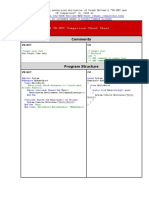
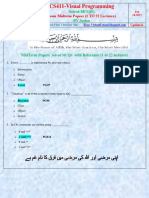
Você também pode gostar
- Assignment: R Q, There Exists A SequeneDocumento1 páginaAssignment: R Q, There Exists A SequeneMirza Ahad BaigAinda não há avaliações
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNo EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNota: 4 de 5 estrelas4/5 (5795)
- Master All Economics 4th EdDocumento280 páginasMaster All Economics 4th EdMirza Ahad BaigAinda não há avaliações
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNo EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNota: 4 de 5 estrelas4/5 (895)
- Iol 2014 Indiv Prob - en UsDocumento5 páginasIol 2014 Indiv Prob - en UsMirza Ahad BaigAinda não há avaliações
- The Yellow House: A Memoir (2019 National Book Award Winner)No EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Nota: 4 de 5 estrelas4/5 (98)
- Haskell Assignment 2Documento1 páginaHaskell Assignment 2Mirza Ahad BaigAinda não há avaliações
- Naclo 2014 Round 1Documento28 páginasNaclo 2014 Round 1Mirza Ahad BaigAinda não há avaliações
- The Little Book of Hygge: Danish Secrets to Happy LivingNo EverandThe Little Book of Hygge: Danish Secrets to Happy LivingNota: 3.5 de 5 estrelas3.5/5 (400)
- International Organisations - CLATGyanDocumento6 páginasInternational Organisations - CLATGyanMirza Ahad BaigAinda não há avaliações
- The Emperor of All Maladies: A Biography of CancerNo EverandThe Emperor of All Maladies: A Biography of CancerNota: 4.5 de 5 estrelas4.5/5 (271)
- LU UG - Admission - Brochure PDFDocumento28 páginasLU UG - Admission - Brochure PDFMirza Ahad BaigAinda não há avaliações
- Never Split the Difference: Negotiating As If Your Life Depended On ItNo EverandNever Split the Difference: Negotiating As If Your Life Depended On ItNota: 4.5 de 5 estrelas4.5/5 (838)
- AMU Ba Syllabus.Documento5 páginasAMU Ba Syllabus.Mirza Ahad BaigAinda não há avaliações
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyNo EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyNota: 3.5 de 5 estrelas3.5/5 (2259)
- Static General Knowledge - I PDFDocumento15 páginasStatic General Knowledge - I PDFMirza Ahad Baig100% (5)
- Users Manual For VRP Spreadsheet Solver v2.1Documento18 páginasUsers Manual For VRP Spreadsheet Solver v2.1Nathan HarmanAinda não há avaliações
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNo EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNota: 4.5 de 5 estrelas4.5/5 (474)
- JavaDocumento69 páginasJavaJohn David100% (1)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNo EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNota: 3.5 de 5 estrelas3.5/5 (231)
- Array: B. Javascript Array Directly (New Keyword)Documento4 páginasArray: B. Javascript Array Directly (New Keyword)DrAmit Kumar ChandananAinda não há avaliações
- Team of Rivals: The Political Genius of Abraham LincolnNo EverandTeam of Rivals: The Political Genius of Abraham LincolnNota: 4.5 de 5 estrelas4.5/5 (234)
- Approval Framework (AWE) Configuring To Be Site SpecificDocumento22 páginasApproval Framework (AWE) Configuring To Be Site Specificparthd21Ainda não há avaliações
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNo EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNota: 4.5 de 5 estrelas4.5/5 (266)
- (Computer Applications) SyllabusDocumento12 páginas(Computer Applications) SyllabusAnonymous bU1Ke2Ainda não há avaliações
