Você também pode gostar
- Introductory Rotational Apparatus: Instruction Manual and Experiment Guide For The PASCO Scientific Model ME-9341Documento40 páginasIntroductory Rotational Apparatus: Instruction Manual and Experiment Guide For The PASCO Scientific Model ME-9341Aldana Ayelén MercadoAinda não há avaliações
- Crystal Plasticity PDFDocumento9 páginasCrystal Plasticity PDFAlexander BennettAinda não há avaliações
- Torsion LabDocumento10 páginasTorsion LabjeffreycychiuAinda não há avaliações
- Graduate Profile SEECS BICSEDocumento46 páginasGraduate Profile SEECS BICSEHajiasifAliAinda não há avaliações
- Bridge Fatigue Reliability Assessment Using Probability Density Functions of Equivalent Stress Range Based On Field Monitoring Data PDFDocumento12 páginasBridge Fatigue Reliability Assessment Using Probability Density Functions of Equivalent Stress Range Based On Field Monitoring Data PDFnagarajuAinda não há avaliações
- Study of Quality Management in Construction Industry: I J I R S E TDocumento8 páginasStudy of Quality Management in Construction Industry: I J I R S E Trizwan hassanAinda não há avaliações
- Axle Application Guidelines: Revised 12-18Documento99 páginasAxle Application Guidelines: Revised 12-18haviettuanAinda não há avaliações
- GCTS RTR Series CatalogueDocumento12 páginasGCTS RTR Series Cataloguevidyaranya_bAinda não há avaliações
- Author: MD Garred, 6/22/61 Approval: EC Przypsnzy Issued: GETS Drafting Bus. Area: Rle Dist: Sheet 1 of 1Documento47 páginasAuthor: MD Garred, 6/22/61 Approval: EC Przypsnzy Issued: GETS Drafting Bus. Area: Rle Dist: Sheet 1 of 1My Dad My WorldAinda não há avaliações
- Paper Spectral Leoben 2012 PDFDocumento11 páginasPaper Spectral Leoben 2012 PDFashish38799Ainda não há avaliações
- Lect 2 cvg4150 PDFDocumento9 páginasLect 2 cvg4150 PDFMewnEProwtAinda não há avaliações
- Calibration and Validation of Water Quality ModelDocumento10 páginasCalibration and Validation of Water Quality ModelGita LestariAinda não há avaliações
- Fea DoneDocumento17 páginasFea DoneLoc NguyenAinda não há avaliações
- Comparative Study and Static Analysis of Piston Using Solid Edge and AnsysDocumento23 páginasComparative Study and Static Analysis of Piston Using Solid Edge and AnsysIJRASETPublicationsAinda não há avaliações
- IRC 58-2011 - A DiscussionDocumento9 páginasIRC 58-2011 - A DiscussionSanjay GargAinda não há avaliações
- EE100B Lab 3 ReportDocumento5 páginasEE100B Lab 3 ReportTina Nguyen0% (2)
- CFD ROM for Aeroelastic AnalysisDocumento78 páginasCFD ROM for Aeroelastic AnalysisFabricio ValenteAinda não há avaliações
- Week 17 STI52 TNT Converting Pressures To Nodal Forces PDFDocumento4 páginasWeek 17 STI52 TNT Converting Pressures To Nodal Forces PDFMiguel F SalamancaAinda não há avaliações
- Mitchell Pad Bearing Experimental ReportDocumento12 páginasMitchell Pad Bearing Experimental ReportAaron PalmAinda não há avaliações
- 11-5699 Inprocess FAQ - FinalDocumento7 páginas11-5699 Inprocess FAQ - Finalsidiq16Ainda não há avaliações
- MSC NASTRAN AeroelasticityDocumento2 páginasMSC NASTRAN Aeroelasticitymat2230Ainda não há avaliações
- Berchtesgaden 2001 16 Eur Use Conf Paper - 61aDocumento14 páginasBerchtesgaden 2001 16 Eur Use Conf Paper - 61aengineeringmteAinda não há avaliações
- STAT3004 Assignment 1: Biomedical Statistics ProblemsDocumento3 páginasSTAT3004 Assignment 1: Biomedical Statistics Problems屁屁豬Ainda não há avaliações
