Você também pode gostar
- Combo Wave ManualDocumento6 páginasCombo Wave ManualHankStoranAinda não há avaliações
- 3 - Frequency DistributionDocumento28 páginas3 - Frequency DistributionShammah Sagunday100% (1)
- Symmetry in The Music of Thelonious Monk PDFDocumento97 páginasSymmetry in The Music of Thelonious Monk PDFMicheleRusso100% (1)
- StatisticsDocumento124 páginasStatisticsHaydee Umandal100% (1)
- ASTM Standards For MetallographyDocumento135 páginasASTM Standards For MetallographyAarón Escorza Mistrán100% (1)
- Tugas Statis PolitikDocumento4 páginasTugas Statis Politik21O9O6O81 RAJA TB PANDAPOTAN SIHALOHOAinda não há avaliações
- EDUP 3063 Task 1Documento21 páginasEDUP 3063 Task 1Amieer Abdul RahimAinda não há avaliações
- MAS Exam Reviewer - 060502Documento44 páginasMAS Exam Reviewer - 060502Clay MaaliwAinda não há avaliações
- Revision c1-3 AnswerDocumento8 páginasRevision c1-3 AnswerNadirah Mohamad SarifAinda não há avaliações
- Heart Rate Variability PDFDocumento7 páginasHeart Rate Variability PDFmik1989Ainda não há avaliações
- Top Down ParsingDocumento45 páginasTop Down Parsinggargsajal9Ainda não há avaliações
- Business Statistics - Assignment 1Documento11 páginasBusiness Statistics - Assignment 1mary michaelAinda não há avaliações
- Frequency Distribution TableDocumento1 páginaFrequency Distribution TableVictorino ViloriaAinda não há avaliações
- Introduction To Statistics and Application in Engineering AnalysisDocumento31 páginasIntroduction To Statistics and Application in Engineering AnalysiswubiedAinda não há avaliações
- Skripsi Thessa CHP III-biblioDocumento21 páginasSkripsi Thessa CHP III-biblioAndreas LalogirothAinda não há avaliações
- 002-Lecture 2 and 3-Organizationand Presentation of Data-S1920Documento15 páginas002-Lecture 2 and 3-Organizationand Presentation of Data-S1920Joy LanajaAinda não há avaliações
- Notes Chap 2 OrganizeDocumento9 páginasNotes Chap 2 OrganizeAbtehal AlfahaidAinda não há avaliações
- #HW2 - Tran Thi Thanh HoaDocumento7 páginas#HW2 - Tran Thi Thanh HoaThanh Hoa TrầnAinda não há avaliações
- Polestico - Assessment ReportDocumento15 páginasPolestico - Assessment ReportIrish PolesticoAinda não há avaliações
- Some of The Individual ValuesDocumento42 páginasSome of The Individual ValuessurojiddinAinda não há avaliações
- Measures of VariabilityDocumento13 páginasMeasures of VariabilitymochiAinda não há avaliações
- Tugas Terstruktur Muhammad Khoiruddin 1810302058Documento2 páginasTugas Terstruktur Muhammad Khoiruddin 1810302058Khoiruddin MuhammadAinda não há avaliações
- Quiz 1 Praktikum SahrulG 2111221001 DDocumento3 páginasQuiz 1 Praktikum SahrulG 2111221001 DSahrul GunaWanAinda não há avaliações
- Edur 8131 Graphical Display ExamplesDocumento9 páginasEdur 8131 Graphical Display ExamplesNazia SyedAinda não há avaliações
- Worksheet 1 - SolutionDocumento2 páginasWorksheet 1 - SolutionMasudul IslamAinda não há avaliações
- Presentation of DataDocumento9 páginasPresentation of Dataelizamae.jasma.mccAinda não há avaliações
- GREM203 Mallo YvoneJoyce MEDocumento3 páginasGREM203 Mallo YvoneJoyce MEYvone Joyce MalloAinda não há avaliações
- BS AssignmentDocumento9 páginasBS AssignmentDarya Khan BughioAinda não há avaliações
- Statistics & Probability Theory: Course Instructor: DR. MASOOD ANWARDocumento67 páginasStatistics & Probability Theory: Course Instructor: DR. MASOOD ANWARManal RizwanAinda não há avaliações
- Organizing and Interpreting Assessment DataDocumento20 páginasOrganizing and Interpreting Assessment DataAhlan Marciano Emmanuel De SilvaAinda não há avaliações
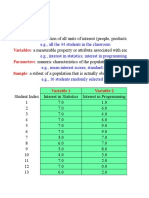
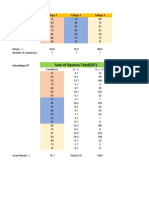
- Population: Variables: Parameters: SampleDocumento15 páginasPopulation: Variables: Parameters: SampleAbdu AbdoulayeAinda não há avaliações
- 192 I Made Aritama Uts StatisticDocumento4 páginas192 I Made Aritama Uts StatisticaritamaAinda não há avaliações
