Você também pode gostar
- The Yellow House: A Memoir (2019 National Book Award Winner)No EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Nota: 4 de 5 estrelas4/5 (98)
- Vimagineering Flyer PDFDocumento1 páginaVimagineering Flyer PDFfreelancer2earnAinda não há avaliações
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNo EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNota: 4 de 5 estrelas4/5 (895)
- Machine Learning and Deep Learning PDFDocumento1 páginaMachine Learning and Deep Learning PDFfreelancer2earnAinda não há avaliações
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNo EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNota: 4 de 5 estrelas4/5 (5794)
- OCW Drilling Hydraulics LectureDocumento59 páginasOCW Drilling Hydraulics Lecturefreelancer2earn100% (1)
- The Little Book of Hygge: Danish Secrets to Happy LivingNo EverandThe Little Book of Hygge: Danish Secrets to Happy LivingNota: 3.5 de 5 estrelas3.5/5 (399)
- Machine Learning and Deep Learning PDFDocumento1 páginaMachine Learning and Deep Learning PDFfreelancer2earnAinda não há avaliações
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNo EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNota: 4.5 de 5 estrelas4.5/5 (266)
- Modeling IPRDocumento19 páginasModeling IPRfreelancer2earnAinda não há avaliações
- Sylvain Ferro NTNU MSC ThesisDocumento96 páginasSylvain Ferro NTNU MSC Thesisfreelancer2earnAinda não há avaliações
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNo EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNota: 4.5 de 5 estrelas4.5/5 (474)
- How To Recognize "Double-Porosity" Systems From Well Tests: Alain C. GringartenDocumento3 páginasHow To Recognize "Double-Porosity" Systems From Well Tests: Alain C. GringartenRafiZafiAinda não há avaliações
- Never Split the Difference: Negotiating As If Your Life Depended On ItNo EverandNever Split the Difference: Negotiating As If Your Life Depended On ItNota: 4.5 de 5 estrelas4.5/5 (838)
- EclipseDocumento43 páginasEclipseBảo Toàn NguyễnAinda não há avaliações
- FishboneDocumento116 páginasFishbonefreelancer2earnAinda não há avaliações
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNo EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNota: 3.5 de 5 estrelas3.5/5 (231)
- Gas Injection DesignDocumento161 páginasGas Injection DesignSarkodie KwameAinda não há avaliações
- YE ZHANG, Introduction To GeostatisticsDocumento36 páginasYE ZHANG, Introduction To Geostatisticsmesquida1993Ainda não há avaliações
- The Emperor of All Maladies: A Biography of CancerNo EverandThe Emperor of All Maladies: A Biography of CancerNota: 4.5 de 5 estrelas4.5/5 (271)
- VariogramsDocumento20 páginasVariogramsBuiNgocHieu92% (13)
- Mathematics HL Paper 3 TZ2 Sets Relations and GroupsDocumento3 páginasMathematics HL Paper 3 TZ2 Sets Relations and GroupsAastha NagarAinda não há avaliações
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyNo EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyNota: 3.5 de 5 estrelas3.5/5 (2259)
- Mathematics 11 Guide (2014)Documento231 páginasMathematics 11 Guide (2014)HumairaAinda não há avaliações
- Reviewed Risk Theory NotesDocumento112 páginasReviewed Risk Theory Notesajami malalaAinda não há avaliações
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNo EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNota: 4.5 de 5 estrelas4.5/5 (344)
- Grade 8 1st Quarter TopicsDocumento3 páginasGrade 8 1st Quarter Topicsapi-295693348100% (2)
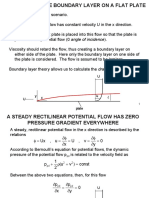
- Boundary Layer Flat PlateDocumento27 páginasBoundary Layer Flat PlateGohar KhokharAinda não há avaliações
