Escolar Documentos
Profissional Documentos
Cultura Documentos
Tema 1
Enviado por
Juan Ramon JMTítulo original
Direitos autorais
Formatos disponíveis
Compartilhar este documento
Compartilhar ou incorporar documento
Você considera este documento útil?
Este conteúdo é inapropriado?
Denunciar este documentoDireitos autorais:
Formatos disponíveis
Tema 1
Enviado por
Juan Ramon JMDireitos autorais:
Formatos disponíveis
Tema 1
Estad
stica Descriptiva
Indice
1. Introducci
on
2. Datos agrupados y sin agrupar
3. Distribuciones de frecuencias
4. Representaciones gr
aficas
4.1. Polgonos de frecuencias
4.2. Histogramas . . . . . . .
4.3. Diagrama de Pareto . .
4.4. Diagrama de sectores . .
.
.
.
.
5
6
6
7
8
5. Medidas de centralizaci
on
5.1. Media aritmetica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.2. Moda . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.3. Mediana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
9
9
10
11
6. Medidas de dispersi
on
6.1. Recorrido . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.2. Varianza, cuasivarianza, desviacion tpica y cuasidesviacion tpica
6.3. Cuantiles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
6.4. Coeficiente de variacion . . . . . . . . . . . . . . . . . . . . . . .
12
13
13
14
17
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
7. Bibliografa
1.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
17
Introducci
on
El conjunto de individuos (objetos, personas, valores de magnitudes fsicas...) en cuyo estudio nos interesamos, se llama poblaci
on. Usualmente la poblacion es tan grande, que para ese estudio debemos
conformarnos, por razones materiales o economicas, con considerar solo una parte de la misma a la que
llamamos muestra.
El aspecto de los individuos de la poblacion que queremos investigar, se llama car
acter. Por ejemplo la
estatura, el diametro, el color..., y para efectuar el estudio, hacemos observaciones de ese caracter sobre
los individuos de la muestra.
Un caracter puede ser cualitativo o cuantitativo, la diferencia es, que en el primer caso, el resultado
de la observacion no es cuantificable numericamente, por ejemplo el color, el sexo..., y en el segundo, por
el contrario, la observacion es una medida cuyo resultado es numerico, como la estatura o la resistencia
electrica. En todo caso, llamaremos dato a cualquiera de los resultados individuales obtenido.
Un estudio estadstico comienza con una primera fase de recogida de datos de la muestra elegida. La
eleccion de esa muestra debe hacerse de tal forma, que el estudio hecho sobre ella pueda extenderse con
1
Tema 1. Estadstica descriptiva
un amplio margen de confianza a toda la poblacion. Ello obliga a que la eleccion de la muestra se haga
de acuerdo con ciertas reglas que son el objeto de estudio de la teora del muestreo.
Despues de la recogida de los datos, se inicia un proceso de elaboracion de estos, ordenandolos, clasificandolos, haciendo graficos y calculando promedios, porcentajes y otras cantidades u
tiles. Esta fase es
conocida como estadstica descriptiva.
Por u
ltimo, y esta es quiza la etapa mas interesante, se pretende, a partir de los datos recogidos en la
muestra, extrapolar conclusiones para toda la poblacion, lo que permitira entre otras cosas, una posterior
toma de decisiones. Esta u
ltima fase se conoce como estadstica inferencial.
2.
Datos agrupados y sin agrupar
Sean n individuos de la poblacion a los que se les mide el caracter X (variable o atributo). X esta constituida por n valores, resultantes de la observacion de dicho caracter sobre los n individuos:
X1 , X2 , X3 , . . . , Xn
Usualmente, los caracteres cualitativos toman pocos valores distintos. Por ejemplo el caracter ((sexo)) solo
toma dos valores. Lo mismo ocurre con algunos caracteres cuantitativos como el ((n
umero de ni
nos nacidos
en un mismo parto)), que puede variar entre 1 y 5, (no consideraremos por lo insolito del caso, n
umeros
mayores) siendo los valores 3, 4 y 5, muy poco frecuentes.
Por el contrario, hay caracteres cuantitativos que pueden tomar muchos valores distintos. Ejemplo de ello
es el caracter ((estatura)) en una poblacion de personas, en el que si se aprecia, como es usual, hasta el
centmetro, pueden darse hasta 41 valores distintos entre, digamos un mnimo de 1,50 m. y un maximo
de 1,90 m.
Llamemos x1 , x2 , x3 , . . . , xk (k 6 n) a los datos distintos obtenidos de la muestra (modalidades). Si k es
peque
no, para describir el conjunto de datos, basta con anotar junto a los x1 , x2 , x3 , . . . , xk , el n
umero de
veces que aparece cada uno. Pero si k es grande, la manipulacion de muchos datos distintos es incomoda,
procediendose (siempre y cuando el caracter a estudiar sea cuantitativo) a agruparlos.
En lneas generales, el procedimiento para ello, consiste en tomar el intervalo cuyos extremos son los datos
mas peque
no y mas grande respectivamente, y dividirlo en subintervalos contiguos de igual longitud, llamados clases. Los datos x1 , x2 , x3 , . . . , xk estaran distribuidos dentro de estas clases. Pero la subdivision
debe hacerse, para no incurrir en ambig
uedades, de tal modo que cada dato distinto, pertenezca a una y
solo una de las clases, es decir, hay que evitar que alguno de los puntos de subdivision coincida con un
dato, ya que ello inducira a confusion con respecto en cual de las dos clases contiguas debe incluirse.
En la practica, los extremos del intervalo que contiene todos los datos, no tiene por que coincidir con
el menor y el mayor de estos. Por ejemplo, si al medir estaturas, el dato mas peque
no recogido en la
muestra es 1,51 m., y el mas grande 1,87 m., es preferible tomar como intervalo a subdividir, el que tiene
por extremos 1,50 y 1,90, ya que resultan mas comodos de manejar los n
umeros cuya u
ltima cifra es 0 o
5. Pero en todo caso, este aumento en la longitud del intervalo, no debe ser excesivo, pues introducira
((espacios muertos)) que hara enga
noso el agrupamiento en clases.
