Escolar Documentos
Profissional Documentos
Cultura Documentos
Tuning Methodology
Enviado por
MuhammadDireitos autorais
Formatos disponíveis
Compartilhar este documento
Compartilhar ou incorporar documento
Você considera este documento útil?
Este conteúdo é inapropriado?
Denunciar este documentoDireitos autorais:
Formatos disponíveis
Tuning Methodology
Enviado por
MuhammadDireitos autorais:
Formatos disponíveis
12/5/12 Tuning_Methodology
1/31 www.pafumi.net/Tuning_Methodology.html
Tuning Methodology
Quick thinks to check for
Check Disk I/O
Improper PGA Setup
Modify init.ora Parameters
SQL Code Tuning
Collect Schema Statistics
Redo Log Switches
Large Full Table Scans
Small Full Table Scans and Index Scans
Many Indexes on Data Buffer Cache
Check for skewed Indexes (unbalanced)
Tuning Database Buffer Cache
Fragmentation on DB Objects
Size of LOG_BUFFER
Size of SHARED_POOL_SIZE
Allocate Files Properly (check waits on them)
Checking Active Statements
Use IPC for local Connections
Check Undo Parameters
Detect High SQL Parse
Monitor Open and Cached Cursors
Detect Top 10 Queries in SQL Area
Allocate Objects into Multiple Block Buffers (another web page)
Check for Indexes not Used and HOT Tables
Detect and Resolve Buffer Busy Waits ***********************
Show Porcentage of a Table in the data buffer
Testing Procedures or Packages for Performance
Using PGA Advice Utility
Check Sorts
Optimizing Indexes (creating 32k block size)
Quick Things to Check for
My goal is to quickly identify and correct performance problems. Here is a summary of the things that I look at first:
1 - Install STATSPACK first, and get hourly snaps working.
2 - Get an SQL access report (or plan9i.sql), an spreport during peak times, and statspack_alert.sql output.
3 - Look for "silver bullet fixes":
partial schema statistics (using dbms_stats)
missing indexes
optimizer_index_cost_adj=15 #10-15 for OLTP systems, 50 for DW #This adjusts the optimizer to favor index access
optimizer_index_caching=85 (depending on RAM for index caching, around 85)
optimizer_mode=first_rows (for OLTP)
parallel_automatic_tuning=TRUE (parallelizes full-table scans, Because parallel full-table scans are very fast, the CBO will give a higher cost to index access and be friendlier
to full-table scans)
hash_area_size too small (too many nested loop joins)
4 - Fully utilize server RAM - On a dedicated Oracle server, use all extra RAM for db_cache_size less PGA's and 20% RAM reserve for OS.
5 - Get the bottlenecks - See STATSPACK top 5 wait events - OEM performance pack reports - TOAD reports
6 - Look for Buffer Busy Waits resulting from table/index freelist shortages
7 - See if large-table full-table scans can be removed with well-placed indexes
8 - If tables are low volatility, seek an MV that can pre-join/pre-aggregate common queries. Turn-on automatic query rewrite
9 - Look for non-reentrant SQL - (literals values inside SQL from v$sql) - If so, set cursor_sharing=force
Non-Use of Bind Variables
A quick method of seeing whether code is being reused (a key indicator of proper bind variable usage) is to look at the values of reusable and non-reusable memory in the shared
pool. A SQL for determining this comparison of reusable to non-reusable code is shown here:
ttitle 'Shared Pool Utilization'
spool sql_garbage
select 1 nopr, to_char(a.inst_id) inst_id, a.users users,
to_char(a.garbage,'9,999,999,999') garbage,
12/5/12 Tuning_Methodology
2/31 www.pafumi.net/Tuning_Methodology.html
to_char(b.good,'9,999,999,999') good,
to_char((b.good/(b.good+a.garbage))*100,'9,999,999.999') good_percent
from (select a.inst_id, b.username users,
sum(a.sharable_mem+a.persistent_mem) Garbage,
to_number(null) good
from sys.gv_$sqlarea a,dba_users b
where (a.parsing_user_id = b.user_id and a.executions<=1)
group by a.inst_id, b.username
union
select distinct c.inst_id, b.username users, to_number(null) garbage,
sum(c.sharable_mem+c.persistent_mem) Good
from dba_users b, sys.gv_$sqlarea c
where (b.user_id=c.parsing_user_id and c.executions>1)
group by c.inst_id, b.username) a,
(select a.inst_id, b.username users, sum(a.sharable_mem+a.persistent_mem) Garbage,
to_number(null) good
from sys.gv_$sqlarea a, dba_users b
where (a.parsing_user_id = b.user_id and a.executions<=1)
group by a.inst_id,b.username
union
select distinct c.inst_id, b.username users, to_number(null) garbage,
sum(c.sharable_mem+c.persistent_mem) Good
from dba_users b, sys.gv_$sqlarea c
where (b.user_id=c.parsing_user_id and c.executions>1)
group by c.inst_id, b.username) b
where a.users=b.users
and a.inst_id=b.inst_id
and a.garbage is not null and b.good is not null
union
select 2 nopr,
'-------' inst_id,'-------------' users,'--------------' garbage,'--------------' good,
'--------------' good_percent from dual
union
select 3 nopr, to_char(a.inst_id,'999999'), to_char(count(a.users)) users,
to_char(sum(a.garbage),'9,999,999,999') garbage, to_char(sum(b.good),'9,999,999,999') good,
to_char(((sum(b.good)/(sum(b.good)+sum(a.garbage)))*100),'9,999,999.999') good_percent
from (select a.inst_id, b.username users, sum(a.sharable_mem+a.persistent_mem) Garbage,
to_number(null) good
from sys.gv_$sqlarea a, dba_users b
where (a.parsing_user_id = b.user_id and a.executions<=1)
group by a.inst_id,b.username
union
select distinct c.inst_id, b.username users, to_number(null) garbage,
sum(c.sharable_mem+c.persistent_mem) Good
from dba_users b, sys.gv_$sqlarea c
where (b.user_id=c.parsing_user_id and c.executions>1)
group by c.inst_id,b.username) a,
(select a.inst_id, b.username users, sum(a.sharable_mem+a.persistent_mem) Garbage,
to_number(null) good
from sys.gv_$sqlarea a, dba_users b
where (a.parsing_user_id = b.user_id and a.executions<=1)
group by a.inst_id,b.username
union
select distinct c.inst_id, b.username users, to_number(null) garbage,
sum(c.sharable_mem+c.persistent_mem) Good
from dba_users b, sys.gv_$sqlarea c
where (b.user_id=c.parsing_user_id and c.executions>1)
group by c.inst_id, b.username) b
where a.users=b.users
and a.inst_id=b.inst_id
and a.garbage is not null and b.good is not null
group by a.inst_id
order by 1,2 desc
/
spool off
ttitle off
set pages 22
An example report is
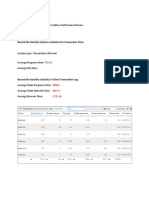
Date: 03/25/05 Page: 1
Time: 17:51 PM Shared Pool Utilization SYSTEM
whoville database
users Non-Shared SQL Shared SQL Percent Shared
-------------------- -------------- -------------- --------------
WHOAPP 532,097,982 1,775,745 .333
SYS 5,622,594 5,108,017 47.602
DBSNMP 678,616 219,775 24.463
SYSMAN 439,915 2,353,205 84.250
SYSTEM 425,586 20,674 4.633
------------- -------------- -------------- --------------
5 541,308,815 9,502,046 1.725
As you can see the majority owner in this application, WHOAPP is only showing 0.3 percent of reusable code by memory usage and is tying up an amazing 530 megabytes with
non-reusable code! Lets look at a database with good reuse statistics. Look at this one:
Date: 11/13/05 Page: 1
Time: 03:15 PM Shared Pool Utilization PERFSTAT
dbaville database
12/5/12 Tuning_Methodology
3/31 www.pafumi.net/Tuning_Methodology.html
users Non-Shared SQL Shared SQL Percent Shared
-------------------- -------------- -------------- --------------
DBAVILLAGE 9,601,173 81,949,581 89.513
PERFSTAT 2,652,827 199,868 7.006
DBASTAGER 1,168,137 35,468,687 96.812
SYS 76,037 5,119,125 98.536
------------- -------------- -------------- --------------
4 13,498,174 122,737,261 90.092
Notice how the two application owners, DBAVILLAGE and DBASTAGER show 89.513 and 96.812 reuse percentage by memory footprint for code.
So what else can we look at to see about code reusage, the above reports give us a gross indication, how about something with a bit more usability to correct the situation? The
V$SQLAREA and V$SQLTEXT views give us the capability to look at the current code in the shared pool and determine if it is using, or not using bind variables.
set lines 140 pages 55 verify off feedback off
col num_of_times heading 'Number|Of|Repeats'
col SQL heading 'SubString - &&chars Characters'
col username format a15 heading 'User'
@title132 'Similar SQL'
spool rep_out\&db\similar_sql&&chars
select b.username,substr(a.sql_text,1,&&chars) SQL,
count(a.sql_text) num_of_times from v$sqlarea a, dba_users b
where a.parsing_user_id=b.user_id
group by b.username,substr(a.sql_text,1,&&chars) having count(a.sql_text)>&&num_repeats
order by count(a.sql_text) desc;
spool off
undef chars
undef num_repeats
clear columns
set lines 80 pages 22 verify on feedback on
ttitle off
It shows a simple script to determine, based on the first x characters (input when the report is executed) the number of SQL statements that are identifical up to the first x
characters. This shows us the repeating code in the database and helps us to track down the offending statements for correction. An example output :
Date: 02/23/05 Page: 1
Time: 10:20 AM Similar SQL SYSTEM
whoville database
User SubString - 120
Characters
--------------- -------------------------------------------------------
Number
Of
Repeats
---------
-
WHOAPP SELECT Invoices."INVOICEKEY", Invoices."CLIENTKEY", Invoices."BUYSTATUS", Invoices."DEBTORKEY",
Invoices."INPUTTRANSKEY"
1752
WHOAPP SELECT DisputeCode.DisputeCode , DisputeCode.Disputed , InvDispute."ROWID" , DisputeCode."ROWID" FROM InvDispute ,
Disp
458
WHOAPP SELECT Transactions.PostDate , Payments.PointsAmt , Payments.Type_ AS PmtType , Payments.Descr , Payments.FeeBasis ,
Pay
449
SYS SELECT SUM(Payments.Amt) AS TotPmtAmt , SUM(Payments.FeeEscrow) AS TotFeeEscrow , SUM(Payments.RsvEscrow) AS
TotRsvEscro
428
WHOAPP SELECT SUM(Payments.Amt) AS TotPmtAmt, SUM(Payments.FeeEscrow) AS TotFeeEscrow, SUM(Payments.RsvEscrow) AS TotRsvEscrow
428
WHOAPP SELECT Transactions.BatchNo , Payments.Amt , Payments."ROWID" , Transactions."ROWID" FROM Payments , Transactions WHERE
396
WHOAPP INSERT INTO Payments (PaymentKey, AcctNo, Amt, ChargeAmt, Descr, FeeBasis, FeeEarned, FeeEscrow, FeeRate, FeeTaxAmt, Hol
244
WHOAPP SELECT Clients.Name , Clients.ClientNo , Invoices.InvNo , Invoices.ClientKey AS InvClientKey , Transactions.ClientKey
AS
244
SYS SELECT COUNT(*) AS RecCount , INVOICES."ROWID" , TRANSACTIONS."ROWID" , PROGRAMS."ROWID" FROM INVOICES , TRANSACTIONS
, 232
Using a substring from the above SQL the V$SQLTEXT view can be used to pull an entire listing of the code
The proper fix for non-bind variable usage is to re-write the application to use bind variables. This of course can be an expensive and time consuming process, but ultimately it
provides the best fix for the problem. However, what if you cant change the code? Oracle has provided the CURSOR_SHARING initialization variable that will automatically
replace the literals in your code with bind variables. The settings for CURSOR_SHARING are EXACT (the default), FORCE, and SIMILAR.
EXACT The statements have to match exactly to be reusable
FORCE Always replace literals
SIMILAR Perform literal peeking and replace when it makes sense
We usually suggest the use of the SIMILAR option for CURSOR_SHARING
12/5/12 Tuning_Methodology
4/31 www.pafumi.net/Tuning_Methodology.html
Improper Index Usage
You will be happy to know that starting with Oracle9i there is a new view that keeps the explain plans for all current SQL in the shared pool, this view, appropriately named
V$SQL_PLAN allows DBAs to determine exactly what statements are using full table scans and more importantly how often the particular SQL statements are being executed
col object_name format a28
col rows|blocks|pool a30
set pages 55
set linesize 140
set trims on
ttitle 'Full Table - Index Scans'
spool Full_Table-Index_Scans.txt
select sp.object_name,
(select executions from v$sqlarea sa
where sa.address = sp.address
and sa.hash_value =sp.hash_value) no_of_full_scans,
(select trim(lpad(nvl(trim(to_char(num_rows)),' '),10,' ')||' | '||lpad(nvl(trim(to_char(blocks)),' '),10,' ')||' |
'||buffer_pool)
from dba_tables where table_name = sp.object_name
and owner = sp.object_owner) "rows|blocks|pool",
(select sql_text from v$sqlarea sa
where sa.address = sp.address
and sa.hash_value =sp.hash_value) sqltext
from v$sql_plan sp
where operation IN ('TABLE ACCESS','INDEX')
and options in ('FULL','FULL SCAN','FAST FULL SCAN','SKIP SCAN','SAMPLE FAST FULL SCAN')
and object_owner IN ('XGUARD935')
and rownum < 60
order by 2 desc,3 desc;
spool off
set pages 20
ttitle off
Notice that I didnt limit myself to just full table scans, I also looked for expensive index scans as well. The Report shows:
Fri Aug 24 page 1
Full Table - Index Scans
OBJECT_NAME NO_OF_FULL_SCANS rows|blocks|pool
---------------------------- ---------------- ---------------------------------
SQLTEXT
--------------------------------------------------------------------------------------------------------------------------------------------
LOOKUP_WORKTYPE 956170 17 | 5 | DEFAULT
SELECT WORKTYPEID FROM LOOKUP_WORKTYPE WHERE WORKTYPECODE = :B1
ROUTINGNUMBER 294118 520 | 5 | DEFAULT
SELECT ROUTINGNUMBERID, ROUTINGNUMBER, BANKID, CENTERID FROM ROUTINGNUMBER WHERE BANKID = :B1
EXCHANGEITEMEXCEPTION 39421 72280 | 1566 | DEFAULT
SELECT COUNT(1) FROM EXCHANGEITEMQUERY EIQU, EXCHANGEITEMEXCEPTION EIEX WHERE :B1 =EIQU.EXCHANGEITEMID AND EIQU.EXCHANGEITEMQUERYID=EIEX.EXC
HANGEITEMQUERYID AND EIEX.REMOVED = 0
ANDOR 3454 20 | 5 | DEFAULT
SELECT ANDORID, EXCEPTIONID, ISAND, LEFTID, RIGHTID FROM ANDOR ORDER BY EXCEPTIONID, ANDORID
EXCEPTIONS 3377 97 | 60 | DEFAULT
SELECT E.EXCEPTIONID, EXCEPTIONNAME, DESCRIPTION, EXCEPTIONCODE, E.CENTERID, E.BANKID, E.CUSTOMERID, E.ACCOUNTID, DATASOURCEID, DATAFIELDID,
INEQUALITYID, CONSTRAINTDATASOURCEID, CONSTRAINTDATAVALUE, D.DEFINITIONID, DEFINITIONATTRIBUTEID, E.ACTIVESTATUSID, E.APPLICATIONID, ISUSER
DEFINED FROM EXCEPTIONS E, DEFINITION D WHERE E.APPLICATIONID = :B1 AND E.EXCEPTIONID = D.EXCEPTIONID (+) ORDER BY E.EXCEPTIONNAME, D.DEFINI
TIONID
X937USERRECORD 3317 0 | 1 | DEFAULT
INSERT INTO X937USERRECORD_ARCH SELECT * FROM X937USERRECORD WHERE OUTJOBID = :B1
UN_CENTERNAME 1679
SELECT CENTERID, CENTERNAME, ACTIVESTATUSID AS CENTERACTIVESTATUSID, COMMENTS AS CENTERCOMMENTS, ITEMSETTINGID AS CENTERITEMSETTINGID, CENTE
RCODE, EXPORTSTATUSID AS CENTEREXPORTSTATUSID, EXPORTTIME AS CENTEREXPORTTIME, GLACCOUNTNUMBER, NULL AS BANKID FROM CENTER ORDER BY CENTERNA
ME
MACHINE 1481 3 | 5 | DEFAULT
SELECT M.MACHINEID, MACHINENAME, IPADDRESS, S.SERVICEID, SERVICENAME, APPLICATIONID FROM SERVICE S, MACHINE M, PROCESS P WHERE S.SERVICEID =
P.SERVICEID AND M.MACHINEID = P.MACHINEID ORDER BY MACHINENAME, SERVICENAME
Notice instead of trying to capture the full SQL statement I just grab the HASH value.