- Internal Combustion Engines ME-215: Hapter NtroductionDocumento36 páginasInternal Combustion Engines ME-215: Hapter NtroductionHasnain KhokharAinda não há avaliações
- Modeling The Hysteretic Response of Mechanical Connections For Wood StructuresDocumento11 páginasModeling The Hysteretic Response of Mechanical Connections For Wood StructuresSheff_studentAinda não há avaliações
- User Manual For The PinchTrack Commander by JTech MedicalDocumento20 páginasUser Manual For The PinchTrack Commander by JTech MedicalphcproductsAinda não há avaliações
- Thesis On Sequential Quadratic Programming As A Method of OptimizationDocumento24 páginasThesis On Sequential Quadratic Programming As A Method of OptimizationNishant KumarAinda não há avaliações
- Niraj Kumar: Study of Sloshing Effects in A Cylindrical Tank With and Without Baffles Under Linear AccelerationDocumento31 páginasNiraj Kumar: Study of Sloshing Effects in A Cylindrical Tank With and Without Baffles Under Linear AccelerationSaurabh Suman100% (1)
- Model Predictive Control of Air Cond LoadsDocumento11 páginasModel Predictive Control of Air Cond LoadsSubhadeep PaladhiAinda não há avaliações
- CET 3135 Lab Report 2-Poisson's RatioDocumento13 páginasCET 3135 Lab Report 2-Poisson's RatioHaroon Rashidi100% (2)
- ECalc - XcopterCalc - The Most Reliable Multicopter Calculator On The WebDocumento3 páginasECalc - XcopterCalc - The Most Reliable Multicopter Calculator On The WebJeferson Mellado TraipeAinda não há avaliações
- 14 - Paving Blocks - J CairnsDocumento51 páginas14 - Paving Blocks - J CairnsEssy BasoenondoAinda não há avaliações
- 4613 ReportDocumento35 páginas4613 ReportRUNLIN MA100% (1)
- Distillation Column Design and SimulationDocumento29 páginasDistillation Column Design and Simulationhinman714Ainda não há avaliações
- Development of An Onboard Decision Support System For Ship Navigation Under Rough Weather ConditionsDocumento8 páginasDevelopment of An Onboard Decision Support System For Ship Navigation Under Rough Weather ConditionsLP PereraAinda não há avaliações
- Centrifugal Pumps - Basic Concepts of Operation, Maintenance, and Troubleshooting - CheengineeringDocumento40 páginasCentrifugal Pumps - Basic Concepts of Operation, Maintenance, and Troubleshooting - CheengineeringSayed KassarAinda não há avaliações
- X 60Documento2 páginasX 60Francisco Correia Dos SantosAinda não há avaliações
- ZSimpWin EIS Software Technical Note on Kramers-Kronig ExtrapolationDocumento13 páginasZSimpWin EIS Software Technical Note on Kramers-Kronig ExtrapolationChaitanya RaiAinda não há avaliações
- 1986 A New Synchronous Current Regulator and An Analysis of Current-Regulated PWM Inverters PDFDocumento13 páginas1986 A New Synchronous Current Regulator and An Analysis of Current-Regulated PWM Inverters PDFdhirajlovesmaaAinda não há avaliações
- SURVIVAL ANALYSIS EXAMPLESDocumento7 páginasSURVIVAL ANALYSIS EXAMPLESSarbarup BanerjeeAinda não há avaliações
- Grade Mixing Analysis in Steelmaking Tundishusing Different Turbulence ModelsDocumento6 páginasGrade Mixing Analysis in Steelmaking Tundishusing Different Turbulence ModelsrakukulappullyAinda não há avaliações
- Embedded Model Predictive Control For An ESP On A PLCDocumento7 páginasEmbedded Model Predictive Control For An ESP On A PLCRhaclley AraújoAinda não há avaliações
- Help MSADocumento34 páginasHelp MSAGiomar OzaitaAinda não há avaliações
- Comparison of Different FE Calculation Methods For The Electromagnetic Torque of PM MachinesDocumento8 páginasComparison of Different FE Calculation Methods For The Electromagnetic Torque of PM Machinesmlkz_01Ainda não há avaliações
