Você também pode gostar
- Native Shader Compilation With LLVM PDFDocumento37 páginasNative Shader Compilation With LLVM PDFthi minh phuong nguyenAinda não há avaliações
- Quiz For Chapter 2 With SolutionsDocumento7 páginasQuiz For Chapter 2 With Solutionsnvdangdt1k52bk03100% (1)
- Unit Iii Data-Level Parallelism in Vector, Simd, and Gpu ArchitecturesDocumento26 páginasUnit Iii Data-Level Parallelism in Vector, Simd, and Gpu ArchitecturesShwetaAinda não há avaliações
- Micro Final TestDocumento6 páginasMicro Final TestKayshan RaajAinda não há avaliações
- Microprocessor ManualDocumento73 páginasMicroprocessor ManualVishal NaikAinda não há avaliações
- CPE 221 Test 2 Solution Spring 2019Documento5 páginasCPE 221 Test 2 Solution Spring 2019Kyra LathonAinda não há avaliações
- Program For ADC 0808 Connecting Temperature Sensor Using 8051Documento13 páginasProgram For ADC 0808 Connecting Temperature Sensor Using 8051Kishore KumarAinda não há avaliações
- C ProgrammingDocumento53 páginasC Programmingphanduy1310Ainda não há avaliações
- Lecture 4 Program Loops and ArraysDocumento50 páginasLecture 4 Program Loops and ArraysAnonymous E9ySJLqsAinda não há avaliações
- Lab Manual 5Documento7 páginasLab Manual 5Fouji 1998Ainda não há avaliações
- 7-VECTOR PROCESSING-04-Jan-2020Material - I - 04-Jan-2020 - VECTOR - PROCESSING PDFDocumento31 páginas7-VECTOR PROCESSING-04-Jan-2020Material - I - 04-Jan-2020 - VECTOR - PROCESSING PDFANTHONY NIKHIL REDDYAinda não há avaliações
- Sas ExamDocumento7 páginasSas Examlanka.cnuAinda não há avaliações
- LCD Interfacing With Embedded CDocumento3 páginasLCD Interfacing With Embedded CatharvAinda não há avaliações
- Experiment No 1: 1. Study of Arm Evaluation SystemDocumento30 páginasExperiment No 1: 1. Study of Arm Evaluation SystemAshok KumarAinda não há avaliações
- Instruction Set ArchitectureDocumento8 páginasInstruction Set ArchitecturekalpanasripathiAinda não há avaliações
- Assembly First ExamDocumento4 páginasAssembly First ExamDu B TramAinda não há avaliações
- ES FinalDocumento26 páginasES FinalBilal AhmedAinda não há avaliações
- Aditya College of Engineering &technology: III-B.Tech: II-Sem (Documento86 páginasAditya College of Engineering &technology: III-B.Tech: II-Sem (Chaitanya KaisarlaAinda não há avaliações
- Instruction Set: Operand NotationDocumento90 páginasInstruction Set: Operand NotationSeahJiaChenAinda não há avaliações
- Embedded System Design: Lab Manual 2011-12Documento35 páginasEmbedded System Design: Lab Manual 2011-12prajkumar324Ainda não há avaliações
- HW10 11Documento3 páginasHW10 11Robert RobinsonAinda não há avaliações
- Assembly LanguageDocumento7 páginasAssembly LanguageDilip JhaAinda não há avaliações
- Midterm Exam1 - 2020-2021 - Model AnswerDocumento2 páginasMidterm Exam1 - 2020-2021 - Model AnswerKhaled HeshamAinda não há avaliações
- CSE 30321 - Lecture 02-03 - in Class Example Handout: Discussion - Overview of Stored ProgramsDocumento8 páginasCSE 30321 - Lecture 02-03 - in Class Example Handout: Discussion - Overview of Stored ProgramsSandipChowdhuryAinda não há avaliações
- CSC3201 - Compiler Construction (Part II) - Lecture 5 - Code GenerationDocumento64 páginasCSC3201 - Compiler Construction (Part II) - Lecture 5 - Code GenerationAhmad AbbaAinda não há avaliações
- EmbeddedDocumento6 páginasEmbeddedAshutosh MishraAinda não há avaliações
- Asm AsmblerDocumento93 páginasAsm AsmblerstormviruxAinda não há avaliações
- CPE 221 Test 1 Solution Spring 2016Documento4 páginasCPE 221 Test 1 Solution Spring 2016Kyra LathonAinda não há avaliações
- Fetch Write Back Decode Issue: Practise QuestionDocumento3 páginasFetch Write Back Decode Issue: Practise QuestionHelliousAinda não há avaliações
- Answers 2 Reviews and ExercisesDocumento26 páginasAnswers 2 Reviews and ExercisesNaw Safrin SattarAinda não há avaliações
- Verilog Session 1,2,3Documento68 páginasVerilog Session 1,2,3Santhos KumarAinda não há avaliações
