Você também pode gostar
- Edgar Acuña - Mas Teoria No ParametricaDocumento19 páginasEdgar Acuña - Mas Teoria No ParametricaLucia Rimachi SialerAinda não há avaliações
- Geometric modeling in computer: Aided geometric designNo EverandGeometric modeling in computer: Aided geometric designAinda não há avaliações
- 05 - Estimacion Local Leccion VulcanDocumento92 páginas05 - Estimacion Local Leccion VulcanYorky Edgardo Castillo50% (2)
- Problemas resueltos de electromagnetismo. Volumen I: ElectrostáticaNo EverandProblemas resueltos de electromagnetismo. Volumen I: ElectrostáticaAinda não há avaliações
- 1.09 The Kernel TrickDocumento9 páginas1.09 The Kernel TrickMartín CoronelAinda não há avaliações
- Minería de Datos KNN Vecinos más próximos clasificaciónDocumento8 páginasMinería de Datos KNN Vecinos más próximos clasificaciónJuliana Della CecaAinda não há avaliações
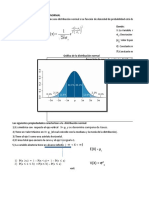
- La Distribución Normal PDFDocumento23 páginasLa Distribución Normal PDFfelipe_cruzpAinda não há avaliações
- Clase-Support Vector MachineDocumento22 páginasClase-Support Vector MachineJuan PabloAinda não há avaliações
- Clase 06Documento28 páginasClase 06Leonardo AlvaradoAinda não há avaliações
- QFC T1Documento9 páginasQFC T1raul reyesAinda não há avaliações
- UNLP AA 4.2 K-MeansDocumento25 páginasUNLP AA 4.2 K-MeansMaría EugeniaAinda não há avaliações
- Aprendizaje Supervisado: Clasificación KNN: Dra. Dulce RiveroDocumento57 páginasAprendizaje Supervisado: Clasificación KNN: Dra. Dulce RiveroJuan ChimarroAinda não há avaliações
- PRESENTACIÓNDocumento46 páginasPRESENTACIÓNCristhian Lenin Mata CabanaAinda não há avaliações
- Algoritmo Optimizacion No Lineal Sin Restricciones MA 33ADocumento14 páginasAlgoritmo Optimizacion No Lineal Sin Restricciones MA 33AMilton TorresAinda não há avaliações
- NormaDocumento6 páginasNormaHOLAAinda não há avaliações
- Cluster 1Documento41 páginasCluster 1tcbazsAinda não há avaliações
- La Varianz1Documento3 páginasLa Varianz1FranklinCruzVillegasAinda não há avaliações
- Implementación Algoritmo GN Ajuste Circunferencia CDocumento4 páginasImplementación Algoritmo GN Ajuste Circunferencia CPedro Fabrizio Zavaleta MatíasAinda não há avaliações
- Practica 3Documento5 páginasPractica 3Alejandro LorAinda não há avaliações
- Optimización sin restricciones en funciones de varias variablesDocumento11 páginasOptimización sin restricciones en funciones de varias variablesradioactiveAinda não há avaliações
- Proyecto Final-Matematicas DiscretasDocumento22 páginasProyecto Final-Matematicas DiscretasAletse Solano HermidaAinda não há avaliações
- Espacio SDocumento10 páginasEspacio SJesus SalvadorAinda não há avaliações
- Apuntes Unid. 6 - Probabilidad y Estadistica Erick Ricardo Leon Yuri)Documento14 páginasApuntes Unid. 6 - Probabilidad y Estadistica Erick Ricardo Leon Yuri)Erick YuriAinda não há avaliações
- Cluaster AnálisisDocumento25 páginasCluaster AnálisisAlejandro Antonio Lopez GaitanAinda não há avaliações
- Guia de Practica.Documento5 páginasGuia de Practica.Santos PavaAinda não há avaliações
- Maquina de Soporte VectorialDocumento10 páginasMaquina de Soporte VectorialAngel Alberto Vargas CanoAinda não há avaliações
- Sem 2 GraficasDocumento7 páginasSem 2 GraficasLeonardo LujanAinda não há avaliações
- SL IiiDocumento17 páginasSL Iiifernanda gaticaAinda não há avaliações
- Distribución NormalDocumento17 páginasDistribución NormalAndy Soto100% (1)