Procedamos ahora a la subdivision, para lo cual comenzamos completando la parte decimal de los datos
con ceros (si ello fuere necesario), con objeto de que todos tengan la misma longitud. Sea d el n
umero de
cifras decimales una vez completadas. Sean tambien a y b, los extremos del intervalo, y p el n
umero de
clases en que se desea agrupar los datos.
La longitud de cada clase sera:
h=
ba
p
El n
umero h debe redondearse hasta la desima cifra decimal. Con ello se logra que los puntos de
subdivision
a = a + 0h, a + 1h, a + 2h, . . . , a + (p 1)h, a + ph = b
Tema 1. Estadstica descriptiva
tengan el mismo n
umero d de cifras decimales que los datos, pero entonces puede darse el caso de que
alguno de estos puntos coincida con un dato. Para evitar este inconveniente, disminuimos el extremo
derecho de cada clase en una unidad de la u
ltima cifra decimal (sera equivalente a tomar el intervalo
cerrado por la izquierda y abierto por la derecha).
Una vez que se han agrupado los datos en clases, estos pierden su individualidad. La u
nica informacion
que tenemos despues del agrupamiento es el n
umero de clases, los extremos de las mismas y el n
umero
de datos en cada una. Esta perdida de informacion es el tributo a pagar por la comodidad de manejar
unas pocas clases en lugar de un volumen, quiza elevado de datos individuales. Es conveniente, para
determinados calculos que se consideraran mas tarde, tener un n
umero que de alguna forma caracterice
a cada clase. Para ello, se calcula su punto central (es decir, la media aritmetica de los extremos), que se
llama representante o marca de esa clase.
Es de observar que el representante de una clase no tiene por que coincidir con un dato de la muestra.
Ademas, el hecho de tomar a este n
umero como una representacion de los ocupantes de la clase lleva
implcita la hipotesis (solo aproximadamente correcta) de que los datos se encuentran uniformemente
repartidos dentro de la clase. A
un no siendo cierta, la hipotesis es plausible si los datos de la muestra
presentan (como suele ocurrir) una relativa uniformidad en su distribucion.
Ejemplo: Vamos a agrupar los datos de la siguiente tabla (ya ordenados de menor a mayor) en clases.
3, 07
3, 35
3, 48
3, 54
3, 62
3, 69
3, 74
3, 83
3, 94
4, 05
3, 09
3, 35
3, 49
3, 55
3, 62
3, 69
3, 75
3, 83
3, 96
4, 06
3, 20
3, 40
3, 49
3, 55
3, 63
3, 70
3, 76
3, 85
3, 98
4, 07
3, 23
3, 41
3, 50
3, 55
3, 64
3, 70
3, 77
3, 87
3, 98
4, 13
3, 24
3, 41
3, 50
3, 56
3, 64
3, 70
3, 78
3, 88
3, 99
4, 18
3, 27
3, 42
3, 51
3, 57
3, 65
3, 70
3, 78
3, 90
4, 00
4, 22
3, 30
3, 43
3, 52
3, 60
3, 66
3, 70
3, 79
3, 90
4, 00
4, 27
3, 31
3, 46
3, 52
3, 60
3, 67
3, 71
3, 80
3, 90
4, 01
4, 29
3, 32
3, 46
3, 53
3, 60
3, 68
3, 71
3, 82
3, 91
4, 03
4, 35
3, 32
3, 46
3, 54
3, 61
3, 68
3, 71
3, 82
3, 93
4, 04
4, 47
Para ello, comenzamos ampliando ligeramente el intervalo cuyos extremos son el mas peque
no y el mayor
de los datos hasta que esos extremos sean 3,00 y 4,50, as trabajaremos con n
umeros cuya u
ltima cifra
es cero. La longitud de este intervalo es 1,50 que es divisible por 2, 3, 5, 6, 10 y 15 con un cociente que
tiene dos cifras decimales exactas. Como el n
umero de cifras decimales de los datos es tambien d = 2,
si tomamos como n
umero de clases p a uno de estos valores, no sera necesario redondear la longitud
h de cada clase para que tenga dos cifras decimales, lo cual siempre es mas comodo. Ahora elegimos
p descartando los valores 2, 3, 5 y 6 porque parecen pocas clases para el volumen de datos (100) que
tenemos. Tambien desechamos 15 porque sin ser demasiado elevado, tampoco es muy peque
no, as que
tomaremos p = 10. Usando las notaciones anteriores, tenemos
a = 3, 00
b = 4, 50
p = 10
h = 0, 15
y efectuando los calculos resulta:
Clase
[3, 00,
[3, 15,
[3, 30,
[3, 45,
[3, 60,
[3, 75,
[3, 90,
[4, 05,
[4, 20,
[4, 35,
3, 15)
3, 30)
3, 45)
3, 60)
3, 75)
3, 90)
4, 05)
4, 20)
4, 35)
4, 50)
Marca
3,075
3,225
3,375
3,525
3,675
3,825
3,975
4,125
4,275
4,425
d=2
Tema 1. Estadstica descriptiva
No hay un criterio objetivo para decidir en cuantas clases se deben agrupar los datos. Una regla emprica
que puede usarse es hallar las dos potencias sucesivas de 2 entre las que se encuentra n, y tomar como
valor
de p el mayor de los dos exponentes. Otra regla emprica sugiere que se tome para p el valor
n convenientemente redondeado a un entero. Tambien puede usarse la siguiente tabla basada en la
experiencia:
no de datos
no de clases
menos de 50
entre 50 y 99
entre 100 y 249
mas de 249
de 5 a 7
de 6 a 10
de 7 a 12
de 10 a 20
Sobre la clasificacion de datos, puede consultarse el segundo captulo del libro de Huntsberger citado en
la bibliografa.
3.
