Você também pode gostar
- Evolving Data Mining Algorithms On The Prevailing Crime Trend - An Intelligent Crime Prediction ModelDocumento6 páginasEvolving Data Mining Algorithms On The Prevailing Crime Trend - An Intelligent Crime Prediction ModelJaydwin LabianoAinda não há avaliações
- An Analysis of Data Mining Applications in Crime Domain: P. Thongtae and S. SrisukDocumento5 páginasAn Analysis of Data Mining Applications in Crime Domain: P. Thongtae and S. Srisukharikk89Ainda não há avaliações
- (IJIT-V7I2P3) :CH - Kalpana, A. Sobhana RhosalineDocumento5 páginas(IJIT-V7I2P3) :CH - Kalpana, A. Sobhana RhosalineIJITJournalsAinda não há avaliações
- A Survey of Data Mining Techniques For CDocumento6 páginasA Survey of Data Mining Techniques For Cynagenon950Ainda não há avaliações
- Kumar Nagpal2019 - Article - AnalysisAndPredictionOfCrimePa 2019 DoneDocumento7 páginasKumar Nagpal2019 - Article - AnalysisAndPredictionOfCrimePa 2019 DoneramAinda não há avaliações
- Buczak Gifford Fuzzy Rules CrimeDocumento10 páginasBuczak Gifford Fuzzy Rules CrimeFaiza ShahAinda não há avaliações
- Crime D Ata MiningDocumento17 páginasCrime D Ata MiningzhijiangAinda não há avaliações
- Week1.Individual Assignment - ResearchDocumento6 páginasWeek1.Individual Assignment - ResearchFrederickPaigeIIIAinda não há avaliações
- CRIME ANALYSIS AND PREDICTION USING DATA MINING TECHNIQUES (1) (AutoRecovered) (Repaired)Documento49 páginasCRIME ANALYSIS AND PREDICTION USING DATA MINING TECHNIQUES (1) (AutoRecovered) (Repaired)AMALA MARIYAAinda não há avaliações
- ISTAfrica2020 Paper Ref 124Documento10 páginasISTAfrica2020 Paper Ref 124Doreen GiftAinda não há avaliações
- Data Driven Policing FinishedDocumento11 páginasData Driven Policing Finishedapi-531950435Ainda não há avaliações
- Crime (Paper 4)Documento8 páginasCrime (Paper 4)Geetika SinghAinda não há avaliações
- Police Crime Recording and Investigation Systems - A User's ViewDocumento26 páginasPolice Crime Recording and Investigation Systems - A User's ViewDinomarshal PezumAinda não há avaliações
- Criminal Profiling Using Machine LearninDocumento7 páginasCriminal Profiling Using Machine LearninRui PereiraAinda não há avaliações
- FICCI-EY Predictive PolicingDocumento32 páginasFICCI-EY Predictive PolicingoxynetAinda não há avaliações
- A Critical Assessment of The Big Data Approach To Violent Crime Analysis During LockdownsDocumento7 páginasA Critical Assessment of The Big Data Approach To Violent Crime Analysis During LockdownsV MAinda não há avaliações
- Widm 1208Documento19 páginasWidm 1208tulusta sipahutarAinda não há avaliações
- Computer ApplicationsDocumento6 páginasComputer ApplicationsSirajuddin AAinda não há avaliações
- Hybrid Approach To Crime Prediction Using Deep Learning: Jaravindhar@hindustanuniv - Ac.inDocumento10 páginasHybrid Approach To Crime Prediction Using Deep Learning: Jaravindhar@hindustanuniv - Ac.inTapan ChowdhuryAinda não há avaliações
- How Data Mining Can Help in Crime and Fraud DetectionDocumento5 páginasHow Data Mining Can Help in Crime and Fraud DetectionKerry LiezAinda não há avaliações
- Crime PredictionDocumento11 páginasCrime PredictionSajjad Hussain JanjuaAinda não há avaliações
- Final Draft of Dissertation Project.Documento14 páginasFinal Draft of Dissertation Project.Mrudula JoshiAinda não há avaliações
- Behavioural Analytics in Cyber Security For Digital Forensics ApplicationDocumento8 páginasBehavioural Analytics in Cyber Security For Digital Forensics ApplicationAnonymous Gl4IRRjzNAinda não há avaliações
- Computer Science and Crime 2016Documento6 páginasComputer Science and Crime 2016Frank VillaAinda não há avaliações
- Crime Investigation System PDFDocumento4 páginasCrime Investigation System PDFKrunal PatelAinda não há avaliações
- IJSC Vol 7 Iss 4 Paper 5 1459 1466Documento9 páginasIJSC Vol 7 Iss 4 Paper 5 1459 1466ajaythermalAinda não há avaliações
- Dissertation On Cybercrime in IndiaDocumento6 páginasDissertation On Cybercrime in IndiaCustomWrittenPaperSingapore100% (1)
- Design and Implementation of Web Based Crime Reporting SystemDocumento26 páginasDesign and Implementation of Web Based Crime Reporting SystemManuAinda não há avaliações
- Transnational Crimes and Information TechnologiesDocumento6 páginasTransnational Crimes and Information TechnologiesS. M. Hasan ZidnyAinda não há avaliações
