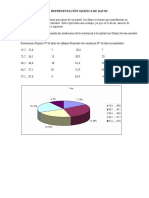
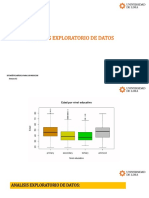
Você também pode gostar
- Tablas dinámicas y Gráficas para Excel: Una guía visual paso a pasoNo EverandTablas dinámicas y Gráficas para Excel: Una guía visual paso a pasoAinda não há avaliações
- Lect 11Documento4 páginasLect 11Mayra Alejandra Fontalvo HernandezAinda não há avaliações
- Diagrama de Tallos y HojasDocumento22 páginasDiagrama de Tallos y HojasEdicson RomeroAinda não há avaliações
- 08 EstDesc Diagramas de Tallo y HojaDocumento8 páginas08 EstDesc Diagramas de Tallo y HojaJesús Hernández RomanoAinda não há avaliações
- Representación Gráfica de Datos2-1Documento14 páginasRepresentación Gráfica de Datos2-1Gerson M. CarrilloAinda não há avaliações
- 1-Estadistica DescriptivaDocumento20 páginas1-Estadistica DescriptivaHector CamayaAinda não há avaliações
- Trabajo Final WordDocumento15 páginasTrabajo Final WordUlises Clemente AcevedoAinda não há avaliações
- Manual Estadisticas Descriptivas MINITABDocumento56 páginasManual Estadisticas Descriptivas MINITABJose DiazAinda não há avaliações
- UVM UNIDAD 1 Regresion Lineal y Correlacion 1a ParteDocumento43 páginasUVM UNIDAD 1 Regresion Lineal y Correlacion 1a Parteveronica basalduaAinda não há avaliações
- Crear y Utilizar Un Diagrama de Caja-ArcGIS Insights - DocumentaciónDocumento4 páginasCrear y Utilizar Un Diagrama de Caja-ArcGIS Insights - Documentaciónusername\Ainda não há avaliações
- Diagrama de Tallos y HojasDocumento30 páginasDiagrama de Tallos y Hojasiacoman100% (1)
- Histograma: 22 Capítulo 1 Introducción A La Estadística y Al Análisis de DatosDocumento1 páginaHistograma: 22 Capítulo 1 Introducción A La Estadística y Al Análisis de Datoshernan ccorimanya sopantaAinda não há avaliações
- Diagrama de Tallos y HojasDocumento8 páginasDiagrama de Tallos y HojasTeresita LirdAinda não há avaliações
- 1-Estadistica DescriptivaDocumento20 páginas1-Estadistica DescriptivaCristian Fernandez WilgenhoffAinda não há avaliações
- Semana 6.2 AED V.finalDocumento31 páginasSemana 6.2 AED V.finalJazmin HerreraAinda não há avaliações
- Estadistica Descriptiva - Diagrama de Tallo y HojasDocumento39 páginasEstadistica Descriptiva - Diagrama de Tallo y HojasManuel ChávezAinda não há avaliações
- Tema 2Documento14 páginasTema 2Ivan Gutierrez GarciaAinda não há avaliações
- Gráfica de Tallo y Hojas Representa Datos Que Separan Cada Valor en Dos Partes El TalloDocumento4 páginasGráfica de Tallo y Hojas Representa Datos Que Separan Cada Valor en Dos Partes El TalloAna PaolaAinda não há avaliações
- Análisis Exploratorio de DatosDocumento27 páginasAnálisis Exploratorio de DatosJIMMY GABRIELAinda não há avaliações
- INTRODUCCION A LA ESTADISTICADocumento16 páginasINTRODUCCION A LA ESTADISTICAMayte Del Villar GonzalezAinda não há avaliações
- 1-Estadistica DescriptivaDocumento20 páginas1-Estadistica Descriptivaraimundo ronaldinhoAinda não há avaliações
- El Análisis Exploratorio de DatosDocumento14 páginasEl Análisis Exploratorio de DatosalbgomezAinda não há avaliações
- Tabulacion y GraficosDocumento24 páginasTabulacion y GraficosEmiliano NuñezAinda não há avaliações
- Estadística Aplicada - (Teoría y Práctica) - Tema 4 - (Psicología - Ucss - 2019-1)Documento8 páginasEstadística Aplicada - (Teoría y Práctica) - Tema 4 - (Psicología - Ucss - 2019-1)Brayan Cristofer Collachagua MeloAinda não há avaliações
- Temaii-Inf-Estad 2023 2Documento105 páginasTemaii-Inf-Estad 2023 2avrmexico4x4Ainda não há avaliações
- Diagrama de Tallo y Hoja de Tipo AdosadoDocumento3 páginasDiagrama de Tallo y Hoja de Tipo AdosadoGerson BonillaAinda não há avaliações
- Guia 103Documento22 páginasGuia 103Alejandro AgredoAinda não há avaliações