I can then use the hash value to pull the interesting SQL statements using SQL similar to:
select sql_text
from v$sqltext
where hash_value=&hash
order by piece;
Once I see the SQL statement I use SQL similar to this to pull the table indexes:
set lines 132
col index_name form a30
col table_name form a30
col column_name format a30
select a.table_name,a.index_name,a.column_name,b.index_type
from dba_ind_columns a, dba_indexes b
where a.table_name =upper('&tab')
and a.table_name=b.table_name
and a.index_owner=b.owner
12/5/12 Tuning_Methodology
5/31 www.pafumi.net/Tuning_Methodology.html
and a.index_name=b.index_name
order by a.table_name,a.index_name,a.column_position;
set lines 80
Once I have both the SQL and the indexes for the full scanned table I can usually quickly come to a tuning decision if any additional indexes are needed or, if an existing index
should be used. In some cases there is an existing index that could be used of the SQL where rewritten. In that case I will usually suggest the SQL be rewritten. An example extract
from a SQL analysis of this type is shown here:
SQL> @get_it
Enter value for hash: 605795936
SQL_TEXT
----------------------------------------------------------------
DELETE FROM BOUNCE WHERE UPDATED_TS < SYSDATE - 21
SQL> @get_tab_ind
Enter value for tab: bounce
TABLE_NAME INDEX_NAME COLUMN_NAME INDEX_TYPE
------------ -------------------------- -------------- ----------
BOUNCE BOUNCE_MAILREPRECJOB_UNDX MAILING_ID NORMAL
BOUNCE BOUNCE_MAILREPRECJOB_UNDX RECIPIENT_ID NORMAL
BOUNCE BOUNCE_MAILREPRECJOB_UNDX JOB_ID NORMAL
BOUNCE BOUNCE_MAILREPRECJOB_UNDX REPORT_ID NORMAL
BOUNCE BOUNCE_PK MAILING_ID NORMAL
BOUNCE BOUNCE_PK RECIPIENT_ID NORMAL
BOUNCE BOUNCE_PK JOB_ID NORMAL
As you can see here there is no index on UPDATED_TS
SQL> @get_it
Enter value for hash: 3347592868
SQL_TEXT
----------------------------------------------------------------
SELECT VERSION_TS, CURRENT_MAJOR, CURRENT_MINOR, CURRENT_BUILD,
CURRENT_URL, MINIMUM_MAJOR, MINIMUM_MINOR, MINIMUM_BUILD, MINIMU
M_URL, INSTALL_RA_PATH, HELP_RA_PATH FROM CURRENT_CLIENT_VERSION
Here there is no WHERE clause, hence a FTS is required.
SQL> @get_it
Enter value for hash: 4278137387
SQL_TEXT
----------------------------------------------------------------
SELECT STATUS FROM DB_STATUS WHERE DB_NAME = 'ARCHIVE'
SQL> @get_tab_ind
Enter value for tab: db_status
Improper Memory Configuration
In this section we will discuss two major areas of memory, the database buffer area and the shared pool area. The PGA areas are discussed in a later section.
The Database Buffer Area
Anything that goes to users or gets into the database must go through the database buffers.
Gone are the days of a single buffer area (the default) now we have 2, 4, 8,, 16, 32 K buffer areas, keep and recycle buffer pools on top of the default area. Within these areas we
have the consistent read, current read, free, exclusive current, and many other types of blocks that are used in Oracles multi-block consistency model.
The V$BH view (and its parent the X$BH table) are the major tools used by the DBA to track block usage, however, you may find that the data in the V$BH view can be
misleading unless you also tie in block size data.
set pages 50
ttitle80 'All Buffers Status'
spool All_Buffers_Status.txt
select '32k '||status as status, count(*) as num
from v$bh
where file# in(select file_id
from dba_data_files
where tablespace_name in ( select tablespace_name
from dba_tablespaces
where block_size=32768))
group by '32k '||status
union
select '16k '||status as status, count(*) as num
from v$bh where file# in(select file_id
from dba_data_files
where tablespace_name in (select tablespace_name
from dba_tablespaces
where block_size=16384))
group by '16k '||status
union
select '8k '||status as status, count(*) as num
12/5/12 Tuning_Methodology
6/31 www.pafumi.net/Tuning_Methodology.html
from v$bh
where file# in( select file_id
from dba_data_files
where tablespace_name in (select tablespace_name
from dba_tablespaces
where block_size=8192))
group by '8k '||status
union
select '4k '||status as status, count(*) as num
from v$bh
where file# in(select file_id
from dba_data_files
where tablespace_name in ( select tablespace_name
from dba_tablespaces
where block_size=4096))
group by '4k '||status
union
select '2k '||status as status, count(*) as num
from v$bh
where file# in(select file_id
from dba_data_files
where tablespace_name in ( select tablespace_name
from dba_tablespaces
where block_size=2048))
group by '2k '||status
union
select status, count(*) as num
from v$bh
where status='free'
group by status
order by 1
/
spool off
ttitle off
As you can see, we will need to be SYS user to run it. An example report would be:
Date: 12/13/05 Page: 1
Time: 10:39 PM All Buffers Status PERFSTAT
whoville database
STATUS NUM
--------- ----------
32k cr 2930
32k xcur 29064
8k cr 1271
8k free 3
8k read 4
8k xcur 378747
free 10371
As you can see, while there are free buffers, only 3 of them are available to the 8k, default area and none are available to our 32K area. The free buffers are actually assigned to a
keep or recycle pool area (hence the null value for the blocksize) and are not available for normal usage.
So, if you see buffer busy waits, db block waits and the like and you run the above report and see no free buffers it is probably a good bet you need to increase the number of
available buffers for the area showing no free buffers. You should not immediately assume you need more buffers because of buffer busy waits as these can be caused by other
problems such as row lock waits, itl waits and other issues. Luckily Oracle10g has made it relatively simple to determine if we have these other types of waits:
-- Crosstab of object and statistic for an owner
--
col "Object" format a20
set numwidth 12
set lines 132
set pages 50
@title132 'Object Wait Statistics'
spool rep_out\&&db\obj_stat_xtab
select * from(
select DECODE(GROUPING(a.object_name), 1, 'All Objects',
a.object_name) AS "Object",
sum(case when a.statistic_name = 'ITL waits'
then a.value else null end) "ITL Waits",
sum(case when a.statistic_name = 'buffer busy waits'
then a.value else null end) "Buffer Busy Waits",
sum(case when a.statistic_name = 'row lock waits'
then a.value else null end) "Row Lock Waits",
sum(case when a.statistic_name = 'physical reads'
then a.value else null end) "Physical Reads",
sum(case when a.statistic_name = 'logical reads'
then a.value else null end) "Logical Reads"
from v$segment_statistics a
where a.owner like upper('&owner')
group by rollup(a.object_name)) b
where (b."ITL Waits">0 or b."Buffer Busy Waits">0)
/
spool off
clear columns
ttitle off
This is an object statistic cross tab report based on the V$SEGMENT_STATISTICS view. The cross tab report generates a listing showing the statistics of concern as headers
12/5/12 Tuning_Methodology
7/31 www.pafumi.net/Tuning_Methodology.html
across the page rather than listings going down the page and summarizes them by object. This allows us to easily compare total buffer busy waits to the number of ITL or row lock
waits. This ability to compare the ITL and row lock waits to buffer busy waits lets us see what objects may be experiencing contention for ITL lists, which may be experiencing
excessive locking activity and through comparisons, which are highly contended for without the row lock or ITL waits. An example of the output of the report, edited for length, is
shown here:
Date: 12/09/05 Page: 1
Time: 07:17 PM Object Wait Statistics PERFSTAT
whoville database
ITL Buffer Busy Row Lock Physical Logical
Object Waits Waits Waits Reads Reads
-------------- ----- ----------- -------- ---------- -----------
BILLING 0 63636 38267 1316055 410219712
BILLING_INDX1 1 16510 55 151085 21776800
...
DELIVER_INDX1 1963 36096 32962 1952600 60809744
DELIVER_INDX2 88 16250 9029 18839481 342857488
DELIVER_PK 2676 99748 29293 15256214 416206384
DELIVER_INDX3 2856 104765 31710 8505812 467240320
...
All Objects 12613 20348859 1253057 1139977207 20947864752
In the above report the BILLING_INDX1 index has a large number of buffer busy waits but we cant account for them from the ITL or Row lock waits, this indicates that the
index is being constantly read and the blocks then aged out of memory forcing waits as they are re-read for the next process. On the other hand, almost all of the buffer busy waits
for the DELIVER_INDX1 index can be attributed to ITL and Row Lock waits.
In situations where there are large numbers of ITL waits we need to consider the increase of the INITRANS setting for the table to remove this source of contention. If the
predominant wait is row lock waits then we need to determine if we are properly using locking and cursors in our application (for example, we may be over using the SELECT
FOR UPDATE type code.) If, on the other hand all the waits are un-accounted for buffer busy waits, then we need to consider increasing the amount of database block buffers we
have in our SGA.
As you can see, this object wait cross tab report can be a powerful addition to our tuning arsenal.
By knowing how our buffers are being used and seeing exactly what waits are causing our buffer wait indications we can quickly determine if we need to tune objects or add
buffers, making sizing buffer areas fairly easy.
But what about the Automatic Memory Manager in 10g? It is a powerful tool for DBAs with systems that have a predictable load profile, however if your system has rapid changes
in user and memory loads then AMM is playing catch up and may deliver poor performance as a result. In the case of memory it may be better to hand the system too much rather
than just enough, just in time (JIT).
As many companies have found when trying the JIT methodology in their manufacturing environment it only works if things are easily predictable.
The AMM is utilized in 10g by setting two parameters, the SGA_MAX_SIZE and the SGA_TARGET. The Oracle memory manager will size the various buffer areas as needed
within the range between base settings or SGA_TARGET and SGA_MAX_SIZE using the SGA_TARGET setting as an optimal and the SGA_MAX_SIZE as a maximum with
the manual settings used in some cases as a minimum size for the specific memory component.
Check Disks I/O
Disk stress will show up on the Oracle side as excessive read or write times. Filesystem stress is shown by calculating the IO timings as shown here:
em Purpose: Calculate IO timing values for datafiles
col name format a65
col READTIM/PHYRDS heading 'Avg|Read Time' format 9,999.999
col WRITETIM/PHYWRTS heading 'Avg|Write Time' format 9,999.999
set lines 132 pages 45
start title132 'IO Timing Analysis'
spool rep_out\&db\io_time
select f.FILE# ,d.name,PHYRDS,PHYWRTS,READTIM/PHYRDS,WRITETIM/PHYWRTS
from v$filestat f, v$datafile d
where f.file#=d.file#
and phyrds>0 and phywrts>0
union
select a.FILE# ,b.name,PHYRDS,PHYWRTS,READTIM/PHYRDS,WRITETIM/PHYWRTS
from v$tempstat a, v$tempfile b
where a.file#=b.file#
and phyrds>0 and phywrts>0
order by 5 desc;
spool off
ttitle off
clear col
An example of the output :
Date: 11/20/05 Page: 1
Time: 11:12 AM IO Timing Analysis PERFSTAT
whoraw database
FILE# NAME PHYRDS PHYWRTS READTIM/PHYRDS WRITETIM/PHYWRTS
----- -------------- ---------- ------- -------------- ----------------
13 /dev/raw/raw19 77751 102092 76.8958599 153.461829
33 /dev/raw/raw35 32948 52764 65.7045041 89.5749375
7 /dev/raw/raw90 245854 556242 57.0748615 76.1539869
54 /dev/raw/raw84 208916 207539 54.5494409 115.610912
40 /dev/raw/raw38 4743 27065 38.4469745 47.1722889
12/5/12 Tuning_Methodology
8/31 www.pafumi.net/Tuning_Methodology.html
15 /dev/raw/raw41 3850 7216 35.6272727 66.1534091
12 /dev/raw/raw4 323691 481471 32.5510193 100.201424
16 /dev/raw/raw50 10917 46483 31.9372538 74.5476626
18 /dev/raw/raw24 3684 4909 30.8045603 71.7942554
23 /dev/raw/raw58 63517 78160 29.8442779 84.4477866
5 /dev/raw/raw91 102783 94639 29.1871516 87.8867909
As you can see we are looking at an example report from a RAW configuration using single disks. Notice how both read and write times exceed even the rather large good practice
limits of 10-20 milliseconds for a disk read. However in my experience for reads you should not exceed 5 milliseconds and usually with modern buffered reads, 1-2 milliseconds.
Oracle is more tolerant for write delays since it uses a delayed write mechanism, so 10-20 milliseconds on writes will normally not cause significant Oracle waits, however, the
smaller you can get read and write times, the better!
For the money, I would suggest RAID0/1 or RAID1/0, that is, striped and mirrored. It provides nearly all of the dependability of RAID5 and gives much better write performance.
You will usually take at least a 20 percent write performance hit using RAID5. For read-only applications RAID5 is a good choice, but in high-transaction/high-performance
environments the write penalties may be too high.
Table 1 shows how Oracle suggests RAID should be used with Oracle database files.
RAID Type of
Raid
Control
File
Database
File
Redo Log
File
Archive
Log File
0 Striping Avoid OK Avoid Avoid
1 Shadowing Best OK Best Best
1+0 Striping and
Shadowing
OK Best Avoid Avoid
3 Striping with
static parity
OK OK Avoid Avoid
5 Striping with
rotating
parity
OK Best if
RAID0-1 not
available
Avoid Avoid
Table 1: RAID Recommendations (From Metalink NOTE: 45635.1)
Improper PGA setup
Oracle provides AWRRPT or statspack reports to track and show the number of sorts. Unfortunately hashes are not so easily tracked. Oracle tracks disk and memory sorts,
number of sort rows and other sort related statistics. Hashes on the other hand only can be tracked usually by the execution plans for cumulative values, and by various views for
live values. After 9i the parameter PGA_AGGREGATE_TARGET was provided to allow automated setting of the sort and hash areas. For currently active sorts or hashes the
following script can be used to watch the growth of temporary areas.
column now format a14
column operation format a15
column dt new_value td noprint
set feedback off
select to_char(sysdate,'ddmonyyyyhh24miss') dt from dual;
set lines 132 pages 55
@title132 'Sorts and Hashes'
spool rep_out\&&db\sorts_hashes&&td
select sid,work_area_size,expected_size,actual_mem_used,max_mem_used,tempseg_size,
to_char(sysdate,'ddmonyyyyhh24miss') now, operation_type operation
from v$sql_workarea_active;
spool off
clear columns
set lines 80 feedback on
ttitle off
Example output from this report.
Date: 01/04/06 Page: 1
Time: 01:27 PM Sorts and Hashes SYS
whoville database
Work Area Expected Actual Mem Max Mem Tempseg
SID Size Size Used Used Size Now Operation
---- --------- -------- ---------- ------- ------- --------------- ---------------
1176 6402048 6862848 0 0 04jan2006132711 GROUP BY (HASH)
582 114688 114688 114688 114688 04jan2006132711 GROUP BY (SORT)
568 5484544 5909504 333824 333824 04jan2006132711 GROUP BY (HASH)
1306 3469312 3581952 1223680 1223680 04jan2006132711 GROUP BY (HASH)
As you can see the whoville database had no hashes, at the time the report was run, going to disk. We can also look at the cumulative statistics in the v$sysstat view for cumulative
sort data.
Date: 12/09/05 Page: 1
Time: 03:36 PM Sorts Report PERFSTAT
sd3p database
Type Sort Number Sorts
-------------------- --------------
sorts (memory) 17,213,802
sorts (disk) 230
sorts (rows) 3,268,041,228
12/5/12 Tuning_Methodology
9/31 www.pafumi.net/Tuning_Methodology.html
Another key indicator that hashes are occurring are if there is excessive IO to the temporary tablespace yet there are few or no disk sorts.
