Você também pode gostar
- HEC Recognized Agriculture Sciences Journals (Valid Up To 30 June, 2018)Documento3 páginasHEC Recognized Agriculture Sciences Journals (Valid Up To 30 June, 2018)Nazimah MaqboolAinda não há avaliações
- Kanwal MTR Protein ExtractionDocumento26 páginasKanwal MTR Protein ExtractionNazimah MaqboolAinda não há avaliações
- RdaDocumento52 páginasRdaNazimah MaqboolAinda não há avaliações
- Natural Science Journals HEC RecognisedDocumento4 páginasNatural Science Journals HEC RecognisedLucky KhanAinda não há avaliações
- Lab SolutionsDocumento6 páginasLab SolutionsMohd Hafiz AhmadAinda não há avaliações
- Vulnerability of Sunflower Germination and Metal Translocation Under Heavy Metals ContaminationDocumento14 páginasVulnerability of Sunflower Germination and Metal Translocation Under Heavy Metals ContaminationNazimah MaqboolAinda não há avaliações
- Bibi Pak DamanDocumento87 páginasBibi Pak DamanNazimah MaqboolAinda não há avaliações
- Volume Mass / ConcentrationDocumento6 páginasVolume Mass / ConcentrationNazimah MaqboolAinda não há avaliações
- 05 Introduction To Plant Pathology - 0 PDFDocumento20 páginas05 Introduction To Plant Pathology - 0 PDFNazimah MaqboolAinda não há avaliações
- Awais Qarni Pdfbooksfree - PK PDFDocumento95 páginasAwais Qarni Pdfbooksfree - PK PDFNazimah MaqboolAinda não há avaliações
- Iso-Osmotic Effect of NaCl and PEG On GrowthDocumento11 páginasIso-Osmotic Effect of NaCl and PEG On GrowthNazimah MaqboolAinda não há avaliações
- Lab SolutionsDocumento6 páginasLab SolutionsMohd Hafiz AhmadAinda não há avaliações
- HEC Recognized Agriculture Sciences Journals (Valid Up To 30 June, 2018)Documento3 páginasHEC Recognized Agriculture Sciences Journals (Valid Up To 30 June, 2018)Nazimah MaqboolAinda não há avaliações
- An Introduction To Plant TaxanomyDocumento187 páginasAn Introduction To Plant TaxanomyNazimah Maqbool100% (1)
- Iso-Osmotic Effect of NaCl and PEG On GrowthDocumento11 páginasIso-Osmotic Effect of NaCl and PEG On GrowthNazimah MaqboolAinda não há avaliações
- BacteriaDocumento6 páginasBacteriaNazimah MaqboolAinda não há avaliações
- Introduction To Plant PhysiologyDocumento23 páginasIntroduction To Plant PhysiologyRose Romero80% (5)
- 324SDocumento329 páginas324SNazimah MaqboolAinda não há avaliações
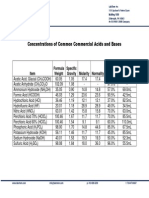
- Concentrations of Common Commercial Acids and BasesDocumento1 páginaConcentrations of Common Commercial Acids and BasesNazimah MaqboolAinda não há avaliações
- Share Repurchase MeanDocumento5 páginasShare Repurchase MeanNazimah MaqboolAinda não há avaliações
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNo EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNota: 4 de 5 estrelas4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)No EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Nota: 4 de 5 estrelas4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNo EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNota: 3.5 de 5 estrelas3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNo EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNota: 4 de 5 estrelas4/5 (895)
- The Little Book of Hygge: Danish Secrets to Happy LivingNo EverandThe Little Book of Hygge: Danish Secrets to Happy LivingNota: 3.5 de 5 estrelas3.5/5 (400)
- Never Split the Difference: Negotiating As If Your Life Depended On ItNo EverandNever Split the Difference: Negotiating As If Your Life Depended On ItNota: 4.5 de 5 estrelas4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNo EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNota: 4.5 de 5 estrelas4.5/5 (474)
- The Emperor of All Maladies: A Biography of CancerNo EverandThe Emperor of All Maladies: A Biography of CancerNota: 4.5 de 5 estrelas4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnNo EverandTeam of Rivals: The Political Genius of Abraham LincolnNota: 4.5 de 5 estrelas4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNo EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNota: 4.5 de 5 estrelas4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNo EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNota: 4.5 de 5 estrelas4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyNo EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyNota: 3.5 de 5 estrelas3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNo EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNota: 4 de 5 estrelas4/5 (1090)
