Você também pode gostar
- Pomodoro Cheat SheetDocumento1 páginaPomodoro Cheat Sheetapi-187219090Ainda não há avaliações
- E-Tivity 2.2 Tharcisse 217010849Documento7 páginasE-Tivity 2.2 Tharcisse 217010849Tharcisse Tossen TharryAinda não há avaliações
- Rss Grad Diploma Module5 Solutions Specimen B PDFDocumento15 páginasRss Grad Diploma Module5 Solutions Specimen B PDFA PirzadaAinda não há avaliações
- Info PcaDocumento3 páginasInfo PcaUma MaheshAinda não há avaliações
- CDASH Implementation Guide 2.0Documento117 páginasCDASH Implementation Guide 2.0octavioascheriAinda não há avaliações
- Algorithmic Trading & DMA: An Introduction To Direct Access and Trading StrategiesDocumento595 páginasAlgorithmic Trading & DMA: An Introduction To Direct Access and Trading Strategiesbig_pete__100% (6)
- Blade Runner Sketchbook PDFDocumento99 páginasBlade Runner Sketchbook PDFRicardo Klenner Moncada100% (2)
- Week 4 Seminar QuestionsDocumento5 páginasWeek 4 Seminar QuestionsRoxana AntociAinda não há avaliações
- Genetic MapsDocumento41 páginasGenetic Mapsgaby-01Ainda não há avaliações
- Problem 3 - R WorkDocumento5 páginasProblem 3 - R WorkAnand BharadwajAinda não há avaliações
- Detecting and Treating Outliers - Treating The Odd One Out!: Data Science BlogathonDocumento6 páginasDetecting and Treating Outliers - Treating The Odd One Out!: Data Science BlogathonNarendra SinghAinda não há avaliações
- Missing Data Analysis: University College London, 2015Documento37 páginasMissing Data Analysis: University College London, 2015charudattasonawane55Ainda não há avaliações
- Making Use of Incomplete Observations in The Analysis of Structural Equation Models The CALIS Procedure's Full Information Maximum Likelihood Method in SAS STAT 9.3Documento20 páginasMaking Use of Incomplete Observations in The Analysis of Structural Equation Models The CALIS Procedure's Full Information Maximum Likelihood Method in SAS STAT 9.3arijitroyAinda não há avaliações
- Handling Missing ValueDocumento12 páginasHandling Missing ValueNarendra SinghAinda não há avaliações
- Use of Statistics by ScientistDocumento22 páginasUse of Statistics by Scientistvzimak2355Ainda não há avaliações
- Co-So-Di-Truyen-Chon-Giong-Cay-Trong - Geneticmaps - (Cuuduongthancong - Com)Documento41 páginasCo-So-Di-Truyen-Chon-Giong-Cay-Trong - Geneticmaps - (Cuuduongthancong - Com)Hai HeoAinda não há avaliações
- 1preparing DataDocumento6 páginas1preparing DataUkkyAinda não há avaliações
- BC 2014 Session2Documento45 páginasBC 2014 Session2Abhilash BhatAinda não há avaliações
- Negative Binomial Regression - R Data Analysis ExamplesDocumento11 páginasNegative Binomial Regression - R Data Analysis ExamplesFhano HendrianAinda não há avaliações
- Nomor 3 UtsDocumento6 páginasNomor 3 UtsNita FerdianaAinda não há avaliações
- Missing Data Imputation Using Singular Value DecompositionDocumento6 páginasMissing Data Imputation Using Singular Value DecompositionAlamgir MohammedAinda não há avaliações
- Programming Python StatisticsDocumento7 páginasProgramming Python StatisticsTate KnightAinda não há avaliações
- Capstone Project - Credit Card Fraud Prediction - Alexandre DaltroDocumento15 páginasCapstone Project - Credit Card Fraud Prediction - Alexandre DaltroDKNAinda não há avaliações
- ValuesDocumento30 páginasValuesSri AgustiniAinda não há avaliações
- Big Data ExerciesesDocumento6 páginasBig Data ExerciesesMenna ElfoulyAinda não há avaliações
- Assignment 1 - LP1Documento14 páginasAssignment 1 - LP1bbad070105Ainda não há avaliações