Distribuciones de frecuencias
Supongamos que al recoger datos relativos a un determinado caracter en una muestra de tama
no n, hemos
obtenido los valores distintos
x1 , x2 , x3 , . . . , xk
(k 6 n)
Admitamos que por ser k peque
no, no se ha juzgado oportuno agrupar los datos en clases.
Definici
on 3.1 Para cada dato xi (i = 1, 2, . . . , k), se llama:
a) frecuencia absoluta ni al n
umero de veces que aparece el dato xi
b) frecuencia relativa fi =
ni
ni
= k
n
X
nj
j=1
c) frecuencia absoluta acumulada Ni =
i
X
nj
j=1
i
d) frecuencia relativa acumulada Fi =
X
Ni
=
fj .
n
j=1
Caso de que por ser k grande (y naturalmente tratarse de un caracter cuantitativo), se haya optado por
agrupar los datos en p clases, podemos definir para la iesima clase
Definici
on 3.2 Para cada clase, se llama:
a) frecuencia absoluta ni al n
umero de datos de la iesima clase
b) frecuencia relativa fi =
ni
ni
= p
X
n
nj
j=1
c) frecuencia absoluta acumulada Ni =
i
X
nj
j=1
i
d) frecuencia relativa acumulada Fi =
X
Ni
=
fj .
n
j=1
Tema 1. Estadstica descriptiva
De ambas definiciones se deducen las desigualdades
a) 0 6 ni 6 n
d) 0 6 fi 6 1
b) 0 6 Ni 6 n
e) Ni 6 Ni+1
c) 0 6 Fi 6 1
A la frecuencia relativa se le llama algunas veces proporci
on, y suele expresarse como un porcentaje
multiplicandola previamente por 100. Tambien es corriente llamar a la frecuencia absoluta simplemente
frecuencia.
Definici
on 3.3 Se llama distribuci
on de frecuencias correspondiente al car
acter bajo estudio, a una
descripci
on, usualmente en forma de tabla, aunque tambien puede expresarse gr
aficamente, de los datos
distintos, o de las clases si se han agrupado, acompa
nados de sus respectivas frecuencias (absolutas,
relativas y/o acumuladas).
Ejemplos:
1. En la muestra formada por los nacimientos habidos en una maternidad durante diez a
nos, se ha
observado el caracter sexo de los recien nacidos, obteniendose la siguiente distribucion de frecuencias:
Sexo
Frecuencia
Hembra
Varon
2055
2180
2. En una muestra de 110 personas que han comprado una casa en determinada ciudad, se ha analizado la
variable edad agrupando los datos obtenidos en ocho clases. La correspondiente distribucion de frecuencias
es
Edad
18
33
38
43
48
53
58
62
4.
32
37
42
47
52
57
62
67
Frecuencia
5
10
10
30
35
10
8
2
Representaciones gr
aficas
Una forma muy com
un de exponer una distribucion de frecuencias es mediante una representacion grafica.
Existen muchas formas distintas de hacerlo, y en este aspecto entre cientfico y artstico, los trabajos
publicados de estadstica descriptiva exhiben multitud de variantes. Un buen ejemplo de ello son los
sondeos de opinion acerca de cualquier tema de interes general, y las encuestas de intencion de voto que
casi siempre en epocas preelectorales publican los periodicos.
Un grafico, sobre todo si esta bien elegido y dise
nado, proporciona una vision rapida y precisa de la
situacion. Su utilidad no solo se manifiesta en la exposicion de los resultados finales, sino que cada vez se
emplean mas para obtener una vision preliminar del comportamiento de los datos de nuestro problema,
su distribucion aproximada, su tendencia, sus valores extremos etc., detalles que nos indican hacia donde
podemos orientar el estudio. Este an
alisis exploratorio de datos que es como se conoce en la literatura
estadstica a esta y a otras tecnicas que nos aproximan al problema, se ha generalizado por la gran facilidad
de los paquetes estadsticos comerciales para trazar de manera rapida y sencilla una gran variedad de
graficos.
En esta leccion solo consideraremos algunos tipos de graficos que suelen ser los mas empleados. Para una
exposicion mas detallada puede consultarse el captulo primero del libro de Mendenhall referenciado en
la bibliografa.
Tema 1. Estadstica descriptiva
4.1.
Polgonos de frecuencias
El primero de ellos es el usual diagrama cartesiano. Se emplea cuando la variable es cualitativa o cuando
es cuantitativa pero no toma demasiados valores distintos. En el eje horizontal se representan los valores
de la variable, y en el vertical las respectivas frecuencias. Ello da origen a una representacion grafica
formada por puntos aislados, que para mejorar su aspecto, se unen mediante segmentos rectilneos. El
resultado es una lnea quebrada, y de ah el nombre polgono de frecuencias.
Figura 1: Ejemplo de polgono de frecuencias.
Ejemplo: Durante dos meses se ha contabilizado el n
umero de das de baja por enfermedad de una
muestra de 100 trabajadores de una empresa. Los resultados estan en la tabla que sigue
Das de baja
no de trabajadores
0
1
2
3
4
5
mas de 5
35
20
16
9
10
8
2
En la Figura 1 se muestra un polgono de frecuencias para estos datos.
4.2.
Histogramas
Cuando los datos estan agrupados en clases es preferible el empleo de una representacion llamada histograma constituida por rectangulos cuyas bases corresponden a la anchura de cada clase, y las alturas
a las respectivas frecuencias.
Ejemplo:
Los datos de la tabla que sigue son los tiempos en segundos de CPU (unidad central de procesos) de 25
trabajos realizados por un ordenador.
0, 02
1, 40
0, 15
1, 59
0, 19 0, 47
1, 61 1, 94
0, 71 0, 75 0, 82
2, 01 2, 16 2, 41
0, 92 0, 96
2, 59 3, 07
1, 16
3, 53
1, 17 1, 23
3, 76 4, 75
La correspondiente distribucion de frecuencias con los datos agrupados en 7 clases es
1, 38
Tema 1. Estadstica descriptiva
Clases
0,015
0,715
1,415
2,115
2,815
3,515
4,215
0,715
1,415
2,115
2,815
3,515
4,215
4,915
Frecuencias
5
9
4
3
1
2
1
En la Figura 2 se ha trazado el histograma correspondiente a esta distribucion de frecuencias.
