Você também pode gostar
- Sample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignNo EverandSample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignAinda não há avaliações
- Stata Ts Introduction To Time-Series CommandsDocumento6 páginasStata Ts Introduction To Time-Series CommandsngocmimiAinda não há avaliações
- Multiple Linear Regression: y BX BX BXDocumento14 páginasMultiple Linear Regression: y BX BX BXPalaniappan SellappanAinda não há avaliações
- Panel Data AssignmentDocumento32 páginasPanel Data AssignmentFatima ZehraAinda não há avaliações
- DOLS ModelDocumento8 páginasDOLS Modelsaeed meo100% (2)
- Econometrics Exam.Documento4 páginasEconometrics Exam.Shayan AhmedAinda não há avaliações
- Time Series AnalysisDocumento3 páginasTime Series AnalysisKamil Mehdi AbbasAinda não há avaliações
- Chapter 9 QADocumento4 páginasChapter 9 QALisden LeeAinda não há avaliações
- Note On Panel DataDocumento19 páginasNote On Panel DataHassanMubasherAinda não há avaliações
- Panel Data Analysis Sunita AroraDocumento28 páginasPanel Data Analysis Sunita Aroralukgv,h100% (1)
- Econometric S Lecture 43Documento36 páginasEconometric S Lecture 43Khurram AzizAinda não há avaliações
- Introduction To Regression Models For Panel Data Analysis Indiana University Workshop in Methods October 7, 2011 Professor Patricia A. McmanusDocumento42 páginasIntroduction To Regression Models For Panel Data Analysis Indiana University Workshop in Methods October 7, 2011 Professor Patricia A. McmanusAnonymous 0sxQqwAIMBAinda não há avaliações
- ECONOMETRICS-Assignment 2Documento2 páginasECONOMETRICS-Assignment 2Gaby Jacinda Andreas100% (1)
- Chapter 2 - EconometricsDocumento41 páginasChapter 2 - Econometricshien05Ainda não há avaliações
- Panel Data AnalysisDocumento8 páginasPanel Data AnalysisAditya Kumar SinghAinda não há avaliações
- Introduction To Econometrics - Stock & Watson - CH 5 SlidesDocumento71 páginasIntroduction To Econometrics - Stock & Watson - CH 5 SlidesAntonio Alvino100% (2)
- (Bruderl) Applied Regression Analysis Using StataDocumento73 páginas(Bruderl) Applied Regression Analysis Using StataSanjiv DesaiAinda não há avaliações
- Chapter 11 Solutions Solution Manual Introductory Econometrics For FinanceDocumento4 páginasChapter 11 Solutions Solution Manual Introductory Econometrics For FinanceNazim Uddin MahmudAinda não há avaliações
- Introduction To Econometrics - Stock & Watson - CH 10 SlidesDocumento99 páginasIntroduction To Econometrics - Stock & Watson - CH 10 SlidesAntonio AlvinoAinda não há avaliações
- STATA Assignment 1 InstructionsDocumento2 páginasSTATA Assignment 1 InstructionsRO BWNAinda não há avaliações
- Dev't PPA I (Chap-4)Documento48 páginasDev't PPA I (Chap-4)ferewe tesfaye100% (1)
- Panel DataDocumento13 páginasPanel DataAzime Hassen100% (1)
- Chapter 7 PDFDocumento17 páginasChapter 7 PDFNarutoLLNAinda não há avaliações
- Forecasting StataDocumento18 páginasForecasting StataGabriela OrtegaAinda não há avaliações
- Quiz 3 SV EDocumento10 páginasQuiz 3 SV ENtxawm MuasAinda não há avaliações
- Exam History of Economic ThoughtDocumento3 páginasExam History of Economic ThoughtLeonardo VidaAinda não há avaliações
- Statistics Final ReviewDocumento21 páginasStatistics Final ReviewtkdforceAinda não há avaliações
- Econometric S Lecture 45Documento31 páginasEconometric S Lecture 45Khurram AzizAinda não há avaliações
- Stochastic Frontier Analysis StataDocumento48 páginasStochastic Frontier Analysis StataAnonymous vI4dpAhc100% (2)
- Multiple Choice Test Bank Questions No Feedback - Chapter 3: y + X + X + X + UDocumento3 páginasMultiple Choice Test Bank Questions No Feedback - Chapter 3: y + X + X + X + Uimam awaluddinAinda não há avaliações
- Panel Vs Pooled DataDocumento9 páginasPanel Vs Pooled DataFesboekii FesboekiAinda não há avaliações
- Chapter 3Documento28 páginasChapter 3Hope Knock100% (1)
- Panel DataDocumento5 páginasPanel Datasaeed meo100% (2)
- New Multivariate Time-Series Estimators in Stata 11Documento34 páginasNew Multivariate Time-Series Estimators in Stata 11Aviral Kumar TiwariAinda não há avaliações
- Heteroscedasticity: What Heteroscedasticity Is. Recall That OLS Makes The Assumption ThatDocumento20 páginasHeteroscedasticity: What Heteroscedasticity Is. Recall That OLS Makes The Assumption Thatbisma_aliyyahAinda não há avaliações