- AADE 03 NTCE 35 PowerDocumento9 páginasAADE 03 NTCE 35 PowerAmalina SulaimanAinda não há avaliações
- @high Frequency Properties of Electro-Textiles For Wearable Antenna ApplicationsDocumento9 páginas@high Frequency Properties of Electro-Textiles For Wearable Antenna ApplicationsMomtaz Islam SobujAinda não há avaliações
- ANSYS AIM DocumentationDocumento306 páginasANSYS AIM DocumentationWilder Molina100% (2)
- Final Report Iec-10Documento10 páginasFinal Report Iec-10protikbiswas2088Ainda não há avaliações
- Biotechnology Syllabus For 2003 Scheme Kerala UniversityDocumento32 páginasBiotechnology Syllabus For 2003 Scheme Kerala Universitymdaditya0% (1)
- The Lax-Wendroff Technique for Solving Hyperbolic PDEsDocumento13 páginasThe Lax-Wendroff Technique for Solving Hyperbolic PDEsSnehit Sanagar100% (1)
- MSA PresentationDocumento37 páginasMSA PresentationStacy MontoyaAinda não há avaliações
- Logger UCAM-70A PDFDocumento3 páginasLogger UCAM-70A PDFjbmune6683Ainda não há avaliações
- Experimental determination of shear modulus (G) of brass rod using torsion testing machineDocumento7 páginasExperimental determination of shear modulus (G) of brass rod using torsion testing machineAbood Al-atiyatAinda não há avaliações
- Shaking Table Interface Design for Substructure TestingDocumento15 páginasShaking Table Interface Design for Substructure TestingTrung Vien PhanAinda não há avaliações
- Simulation of Brushless DC Motor Speed Control in Matlab-Ijaerdv04i1290151Documento7 páginasSimulation of Brushless DC Motor Speed Control in Matlab-Ijaerdv04i1290151Wairokpam DhanrajAinda não há avaliações
- COntentDocumento43 páginasCOntentprabu sekarAinda não há avaliações
- Crop Selection Method To Maximize Crop Yield Rate Using Machine Learning TechniqueDocumento8 páginasCrop Selection Method To Maximize Crop Yield Rate Using Machine Learning TechniqueArshanday UkundamayAinda não há avaliações
- Updated Research Paper_295Documento19 páginasUpdated Research Paper_295Pratik NagareAinda não há avaliações
- Design Paper GID 38Documento13 páginasDesign Paper GID 38msingh231974Ainda não há avaliações
- Use Cases of AI and ML in Agriculture: Smart Project IdeasNo EverandUse Cases of AI and ML in Agriculture: Smart Project IdeasAinda não há avaliações
- Togaf Question Bank 3Documento2 páginasTogaf Question Bank 3Ashraf Sayed AbdouAinda não há avaliações
- Sample Exam Istqb Foundation Level 2011 Syllabus: International Software Testing Qualifications BoardDocumento27 páginasSample Exam Istqb Foundation Level 2011 Syllabus: International Software Testing Qualifications BoardAshraf Sayed AbdouAinda não há avaliações
- Togaf Question Bank 6Documento7 páginasTogaf Question Bank 6Ashraf Sayed Abdou100% (1)
- Database Systems: Homework 1 Key SolutionsDocumento7 páginasDatabase Systems: Homework 1 Key SolutionsAshraf Sayed AbdouAinda não há avaliações
- Inf1343 2011W Assignment 1Documento4 páginasInf1343 2011W Assignment 1Ashraf Sayed AbdouAinda não há avaliações
- Sample Exam A Istqb Foundation Level 2018 Syllabus: Released Version 2018Documento20 páginasSample Exam A Istqb Foundation Level 2018 Syllabus: Released Version 2018Ashraf Sayed AbdouAinda não há avaliações
- SQL 1-3 PDFDocumento58 páginasSQL 1-3 PDFAshraf Sayed AbdouAinda não há avaliações
- Name For Correspondence From PMI: Mr. Mohammed HamedDocumento5 páginasName For Correspondence From PMI: Mr. Mohammed HamedAshraf Sayed AbdouAinda não há avaliações
