell - Studio - 1435 - 1535 - QUANTA - FM6 - DISCRETE - REV - 3A PDFDocumento58 páginasHannstar J mv-4 94v-0 0823 - Dell - Studio - 1435 - 1535 - QUANTA - FM6 - DISCRETE - REV - 3A PDFPaxOtium75% (4)
- I-7018 (R) (BL) (P), M-7018 (R) Quick Start GuideDocumento4 páginasI-7018 (R) (BL) (P), M-7018 (R) Quick Start GuideData CommunicationAinda não há avaliações
- Terms of Reference - Remote Sensing - FMBDocumento2 páginasTerms of Reference - Remote Sensing - FMBgisphilAinda não há avaliações
- WikipediaHandbookofComputerSecurityandDigitalForensics2015 PartI PDFDocumento212 páginasWikipediaHandbookofComputerSecurityandDigitalForensics2015 PartI PDFDhanaraj ShanmugasundaramAinda não há avaliações
- Todas As Versões Das Chaves de Segurança Do Windows 7Documento7 páginasTodas As Versões Das Chaves de Segurança Do Windows 7betopsantosAinda não há avaliações
- RepDocumento41 páginasReppriyarajagopal_kAinda não há avaliações
- Lecture - 5Documento30 páginasLecture - 5Aweem SaidAinda não há avaliações
- Sap Simple Logistics TutorialDocumento74 páginasSap Simple Logistics TutorialAswathyAkhosh96% (27)
- ANSYS Installation TutorialDocumento162 páginasANSYS Installation Tutorialtienanh_08Ainda não há avaliações
- Activiti User GuideDocumento305 páginasActiviti User GuideyogaarsaAinda não há avaliações
- Online Course On Embedded SystemsDocumento75 páginasOnline Course On Embedded SystemspandiAinda não há avaliações
- 74 Ls 175Documento8 páginas74 Ls 175AndrescronqueAinda não há avaliações
- PPPoE ICONECT - 09 de Ago 2019Documento46 páginasPPPoE ICONECT - 09 de Ago 2019Fábio FariasAinda não há avaliações
- Ulti Net Install ProcedureDocumento6 páginasUlti Net Install Procedurezotya54Ainda não há avaliações
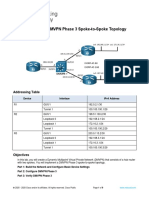
- 19.1.4 Lab - Implement A DMVPN Phase 3 Spoke To Spoke TopologyDocumento9 páginas19.1.4 Lab - Implement A DMVPN Phase 3 Spoke To Spoke Topology抓愛恰Ainda não há avaliações
- 05-6632A01 RevI MCR Tech ManualDocumento507 páginas05-6632A01 RevI MCR Tech ManualGustavo PargadeAinda não há avaliações
- HRM Literature ReviewDocumento2 páginasHRM Literature ReviewMuhammad Shayan ArifAinda não há avaliações
- HPE Storage Course SummaryDocumento3 páginasHPE Storage Course SummaryJuan DAinda não há avaliações
- Mrityunjay ResumeDocumento2 páginasMrityunjay ResumeMrityunjay SinghAinda não há avaliações
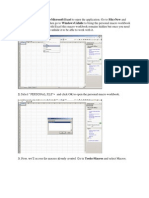
- Visual Basic For MacrosDocumento9 páginasVisual Basic For Macrosmalvin_ongAinda não há avaliações
- Price List From Portworld NicoleDocumento3 páginasPrice List From Portworld NicoleNew Strength SolutionsAinda não há avaliações
- Fortinet NSE4Documento34 páginasFortinet NSE4Hamed Ghabi100% (1)