- IBM SPSS Missing ValuesDocumento34 páginasIBM SPSS Missing ValuesKuldeepBukarwalAinda não há avaliações
- Data Science Interview Q's - IDocumento11 páginasData Science Interview Q's - IRajaAinda não há avaliações
- ISOMAP in MLDocumento12 páginasISOMAP in MLVishwa MuthukumarAinda não há avaliações
- CBRG A Novel Algorithm For Handling Missing Data Using Bayesian Ridge Regression and FeaDocumento17 páginasCBRG A Novel Algorithm For Handling Missing Data Using Bayesian Ridge Regression and FeaEECE MasterAinda não há avaliações
- Visual Presentation of Data: by Means of Box PlotsDocumento4 páginasVisual Presentation of Data: by Means of Box PlotshutomorezkyAinda não há avaliações
- Tutorial 4Documento8 páginasTutorial 4POEASOAinda não há avaliações
- Some Methods of Detection of Outliers in Linear Regression Model-Ranjit PDFDocumento19 páginasSome Methods of Detection of Outliers in Linear Regression Model-Ranjit PDFmuralidharanAinda não há avaliações
- 6 Different Ways To Compensate For Missing Values in A DatasetDocumento6 páginas6 Different Ways To Compensate For Missing Values in A DatasetichaAinda não há avaliações
- Experiments of FODSDocumento5 páginasExperiments of FODSdark beastAinda não há avaliações
- 11 4variationswithinadatasetDocumento4 páginas11 4variationswithinadatasetChristian BatistaAinda não há avaliações
- HW2 For Students PDFDocumento5 páginasHW2 For Students PDFmsk123123Ainda não há avaliações
- ISOMAPDocumento11 páginasISOMAPVishwa Muthukumar100% (1)
- R Code For Discriminant and Cluster AnalysisDocumento23 páginasR Code For Discriminant and Cluster AnalysisNguyễn OanhAinda não há avaliações
- Data Compression Seminar ReportDocumento34 páginasData Compression Seminar ReportRahul Biradar67% (6)
- Predicting Breast Cancer Using Logistic Regression - by Mo Kaiser - The Startup - MediumDocumento15 páginasPredicting Breast Cancer Using Logistic Regression - by Mo Kaiser - The Startup - MediumGhifari RakaAinda não há avaliações
- WS3 7stamariaDocumento6 páginasWS3 7stamariaJian KarloAinda não há avaliações
- Data Mining Lab Maual Through Python 031023Documento22 páginasData Mining Lab Maual Through Python 031023Manish KumarAinda não há avaliações
- IDS Project Group 11Documento35 páginasIDS Project Group 11Faheem AkramAinda não há avaliações
- Lesson 1Documento18 páginasLesson 1lorosiricoAinda não há avaliações
- Publication 2Documento8 páginasPublication 2MariaAinda não há avaliações
- A Comparative Study of Multiple Imputation and Maximum Likelihood Methods of Imputing Missing Data in ADocumento14 páginasA Comparative Study of Multiple Imputation and Maximum Likelihood Methods of Imputing Missing Data in Asegun aladeAinda não há avaliações
- Illustration of Using Excel To Find Maximum Likelihood EstimatesDocumento14 páginasIllustration of Using Excel To Find Maximum Likelihood EstimatesRustam MuhammadAinda não há avaliações
- Lab 4 - Unsupervised Learning: K-Means ClusteringDocumento7 páginasLab 4 - Unsupervised Learning: K-Means ClusteringFaisal zafarAinda não há avaliações
- Ass-3 DsDocumento7 páginasAss-3 DsVedant AndhaleAinda não há avaliações
- Lec3 SWN BC-1Documento18 páginasLec3 SWN BC-1Hamza Abu AsbaAinda não há avaliações
- Handling Missing DataDocumento23 páginasHandling Missing Datassakhare2001Ainda não há avaliações
- Sampling Distributions CourseraDocumento8 páginasSampling Distributions CourserarrutayisireAinda não há avaliações
