Você também pode gostar
- Concept Testing in Product DesignDocumento28 páginasConcept Testing in Product Designvenkatesh prasadAinda não há avaliações
- The PDMA ToolBook 1 for New Product DevelopmentNo EverandThe PDMA ToolBook 1 for New Product DevelopmentPaul BelliveauAinda não há avaliações
- An Analytic Review of EVM Studies in Construction IndustryDocumento11 páginasAn Analytic Review of EVM Studies in Construction IndustryRaul LopezAinda não há avaliações
- Machine Learning For Revenue Management A Complete Guide - 2020 EditionNo EverandMachine Learning For Revenue Management A Complete Guide - 2020 EditionAinda não há avaliações
- Conjoint Analysis Basic PrincipleDocumento16 páginasConjoint Analysis Basic PrinciplePAglu JohnAinda não há avaliações
- Asessing Market PotentialDocumento31 páginasAsessing Market Potentialchander shekharAinda não há avaliações
- AssignmentDocumento8 páginasAssignmentJunaid AfridiAinda não há avaliações
- GE MatrixDocumento35 páginasGE MatrixPriya SinghAinda não há avaliações
- Conjoint AnalysisDocumento4 páginasConjoint AnalysisTanmay YadavAinda não há avaliações
- CONCEPT TESTING ELECTRIC SCOOTERDocumento26 páginasCONCEPT TESTING ELECTRIC SCOOTERkushal pramanickAinda não há avaliações
- NPD Case Assignment 1Documento6 páginasNPD Case Assignment 1Yogita RaoAinda não há avaliações
- Conjoint Analysis TutorialDocumento24 páginasConjoint Analysis TutorialMohammad ShayziAinda não há avaliações
- How Do I Conduct A Concept TestDocumento3 páginasHow Do I Conduct A Concept TestSalim H.Ainda não há avaliações
- Product PricingDocumento54 páginasProduct PricingAbraham tilahunAinda não há avaliações
- Concept TestingDocumento17 páginasConcept TestingHailemariam WeldegebralAinda não há avaliações
- The Ultimate SDK Guide For Mobile Apps 2019Documento33 páginasThe Ultimate SDK Guide For Mobile Apps 2019Mahmoud HabakAinda não há avaliações
- EVA Momentum The One Ratio That Tells The Whole StoryDocumento15 páginasEVA Momentum The One Ratio That Tells The Whole StorySiYuan ZhangAinda não há avaliações
- Kano Model TemplateDocumento3.059 páginasKano Model TemplateHOÀNG Võ Nhật0% (1)
- Concept Testing: Prof M R SureshDocumento16 páginasConcept Testing: Prof M R SureshAastha VyasAinda não há avaliações
- New Product Development ProcessDocumento12 páginasNew Product Development ProcessWan Zulkifli Wan IdrisAinda não há avaliações
- Concept Testing & Product Architecture PDFDocumento37 páginasConcept Testing & Product Architecture PDFcadcam010% (1)
- Lean Project DeliveryDocumento18 páginasLean Project Deliverydodoy kangkongAinda não há avaliações
- Designing and Leveraging Buyer Personas: Sam Mallikarjunan @mallikarjunanDocumento31 páginasDesigning and Leveraging Buyer Personas: Sam Mallikarjunan @mallikarjunanAravin KumarAinda não há avaliações
- A Practical Guide To Conjoint AnalysisDocumento8 páginasA Practical Guide To Conjoint AnalysisRajeev SharmaAinda não há avaliações
- Equity Valuation Report - SpotifyDocumento3 páginasEquity Valuation Report - SpotifyFEPFinanceClub100% (1)
- Creating A Stock Analysis Chart WorksheetDocumento1 páginaCreating A Stock Analysis Chart WorksheetAnam TawhidAinda não há avaliações
- Product and Process DesignDocumento15 páginasProduct and Process DesignRahul Sethi100% (1)
- Agile Development MethodologyDocumento11 páginasAgile Development Methodologycomp enggAinda não há avaliações
- Product StrategyDocumento4 páginasProduct StrategyShaira SalandaAinda não há avaliações
- Product MetricsDocumento22 páginasProduct MetricsAkash DattaAinda não há avaliações