Figura 2: Ejemplo de histograma. En el eje horizontal se han colocado los extremos de las
clases.
4.3.
Diagrama de Pareto
En problemas de control de calidad y de analisis de fallos en procesos, es frecuente el uso de diagramas
que reunen un histograma y un polgono de frecuencias, llamado diagrama de Pareto1 . En el los
rectangulos correspondientes a cada una de las clases estan colocados de izquierda a derecha en orden
de frecuencias decrecientes, y superpuesto se coloca un polgono de frecuencias relativas acumuladas. A
derecha e izquierda se situan ejes en los que se marcan las frecuencias absolutas y las frecuencias relativas
acumuladas respectivamente.
Aunque este tipo de diagrama puede usarse indistintamente para datos cuantitativos y cualitativos , se
prefiere su uso para estos u
ltimos.
Ejemplo: En un proceso de fabricacion de circutos integrados, las causas mas frecuentes de fallos son
las que se indican en la siguiente tabla junto con la frecuencia de cada una de ellas en una muestra de 31
circutos examinados
1 Vilfredo
Frederigo Samaso, Marqu
es de Pareto 18481923, soci
ologo y economista italiano.
Tema 1. Estadstica descriptiva
Causa de fallo
Frecuencia
corrosion
oxido
contaminacion
metalizacion
silicio
doping
varios
2
8
14
2
1
1
3
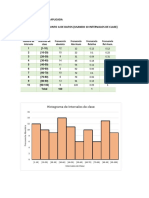
En la Figura 3 se ha trazado un diagrama de Pareto para estos datos. Observando el diagrama podemos
Figura 3: Ejemplo de diagrama de Pareto.
deducir que la contaminacion afecta a mas del 40 % de los circutos seguido del oxido que afecta a casi el
30 %. No se olvide que las alturas de los rectangulos (las frecuencias absolutas) se miden en el eje de la
izquierda, y la posicion de los puntos del polgono de frecuencias (las frecuencias relativas acumuladas),
se miden en el eje de la derecha.
4.4.
Diagrama de sectores
Si el caracter estudiado tiene pocos valores distintos (como suele ocurrir con los caracteres cualitativos)
se puede usar un diagrama en forma de crculo dividido en tantos sectores como datos distintos haya,
en el que el angulo de cada sector es proporcional a la frecuencia relativa del correspondiente dato. Esta
representaci
on grafica se denomina diagrama de sectores o diagrama de tarta. Tambien pueden
emplearse para datos cuantitativos agrupados en clases, y en tales casos, cada sector corresponde a una
clase. Dada la ndole de esta representaci
on, solo se utiliza para distribuciones de frecuencias relativas
usualmente expresadas en porcentajes.
Ejemplo: La encuesta de poblacion activa elaborada por el Instituto Nacional de Estadstica referente
al cuarto trimestre de 1970 presenta para el n
umero de empleados por rama de actividad los siguientes
datos
Tema 1. Estadstica descriptiva
Rama de actividad
Miles de empleados
Agricultura, caza y pesca
Fabriles
Construccion
Comercio
Transporte
Otros servicios
3706,3
3437,8
1096,3
1388,3
648,7
2454,8
En la Figura 4 se muestra un diagrama de sectores para esta distribucion de frecuencias.
Figura 4: Ejemplo de diagrama de sectores.
5.
Medidas de centralizaci
on
Con el nombre de medidas de centralizaci
on se denominan a determinados valores que, bien porque
ocupan posiciones centrales, o bien porque cerca de ellos se sit
uan un n
umero apreciable de datos,
((destacan)) en una distribucion de frecuencias. Estos valores son de alguna manera representativos de
toda la muestra y en ello estriba su interes. Piensese por ejemplo en las calificaciones obtenidas por una
persona en los distintos ejercicios que componen un examen. Para asignar una calificacion global a ese
examen, se toma la media aritmetica como una medida que en cierta forma representa y re
une en un solo
dato, las calificaciones parciales.
A continuacion pasamos a definir tres de esas medidas que son con mucho las mas importantes.
5.1.
Media aritm
etica
Definici
on 5.1 Si al medir un car
acter cuantitativo sobre los elementos de una muestra, obtenemos los
valores X1 , X2 , . . . , Xn , se llama media aritm
etica de la correspondiente distribuci
on de frecuencias a
n
x
=
1X
Xi
n i=1
Si consideramos los datos distintos x1 , x2 , . . . , xk (k 6 n) y sus respectivas frecuencias n1 , n2 , . . . , nk ,
podemos escribir
k
X
ni xi
n
1X
i=1
.
Xi = k
x
=
n i=1
X
ni
i=1
Tema 1. Estadstica descriptiva
10
Si los datos estan agrupados en p clases, y llamamos xi al representante de la i-esima clase, la media
aritmetica se define as
p
1X
x
=
ni xi
n i=1
Al hacer uso de xi estamos en la hipotesis de espaciado uniforme de los datos dentro de cada clase, lo que
no es en general cierto. Debido a ello, si en una muestra no agrupamos los datos y calculamos la media
aritmetica, el valor obtenido diferira ligeramente del que resultara con los mismos datos pero agrupados
en clases.
5.2.
Moda
Definici
on 5.2 Si los datos obtenidos de una muestra no est
an agrupados, se llama moda de la correspondiente distribuci
on de frecuencias al dato (o datos) de mayor frecuencia. La denotaremos por M o.
Se deduce de esta definicion que una distribucion de frecuencias puede tener mas de una moda, incluso
puede no tener ninguna, lo que ocurrira en el caso poco com
un de que todos los datos tuvieran igual
frecuencia.