- Panel Data 1Documento6 páginasPanel Data 1Abdul AzizAinda não há avaliações
- PowerBI Handwritten NoteDocumento2 páginasPowerBI Handwritten NoteririxayAinda não há avaliações
- Linear Regression Models For Panel Data Using SAS, STATA, LIMDEP and SPSSDocumento67 páginasLinear Regression Models For Panel Data Using SAS, STATA, LIMDEP and SPSSLuísa Martins100% (2)
- Lecture 7 VARDocumento34 páginasLecture 7 VAREason SaintAinda não há avaliações
- Panel Data ModelsDocumento112 páginasPanel Data ModelsAlemuAinda não há avaliações
- ECON 330-Econometrics-Dr. Farooq NaseerDocumento5 páginasECON 330-Econometrics-Dr. Farooq NaseerWahaj KamranAinda não há avaliações
- ForecastingDocumento21 páginasForecastingDaniel Ong100% (1)
- Introductory Econometrics For Finance Chris Brooks Solutions To Review - Chapter 3Documento7 páginasIntroductory Econometrics For Finance Chris Brooks Solutions To Review - Chapter 3Bill Ramos100% (2)
- Multiple Linear Regression in Data MiningDocumento14 páginasMultiple Linear Regression in Data Miningakirank1100% (1)
- Structural Equation Modeling in StataDocumento10 páginasStructural Equation Modeling in StatajamazalaleAinda não há avaliações
- Chapter1 - An Overview of Regression AnalysisDocumento35 páginasChapter1 - An Overview of Regression AnalysisZiaNaPiramLiAinda não há avaliações
- STATA Data PanelDocumento11 páginasSTATA Data PanelalbertolossAinda não há avaliações
- DSE Past Year 2016 Paper and SolutionDocumento20 páginasDSE Past Year 2016 Paper and SolutionshakthiAinda não há avaliações
- Nature of Regression AnalysisDocumento22 páginasNature of Regression Analysiswhoosh2008Ainda não há avaliações
- Stationarity and Unit Root TestingDocumento21 páginasStationarity and Unit Root TestingAwAtef LHAinda não há avaliações
- AP Statistics 1st Semester Study GuideDocumento6 páginasAP Statistics 1st Semester Study GuideSusan HuynhAinda não há avaliações
- Micro Perfect and MonopolyDocumento57 páginasMicro Perfect and Monopolytegegn mogessieAinda não há avaliações
- Introduction To Econometrics - Stock & Watson - CH 9 SlidesDocumento69 páginasIntroduction To Econometrics - Stock & Watson - CH 9 SlidesAntonio Alvino100% (1)
- Ordinary Least Square EstimationDocumento30 páginasOrdinary Least Square Estimationthrphys1940Ainda não há avaliações
- Time Sereis Analysis Using StataDocumento26 páginasTime Sereis Analysis Using StataSayed Farrukh AhmedAinda não há avaliações
- Statistical Analysis Using SASDocumento47 páginasStatistical Analysis Using SASMuneesh BajpaiAinda não há avaliações
- What Statistical Analysis Should I UseDocumento48 páginasWhat Statistical Analysis Should I UseErick BarriosAinda não há avaliações
- Statistical Analysis Using SPSSDocumento52 páginasStatistical Analysis Using SPSSSherwan R Shal100% (2)
- What Statistical Analysis Should I Use - Statistical Analyses Using SPSS - IDRE StatsDocumento43 páginasWhat Statistical Analysis Should I Use - Statistical Analyses Using SPSS - IDRE StatsIntegrated Fayomi Joseph AjayiAinda não há avaliações
- Statistical Tests in SPSSDocumento26 páginasStatistical Tests in SPSSatul_18100% (1)
- The Ins and Outs Indirect OrvinuDocumento8 páginasThe Ins and Outs Indirect OrvinusatishAinda não há avaliações
- Company Profile 4Documento54 páginasCompany Profile 4Khuloud JamalAinda não há avaliações
- Stellite 6 FinalDocumento2 páginasStellite 6 FinalGumersindo MelambesAinda não há avaliações
- Philippine Rural Development Project: South Luzon Cluster C Ommunication Resourc ES Management WorkshopDocumento45 páginasPhilippine Rural Development Project: South Luzon Cluster C Ommunication Resourc ES Management WorkshopAlorn CatibogAinda não há avaliações
- SUNGLAO - TM PortfolioDocumento60 páginasSUNGLAO - TM PortfolioGIZELLE SUNGLAOAinda não há avaliações
- Bus105 Pcoq 2 100%Documento9 páginasBus105 Pcoq 2 100%Gish KK.GAinda não há avaliações
- BS en 50216-6 2002Documento18 páginasBS en 50216-6 2002Jeff Anderson Collins100% (3)
- General Mathematics SS3 2ND Term SchemeDocumento2 páginasGeneral Mathematics SS3 2ND Term Schemesam kaluAinda não há avaliações
- TakeawaysDocumento2 páginasTakeawaysapi-509552154Ainda não há avaliações
