Você também pode gostar
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)No EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Nota: 4.5 de 5 estrelas4.5/5 (119)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNo EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNota: 4.5 de 5 estrelas4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingNo EverandThe Little Book of Hygge: Danish Secrets to Happy LivingNota: 3.5 de 5 estrelas3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNo EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNota: 3.5 de 5 estrelas3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItNo EverandNever Split the Difference: Negotiating As If Your Life Depended On ItNota: 4.5 de 5 estrelas4.5/5 (838)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNo EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNota: 4 de 5 estrelas4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnNo EverandTeam of Rivals: The Political Genius of Abraham LincolnNota: 4.5 de 5 estrelas4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyNo EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyNota: 3.5 de 5 estrelas3.5/5 (2219)
- The Emperor of All Maladies: A Biography of CancerNo EverandThe Emperor of All Maladies: A Biography of CancerNota: 4.5 de 5 estrelas4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNo EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNota: 4 de 5 estrelas4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNo EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNota: 4.5 de 5 estrelas4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNo EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNota: 4 de 5 estrelas4/5 (894)
- Guide To Certifications Robert HalfDocumento26 páginasGuide To Certifications Robert HalfBrook Rene JohnsonAinda não há avaliações
- 6 components of the Code of Ethics and 7 Standards of Professional ConductDocumento258 páginas6 components of the Code of Ethics and 7 Standards of Professional ConductBrook Rene Johnson71% (7)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNo EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNota: 4.5 de 5 estrelas4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaNo EverandThe Unwinding: An Inner History of the New AmericaNota: 4 de 5 estrelas4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)No EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Nota: 4 de 5 estrelas4/5 (98)
- The Amazing Story of Stock Market SeasonalityDocumento5 páginasThe Amazing Story of Stock Market SeasonalityBrook Rene JohnsonAinda não há avaliações
- History of Computer AnimationDocumento39 páginasHistory of Computer AnimationRanzelle UrsalAinda não há avaliações
- NACE CIP Part II - (6) Coatings For Industry - (Qs - As)Documento23 páginasNACE CIP Part II - (6) Coatings For Industry - (Qs - As)Almagesto QuenayaAinda não há avaliações
- Waves 100Documento6 páginasWaves 100Brook Rene JohnsonAinda não há avaliações
- 9-Lesson 5 Direct and Indirect SpeechDocumento8 páginas9-Lesson 5 Direct and Indirect Speechlaiwelyn100% (4)
- GRE Quant Concepts FormulaeDocumento31 páginasGRE Quant Concepts Formulaeshaliniark100% (3)
- What Is A Lecher AntennaDocumento4 páginasWhat Is A Lecher AntennaPt AkaashAinda não há avaliações
- Designers' Guide To Eurocode 7 Geothechnical DesignDocumento213 páginasDesigners' Guide To Eurocode 7 Geothechnical DesignJoão Gamboias100% (9)
- Inventory ManagementDocumento60 páginasInventory Managementdrashti0% (1)
- Deep WebDocumento49 páginasDeep WebBrook Rene JohnsonAinda não há avaliações
- Changing Cycle Frequencies Produces Different Effects Armstrong EconomicsDocumento3 páginasChanging Cycle Frequencies Produces Different Effects Armstrong EconomicsBrook Rene JohnsonAinda não há avaliações
- Differenced Price Has Low R SquaredDocumento1 páginaDifferenced Price Has Low R SquaredBrook Rene JohnsonAinda não há avaliações
- The 21 Laws of Boldness PDFDocumento59 páginasThe 21 Laws of Boldness PDFVishnu Agnihotri100% (1)
- One-Way ANOVA Guide for Hypothesis TestingDocumento18 páginasOne-Way ANOVA Guide for Hypothesis TestingBrook Rene JohnsonAinda não há avaliações
- Directions Magazine - GIS Jobs 2013Documento48 páginasDirections Magazine - GIS Jobs 2013odcardozoAinda não há avaliações
- One-Way ANOVA Guide for Hypothesis TestingDocumento18 páginasOne-Way ANOVA Guide for Hypothesis TestingBrook Rene JohnsonAinda não há avaliações