- Psych Stat Problem and AnswersDocumento3 páginasPsych Stat Problem and AnswersSummer LoveAinda não há avaliações
- OneWay AnovaDocumento9 páginasOneWay AnovaSubha ShiniAinda não há avaliações
- Suggested Solutions: Exercise 1: Introductory Statistics, Period 1Documento2 páginasSuggested Solutions: Exercise 1: Introductory Statistics, Period 1Alejandro RamirezAinda não há avaliações
- Chapter 2 VISUAL PRESENTATION OF DATADocumento14 páginasChapter 2 VISUAL PRESENTATION OF DATAIsraelAinda não há avaliações
- Introduction To Machine LearningDocumento48 páginasIntroduction To Machine LearningKylleAinda não há avaliações
- Lecture 2: Measures of Variability - Measures How Spread Out The Numbers AreDocumento6 páginasLecture 2: Measures of Variability - Measures How Spread Out The Numbers AreKhadim HussainAinda não há avaliações
- I. Data Minat: Milik Amalia Janatun Ma'wa 3A BiologiDocumento27 páginasI. Data Minat: Milik Amalia Janatun Ma'wa 3A BiologiAmalia Janatun Ma'waAinda não há avaliações
- Shailesh020902@gmail - Com 1Documento1 páginaShailesh020902@gmail - Com 1Shailendra chaudharyAinda não há avaliações
- UAS Nomer 2Documento7 páginasUAS Nomer 2Bee KemonAinda não há avaliações
- Uji Beda Sains Dan UmumDocumento19 páginasUji Beda Sains Dan UmumAde FitriyaniAinda não há avaliações
- Latihan 1Documento3 páginasLatihan 1achmad maregaAinda não há avaliações
- Data Terendah 65 Data Tertinggi 82 Kelas 6 Range 17 Interval 3Documento3 páginasData Terendah 65 Data Tertinggi 82 Kelas 6 Range 17 Interval 3IkhwanusShofaFitrianAinda não há avaliações
- 8.3 Measures of Dispersion: Standard DeviationDocumento19 páginas8.3 Measures of Dispersion: Standard Deviationbilal safiAinda não há avaliações
- Submission of AQs and ATs For LP4 Part A Paclita, AngelicaDocumento6 páginasSubmission of AQs and ATs For LP4 Part A Paclita, AngelicaRodrick Lim FormesAinda não há avaliações
- ANOVA For Repeated Measures - FontecillaDocumento49 páginasANOVA For Repeated Measures - FontecilladocjenniferfranciadamoAinda não há avaliações
- Group 1 Addmaths SbaDocumento25 páginasGroup 1 Addmaths SbaAidan FernandesAinda não há avaliações
- Descriptive Statistics PDFDocumento3 páginasDescriptive Statistics PDFVishal ShuklaAinda não há avaliações
- Histogram Data Distribusi FrekuensiDocumento13 páginasHistogram Data Distribusi FrekuensiAgung FirdausAinda não há avaliações
- Activity 4Documento2 páginasActivity 4Jherald AcopraAinda não há avaliações
- Activity 4Documento2 páginasActivity 4Jherald AcopraAinda não há avaliações
- Normal Distribution 2012Documento29 páginasNormal Distribution 2012Isaac Daplas RosarioAinda não há avaliações
- Let LetDocumento29 páginasLet LetIsaac Daplas RosarioAinda não há avaliações
- Tugas 1statistikDocumento2 páginasTugas 1statistikFitriana Afni sAinda não há avaliações
- Chapter3 Frequency DistributionDocumento20 páginasChapter3 Frequency Distributionmonkey luffyAinda não há avaliações
- Survey On Unsupervised Learning in Datamining: S.Uma Parameswari, B.JayanthiDocumento8 páginasSurvey On Unsupervised Learning in Datamining: S.Uma Parameswari, B.JayanthigeraltAinda não há avaliações
- Data Management NotesDocumento40 páginasData Management NotesDzan NerloAinda não há avaliações
- Regression: Standardized CoefficientsDocumento8 páginasRegression: Standardized CoefficientsgedleAinda não há avaliações
- Submission of AQs and ATs For LP4 Part A Paclita, AngelicaDocumento5 páginasSubmission of AQs and ATs For LP4 Part A Paclita, AngelicaRodrick Lim FormesAinda não há avaliações
- Business Report - Predictive Modelling - Rupesh KumarDocumento100 páginasBusiness Report - Predictive Modelling - Rupesh KumarRupesh GaurAinda não há avaliações