The PGA_AGGREGATE_TARGET is the target total amount of space for all PGA memory areas. However, only 5% or a maximum of 200 megabytes can be assigned to any
single process. The limit for PGA_AGGREGATE_TARGET is 4 gigabytes (supposedly) however you can increase the setting above this point. The 200 megabyte limit is set by
the _pga_max_size undocumented parameter, this parameter can be reset but only under the guidance of Oracle support. But what size should PGA_AGGREGATE_TARGET
be set? The AWRRPT report in 10g provides a sort histogram which can help in this decision.
PGA Aggr Target Histogram DB/Inst: OLS/ols Snaps: 73-74
-> Optimal Executions are purely in-memory operations
Low High
Optimal Optimal Total Execs Optimal Execs 1-Pass Execs M-Pass Execs
------- ------- -------------- -------------- ------------ ------------
2K 4K 1,283,085 1,283,085 0 0
64K 128K 2,847 2,847 0 0
128K 256K 1,611 1,611 0 0
256K 512K 1,668 1,668 0 0
512K 1024K 91,166 91,166 0 0
1M 2M 690 690 0 0
2M 4M 174 164 10 0
4M 8M 18 12 6 0
-------------------------------------------------------------
In this case we are seeing 1-pass executions indicating disk sorts are occurring with the maximum size being in the 4m to 8m range. For an 8m sort area the
PGA_AGGREGATE_TARGET should be set at 320 megabytes (sorts get 0.5*(.05*PGA_AGGREGATE_TARGET)). For this system the setting was at 160 so 4 megabytes
was the maximum sort size, as you can see we were seeing 1-pass sorts in the 2-4m range as well even at 160m.
By monitoring the realtime or live hashes and sorts and looking at the sort histograms from the AWRRPT reports you can get a very good idea of the needed
PGA_AGGREGATE_TARGET setting. If you need larger than 200 megabyte sort areas you may need to get approval from Oracle support through the i-tar process to set the
_pga_max_size parameter to greater than 200 megabytes.
Modify init.ora Parameters
- For OLTP systems the parameter DB_FILE_MULTIBLOCK_READ_COUNT is set to values 8 - 16 while in decision support systems it is set to higher values. This
parameter determines the maximum number of database blocks read in one I/O operation during a full table scan. The setting of this parameter can reduce the number of I/O calls
required for a full table scan, thus improving performance.
- OPTIMIZER_INDEX_COST_ADJ
This initialization parameter is a percentage value representing a comparison between the relative cost of physical I/O requests for indexed access and full table-scans. The default
value of 100 indicates to the cost-based optimizer that indexed access is 100% as costly (i.e., equally costly) as FULL table scan access. Usually it's around 15 for an OLTP
system and 50 for DW systems. The smaller the value, the cheaper the cost of index access. I usually start with 20. Query to suggest its value:
col c1 heading 'Average Waits for|Full Scan Read I/O' format 9999.999
col c2 heading 'Average Waits for|Index Read I/O' format 9999.999
col c3 heading 'Percent of| I/O Waits|for Full Scans' format 9.99
col c4 heading 'Percent of| I/O Waits|for Index Scans' format 9.99
col c5 heading 'Starting|Value|for|optimizer|index|cost|adj' format 999
select a.average_wait c1,
b.average_wait c2,
a.total_waits /(a.total_waits + b.total_waits) c3,
b.total_waits /(a.total_waits + b.total_waits) c4,
(b.average_wait / a.average_wait)*100 c5
from v$system_event a,
v$system_event b
where a.event = 'db file scattered read'
and b.event = 'db file sequential read';
Here is the listing from this script:
Starting
Value
for
optimizer
Percent of Percent of index
Average Waits for Average Waits for I/O Waits I/O Waits cost
Full Scan Read I/O Index Read I/O for Full Scans for Index Scans adj
------------------ ----------------- -------------- --------------- ---------
1.473 .289 .02 .98 20
As you can see, the suggested starting value for optimizer_index_cost_adj may be too high because 98% of data waits are on index (sequential) block access. How we can
"weight" this starting value for optimizer_index_cost_adj to reflect the reality that this system has only 2% waits on full-table scan reads (a typical OLTP system with few full-table
scans)? As a practical matter, we never want an automated value for optimizer_index_cost_adj to be less and 1, nor more than 100.
Another one:
col a1 head "avg. wait time|(db file sequential read)"
col a2 head "avg. wait time|(db file scattered read)"
col a3 head "new setting for|optimizer_index_cost_adj"
select a.average_wait a1, b.average_wait a2,
round( ((a.average_wait/b.average_wait)*100) ) a3
from (select d.kslednam EVENT, s.kslestim / (10000 * s.ksleswts) AVERAGE_WAIT
from x$kslei s, x$ksled d
where s.ksleswts != 0 and s.indx = d.indx) a,
(select d.kslednam EVENT, s.kslestim / (10000 * s.ksleswts) AVERAGE_WAIT
from x$kslei s, x$ksled d
where s.ksleswts != 0 and s.indx = d.indx) b
12/5/12 Tuning_Methodology
10/31 www.pafumi.net/Tuning_Methodology.html
where a.event = 'db file sequential read'
and b.event = 'db file scattered read';
- OPTIMIZER_INDEX_CACHING
This initialization parameter represents a percentage value, ranging between the values of 0 and 99. The default value of 0 indicates to the CBO that 0% of database blocks
accessed using indexed access can be expected to be found in the Buffer Cache of the Oracle SGA. This implies that all index accesses will require a physical read from the I/O
subsystem for every logical read from the Buffer Cache, also known as a 0% hit ratio on the Buffer Cache. This parameter applies only to the CBOs calculations of accesses for
blocks in an index, not for the blocks in the table related to the index. It should be set to 90.
- Set the OPTIMIZER_FEATURES_ENABLE = 9.2.0
- OPTIMIZER_MODE = first_rows (for OLTP systems). This parameter returns the rows faster.
SQL Code Tuning
If the SQL hash value (SHV) corresponding to the SQL statement is not found in the library cache during the soft parse, the server process must perform a hard parse on the
statement. During this operation, the execution plan for the statement must be determined and the result must be stored in the library cache. This is a computationally expensive step.
The hard parse is usually accompained by latch contention on the shared pool and library cache latches. In OLTP the aim is to parse once, execute many times. Ideally soft parse
should be > 95%, if falls significantly lower than 80% then we need to investigate.
--The following query is useful for detecting programs that are performing excessive hard parses.
spool excessive_hard_parses.txt
SELECT /*+ RULE */ substr(s.program,1,20) program, COUNT(*) users,
SUM(t.value) parses, SUM(t.value)/COUNT(*) parses_per_session,
SUM(t.value)/(SUM(sysdate-s.logon_time)*24) parses_per_hour
FROM v$session s, v$sesstat t
WHERE t.statistic# = 153
AND s.sid = t.sid
GROUP BY s.program HAVING SUM(t.value)/COUNT(*) > 2.0
ORDER BY parses_per_hour DESC;
spool off
The query produces several parse metrics aggregated by program name. The parses column indicates the total hard parse count. parses_per_session is the average number of
parses for all sessions running the program, and parses_per_hour is the average number of parses per hour for all sessions running the program. Search for high numbers in the
parses_per_hour column. The term high is relative. For OLTP programs, numbers below 10 are reasonable. For batch programs, higher values are acceptable. Any programs with
values higher than 10 should be investigated further.
For programs that are suspect, query the library cache to identify the SQL statements being executed using the following query. Run this query as many times as are required to get
a reasonable sample.
SELECT /*+ RULE */ t.sql_text
FROM v$sql t, v$session s
WHERE s.sql_address = t.address
AND s.sql_hash_value = t.hash_value
AND s.sid = &SID;
--Identifying unnecessary parse calls at system level
spool unnecessary_parse_calls_system_level.txt
select parse_calls, executions, substr(sql_text, 1, 300)
from v$sqlarea
where command_type in (2, 3, 6, 7)
order by 3;
spool off
Check for statements with a lot of executions. It is bad to have the PARSE_CALLS value in the above statement close to the EXECUTIONS value. The previous query will fire
only for DML statements (to check on other types of statements use the appropriate command type number). Also ignore Recursive calls (dictionary access), as it is internal to
Oracle
--Identifying unnecessary parse calls at session level
spool unnecessary_parse_calls_sess_level.txt
select b.sid, substr(c.username,1,12) username,
substr(c.program,1,15) program, substr(a.name,1,20) name, b.value
from v$sesstat b, v$statname a , v$session c
where a.name in ('parse count (hard)', 'execute count')
and b.statistic# = a.statistic#
and b.sid = c.sid
and c.username not in ('SYS','SYSTEM')
order by sid;
spool off
Identify the sessions involved with a lot of re-parsing (VALUE column). Query these sessions from V$SESSION and then locate the program that is being executed, resulting in so
much parsing.
select a.parse_calls, a.executions, substr(a.sql_text, 1, 100)
from v$sqlarea a, v$session b
where b.schema# = a.parsing_schema_id
and b.sid = &sid
order by 1 desc;
As stated earlier, excessive parsing will result in higher than optimal CPU consumption.
However, the greater impact is likely to be contention for resources in the shared pool. If many small statements are hard parsed, shared pool fragmentation is likely to result. As the
12/5/12 Tuning_Methodology
11/31 www.pafumi.net/Tuning_Methodology.html
shared pool becomes more fragmented, the amount of time required to complete a hard parse increases. As the process of executing many unique statements continues, resource
contention worsens. The critical resources will likely be memory in the library cache and the various latches associated with the shared pool. There are several straightforward
methods to detect contention. The following query shows a list events on which sessions are waiting to complete before continuing. Since v$session_wait contains one row for each
session, the query will return the total number of sessions waiting for each event. The view contains real-time data so it should be run repeatedly to detect possible problems.
SELECT /*+ RULE */ SUBSTR(event,1,30) event, COUNT(*)
FROM v$session_wait
WHERE wait_time = 0
GROUP BY SUBSTR (event,1,30), state;
If the latch free event appears continuously, then there is latch resource contention. The following query can be used to determine which latches have contention. Since
v$latchholder contains one row for each session, the query will return the total number of sessions waiting for each latch. The view contains real-time data so it should be run
repeatedly.
SELECT /*+ RULE */ name, COUNT(*)
FROM v$latchholder
GROUP BY name;
If library cache or shared pool latches appear continuously with any frequency, then there is contention.
Latch Contention Analysis
When an Oracle session needs to place a new SQL statement in the shared pool, it has to acquire a latch, or internal lock. Under some circumstances, contention for these latches
can result in poor performance. This does not happen frequently but it is worth checking. Set the db_block_lru_latches to a higher number if you are experiencing a high number of
misses or sleeps.
spool latch_content_analysis.txt
clear breaks
clear computes
clear columns
column name heading "Latch Type" format a25
column pct_miss heading "Misses/Gets (%)" format 999.99999
column pct_immed heading "Immediate Misses/Gets (%)" format 999.99999
ttitle 'Latch Contention Analysis Report' skip
select n.name, misses*100/(gets+1) pct_miss,
immediate_misses*100/(immediate_gets+1) pct_immed
from v$latchname n,v$latch l
where n.latch# = l.latch#
and n.name in('%cache bugffer%','%protect%');
spool off
The Quick Fix
Correcting the offending software may require days or weeks However, if performance is poor, there are some things that can be done to improve performance until the source of
the problem can be corrected.
1. Increase the size of the shared pool. For minor contention problems, an increase of 20% should be suitable. For more severe problems, consider incremental increases of 50%
until performance improves. If the host system has limited memory and the buffer cache hit rate is above 90%, consider reducing the size of the buffer cache to increase the size of
the shared pool. A buffer cache hit ratio of 80-85% with reduced latch contention will likely produce better database performance than a higher buffer cache hit ratio with high latch
contention.
2. Consider reducing the value of the optimizer_max_permutations parameter if the cost-based optimizer is being used and the database is using Oracle Enterprise Server Version
8.0 or higher. This parameter controls the maximum number of execution plans that the optimizer will develop to identify the one with the lowest cost. The default value is 80,000
but values of 100 to 1,000 usually produce identical execution plans to those when a higher value is used. Since hard parses account for a significant amount of CPU consumed on
short-running SQL statements, one of the artifacts of high hard parse counts is high CPU consumption. Reducing the value of optimizer_max_permutations will help mitigate the
problem.
3. Flush the shared pool periodically. This will reduce memory fragmentation in the shared pool, which will reduce the elapsed time of the hard parse. The frequency
depends upon the size of the shared pool and the severity of the problem. For mild problems, consider flushing twice each day. For severe problems, it may be
necessary to flush the shared pool every few hours.
4. Pin frequently used PL/SQL functions and packages in the shared pool. When a program calls a method within a package, the entire package must be loaded into the shared
pool. If the shared pool is highly fragmented and there is considerable latch contention, a significant amount of clock time may be required to load large packages into memory.
Pinning packages and functions will improve the response time when they are accessed.
spool frequently_used_reloaded_objects.txt
--To view a list of frequently used and re-loaded objects
set linesize 200
select loads, executions, substr(owner, 1, 15) "Owner",
substr(namespace, 1, 20) "Type", substr(name, 1, 100) "Text"
from v$db_object_cache
where owner not in ('SYS','SYSTEM','PERFSTAT','WMSYS','XDB')
order by loads desc;
spool off
--To pin a package in memory
exec dbms_shared_pool.keep('standard', 'p');
spool pinned_objects.txt
--To view a list of pinned objects
select substr(owner, 1, 15) "Owner",
substr(namespace, 1, 20) "Type",
substr(name, 1, 42) "Text"
from v$db_object_cache
where kept = 'YES'
and owner not in ('SYS','SYSTEM')
12/5/12 Tuning_Methodology
12/31 www.pafumi.net/Tuning_Methodology.html
order by 1,3;
spool off
It is straightforward to verify that an application is using bind variables using the Oracle trace facility and tkprof, the application profiler.
Tkprof produces a list of all SQL statements executed along with their execution plans and some performance statistics. These metrics are aggregated for each unique SQL
statement. Verify that excess parsing is not occurring. Below is an example of a query that was parsed once for each execution. Notice that in the count
column, the number of parses is equal to the number of executions. The Parse row indicates the number of hard parses that occurred for the statement. In the ideal case, the
statement would be parsed once and executed many times. call count cpu elapsed disk query current rows
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 27 0.02 0.00 0 0 0 0
Execute 27 0.00 0.00 0 0 0 0
Fetch 108 0.03 0.00 0 189 0 81
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 162 0.05 0.00 2 189 0 81
Once the application has been corrected, the size of the shared pool should be reevaluated to determine if it could be reduced to its original size. If shared pool flushes were
employed as a temporary remedy, try to reduce the number of flushes to perhaps once per day. Excessive shared pool flushes will also result in performance degradation.