- Home Protector - Quick - Quote - Cheat SheetDocumento8 páginasHome Protector - Quick - Quote - Cheat SheetBrook Rene JohnsonAinda não há avaliações
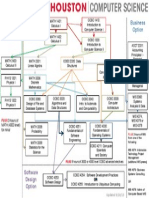
- COSC FlowchartDocumento1 páginaCOSC FlowchartBrook Rene JohnsonAinda não há avaliações
- Time Value of Money Problems On A Texas Instruments TI-83 - TVM Appendix B Using The TI-83-84Documento10 páginasTime Value of Money Problems On A Texas Instruments TI-83 - TVM Appendix B Using The TI-83-84Brook Rene JohnsonAinda não há avaliações
- Recession Proof Graduate1Documento30 páginasRecession Proof Graduate1truongpham91Ainda não há avaliações
- Predictability-Chaos-Lorenz Attractor MEA719 Lec4 Jan28 2009Documento35 páginasPredictability-Chaos-Lorenz Attractor MEA719 Lec4 Jan28 2009Brook Rene JohnsonAinda não há avaliações
- Introduction to Fractals in FinanceDocumento28 páginasIntroduction to Fractals in FinanceprsrivastavAinda não há avaliações
- User GuideDocumento42 páginasUser GuideBrook Rene JohnsonAinda não há avaliações
- Containing Systemic Risk: The Road To Reform CRMPG-IIIDocumento176 páginasContaining Systemic Risk: The Road To Reform CRMPG-IIICDObaby100% (2)
- 5 Grade - Lesson 1.3 Dissolving and Back Again: ObjectiveDocumento4 páginas5 Grade - Lesson 1.3 Dissolving and Back Again: ObjectiveManushka ThomasAinda não há avaliações
- Board of Intermediate & Secondary Education, Lahore: Tahir Hussain JafriDocumento2 páginasBoard of Intermediate & Secondary Education, Lahore: Tahir Hussain Jafridr_azharhayatAinda não há avaliações
- Adopt 2017 APCPI procurement monitoringDocumento43 páginasAdopt 2017 APCPI procurement monitoringCA CAAinda não há avaliações
- WORK ORDER TITLEDocumento2 páginasWORK ORDER TITLEDesign V-Tork ControlsAinda não há avaliações
- Fort St. John - Tender Awards - RCMP Building ConstructionDocumento35 páginasFort St. John - Tender Awards - RCMP Building ConstructionAlaskaHighwayNewsAinda não há avaliações
- Mindfulness With Collegiate Gymnasts - Effects On Flow, Stress and Overall Mindfulness LevelsNicholas P. Cherupa,, Zeljka VidicDocumento13 páginasMindfulness With Collegiate Gymnasts - Effects On Flow, Stress and Overall Mindfulness LevelsNicholas P. Cherupa,, Zeljka VidicGABRIELAinda não há avaliações
- 1136 E01-ML01DP5 Usermanual EN V1.2Documento11 páginas1136 E01-ML01DP5 Usermanual EN V1.2HectorAinda não há avaliações
- Y06209 November 2015Documento28 páginasY06209 November 2015Fredy CoyagoAinda não há avaliações
- Mock PPT 2023 TietDocumento22 páginasMock PPT 2023 Tiettsai42zigAinda não há avaliações
- Saes H 201Documento9 páginasSaes H 201heartbreakkid132Ainda não há avaliações
- IPA Assignment Analyzes New Public AdministrationDocumento8 páginasIPA Assignment Analyzes New Public AdministrationKumaran ViswanathanAinda não há avaliações
- Use DCP to Predict Soil Bearing CapacityDocumento11 páginasUse DCP to Predict Soil Bearing CapacitysarvaiyahimmatAinda não há avaliações
- The Effects of Self-Esteem On Makeup InvolvementDocumento9 páginasThe Effects of Self-Esteem On Makeup InvolvementMichelle Nicole Tagupa SerranoAinda não há avaliações
- PrEN 12271-10 - Factory Production ControlDocumento17 páginasPrEN 12271-10 - Factory Production ControlPedjaAinda não há avaliações
- CommunicationDocumento5 páginasCommunicationRyan TomeldenAinda não há avaliações
- Non-Destructive Examination & Standard CF Acceptance For - Forgsd - Pipe Work Stub PiecesDocumento2 páginasNon-Destructive Examination & Standard CF Acceptance For - Forgsd - Pipe Work Stub PiecesveeramalaiAinda não há avaliações
- Xiaomi Mi Drone 4K User Manual GuideDocumento47 páginasXiaomi Mi Drone 4K User Manual GuideΜιχάλης ΛαχανάςAinda não há avaliações
- Investigation of Twilight Using Sky Quality Meter For Isha' Prayer TimeDocumento1 páginaInvestigation of Twilight Using Sky Quality Meter For Isha' Prayer Timeresurgam52Ainda não há avaliações
- CA Module Franklin Gari RDocumento28 páginasCA Module Franklin Gari RFranklin GariAinda não há avaliações
- Proposed - TIA - 1392 - NFPA - 221Documento2 páginasProposed - TIA - 1392 - NFPA - 221Junior TorrejónAinda não há avaliações
- Electromagnetic Braking SystemDocumento14 páginasElectromagnetic Braking SystemTanvi50% (2)
- The Critical Need For Software Engineering EducationDocumento5 páginasThe Critical Need For Software Engineering EducationGaurang TandonAinda não há avaliações
- Kuliah 1 - Konservasi GeologiDocumento5 páginasKuliah 1 - Konservasi GeologiFerdianAinda não há avaliações
- BA 302 Lesson 3Documento26 páginasBA 302 Lesson 3ピザンメルビンAinda não há avaliações