- Advantage: Useful For Large Data Sets. They Make The Form or Shape of The Disadvantage: Scores Tend To Lose Their Individual IdentityDocumento4 páginasAdvantage: Useful For Large Data Sets. They Make The Form or Shape of The Disadvantage: Scores Tend To Lose Their Individual IdentityQueen GaleonAinda não há avaliações
- Performance Based Assessment 11.4.2Documento8 páginasPerformance Based Assessment 11.4.2Nikkaa XOXAinda não há avaliações
- Instructional Module On Correlation and Regression ProceduresDocumento23 páginasInstructional Module On Correlation and Regression ProceduresAlbyra Bianca Sy TamcoAinda não há avaliações
- Batten & Bahaj 2008 The Prediction of The Hydrodynamic Performance of Amrine Current TurbinesDocumento12 páginasBatten & Bahaj 2008 The Prediction of The Hydrodynamic Performance of Amrine Current TurbinesthadgeAinda não há avaliações
- Echo Park Community Design OverlayDocumento4 páginasEcho Park Community Design OverlayechodocumentsAinda não há avaliações
- FEEDBACKDocumento43 páginasFEEDBACKMenaka kaulAinda não há avaliações
- Erc111 DKRCC - Es.rl0.e3.02 520H8596Documento24 páginasErc111 DKRCC - Es.rl0.e3.02 520H8596Miguel BascunanAinda não há avaliações
- Rakesh Mandal 180120031Documento7 páginasRakesh Mandal 180120031Rakesh RajputAinda não há avaliações
- Chemguide Atom, MoleculeDocumento28 páginasChemguide Atom, MoleculeSabina SabaAinda não há avaliações
- Elasticity & Oscillations: Ut Tension, Sic Vis As Extension, So Force. Extension Is Directly Proportional To ForceDocumento11 páginasElasticity & Oscillations: Ut Tension, Sic Vis As Extension, So Force. Extension Is Directly Proportional To ForceJustin Paul VallinanAinda não há avaliações
- 2.research Paper Solution of Fractional Partial DiffDocumento17 páginas2.research Paper Solution of Fractional Partial Diff8103 Suyash DewanganAinda não há avaliações
- Climate WorkbookDocumento119 páginasClimate WorkbookreaderdarkeyeAinda não há avaliações
- Open Channel Flow Resistance - Ben Chie Yen - 2002 PDFDocumento20 páginasOpen Channel Flow Resistance - Ben Chie Yen - 2002 PDFAndres Granados100% (2)
- P3 Mock PaperDocumento10 páginasP3 Mock PaperRahyan AshrafAinda não há avaliações
- (Semantic) - Word, Meaning and ConceptDocumento13 páginas(Semantic) - Word, Meaning and ConceptIan NugrahaAinda não há avaliações
- Taylor Introms11GE PPT 01Documento27 páginasTaylor Introms11GE PPT 01hddankerAinda não há avaliações
- Spe 163492 Pa PDFDocumento17 páginasSpe 163492 Pa PDFsanty222Ainda não há avaliações
- ABC AnalysisDocumento12 páginasABC AnalysisGujar DwarkadasAinda não há avaliações
- Linear Law HandoutDocumento13 páginasLinear Law HandoutHafiz NasirAinda não há avaliações
- DepressionnnDocumento5 páginasDepressionnnMilkie MangaoilAinda não há avaliações
- Integrals of Differential Binomials and Chebyshev's CriterionDocumento4 páginasIntegrals of Differential Binomials and Chebyshev's CriterionEnrique GonzalezAinda não há avaliações
- FMEA Minus The Pain FiguresDocumento3 páginasFMEA Minus The Pain FiguresMUNISAinda não há avaliações
- Upper and Lower Bounds Questions MMEDocumento8 páginasUpper and Lower Bounds Questions MMERUDRAKSHI PATELAinda não há avaliações
- U Exercise Work Male Height Weight Age Health: 5.2. Consider A Model For The Health of An IndividualDocumento21 páginasU Exercise Work Male Height Weight Age Health: 5.2. Consider A Model For The Health of An IndividualDella ShabrinaAinda não há avaliações
- Questions 16 and 17 Are Based On The FollowingDocumento2 páginasQuestions 16 and 17 Are Based On The FollowingkksAinda não há avaliações
- Adelia Salsabila-Assign-5 2Documento10 páginasAdelia Salsabila-Assign-5 2Adelia SalsabilaAinda não há avaliações
- quizlet-QUIZ 3 Variables in OutsystemsDocumento2 páginasquizlet-QUIZ 3 Variables in OutsystemsedymaradonaAinda não há avaliações
- Sr. No. A B C D Ans: Engineering Mechanics (2019 Pattern) Unit 2Documento14 páginasSr. No. A B C D Ans: Engineering Mechanics (2019 Pattern) Unit 2Ajit MoreAinda não há avaliações