- Marketing ManagementDocumento22 páginasMarketing ManagementJulyanawaty WangAinda não há avaliações
- High Accuracy Forecasting For Configurable Products and Products With VariantsDocumento6 páginasHigh Accuracy Forecasting For Configurable Products and Products With VariantsEmcienAinda não há avaliações
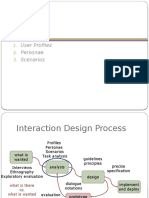
- Analysis: User Profiles Personae ScenariosDocumento32 páginasAnalysis: User Profiles Personae ScenariosSalmanAinda não há avaliações
- Eric Multi-Channel Ad AttributionDocumento53 páginasEric Multi-Channel Ad AttributionKrishnakumarSAinda não há avaliações
- Measuring Ease of Use of Mobile Applications in Ecommerce Retailing From The Perspective of Consumer Online Shopping Behaviour PatternsDocumento12 páginasMeasuring Ease of Use of Mobile Applications in Ecommerce Retailing From The Perspective of Consumer Online Shopping Behaviour PatternsAmber ZahraAinda não há avaliações
- MphasisDocumento4 páginasMphasisadc11Ainda não há avaliações
- What Is A Mockup?Documento3 páginasWhat Is A Mockup?WAR GAMING100% (1)
- Equity Research Analyst Interview Questions and Answers 1700748561Documento15 páginasEquity Research Analyst Interview Questions and Answers 1700748561rascalidkAinda não há avaliações
- State of Agile Marketing Report 2016 PDFDocumento22 páginasState of Agile Marketing Report 2016 PDFBlîndu Alexandru PetruAinda não há avaliações
- 2018-19 Manuf Extended JobAid enDocumento2 páginas2018-19 Manuf Extended JobAid enAayush10Ainda não há avaliações
- TOPIC 4 ER ModelingDocumento37 páginasTOPIC 4 ER ModelingNowlghtAinda não há avaliações
- PWC SAP Alliance Conf Sapphire Presenter Schedule 2012Documento6 páginasPWC SAP Alliance Conf Sapphire Presenter Schedule 2012Paco González MoraAinda não há avaliações
- Product Strategy: Developing the Right ApproachDocumento4 páginasProduct Strategy: Developing the Right ApproachGracielle Falcasantos DalaguitAinda não há avaliações
- Poison JobDocumento2 páginasPoison JobSaurabhAinda não há avaliações
- Marketing Management (BMA 5009) : National University of Singapore NUS Business SchoolDocumento17 páginasMarketing Management (BMA 5009) : National University of Singapore NUS Business SchoolalexdelcampoAinda não há avaliações
- ERP Innovation Implementation Model Incorporating Change ManagementDocumento15 páginasERP Innovation Implementation Model Incorporating Change ManagementKinshuk DasAinda não há avaliações
- AB TestingPlaybook - v2.0 May2017Documento48 páginasAB TestingPlaybook - v2.0 May2017Sean SimAinda não há avaliações
- Mobile Bus Ticketing System DevelopmentDocumento8 páginasMobile Bus Ticketing System Developmentralf casagdaAinda não há avaliações
- QM Road MapDocumento1 páginaQM Road MapMansur ShaikAinda não há avaliações
- Cell2Cell Data DocumentationDocumento2 páginasCell2Cell Data DocumentationJayesh PatilAinda não há avaliações
- Decision Management PDFDocumento241 páginasDecision Management PDFSrikanthchowdary MaguluriAinda não há avaliações
- ThoughtWorks Assignment PoojaRDocumento2 páginasThoughtWorks Assignment PoojaRPooja RajAinda não há avaliações
- Beer Distribution Game - Wikipedia, The Free EncyclopediaDocumento3 páginasBeer Distribution Game - Wikipedia, The Free EncyclopediaSana BhittaniAinda não há avaliações
- DSS Characteristics Data Warehouse OLAPDocumento4 páginasDSS Characteristics Data Warehouse OLAPHiraAinda não há avaliações
- Assessing ERP Post-Implementation SuccessDocumento25 páginasAssessing ERP Post-Implementation SuccessAkshay UpwanshiAinda não há avaliações