- 1.9 Histograma, 1.10 Dispersion y 1.11 EstratificaciónDocumento49 páginas1.9 Histograma, 1.10 Dispersion y 1.11 EstratificaciónAdan Santiago OrtizAinda não há avaliações
- Tablas Dina MicasDocumento0 páginaTablas Dina MicasedgaralexisbrandanAinda não há avaliações
- Diagrama de Tallos y HojasDocumento8 páginasDiagrama de Tallos y HojasJamirDiazMechanAinda não há avaliações
- Qué es una tabla de contingenciaDocumento5 páginasQué es una tabla de contingenciaJonathan FelixAinda não há avaliações
- U1 EstadísticaDocumento26 páginasU1 EstadísticaJessica SánchezAinda não há avaliações
- Caracterización de Datos Cuantitativos AgrupadosDocumento7 páginasCaracterización de Datos Cuantitativos AgrupadosLpz Angie67% (3)
- Un Histograma Es Una Representación Gráfica de Una Variable en Forma de BarrasDocumento9 páginasUn Histograma Es Una Representación Gráfica de Una Variable en Forma de BarrasAlberto ReyesAinda não há avaliações
- Descripciones Importantes de La Estadística DescriptivaDocumento24 páginasDescripciones Importantes de La Estadística DescriptivaDuran Santos Angel XavierAinda não há avaliações
- Tablas ContingenciaDocumento9 páginasTablas ContingenciaMaicol M MendozaAinda não há avaliações
- Diagrama de Tallos y HojasDocumento5 páginasDiagrama de Tallos y Hojaslalo martinezAinda não há avaliações
- Estadistica para Casio FX 9860g II PDFDocumento59 páginasEstadistica para Casio FX 9860g II PDFDerrick Boza Carbonelli100% (2)
- Trabajo Finall WordDocumento20 páginasTrabajo Finall WordUlises Clemente AcevedoAinda não há avaliações
- Informe Taller RDocumento9 páginasInforme Taller RAngelo Santiago Alba VargasAinda não há avaliações
- Guia de Laboratorio 2 GraficosDocumento23 páginasGuia de Laboratorio 2 GraficosProfe JamesAinda não há avaliações
- Que Es Una Grafica Lineal Simple y de Un EjemploDocumento8 páginasQue Es Una Grafica Lineal Simple y de Un EjemploTito Julio Portocarrero WongAinda não há avaliações
- 3 Representación Gráfica 2014Documento82 páginas3 Representación Gráfica 2014Oskar RecinosAinda não há avaliações
- Calculos Estadísticos Con Excel PDFDocumento12 páginasCalculos Estadísticos Con Excel PDFOscar Rodrigo Fuentes PalavecinosAinda não há avaliações
- HistogramaDocumento10 páginasHistogramaBrenda xel-ha Arenas BlancoAinda não há avaliações
- Pasos para Construir Una Tabla de FrecuenciasDocumento23 páginasPasos para Construir Una Tabla de FrecuenciasLuis Fernando Castañeda PulidoAinda não há avaliações
- Diagrama de Cajas y Bigotes2.0Documento10 páginasDiagrama de Cajas y Bigotes2.0Juan Carlos MárquezAinda não há avaliações
- Análisis Exploratorio de Datos (AED)Documento45 páginasAnálisis Exploratorio de Datos (AED)caligro291Ainda não há avaliações
- Tablas de Distribucion de FrecuenciasDocumento31 páginasTablas de Distribucion de FrecuenciasGRANRICKYAinda não há avaliações
- Practica 2Documento7 páginasPractica 2Alberto Alises AraezAinda não há avaliações
- Clase 01 Material de Apoyo 2Documento44 páginasClase 01 Material de Apoyo 2Diego MoranAinda não há avaliações
- Diagrama de Tallos HojasDocumento2 páginasDiagrama de Tallos HojasJuan Carlos Carrasco ZapataAinda não há avaliações
- Consult ADocumento14 páginasConsult AJuliana AvilaAinda não há avaliações
- 2do Trabajo de ProbabilidadDocumento13 páginas2do Trabajo de ProbabilidadDomínguez MelvinAinda não há avaliações
- Estadistica Descriptiva GraficosDocumento13 páginasEstadistica Descriptiva Graficosaldo bustosAinda não há avaliações
- Elementos de estadística para ingeniería: Un curso básicoNo EverandElementos de estadística para ingeniería: Un curso básicoAinda não há avaliações
