Você também pode gostar
- Central Limit TheoremDocumento38 páginasCentral Limit TheoremNiraj Gupta100% (2)
- Six Sigma Handbook - 2007 PDFDocumento641 páginasSix Sigma Handbook - 2007 PDFkarlos26com100% (7)
- M Phil Clinical PsychologyDocumento41 páginasM Phil Clinical PsychologyNazema_SagiAinda não há avaliações
- Basic Concepts of Hypothesis TestingDocumento5 páginasBasic Concepts of Hypothesis Testingjudith matienzo100% (3)
- EViews 1st Week Assignment With SolutionDocumento7 páginasEViews 1st Week Assignment With SolutionFagbola Oluwatobi OmolajaAinda não há avaliações
- Schaum's Easy Outline of Probability and Statistics, Revised EditionNo EverandSchaum's Easy Outline of Probability and Statistics, Revised EditionAinda não há avaliações
- Normal Binomial PoissonDocumento12 páginasNormal Binomial Poissonamit447100% (1)
- 13-Statisticsandprobability q4 Mod13 Populationproportiondraw-ConclusionsDocumento27 páginas13-Statisticsandprobability q4 Mod13 Populationproportiondraw-ConclusionsLerwin Garinga80% (5)
- Confidence IntervalDocumento19 páginasConfidence IntervalAjinkya Adhikari100% (1)
- Probility DistributionDocumento41 páginasProbility Distributionnitindhiman30Ainda não há avaliações
- Lecture 3 - Sampling-Distribution & Central Limit TheoremDocumento5 páginasLecture 3 - Sampling-Distribution & Central Limit TheoremNilo Galvez Jr.Ainda não há avaliações
- Project Management A Managerial Approach 7th EdDocumento188 páginasProject Management A Managerial Approach 7th Edgautham20% (5)
- Normal Distribution and Probability: Mate14 - Design and Analysis of Experiments in Materials EngineeringDocumento23 páginasNormal Distribution and Probability: Mate14 - Design and Analysis of Experiments in Materials EngineeringsajeerAinda não há avaliações
- Sample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignNo EverandSample Size for Analytical Surveys, Using a Pretest-Posttest-Comparison-Group DesignAinda não há avaliações
- An Introduction To Two-Way ANOVA: Prepared ByDocumento46 páginasAn Introduction To Two-Way ANOVA: Prepared BypradeepAinda não há avaliações
- GCSE Maths Revision: Cheeky Revision ShortcutsNo EverandGCSE Maths Revision: Cheeky Revision ShortcutsNota: 3.5 de 5 estrelas3.5/5 (2)
- Point and Interval Estimation-26!08!2011Documento28 páginasPoint and Interval Estimation-26!08!2011Syed OvaisAinda não há avaliações
- Lean Six Sigma Green Belt CurriculumDocumento6 páginasLean Six Sigma Green Belt Curriculumhim2000himAinda não há avaliações
- 3 UnequalDocumento7 páginas3 UnequalRicardo TavaresAinda não há avaliações
- Module 2 in IStat 1 Probability DistributionDocumento6 páginasModule 2 in IStat 1 Probability DistributionJefferson Cadavos CheeAinda não há avaliações
- שפות סימולציה- הרצאה 12 - Output Data Analysis IDocumento49 páginasשפות סימולציה- הרצאה 12 - Output Data Analysis IRonAinda não há avaliações
- Confidence Intervals and Hypothesis Tests For MeansDocumento40 páginasConfidence Intervals and Hypothesis Tests For MeansJosh PotashAinda não há avaliações
- SamplingDistributions LectureDocumento13 páginasSamplingDistributions LectureJeanpierre AklAinda não há avaliações
- Insurance Pricing Basic Statistical PrinciplesDocumento33 páginasInsurance Pricing Basic Statistical PrinciplesEsra Gunes YildizAinda não há avaliações
- Random Variable & Probability DistributionDocumento48 páginasRandom Variable & Probability DistributionRISHAB NANGIAAinda não há avaliações
- Sampling Distributions of Statistics: Corresponds To Chapter 5 of Tamhaneand DunlopDocumento36 páginasSampling Distributions of Statistics: Corresponds To Chapter 5 of Tamhaneand DunlopLuis LoredoAinda não há avaliações
- S2 Revision NotesDocumento2 páginasS2 Revision NotesimnulAinda não há avaliações
- Estimation 1Documento35 páginasEstimation 1Fun Toosh345Ainda não há avaliações
- Quant Part2Documento40 páginasQuant Part2TAKESHI OMAR CASTRO REYESAinda não há avaliações
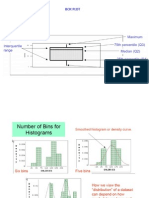
- f (x) ≥0, Σf (x) =1. We can describe a discrete probability distribution with a table, graph,Documento4 páginasf (x) ≥0, Σf (x) =1. We can describe a discrete probability distribution with a table, graph,missy74Ainda não há avaliações