- Putnam ModelDocumento2 páginasPutnam ModelNitin DalviAinda não há avaliações
- Agile Product Roadmap Tutorial: Roman Pichler'sDocumento25 páginasAgile Product Roadmap Tutorial: Roman Pichler'smy nAinda não há avaliações
- Inspired 1 & 2 SummaryDocumento19 páginasInspired 1 & 2 SummaryjoeAinda não há avaliações
- Concept Testing: Seven Step Method For Testing Product ConceptsDocumento3 páginasConcept Testing: Seven Step Method For Testing Product ConceptsAnkit saxenaAinda não há avaliações
- Regression TestingDocumento18 páginasRegression TestingAaka ShAinda não há avaliações
- Automotive Functional Safety WPDocumento14 páginasAutomotive Functional Safety WPAvinash ChiguluriAinda não há avaliações
- Wesern Digital RaptorDocumento2 páginasWesern Digital RaptorcedlanioAinda não há avaliações
- Class 12 CSC Practical File MysqlDocumento21 páginasClass 12 CSC Practical File MysqlS JAY ADHITYAA100% (1)
- Burner Logic System PDFDocumento5 páginasBurner Logic System PDFshiviitd02Ainda não há avaliações
- 800-27015-E Honeywell Smart Viewer (HSV) Desktop App User Guide-0912Documento63 páginas800-27015-E Honeywell Smart Viewer (HSV) Desktop App User Guide-0912Atif AmeenAinda não há avaliações
- HTTP Boot Console LogDocumento31 páginasHTTP Boot Console Logdhiraj.testingAinda não há avaliações
- NNDKProg ManDocumento138 páginasNNDKProg Manflo72afAinda não há avaliações
- STM32-LCD Development Board Users Manual: All Boards Produced by Olimex Are ROHS CompliantDocumento19 páginasSTM32-LCD Development Board Users Manual: All Boards Produced by Olimex Are ROHS Compliantom_irawanAinda não há avaliações
- SAP Workflow and Events - Control The Flow!Documento35 páginasSAP Workflow and Events - Control The Flow!AMRAinda não há avaliações
- GCX Nihon Kohden Vismo PVM-2700Documento3 páginasGCX Nihon Kohden Vismo PVM-2700Felipe Ignacio Salinas PizarroAinda não há avaliações
- Far East College of Information Technology: Preliminary Examination in Ict5Documento5 páginasFar East College of Information Technology: Preliminary Examination in Ict5Katz EscañoAinda não há avaliações
- 2023 BlackRock Summer Analyst Program AcceleratorDocumento1 página2023 BlackRock Summer Analyst Program AcceleratorOlaoluwa OgunleyeAinda não há avaliações
- CIE Lab Color SpaceDocumento6 páginasCIE Lab Color SpaceOswaldo Cortés Vázquez0% (1)
- Java Lab AssignmentsDocumento12 páginasJava Lab AssignmentsPradeep Tiwari0% (1)
- Turnitin - Originality Report - BTP ReportDocumento7 páginasTurnitin - Originality Report - BTP Reportatharvapatle1214129Ainda não há avaliações
- How to Start a Software Company in 3 StepsDocumento3 páginasHow to Start a Software Company in 3 Stepshigh2Ainda não há avaliações
- ScrapyDocumento230 páginasScrapyKaligula GAinda não há avaliações
- Bapi Sap AbapDocumento73 páginasBapi Sap Abaprajesh98765Ainda não há avaliações
- Configuration Data Sheet Roclink 800 Configuration Software Rl800 en 132208Documento5 páginasConfiguration Data Sheet Roclink 800 Configuration Software Rl800 en 132208Leonardo Holanda100% (1)
- 2007 TL Navigation Diagnostic MenuDocumento13 páginas2007 TL Navigation Diagnostic MenuZsolt GeraAinda não há avaliações
- Report (Final) 222 PDFDocumento62 páginasReport (Final) 222 PDFNavin KumarAinda não há avaliações
- Surecom Ep-4904sx ManualDocumento53 páginasSurecom Ep-4904sx ManualCarlos Eduardo Dos SantosAinda não há avaliações
- Manu1 U1 A2 OsrrDocumento23 páginasManu1 U1 A2 OsrrCinthya Alejandra RobledoAinda não há avaliações
