Você também pode gostar
- Remote Soldier Monitoring with GPRSDocumento6 páginasRemote Soldier Monitoring with GPRSPrabhakar CaptainAinda não há avaliações
- GraphDocumento6 páginasGraphPrabhakar CaptainAinda não há avaliações
- NOT Gates or Inverters LadderDocumento5 páginasNOT Gates or Inverters LadderPrabhakar CaptainAinda não há avaliações
- Unit 7 8279Documento47 páginasUnit 7 8279subramanyam62Ainda não há avaliações
- Mutual Exclusion (Mutex) With A SemaphoreDocumento38 páginasMutual Exclusion (Mutex) With A SemaphorePrabhakar CaptainAinda não há avaliações
- An Early Screening System For The Detection of Diabetic Retinopathy Using Image ProcessingDocumento5 páginasAn Early Screening System For The Detection of Diabetic Retinopathy Using Image ProcessingPrabhakar CaptainAinda não há avaliações
- Closed Loop Performance InvestigationDocumento5 páginasClosed Loop Performance InvestigationPrabhakar CaptainAinda não há avaliações
- An Entire Concept of Embedded Systems-EntireDocumento114 páginasAn Entire Concept of Embedded Systems-EntirePrabhakar Captain100% (1)
- Never Split the Difference: Negotiating As If Your Life Depended On ItNo EverandNever Split the Difference: Negotiating As If Your Life Depended On ItNota: 4.5 de 5 estrelas4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNo EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNota: 4.5 de 5 estrelas4.5/5 (474)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNo EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNota: 4 de 5 estrelas4/5 (5782)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNo EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNota: 4 de 5 estrelas4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)No EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Nota: 4 de 5 estrelas4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingNo EverandThe Little Book of Hygge: Danish Secrets to Happy LivingNota: 3.5 de 5 estrelas3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNo EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNota: 3.5 de 5 estrelas3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnNo EverandTeam of Rivals: The Political Genius of Abraham LincolnNota: 4.5 de 5 estrelas4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNo EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNota: 4.5 de 5 estrelas4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNo EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNota: 4.5 de 5 estrelas4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerNo EverandThe Emperor of All Maladies: A Biography of CancerNota: 4.5 de 5 estrelas4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyNo EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyNota: 3.5 de 5 estrelas3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaNo EverandThe Unwinding: An Inner History of the New AmericaNota: 4 de 5 estrelas4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNo EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNota: 4 de 5 estrelas4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)No EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Nota: 4.5 de 5 estrelas4.5/5 (119)
- Department of Computer Applications Iii Semester Mc5304-Programming With JavaDocumento32 páginasDepartment of Computer Applications Iii Semester Mc5304-Programming With JavaManibharathiAinda não há avaliações
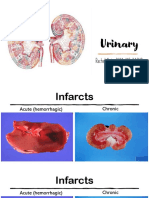
- Urinary: Rachel Neto, DVM, MS, DACVP May 28 2020Documento15 páginasUrinary: Rachel Neto, DVM, MS, DACVP May 28 2020Rachel AutranAinda não há avaliações
- Chapter 2 (Teacher)Documento19 páginasChapter 2 (Teacher)ajakazAinda não há avaliações
- Sales TAX FORMATDocumento6 páginasSales TAX FORMATMuhammad HamzaAinda não há avaliações
- Chapter 2 ResearchDocumento14 páginasChapter 2 ResearchabibualAinda não há avaliações
- ENGLISH COACHING CORNER MATHEMATICS PRE-BOARD EXAMINATIONDocumento2 páginasENGLISH COACHING CORNER MATHEMATICS PRE-BOARD EXAMINATIONVaseem QureshiAinda não há avaliações
- DIRECTORS1Documento28 páginasDIRECTORS1Ekta ChaudharyAinda não há avaliações
- The NF and BNF Charts from the Trading RoomDocumento23 páginasThe NF and BNF Charts from the Trading RoomSinghRaviAinda não há avaliações
- Contract Management Software BenefitsDocumento9 páginasContract Management Software BenefitsYashas JaiswalAinda não há avaliações
- BLDG TECH Juson Assignment Lecture 1Documento23 páginasBLDG TECH Juson Assignment Lecture 1Ma. Janelle GoAinda não há avaliações
- Multinational Business Finance 12th Edition Slides Chapter 12Documento33 páginasMultinational Business Finance 12th Edition Slides Chapter 12Alli Tobba100% (1)
- Technology Unit 1 UTUDocumento19 páginasTechnology Unit 1 UTUDaAinda não há avaliações
- Architecture Vernacular TermsDocumento3 páginasArchitecture Vernacular TermsJustine Marie RoperoAinda não há avaliações
- Non-Traditional Machining: Unit - 1Documento48 páginasNon-Traditional Machining: Unit - 1bunty231Ainda não há avaliações
- Hiata 2Documento21 páginasHiata 2AnnJenn AsideraAinda não há avaliações
- Procedures in Using Ge-Survey System PDFDocumento54 páginasProcedures in Using Ge-Survey System PDFJoel PAcs73% (11)
- Mr. Frank Remedios Certified Career Counselor Authorised Franchise-Brain CheckerDocumento24 páginasMr. Frank Remedios Certified Career Counselor Authorised Franchise-Brain Checkerrwf0606Ainda não há avaliações
- Philips Solar+LED Marketing StrategyDocumento15 páginasPhilips Solar+LED Marketing StrategyrejinairAinda não há avaliações
- Denny Darmawan Diredja: Professional Attributes / Skills ExperiencesDocumento2 páginasDenny Darmawan Diredja: Professional Attributes / Skills ExperiencesIntan WidyawatiAinda não há avaliações
- Consular Assistance For Indians Living Abroad Through "MADAD"Documento12 páginasConsular Assistance For Indians Living Abroad Through "MADAD"NewsBharatiAinda não há avaliações
- The International Journal of Periodontics & Restorative DentistryDocumento7 páginasThe International Journal of Periodontics & Restorative DentistrytaniaAinda não há avaliações
- Ammonium Nitrophosphate Production ProcessDocumento133 páginasAmmonium Nitrophosphate Production ProcessHit Busa100% (1)
- CamScanner Scanned PDF DocumentDocumento205 páginasCamScanner Scanned PDF DocumentNabila Tsuroya BasyaAinda não há avaliações
- Install CH340 driver for ArduinoDocumento8 páginasInstall CH340 driver for Arduinosubbu jangamAinda não há avaliações
- Behavioural Theory of The Firm: Presented By: Shubham Gupta Sumit MalikDocumento26 páginasBehavioural Theory of The Firm: Presented By: Shubham Gupta Sumit MalikvarunymrAinda não há avaliações
- Small-Scale Fisheries Co-op ConstitutionDocumento37 páginasSmall-Scale Fisheries Co-op ConstitutionCalyn MusondaAinda não há avaliações
- Chapter 2 EnglishDocumento9 páginasChapter 2 Englishdgdhdh_66Ainda não há avaliações
- Cyolo Datasheet 2022 - Driving Digital BusinessDocumento3 páginasCyolo Datasheet 2022 - Driving Digital BusinessAlexis MoralesAinda não há avaliações
- Easa Ad 2023-0133 1Documento6 páginasEasa Ad 2023-0133 1Pedro LucasAinda não há avaliações