Collect Schema and DB Statistics
Is CRITICAL for Oracle to have accurate statistics. More information HERE. Examples:
--For one Table and all its indexes
BEGIN dbms_stats.gather_table_stats
(ownname => 'LABTEST',
tabname => 'DIEGO',
partname => null,
estimate_percent => 10, --or DBMS_STATS.AUTO_SAMPLE_SIZE
degree => 3 ,
cascade => true); END;
--For a Full Schema
BEGIN dbms_stats.gather_schema_stats(ownname => 'LABTEST',
estimate_percent => 10,
granularity => 'ALL',
method_opt => 'FOR ALL COLUMNS', --or method_opt=>'FOR ALL COLUMNS SIZE AUTO'
degree => DBMS_STATS.DEFAULT_DEGREE,
options => 'GATHER AUTO',
cascade => TRUE ); END;
Redo Logs Switches
Check Alert Log File to see frequency of Redo Log Swtiches. If you see errors there or that the switches are too often (ideally once every 30 minutes), then :
1- Increase Redo Log Files
2- Add more groups
3- Modify LOG_CHECKPOINT_TIMEOUT=0 and duplicate the value on LOG_CHECKPOINT_INTERVAL
4- Modify archive_lag_target = 1800, so it will force the generation of archive log files to 30 minutes.
spool redo_log_switches.txt
set pages 100
column d1 form a20 heading "Date"
column sw_cnt form 99999 heading 'Number|of|Switches'
column Mb form 999,999 heading "Redo Size"
column redoMbytes form 999,999,9999 heading "Redo Log File Size (Mb)"
break on report
compute sum of sw_cnt on report
compute sum of Mb on report
var redoMbytes number;
begin
select max(bytes)/1024/1024 into :redoMbytes from v$log;
end;
/
print redoMbytes
select trunc(first_time) d1
, count(*) sw_cnt
, count(*) * :redoMbytes Mb
from v$log_history
group by trunc(first_time);
spool off
Check for Large Table Full Scans
spool large_table_scans.txt
--Find Large Table Scans
12/5/12 Tuning_Methodology
13/31 www.pafumi.net/Tuning_Methodology.html
SELECT substr(table_owner,1,10) Owner,
substr(table_name,1,15) Table_Name,
size_kb, statement_count, reference_count,
substr(executions,1,4) Exec,
substr(executions * reference_count,1,8) tot_scans
FROM (SELECT a.object_owner table_owner,
a.object_name table_name,
b.segment_type table_type,
b.bytes / 1024 size_kb,
SUM(c.executions ) executions,
COUNT( DISTINCT a.hash_value ) statement_count,
COUNT( * ) reference_count
FROM sys.v_$sql_plan a, sys.dba_segments b, sys.v_$sql c
WHERE a.object_owner (+) = b.owner
AND a.object_name (+) = b.segment_name
AND b.segment_type IN ('TABLE', 'TABLE PARTITION')
AND a.operation LIKE '%TABLE%'
AND a.options = 'FULL'
AND a.hash_value = c.hash_value
AND b.bytes / 1024 > 1024
AND a.object_owner != 'SYS'
GROUP BY a.object_owner, a.object_name, a.operation, b.bytes/1024, b.segment_type
ORDER BY 4 DESC, 1, 2 );
spool off
spool recent_full_table_scans.txt
-- Recent full table scan
-- Should be run as SYS user
set verify off
col object_name form a30
col o.owner form a15
PROMPT Column flag in x$bh table is set to value 0x80000, when
PROMPT block was read by a sequential scan.
SELECT o.object_name,o.object_type,o.owner, count(*)
FROM dba_objects o,x$bh x
WHERE x.obj=o.object_id
AND o.object_type='TABLE'
AND standard.bitand(x.flag,524288)>0
AND o.owner<>'SYS'
having count(*) > 2
group by o.object_name,o.object_type,o.owner
order by 4 desc;
spool off
spool unused_indexes.txt
-- Do these tables contain indexes ??
-- This query creates a mini "unused indexes" report that you can use to ensure that
-- any large tables that are being scanned on your system have the proper indexing scheme.
SELECT DISTINCT substr(a.object_owner,1,10) table_owner,
substr(a.object_name,1,15) table_name,
b.bytes / 1024 size_kb,
d.index_name
FROM sys.v_$sql_plan a, sys.dba_segments b, sys.dba_indexes d
WHERE a.object_owner (+) = b.owner
AND a.object_name (+) = b.segment_name
AND b.segment_type IN ('TABLE', 'TABLE PARTITION')
AND a.operation LIKE '%TABLE%'
AND a.options = 'FULL'
AND b.bytes / 1024 > 1024
AND b.segment_name = d.table_name
AND b.owner = d.table_owner
AND b.owner != 'SYS'
ORDER BY 1, 2;
spool off
spool physical_IO.txt
--How much physical I/O, etc., a large table scan causes on a system
--It displays I/O and some wait metrics that can give a DBA more insight into what Oracle is doing behind the scenes to access the object.
--Solution: Create indexes, force use with hints
SELECT DISTINCT substr(a.object_owner,1,8) table_owner,
substr(a.object_name,1,15) table_name,
b.bytes / 1024 size_kb,
substr(c.tablespace_name,1,10) Tablespace,
substr(c.statistic_name,1,27) Statistic_Name ,
substr(c.value,1,5) Value
FROM sys.v_$sql_plan a,
sys.dba_segments b,
sys.v_$segment_statistics c
WHERE a.object_owner (+) = b.owner
AND a.object_name (+) = b.segment_name
AND b.segment_type IN ('TABLE', 'TABLE PARTITION')
AND a.operation LIKE '%TABLE%'
AND a.options = 'FULL'
AND b.bytes / 1024 > 1024
AND b.owner = c.owner
AND b.owner != 'SYS'
AND b.segment_name = c.object_name
ORDER BY 1, 2;
spool off
Solution
Create indexes, force use with hints
12/5/12 Tuning_Methodology
14/31 www.pafumi.net/Tuning_Methodology.html
Check for Small Table and Index Full-Scans
spool Object_Access.txt
-- You detect this by watching db file scattered reads' on top 5 wait events
set heading on
set feedback on
set linesize 120
ttitle 'Full Table Scans and Counts| |The "K" indicates that the table is in the KEEP Pool.'
select substr(p.owner,1,10) owner, substr(p.name,1,30) name, t.num_rows,
-- ltrim(t.cache) ch,
decode(t.buffer_pool,'KEEP','Y','DEFAULT','N') K,
s.blocks blocks, sum(a.executions) nbr_FTS
from dba_tables t, dba_segments s, v$sqlarea a,
(select distinct address, object_owner owner, object_name name
from v$sql_plan
where operation = 'TABLE ACCESS'
and options = 'FULL') p
where a.address = p.address
and t.owner = s.owner
and t.table_name = s.segment_name
and t.table_name = p.name
and t.owner = p.owner
and t.owner not in ('SYS','SYSTEM')
having sum(a.executions) > 1
group by p.owner, p.name, t.num_rows, t.cache, t.buffer_pool, s.blocks
order by sum(a.executions) desc;
column nbr_scans format 999,999,999
column num_rows format 999,999,999
column tbl_blocks format 999,999,999
column owner format a15;
column table_name format a25;
column index_name format a25;
ttitle 'Index full scans and counts'
select p.owner, d.table_name, p.name index_name,
seg.blocks tbl_blocks, sum(s.executions) nbr_scans
from dba_segments seg, v$sqlarea s, dba_indexes d,
(select distinct address, object_owner owner, object_name name
from v$sql_plan
where operation = 'INDEX'
and options = 'FULL SCAN') p
where d.index_name = p.name
and s.address = p.address
and d.table_name = seg.segment_name
and seg.owner = p.owner
and seg.owner not in ('SYS','SYSTEM')
having sum(s.executions) > 9
group by p.owner, d.table_name, p.name, seg.blocks
order by sum(s.executions) desc;
ttitle 'Index range scans and counts'
select p.owner, d.table_name, p.name index_name,
seg.blocks tbl_blocks, sum(s.executions) nbr_scans
from dba_segments seg, v$sqlarea s, dba_indexes d,
(select distinct address, object_owner owner, object_name name
from v$sql_plan
where operation = 'INDEX'
and options = 'RANGE SCAN') p
where d.index_name = p.name
and s.address = p.address
and d.table_name = seg.segment_name
and seg.owner = p.owner
and seg.owner not in ('SYS','SYSTEM')
having sum(s.executions) > 9
group by p.owner, d.table_name, p.name, seg.blocks
order by sum(s.executions) desc;
ttitle 'Index unique scans and counts'
select p.owner, d.table_name, p.name index_name, sum(s.executions) nbr_scans
from v$sqlarea s, dba_indexes d,
(select distinct address, object_owner owner, object_name name
from v$sql_plan
where operation = 'INDEX'
and options = 'UNIQUE SCAN') p
where d.index_name = p.name
and s.address = p.address
having sum(s.executions) > 9
group by p.owner, d.table_name, p.name
order by sum(s.executions) desc;
spool off
Solution
Check if is it OK those access. Pin those tables and indexes.
Example: alter table/index . Storage (buffer_pool keep);
Check for many indexes on data buffer cache
Query the tables $BH and user_indexes
spool indexused_on_data_buffer_cache.txt
--Solution: Adjust parameters OPTIMIZER_INDEX_COST_ADJ=15 AND OPTIMIZER_INDEX_CACHING=85 with the % of indexes on data buffer cache
/* Recently used indexes */
/* Should be run as SYS user */
set serverout on size 1000000
set verify off
column owner format a20 trunc
column segment_name format a30 trunc
select distinct b.owner, b.segment_name
from x$bh a, dba_extents b
where b.file_id=a.dbarfil
and a.dbablk between b.block_id
and b.block_id+blocks-1
and segment_type='INDEX'
and b.owner = upper('&OWNER')
/
spool off
Solution
Adjust parameters OPTIMIZER_INDEX_COST_ADJ=15 AND OPTIMIZER_INDEX_CACHING=85 with the % of indexes on data buffer cache
Check for skewed Indexes (Unbalanced)
Another performance issue could be that your indexes are skewed, this happens when you have a lot of DML activity in your tables. In order to check that, perform the following
steps:
1- Analyze your indexes with compute (or estimate if the you have more than 100,000 rows in your table)
analyze index xxxxxxx compute statistics;
2- Run the following query to see the BLEVEL of the index and if you need to rebuid them. If the blevel is higher than 3, you should rebuild it.
spool Unbalanced_Indexes.txt
--If the blevel is higher than 3, you should rebuild it
select substr(table_name,1,15) "Table Name",
substr(index_name,1,20) "Index Name", blevel,
decode(blevel,0,'OK BLEVEL',1,'OK BLEVEL',
2,'OK BLEVEL',3,'OK BLEVEL', null,'?????????','***BLEVEL HIGH****') OK
from dba_indexes
where owner=UPPER('&OWNER')
order by 1,2;
spool off
3- Gather more index statistics using the VALIDATE STRUCTURE option of the ANALYZE command to populate the INDEX_STATS virtual table.
analyze index xxxxxxxxx validate structure;
4-The INDEX_STATS view will hold information for one index at a time: it will never contain more than one row. Therefore you need to query this view before you analyze next
index
select name "INDEXNAME", HEIGHT,
DEL_LF_ROWS*100/decode(LF_ROWS, 0, 1, LF_ROWS) PCT_DELETED,
(LF_ROWS-DISTINCT_KEYS)*100/ decode(LF_ROWS,0,1,LF_ROWS) DISTINCTIVENESS
from index_stats;
The PCT_DELETED column shows what percent of leaf entries (index entries) have been deleted and remain unfilled. The more deleted entries exist on an index, the more
unbalanced the index becomes. If the PCT_DELETED is 20% or higher, the index is candidate for rebuilding. If you can afford to rebuild indexes more frequently, then do so if the
value is higher than 10%. Leaving indexes with high PCT_DELETED without rebuild might cause excessive redo allocation on some systems.
The DISTINCTIVENESS column shows how often a value for the column(s) of the index is repeated on average. For example, if a table has 10000 records and 9000 distinct
SSN values, the formula would result in (10000-9000) x 100 / 10000 = 10. This shows a good distribution of values. If, however, the table has 10000 records and only 2 distinct
SSN values, the formula would result in (10000-2) x 100 /10000 = 99.98. This shows that there are very few distinct values as a percentage of total records in the column. Such
columns are not candidates for a rebuild but good candidates for bitmapped indexes.
The following PL/SQL code will analyze your indexes and then create a report of the indexes to rebuild. Run it as the owner of the indexes.
declare
pMaxHeight integer := 3;
pMaxLeafsDeleted integer := 20;
cursor csrIndexStats is
select name, height, lf_rows as leafRows,
del_lf_rows as leafRowsDeleted
from index_stats;
vIndexStats csrIndexStats%rowtype;
cursor csrGlobalIndexes is
select index_name, tablespace_name
from user_indexes
where partitioned = 'NO';
cursor csrLocalIndexes is
select index_name, partition_name, tablespace_name
from user_ind_partitions
where status = 'USABLE';
vCount integer := 0;
begin
dbms_output.enable(100000);
/* Working with Global/Normal indexes */
for vIndexRec in csrGlobalIndexes
loop
execute immediate 'analyze index ' || vIndexRec.index_name ||' validate structure';
12/5/12 Tuning_Methodology
16/31 www.pafumi.net/Tuning_Methodology.html
open csrIndexStats;
fetch csrIndexStats into vIndexStats;
if csrIndexStats%FOUND then
if (vIndexStats.height > pMaxHeight)
or (vIndexStats.leafRows > 0
and vIndexStats.leafRowsDeleted > 0
and (vIndexStats.leafRowsDeleted * 100 / vIndexStats.leafRows) > pMaxLeafsDeleted) then
vCount := vCount + 1;
dbms_output.put_line('Rebuilding index ' || vIndexRec.index_name || '...');
execute immediate 'alter index ' || vIndexRec.index_name ||
' rebuild online parallel nologging compute statistics' ||
' tablespace ' || vIndexRec.tablespace_name;
end if;
end if;
close csrIndexStats;
end loop;
dbms_output.put_line('Global indexes rebuilt: ' || to_char(vCount));
vCount := 0;
/* Local indexes */
for vIndexRec in csrLocalIndexes
loop
execute immediate 'analyze index ' || vIndexRec.index_name ||
' partition (' || vIndexRec.partition_name ||
') validate structure';
open csrIndexStats;
fetch csrIndexStats into vIndexStats;
if csrIndexStats%FOUND then
if (vIndexStats.height > pMaxHeight)
or (vIndexStats.leafRows > 0
and vIndexStats.leafRowsDeleted > 0
and (vIndexStats.leafRowsDeleted * 100 / vIndexStats.leafRows) > pMaxLeafsDeleted) then
vCount := vCount + 1;
dbms_output.put_line('Rebuilding index ' || vIndexRec.index_name || '...');
execute immediate 'alter index ' || vIndexRec.index_name ||
' rebuild partition ' || vIndexRec.partition_name ||
' online parallel nologging estimate statistics' ||
' tablespace ' || vIndexRec.tablespace_name;
end if;
end if;
close csrIndexStats;
end loop;
dbms_output.put_line('Local indexes rebuilt: ' || to_char(vCount));
end RebuildUnbalancedIndexes;
/
Fragmentation on DB Objects
Another performance problem may be the DB fragmentation. Run the following to detect:
REM Segments that are fragmented and level of fragmentation
REM It counts number of extents
set heading on
set termout on
set pagesize 66
set line 132
select substr(de.owner,1,8) "Owner",
substr(de.segment_type,1,8) "Seg_Type",
substr(de.segment_name,1,25) "Segment_Name",
substr(de.tablespace_name,1,15) "Tblspace_Name",
count(*) "Frag NEED",
substr(df.name,1,40) "DataFile_Name"
from sys.dba_extents de, v$datafile df
where de.owner not in ('SYS','SYSTEM')
and de.file_id = df.file#
and de.segment_type = 'TABLE'
group by de.owner, de.segment_name, de.segment_type, de.tablespace_name, df.name
having count(*) > 4
order by count(*) asc;
Tuning buffer cache
Step 1.Identify how frequently data blocks are accessed from the buffer cache (a. k. a Block Buffer Hit Ratio).
Oracle database maintains dynamic performance view V$BUFFER_POOL_STATISTICS with overall buffer usage statistics. This view maintains the following counts every time a data block
is accessed either from the block buffers or from the disk:
NAME Name of the buffer pool
PHYSICAL_READS Number of physical reads
DB_BLOCK_GETS Number of reads for INSERT, UPDATE and DELETE
CONSISTENT_GETS Number of reads for SELECT
DB_BLOCK_GETS + CONSISTENT_GETS = Total Number of reads
Based on above statistics we can calculate the percentage of data blocks being accessed from the memory to that of the disk (block buffer hit ratio). The following SQL statement will
return the block buffer hit ratio:
SELECT NAME, 100 round ((PHYSICAL_READS / (DB_BLOCK_GETS + CONSISTENT_GETS))*100,2) HitRatio
FROM V$BUFFER_POOL_STATISTICS;
NAME HITRATIO
12/5/12 Tuning_Methodology
17/31 www.pafumi.net/Tuning_Methodology.html
-------------------- ----------
DEFAULT 96.82
Before measuring the database buffer hit ratio, it is very important to check that the database is running in a steady state with normal workload and no unusual activity has taken place. For
example, when you run a SQL statement just after database startup, no data blocks have been cached in the block buffers. At this point, Oracle reads the data blocks from the disk and
will cache the blocks in the memory. If you run the same SQL statement again, then most likely the data blocks will still be present in the cache, and Oracle will not have to perform disk
IO. If you run the same SQL statement multiple times you will get a higher buffer hit ratio. On the other hand, if you either run SQL statements that rarely query the same data, or run a
select on a very large table, the data block may not be in the buffer cache and Oracle will have to perform disk IO, thereby lowering the buffer hit ratio.