- Creating Webservice Using JBossDocumento7 páginasCreating Webservice Using JBossMatthias TiedemannAinda não há avaliações
- CISSP Cheat Sheet Domain 3Documento1 páginaCISSP Cheat Sheet Domain 3Zainulabdin100% (4)
- Cheat Sheet: 10 React Security Best PracticesDocumento1 páginaCheat Sheet: 10 React Security Best PracticesraduAinda não há avaliações
- HCVR 5208a 5216aDocumento1 páginaHCVR 5208a 5216ajamesdd10Ainda não há avaliações
- MET 205 - Cotter PinDocumento64 páginasMET 205 - Cotter Pintomtom9649Ainda não há avaliações
- Visual Basic Guide for BeginnersDocumento28 páginasVisual Basic Guide for BeginnersSasi Rekha SankarAinda não há avaliações
- $100M Leads: How to Get Strangers to Want to Buy Your StuffNo Everand$100M Leads: How to Get Strangers to Want to Buy Your StuffNota: 5 de 5 estrelas5/5 (12)
- $100M Offers: How to Make Offers So Good People Feel Stupid Saying NoNo Everand$100M Offers: How to Make Offers So Good People Feel Stupid Saying NoNota: 5 de 5 estrelas5/5 (20)
- Surrounded by Idiots: The Four Types of Human Behavior and How to Effectively Communicate with Each in Business (and in Life) (The Surrounded by Idiots Series) by Thomas Erikson: Key Takeaways, Summary & AnalysisNo EverandSurrounded by Idiots: The Four Types of Human Behavior and How to Effectively Communicate with Each in Business (and in Life) (The Surrounded by Idiots Series) by Thomas Erikson: Key Takeaways, Summary & AnalysisNota: 4.5 de 5 estrelas4.5/5 (2)
- The Coaching Habit: Say Less, Ask More & Change the Way You Lead ForeverNo EverandThe Coaching Habit: Say Less, Ask More & Change the Way You Lead ForeverNota: 4.5 de 5 estrelas4.5/5 (186)
- The First Minute: How to start conversations that get resultsNo EverandThe First Minute: How to start conversations that get resultsNota: 4.5 de 5 estrelas4.5/5 (55)
- The Millionaire Fastlane, 10th Anniversary Edition: Crack the Code to Wealth and Live Rich for a LifetimeNo EverandThe Millionaire Fastlane, 10th Anniversary Edition: Crack the Code to Wealth and Live Rich for a LifetimeNota: 4.5 de 5 estrelas4.5/5 (85)
- 12 Months to $1 Million: How to Pick a Winning Product, Build a Real Business, and Become a Seven-Figure EntrepreneurNo Everand12 Months to $1 Million: How to Pick a Winning Product, Build a Real Business, and Become a Seven-Figure EntrepreneurNota: 4 de 5 estrelas4/5 (2)
- Think Faster, Talk Smarter: How to Speak Successfully When You're Put on the SpotNo EverandThink Faster, Talk Smarter: How to Speak Successfully When You're Put on the SpotNota: 5 de 5 estrelas5/5 (1)
- Broken Money: Why Our Financial System Is Failing Us and How We Can Make It BetterNo EverandBroken Money: Why Our Financial System Is Failing Us and How We Can Make It BetterNota: 5 de 5 estrelas5/5 (1)
- Get to the Point!: Sharpen Your Message and Make Your Words MatterNo EverandGet to the Point!: Sharpen Your Message and Make Your Words MatterNota: 4.5 de 5 estrelas4.5/5 (280)
- Nonviolent Communication by Marshall B. Rosenberg - Book Summary: A Language of LifeNo EverandNonviolent Communication by Marshall B. Rosenberg - Book Summary: A Language of LifeNota: 4.5 de 5 estrelas4.5/5 (49)
- How to Talk to Anyone at Work: 72 Little Tricks for Big Success Communicating on the JobNo EverandHow to Talk to Anyone at Work: 72 Little Tricks for Big Success Communicating on the JobNota: 4.5 de 5 estrelas4.5/5 (36)
- Seeing What Others Don't: The Remarkable Ways We Gain InsightsNo EverandSeeing What Others Don't: The Remarkable Ways We Gain InsightsNota: 4 de 5 estrelas4/5 (288)