Você também pode gostar
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNo EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNota: 4 de 5 estrelas4/5 (5794)
- Support Vector Machine ReferencesDocumento1 páginaSupport Vector Machine Referencesnalluri_08Ainda não há avaliações
- Machine Learning ReferencesDocumento3 páginasMachine Learning Referencesnalluri_08Ainda não há avaliações
- Decision Tree ReferencesDocumento1 páginaDecision Tree Referencesnalluri_08Ainda não há avaliações
- Machine Learning Lesson - PlanDocumento3 páginasMachine Learning Lesson - Plannalluri_08Ainda não há avaliações
- Graphs PDFDocumento1 páginaGraphs PDFnalluri_08Ainda não há avaliações
- Script Programming: 18IT403 B.Tech., (Semester - IV) Section ADocumento2 páginasScript Programming: 18IT403 B.Tech., (Semester - IV) Section Analluri_08Ainda não há avaliações
- Ida PDFDocumento62 páginasIda PDFnalluri_08Ainda não há avaliações
- Bapatla Engineering College: Unit - IDocumento2 páginasBapatla Engineering College: Unit - Inalluri_08Ainda não há avaliações
- R Programming NotesDocumento113 páginasR Programming Notesnalluri_08Ainda não há avaliações
- Y18curriculam PDFDocumento160 páginasY18curriculam PDFnalluri_08Ainda não há avaliações
- Y18curriculam PDFDocumento160 páginasY18curriculam PDFnalluri_08Ainda não há avaliações
- Script Programming: Scheme of Valuation 18IT404 B.Tech., (Semester-IV)Documento2 páginasScript Programming: Scheme of Valuation 18IT404 B.Tech., (Semester-IV)nalluri_08Ainda não há avaliações
- Teaching Content - 1 18IT403Documento9 páginasTeaching Content - 1 18IT403nalluri_08Ainda não há avaliações
- Bapatla Engineering College: Unit - IDocumento3 páginasBapatla Engineering College: Unit - Inalluri_08Ainda não há avaliações
- Hall Ticket Number:: III/IV B.Tech (Regular/Supplementary) DEGREE EXAMINATIONDocumento11 páginasHall Ticket Number:: III/IV B.Tech (Regular/Supplementary) DEGREE EXAMINATIONnalluri_08Ainda não há avaliações
- Sheet Name Reg No Look Up KBR Pavk NSR Name Look Up KRT KSK GP PSR KSR MPK DSP PCR PRK BK PRP KSP KKKDocumento35 páginasSheet Name Reg No Look Up KBR Pavk NSR Name Look Up KRT KSK GP PSR KSR MPK DSP PCR PRK BK PRP KSP KKKnalluri_08Ainda não há avaliações
- List of Symbols: Number SetsDocumento1 páginaList of Symbols: Number Setsnalluri_08Ainda não há avaliações
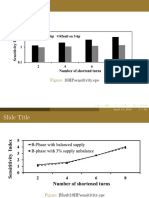
- 10hpsensitivity - Eps: April 14, 2016 1 / 49Documento49 páginas10hpsensitivity - Eps: April 14, 2016 1 / 49nalluri_08Ainda não há avaliações
- This Is On Algorithms: 1 Algorithm in L TEXDocumento2 páginasThis Is On Algorithms: 1 Algorithm in L TEXnalluri_08Ainda não há avaliações
- "Hello, World": (Printf ) (P P Malloc P Malloc Free (P) )Documento1 página"Hello, World": (Printf ) (P P Malloc P Malloc Free (P) )nalluri_08Ainda não há avaliações
- Rigid Body Dynamics: Coriolis AccelerationDocumento3 páginasRigid Body Dynamics: Coriolis Accelerationnalluri_08Ainda não há avaliações
- Using graphics and pictures in L TEX 2ε: 1 The picture environmentDocumento3 páginasUsing graphics and pictures in L TEX 2ε: 1 The picture environmentnalluri_08Ainda não há avaliações
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNo EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNota: 4 de 5 estrelas4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)No EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Nota: 4 de 5 estrelas4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingNo EverandThe Little Book of Hygge: Danish Secrets to Happy LivingNota: 3.5 de 5 estrelas3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerNo EverandThe Emperor of All Maladies: A Biography of CancerNota: 4.5 de 5 estrelas4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItNo EverandNever Split the Difference: Negotiating As If Your Life Depended On ItNota: 4.5 de 5 estrelas4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyNo EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyNota: 3.5 de 5 estrelas3.5/5 (2259)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNo EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNota: 4.5 de 5 estrelas4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNo EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNota: 3.5 de 5 estrelas3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnNo EverandTeam of Rivals: The Political Genius of Abraham LincolnNota: 4.5 de 5 estrelas4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNo EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNota: 4.5 de 5 estrelas4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNo EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNota: 4.5 de 5 estrelas4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaNo EverandThe Unwinding: An Inner History of the New AmericaNota: 4 de 5 estrelas4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNo EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNota: 4 de 5 estrelas4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)No EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Nota: 4.5 de 5 estrelas4.5/5 (121)