- IJCSIS Copyright Transfer FormDocumento2 páginasIJCSIS Copyright Transfer FormAshraf Sayed AbdouAinda não há avaliações
- Defect Prediction: Using Machine Learning: Kirti Hegde, Consultant Trupti Songadwala, Senior Consultant DeloitteDocumento13 páginasDefect Prediction: Using Machine Learning: Kirti Hegde, Consultant Trupti Songadwala, Senior Consultant DeloitteAshraf Sayed AbdouAinda não há avaliações
- Inf1343 2011W Assignment 1Documento4 páginasInf1343 2011W Assignment 1Ashraf Sayed AbdouAinda não há avaliações
- Ahmed TaherDocumento5 páginasAhmed TaherAshraf Sayed AbdouAinda não há avaliações
- Deda Thi Thu THPTQGDocumento8 páginasDeda Thi Thu THPTQGAshraf Sayed AbdouAinda não há avaliações
- IJCA Paper-F Ver 28-4-2018Documento12 páginasIJCA Paper-F Ver 28-4-2018Ashraf Sayed AbdouAinda não há avaliações
- Levels of Software Testing ExplainedDocumento17 páginasLevels of Software Testing ExplainedAshraf Sayed AbdouAinda não há avaliações
- 04 PGDipGISDocumento6 páginas04 PGDipGISAshraf Sayed AbdouAinda não há avaliações
- QA technical interview questionsDocumento2 páginasQA technical interview questionsAshraf Sayed AbdouAinda não há avaliações
- QA technical interview questionsDocumento2 páginasQA technical interview questionsAshraf Sayed AbdouAinda não há avaliações
- Wang WCNC DeepFiDocumento6 páginasWang WCNC DeepFiAshraf Sayed AbdouAinda não há avaliações
- BiLoc ChapterDocumento27 páginasBiLoc ChapterAshraf Sayed AbdouAinda não há avaliações
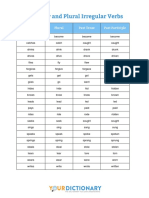
- 152 Irregularverblist-Singularplural PDFDocumento1 página152 Irregularverblist-Singularplural PDFAshraf Sayed AbdouAinda não há avaliações
- Tips For Writing Effective Test Cases For Any ApplicationDocumento9 páginasTips For Writing Effective Test Cases For Any ApplicationsysastroAinda não há avaliações
- (International) Indoor Fingerprint Positioning Based On Wi-Fi PDFDocumento25 páginas(International) Indoor Fingerprint Positioning Based On Wi-Fi PDFWilzHuangAinda não há avaliações
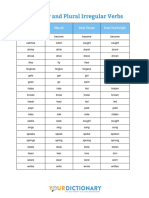
- 152.irregularverblist-Singularplural 2 PDFDocumento1 página152.irregularverblist-Singularplural 2 PDFAshraf Sayed AbdouAinda não há avaliações
- Petroleum ProductsDocumento5 páginasPetroleum ProductsAshraf Sayed AbdouAinda não há avaliações
- American Literature 1Documento5 páginasAmerican Literature 1api-310256368Ainda não há avaliações
- Eeg 1,2,3,4,5,6,7,8Documento75 páginasEeg 1,2,3,4,5,6,7,8P I X Ξ LAinda não há avaliações
- ISTQB1Documento3 páginasISTQB1Ashraf Sayed AbdouAinda não há avaliações
- InderscienceDocumento3 páginasIndersciencePrabir SahaAinda não há avaliações
- Complete Test 1Documento17 páginasComplete Test 1Ashraf Sayed Abdou100% (1)
- 02 Stuck Pipe - Free Point & Back Off PDFDocumento31 páginas02 Stuck Pipe - Free Point & Back Off PDFام فاطمة البطاط100% (2)
- 5100 Series Gas Analyzer: Product Data SheetDocumento2 páginas5100 Series Gas Analyzer: Product Data SheetSai KamalaAinda não há avaliações
- Latka March2020 DigitalDocumento68 páginasLatka March2020 DigitalDan100% (2)
- Detailed Scheduling Planning Board Technical HelpDocumento6 páginasDetailed Scheduling Planning Board Technical Helpmanojnarain100% (1)
- Daniel Kipkirong Tarus C.VDocumento19 páginasDaniel Kipkirong Tarus C.VPeter Osundwa KitekiAinda não há avaliações
- Digital Bending Machine User Manual - BD SeriesDocumento7 páginasDigital Bending Machine User Manual - BD SeriesTatiane Silva BarbosaAinda não há avaliações