- Excel para principiantes: Aprenda a utilizar Excel 2016, incluyendo una introducción a fórmulas, funciones, gráficos, cuadros, macros, modelado, informes, estadísticas, Excel Power Query y másNo EverandExcel para principiantes: Aprenda a utilizar Excel 2016, incluyendo una introducción a fórmulas, funciones, gráficos, cuadros, macros, modelado, informes, estadísticas, Excel Power Query y másNota: 2.5 de 5 estrelas2.5/5 (3)
- Estadística descriptiva para datos categóricosNo EverandEstadística descriptiva para datos categóricosAinda não há avaliações
- Tablas dinámicas para todos. Desde simples tablas hasta Power-Pivot: Guía útil para crear tablas dinámicas en ExcelNo EverandTablas dinámicas para todos. Desde simples tablas hasta Power-Pivot: Guía útil para crear tablas dinámicas en ExcelAinda não há avaliações
- S11-12 DIEDSU ActividadDocumento5 páginasS11-12 DIEDSU Actividadpaola meza maldonadoAinda não há avaliações
- 686-Texto Del Artículo-1813-1-10-20170619Documento13 páginas686-Texto Del Artículo-1813-1-10-20170619paola meza maldonadoAinda não há avaliações
- S11-12 GEINCU Actividad6Documento5 páginasS11-12 GEINCU Actividad6paola meza maldonadoAinda não há avaliações
- S12 DPCYSES LO1elisaDocumento16 páginasS12 DPCYSES LO1elisapaola meza maldonadoAinda não há avaliações
- 2302-Texto Del Artículo-3874-1-10-20210722Documento24 páginas2302-Texto Del Artículo-3874-1-10-20210722paola meza maldonadoAinda não há avaliações
- Plantilla Gráfico de Gantt NEXELDocumento9 páginasPlantilla Gráfico de Gantt NEXELpaola meza maldonadoAinda não há avaliações
- Concepción o Elección Del Diseño de InvestigaciónDocumento32 páginasConcepción o Elección Del Diseño de Investigaciónpaola meza maldonadoAinda não há avaliações
- S11 Diedsu Lo1Documento10 páginasS11 Diedsu Lo1paola meza maldonadoAinda não há avaliações
- Proceso Cuantitativo: EtapasDocumento42 páginasProceso Cuantitativo: Etapaspaola meza maldonadoAinda não há avaliações
- Escala de Likert Con Tabla DinámicaDocumento8 páginasEscala de Likert Con Tabla Dinámicapaola meza maldonadoAinda não há avaliações
- ExperimentalDocumento19 páginasExperimentalpaola meza maldonadoAinda não há avaliações
- Herramientas para el análisis cualitativoDocumento14 páginasHerramientas para el análisis cualitativopaola meza maldonadoAinda não há avaliações
- CuantiDocumento40 páginasCuantipaola meza maldonadoAinda não há avaliações
- Fiabilidad sistema categorías foro e-LearningDocumento17 páginasFiabilidad sistema categorías foro e-LearningOscar Palacio LeonAinda não há avaliações
- Plantilla de Excel Diagrama de Gantt para La Gestion de ProyectosDocumento13 páginasPlantilla de Excel Diagrama de Gantt para La Gestion de Proyectospaola meza maldonadoAinda não há avaliações
- Laboratorio 1Documento1 páginaLaboratorio 1paola meza maldonadoAinda não há avaliações
- MCUALI Clase-4Documento3 páginasMCUALI Clase-4paola meza maldonadoAinda não há avaliações
- Normas básicas de presentación de trabajos de sociologíaDocumento11 páginasNormas básicas de presentación de trabajos de sociologíapaola meza maldonadoAinda não há avaliações
- Mqiv 8Documento14 páginasMqiv 8paola meza maldonadoAinda não há avaliações
- Mcuali Clase 5Documento1 páginaMcuali Clase 5paola meza maldonadoAinda não há avaliações
- MCUALI Clase-3Documento8 páginasMCUALI Clase-3paola meza maldonadoAinda não há avaliações
- MCUALI Clase-1Documento2 páginasMCUALI Clase-1paola meza maldonadoAinda não há avaliações
- MCUALI Clase-22Documento4 páginasMCUALI Clase-22paola meza maldonadoAinda não há avaliações
- Mqiv 5-7Documento48 páginasMqiv 5-7paola meza maldonadoAinda não há avaliações
- Mqiv 2Documento33 páginasMqiv 2paola meza maldonadoAinda não há avaliações
- Mqiv 3Documento32 páginasMqiv 3paola meza maldonadoAinda não há avaliações
- Mqiv 1Documento48 páginasMqiv 1paola meza maldonadoAinda não há avaliações