- Programming PIC PeripheralsDocumento44 páginasProgramming PIC PeripheralsSreekesh ManipuzhaAinda não há avaliações
- JCOMPDocumento22 páginasJCOMPAMIT VERMAAinda não há avaliações
- Chapter 15 - Exercises - Reduced Instruction Set ComputersDocumento6 páginasChapter 15 - Exercises - Reduced Instruction Set ComputersNguyen Quang ChienAinda não há avaliações
- Instruction SetDocumento58 páginasInstruction SetZ libAinda não há avaliações
- Lec13 X86asmDocumento71 páginasLec13 X86asmmeowmeow88Ainda não há avaliações
- A First C Program: Department of Computer and Information Science, School of Science, IUPUIDocumento14 páginasA First C Program: Department of Computer and Information Science, School of Science, IUPUIAnjali NaiduAinda não há avaliações
- Pertemuan 7 Bahasa Rakitan: III: Matakuliah: T0324 / Arsitektur Dan Organisasi Komputer Tahun: 2005 Versi: 1Documento30 páginasPertemuan 7 Bahasa Rakitan: III: Matakuliah: T0324 / Arsitektur Dan Organisasi Komputer Tahun: 2005 Versi: 1Ten Dian Novita SariAinda não há avaliações
- HW 2 Is Out! Due 9/25!Documento21 páginasHW 2 Is Out! Due 9/25!tauqeerahmadpk786Ainda não há avaliações
- CD Unit 5 RVDocumento23 páginasCD Unit 5 RVAkashAinda não há avaliações
- Lab04 CADocumento5 páginasLab04 CALama ImamAinda não há avaliações
- Verilog HDL Introduction: ECE 554 Digital Engineering LaboratoryDocumento79 páginasVerilog HDL Introduction: ECE 554 Digital Engineering LaboratoryBbsn EmbeddedAinda não há avaliações
- Tcs Questions With Answers: Note To The StudentsDocumento55 páginasTcs Questions With Answers: Note To The StudentsPuneethAinda não há avaliações
- AT - Better C Code For ARM DevicesDocumento30 páginasAT - Better C Code For ARM DevicesjvgediyaAinda não há avaliações
- 09 - Sequential LogicDocumento13 páginas09 - Sequential LogickAinda não há avaliações
- MES Lab ManualDocumento77 páginasMES Lab ManualNavya MAinda não há avaliações
- FOP Question PaperDocumento2 páginasFOP Question PapernajoshiAinda não há avaliações
- CSEN701 PA5 Solution 27551 29906Documento5 páginasCSEN701 PA5 Solution 27551 29906no nameAinda não há avaliações
- CS401 ProbvDocumento11 páginasCS401 Probvaamir shahzad khanAinda não há avaliações
- ARM Instruction SetDocumento32 páginasARM Instruction SetLordwin MichealAinda não há avaliações
- Delhi Public School Navi Mumbai Revision Examination 2016-17. I. Answer The Following QuestionsDocumento10 páginasDelhi Public School Navi Mumbai Revision Examination 2016-17. I. Answer The Following QuestionsShrey PanditAinda não há avaliações
- Class 12 Computer Science Solved Sample Paper 1 - 2012Documento18 páginasClass 12 Computer Science Solved Sample Paper 1 - 2012cbsestudymaterialsAinda não há avaliações
- CH 16Documento11 páginasCH 16Ankur SinghAinda não há avaliações
- VLSI Lab Manual Exercise ProblemsDocumento38 páginasVLSI Lab Manual Exercise ProblemsPrakhar Kumar100% (1)
- Data Transfer and Arithmetic InstructionsDocumento6 páginasData Transfer and Arithmetic InstructionsAkshaya ThirumalairajAinda não há avaliações
- Dynamic ProgrammingDocumento28 páginasDynamic ProgrammingAmisha SharmaAinda não há avaliações
- Projects With Microcontrollers And PICCNo EverandProjects With Microcontrollers And PICCNota: 5 de 5 estrelas5/5 (1)
- Whitebook EcommerceDocumento50 páginasWhitebook EcommercesoklaykyAinda não há avaliações
- Resume Deepti KelaDocumento4 páginasResume Deepti KelamdkamalAinda não há avaliações
- Resume Ashwani MishraDocumento8 páginasResume Ashwani Mishramdkamal0% (1)
- WelcomLetter New SPLDocumento2 páginasWelcomLetter New SPLmdkamalAinda não há avaliações
- JAX RS Security CZJUG ShortDocumento48 páginasJAX RS Security CZJUG Shortmigg_gAinda não há avaliações
- Building REST Services With SpringDocumento46 páginasBuilding REST Services With SpringPham Van ThuanAinda não há avaliações
- VLSI Design-Debaprasad Das - (Ecerelatedbooks - Blogspot.in) PDFDocumento669 páginasVLSI Design-Debaprasad Das - (Ecerelatedbooks - Blogspot.in) PDFTHE GAMING CHANNELAinda não há avaliações