Cuando los datos estan agrupados en clases, se define la clase modal exactamente de la misma forma, y
en algunas ocasiones, se llama moda al representante de la clase modal. No obstante, si las clases contiguas
hi hi+1
hi hi1
xi1
Li2
xi+1
xi
Li1
Li
Li+1
Mo
Figura 5: C
alculo aproximado de la moda.
a la clase modal no tienen igual frecuencia, parece conveniente tener en cuenta esta ((asimetra)), y tomar
como moda a un punto de la clase modal que este mas proximo a la clase contigua de mas frecuencia.
Supongamos que la longitud de los intervalos, ai = Li Li1 , i = 1, . . . , p, no es necesariamente
ni
de los intervalos en la Figura 5. De aqu se deduce que
constante y consideramos las alturas hi =
ai
Li M o
M o Li1
=
hi hi1
hi hi+1
y por lo tanto
Mo =
Li1 (hi hi+1 ) + Li (hi hi1 )
.
2hi hi1 hi+1
Tema 1. Estadstica descriptiva
11
Sustituyendo en la expresion anterior Li = ai + Li1 obtenemos
M o = Li1 +
hi hi1
ai .
2hi hi1 hi+1
ni
En el caso en que todos los intervalos tienen la misma longitud ai = a, se tiene entonces que hi = ,
a
y por tanto
ni ni1
M o = Li1 +
a.
2ni ni1 ni+1
Ejemplos:
a) En la siguiente distribucion de frecuencias
dato
frecuencia
1
3
2
4
3
3
4
2
5
1
7
1
9
4
se observa que hay dos modas, que son los datos 2 y 9.
b) La duracion en horas, agrupadas en clases, de una muestra de focos se expone en la siguiente tabla
duraci
on
frecuencias
duracion
frecuencias
9501050
10501150
11501250
12501350
13501450
14501550
4
9
19
36
51
58
15501650
16501750
17501850
18501950
19502050
20502150
53
37
20
9
3
1
De la observacion de la tabla se deduce que la clase modal, que en este caso es u
nica, es la sexta, ya que
su frecuencia f6 = 58 es la mayor de todas. Para calcular aproximadamente la moda de la distribucion,
teniendo en cuenta que la longitud de las clases es constante con a = 100, usando la formula que mostramos
antes para este caso se tiene
L6 = 1450
L7 = 1550
n5 = 51
n6 = 58
n7 = 53
luego
(58 51)100
= 1508, 33
2 58 51 53
Si hubiera mas clases modales, el calculo aproximado de las modas se hara aplicando este procedimiento
a cada una de dichas clases modales.
M o = 1450 +
5.3.
Mediana
Definici
on 5.3 Si al medir un car
acter cuantitativo sobre los elementos de una muestra, obtenemos un
n
umero impar de datos n, y los ordenamos de menor a mayor, se llama mediana al dato que ocupa el
lugar central, es decir al (n + 1)/2esimo. Si el n
umero de datos es par, se llama mediana a la media
arimetica de los dos datos que ocupan los lugares centrales. As si llamamos M e a la mediana, tenemos
X
si n es impar
(n+1)/2
Me =
Xn/2 + X(n+2)/2
si n es par
2
Si los datos no estan agrupados en clases, el calculo de la mediana se lleva a cabo mediante una simple
inspeccion de los datos ordenados, pero cuando los datos estan agrupados, para el calculo de la mediana
es preciso localizar aquella clase (digamos la iesima) que cumple las desigualdades
Ni1 <
n
2
Ni >
n
2
Tema 1. Estadstica descriptiva
12
Como la mediana es un n
umero menor (o igual) que la mitad de los datos y mayor (o igual) que la otra
mitad, debe encontrarse en esta iesima clase. Aceptando, como es habitual, la hipotesis de espaciado
n/2 datos
L1
L2
L3
Li1 M e Li
Ni1 datos
ni datos
Figura 6: C
alculo aproximado de la mediana.
uniforme de los datos dentro de cada clase, podemos plantear de acuerdo con la Figura 6 la siguiente
proporcionalidad
Li Li1
ni
= n
M e Li1
Ni1
2
de la que resulta
n
Ni1
(Li Li1 )
M e = Li1 + 2
ni
Dado que una vez mas hemos hecho la suposicion de que los datos se encuentran dentro de cada clase,
igualmente distribudos, el calculo de la mediana mediante este u
ltimo procedimiento diferira ligeramente
del que se obtendra sin proceder a la agrupacion de los datos.
Ejemplos:
a) Los n
umeros que siguen son valores de resistencias (en ohmios) de una muestra de veinte.
96
102
96 97
103 103
98
103
99
104
99
106
100
106
100
108
101
110
101
110
Dado que el n
umero de datos es par, la mediana es la media aritmetica de los dos centrales, es decir del
decimo y el undecimo:
101 + 102
Me =
= 101,5
2
b) En la siguiente tabla se encuentran agrupados en clases, los valores de la resistencia a la compresion
(en kg/cm3 ) de bloques de hormigon:
marcas de clase
200
225
250
275
300
325
350
375
400
425
450
475
500
frecuencias
10
19
17
11
Observemos que la frecuencia acumulada de la quinta clase es N5 = 30, y la de la sexta N6 = 49, luego
en esta u
ltima ha de estar la mediana, ya que la mitad del n
umero de datos es n/2 = 90/2 = 45. Los
lmites de la sexta clase son L6 = 312,5 y L7 = 337,5, y su frecuencia n6 = 19. Con toda esta informacion
podemos calcular la mediana por el procedimiento aproximado explicado mas arriba
M e ' 312,5 +
6.
45 30
(337,5 312,5) = 332,24
19
Medidas de dispersi
on
Contrariamente a las medidas de centralizacion que informan de la concentraci
on de los datos alrededor
de ciertos valores notables, las medidas de dispersi
on dan cuenta del esparcimiento que presentan tales
datos. La mas elemental de todas es la que definimos a continuacion
Tema 1. Estadstica descriptiva
6.1.