- MQIII2Documento15 páginasMQIII2paola meza maldonadoAinda não há avaliações
- Mqiv 4Documento13 páginasMqiv 4paola meza maldonadoAinda não há avaliações
- MQIII1Documento13 páginasMQIII1paola meza maldonadoAinda não há avaliações
- Clases de Mep Mezcla EstequiometricaDocumento17 páginasClases de Mep Mezcla EstequiometricaROGELIO LEONAinda não há avaliações
- Alcance Diseño QuantaDocumento18 páginasAlcance Diseño QuantaWALTERAinda não há avaliações
- Medición y errores en el pesoDocumento13 páginasMedición y errores en el pesoyakelin solisAinda não há avaliações
- Taller Estadistica ProbabilidadDocumento9 páginasTaller Estadistica ProbabilidadLiseth GomezAinda não há avaliações
- Parte 1 Guia SIMULACION WITH CON ARENADocumento36 páginasParte 1 Guia SIMULACION WITH CON ARENAGrover100% (1)
- Superposición e Interferencia de OndasDocumento3 páginasSuperposición e Interferencia de OndasGerson Chavez Vasquez100% (2)
- Sensores AutomotricesDocumento4 páginasSensores Automotriceswuanfuchu0% (1)
- CM Semana 1Documento3 páginasCM Semana 1ClaudioMurúaAinda não há avaliações
- Interpretación de Análisis de Fertilidad Del Suelo Información GeneralDocumento1 páginaInterpretación de Análisis de Fertilidad Del Suelo Información GeneralRudy Puma VilcaAinda não há avaliações
- TacnodosDocumento2 páginasTacnodosgermanAinda não há avaliações
- T1 Sistemas de Ecuaciones 2x2 MAT 3 ALG LINEAL 15082021Documento2 páginasT1 Sistemas de Ecuaciones 2x2 MAT 3 ALG LINEAL 15082021CARLOS CABEZASAinda não há avaliações
- Ramas de La Climatología-Grupo 1Documento14 páginasRamas de La Climatología-Grupo 1Yunior RomanAinda não há avaliações
- Unidad 2 Logica Matematica Unad Ejercicios Stiven Javier Murillo TrianaDocumento5 páginasUnidad 2 Logica Matematica Unad Ejercicios Stiven Javier Murillo TrianaStiven JavierAinda não há avaliações
- Plantilla Flujo de ProcesosDocumento6 páginasPlantilla Flujo de ProcesosestebanAinda não há avaliações
- Ficha Adicional de MatemáticaDocumento7 páginasFicha Adicional de MatemáticaDulce MimiAinda não há avaliações
- Economia 3Documento2 páginasEconomia 3Karla SamanezAinda não há avaliações
- I7038 Inteligenciaartificial I 0Documento8 páginasI7038 Inteligenciaartificial I 0Usuario 19Ainda não há avaliações
- Definicion de Los Nombres de La FilosofiaDocumento5 páginasDefinicion de Los Nombres de La FilosofiaEdgar CardenasAinda não há avaliações
- Practica 2 DensidadDocumento3 páginasPractica 2 DensidadYahuinzi CruzAinda não há avaliações
- Problemas Resueltos de Cinetica QuimicaDocumento3 páginasProblemas Resueltos de Cinetica Quimicacarmen perez llacerAinda não há avaliações
- 2020 1105actividad3 PDFDocumento5 páginas2020 1105actividad3 PDFmargarita giraldoAinda não há avaliações
- Monitorización Cardiaca Definición Y Objetivo Enfermería en Cuidados Críticos Pediátricos y Neonatales 2Documento1 páginaMonitorización Cardiaca Definición Y Objetivo Enfermería en Cuidados Críticos Pediátricos y Neonatales 2Maygualidia AguilarAinda não há avaliações
- Ciclones, Terremotos, Volcanes y Otros Fenómenos Eléctricos PDFDocumento12 páginasCiclones, Terremotos, Volcanes y Otros Fenómenos Eléctricos PDFAngi Uribe50% (2)
- Taller de RepasoDocumento4 páginasTaller de RepasoJuan Camilo BelalcazarAinda não há avaliações
- CatálogoDocumento2 páginasCatálogoErasmo Franco SAinda não há avaliações
- Informe 8 ElectroneumaticaDocumento18 páginasInforme 8 Electroneumaticakevin vilchez vargasAinda não há avaliações
- Trabajo Practico MiguelDocumento3 páginasTrabajo Practico MiguelMiguel OrtizAinda não há avaliações
- GasificaciónDocumento11 páginasGasificaciónCoral Rubi BernalAinda não há avaliações
- Sec 3 Matematicas 2Documento4 páginasSec 3 Matematicas 2Toño HernandezAinda não há avaliações