Você também pode gostar
- Las Quarter 2 Empowerment Technology Week 1Documento6 páginasLas Quarter 2 Empowerment Technology Week 1Ruben Rosendal De Asis100% (5)
- Total Supra DMLDocumento17 páginasTotal Supra DMLTube10 rAinda não há avaliações
- System Design SpecificationDocumento8 páginasSystem Design Specificationapi-278499472Ainda não há avaliações
- Title Search Engine: Submitted in Partial Fulfillment For The Award of DegreeDocumento40 páginasTitle Search Engine: Submitted in Partial Fulfillment For The Award of DegreevineetkanwatAinda não há avaliações
- Naman Internship Project (1) (1) PrintDocumento57 páginasNaman Internship Project (1) (1) Printprahlad kumarAinda não há avaliações
- ACN PracticalsDocumento61 páginasACN Practicalskrupanick24Ainda não há avaliações
- Web & Desktop Application DevelopmentDocumento10 páginasWeb & Desktop Application DevelopmentИн ВестAinda não há avaliações
- Bus Reservation System WebBased ApllicationDocumento73 páginasBus Reservation System WebBased ApllicationVaibhav0% (1)
- Eshopping ProjectDocumento49 páginasEshopping ProjectGyanendra SharmaAinda não há avaliações
- Simon-Game: Integrated Project ReportDocumento13 páginasSimon-Game: Integrated Project ReportBhumika Sharma2626100% (1)
- Introduction To C++Documento33 páginasIntroduction To C++Roshan ShawAinda não há avaliações
- What Is HTMLDocumento181 páginasWhat Is HTMLQamar ZamanAinda não há avaliações
- 1.1. Background: Chapter 1: IntroductionDocumento21 páginas1.1. Background: Chapter 1: IntroductionDhiraj JhaAinda não há avaliações
- Online Pet Shop Management SystemDocumento49 páginasOnline Pet Shop Management SystemVENNILA G MCAAinda não há avaliações
- Smart Note TakerDocumento19 páginasSmart Note TakerNamithaAinda não há avaliações
- Web Development ReportDocumento23 páginasWeb Development Reportpratiksha24Ainda não há avaliações
- Web-Development ToC PDFDocumento3 páginasWeb-Development ToC PDFRitik GuptaAinda não há avaliações
- PDF Ebooks PHP EbookDocumento34 páginasPDF Ebooks PHP EbookBasant PaliwalAinda não há avaliações
- CG PDFDocumento63 páginasCG PDFVarnakeepcreating Varna100% (1)
- INNOVATIVE PROJECT On PORTFOLIODocumento14 páginasINNOVATIVE PROJECT On PORTFOLIONeha SinghAinda não há avaliações
- Dot Net Frame WorkDocumento9 páginasDot Net Frame WorksefAinda não há avaliações
- Week 8 ActivityDocumento1 páginaWeek 8 ActivityDanny MannoAinda não há avaliações
- Chat App ReportDocumento21 páginasChat App Reportpravesh yadavAinda não há avaliações
- Attendance Management System in Java With Source Code - Source Code & ProjectsDocumento6 páginasAttendance Management System in Java With Source Code - Source Code & ProjectsAbdiket Kumsa Gudeta100% (1)
- BSIT (Morning) Final Year Projects Proposal Evaluation ReportDocumento3 páginasBSIT (Morning) Final Year Projects Proposal Evaluation ReportZeeshan BhattiAinda não há avaliações
- Introduction To Assembly Language ProgrammingDocumento27 páginasIntroduction To Assembly Language ProgrammingKa Tze TingAinda não há avaliações
- NET E-Business ArchitectureDocumento689 páginasNET E-Business ArchitecturealfiettaAinda não há avaliações
- M.Tech CSE 3rd Sem Introduction To Block Chain Unit 1 Lecture NotesDocumento39 páginasM.Tech CSE 3rd Sem Introduction To Block Chain Unit 1 Lecture Notesrupak05Ainda não há avaliações
- PHP SyllabusDocumento13 páginasPHP Syllabussenthil_suruliAinda não há avaliações
- An Overview and Study of Security Issues & Challenges in Cloud ComputingDocumento6 páginasAn Overview and Study of Security Issues & Challenges in Cloud ComputingRoyal TAinda não há avaliações
- S.R. Smart Note Taker (5-...... )Documento27 páginasS.R. Smart Note Taker (5-...... )Dhiraj TekadeAinda não há avaliações
- Data Structure and Algorithm ReportDocumento22 páginasData Structure and Algorithm ReportAmarjit KumarAinda não há avaliações
- News Paper AppDocumento58 páginasNews Paper AppRàjput Atul SinghAinda não há avaliações
- 2082 - Unit 4 Notes WT (BCA 204)Documento26 páginas2082 - Unit 4 Notes WT (BCA 204)DhananjayKumarAinda não há avaliações