- Vspa 50Documento5 páginasVspa 50elfo111Ainda não há avaliações
- Nb7040 - Rules For Pipe Connections and Spools: Acc. Building Specification. Rev. 2, November 2016Documento4 páginasNb7040 - Rules For Pipe Connections and Spools: Acc. Building Specification. Rev. 2, November 201624142414Ainda não há avaliações
- Future Time ClausesDocumento7 páginasFuture Time ClausesAmanda RidhaAinda não há avaliações
- Floor Heating Controls Wiring Instructions for FS and BA Master Weather CompensationDocumento12 páginasFloor Heating Controls Wiring Instructions for FS and BA Master Weather Compensationjamppajoo2Ainda não há avaliações
- Latex WikibookDocumento313 páginasLatex Wikibookraul_apAinda não há avaliações
- C 6 Slings SafetyDocumento29 páginasC 6 Slings SafetyAshraf BeramAinda não há avaliações
- Iso 9712 2012 PDFDocumento19 páginasIso 9712 2012 PDFBala KrishnanAinda não há avaliações
- Western Preços - SPDocumento28 páginasWestern Preços - SPRobertaoJasperAinda não há avaliações
- Speech Language Impairment - Eduu 511Documento15 páginasSpeech Language Impairment - Eduu 511api-549169454Ainda não há avaliações
- Quenching & TemperingDocumento4 páginasQuenching & Temperingkgkganesh8116Ainda não há avaliações
- Disaster Readiness Exam SpecificationsDocumento2 páginasDisaster Readiness Exam SpecificationsRICHARD CORTEZAinda não há avaliações
- Johnson RPM Chart Evinrude E-Tec RPM Chart Mercury 4-Stroke RPM ChartDocumento2 páginasJohnson RPM Chart Evinrude E-Tec RPM Chart Mercury 4-Stroke RPM ChartUlf NymanAinda não há avaliações
- TCXD 46-1984 / Lightning Protection For Buildings - Standard For Design and ConstructionDocumento30 páginasTCXD 46-1984 / Lightning Protection For Buildings - Standard For Design and ConstructiontrungjindoAinda não há avaliações
- Waffle Slab - WikipediaDocumento15 páginasWaffle Slab - WikipediaBryan PongaoAinda não há avaliações
- BW1114-B2 Bendix Brake CatalogDocumento116 páginasBW1114-B2 Bendix Brake Cataloggearhead1100% (1)
- A Thesis 123Documento77 páginasA Thesis 123Meli SafiraAinda não há avaliações
- OHS Policies and Guidelines (TESDA CSS NC2 COC1)Documento1 páginaOHS Policies and Guidelines (TESDA CSS NC2 COC1)Anonymous fvY2BzPQVx100% (2)
- Name: Keatlaretse Bridgette Surname: Macucwa Module Name: Social Work Practice Module Code: BSW 2605 Assessment No: 2 Due Date: 14 August 2020Documento6 páginasName: Keatlaretse Bridgette Surname: Macucwa Module Name: Social Work Practice Module Code: BSW 2605 Assessment No: 2 Due Date: 14 August 2020keatlaretse macucwaAinda não há avaliações
- Mouse Molecular Genetics Student Activity 2Documento7 páginasMouse Molecular Genetics Student Activity 2Jonathan ZhouAinda não há avaliações
- TMJC - H2 - 2021 - Prelim P2Documento9 páginasTMJC - H2 - 2021 - Prelim P2猪猪侠Ainda não há avaliações
- LGBT Workplace Equality Policy and Customer Satisfaction: The Roles of Marketing Capability and Demand InstabilityDocumento20 páginasLGBT Workplace Equality Policy and Customer Satisfaction: The Roles of Marketing Capability and Demand InstabilityFatima ZafarAinda não há avaliações
- Tugas (UTS) ASPK - Andro Tri Julianda (95017019)Documento4 páginasTugas (UTS) ASPK - Andro Tri Julianda (95017019)محمد عزيرAinda não há avaliações
- 2016 Book IrrigationAndDrainageEngineeriDocumento747 páginas2016 Book IrrigationAndDrainageEngineeriJesús Garre Ruiz100% (2)
- Maintenance Manual - Booms: S Booms Z BoomsDocumento185 páginasMaintenance Manual - Booms: S Booms Z BoomsRafael Vieira De AssisAinda não há avaliações