- Inferential Statistic: 1 Estimation of A Population MeanDocumento8 páginasInferential Statistic: 1 Estimation of A Population MeanshahzebAinda não há avaliações
- Faculty of Information Science & Technology (FIST) : PSM 0325 Introduction To Probability and StatisticsDocumento7 páginasFaculty of Information Science & Technology (FIST) : PSM 0325 Introduction To Probability and StatisticsMATHAVAN A L KRISHNANAinda não há avaliações
- PSYCH 240: Statistics For Psychologists: Interval Estimation: Understanding The T DistributionDocumento44 páginasPSYCH 240: Statistics For Psychologists: Interval Estimation: Understanding The T DistributionSatish NamjoshiAinda não há avaliações
- Tatang A Gumanti 2010: Pengenalan Alat-Alat Uji Statistik Dalam Penelitian SosialDocumento15 páginasTatang A Gumanti 2010: Pengenalan Alat-Alat Uji Statistik Dalam Penelitian SosialPrima JoeAinda não há avaliações
- Lc07 SL Estimation - PPT - 0Documento48 páginasLc07 SL Estimation - PPT - 0Deni ChanAinda não há avaliações
- Confidence Interval EstimationDocumento62 páginasConfidence Interval EstimationVikrant LadAinda não há avaliações
- Lec 3 - Continuous ProbabilitiesDocumento9 páginasLec 3 - Continuous ProbabilitiesCharles QuahAinda não há avaliações
- Inferences Based On A Single Sample: Confidence Intervals and Tests of Hypothesis (9 Hours)Documento71 páginasInferences Based On A Single Sample: Confidence Intervals and Tests of Hypothesis (9 Hours)Kato AkikoAinda não há avaliações
- Chapter06 091211160706 Phpapp01Documento42 páginasChapter06 091211160706 Phpapp01shan4600Ainda não há avaliações
- 3 DistributionsDocumento42 páginas3 DistributionsAngga Ade PutraAinda não há avaliações
- CHAPTER 5 - Sampling Distributions Sections: 5.1 & 5.2: AssumptionsDocumento9 páginasCHAPTER 5 - Sampling Distributions Sections: 5.1 & 5.2: Assumptionssound05Ainda não há avaliações
- Mechanical MeasurementsDocumento22 páginasMechanical MeasurementsBanamali MohantaAinda não há avaliações
- Sampling Dist 18 Aug 10Documento2 páginasSampling Dist 18 Aug 10GolamKibriabipuAinda não há avaliações
- ASPjskjkjksnkxdqlcwlDocumento34 páginasASPjskjkjksnkxdqlcwlSonuBajajAinda não há avaliações
- The Practice of Statistic For Business and Economics Is An IntroductoryDocumento15 páginasThe Practice of Statistic For Business and Economics Is An IntroductoryuiysdfiyuiAinda não há avaliações
- Group 2Documento65 páginasGroup 2Fazal McphersonAinda não há avaliações
- Sampling DistributionDocumento22 páginasSampling Distributionumar2040Ainda não há avaliações
- STATISTICS FOR BUSINESS - CHAP05 - Sampling and Sampling Distribution PDFDocumento3 páginasSTATISTICS FOR BUSINESS - CHAP05 - Sampling and Sampling Distribution PDFHoang NguyenAinda não há avaliações
- STATISTICSDocumento8 páginasSTATISTICSmesfindukedomAinda não há avaliações
- Statistics For Business and Economics: Module 1:probability Theory and Statistical Inference Spring 2010Documento20 páginasStatistics For Business and Economics: Module 1:probability Theory and Statistical Inference Spring 2010S.WaqquasAinda não há avaliações
- Value of Z Area Between Z and - Z Area From Z ToDocumento3 páginasValue of Z Area Between Z and - Z Area From Z Topatricia_castillo_49Ainda não há avaliações
- Business Statistics - Session Probability DistributionDocumento21 páginasBusiness Statistics - Session Probability Distributionmukul3087_305865623Ainda não há avaliações
- AP Statistics - Chapter 8 Notes: Estimating With Confidence 8.1 - Confidence Interval BasicsDocumento2 páginasAP Statistics - Chapter 8 Notes: Estimating With Confidence 8.1 - Confidence Interval BasicsRhivia LoratAinda não há avaliações
- Normal Dist - Student LectureDocumento43 páginasNormal Dist - Student LecturesovolojikAinda não há avaliações
- Module 6-1Documento21 páginasModule 6-1Ho Uyen Thu NguyenAinda não há avaliações
- IISER BiostatDocumento87 páginasIISER BiostatPrithibi Bodle GacheAinda não há avaliações
- Lecture 03 & 04 EC5002 CLT & Normal Distribution 2015-16Documento13 páginasLecture 03 & 04 EC5002 CLT & Normal Distribution 2015-16nishit0157623637Ainda não há avaliações