- Crime Analysis SurveypaperDocumento6 páginasCrime Analysis SurveypaperVivek AmrutkarAinda não há avaliações
- .NG - 46992.24317 Design and Implementation of Web Based Crime Reporting SystemDocumento41 páginas.NG - 46992.24317 Design and Implementation of Web Based Crime Reporting SystemManuAinda não há avaliações
- Cybercrime Forecasting Using Data Mining TechniquesDocumento5 páginasCybercrime Forecasting Using Data Mining TechniquesBhupender YadavAinda não há avaliações
- JCP 01 00029Documento17 páginasJCP 01 00029noorAinda não há avaliações
- Week-6 - Case Study DiscussionDocumento3 páginasWeek-6 - Case Study DiscussionNidheena K SAinda não há avaliações
- Crime Data Mining - Case StudyDocumento33 páginasCrime Data Mining - Case Studyrajv88100% (4)
- Devil Crime Rate Prediction Using K-MeansDocumento14 páginasDevil Crime Rate Prediction Using K-MeansYash JaiswalAinda não há avaliações
- Design and Implementation of A Computerized Biological Verification System For Crime Control (Documento12 páginasDesign and Implementation of A Computerized Biological Verification System For Crime Control (Suzan OmagaAinda não há avaliações
- An Contemplated Approach For Criminality Data Using Mining AlgorithmDocumento5 páginasAn Contemplated Approach For Criminality Data Using Mining AlgorithmRahul SharmaAinda não há avaliações
- Cybercrime in Ecuador Exploration Defines National PoliciesDocumento7 páginasCybercrime in Ecuador Exploration Defines National PoliciesJose AntambaAinda não há avaliações
- Building an Integrated Tech Framework for Crime PreventionDocumento16 páginasBuilding an Integrated Tech Framework for Crime PreventionSaanii UmarAinda não há avaliações
- Iijcs 2014 10 10 10Documento5 páginasIijcs 2014 10 10 10International Journal of Application or Innovation in Engineering & ManagementAinda não há avaliações
- PROJECT Crime Management Information SystemsDocumento38 páginasPROJECT Crime Management Information Systemsmercuryboss90Ainda não há avaliações
- Data MiningDocumento9 páginasData MiningRanjitha MadaAinda não há avaliações
- Crime Rate Prediction Using KNN: Ms. Vrushali Pednekar Ms. Trupti Mahale Ms. Pratiksha Gadhave Prof. Arti GoreDocumento4 páginasCrime Rate Prediction Using KNN: Ms. Vrushali Pednekar Ms. Trupti Mahale Ms. Pratiksha Gadhave Prof. Arti GoreEditor IJRITCCAinda não há avaliações
- CH 6 Case StudyDocumento1 páginaCH 6 Case StudyErlangga RizkyAinda não há avaliações
- CH 6 - Case StudyDocumento1 páginaCH 6 - Case Studydivyesh75% (4)
- What Are The Benefits of Intelligence-Driven Prosecution For Crime Fighters and TheDocumento1 páginaWhat Are The Benefits of Intelligence-Driven Prosecution For Crime Fighters and TheFahmia Winata8Ainda não há avaliações
- Exploratory Data Analysis and Crime Prevention Using Machine Learning The Case of GhanaDocumento10 páginasExploratory Data Analysis and Crime Prevention Using Machine Learning The Case of GhanaInternational Journal of Innovative Science and Research TechnologyAinda não há avaliações
- Degeling Berendt 2017Documento17 páginasDegeling Berendt 2017Juan Pablo MontenegroAinda não há avaliações
- Crime Prediction Using Machine Learning and Deep Learning: A Systematic Review and Future DirectionsDocumento35 páginasCrime Prediction Using Machine Learning and Deep Learning: A Systematic Review and Future DirectionsmanuAinda não há avaliações
- A Multidisciplinary Approach To Policing: Strategies For Effectively Dealing With Crime in The Transition Toward An Ideal Policing ModelDocumento15 páginasA Multidisciplinary Approach To Policing: Strategies For Effectively Dealing With Crime in The Transition Toward An Ideal Policing ModelInternational Journal of Innovative Science and Research TechnologyAinda não há avaliações
- Crime Analysis and Prediction Using Data PDFDocumento6 páginasCrime Analysis and Prediction Using Data PDFvarun shrivastavaAinda não há avaliações
- Automated Fingerprint Biometric System for Crime Record ManagementDocumento11 páginasAutomated Fingerprint Biometric System for Crime Record Managementshaikhsahil hafijAinda não há avaliações
- Leapcm Ass2Documento4 páginasLeapcm Ass2Monica RilveriaAinda não há avaliações
- CriminologyDocumento4 páginasCriminologyRONNY WINGAAinda não há avaliações