- Virtual Assistant: Project Bachelor of Technology CSEDocumento11 páginasVirtual Assistant: Project Bachelor of Technology CSESantanu DassAinda não há avaliações
- PHP - Project TitlesDocumento7 páginasPHP - Project TitlesBharath KalyanAinda não há avaliações
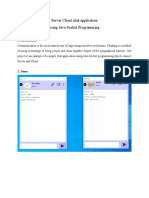
- Server Client Chat ApplicationDocumento5 páginasServer Client Chat ApplicationBích NgọcAinda não há avaliações
- Experiment No. - 1: Design PHP Based Web Pages Using Correct PHP, CSS, and XHTML Syntax, StructureDocumento6 páginasExperiment No. - 1: Design PHP Based Web Pages Using Correct PHP, CSS, and XHTML Syntax, StructureAkash PariharAinda não há avaliações
- Web Services On Mobile Platform DocumentationDocumento18 páginasWeb Services On Mobile Platform Documentationmukesh427100% (4)
- Web Development Using PHPDocumento51 páginasWeb Development Using PHPSrinidhi UpadhyaAinda não há avaliações
- Star UMLDocumento24 páginasStar UMLTirumala Placement Cell-hydAinda não há avaliações
- Online Crime Report Final DocumentationDocumento92 páginasOnline Crime Report Final DocumentationWaris Awais100% (1)
- Design ER Diagram For Library: A Micro Project OnDocumento14 páginasDesign ER Diagram For Library: A Micro Project OnVirendra NawkarAinda não há avaliações
- Mobile Computing Lab ManualDocumento64 páginasMobile Computing Lab Manualvishnu91_k100% (2)
- Computer Graphics - OpenglDocumento150 páginasComputer Graphics - Openglapoorvs75Ainda não há avaliações
- WEB PROGRAMMING I Course NotesDocumento129 páginasWEB PROGRAMMING I Course NotesBahtinyuy CliffordAinda não há avaliações
- DocumentationDocumento23 páginasDocumentationAmmuAinda não há avaliações
- Web Technologies 0108Documento15 páginasWeb Technologies 0108Tracey JonesAinda não há avaliações
- HTML Project Report: RestaurantDocumento9 páginasHTML Project Report: RestaurantSandeep ChowdaryAinda não há avaliações
- Web Designing and Development Training Courses in Pune - TIPDocumento6 páginasWeb Designing and Development Training Courses in Pune - TIPudayAinda não há avaliações
- 6th Sem Basic of .Net Kuvempu UniversityDocumento11 páginas6th Sem Basic of .Net Kuvempu Universitymofid khanAinda não há avaliações
- Advanced Database Systems Chapter 2Documento16 páginasAdvanced Database Systems Chapter 2Jundu OmerAinda não há avaliações
- InfyTQ DBMS Lecture Session 1Documento35 páginasInfyTQ DBMS Lecture Session 1Akash JinturkarAinda não há avaliações
- Python Project Music SystemDocumento34 páginasPython Project Music SystemAyush Dubey100% (1)
- Project On Web DevelopmentDocumento13 páginasProject On Web DevelopmentArnav LekharaAinda não há avaliações
- Ty B.C.A. Sem V..Documento17 páginasTy B.C.A. Sem V..coolnycilAinda não há avaliações
- Computer GraphicsDocumento40 páginasComputer Graphicsanchitkharbanda0% (1)
- Understanding the Internet: A Glimpse into the Building Blocks, Applications, Security and Hidden Secrets of the WebNo EverandUnderstanding the Internet: A Glimpse into the Building Blocks, Applications, Security and Hidden Secrets of the WebAinda não há avaliações
- Drupal for Education and E-Learning - Second EditionNo EverandDrupal for Education and E-Learning - Second EditionAinda não há avaliações
- Network Management System A Complete Guide - 2020 EditionNo EverandNetwork Management System A Complete Guide - 2020 EditionNota: 5 de 5 estrelas5/5 (1)
- Tallip Si CFP 09 2021 Recent AdvancesDocumento2 páginasTallip Si CFP 09 2021 Recent AdvancesPawan LahotiAinda não há avaliações
- Cross Lingual Information Retrieval and Error Tracking in Search EngineDocumento37 páginasCross Lingual Information Retrieval and Error Tracking in Search EnginePawan LahotiAinda não há avaliações
- Amlan Chakraborty 0440954: Amlan@cs - Washington.eduDocumento8 páginasAmlan Chakraborty 0440954: Amlan@cs - Washington.eduPawan LahotiAinda não há avaliações
- Data Masking: A New Approach For Steganography?: Polytechnic University, Brooklyn, NY 11201, USADocumento11 páginasData Masking: A New Approach For Steganography?: Polytechnic University, Brooklyn, NY 11201, USAPawan LahotiAinda não há avaliações