- Ojt Evaluation Forms (Supervised Industry Training) SampleDocumento5 páginasOjt Evaluation Forms (Supervised Industry Training) SampleJayJay Jimenez100% (3)
- Pricelist 1Documento8 páginasPricelist 1ChinangAinda não há avaliações
- Project 4 Close TestDocumento7 páginasProject 4 Close TestErika MolnarAinda não há avaliações
- Rubric For Audio Speech DeliveryDocumento2 páginasRubric For Audio Speech DeliveryMarie Sol PanganAinda não há avaliações
- Nicole Rapp Resume 3Documento2 páginasNicole Rapp Resume 3api-341337144Ainda não há avaliações
- RTD IncotestDocumento2 páginasRTD IncotestJabari KaneAinda não há avaliações
- PERSONAL DEVELOPMENT (What Is Personal Development?)Documento37 páginasPERSONAL DEVELOPMENT (What Is Personal Development?)Ronafe Roncal GibaAinda não há avaliações
- Pitch AnythingDocumento8 páginasPitch AnythingDoland drumb100% (1)
- Mortars in Norway From The Middle Ages To The 20th Century: Con-Servation StrategyDocumento8 páginasMortars in Norway From The Middle Ages To The 20th Century: Con-Servation StrategyUriel PerezAinda não há avaliações
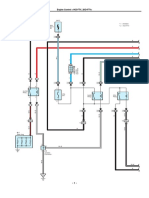
- Diagrama Hilux 1KD-2KD PDFDocumento11 páginasDiagrama Hilux 1KD-2KD PDFJeni100% (1)
- Lecture Notes - Introduction To Big DataDocumento8 páginasLecture Notes - Introduction To Big Datasakshi kureley0% (1)
- Sunrise - 12 AB-unlockedDocumento81 páginasSunrise - 12 AB-unlockedMohamed Thanoon50% (2)
- (Database Management Systems) : Biag, Marvin, B. BSIT - 202 September 6 2019Documento7 páginas(Database Management Systems) : Biag, Marvin, B. BSIT - 202 September 6 2019Marcos JeremyAinda não há avaliações
- 1207 - RTC-8065 II InglesDocumento224 páginas1207 - RTC-8065 II InglesGUILHERME SANTOSAinda não há avaliações
- A History of The Ecological Sciences, Part 1 - Early Greek OriginsDocumento6 páginasA History of The Ecological Sciences, Part 1 - Early Greek OriginskatzbandAinda não há avaliações
- Nielsen Report - The New Trend Among Indonesia's NetizensDocumento20 páginasNielsen Report - The New Trend Among Indonesia's NetizensMarsha ImaniaraAinda não há avaliações
- Grade 6 q2 Mathematics LasDocumento151 páginasGrade 6 q2 Mathematics LasERIC VALLE80% (5)
- Contract 1 ProjectDocumento21 páginasContract 1 ProjectAditi BanerjeeAinda não há avaliações
- General Introduction: 1.1 What Is Manufacturing (MFG) ?Documento19 páginasGeneral Introduction: 1.1 What Is Manufacturing (MFG) ?Mohammed AbushammalaAinda não há avaliações
- Assignment 1 - Vertical Alignment - SolutionsDocumento6 páginasAssignment 1 - Vertical Alignment - SolutionsArmando Ramirez100% (1)
- PST SubjectDocumento2 páginasPST SubjectCarol ElizagaAinda não há avaliações
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)No EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)Ainda não há avaliações
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsNo EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsNota: 4.5 de 5 estrelas4.5/5 (3)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeNo EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeNota: 4 de 5 estrelas4/5 (2)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.No EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Nota: 5 de 5 estrelas5/5 (1)
- Images of Mathematics Viewed Through Number, Algebra, and GeometryNo EverandImages of Mathematics Viewed Through Number, Algebra, and GeometryAinda não há avaliações
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormNo EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormNota: 5 de 5 estrelas5/5 (5)
- Limitless Mind: Learn, Lead, and Live Without BarriersNo EverandLimitless Mind: Learn, Lead, and Live Without BarriersNota: 4 de 5 estrelas4/5 (6)
- Math Workshop, Grade K: A Framework for Guided Math and Independent PracticeNo EverandMath Workshop, Grade K: A Framework for Guided Math and Independent PracticeNota: 5 de 5 estrelas5/5 (1)
- ParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)No EverandParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)Ainda não há avaliações
- Mental Math Secrets - How To Be a Human CalculatorNo EverandMental Math Secrets - How To Be a Human CalculatorNota: 5 de 5 estrelas5/5 (3)
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldNo EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldNota: 3 de 5 estrelas3/5 (80)