- The Unwinding: An Inner History of the New AmericaNo EverandThe Unwinding: An Inner History of the New AmericaNota: 4 de 5 estrelas4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)No EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Nota: 4.5 de 5 estrelas4.5/5 (121)
- Practice of Introductory Time Series With RDocumento22 páginasPractice of Introductory Time Series With Rapi-285777244Ainda não há avaliações
- 2729-6708-1-SM-mgt Perub-Bdy Orgn-Kualitas Kerja THD Kinerja PegawaiDocumento8 páginas2729-6708-1-SM-mgt Perub-Bdy Orgn-Kualitas Kerja THD Kinerja Pegawaidini andrianiAinda não há avaliações
- Least Squares RegressionDocumento7 páginasLeast Squares RegressionHelena AdamAinda não há avaliações
- This Study Resource Was: MAT 243 Project Three Summary ReportDocumento8 páginasThis Study Resource Was: MAT 243 Project Three Summary ReportnellyAinda não há avaliações
- Merged DocumentDocumento39 páginasMerged Documentgabriel pAinda não há avaliações
- Che 621 Midterm 2Documento16 páginasChe 621 Midterm 2Anshu IngleAinda não há avaliações
- 40 Interview Questions Asked at Startups in Machine Learning - Data ScienceDocumento33 páginas40 Interview Questions Asked at Startups in Machine Learning - Data SciencePallav Anand100% (3)
- Investigating The Relationship Between Scores: © 2006 Mcgraw-Hill Higher Education. All Rights ReservedDocumento20 páginasInvestigating The Relationship Between Scores: © 2006 Mcgraw-Hill Higher Education. All Rights ReservedGabrielle Anne San GabrielAinda não há avaliações
- The Relationship Between The Standardized Root Mean Square Residual and Model Misspecification in Factor Analysis ModelsDocumento20 páginasThe Relationship Between The Standardized Root Mean Square Residual and Model Misspecification in Factor Analysis ModelsAngel Christopher Zegarra LopezAinda não há avaliações
- Linear Regression With PythonDocumento1 páginaLinear Regression With PythonAseer AnwarAinda não há avaliações
- Jurnal Eko RegionalDocumento14 páginasJurnal Eko Regionalham daniAinda não há avaliações
- Tugas Manrpo 2020 Kelompok 7 Forecasting CaseDocumento13 páginasTugas Manrpo 2020 Kelompok 7 Forecasting CasewinandaAinda não há avaliações
- ch14 JWC7Documento3 páginasch14 JWC7Rashik Intesir AdorAinda não há avaliações
- Chapter 5 Solutions Solution Manual Introductory Econometrics For FinanceDocumento9 páginasChapter 5 Solutions Solution Manual Introductory Econometrics For FinanceNazim Uddin MahmudAinda não há avaliações
- Presentation 1Documento12 páginasPresentation 1eflitadataAinda não há avaliações
- 08 Dummy VariableDocumento24 páginas08 Dummy VariableZiaNaPiramLiAinda não há avaliações
- Report hw1Documento10 páginasReport hw1api-515961562Ainda não há avaliações
- Correlation DesignDocumento5 páginasCorrelation DesignBernadeth TenorioAinda não há avaliações
- Alessandro Carrato From Chain Ladder To Individual Claims Reserving Using Machine Learning ASTIN ColloquiumDocumento19 páginasAlessandro Carrato From Chain Ladder To Individual Claims Reserving Using Machine Learning ASTIN ColloquiumMatheus BarretoAinda não há avaliações
- Regression in R & Python PaperDocumento38 páginasRegression in R & Python PaperdesaihaAinda não há avaliações
- Distinguishing Between Random and Fixed: Variables, Effects, and CoefficientsDocumento3 páginasDistinguishing Between Random and Fixed: Variables, Effects, and CoefficientsPradyuman SharmaAinda não há avaliações
- Pro1 FinalDocumento6 páginasPro1 FinalLizi ChenAinda não há avaliações
- Mediator Versus Moderator VariablesDocumento2 páginasMediator Versus Moderator VariablesWael BasriAinda não há avaliações
- Subject: COMP - VI / R-2016 / MLDocumento9 páginasSubject: COMP - VI / R-2016 / MLW PAinda não há avaliações
- Pengaruh Skeptisisme Profesional Auditor, Kompetensi, Independensi Dan Kompleksitas Audit Terhadap Kualitas AuditDocumento18 páginasPengaruh Skeptisisme Profesional Auditor, Kompetensi, Independensi Dan Kompleksitas Audit Terhadap Kualitas AuditVeronika TianaAinda não há avaliações
- Britannia Industries Historical Closing Price Data-FinalDocumento48 páginasBritannia Industries Historical Closing Price Data-FinalSourabh ChiprikarAinda não há avaliações
- Biostat Finals ReviewerDocumento4 páginasBiostat Finals ReviewerAnne Olfato ParojinogAinda não há avaliações
- ANL252 SU5 Jul2022Documento58 páginasANL252 SU5 Jul2022EbadAinda não há avaliações
- Correleation and PMCCDocumento12 páginasCorreleation and PMCCbhowteAinda não há avaliações
- SYLLABUS IN ADVANCED STATISTICS PHDDocumento2 páginasSYLLABUS IN ADVANCED STATISTICS PHDchiara maye notarte100% (3)