13
Recorrido
Definici
on 6.1 Si son X1 , X2 , . . . , Xn los datos cuantitativos y sin agrupar obtenidos de la muestra, y
llamamos Xmn e Xmax al m
as peque
no y al m
as grande de ellos, se llama recorrido a
R = Xmax Xmn
El recorrido es una medida muy facil de calcular, pero la informacion que da es de una utilidad relativa,
ya que es muy sensible a la presencia de un dato muy peque
no o muy grande. En efecto, en una situacion
en la que los datos estuvieran muy concentrados (es decir, hubiera poco esparcimiento) pero uno solo de
ellos estuviera muy alejado de los demas, tendramos un valor grande del recorrido estando sin embargo
los datos muy concentrados.
No obstante, si el n
umero de datos es peque
no, es poco probable que haya alguno muy distinto de los
demas, por lo que en aquellas aplicaciones en las que se utilicen muestras peque
nas, y sobre todo si
son muchas, como en las cartas de control usadas en el Control Estadstico de la Calidad, el recorrido
constituye una medida de dispersion u
til y comoda de calcular.
6.2.
Varianza, cuasivarianza, desviaci
on tpica y cuasidesviaci
on tpica
De uso mas com
un son las medidas de dispersion que involucran las desviaciones de los datos en torno a
ciertos valores ((centrales)) como la media aritmetica.
Consideremos de nuevo los datos cuantitativos distintos x1 , x2 , . . . , xk obtenidos de la muestra, y sea x
la media aritmetica. Se llama desviaci
on del iesimo dato a
di = xi x
i = 1, 2, . . . , k
Ahora bien, en cada muestra hay tantas desviaciones como datos distintos, lo que no es muy practico.
As que reuniendo la informacion proporcionada por las desviaciones en un solo n
umero para que resulte
mas manejable, definimos la desviaci
on media como la media aritmetica de las desviaciones:
k
1X
ni (xi x
)
n i=1
Pero la desviacion media siempre es cero como es facil comprobar:
k
1X
1X
1X
x
X
x
ni (xi x
) =
ni xi
ni x
=x
ni = x
n = 0.
n i=1
n i=1
n i=1
n i=1
n
Esta propiedad, debida a que las desviaciones positivas y negativas se compensan, la hace completamente
in
util. Podemos no obstante evitar esta dificultad si tomamos los valores absolutos de las desviaciones:
k
1X
ni |xi x
|
n i=1
Esta medida de dispersion informa del esparcimiento de los datos de la muestra promediando las dispersiones, y en ese sentido tiene interes. Ademas, a diferencia del recorrido, tiene en cuenta a todos los
datos, y no solo a los mas extremos, pero presenta el inconveniente de lo incomodo que resulta bajo el
punto de vista del calculo, el empleo de los valores absolutos.
Para superar esta u
ltima dificultad, reeemplazamos los valores absolutos por los cuadrados de las dispersiones resultando la siguiente
Definici
on 6.2 Se llama varianza de la muestra a
k
1X
ni (xi x
)2
s =
n i=1
2
Tema 1. Estadstica descriptiva
14
Se llama desviaci
on tpica de la muestra a:
v
u
k
u1 X
s=t
ni (xi x
)2
n i=1
La razon de considerar la desviacion tpica como medida de dispersion ademas de la varianza es que
aquella se mide en las mismas unidades que los datos de la muestra en tanto que la varianza se mide en
el cuadrado de esas unidades. Por eso, en ocasiones resulta mas descriptivo el empleo de la desviacion
tpica.
La varianza y la desviacion tpica son poco u
tiles para la inferencia estadstica. Ello es debido a que como
estimadores de la varianza y de la desviaci
on tpica de la poblaci
on, son sesgados. El significado de esta
u
ltima frase quedara claro al estudiar la Estadstica Inferencial. Cuando abordemos su estudio, necesitaremos unos conceptos muy similares a la varianza y a la desviacion tpica pero que como estimadores
sean insesgados, es por ello que definimos
Definici
on 6.3 Se llama cuasi varianza de la muestra a
k
s2c =
1 X
ni (xi x
)2
n 1 i=1
Se llama cuasi desviaci
on tpica de la muestra a:
v
u
k
u 1 X
sc = t
ni (xi x
)2
n 1 i=1
El denominador n de la varianza se explica porque la varianza es la media aritmetica de los cuadrados
de las desviaciones, pero no as la cuasi varianza que resulta por lo tanto menos intuitiva. La razon de
emplear el denominador n 1 en la cuasi varianza se pondra de manifiesto al estudiar la estadstica
inferencial. La relacion entre ambas esta dada por la igualdad
n
s2c =
s2
n1
6.3.
Cuantiles
Otras medidas de dispersion que vamos a considerar estan basadas en la misma idea que sirvio para
definir la mediana. Recordemos que esta es un n
umero por debajo del cual se encuentra la mitad de los
datos de la muestra. Se presentaba una disyuntiva entre si el n
umero de datos era par o impar, lo que
obligaba a considerar dos definiciones distintas. Pero nada de eso ocurra si los datos estaban agrupados en
clases, procediendose en tal caso al empleo de una formula aproximada. Para las medidas que definiremos
a continuacion, se presentan tambien diferentes posibilidades seg
un que el n
umero de datos sea o no
divisible por 4, pero el considerar las alternativas posibles complicara mucho la exposicion y hara poco
practicos los conceptos que se van a definir, de modo que de entrada partiremos de que los datos estan
agrupados en clases.