- VCTest 1 BF09 AnsDocumento9 páginasVCTest 1 BF09 AnsDerick OrAinda não há avaliações
- Probability and Statistics Week 1 Text BookDocumento10 páginasProbability and Statistics Week 1 Text BookHina Hanif UsmanAinda não há avaliações
- Data Science - ProbabilityDocumento53 páginasData Science - ProbabilityNguyen Van TienAinda não há avaliações
- MIssing Data Imputation Using Machine Learning AlgorithmDocumento11 páginasMIssing Data Imputation Using Machine Learning AlgorithmdataprodcsAinda não há avaliações
- Lecture 9 PDFDocumento22 páginasLecture 9 PDFTiago MartinsAinda não há avaliações
- Dealing With Missing Data in Python PandasDocumento14 páginasDealing With Missing Data in Python PandasSelloAinda não há avaliações
- Monteiro Iwcca2011Documento36 páginasMonteiro Iwcca2011antoniolamadeuAinda não há avaliações
- Data Preparation 1Documento17 páginasData Preparation 1Vivek MunjayasraAinda não há avaliações
- Interpret All Statistics and Graphs For Display Descriptive StatisticsDocumento22 páginasInterpret All Statistics and Graphs For Display Descriptive StatisticsShenron InamoratoAinda não há avaliações
- Data Mining AssignmentDocumento8 páginasData Mining AssignmentAmanat ConstructionAinda não há avaliações
- Data ScienceDocumento17 páginasData ScienceNabajitAinda não há avaliações
- Robust Nonlinear Regression: with Applications using RNo EverandRobust Nonlinear Regression: with Applications using RAinda não há avaliações
- Framework For Data Collection and Analysis - University of Maryland, College Park - Course Info - CourseraDocumento5 páginasFramework For Data Collection and Analysis - University of Maryland, College Park - Course Info - CourseraoctavioascheriAinda não há avaliações
- How To Install MedDRA With Pinnacle 21 Community - Pinnacle 21Documento4 páginasHow To Install MedDRA With Pinnacle 21 Community - Pinnacle 21octavioascheriAinda não há avaliações
- BIA - A Glossary of Terms Used in Payments and Settlement SystemsDocumento53 páginasBIA - A Glossary of Terms Used in Payments and Settlement SystemscjackchenAinda não há avaliações
- Combining and Analyzing Complex Data - University of Maryland, College Park - Course Info - CourseraDocumento3 páginasCombining and Analyzing Complex Data - University of Maryland, College Park - Course Info - CourseraoctavioascheriAinda não há avaliações
- R-Cheat SheetDocumento4 páginasR-Cheat SheetPrasad Marathe100% (1)
- Article - Future of Statistics - 2004Documento22 páginasArticle - Future of Statistics - 2004octavioascheriAinda não há avaliações
- Package SurveyDocumento129 páginasPackage SurveyoctavioascheriAinda não há avaliações
- Introduction To DplyrDocumento12 páginasIntroduction To DplyroctavioascheriAinda não há avaliações
- MICE PackageDocumento142 páginasMICE PackageoctavioascheriAinda não há avaliações
- Package SmoothHRDocumento11 páginasPackage SmoothHRoctavioascheriAinda não há avaliações
- Amelia PackageDocumento23 páginasAmelia PackageoctavioascheriAinda não há avaliações
- DoeDocumento143 páginasDoepandaprasadAinda não há avaliações
- Robotics - A Historical PerspectiveDocumento21 páginasRobotics - A Historical PerspectiveoctavioascheriAinda não há avaliações
- Package ForeignDocumento23 páginasPackage ForeignoctavioascheriAinda não há avaliações
- The Big Data Talent Gap White Paper1Documento15 páginasThe Big Data Talent Gap White Paper1octavioascheriAinda não há avaliações
- MATH 231-Statistics-Dr. Hanif MianDocumento3 páginasMATH 231-Statistics-Dr. Hanif MianSubayyal IlyasAinda não há avaliações