A hit ratio of 95% or greater is considered to be a good hit ratio for OLTP systems. The hit ratio for DSS (Decision Support System) may vary depending on the database load. A lower hit
ratio means Oracle is performing more disk IO on the server. In such a situation, you can increase the size of database block buffers to increase the database performance. You may have
to increase the physical memory on the server if the server starts swapping after increasing block buffers.
Step 2: Identify frequently used and rarely used data blocks. Cache frequently used blocks and discard rarely used blocks.
If you have a low buffer hit ratio and you cannot increase the size of the database block buffers, you can still gain some performance advantage by tuning the block buffers and efficiently
caching the data block that will provide maximum benefits. Ideally, we should cache data blocks that are either frequently used in SQL statements, or data blocks used by performance
sensitive SQL statements (A SQL statement whose performance is critical to the system performance). An ad-hoc query that scans a large table can significantly degrade overall database
performance. A SQL on a large table may flush out frequently used data blocks from the buffer cache to store data blocks from the large table. During the peak time, ad-hoc queries that
select data from large tables or from tables that are rarely used should be avoided. If we cannot avoid such queries, we can limit the impact on the buffer cache by using RECYCLE buffer
pool.
A DBA can create multiple buffer pools in the SGA to store data blocks efficiently. For example, we can use RECYCLE pool to cache data blocks that are rarely used in the application.
Typically, this will be a small area in the SGA to store data blocks for current SQL statement / transaction that we do not intend to hold in the memory after the transaction is completed.
Similarly, we can use KEEP pool to cache data blocks that are frequently used by the application. Typically, this will be big enough to store data blocks that we want to always keep in
memory. By storing data blocks in KEEP and RECYCLE pools you can store frequently used data blocks separately from the rarely used data blocks, and control which data blocks are
flushed from the buffer cache. Using RECYCLE pool, we can also prevent a large table scan from flushing frequently used data blocks. You can create the RECYCLE and KEEP pools by
specifying the following init.ora parameters:
DB_KEEP_CACHE_SIZE = <size of KEEP pool>
DB_RECYCLE_CACHE_SIZE = < size of RECYCLE pool>
When you use the above parameters, the total memory allocated to the block buffers is the sum of DB_KEEP_CACHE_SIZE, DB_RECYCLE_CACHE_SIZE, and DB_CACHE_SIZE.
Step 3: Assign tables to KEEP / RECYCLE pool. Identify buffer hit ratio for KEEP, RECYCLE, and DEFAULT pool. Adjust the initialization parameters for optimum
performance.
By default, data blocks are cached in the DEFAULT pool. The DBA must configure the table to use the KEEP or the RECYCLE pool by specifying BUFFER_POOL keyword in the
CREATE TABLE or the ALTER TABLE statement. For example, you can assign a table to the recycle pool by using the following ALTER TABLE SQL statement.
ALTER TABLE <TABLE NAME> STORAGE (BUFFER_POOL RECYCLE)
The DBA can take help from application designers in identifying tables that should use KEEP or RECYCLE pool. You can also query X$BH to examine the current block buffer usage by
database objects (You must log in as SYS to query X$BH).
spool tables_to_RECYCLE_Pool.txt
--The following query returns a list of tables that are rarely used and can be assigned to the RECYCLE pool.
Col owner format a14
Col object_name format a36
Col object_type format a15
SELECT o.owner, object_name, object_type, COUNT(1) buffers
FROM SYS.x$bh, dba_objects o
WHERE (tch = 1 OR (tch = 0 AND lru_flag < 8))
AND obj = o. object_id
AND o.owner upper('&OWNER')
GROUP BY o.owner, object_name, object_type
ORDER BY buffers;
spool off
spool tables_to_KEEP_Pool.txt
--The following query will return a list of tables that are frequently
-- used by SQL statements and can be assigned to the KEEP pool.
Col owner format a14
Col object_name format a36
Col object_type format a15
SELECT o.owner, object_name, object_type, COUNT(1) buffers
FROM SYS.x$bh, dba_objects o
WHERE tch > 10
AND lru_flag = 8
AND obj = o.object_id
AND o.owner = upper('&OWNER')
GROUP BY o.owner, object_name, object_type
ORDER BY buffers;
spool off
Once you have setup the database to use KEEP and RECYCLE pools, you can monitor the buffer hit ratio by querying V$BUFFER_POOL_STATISTICS and V$DB_CACHE_ADVICE to
adjust the buffer pool initialization parameters.
Step 4: Identify the amount of memory needed to maintain required performance.
Oracle 9i maintains block buffer advisory information in V$DB_CACHE_ADVICE. This view contains simulated physical reads for a range of buffer cache sizes. The DBA can query this
view to estimate buffer cache requirement for the database. The cache advisory can be activated by setting DB_CACHE_ADIVE initialization parameter.
DB_CACHE_ADVICE = ON
There is a minor overhead associated with cache advisory collection. Hence, it is not advisable to collect these statistics in production databases until there is a need to tune the buffer
12/5/12 Tuning_Methodology
18/31 www.pafumi.net/Tuning_Methodology.html
cache. The DBA can turn on DB_CACHE_ADVISE dynamically for the duration of sample workload period and collect advisory statistics.
Conclusion
Using this methodical approach, a DBA can easily identify the problem areas, and tune the database block buffers. The DBA can create the following buffer pool to efficiently cache data
blocks in SGA:
1. KEEP: Cache tables that are very critical for system performance. Typically, lookup tables are very good candidates for the KEEP pool. The DBA should create the KEEP pool
large enough to maintain 99% buffer hit ratio on this pool.
2. RECYCLE: Cache tables that are not critical for system performance. Typically, a table containing historical information that is either rarely queried or used by batch process is a
good candidate for the RECYCLE pool. The DBA should create the RECYCLE pool large enough to finish the current transaction.
3. DEFAULT: Cache tables that do not belong to either KEEP or RECYCLE pool.
The DBA can setup OEM jobs, Oracle statspack, or custom monitoring scripts to monitor your production database block buffer efficiency, and to identify and tune the problem area.
Check Size of LOG_BUFFER
Bigger is better and reduces I/O
Check ML 147471.1 item 4.
Check for contention on 'redo allocation latch', 'redo copy latch'.
Using that query check if 'redo log space request' not near 0, process had to wait for space in the buffer
If you get 'redo allocation latch', then increase LOG_PARALLELISM
If you get 'redo copy latch', then increase _LOGSIMULTANEOUS_COPIES (default is 2 times # of CPU)
Check Size of SHARED_POOL_SIZE Variable
Usually we want this variable to be around 250-300MB.
Using the v_$SGASTAT, check if you see a large value under "shared pool free memory", if so, reduce it. You don't want to have a big space with lot of SQL Staments that are
not re-used. If you have that, then Oracle is going to take too long to find those statements in memory.
Allocate Files properly (Tuning buffer busy waits by file)
Check for Buffer busy Waits.
This view (based on X$KCBWAIT) reports the number of times an instance has had buffer busy waits on different classes of blocks since the instance was started.
Oracle also provides a companion view called X$KCBFWAIT which duplicates the function of X$KCBWAIT, but summarises the waits by file id.
SPOOL file_wait.txt
SET linesize 180
SET pagesize 9000
COLUMN filename FORMAT a40 HEAD "File Name"
COLUMN file# FORMAT 99 HEAD "F#"
COLUMN ct FORMAT 999,999,999 HEAD "Waits"
COLUMN time FORMAT 999,999,999 HEAD "Time"
COLUMN avg FORMAT 999.999 HEAD "Avg Time"
SELECT indx+1 file#
, b.name filename
, count ct
, time
, time/(DECODE(count,0,1,count)) avg
FROM x$kcbfwait a, v$datafile b
WHERE indx < (select count(*) from v$datafile)
AND a.indx+1 = b.file#
order by ct desc
/
spool off
Checking ACTIVE Statements
spool Active_Statements.txt
set linesize 110
--Extracting the active SQL a user is executing
select sesion.sid,
substr(sesion.username,1,15) username,
substr(optimizer_mode,1,10) opt_mode,
hash_value,
address,
cpu_time,
elapsed_time,
sql_text
from v$sqlarea sqlarea, v$session sesion
where sesion.sql_hash_value = sqlarea.hash_value
and sesion.sql_address = sqlarea.address
and sesion.username is not null;
--I/O being done by an active SQL statement
select sess_io.sid,
sess_io.block_gets,
sess_io.consistent_gets,
sess_io.physical_reads,
12/5/12 Tuning_Methodology
19/31 www.pafumi.net/Tuning_Methodology.html
sess_io.block_changes,
sess_io.consistent_changes
from v$sess_io sess_io, v$session sesion
where sesion.sid = sess_io.sid
and sesion.username is not null;
-- If by chance the query shown earlier in the V$SQLAREA view did not show your full SQL text
-- because it was larger than 1000 characters, this V$SQLTEXT view should be queried
-- to extract the full SQL. It is a piece by piece of 64 characters by line,
-- that needs to be ordered by the column PIECE.
-- SQL to show the full SQL executing for active sessions
select sesion.sid,
sql_text
from v$sqltext sqltext, v$session sesion
where sesion.sql_hash_value = sqltext.hash_value
and sesion.sql_address = sqltext.address
and sesion.username is not null
order by sqltext.piece;
spool off
Use IPC for local connections
When a process is on the same machine as the server, use the IPC protocol for connectivity instead of TCP. Inner Process Communication on the same machine does not have the
overhead of packet building and deciphering that TCP has. I've seen a SQL job that runs in 10 minutes using TCP on a local machine run as fast as one minute using an IPC
connection.
You can set up your tnsnames file like this on a local machine so that local connection with use IPC connections first and then TCP connection second.
PROD =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = IPC)(Key = IPCKEY))
(ADDRESS = (PROTOCOL = TCP)(HOST = MYHOST)(PORT = 1521))
)
(CONNECT_DATA =
(SID = PROD)
)
)
Check undo parameters
When you are working with UNDO, there are two important things to consider:
The size of the UNDO tablespace
The UNDO_RETENTION parameter.
To get information of your current settings you can use the following query:
set serveroutput on
DECLARE
tsn VARCHAR2(40);
tss NUMBER(10);
aex BOOLEAN;
unr NUMBER(5);
rgt BOOLEAN;
retval BOOLEAN;
BEGIN
retval := dbms_undo_adv.undo_info(tsn, tss, aex, unr, rgt);
dbms_output.put_line('UNDO Tablespace is: ' || tsn);
dbms_output.put_line('UNDO Tablespace size is: ' || TO_CHAR(tss));
IF aex THEN
dbms_output.put_line('Undo Autoextend is set to: TRUE');
ELSE
dbms_output.put_line('Undo Autoextend is set to: FALSE');
END IF;
dbms_output.put_line('Undo Retention is: ' || TO_CHAR(unr));
IF rgt THEN
dbms_output.put_line('Undo Guarantee is set to: TRUE');
ELSE
dbms_output.put_line('Undo Guarantee is set to: FALSE');
END IF;
END;
/
There are two ways to proceed to optimize your resources.
You can choose to allocate a specific size for the UNDO tablespace and then set the UNDO_RETENTION parameter to an optimal value according to the UNDO size and the
database activity. If your disk space is limited and you do not want to allocate more space than necessary to the UNDO tablespace, this is the way to proceed.
If you are not limited by disk space, then it would be better to choose the UNDO_RETENTION time that is best for you (for FLASHBACK, etc.). Allocate the appropriate size
to the UNDO tablespace according to the database activity.
This tip help you get the information you need whatever the method you choose.
spool Check_Undo_Parameters.txt
set serverout on size 1000000
set feedback off
set heading off
set lines 132
declare
cursor get_undo_stat is
select d.undo_size/(1024*1024) "C1",
substr(e.value,1,25) "C2",
(to_number(e.value) * to_number(f.value) * g.undo_block_per_sec) / (1024*1024) "C3",
round((d.undo_size / (to_number(f.value) * g.undo_block_per_sec))) "C4"
from (select sum(a.bytes) undo_size
from v$datafile a,
v$tablespace b,
dba_tablespaces c
where c.contents = 'UNDO'
and c.status = 'ONLINE'
and b.name = c.tablespace_name
and a.ts# = b.ts#) d,
v$parameter e,
v$parameter f,
(select max(undoblks/((end_time-begin_time)*3600*24))undo_block_per_sec from v$undostat) g
where e.name = 'undo_retention'
and f.name = 'db_block_size';
begin
dbms_output.put_line(chr(10)||chr(10)||chr(10)||chr(10) || 'To optimize UNDO you have two choices :');
dbms_output.put_line('====================================================' || chr(10));
for rec1 in get_undo_stat loop
dbms_output.put_line('A) Adjust UNDO tablespace size according to UNDO_RETENTION :' || chr(10));
dbms_output.put_line(rpad('ACTUAL UNDO SIZE ',61,'.')|| ' : ' || TO_CHAR(rec1.c1,'999999') || ' MEGS');
dbms_output.put_line(rpad('OPTIMAL UNDO SIZE WITH ACTUAL UNDO_RETENTION (' ||
ltrim(TO_CHAR(rec1.c2/60,'999999'))
|| ' MINUTES) ',61,'.') || ' : '
|| TO_CHAR(rec1.c3,'999999') || ' MEGS');
dbms_output.put_line(chr(10));
dbms_output.put_line('B) Adjust UNDO_RETENTION according to UNDO tablespace size :' || chr(10));
dbms_output.put_line(rpad('ACTUAL UNDO RETENTION ',61,'.') || ' : ' || TO_CHAR(rec1.c2/60,'999999')
|| ' MINUTES');
dbms_output.put_line(rpad('OPTIMAL UNDO RETENTION WITH ACTUAL UNDO SIZE (' || ltrim(TO_CHAR(rec1.c1,'999999'))
|| ' MEGS) ',61,'.') || ' : ' || TO_CHAR(rec1.c4/60,'999999')
|| ' MINUTES');
end loop;
dbms_output.put_line(chr(10)||chr(10));
end;
/
select 'Number of "ORA-01555 (Snapshot too old)" encountered since the last startup of the instance : ' || sum(ssolderrcnt)
from v$undostat;
spool off
Detect High SQL parse calls
One of the first things that an Oracle DBA does when checking the performance of any database is to check for high-use SQL statements. The script below will display all SQL
where the number of parse calls is more than twice the number of SQL executions. The output from this script is a good starting point for detailed SQL tuning. This query can also
be modified to display the most frequently executed SQL statements that reside in the library cache.
prompt **********************************************************
prompt SQL High parse calls
prompt **********************************************************
select sql_text, parse_calls, executions
from v$sqlarea
where parse_calls > 300
and executions < 2*parse_calls
and executions > 1;
This script is great for finding non-reusable SQL statements that contain embedded literals. As you may know, non-reusable SQL statements place a heavy burden on the Oracle
library cache. When cursor_sharing=FORCE, Oracle8i will re-write the SQL with literal values so it can use a host variable instead. This is a great silver bullet for system where
the literal SQL cannot be changed.
Monitor Open and Cached Cursors
Open cursors take up space in the shared pool, in the library cache. To keep a renegade session from filling up the library cache, or clogging the CPU with millions of parse
requests, we set the parameter OPEN_CURSORS.
OPEN_CURSORS sets the maximum number of cursors each session can have open, per session. For example, if OPEN_CURSORS is set to 1000, then each session can have
up to 1000 cursors open at one time. If a single session has OPEN_CURSORS # of cursors open, it will get an ora-1000 error when it tries to open one more cursor.
The default is value for OPEN_CURSORS is 50, but Oracle recommends that you set this to at least 500 for most applications. Some applications may need more, eg. web
applications that have dozens to hundreds of users sharing a pool of sessions. Tom Kyte recommends setting it around 1000.
If SESSION_CACHED_CURSORS is not set, it defaults to 0 and no cursors will be cached for your session. (Your cursors will still be cached in the shared pool, but your
session will have to find them there.) If it is set, then when a parse request is issued, Oracle checks the library cache to see whether more than 3 parse requests have been issued for
that statement. If so, Oracle moves the session cursor associated with that statement into the session cursor cache. Subsequent parse requests for that statement by the same session
are then filled from the session cursor cache, thus avoiding even a soft parse. (Technically, a parse can't be completely avoided; a "softer" soft parse is done that's faster and
requires less CPU.)