Busquemos aquel valor por debajo del cual se encuentra la cuarta parte de los datos. Para ello debemos
localizar el valor de i que cumple
n
n
y
Ni >
Ni1 <
4
4
el n
umero buscado tiene que encontrarse en la iesima clase. Si lo llamamos Q1 tenemos el esquema de
la Figura 7. Con respecto a tal figura, y en la hipotesis de espaciado uniforme de los datos dentro de
cada clase, podemos plantear la siguiente proporcionalidad
ni
Li Li1
= n
Q1 Li
Ni1
4
Tema 1. Estadstica descriptiva
15
n/4 datos
L1
L2
L3
Li1 q1
Ni1 datos
Li
ni datos
Figura 7: C
alculo del primer cuartil.
de la que resulta
n
Ni1
Q1 = Li1 + 4
(Li Li1 )
ni
De modo completamente analogo consideraramos el valor Q3 por debajo del cual se encuentran las tres
cuartas partes de los datos y definir
Definici
on 6.4 En una muestra de n datos, se llama:
a) primer cuartil
n
Ni1
(Li Li1 )
Q1 = Li1 + 4
ni
n
n
donde i es el n
umero que verifica Ni1 < y Ni >
4
4
b) tercer cuartil
3n
Ni1
Q3 = Li1 + 4
(Li Li1 )
ni
3n
3n
donde i es el n
umero que verifica Ni1 <
y Ni >
4
4
En esta definicion, Li1 y Li son los lmites de la iesima clase, y ni y Ni las frecuencias absoluta y
absoluta acumulada de la misma clase. Es evidente que el segundo cuartil es la mediana
Ejemplo:
Se elige una muestra de dispositivos electronicos de entre los producidos en una lnea de fabricacion, y se
mide para cada uno de ellos el tiempo transcurrido (en horas), entre dos fallos sucesivos. Los resultados,
agrupados en clases, se encuentran en la siguiente tabla
Tiempo entre fallos
N
umero de fallos
[0, 50)
[50, 100)
[100, 150)
[150, 200)
[200, 250)
[250, 300)
[300, 350)
[350, 400)
[400, 450)
3
7
13
18
22
21
12
8
1
N
umero de fallos acumulados
3
10
23
41
63
84
96
104
105
n
Puesto que n = 105, tenemos = 26, 25, as que el primer cuartil se encuentra en la cuarta clase, ya que
4
N3 = 23 < 26, 25 < 41 = N4 . Los lmites y la frecuencia de esa clase son L4 = 150, L5 = 200 y n4 = 18,
Tema 1. Estadstica descriptiva
16
as que el primer cuartil es
26, 25 23
(200 150) = 159, 03
18
Q1 = 150 +
Analogamente, el tercer cuartil es
78, 75 63
(300 250) = 287, 5
21
Esta definicion es susceptible de generalizacion de esta manera:
Q3 = 250 +
Definici
on 6.5 En una muestra de n datos, se llama j
esimo decil (j = 1, 2, . . . , 9) a
jn
Ni1
Dj = Li1 + 10
(Li Li1 )
ni
jn
jn
donde i es el n
umero que verifica Ni1 <
y Ni >
10
10
y tambien de esta otra
Definici
on 6.6 En una muestra de n datos, se llama j
esimo percentil (j = 1, 2, . . . 99) a
jn
Ni1
Pj = Li1 + 100
(Li Li1 )
ni
jn
jn
donde i es el n
umero que verifica Ni1 <
y Ni >
.
100
100
Ejemplos:
a) Calcular el septimo decil de la distribucion de frecuencias dada en la siguiente tabla
clases
frecuencias
[10, 25)
[25, 40)
[40, 55)
[55, 70)
[70, 85)
[85, 100)
15
25
42
50
38
30
jn
7 200
=
= 140. Observando la tabla podemos ver que
10
10
N4 = 132 < 140 < 170 = N5 , luego k = 5. Los lmites y la frecuencia absoluta de la quinta clase son
L5 = 70, L6 = 85, n5 = 38, con lo cual estamos en condiciones de calcular el decil pedido:
7 200
132
D7 = 70 + 10
(85 70) = 73, 16.
38
jn
32 200
b) Vamos ahora a calcular el 32 percentil de la misma distribucion. Tenemos que
=
= 64.
100
100
De la tabla se deduce que N2 = 40 < 64 < 82 = N3 , luego i = 3. Los lmites y la frecuencia absoluta de
la tercera clase son L3 = 40, L4 = 55, n3 = 42, as que podemos calcular el percentil pedido:
32 200
40
(55 40) = 48,57.
P32 = 40 + 100
42
Todas estas medidas (cuartiles, deciles y percentiles) reciben el nombre generico de cuantiles. De un
modo expresivo, pero sin mucha precision si el n
umero de datos es peque
no, podemos decir que el primer
cuartil es un n
umero por debajo del cual se halla el 25 % de los datos y por encima el 75 % restante.
Asimismo, el sexto decil es un n
umero por debajo del cual se encuentra el 60 % de los datos y por encima
el 40 % restante, y el 89 percentil, el n
umero por debajo del cual esta el 89 % de los datos y por encima
el restante 11 %.
El n
umero de datos es n = 200, de modo que
Tema 1. Estadstica descriptiva
6.4.
17
Coeficiente de variaci
on
Cuando se estudian los errores en las medidas, se emplea el error relativo para tener en cuenta no solo el
tama
nodel error (error absoluto) sino tambien el tama
node la medida, ya que un error de 10 en una
medida de 1000, supone un 1 % mientras que en una medida de 100 es un 10 %. De modo analogo, una
desviacion tpica de 10 en una muestra de media 1000 puede ser menos importante que en una muestra
de media 100. Por ello se define un concepto analogo al error relativo, y como el suele expresarse en
porcentajes despues de multiplicarlo por 100.
Definici
on 6.7 Se llama coeficiente de variaci
on (o de dispersi
on) de una muestra de media x
y
s
desviaci
on tpica s al cociente CV = .
x
El coeficiente de variacion es independiente de las unidades en que se hayan expresado los datos, por ello
puede usarse para comparar distribuciones de frecuencias cuyos datos esten en diferentes unidades.
Un inconveniente del coeficiente de variaci
on es que pierde su utilidad en distribuciones con media cercana
a cero.
7.
Bibliografa
Calot G. Curso de Estadstica Descriptiva. Paraninfo
Huntsberger D.V. y Billingsley P. Elementos de Estadstica Inferencial. Compa
nia Editorial Continental 1983.
Mendenhall W. y Sincich T. Probabilidad y Estadstica para Ingeniera y Ciencias (4a edicion).
