Você também pode gostar
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNo EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNota: 4 de 5 estrelas4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNo EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNota: 4 de 5 estrelas4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)No EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Nota: 4 de 5 estrelas4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingNo EverandThe Little Book of Hygge: Danish Secrets to Happy LivingNota: 3.5 de 5 estrelas3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerNo EverandThe Emperor of All Maladies: A Biography of CancerNota: 4.5 de 5 estrelas4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItNo EverandNever Split the Difference: Negotiating As If Your Life Depended On ItNota: 4.5 de 5 estrelas4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyNo EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyNota: 3.5 de 5 estrelas3.5/5 (2259)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNo EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNota: 4.5 de 5 estrelas4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNo EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNota: 3.5 de 5 estrelas3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnNo EverandTeam of Rivals: The Political Genius of Abraham LincolnNota: 4.5 de 5 estrelas4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNo EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNota: 4.5 de 5 estrelas4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNo EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNota: 4.5 de 5 estrelas4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaNo EverandThe Unwinding: An Inner History of the New AmericaNota: 4 de 5 estrelas4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNo EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNota: 4 de 5 estrelas4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)No EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Nota: 4.5 de 5 estrelas4.5/5 (121)
- Notice Inviting Bid: National Highways Authority of India, G-5 & 6, Sector-10, Dwarka, New Delhi-110075Documento1 páginaNotice Inviting Bid: National Highways Authority of India, G-5 & 6, Sector-10, Dwarka, New Delhi-110075NaveenAinda não há avaliações
- Terex All Terrain Cranes Spec Df99efDocumento16 páginasTerex All Terrain Cranes Spec Df99efPaizinho Imms GomezAinda não há avaliações
- Model Scheme On Fish Cold StoragesDocumento23 páginasModel Scheme On Fish Cold StoragesHarry SingadilagaAinda não há avaliações
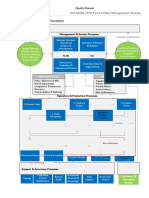
- Quality Management System Process MapDocumento1 páginaQuality Management System Process MapN.GanesanAinda não há avaliações
- A Brief Overview of Our Sharepoint HR SystemDocumento10 páginasA Brief Overview of Our Sharepoint HR SystemisritechnologiesAinda não há avaliações
- Heizer Om10 ModbDocumento48 páginasHeizer Om10 ModbbsaAinda não há avaliações
- Exhibit J - List of Vendor and SubcontractorDocumento62 páginasExhibit J - List of Vendor and SubcontractorpragatheeskAinda não há avaliações
- Dips Gurgaon 2015-16 PDFDocumento90 páginasDips Gurgaon 2015-16 PDFMeghna MittalAinda não há avaliações
- Hyscan II IomDocumento33 páginasHyscan II Ioma1gulesAinda não há avaliações
- TATADocumento25 páginasTATAanupamjeet kaur80% (5)
- Brand Position of Various Cement BrandsDocumento92 páginasBrand Position of Various Cement Brandsvineet228767% (6)
- Welder Id Card DhavalDocumento18 páginasWelder Id Card DhavalDhaval engineeringAinda não há avaliações
- CemSyn Silica For Construction, Bee Chems, IndiaDocumento2 páginasCemSyn Silica For Construction, Bee Chems, IndiaDhan Raj Bandi0% (1)
- Crash Test DummyDocumento8 páginasCrash Test DummyZakaria ShaikhAinda não há avaliações
- Contact Type in Oil and Gas - 1Documento5 páginasContact Type in Oil and Gas - 1Halimi AyoubAinda não há avaliações
- Performance Measurement System Design - A Literature Review and Research AgendaDocumento37 páginasPerformance Measurement System Design - A Literature Review and Research AgendaAlfa Riza GryffieAinda não há avaliações
- Company Brochure: Thekwini Wire & Fasteners (Pty) LTDDocumento6 páginasCompany Brochure: Thekwini Wire & Fasteners (Pty) LTDCristinaAinda não há avaliações
- SQ Assessment Report Sample 2Documento1 páginaSQ Assessment Report Sample 2Sabahat HussainAinda não há avaliações
- Chapter1 - Technology ManagementDocumento16 páginasChapter1 - Technology ManagementJawad Ahmad SahibzadaAinda não há avaliações
- Swagelok VRC Metal Gasket Face Seal FittingsDocumento20 páginasSwagelok VRC Metal Gasket Face Seal FittingstotcsabAinda não há avaliações
- Exin ISO 20000Documento117 páginasExin ISO 20000alokfit100% (1)
- IDA - MTCS X-Cert - Gap Analysis Report - MTCS To ISO270012013 - ReleaseDocumento50 páginasIDA - MTCS X-Cert - Gap Analysis Report - MTCS To ISO270012013 - ReleasekinzaAinda não há avaliações
- Parking Access Design Standards Handbook 2010Documento25 páginasParking Access Design Standards Handbook 2010Sopheak ThapAinda não há avaliações
- 1490Documento8 páginas1490Ahmed SaadAinda não há avaliações
- System Manager 7.4 User GuideDocumento158 páginasSystem Manager 7.4 User GuidemasterboloAinda não há avaliações
- Analisis Kesehatan Dan Keselamatan Kerja Pada Industri Furnitur Kayu Dengan Metode Job Safety AnalysisDocumento10 páginasAnalisis Kesehatan Dan Keselamatan Kerja Pada Industri Furnitur Kayu Dengan Metode Job Safety Analysisyendri putri febriyantiAinda não há avaliações
- Scientific American Architects and Builders Edition 1890 Jul-DecDocumento240 páginasScientific American Architects and Builders Edition 1890 Jul-DecNickiedeposieAinda não há avaliações
- QS - Lesson - Plan PDFDocumento2 páginasQS - Lesson - Plan PDFrajaanwarAinda não há avaliações
- A Look at The Greenfield Foundries of 2020Documento12 páginasA Look at The Greenfield Foundries of 2020skluxAinda não há avaliações