The obvious advantage to caching cursors by session is reduced parse times, which leads to faster overall execution times. This is especially so for applications like Oracle Forms
applications, where switching from one form to another will close all the session cursors opened for the first form. Switching back then opens identical cursors. So caching cursors
by session really cuts down on reparsing.
There's another advantage, though. Since a session doesn't have to go looking in the library cache for previously parsed SQL, caching cursors by session results in less use of the
library cache and shared pool latches. These are often points of contention for busy OLTP systems. Cutting down on latch use cuts down on latch waits, providing not only an
increase in speed but an increase in scalability.
12/5/12 Tuning_Methodology
21/31 www.pafumi.net/Tuning_Methodology.html
This will give the number of currently opened cursors, by session:
--total cursors open, by session
select a.value, s.username, s.sid, s.serial#
from v$sesstat a, v$statname b, v$session s
where a.statistic# = b.statistic# and s.sid=a.sid
and b.name = 'opened cursors current';
If you're running several N-tiered applications with multiple webservers, you may find it useful to monitor open cursors by username and machine:
--total cursors open, by username & machine
select sum(a.value) total_cur, avg(a.value) avg_cur, max(a.value) max_cur, s.username, s.machine
from v$sesstat a, v$statname b, v$session s
where a.statistic# = b.statistic# and s.sid=a.sid
and b.name = 'opened cursors current'
group by s.username, s.machine
order by 1 desc;
The best advice for tuning OPEN_CURSORS is not to tune it. Set it high enough that you won't have to worry about it. If your sessions are running close to the limit you've set for
OPEN_CURSORS, raise it. If you set OPEN_CURSORS to a high value, this doesn't mean that every session will have that number of cursors open. Cursors are opened on an
as-needed basis
To see if you've set OPEN_CURSORS high enough, monitor v$sesstat for the maximum opened cursors current. If your sessions are running close to the limit, up the value of
OPEN_CURSORS.
select max(a.value) as highest_open_cur, p.value as max_open_cur
from v$sesstat a, v$statname b, v$parameter p
where a.statistic# = b.statistic#
and b.name = 'opened cursors current'
and p.name= 'open_cursors'
group by p.value;
HIGHEST_OPEN_CUR MAX_OPEN_CUR
---------------- ------------
1953 2500
Monitoring the session cursor cache
v$sesstat also provides a statistic to monitor the number of cursors each session has in its session cursor cache.
--session cached cursors, by session
select a.value, s.username, s.sid, s.serial#
from v$sesstat a, v$statname b, v$session s
where a.statistic# = b.statistic# and s.sid=a.sid
and b.name = 'session cursor cache count' ;
You can also see directly what is in the session cursor cache by querying v$open_cursor. v$open_cursor lists session cached cursors by SID, and includes the first few characters
of the statement and the sql_id, so you can actually tell what the cursors are for.
select c.user_name, c.sid, sql.sql_text
from v$open_cursor c, v$sql sql
where c.sql_id=sql.sql_id
and c.sid=&sid;
Tuning SESSION_CACHED_CURSORS
If you choose to use SESSION_CACHED_CURSORS to help out an application that is continually closing and reopening cursors, you can monitor its effectiveness via two more
statistics in v$sesstat. The statistic "session cursor cache hits" reflects the number of times that a statement the session sent for parsing was found in the session cursor cache,
meaning it didn't have to be reparsed and your session didn't have to search through the library cache for it. You can compare this to the statistic "parse count (total)"; subtract
"session cursor cache hits" from "parse count (total)" to see the number of parses that actually occurred.
select cach.value cache_hits, prs.value all_parses, prs.value-cach.value sess_cur_cache_not_used
from v$sesstat cach, v$sesstat prs, v$statname nm1, v$statname nm2
where cach.statistic# = nm1.statistic#
and nm1.name = 'session cursor cache hits'
and prs.statistic#=nm2.statistic#
and nm2.name= 'parse count (total)'
and cach.sid= &sid and prs.sid= cach.sid ;
Enter value for sid: 947
old 8: and cach.sid= &sid and prs.sid= cach.sid
new 8: and cach.sid= 947 and prs.sid= cach.sid
CACHE_HITS ALL_PARSES SESS_CUR_CACHE_NOT_USED
---------- ---------- -----------------------
106 210 104
Monitor this in concurrence with the session cursor cache count.
--session cached cursors, for a given SID, compared to max
select a.value curr_cached, p.value max_cached, s.username, s.sid, s.serial#
from v$sesstat a, v$statname b, v$session s, v$parameter2 p
where a.statistic# = b.statistic# and s.sid=a.sid and a.sid=&sid
and p.name='session_cached_cursors'
and b.name = 'session cursor cache count' ;
12/5/12 Tuning_Methodology
22/31 www.pafumi.net/Tuning_Methodology.html
Detect Top 10 Queries in SQL Area
spool top10_sqlarea.txt
/*
This script queries the SQL area ordered by the the average cost of the statement.
The "Avg Cost" row is basically the No. of Buffer Gets per Rows processed.
Where no rows are processed, all Buffer Gets are reported for the statement.
The script also lists any potential candidates for a converting to stored procedures
by running a case insensitive query.
*/
set pagesize 66 linesize 132
set echo off
column executions heading "Execs" format 99999999
column rows_processed heading "Rows Procd" format 99999999
column loads heading "Loads" format 999999.99
column buffer_gets heading "Buffer Gets"
column disk_reads heading "Disk Reads"
column elapsed_time heading "Elasped Time"
column cpu_time heading "CPU Time"
column sql_text heading "SQL Text" format a120 wrap
column avg_cost heading "Avg Cost" format 99999999
column gets_per_exec heading "Gets Per Exec" format 99999999
column reads_per_exec heading "Read Per Exec" format 99999999
column rows_per_exec heading "Rows Per Exec" format 99999999
break on report
compute sum of rows_processed on report
compute sum of executions on report
compute avg of avg_cost on report
compute avg of gets_per_exec on report
compute avg of reads_per_exec on report
compute avg of row_per_exec on report
PROMPT
PROMPT Top 10 most expensive SQL by Elapsed Time...
PROMPT
select rownum as rank, a.*
from ( select elapsed_Time, executions, buffer_gets, disk_reads, cpu_time, hash_value, sql_text
from v$sqlarea
where elapsed_time > 20000
order by elapsed_time desc) a
where rownum < 11;
PROMPT
PROMPT Top 10 most expensive SQL by CPU Time...
PROMPT
select rownum as rank, a.*
from ( select elapsed_Time, executions, buffer_gets, disk_reads, cpu_time, hash_value, sql_text
from v$sqlarea
where cpu_time > 20000
order by cpu_time desc) a
where rownum < 11;
PROMPT
PROMPT Top 10 most expensive SQL by Buffer Gets by Executions...
PROMPT
select rownum as rank, a.*
from (select buffer_gets, executions,
buffer_gets/ decode(executions,0,1, executions) gets_per_exec,
hash_value, sql_text
from v$sqlarea
where buffer_gets > 50000
order by buffer_gets desc) a
where rownum < 11;
PROMPT
PROMPT Top 10 most expensive SQL by Physical Reads by Executions...
PROMPT
select rownum as rank, a.*
from (select disk_reads, executions,
disk_reads / decode(executions,0,1, executions) reads_per_exec,
hash_value, sql_text
from v$sqlarea
where disk_reads > 10000
order by disk_reads desc) a
where rownum < 11;
PROMPT
PROMPT Top 10 most expensive SQL by Rows Processed by Executions...
PROMPT
select rownum as rank, a.*
from (select rows_processed, executions,
rows_processed / decode(executions,0,1, executions) rows_per_exec,
hash_value, sql_text
from v$sqlarea
where rows_processed > 10000
order by rows_processed desc) a
where rownum < 11;
PROMPT
PROMPT Top 10 most expensive SQL by Buffer Gets vs Rows Processed...
PROMPT
12/5/12 Tuning_Methodology
23/31 www.pafumi.net/Tuning_Methodology.html
select rownum as rank, a.*
from ( select buffer_gets, lpad(rows_processed ||
decode(users_opening + users_executing, 0, ' ','*'),20) "rows_processed",
executions, loads,
(decode(rows_processed,0,1,1)) * buffer_gets/ decode(rows_processed,0,1,rows_processed) avg_cost,
sql_text
from v$sqlarea
where decode(rows_processed,0,1,1) * buffer_gets/ decode(rows_processed,0,1,rows_processed) > 10000
order by 5 desc) a
where rownum < 11;
rem Check to see if there are any candidates for procedures or
rem for using bind variables. Check this by comparing UPPER
rem
rem This May be a candidate application for using the init.ora parameter
rem CURSOR_SHARING = FORCE|SIMILAR
select rownum as rank, a.*
from (select upper(substr(sql_text, 1, 65)) sqltext, count(*)
from v$sqlarea
group by upper(substr(sql_text, 1, 65))
having count(*) > 1
order by count(*) desc) a
where rownum < 11;
prompt Output spooled to top10_sqlarea.txt
spool off
If you want to see the full text of the sql statement, you can run the following query:
select v2.sql_text, v2.address
from v$sqlarea v1, v$sqltext v2
where v1.address=v2.address
and v1.sql_text like 'SELECT COUNT(*) FROM DEPT%'
order by v2.address, v2.piece;
The next query returns the SQL text from a hash value that must be determined from each v$sqlarea row in question.
select sql_text
from v$sqltext
where hash_value=&hash_value
order by piece;
Check for Indexes not Used and HOT Tables
If you want to know if an index has ever been used since instance startup, or the use of a specific table, the solution is quite easy.
Simply query V$SEGMENT_STATISTICS to see if there has even been a physical read on the index in question. Queries similar to the following can help:
select index_name from all_indexes
where owner = 'FRAUDGUARD'
and index_name not in ( select object_name
from v$segment_statistics
where owner='FRAUDGUARD'
and statistic_name='physical reads');
If you get no rows, that means that all your indexes has been used.
Next, we'll determine the top 10 tables that have incurred the most physical I/O operations.
select table_name,total_phys_io
from (select owner||'.'||object_name as table_name, sum(value) as total_phys_io
from v$segment_statistics
where owner='FRAUDGUARD'
and object_type='TABLE'
and statistic_name in ('physical reads','physical reads direct','physical writes','physical writes direct')
group by owner||'.'||object_name
order by total_phys_io desc)
where rownum <=10;
TABLE_NAME TOTAL_PHYS_IO
------------------------------------------------------------- -------------
FG83_DEV.FLOWDOCUMENT_ARCH 1011844
FG83_DEV.FLOWDOCUMENT 697512
FG83_DEV.FLOWFIELD_ARCH 21423
FG83_DEV.USERACTIVITYLOG_ARCH 13987
FG83_DEV.FLOWDATA 13607
FG83_DEV.USERACTIVITYLOG 12334
FG83_DEV.SIGNATURES 8992
FG83_DEV.PROCESSLOG 4764
FG83_DEV.EXCEPTIONITEM_ARCH 399
FG83_DEV.USERLEVELPERMISSION 276
The query above eliminated any data dictionary tables from the results. It should now be clear what the exact table is that experiences the most physical I/O operations. Appropriate
actions can now be taken to isolate this potential hotspot from other highly active database segments.
If you've ever dealt with wait events, you may have seen the 'buffer busy waits' event. This event occurs when one session is waiting on another session to read the buffer into the
cache, or some other session is changing the buffer. This even can often be seen when querying V$SYSTEM_EVENT.
If I query my database, I have approximately 13 million waits on this specific event.
select event,total_waits from v$system_event
where event='buffer busy waits';
EVENT TOTAL_WAITS
---------------------------------------- -----------
buffer busy waits 12976210
The big question is to determine which segments are contributing to this overall wait event. Querying V$SEGMENT_STATISTICS can help us determine the answer.
select substr(segment_name,1,30) segment_name,
object_type,total_buff_busy_waits
from (select owner||'.'||object_name as segment_name,object_type, value as total_buff_busy_waits
from v$segment_statistics
where statistic_name in ('buffer busy waits')
order by total_buff_busy_waits desc)
where rownum <=10;
SEGMENT_NAME OBJECT_TYPE TOTAL_BUFF_BUSY_WAITS
----------------------------------- ------------- ---------------------
WEBMAP.SDE_BLK_1103 TABLE 10522135
WEBMAP.SDE_BLK_804 TABLE 1176185
SRTM.SDE_BLK_1101 TABLE 651175
WEBMAP.SDE_BLK_804_UK INDEX 100242
SYS.DBMS_LOCK_ALLOCATED TABLE 64695
NED.SDE_BLK_1002 TABLE 48582
WEBMAP.BTS_ROADS_MD TABLE 27068
WEBMAP.SDE_BLK_1103_UK INDEX 25707
ARCIMS.SDE_LOGFILE_DATA_IDX1 INDEX 24618
NED.SDE_BLK_62 TABLE 14710
From the query above, we can see that one specific table contributed 10.5 million, or approximately 80%, of the total waits.
If you ever want to know why the access to a specific table (Example: EMP) is slow, one of the first actions would be to run:
select statistic_name, value
from v$segment_statistics
where owner='SCOTT' and object_name = 'EMP';
STATISTIC_NAME VALUE
---------------------------------------------------------------- ----------
logical reads 17653
buffer busy waits 1744
db block changes 16234
physical reads 1110
physical writes 516
physical reads direct 0
physical writes direct 0
global cache cr blocks served 0
global cache current blocks served 0
ITL waits 0
row lock waits 6
From the above query we can see that EMP is forever being modified and rarely just being selected. And those modifications has problems because of the high number of bussy
waits (users try to access to the same block). Perhaps if that table has a higher PCTFREE the problem would disappear. Or maybe this is a case for ASSM.
Detect and Resolve Buffer Busy Waits
Whenever multiple insert or update tasks access a table, it is possible that Oracle may be forced to wait to access the first block in the table. The first block is called the segment
header, and the segment header contains the freelist for the table. The number of freelists for any table should be set to the high-water mark of concurrent inserts or updates.
The script below will tell you if you have waits for table or index freelists. If so, you need to identify the table and add additional freelists. You can add freelists with the ALTER
table command.
The procedure for identifying the specific table associated with a freelist wait or a buffer busy wait is complex, but it is fully described in the book Oracle High-Performance Tuning
with STATSPACK.
column s_v format 999,999,999 heading 'Total Requests' new_value tnr
column count format 99999990 heading count new_value cnt
column proc heading 'Ratio of waits'
PROMPT Current v$waitstat freelist waits...
PROMPT
set heading on;
prompt - This displays the total current waits on freelists
select class, count
from v$waitstat
where class = 'free list';
prompt - This displays the total gets in the database
select sum(value) s_v
from v$sysstat
where name IN ('db block gets', 'consistent gets');
PROMPT - Here is the ratio
select &cnt/&tnr * 100 proc
from dual;
12/5/12 Tuning_Methodology
25/31 www.pafumi.net/Tuning_Methodology.html
Current v$waitstat freelist waits...
- This displays the total current waits on freelists
CLASS COUNT
------------------ ---------
free list 0
- This displays the total gets in the database
Total Num of Requests
---------------------
140318872
- Here is the ratio
Ratio in %
----------
0
Please note the freelist contention also can be manifested as a buffer busy wait. This is because the block is already in the buffer, but cannot be accessed because another task has
the segment header. The section below describes the process the block address associated with a wait. As we discussed, Oracle does not keep an accumulator to track individual
buffer busy waits. To see them, you must create a script to detect them and then schedule the task to run frequently on your database server.
vi get_busy.ksh
#!/bin/ksh
# First, we must set the environment . . . .
export ORACLE_SID=proderp
export ORACLE_HOME=`cat /var/opt/oracle/oratab|grep \^$ORACLE_SID:|cut -f2 -d':'`
export PATH=$ORACLE_HOME/bin:$PATH
export SERVER_NAME=`uname -a|awk '{print $2}'`
typeset -u SERVER_NAME
# sample every 10 seconds
SAMPLE_TIME=10
while true
do
#*************************************************************
# Test to see if Oracle is accepting connections
#*************************************************************
$ORACLE_HOME/bin/sqlplus -s /<<! > /tmp/check_$ORACLE_SID.ora
select * from v\$database;
exit
!