Pearson Educacion 1995.
Spiegel M.R. Estadstica. McGraw-Hill. (Coleccion Schaum)
Walpole R.E., Myers R.H. y Myers, S. L. Probabilidad y Estadstica para Ingenieros (6a edicion).
Pearson Educacion 1998.
Você também pode gostar
- Analisis de RegresionDocumento13 páginasAnalisis de RegresionJuan Ramon JMAinda não há avaliações
- Control Estadístico de CalidadDocumento14 páginasControl Estadístico de CalidadJuan Ramon JMAinda não há avaliações
- Estadística - Estimacion y Pruebas de HipótesisDocumento21 páginasEstadística - Estimacion y Pruebas de HipótesisJuan Ramon JMAinda não há avaliações
- Estadística - Estimacion y Pruebas de HipótesisDocumento21 páginasEstadística - Estimacion y Pruebas de HipótesisJuan Ramon JMAinda não há avaliações
- Elasticidad y Resistencia de MaterialesDocumento30 páginasElasticidad y Resistencia de MaterialesJuan Ramon JMAinda não há avaliações
- Libro Elasticidad de MaterialesDocumento30 páginasLibro Elasticidad de MaterialesJuan Ramon JMAinda não há avaliações
- Combinatoria PDFDocumento5 páginasCombinatoria PDFpepefisicoAinda não há avaliações
- SABINADocumento2 páginasSABINAJuan Ramon JMAinda não há avaliações
- Led Regeneracion FAPDocumento8 páginasLed Regeneracion FAPJuan Ramon JMAinda não há avaliações
- ESTADISTICADocumento45 páginasESTADISTICARoemer Palomino EspiñalAinda não há avaliações
- Soluciones Actividad 2Documento8 páginasSoluciones Actividad 2julio césar quintero sánchezAinda não há avaliações
- Taller #2 G2 (Alpala, Cedeño, Garcia, Moyano, Santana)Documento38 páginasTaller #2 G2 (Alpala, Cedeño, Garcia, Moyano, Santana)Narci CedeñoAinda não há avaliações
- Cuestionario Sobre Medidas de VariabilidadDocumento20 páginasCuestionario Sobre Medidas de Variabilidadjean carlos abreuAinda não há avaliações
- Formulario - Estadística Descriptiva y ProbabilidadesDocumento3 páginasFormulario - Estadística Descriptiva y ProbabilidadesKIDO PÁAinda não há avaliações
- Taller Tranbersal de MatemáticaDocumento10 páginasTaller Tranbersal de Matemáticaeduar maldonadoAinda não há avaliações
- 2023 2PrimerEvaluacià NparcialDocumento2 páginas2023 2PrimerEvaluacià NparcialHector Toledano EspinosaAinda não há avaliações
- Practica 1 y 2Documento16 páginasPractica 1 y 2Jorge PumacotaAinda não há avaliações
- Actividad Distribución Normal, Angie GarzonDocumento7 páginasActividad Distribución Normal, Angie GarzonAngie Celeny GarzonAinda não há avaliações
- Teoria Unif Prob y Estadist. (Unid 1 A 10) PDFDocumento54 páginasTeoria Unif Prob y Estadist. (Unid 1 A 10) PDFSandra NataliaAinda não há avaliações
- Intervalos de ConfianzaDocumento8 páginasIntervalos de ConfianzaANDY STEVE GARATE HUAMANAinda não há avaliações
- Tarea 2 Gerencia FinancieraDocumento14 páginasTarea 2 Gerencia FinancieraJoseline QuintanillaAinda não há avaliações
- Examen Final Estadistica 2020Documento2 páginasExamen Final Estadistica 2020Antonio Bernal50% (2)
- Calidad (14,15,16,17)Documento15 páginasCalidad (14,15,16,17)Marcela ParraAinda não há avaliações
- Actividad de Variables Cuantitativas (Autos)Documento13 páginasActividad de Variables Cuantitativas (Autos)Carmen JimenezAinda não há avaliações
- 3 Tablas Bidimensionales - 2Documento16 páginas3 Tablas Bidimensionales - 2Joan GarcesAinda não há avaliações
- Medidas de DispersiónDocumento11 páginasMedidas de DispersiónEricka Diaz ChicahuariAinda não há avaliações
- Tarea 4 Estadistica1Documento10 páginasTarea 4 Estadistica1Wellington AcostaAinda não há avaliações
- Ejemplo de Cálculo de Medidas de Tendencia Central para Datos AgrupadosDocumento9 páginasEjemplo de Cálculo de Medidas de Tendencia Central para Datos AgrupadosDanAinda não há avaliações
- I.F Estadistica IDocumento4 páginasI.F Estadistica IAnonymous 6w5SkeAinda não há avaliações
- SpssBasico UnivariadaDocumento17 páginasSpssBasico Univariadarosario gago riosAinda não há avaliações
- Mega Pack Estadistica 1parcial 1 PDFDocumento120 páginasMega Pack Estadistica 1parcial 1 PDFEnrique Enriquez EstupiñanAinda não há avaliações
- Mary BartelDocumento2 páginasMary BartelAlejandro At100% (2)
- Estadist y Ciencias de Datos - 1-5Documento5 páginasEstadist y Ciencias de Datos - 1-5Claudia WavrenchukAinda não há avaliações
- Medidas de Posicion Parte I Exposicion de EstadisticaDocumento27 páginasMedidas de Posicion Parte I Exposicion de EstadisticaJesus GuilarteAinda não há avaliações
- Estadistica ExamenDocumento8 páginasEstadistica ExamenReyna LópezAinda não há avaliações
- Pratica #2 Movimiento en Plano InclinadoDocumento26 páginasPratica #2 Movimiento en Plano InclinadoDiana LópezAinda não há avaliações
- Tarea de Estadistica AplicadaDocumento3 páginasTarea de Estadistica AplicadaAlan CortesAinda não há avaliações
- Ejercicios Word 1bDocumento21 páginasEjercicios Word 1bJULIAN Neira50% (2)