- Team of Rivals: The Political Genius of Abraham LincolnNo EverandTeam of Rivals: The Political Genius of Abraham LincolnNota: 4.5 de 5 estrelas4.5/5 (234)
- Grade 7 Math Worksheet 1 (4th Quarter)Documento7 páginasGrade 7 Math Worksheet 1 (4th Quarter)Kibrom KirosAinda não há avaliações
- Time, Temporal Geometry, and CosmologyDocumento28 páginasTime, Temporal Geometry, and CosmologyclonejksAinda não há avaliações
- Problem Set D: Attempt HistoryDocumento10 páginasProblem Set D: Attempt HistoryHenryAinda não há avaliações
- The Unwinding: An Inner History of the New AmericaNo EverandThe Unwinding: An Inner History of the New AmericaNota: 4 de 5 estrelas4/5 (45)
- POLYMATH Results: Calculated Values of The DEQ VariablesDocumento2 páginasPOLYMATH Results: Calculated Values of The DEQ VariablesAlejandra G.RAinda não há avaliações
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNo EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNota: 4 de 5 estrelas4/5 (1090)
- College InformationDocumento29 páginasCollege InformationtakundaAinda não há avaliações
- CEG5301: Machine Learning With Applications: Part I: Fundamentals of Neural NetworksDocumento57 páginasCEG5301: Machine Learning With Applications: Part I: Fundamentals of Neural NetworksWantong LiaoAinda não há avaliações
- Complex NumbersDocumento87 páginasComplex NumbersPriya DudetteAinda não há avaliações
- Ckfëtf Epsf Jolqmx? SF) CLWSF/ DJGWL DXF +WL PJ+:J) Lr5S K - F) 6F) SN @) )Documento14 páginasCkfëtf Epsf Jolqmx? SF) CLWSF/ DJGWL DXF +WL PJ+:J) Lr5S K - F) 6F) SN @) )Krishna ThapaAinda não há avaliações
- Lab 08: Fourier TransformDocumento3 páginasLab 08: Fourier Transformsaran gulAinda não há avaliações
- HRM Report - Human Resource PlanningDocumento32 páginasHRM Report - Human Resource PlanningKeith Amor100% (1)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)No EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Nota: 4.5 de 5 estrelas4.5/5 (121)
- Atkinson 2003Documento64 páginasAtkinson 2003Akshay29Ainda não há avaliações
- 5054 w10 Ms 41Documento3 páginas5054 w10 Ms 41Ali RanaAinda não há avaliações
- Multinomial Logistic Regression Models: Newsom Psy 525/625 Categorical Data Analysis, Spring 2021 1Documento5 páginasMultinomial Logistic Regression Models: Newsom Psy 525/625 Categorical Data Analysis, Spring 2021 1Deo TuremeAinda não há avaliações
- MATH2239-Complex Number E1Documento21 páginasMATH2239-Complex Number E1Lê Gia HânAinda não há avaliações
- Mroz ReplicationDocumento9 páginasMroz ReplicationMateo RiveraAinda não há avaliações
- K2 MathsDocumento49 páginasK2 MathsNaina Mohamed HAinda não há avaliações
- Discipulus - Decompiled Program InterfaceDocumento21 páginasDiscipulus - Decompiled Program InterfaceaadbosmaAinda não há avaliações
- 1.moderation and Mediation Analysis Using Process MacroDocumento8 páginas1.moderation and Mediation Analysis Using Process MacroKelly KavitaAinda não há avaliações
- Fig 2.1 Three Leg Topology of Shunt Active Power FilterDocumento19 páginasFig 2.1 Three Leg Topology of Shunt Active Power FiltersivaAinda não há avaliações
- All Cases of HCF & LCMDocumento10 páginasAll Cases of HCF & LCMmail.kaivalyasharma14Ainda não há avaliações
- Kombinasi Hukum I Dan II Termodinamika - enDocumento17 páginasKombinasi Hukum I Dan II Termodinamika - enEkok Ec100% (1)
- TMP AFCDocumento16 páginasTMP AFCFrontiersAinda não há avaliações
- Module-II Logic Gates & Logic FamiliesDocumento143 páginasModule-II Logic Gates & Logic Familiesvamshi krishna veerakotiAinda não há avaliações
- CMC PresentationDocumento34 páginasCMC PresentationSandeep Kumar Sinha100% (2)
- Machine Model REGC - BDocumento2 páginasMachine Model REGC - BManuelAinda não há avaliações