- Ejercicios Resueltos #1-Unidad IIIDocumento4 páginasEjercicios Resueltos #1-Unidad IIIHary Mora MendiolaAinda não há avaliações
- Física II - 4° Trabajo PrácticoDocumento6 páginasFísica II - 4° Trabajo PrácticoJoaquina CastroAinda não há avaliações
- Tema 1.2 - Normas matricialesDocumento15 páginasTema 1.2 - Normas matricialesPablo MenéndezAinda não há avaliações
- Metodos AlcubierreDocumento22 páginasMetodos AlcubierreCarlos MillanAinda não há avaliações
- Practica de Computo CientificoDocumento5 páginasPractica de Computo CientificoYadhyra Itzel EstradaAinda não há avaliações
- Unidad 4 Métodos de Optimización Sin RestriccionesDocumento12 páginasUnidad 4 Métodos de Optimización Sin RestriccionesJeikel JosueAinda não há avaliações
- Programacion ConicaDocumento6 páginasProgramacion ConicaUlises ArayaAinda não há avaliações
- AgrupamientosDocumento8 páginasAgrupamientoskorteturtoAinda não há avaliações
- Algebra de EstructurasDocumento8 páginasAlgebra de EstructuraseleannybmAinda não há avaliações
- Minimización de energía molecularDocumento18 páginasMinimización de energía molecularKarla Sanchez del AngelAinda não há avaliações
- TAREA 3 OptimizaciónDocumento11 páginasTAREA 3 OptimizaciónLaura Rodriguez CoronaAinda não há avaliações
- Analisis ClusterDocumento20 páginasAnalisis ClusterFERNANDO FERNANDEZ-PEDRAZAAinda não há avaliações
- Viga 2d Fem Ejemplo 1p5Documento17 páginasViga 2d Fem Ejemplo 1p5Canchari Gutiérrez EdmundoAinda não há avaliações
- Notas regreNoPara y SemiParaEstudiantesDocumento138 páginasNotas regreNoPara y SemiParaEstudiantesTeodocio Olivares ItzelAinda não há avaliações
- Optimizacion - Newton - Raphson PDFDocumento12 páginasOptimizacion - Newton - Raphson PDFCarlos Eduardo Paiva MariáteguiAinda não há avaliações
- Optimizacion VectorialDocumento32 páginasOptimizacion VectorialjoelAinda não há avaliações
- Aplicacion de La InterpolacionDocumento6 páginasAplicacion de La InterpolacionArabere MePox0% (2)
- Solución numérica de ecuaciones algebraicasDocumento23 páginasSolución numérica de ecuaciones algebraicasValeria VelazquezAinda não há avaliações
- Trabajo FinalDocumento21 páginasTrabajo FinalJose Armando Ricalde PalaciosAinda não há avaliações
- 2.1 Introduction To Matlab 2021-2Documento35 páginas2.1 Introduction To Matlab 2021-2brayan virguezAinda não há avaliações
- Demostraciones Principales Metnum v2Documento13 páginasDemostraciones Principales Metnum v2Agus SierraAinda não há avaliações
- Semana 3 Refuerzo 3CC FisicaDocumento4 páginasSemana 3 Refuerzo 3CC FisicaJorge Hernán Esparza CórdovaAinda não há avaliações
- DERIVADASDocumento28 páginasDERIVADASJosé PérezAinda não há avaliações
- Trabajo de Variables Aleatorias (Metodo Directo - Aceptacion Rechazo)Documento7 páginasTrabajo de Variables Aleatorias (Metodo Directo - Aceptacion Rechazo)Luis Antonio Cornejo Olivera100% (1)
- Algoritmo KNNDocumento4 páginasAlgoritmo KNNAnderson Arango RAinda não há avaliações
- Informe de Distri - NormalDocumento12 páginasInforme de Distri - NormalGreys VillaAinda não há avaliações
- K Vecinos Más PróximosDocumento4 páginasK Vecinos Más PróximosJuan ZapataAinda não há avaliações
- Análisis de una viga mediante el método de elementos finitos en MatlabDocumento20 páginasAnálisis de una viga mediante el método de elementos finitos en MatlabFelipe V. FuentesAinda não há avaliações
- MaxwellDocumento49 páginasMaxwellIgnacio BarríaAinda não há avaliações
- Clasificadores KNNDocumento3 páginasClasificadores KNNMauro Muñoz MedinaAinda não há avaliações