- GSM Based Implementation of RFID Authentication Protocol Using ARMDocumento3 páginasGSM Based Implementation of RFID Authentication Protocol Using ARMerpublicationAinda não há avaliações
- Iptv - RTMP RTSP HLSDocumento9 páginasIptv - RTMP RTSP HLSpjvlenterprisesAinda não há avaliações
- BT-2xx ONU Configuration ManualDocumento13 páginasBT-2xx ONU Configuration ManualJhon Edwin CordobaAinda não há avaliações
- Ipad and Ipad Pro vs. MacBook and MacBook Pro - Which Should You Buy - IMoreDocumento21 páginasIpad and Ipad Pro vs. MacBook and MacBook Pro - Which Should You Buy - IMoreFILESONICAinda não há avaliações
- Cobol Programming Guide - Igy5pg20Documento910 páginasCobol Programming Guide - Igy5pg20viriathvsAinda não há avaliações
- Computers GenerationsDocumento7 páginasComputers GenerationsBubrikaAinda não há avaliações
- BZT52C2V4Documento3 páginasBZT52C2V4Fikri HidayatAinda não há avaliações
- DAGDocumento30 páginasDAGKrishAinda não há avaliações
- Star Delta Transformation: Dr.V.Joshi ManoharDocumento14 páginasStar Delta Transformation: Dr.V.Joshi ManoharhariAinda não há avaliações
- Exam 350-401 - Pg11Documento4 páginasExam 350-401 - Pg11Info4 DetailAinda não há avaliações
- Product Information: SIMATIC S7-200 EM231, EM232, EM235 Analog Input and Output Modules ReleaseDocumento13 páginasProduct Information: SIMATIC S7-200 EM231, EM232, EM235 Analog Input and Output Modules ReleaseLuisAinda não há avaliações
- ReadmeDocumento6 páginasReadmebetabloqueanteAinda não há avaliações
- CompTIA Network+ Certification Passport, 7th Edition Exam N10 008Documento449 páginasCompTIA Network+ Certification Passport, 7th Edition Exam N10 008Dhanraj chavan100% (3)
- Kubernetes Full INSAT's CourseDocumento55 páginasKubernetes Full INSAT's CourseHAMDI GDHAMIAinda não há avaliações
- 3102213-En FW-UL6W FireWorks Workstation Installation ManualDocumento62 páginas3102213-En FW-UL6W FireWorks Workstation Installation ManualTrung Thành VõAinda não há avaliações
- Workbench External Connection Add-InDocumento118 páginasWorkbench External Connection Add-InAmeerSaadAinda não há avaliações
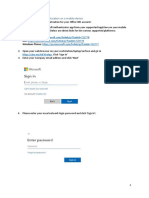
- Office 365 Multi Factor Authentication Setup GuideDocumento7 páginasOffice 365 Multi Factor Authentication Setup Guideit cleancoAinda não há avaliações
- CV 2022 PratikshaDocumento6 páginasCV 2022 Pratikshavijay sharmaAinda não há avaliações
- BSSPAR Chapter 05 Power Control MODocumento18 páginasBSSPAR Chapter 05 Power Control MOSamir MezouarAinda não há avaliações
- C QuestionDocumento65 páginasC QuestionJamuna12Ainda não há avaliações
- Vlsi Digital Design IssuesDocumento94 páginasVlsi Digital Design Issuesraghava06Ainda não há avaliações
- Get Current Location From Best Available Provider - Stack OverflowDocumento4 páginasGet Current Location From Best Available Provider - Stack Overflowjayanth3dAinda não há avaliações
- 74LS194 MotorolaDocumento4 páginas74LS194 MotorolawolfstarprojectsAinda não há avaliações
- Gujarat Technological UniversityDocumento2 páginasGujarat Technological UniversityMihir RanaAinda não há avaliações
- Emerson Automated Patch Management ServiceDocumento8 páginasEmerson Automated Patch Management ServicebioAinda não há avaliações
- Features General Description: High Performance Single Synchronous Buck Converter GS7317Documento1 páginaFeatures General Description: High Performance Single Synchronous Buck Converter GS7317Imma Real Pcy50% (2)
- ICT Summative Assessment 1Documento2 páginasICT Summative Assessment 1Zapirah Nirel LayloAinda não há avaliações
- Maasai Mara University: Answer Question ONE and Any Other TWODocumento3 páginasMaasai Mara University: Answer Question ONE and Any Other TWOAlbert OmondiAinda não há avaliações
- Automatic Stabilization of Zigbee Network: Guanghui Pan Jia HeDocumento4 páginasAutomatic Stabilization of Zigbee Network: Guanghui Pan Jia HeEdgar A.BAinda não há avaliações