#*************************************************************
# If not, exit immediately . . .
#*************************************************************
check_stat=`cat /tmp/check_$ORACLE_SID.ora|grep -i error|wc -l`;
oracle_num=`expr $check_stat`
if [ $oracle_num -gt 0 ]
then
exit 0
fi
rm -f /export/home/oracle/statspack/busy.lst
$ORACLE_HOME/bin/sqlplus -s perfstat/perfstat<<!> /tmp/busy.lst
set feedback off;
select sysdate, event, substr(tablespace_name,1,14), p2
from v\$session_wait a, dba_data_files b
where a.p1 = b.file_id;
!
var=`cat /tmp/busy.lst|wc -l`
echo $var
if [[ $var -gt 1 ]];
then
echo
**********************************************************************"
echo "There are waits"
cat /tmp/busy.lst|mailx -s "Prod block wait found"\
dpafumi at yahoo com
echo
**********************************************************************"
exit
fi
sleep $SAMPLE_TIME
done
As we can see from this script, it probes the database for buffer busy waits every 10 seconds. When a buffer busy wait is found, it mails the date, tablespace name, and block
number to the DBA. Here is an example of a block alert e-mail:
SYSDATE SUBSTR(TABLESP BLOCK
--------- -------------- ----------
28-DEC-00 APPLSYSD 25654
Here we see that we have a block wait condition at block 25654 in the applsysd tablespace. The procedure for locating this block is beyond the scope of this tip, but complete
12/5/12 Tuning_Methodology
26/31 www.pafumi.net/Tuning_Methodology.html
directions are in Chapter 10 of Oracle High Performance Tuning with STATSPACK
One of the most confounding problems with Oracle is the resolution of buffer busy wait events. Buffer busy waits are common in an I/O-bound Oracle system, as evidenced by any
system with read (sequential/scattered) waits in the top-five waits in the Oracle STATSPACK report, like this:
Top 5 Timed Events
% Total
Event Waits Time (s) Ela Time
--------------------------- ------------ ----------- -----------
db file sequential read 2,598 7,146 48.54
db file scattered read 25,519 3,246 22.04
library cache load lock 673 1,363 9.26
CPU time 2,154 934 7.83
log file parallel write 19,157 837 5.68
The main way to reduce buffer busy waits is to reduce the total I/O on the system. This can be done by tuning the SQL to access rows with fewer block reads (i.e., by adding
indexes). Even if we have a huge db_cache_size, we may still see buffer busy waits, and increasing the buffer size won't help.
In order to look at system-wide wait events, we can query the v$system_event performance view. This view, shown below, provides the name of the wait event, the total number
of waits and timeouts, the total time waited, and the average wait time per event.
spool Wait_Events.txt
select substr(event,1,25) event, total_waits, total_timeouts, time_waited, average_wait
from v$system_event
where event like '%wait%'
order by 2 desc;
spool off
EVENT TOTAL_WAITS TOTAL_TIMEOUTS TIME_WAITED AVERAGE_WAIT
--------------------------- ----------- -------------- ----------- ------------
buffer busy waits 636528 1557 549700 .863591232
write complete waits 1193 0 14799 12.4048617
free buffer waits 1601 0 622 .388507183
If you want to see all the events, you can try with:
set pages 999
set lines 90
column c1 heading 'Event|Name' format a30
column c2 heading 'Total|Waits' format 999,999,999
column c3 heading 'Seconds|Waiting' format 999,999
column c4 heading 'Total|Timeouts' format 999,999,999
column c5 heading 'Average|Wait|(in secs)' format 99.999
ttitle 'System-wide Wait Analysis|for current wait events'
select event c1, total_waits c2, time_waited/100 c3,
total_timeouts c4, average_wait/100 c5
from sys.v_$system_event
where event not in (
'dispatcher timer',
'lock element cleanup',
'Null event',
'parallel query dequeue wait',
'parallel query idle wait - Slaves',
'pipe get',
'PL/SQL lock timer',
'pmon timer',
'rdbms ipc message',
'slave wait',
'smon timer',
'SQL*Net break/reset to client',
'SQL*Net message from client',
'SQL*Net message to client',
'SQL*Net more data to client',
'virtual circuit status',
'WMON goes to sleep'
)
AND event not like 'DFS%'
and event not like '%done%'
and event not like '%Idle%'
AND event not like 'KXFX%'
order by c2 desc;
Wed Feb 14
12/5/12 Tuning_Methodology
27/31 www.pafumi.net/Tuning_Methodology.html
page 1
System-wide Wait Analysis
for current wait events
Average
Event Total Seconds Total Wait
Name Waits Waiting Timeouts (in secs)
------------------------------ ------------ -------- ------------ ---------
db file sequential read 812 7 0 .010
control file parallel write 645 3 0 .000
control file sequential read 378 4 0 .010
log file parallel write 213 0 127 .000
db file scattered read 111 2 0 .020
wakeup time manager 61 1,874 61 30.720
direct path read 27 0 0 .000
rdbms ipc reply 10 2 0 .180
db file parallel write 8 0 4 .020
direct path write 8 0 0 .000
buffer busy waits 7 0 0 .000
log file sequential read 4 0 0 .000
log file single write 4 0 0 .000
LGWR wait for redo copy 2 0 0 .000
log file sync 2 0 0 .010
library cache load lock 2 0 0 .000
instance state change 2 0 0 .000
reliable message 1 0 0 .070
refresh controlfile command 1 0 0 .050
control file heartbeat 1 4 1 4.100
The type of buffer that causes the wait can be queried using the v$waitstat view. This view lists the waits per buffer type for buffer busy waits, where COUNT is the sum of all waits
for the class of block, and TIME is the sum of all wait times for that class:
select * from v$waitstat;
CLASS COUNT TIME
------------------ ---------- ----------
data block 1961113 1870278
segment header 34535 159082
undo header 233632 86239
undo block 1886 1706
Buffer busy waits occur when an Oracle session needs to access a block in the buffer cache, but cannot because the buffer copy of the data block is locked. This buffer busy wait
condition can happen for either of the following reasons:
The block is being read into the buffer by another session, so the waiting session must wait for the block read to complete.
Another session has the buffer block locked in a mode that is incompatible with the waiting session's request.
Because buffer busy waits are due to contention between particular blocks, there's nothing you can do until you know which blocks are in conflict and why the conflicts are
occurring. Tuning therefore involves identifying and eliminating the cause of the block contention.
The v$session_wait performance view, shown below, can give some insight into what is being waited for and why the wait is occurring.
SQL> desc v$session_wait
Name Null? Type
----------------------------------------- -------- ---------------------
SID NUMBER
SEQ# NUMBER
EVENT VARCHAR2(64)
P1TEXT VARCHAR2(64)
P1 NUMBER
P1RAW RAW(4)
P2TEXT VARCHAR2(64)
P2 NUMBER
P2RAW RAW(4)
P3TEXT VARCHAR2(64)
P3 NUMBER
P3RAW RAW(4)
WAIT_TIME NUMBER
SECONDS_IN_WAIT NUMBER
STATE VARCHAR2(19)
The columns of the v$session_wait view that are of particular interest for a buffer busy wait event are:
P1The absolute file number for the data file involved in the wait.
P2The block number within the data file referenced in P1 that is being waited upon.
P3The reason code describing why the wait is occurring.
Here's an Oracle data dictionary query for these values:
select p1 "File #", p2 "Block #", p3 "Reason Code"
from v$session_wait
where event = 'buffer busy waits';
If the output from repeatedly running the above query shows that a block or range of blocks is experiencing waits, the following query should show the name and type of the
segment:
select owner, segment_name, segment_type
12/5/12 Tuning_Methodology
28/31 www.pafumi.net/Tuning_Methodology.html
from dba_extents
where file_id = &P1
and &P2 between block_id and block_id + blocks -1;
Once the segment is identified, the v$segment_statistics performance view facilitates real-time monitoring of segment-level statistics. This enables a DBA to identify performance
problems associated with individual tables or indexes, as shown below.
select object_name, statistic_name, value
from V$SEGMENT_STATISTICS
where object_name = 'SOURCE$';
OBJECT_NAME STATISTIC_NAME VALUE
----------- ------------------------- ----------
SOURCE$ logical reads 11216
SOURCE$ buffer busy waits 210
SOURCE$ db block changes 32
SOURCE$ physical reads 10365
SOURCE$ physical writes 0
SOURCE$ physical reads direct 0
SOURCE$ physical writes direct 0
SOURCE$ ITL waits 0
SOURCE$ row lock waits
We can also query the dba_data_files to determine the file_name for the file involved in the wait by using the P1 value from v$session_wait for the file_id.
SQL> desc dba_data_files
Name Null? Type
----------------------------------------- -------- ----------------------------
FILE_NAME VARCHAR2(513)
FILE_ID NUMBER
TABLESPACE_NAME VARCHAR2(30)
BYTES NUMBER
BLOCKS NUMBER
STATUS VARCHAR2(9)
RELATIVE_FNO NUMBER
AUTOEXTENSIBLE VARCHAR2(3)
MAXBYTES NUMBER
MAXBLOCKS NUMBER
INCREMENT_BY NUMBER
USER_BYTES NUMBER
USER_BLOCKS NUMBER
Interrogating the P3 (reason code) value from v$session_wait for a buffer busy wait event will tell us why the session is waiting. The reason codes range from 0 to 300 and can be
decoded, as shown in Table A.
Table A
Code Reason for wait
-
A modification is happening on a SCUR or XCUR buffer but has not yet
completed.
0
The block is being read into the buffer cache.
100
We want to NEW the block, but the block is currently being read by another
session (most likely for undo).
110
We want the CURRENT block either shared or exclusive but the block is being
read into cache by another session, so we have to wait until its read() is
completed.
120
We want to get the block in current mode, but someone else is currently reading
it into the cache. Wait for the user to complete the read. This occurs during
buffer lookup.
130
Block is being read by another session, and no other suitable block image was
found, so we wait until the read is completed. This may also occur after a buffer
cache assumed deadlock. The kernel can't get a buffer in a certain amount of
time and assumes a deadlock. Therefore it will read the CR version of the block.
200
We want to NEW the block, but someone else is using the current copy, so we
have to wait for that user to finish.
210
The session wants the block in SCUR or XCUR mode. If this is a buffer
exchange or the session is in discrete TXmode, the session waits for the first
time and the second time escalates the block as a deadlock, so does not show
up as waiting very long. In this case, the statistic: "exchange deadlocks" is
incremented, and we yield the CPU for the "buffer deadlock" wait event.
220
During buffer lookup for a CURRENT copy of a buffer, we have found the buffer
but someone holds it in an incompatible mode, so we have to wait.
230
Trying to get a buffer in CR/CRXmode, but a modification has started on the
buffer that has not yet been completed.
231
CR/CRXscan found the CURRENT block, but a modification has started on the
buffer that has not yet been completed.
Reason codes
As I mentioned at the beginning of this article, buffer busy waits are prevalent in I/O-bound systems. I/O contention, resulting in waits for data blocks, is often due to numerous
sessions repeatedly reading the same blocks, as when many sessions scan the same index. In this scenario, session one scans the blocks in the buffer cache quickly, but then a block
has to be read from disk. While session one awaits the disk read to complete, other sessions scanning the same index soon catch up to session one and want the same block
12/5/12 Tuning_Methodology
29/31 www.pafumi.net/Tuning_Methodology.html
currently being read from disk. This is where the buffer busy wait occurswaiting for the buffer blocks that are being read from disk. The following rules of thumb may be useful for
resolving each of the noted contention situations:
Data block contentionIdentify and eliminate HOT blocks from the application via changing PCTFREE and or PCTUSED values to reduce the number of rows per data
block. Check for repeatedly scanned indexes. Since each transaction updating a block requires a transaction entry, increase the INITRANS value.
Freelist block contentionIncrease the FREELISTS value. Also, when using Parallel Server, be certain that each instance has its own FREELIST GROUPs.
Segment header contentionAgain, increase the number of FREELISTs and use FREELIST GROUPs, which can make a difference even within a single instance.
Undo header contentionIncrease the number of rollback segments.
The following STATSPACK script is very useful for detecting those times when the database has a high-level of buffer busy waits.
prompt ***********************************************************
prompt Buffer Busy Waits may signal a high update table with too
prompt few freelists. Find the offending table and add more freelists.
prompt ***********************************************************
prompt
column buffer_busy_wait format 999,999,999
column mydate heading 'yr. mo dy Hr.'
select to_char(snap_time,'yyyy-mm-dd HH24') mydate,
new.name,
new.buffer_busy_wait-old.buffer_busy_wait buffer_busy_wait
from perfstat.stats$buffer_pool_statistics old,
perfstat.stats$buffer_pool_statistics new,
perfstat.stats$snapshot sn
where snap_time > sysdate-&1
and new.name <> 'FAKE VIEW'
and new.snap_id = sn.snap_id
and old.snap_id = sn.snap_id-1
and new.buffer_busy_wait-old.buffer_busy_wait > 1
group by to_char(snap_time,'yyyy-mm-dd HH24'), new.name, new.buffer_busy_wait-old.buffer_busy_wait ;
Show the percentage of a table in the data buffer
In Oracle9i we have a multiple blocks size feature, and separate independent data buffers can be created for all objects in the today, for 2k, 4k, 8k, 16k and 32k blocks sizes.
The following script will interrogate to the v$bh view and give us counts all the number of data blocks in the buffer on a segment-by-segment basis. Note that the script also then
joins into the dba_objects view in order to count the number of data blocks in the segment and compare it to the buffer. This script is a multi-step process, and rather than make
the query complex with in-line views or subqueries, the script has been broken down into three separate queries using temporary tables to hold the intermediate results. The
following query is extremely useful for showing the percentage of data blocks for on each table within the data buffer caches.
set pages 999
set lines 80
ttitle 'Contents of Data Buffers'
drop table t1;
create table t1 as
select o.object_name object_name, o.object_type object_type,
count(1) num_blocks
from dba_objects o, v$bh bh
where o.object_id = bh.objd
and o.owner not in ('SYS','SYSTEM')
group by o.object_name, o.object_type
order by count(1) desc;
column c1 heading "Object|Name" format a30
column c2 heading "Object|Type" format a12
column c3 heading "Number of|Blocks" format 999,999,999,999
column c4 heading "Percentage|of object|data blocks|in Buffer" format 999
select object_name c1, object_type c2, num_blocks c3,
(num_blocks/decode(sum(blocks), 0, .001, sum(blocks)))*100 c4
from t1, dba_segments s
where s.segment_name = t1.object_name
and num_blocks > 10
group by object_name, object_type, num_blocks
order by num_blocks desc;
drop table t1;
Wed Oct 23 page 1
Contents of Data Buffers
Percentage
of object
Object Object Number of data blocks
Name Type Blocks in Buffer
--------------------------- ------- ------------ -----------
MTL_DEMAND_INTERFACE TABLE 38,745 100
FND_CONCURRENT_REQUESTS TABLE 16,636 88
WIP_TRANSACTIONS TABLE 14,777 100
WIP_TRANSACTION_ACCOUNTS TABLE 13,390 33
CRP_RESOURCE_HOURS TABLE 7,806 100
SO_LINES_ALL TABLE 7,576 100
ABC_EDI_LINES TABLE 7,041 100
12/5/12 Tuning_Methodology
30/31 www.pafumi.net/Tuning_Methodology.html
BOM_INVENTORY_COMPONENTS TABLE 6,882 46
MTL_SYSTEM_ITEMS TABLE 4,747 63
WIP_TRANSACTION_ACCOUNTS_N1 INDEX 3,996 38
MTL_ITEM_CATEGORIES TABLE 3,390 100
RA_CUSTOMER_TRX_LINES_ALL TABLE 3,264 100
MRP_FORECAST_DATES TABLE 3,082 99
RA_CUSTOMER_TRX_ALL TABLE 2,739 97
WIP_OPERATIONS TABLE 2,311 34
SO_PICKING_LINES_ALL TABLE 2,006 100
MTL_DEMAND_INTERFACE_N10 INDEX 1,482 76
BOM_OPERATION_RESOURCES TABLE 1,456 45
ABC_EDI_ERRORS TABLE 1,427 100
ABC_EDI_HEADERS TABLE 1,188 100
Testing Procedures or Packages for Performance
-- before.sql
set echo off
set timing off
set recsep off
column CPU noprint new_value before_cpu
column READS noprint new_value before_reads
select s_cpu.value CPU,
sum(s_reads.value) READS
from sys.v_$session se,
sys.v_$statname n_cpu,
sys.v_$statname n_reads,
sys.v_$sesstat s_cpu,
sys.v_$sesstat s_reads
where n_reads.name in ('db block gets', 'consistent gets')
and n_cpu.name = 'CPU used by this session'
and n_cpu.statistic# = s_cpu.statistic#
and n_reads.statistic# = s_reads.statistic#
and s_cpu.sid = se.sid
and s_reads.sid = se.sid
and se.audsid = userenv('SESSIONID')
group by s_cpu.value
/
column CPU clear
column READS clear
will display nothing but blank lines but will collect values before your PL/SQL runs; immediately after your PL/SQL, run this :
-- after.sql
set echo off
set timing off
set recsep off
column CPU print format 999999
column READS print format 9999999999999
select s_cpu.value - &&before_cpu - 97 CPU,
sum(s_reads.value) - &&before_reads - 10 READS
from sys.v_$session se,
sys.v_$statname n_cpu,
sys.v_$statname n_reads,
sys.v_$sesstat s_cpu,
sys.v_$sesstat s_reads
where n_reads.name in ('db block gets', 'consistent gets')
and n_cpu.name = 'CPU used by this session'
and n_cpu.statistic# = s_cpu.statistic#
and n_reads.statistic# = s_reads.statistic#
and s_cpu.sid = se.sid
and s_reads.sid = se.sid
and se.audsid = userenv('SESSIONID')
group by s_cpu.value
/
column CPU clear
column READS clear
Check Sorts
spool sorts.txt
--The ratio of sorts (disk) to sorts (memory) should be < 5%.