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNo EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNota: 4.5 de 5 estrelas4.5/5 (345)
- Gulbarga University BBM SyllabusDocumento59 páginasGulbarga University BBM SyllabusNag28raj50% (6)
- C Programming LanguageDocumento22 páginasC Programming LanguageMadhu MidhaAinda não há avaliações
- The Unwinding: An Inner History of the New AmericaNo EverandThe Unwinding: An Inner History of the New AmericaNota: 4 de 5 estrelas4/5 (45)
- Declare OpenSTAADDocumento34 páginasDeclare OpenSTAADAnonymous JZFSB3DAinda não há avaliações
- CheatSheet C# Vs VBdoc PDFDocumento16 páginasCheatSheet C# Vs VBdoc PDFRastateAinda não há avaliações
- What Are Arrays in JavaScriptDocumento9 páginasWhat Are Arrays in JavaScriptMiguel LoureiroAinda não há avaliações
- Nota Tecnica WonderwareDocumento3 páginasNota Tecnica WonderwarerodrigofmarquesAinda não há avaliações
- Swift Notes For ProfessionalsDocumento289 páginasSwift Notes For ProfessionalskriAinda não há avaliações
- Python For Data Science - Unit 4 - Week 2Documento6 páginasPython For Data Science - Unit 4 - Week 2Shashikant Kale100% (1)
- UCCD1024 Lecture2 ArrayDocumento26 páginasUCCD1024 Lecture2 Array添シュン Ice lemonAinda não há avaliações
- FNT Software Solutions Placement PapersDocumento8 páginasFNT Software Solutions Placement PapersfntsofttechAinda não há avaliações
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNo EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNota: 4 de 5 estrelas4/5 (1090)
- UNIT-1 OBJECT ORIENTED THINKING: Need For OOP Paradigm, OOP ConceptsDocumento33 páginasUNIT-1 OBJECT ORIENTED THINKING: Need For OOP Paradigm, OOP ConceptsGopi KrishnaAinda não há avaliações
- 4.1 Programming and Iterative, Evolutionary Development: Chapter 4: ImplementationDocumento31 páginas4.1 Programming and Iterative, Evolutionary Development: Chapter 4: ImplementationSawn HotAinda não há avaliações
- Java NotesDocumento35 páginasJava NotesNavyaAinda não há avaliações
- Programming in Perl: Randy Julian Lilly Research LaboratoriesDocumento17 páginasProgramming in Perl: Randy Julian Lilly Research Laboratoriespsahu2011Ainda não há avaliações
- Python Interview Questions and Answers For 2019 - IntellipaatDocumento25 páginasPython Interview Questions and Answers For 2019 - IntellipaatVinod BawaneAinda não há avaliações
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)No EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Nota: 4.5 de 5 estrelas4.5/5 (121)
- E ScriptDocumento328 páginasE ScriptArminto_sanAinda não há avaliações
- Six Weeks Summer Training On C ProgrammingDocumento17 páginasSix Weeks Summer Training On C ProgrammingSOHAIL PATHANAinda não há avaliações
- Course Ada AdvancedDocumento93 páginasCourse Ada AdvancedDavid BriggsAinda não há avaliações
- BlackCat USB Script FunctionsDocumento9 páginasBlackCat USB Script FunctionsCraig SpencerAinda não há avaliações
- Chapter 7Documento34 páginasChapter 7WeeHong NgeoAinda não há avaliações
- CS411MidTermMCQsWithReferenceSolvedByArslan PDFDocumento65 páginasCS411MidTermMCQsWithReferenceSolvedByArslan PDFMuhammad Usman100% (1)
- CPPS LAB 15 SolutionsDocumento11 páginasCPPS LAB 15 SolutionsJoyceAinda não há avaliações
- Netlinx Programming LanguageDocumento246 páginasNetlinx Programming Languageharminder ratraAinda não há avaliações
- MongoDB MCQDocumento26 páginasMongoDB MCQArun Kumar100% (1)
- 2 Lecture 2 - Strings and FunctionsDocumento33 páginas2 Lecture 2 - Strings and FunctionsReuel Patrick CornagoAinda não há avaliações