- Statistical Inference: Prepared By: Antonio E. Chan, M.DDocumento227 páginasStatistical Inference: Prepared By: Antonio E. Chan, M.Dश्रीकांत शरमाAinda não há avaliações
- Sampling Distributions of Sample MeansDocumento7 páginasSampling Distributions of Sample MeansDaryl Vincent RiveraAinda não há avaliações
- Review of StatisticsDocumento36 páginasReview of StatisticsJessica AngelinaAinda não há avaliações
- DistributionDocumento6 páginasDistributionRamos LeonaAinda não há avaliações
- Notes ch3 Sampling DistributionsDocumento20 páginasNotes ch3 Sampling DistributionsErkin DAinda não há avaliações
- 6 Monte Carlo Simulation: Exact SolutionDocumento10 páginas6 Monte Carlo Simulation: Exact SolutionYuri PazaránAinda não há avaliações
- Introduction To The T-Statistic: PSY295 Spring 2003 SummerfeltDocumento19 páginasIntroduction To The T-Statistic: PSY295 Spring 2003 SummerfeltEddy MwachenjeAinda não há avaliações
- STAT 241 - Unit 5 NotesDocumento9 páginasSTAT 241 - Unit 5 NotesCassie LemonsAinda não há avaliações
- Sats 12Documento6 páginasSats 12saima shahnawazAinda não há avaliações
- Quantum XLExampleDocumento83 páginasQuantum XLExamplesankar22Ainda não há avaliações
- An Assessment of The Role of External Auditor in The Detection and Prevention of Fraud in Deposit Money Banks in Nigeria (2005-2014)Documento24 páginasAn Assessment of The Role of External Auditor in The Detection and Prevention of Fraud in Deposit Money Banks in Nigeria (2005-2014)Shuhada ShamsuddinAinda não há avaliações
- Ch10 - SimulationDocumento51 páginasCh10 - SimulationBambang AriwibowoAinda não há avaliações
- Chap 017Documento14 páginasChap 017Darin M SadiqAinda não há avaliações
- Experiment - 10: Question: A Structural Engineer Is Studying The Strength of Aluminium Alloy Purchased FromDocumento5 páginasExperiment - 10: Question: A Structural Engineer Is Studying The Strength of Aluminium Alloy Purchased FromQuoraAinda não há avaliações
- Research Methodology SyllabusDocumento3 páginasResearch Methodology SyllabusDharshan K100% (1)
- Assessment of Statistical Literacy of Post-Graduate Students in The University of Port HarcourtDocumento9 páginasAssessment of Statistical Literacy of Post-Graduate Students in The University of Port HarcourtIjahss JournalAinda não há avaliações
- GROUP IV-Written ReportDocumento21 páginasGROUP IV-Written ReportCarla Dela Rosa AbalosAinda não há avaliações
- 8614 Assignment 2 by M MURSLAIN BY677681Documento18 páginas8614 Assignment 2 by M MURSLAIN BY677681M ImranAinda não há avaliações
- Topic 2: ANOVA - One Way, Two WayDocumento2 páginasTopic 2: ANOVA - One Way, Two WayShaiswe SVAinda não há avaliações
- Module 1 Scientific InquiryDocumento39 páginasModule 1 Scientific InquiryAbdiAinda não há avaliações
- Circular Data AnalysisDocumento29 páginasCircular Data AnalysisBenthosmanAinda não há avaliações
- CJCER Vol21 No8 June 2021-7Documento14 páginasCJCER Vol21 No8 June 2021-7RemikAinda não há avaliações
- WWW Thoughtco Com Null Hypothesis Examples 609097Documento8 páginasWWW Thoughtco Com Null Hypothesis Examples 609097Mcode TeamAinda não há avaliações
- BS101B Final Assessment Guidelines 1 2020 FinalDocumento7 páginasBS101B Final Assessment Guidelines 1 2020 FinalThuli Mashinini0% (1)
- Unit 5.2 Testing Two Population MeansDocumento24 páginasUnit 5.2 Testing Two Population Meansshane naigalAinda não há avaliações
- Truck Factor PDFDocumento91 páginasTruck Factor PDFschavezlozano100% (1)
- Research Methods IntroDocumento45 páginasResearch Methods IntroorodizodanieloAinda não há avaliações
- G-Test: Statistics Likelihood-Ratio Maximum Likelihood Statistical Significance Chi-Squared TestsDocumento5 páginasG-Test: Statistics Likelihood-Ratio Maximum Likelihood Statistical Significance Chi-Squared TestsJesús CastellanosAinda não há avaliações
- Rau J Statistical Mechanics in A NutshellDocumento23 páginasRau J Statistical Mechanics in A NutshellcrguntalilibAinda não há avaliações
- Effect Size, Calculating Cohen's DDocumento6 páginasEffect Size, Calculating Cohen's DBobbyNicholsAinda não há avaliações