-- Increase the size of SORT_AREA_SIZE if it is less than 5%.
-- Increments of 10% should be fine.
select disk.value "Disk", mem.value "Mem", (disk.value/mem.value)*100 "Ratio"
from v$sysstat mem, v$sysstat disk
where mem.name = 'sorts (memory)'
and disk.name = 'sorts (disk)';
spool off
Optimizing Indexes
12/5/12 Tuning_Methodology
31/31 www.pafumi.net/Tuning_Methodology.html
Move Indexes to a 32k Block Size
Create a 32k_block Cache in the SPFILE
db_32k_cache_size = 32M
Create a Tablespace using 32K Blocks
CREATE TABLESPACE "TS_32K_INDEXES" LOGGING DATAFILE '/oradata/SID/TS_32K_IND.dbf'
SIZE 100M BLOCKSIZE 32768 EXTENT
MANAGEMENT LOCAL UNIFORM SIZE 1M SEGMENT SPACE MANAGEMENT AUTO;
Você também pode gostar
- Tuning Methodology - HTMLDocumento56 páginasTuning Methodology - HTMLbalajismithAinda não há avaliações
- Locating Similar SQL in OracleDocumento5 páginasLocating Similar SQL in Oracleapi-3759101Ainda não há avaliações
- Dump Oracle Exam Question - Paper - 1Documento13 páginasDump Oracle Exam Question - Paper - 1api-3745527Ainda não há avaliações
- Evidence of Sort Sizes in An Oracle10g DatabaseDocumento230 páginasEvidence of Sort Sizes in An Oracle10g Databasedan629Ainda não há avaliações
- Database Performance Tuning by ExamplesDocumento16 páginasDatabase Performance Tuning by ExamplesTejaswi SedimbiAinda não há avaliações
- DB12c Tuning New Features Alex Zaballa PDFDocumento82 páginasDB12c Tuning New Features Alex Zaballa PDFGanesh KaralkarAinda não há avaliações
- SQL Select From V$SGADocumento16 páginasSQL Select From V$SGAk2sh07Ainda não há avaliações
- TuningDocumento53 páginasTuningbalajismithAinda não há avaliações
- Script SharepoolDocumento8 páginasScript SharepoolMahmadsalim MemonAinda não há avaliações
- Solaris KernelDocumento3 páginasSolaris KernelDungAinda não há avaliações
- Performance Tuning - Now You Are The V8 ExpertDocumento37 páginasPerformance Tuning - Now You Are The V8 Expertgorthi.pavanAinda não há avaliações
- Database Tuning Improvements: User Initiated Buffer Cache FlushingDocumento4 páginasDatabase Tuning Improvements: User Initiated Buffer Cache FlushingVyom RastogiAinda não há avaliações
- Oracle9i NF: Dynamic Buffer Cache Advisory 19-JUL-2005Documento4 páginasOracle9i NF: Dynamic Buffer Cache Advisory 19-JUL-2005elcaso34Ainda não há avaliações
- How To Determine If PGA Size Is Set ProperlyDocumento5 páginasHow To Determine If PGA Size Is Set Properlypatrick_wangrui100% (1)
- STBCDocumento4 páginasSTBCsravan.appsdbaAinda não há avaliações
- Oracle Database 19c Auto-IndexingDocumento15 páginasOracle Database 19c Auto-IndexinglocutoAinda não há avaliações
- Tuning Tips by Oracle DBA GuruDocumento32 páginasTuning Tips by Oracle DBA Gurusbukka100% (13)
- UAT Database ObservationsDocumento26 páginasUAT Database Observationsmoni.aro28Ainda não há avaliações
- DB Cache AdviceDocumento2 páginasDB Cache Adviceelcaso34Ainda não há avaliações
- Monitoring CPU UsageDocumento3 páginasMonitoring CPU UsagePapa Sachin Goud KAinda não há avaliações
- What To Expect in Oracle 19cDocumento42 páginasWhat To Expect in Oracle 19cwalterpotocki100% (1)
- Performance Tunning StepsDocumento11 páginasPerformance Tunning StepsVinu3012Ainda não há avaliações
- Database Administration Lab ManualDocumento18 páginasDatabase Administration Lab ManualMehar AliAinda não há avaliações
- Lead2Pass - Latest Free Oracle 1Z0 060 Dumps (31 40) Download!Documento5 páginasLead2Pass - Latest Free Oracle 1Z0 060 Dumps (31 40) Download!aaAinda não há avaliações
- Understanding Performance Tuning in OracleDocumento17 páginasUnderstanding Performance Tuning in Oracleramesh158100% (1)
- ServiceNow Performance ReviewDocumento26 páginasServiceNow Performance ReviewRizwanAinda não há avaliações
- Oracle Realtests 1z0-067 v2015-03-08 by Rene 176qDocumento97 páginasOracle Realtests 1z0-067 v2015-03-08 by Rene 176qmosesAinda não há avaliações
- QueryTuning V2Documento8 páginasQueryTuning V2Lakshminarayana SamaAinda não há avaliações
- Oracle Tips and TricksDocumento28 páginasOracle Tips and TricksanandAinda não há avaliações
- PT Vol1-2 PDFDocumento100 páginasPT Vol1-2 PDFshafeeq1985gmailAinda não há avaliações
- Performacne - Tuning - Vol1 (Unlock) - 3Documento50 páginasPerformacne - Tuning - Vol1 (Unlock) - 3ChristianQuirozPlefkeAinda não há avaliações
- Oracle Database Performance Tuning: Presented by - Rahul GaikwadDocumento42 páginasOracle Database Performance Tuning: Presented by - Rahul Gaikwadthamizh karuvoolamAinda não há avaliações
- Cache Hit RatioDocumento3 páginasCache Hit Ratiogurukarthick_dbaAinda não há avaliações
- DbaDocumento29 páginasDbadbareddyAinda não há avaliações
- Advanced Database Administration IDocumento9 páginasAdvanced Database Administration Iمحمد الحامدAinda não há avaliações
- Purging Statistics From The SYSAUX TablespaceDocumento5 páginasPurging Statistics From The SYSAUX Tablespacef_isdnAinda não há avaliações
- Performance Check ListDocumento2 páginasPerformance Check ListJayendra TripathiAinda não há avaliações
- Performance TuningDocumento38 páginasPerformance TuningAnweshKota100% (1)
- Anthony - Awr Report InterpretationDocumento17 páginasAnthony - Awr Report InterpretationPraveen KumarAinda não há avaliações
- TeraData DBADocumento7 páginasTeraData DBAavinashkakarlaAinda não há avaliações
- AWR Architecture: - V$Sess - Time - Model V$Sys - Time - Model - V$Active - Session - History - V$Sysstat V$SesstatDocumento11 páginasAWR Architecture: - V$Sess - Time - Model V$Sys - Time - Model - V$Active - Session - History - V$Sysstat V$SesstatThoufic SAinda não há avaliações
- Technical Skills Enhancement - PL/SQL Best Practices Oracle ArchitectureDocumento35 páginasTechnical Skills Enhancement - PL/SQL Best Practices Oracle ArchitectureHuynh Sy NguyenAinda não há avaliações
- Oracle SQL Tuning - File IO PerformanceDocumento6 páginasOracle SQL Tuning - File IO Performancelado55Ainda não há avaliações
- SQLDocumento3 páginasSQLNagarajuAinda não há avaliações
- What Is Mutating Trigger?: Test Empno Test 1001Documento24 páginasWhat Is Mutating Trigger?: Test Empno Test 1001shAinda não há avaliações
- Database Health CheckDocumento6 páginasDatabase Health CheckJennifer NorrisAinda não há avaliações
- Reading Statspack ReportDocumento24 páginasReading Statspack Reportravtank1982_28100% (1)
- Stored ProcedureDocumento16 páginasStored ProcedurePrasanga WdzAinda não há avaliações
- Oracle InterviewDocumento13 páginasOracle Interviewsubash pradhanAinda não há avaliações
- Oracle - Database - Health - Check PDFDocumento14 páginasOracle - Database - Health - Check PDFmca_javaAinda não há avaliações
- 1Z0-062 - Oracle Database 12cinstallation and AdministrationDocumento146 páginas1Z0-062 - Oracle Database 12cinstallation and Administrationjavier100% (3)
- ORACLE Database Health - Query TunningDocumento55 páginasORACLE Database Health - Query TunningRishi MathurAinda não há avaliações
- Oracle - Passit4sure.1z0 062.v2015!04!04.by - Concetta.189qDocumento85 páginasOracle - Passit4sure.1z0 062.v2015!04!04.by - Concetta.189qdinhnguyenngocAinda não há avaliações
- Oracle 11g New Tuning Features: Donald K. BurlesonDocumento36 páginasOracle 11g New Tuning Features: Donald K. BurlesonSreekar PamuAinda não há avaliações
- Stored Procedures - IDocumento6 páginasStored Procedures - INitin PatelAinda não há avaliações
- SAS Programming Guidelines Interview Questions You'll Most Likely Be AskedNo EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be AskedAinda não há avaliações
- Oracle Database Administration Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo EverandOracle Database Administration Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNota: 5 de 5 estrelas5/5 (1)
- SAS Interview Questions You'll Most Likely Be AskedNo EverandSAS Interview Questions You'll Most Likely Be AskedAinda não há avaliações
- ToadforOracle 12.1 DBASuiteRACInstallationGuideDocumento22 páginasToadforOracle 12.1 DBASuiteRACInstallationGuideMuhammadAinda não há avaliações
- Oracle 11g New Features Student GuideDocumento591 páginasOracle 11g New Features Student GuideMuhammadAinda não há avaliações
- Configuration of SAP NetWeaver For Oracle 10gDocumento70 páginasConfiguration of SAP NetWeaver For Oracle 10gManish TalrejaAinda não há avaliações
- We Know They KnowDocumento6 páginasWe Know They KnowMuhammadAinda não há avaliações
- Running SAP R/3 On Oracle 9.2 Real Application Clusters at ABBDocumento15 páginasRunning SAP R/3 On Oracle 9.2 Real Application Clusters at ABBMuhammadAinda não há avaliações
- SAP How To Step by Step Guide With Screen ShotDocumento8 páginasSAP How To Step by Step Guide With Screen ShotMuhammadAinda não há avaliações
- BWP SB Solutions On LinuxDocumento4 páginasBWP SB Solutions On LinuxMuhammadAinda não há avaliações
- Codex Standard For Boiled Dried Salted Anchovies CODEX STAN 236-2003Documento6 páginasCodex Standard For Boiled Dried Salted Anchovies CODEX STAN 236-2003henryAinda não há avaliações
- Berna1Documento4 páginasBerna1Kenneth RomanoAinda não há avaliações
- Reflection Week 3 - The Sensible ThingDocumento3 páginasReflection Week 3 - The Sensible Thingtho truongAinda não há avaliações
- Course Outline BA301-2Documento4 páginasCourse Outline BA301-2drugs_182Ainda não há avaliações
- VBH - Pull Handle - FramelessDocumento10 páginasVBH - Pull Handle - FramelessgoreechongAinda não há avaliações
- NCP-26 Construction Project Management TechniquesDocumento32 páginasNCP-26 Construction Project Management TechniquesVivek Rai100% (1)
- Chapter 2 - Consumer Behavior - Market SegmentationDocumento26 páginasChapter 2 - Consumer Behavior - Market SegmentationAhmed RaufAinda não há avaliações
- Batch Controller LH SeriesDocumento1 páginaBatch Controller LH SeriesakhlaquemdAinda não há avaliações
- Forecasting TechniquesDocumento38 páginasForecasting TechniquesNazia ZebinAinda não há avaliações
- Status Report Cbms 2020Documento20 páginasStatus Report Cbms 2020Lilian Belen Dela CruzAinda não há avaliações
- GRADES 1 To 12 Daily Lesson Log Monday Tuesday Wednesday Thursday FridayDocumento4 páginasGRADES 1 To 12 Daily Lesson Log Monday Tuesday Wednesday Thursday FridayAILEEN GALIDOAinda não há avaliações
- DLL Araling Panlipunan 3 q4 w3Documento3 páginasDLL Araling Panlipunan 3 q4 w3Jessica Agbayani CambaAinda não há avaliações
- Comparative Law Comparative Jurisprudence Comparative LegislationDocumento5 páginasComparative Law Comparative Jurisprudence Comparative LegislationShubhamSudhirSrivastavaAinda não há avaliações
- Effect of Hamstring Emphasized Resistance Training On H-Q Strength RatioDocumento7 páginasEffect of Hamstring Emphasized Resistance Training On H-Q Strength RatioRaja Nurul JannatAinda não há avaliações
- Argumentative Essay TemplateDocumento4 páginasArgumentative Essay Template민수Ainda não há avaliações
- Introduction To Media ART: Course: History of Media Art Instructor: Zeib JahangirDocumento17 páginasIntroduction To Media ART: Course: History of Media Art Instructor: Zeib JahangirLiaqat AleeAinda não há avaliações
- Loss Prevention PresentationDocumento46 páginasLoss Prevention PresentationThanapaet RittirutAinda não há avaliações
- The Universe ALWAYS Says YES - Brad JensenDocumento15 páginasThe Universe ALWAYS Says YES - Brad JensenNicole Weatherley100% (3)
- z80 LH0080 Tech ManualDocumento25 páginasz80 LH0080 Tech ManualAnonymous 8rb48tZSAinda não há avaliações
- Lab Report Physics FinalDocumento5 páginasLab Report Physics FinalJahrel DaneAinda não há avaliações
- Garcia Status and Implementation of Disaster Risk ReductionDocumento30 páginasGarcia Status and Implementation of Disaster Risk ReductionShen-shen Tongson Madreo-Mas Millado100% (1)
- Them As Foreigners': Theme 2: OtherizationDocumento3 páginasThem As Foreigners': Theme 2: OtherizationNastjaAinda não há avaliações
- FCOE Directory 2015-16Documento196 páginasFCOE Directory 2015-16Cheryl WestAinda não há avaliações
- 0401110Documento66 páginas0401110HomeAinda não há avaliações
- Trionic 7Documento126 páginasTrionic 7Adrian100% (1)
- Toeic 1Documento28 páginasToeic 1Jordan Antoneo ToelleAinda não há avaliações
- Project Management Methodologies and ConceptsDocumento24 páginasProject Management Methodologies and ConceptsrnvvprasadAinda não há avaliações
- Univariate Homework 2 (1) CompletedDocumento6 páginasUnivariate Homework 2 (1) CompletedNytaijah McAuleyAinda não há avaliações
- Assignment 2 - Written Intentions - Selecting A Reading/Writing PlaceDocumento1 páginaAssignment 2 - Written Intentions - Selecting A Reading/Writing PlaceDipu GeorgeAinda não há avaliações
- r050210803 Chemical Process CalculationsDocumento8 páginasr050210803 Chemical Process CalculationsSrinivasa Rao GAinda não há avaliações