- Articulo Sistema de Proteccion SismicaDocumento37 páginasArticulo Sistema de Proteccion SismicaDiseño de ProyectosAinda não há avaliações
- Direccion Hidraulica ManualDocumento0 páginaDireccion Hidraulica Manualgeorgeus2967% (3)
- Manual de Ingenierias en La EdificacionDocumento131 páginasManual de Ingenierias en La EdificacionJorge Abraham DevoAinda não há avaliações
- Ejercicios Cinetica, Estequiometria y Diseño BiorreactoresDocumento2 páginasEjercicios Cinetica, Estequiometria y Diseño Biorreactoresantonioch3003Ainda não há avaliações
- Módulo La Hora 4 BásicoDocumento10 páginasMódulo La Hora 4 BásicoKathy TapiaAinda não há avaliações
- Ciclo de Vida de La EdificaciónDocumento9 páginasCiclo de Vida de La EdificaciónJavier Barona100% (1)
- QuicliaDocumento14 páginasQuicliaFernando Rivera HuaytallaAinda não há avaliações
- PEC 2 Ciencia de MaterialesDocumento10 páginasPEC 2 Ciencia de MaterialesNiggafart dotcomAinda não há avaliações
- Estructuras de AceroDocumento9 páginasEstructuras de AceroJacs AlexAinda não há avaliações
- Flexible 2Documento55 páginasFlexible 2Felicitas OriPerú PilarAinda não há avaliações
- Ambientes de Trabajo III Ventilacion IasDocumento278 páginasAmbientes de Trabajo III Ventilacion IasMora Lorena Ruiz100% (3)
- Expresiones Regulares en JSDocumento3 páginasExpresiones Regulares en JSpatAinda não há avaliações
- Diagramas de fase I: conceptos básicos y clasificación de aleacionesDocumento10 páginasDiagramas de fase I: conceptos básicos y clasificación de aleacionesEfraín MagosAinda não há avaliações
- Lab 14 HidrroDocumento10 páginasLab 14 HidrroKevin Soller CardenasAinda não há avaliações
- Reglas Básicas para Un Mejor Desalado de Aceite CrudoDocumento27 páginasReglas Básicas para Un Mejor Desalado de Aceite CrudoJuanAndresMedina100% (1)
- Exposion Geotecnia.Documento5 páginasExposion Geotecnia.Edwin Centeno FloresAinda não há avaliações
- 01-Estudio de Mejora de Eficiencia Energética en Instalaciones FrigoríficasDocumento14 páginas01-Estudio de Mejora de Eficiencia Energética en Instalaciones FrigoríficasaparherAinda não há avaliações
- Manual Yamaha Yzf r1Documento106 páginasManual Yamaha Yzf r1ordep2012100% (1)
- Fisica II - FotocopiadoraDocumento7 páginasFisica II - FotocopiadoraJohn Hower Mamani AyqueAinda não há avaliações
- Memoria Descriptiva para SubDocumento2 páginasMemoria Descriptiva para SubCarlos DominguezAinda não há avaliações
- Manual de CordovaDocumento11 páginasManual de CordovaOliver Tom100% (1)
- PromartDocumento2 páginasPromartCarlos Trejo GuerraAinda não há avaliações
- Fundamento TeoricoDocumento13 páginasFundamento Teoricovaras123Ainda não há avaliações
- Fase 4. Trabajo Individual Modelacion AmbientalDocumento10 páginasFase 4. Trabajo Individual Modelacion AmbientalYekaAinda não há avaliações
- Gráfico de control Xbarra-R para análisis de datos de calidad en sucursalesDocumento11 páginasGráfico de control Xbarra-R para análisis de datos de calidad en sucursalesRocío leónAinda não há avaliações
- Emergencias 19 Al 31 de Diciembre 2022Documento180 páginasEmergencias 19 Al 31 de Diciembre 2022Ferchand EncisoAinda não há avaliações
- Super Fácil Antena VHF 1Documento4 páginasSuper Fácil Antena VHF 1panaqueespiAinda não há avaliações
- Telnet SSHDocumento14 páginasTelnet SSHJeison VargasAinda não há avaliações
- Examen Parcial I Pavimentos UcvDocumento2 páginasExamen Parcial I Pavimentos UcvErik Jhan Armas FloresAinda não há avaliações
- Tasaciones ChileDocumento69 páginasTasaciones ChileRegularización Concón100% (1)