- Statement 1581241871570Documento13 páginasStatement 1581241871570RJ Rishabh TyagiAinda não há avaliações
- USR-N540-User-Manual - V1 1 0 01Documento73 páginasUSR-N540-User-Manual - V1 1 0 01carlosboccadoroAinda não há avaliações
- SM System Unit Ir6000Documento79 páginasSM System Unit Ir6000ADVC TECH100% (1)
- Module Iii Cyber CrimesDocumento198 páginasModule Iii Cyber CrimesGuru CharanAinda não há avaliações
- Logistic Regression With Newton MethodDocumento16 páginasLogistic Regression With Newton MethodAster RevAinda não há avaliações
- Lecture 12 -HCI in the Software Process and Usability EngineeringDocumento38 páginasLecture 12 -HCI in the Software Process and Usability Engineeringkamandejessee42Ainda não há avaliações
- Beginning PyQt A Hands-On Approach To GUI Programming With PyQt6 (Joshua M Willman) (Z-Library)Documento446 páginasBeginning PyQt A Hands-On Approach To GUI Programming With PyQt6 (Joshua M Willman) (Z-Library)EZE CHRISTIAN KELECHIAinda não há avaliações
- Bayan KH SawariahDocumento1 páginaBayan KH SawariahDuha AburummanAinda não há avaliações
- Smart Controls Systems - Corporate ProfileDocumento13 páginasSmart Controls Systems - Corporate ProfileZeeshan Ul HaqAinda não há avaliações
- Age and Gender Detection Using CNNDocumento5 páginasAge and Gender Detection Using CNNdtssAinda não há avaliações
- Our Users Usually Achieve: Using Some Detailed Bump-And Reflectivity Maps in SketchupDocumento23 páginasOur Users Usually Achieve: Using Some Detailed Bump-And Reflectivity Maps in SketchupAnaivatcoAinda não há avaliações
- 2020-Ag-6441 Assignment 2Documento5 páginas2020-Ag-6441 Assignment 26441 Abdul RehmanAinda não há avaliações
- Extreme: Portable Photo/Video StorageDocumento17 páginasExtreme: Portable Photo/Video StorageTero NuppiAinda não há avaliações
- Graph The Histogram and Ogive of The Given DataDocumento1 páginaGraph The Histogram and Ogive of The Given DataMath TeacherAinda não há avaliações
- Firewalls CompleteDocumento406 páginasFirewalls CompleteIng Alfredo JeanAinda não há avaliações
- Active Directory Domain ControllerDocumento33 páginasActive Directory Domain ControllerVim SamAinda não há avaliações
- Section 2Documento50 páginasSection 2Gamba MercenariaAinda não há avaliações
- LT 6146 MIX 4090 Device ProgrammerDocumento3 páginasLT 6146 MIX 4090 Device ProgrammerPaul PiguaveAinda não há avaliações
- 10.1 Functions of Input and Output DevicesDocumento6 páginas10.1 Functions of Input and Output DevicesvmhsphysicsAinda não há avaliações
- Seminar Cloud Offerings in IoTDocumento19 páginasSeminar Cloud Offerings in IoTGauraviAinda não há avaliações
- Model Exam 2 Click Here To Attempt - Attempt ReviewDocumento51 páginasModel Exam 2 Click Here To Attempt - Attempt RevieworsangobirukAinda não há avaliações
- Computer Graphics Basics - TutorialspointDocumento1 páginaComputer Graphics Basics - Tutorialspointgdcenr recordsAinda não há avaliações
- Guidelines For Using Digital Games and Gamification in Youth Work - GAME+Documento85 páginasGuidelines For Using Digital Games and Gamification in Youth Work - GAME+Saúl Parra GutiérrezAinda não há avaliações
- Add/Renew An SSL Certificate For SAP HANA Enterprise Cloud: Guide Internal / External Parties Under NDADocumento6 páginasAdd/Renew An SSL Certificate For SAP HANA Enterprise Cloud: Guide Internal / External Parties Under NDATakeo GotoAinda não há avaliações
- Monitoring and Deleting Fake Reviews of Online Products: 1) Background/ Problem StatementDocumento8 páginasMonitoring and Deleting Fake Reviews of Online Products: 1) Background/ Problem StatementSUGUMAR A CSEAinda não há avaliações
- Cisco IOS File System and Image Management Configuration Guide, Cisco IOS Release 15.2 (2) SE (Catalyst 2960-X Switch)Documento56 páginasCisco IOS File System and Image Management Configuration Guide, Cisco IOS Release 15.2 (2) SE (Catalyst 2960-X Switch)aliveli85Ainda não há avaliações
- Computer Awareness PDFDocumento7 páginasComputer Awareness PDFrajithaalugati100% (1)