- Accepted Manuscript: Computers & SecurityDocumento39 páginasAccepted Manuscript: Computers & SecurityBehnamAinda não há avaliações
- Crime Analysis and The CriticalDocumento3 páginasCrime Analysis and The CriticalRubelyn EngAinda não há avaliações
- Modern Law Enforcement and Crime PreventionDocumento12 páginasModern Law Enforcement and Crime PreventionSaba Iqbal100% (3)
- Final EportDocumento20 páginasFinal EportIngrid BayiyanaAinda não há avaliações
- Lifetime Physical Fitness and Wellness A Personalized Program 14th Edition Hoeger Test BankDocumento34 páginasLifetime Physical Fitness and Wellness A Personalized Program 14th Edition Hoeger Test Bankbefoolabraida9d6xm100% (27)
- Six Thinking Hats TrainingDocumento34 páginasSix Thinking Hats TrainingNishanthan100% (1)
- Error 500 Unknown Column 'A.note' in 'Field List' - Joomla! Forum - Community, Help and SupportDocumento1 páginaError 500 Unknown Column 'A.note' in 'Field List' - Joomla! Forum - Community, Help and Supportsmart.engineerAinda não há avaliações
- Brexit Essay - Jasraj SinghDocumento6 páginasBrexit Essay - Jasraj SinghJasraj SinghAinda não há avaliações
- What is Software Development Life Cycle (SDLC)? Key Phases and ActivitiesDocumento11 páginasWhat is Software Development Life Cycle (SDLC)? Key Phases and ActivitiessachinAinda não há avaliações
- Manual de Motores Vol 4Documento75 páginasManual de Motores Vol 4Gabriel Piñon Conde100% (1)
- Dimetra Tetra System White PaperDocumento6 páginasDimetra Tetra System White PapermosaababbasAinda não há avaliações
- TROOP - of - District 2013 Scouting's Journey To ExcellenceDocumento2 páginasTROOP - of - District 2013 Scouting's Journey To ExcellenceAReliableSourceAinda não há avaliações
- Seaflo Outdoor - New Pedal Kayak Recommendation July 2022Documento8 páginasSeaflo Outdoor - New Pedal Kayak Recommendation July 2022wgcvAinda não há avaliações
- 1st WeekDocumento89 páginas1st Weekbicky dasAinda não há avaliações
- A Study of Arcing Fault in The Low-Voltage Electrical InstallationDocumento11 páginasA Study of Arcing Fault in The Low-Voltage Electrical Installationaddin100% (1)
- Duratone eDocumento1 páginaDuratone eandreinalicAinda não há avaliações
- Frito LaysDocumento6 páginasFrito LaysElcamino Torrez50% (2)
- Banking Finance Agile TestingDocumento4 páginasBanking Finance Agile Testinganil1karnatiAinda não há avaliações
- Research Paper About Cebu PacificDocumento8 páginasResearch Paper About Cebu Pacificwqbdxbvkg100% (1)
- The Problem and Its SettingDocumento36 páginasThe Problem and Its SettingRodel CamposoAinda não há avaliações
- Washington State Employee - 4/2010Documento8 páginasWashington State Employee - 4/2010WFSEc28Ainda não há avaliações
- Aesculap Qatar UniversityDocumento3 páginasAesculap Qatar UniversityAl Quran AcademyAinda não há avaliações
- Data Science Machine LearningDocumento15 páginasData Science Machine LearningmagrinraphaelAinda não há avaliações
- Notes and Questions On-Op AmpDocumento11 páginasNotes and Questions On-Op AmpjitenAinda não há avaliações
- PC-II Taftan Master PlanDocumento15 páginasPC-II Taftan Master PlanMunir HussainAinda não há avaliações
- 3.1.2 Cable FPLR 2X18 AwgDocumento3 páginas3.1.2 Cable FPLR 2X18 Awgluis rios granadosAinda não há avaliações
- Javacore 20100918 202221 6164 0003Documento44 páginasJavacore 20100918 202221 6164 0003actmon123Ainda não há avaliações
- Tool Catalog Ei18e-11020Documento370 páginasTool Catalog Ei18e-11020Marcelo Diesel85% (13)
- 7 ways to improve energy efficiency of pumpsDocumento1 página7 ways to improve energy efficiency of pumpsCharina Malolot VillalonAinda não há avaliações
- My Sweet Beer - 23 MaiDocumento14 páginasMy Sweet Beer - 23 Maihaytem chakiriAinda não há avaliações
- Smart Card PresentationDocumento4 páginasSmart Card PresentationNitika MithalAinda não há avaliações
- Wireshark Lab: 802.11: Approach, 6 Ed., J.F. Kurose and K.W. RossDocumento5 páginasWireshark Lab: 802.11: Approach, 6 Ed., J.F. Kurose and K.W. RossN Azzati LabibahAinda não há avaliações
- Study apparel export order processDocumento44 páginasStudy apparel export order processSHRUTI CHUGH100% (1)
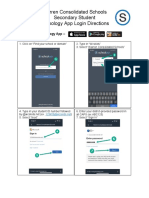
- Schoology App Login DirectionsDocumento5 páginasSchoology App Login Directionsapi-234989244Ainda não há avaliações