- Advanced Statistical InferenceDocumento7 páginasAdvanced Statistical InferencePere Barber LlorénsAinda não há avaliações
- Statistics NotesDocumento18 páginasStatistics Notesmike chanAinda não há avaliações
- Nonparametric StatisticsDocumento12 páginasNonparametric StatisticsisaganiAinda não há avaliações
- Sampling DistributionDocumento10 páginasSampling DistributionSamhith ReddyAinda não há avaliações
- Formulae and Table Booklet (PGDAST)Documento85 páginasFormulae and Table Booklet (PGDAST)venkat raAinda não há avaliações
- Probability, Statistics and Random Processes / T. VeerarajanDocumento1 páginaProbability, Statistics and Random Processes / T. Veerarajanakhilakky55Ainda não há avaliações
- Chapter 6 - Random Variables and Probability DistributionsDocumento101 páginasChapter 6 - Random Variables and Probability DistributionsPoison IveeAinda não há avaliações
- Navidi ch5Documento34 páginasNavidi ch5binoAinda não há avaliações
- Math 564, Theory of Probability, HW08 Zihan ZhuDocumento7 páginasMath 564, Theory of Probability, HW08 Zihan ZhuZihan ZhuAinda não há avaliações
- Test of HypothesisDocumento8 páginasTest of HypothesisS M NAHID HASANAinda não há avaliações
- Solution Manual For Statistics For The Behavioral Sciences 10th EditionDocumento37 páginasSolution Manual For Statistics For The Behavioral Sciences 10th Editionzedlenimenthy6kr100% (23)
- Basics of Hypothesis TestingDocumento36 páginasBasics of Hypothesis TestingRoyal MechanicalAinda não há avaliações
- Lec2 PDFDocumento8 páginasLec2 PDFJoy AJAinda não há avaliações
- Distribution Tables: Z Table T Table Chi-Square Table F Tables For: Alpha .10 Alpha .05 Alpha .025 Alpha .01Documento17 páginasDistribution Tables: Z Table T Table Chi-Square Table F Tables For: Alpha .10 Alpha .05 Alpha .025 Alpha .01Cahyo ApAinda não há avaliações
- Lecture 3 Prob I If 2016Documento44 páginasLecture 3 Prob I If 2016Mobasher MessiAinda não há avaliações
- Advance Statistics ModuleDocumento64 páginasAdvance Statistics Moduleleobert ortego100% (1)
- CHAPTER 1 Basic Concepts in Audit Sampling PDFDocumento10 páginasCHAPTER 1 Basic Concepts in Audit Sampling PDFJovelle LeonardoAinda não há avaliações
- Sampling Distribution-2: Unit-5Documento51 páginasSampling Distribution-2: Unit-5PAVAN YADAVAinda não há avaliações
- Normality TestDocumento10 páginasNormality Testdipen sapkotaAinda não há avaliações
- The Mann Whitney U TestDocumento4 páginasThe Mann Whitney U Testmnb0987Ainda não há avaliações
- LC M11 12SP-IVa-1Documento20 páginasLC M11 12SP-IVa-1Jean S. FraserAinda não há avaliações
- ST2134 Advanced Statistics Statistical InferenceDocumento2 páginasST2134 Advanced Statistics Statistical InferenceMihirinie AbhayawardhanaAinda não há avaliações
- EE315 Syllabus 211 LASTDocumento2 páginasEE315 Syllabus 211 LASTJafar 2014Ainda não há avaliações
- Ee5143 Pset1 PDFDocumento4 páginasEe5143 Pset1 PDFSarthak VoraAinda não há avaliações
- Test of HypothesisDocumento200 páginasTest of HypothesisCharlene AngacAinda não há avaliações
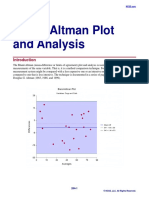
- Bland-Altman Plot and AnalysisDocumento25 páginasBland-Altman Plot and AnalysisRachmi FadillahAinda não há avaliações
- ARCAS Stats Workshop FlyerDocumento2 páginasARCAS Stats Workshop FlyerArchaeoAnalytics MeetingAinda não há avaliações
- Univariate and Bivariate AnalysisDocumento21 páginasUnivariate and Bivariate AnalysisMuhammad GulfamAinda não há avaliações