Você também pode gostar
- Statistical Inference for Models with Multivariate t-Distributed ErrorsNo EverandStatistical Inference for Models with Multivariate t-Distributed ErrorsAinda não há avaliações
- Anscombes Quartet eDocumento3 páginasAnscombes Quartet eSweta Jain SewakAinda não há avaliações
- Storytelling and Data in Numerical Simulations: Visual VisualizationDocumento68 páginasStorytelling and Data in Numerical Simulations: Visual VisualizationmopliqAinda não há avaliações
- Why Data Visualizations Are Not Optional: Anscombe's QuartetDocumento2 páginasWhy Data Visualizations Are Not Optional: Anscombe's QuartetabianakiAinda não há avaliações
- Anscombe's QuartetDocumento4 páginasAnscombe's Quartetharrison9Ainda não há avaliações
- Data Warehousing, Mining, Neural NetworkDocumento26 páginasData Warehousing, Mining, Neural NetworkRema VanchhawngAinda não há avaliações
- Anscombe's Data WorkbookDocumento5 páginasAnscombe's Data WorkbookSamerAinda não há avaliações
- LAB 06 One Way AnovaDocumento9 páginasLAB 06 One Way AnovaShafi UllahAinda não há avaliações
- Bio2 Module 2 - Non-Parametric MethodsDocumento14 páginasBio2 Module 2 - Non-Parametric Methodstamirat hailuAinda não há avaliações
- Role of Operations ResearchDocumento34 páginasRole of Operations ResearchKevin NdemoAinda não há avaliações
- eXPLORATORY aNALYSIS2Documento11 páginaseXPLORATORY aNALYSIS2MuzamilAinda não há avaliações
- Histogram Steps V V ImpDocumento15 páginasHistogram Steps V V ImpAnirban BhowalAinda não há avaliações
- Advance Statistics JamesDocumento15 páginasAdvance Statistics JamesJames Geronimo LopezAinda não há avaliações
- Lec448B 20160406Documento30 páginasLec448B 20160406NGuyen thi Kim TuyenAinda não há avaliações
- ST 3901Documento3 páginasST 3901Jalak PatelAinda não há avaliações
- 8-Multivariate Analysis Using SASDocumento26 páginas8-Multivariate Analysis Using SASSvend Erik FjordAinda não há avaliações
- Final Assignmnt Stat KamiiDocumento6 páginasFinal Assignmnt Stat Kamiikamranwaris405Ainda não há avaliações
- Investigating Centripetal ForceDocumento5 páginasInvestigating Centripetal ForceKevin KimAinda não há avaliações
- Topic 2.1 Species and Populations - The Mathematics of Populations - Describing PopulationsDocumento8 páginasTopic 2.1 Species and Populations - The Mathematics of Populations - Describing PopulationsAnika HinkovaAinda não há avaliações
- Bs SampleDocumento2 páginasBs SamplejanedohAinda não há avaliações
- Statistics Module 11Documento9 páginasStatistics Module 11Gaile YabutAinda não há avaliações
- Subgroup Sample 1 Sample 2 Sample 3 Sample 4 Sample 5 Mean RangeDocumento13 páginasSubgroup Sample 1 Sample 2 Sample 3 Sample 4 Sample 5 Mean RangeGuttula ChaitanyaAinda não há avaliações
- Reflective Learning Journal: St. Paul University ManilaDocumento11 páginasReflective Learning Journal: St. Paul University Manilaapi-351776914Ainda não há avaliações
- Quality Engineering 06/02/2019 General Recommendations:: Index1 Index2 Index3 Index4Documento15 páginasQuality Engineering 06/02/2019 General Recommendations:: Index1 Index2 Index3 Index4Giuseppe D'AngeloAinda não há avaliações
- Statistics Questions Practice w2 FinalDocumento23 páginasStatistics Questions Practice w2 FinalRaniaKaliAinda não há avaliações
- Estimating Probabilities by SimulationDocumento1 páginaEstimating Probabilities by SimulationMud YúAinda não há avaliações
- Journal of Statistical Software: Nonparametric Inference For Multivariate Data: The R Package NPMVDocumento18 páginasJournal of Statistical Software: Nonparametric Inference For Multivariate Data: The R Package NPMVÚt NhỏAinda não há avaliações
- MMW Module 9 (Dona Vie) PDFDocumento4 páginasMMW Module 9 (Dona Vie) PDFRey RoseteAinda não há avaliações
- NCERT Solutions For Class 11 Maths Chapter - 15 StatisticsDocumento6 páginasNCERT Solutions For Class 11 Maths Chapter - 15 StatisticsMukund YadavAinda não há avaliações
- 1 2Documento31 páginas1 2Rolando Martìnez AguilarAinda não há avaliações
- Business Statistics & Analytics KMBN104 UNIT-1Documento13 páginasBusiness Statistics & Analytics KMBN104 UNIT-1Arkhitekton DesignAinda não há avaliações
- DEA IntroductionDocumento15 páginasDEA IntroductionFrancisco AraújoAinda não há avaliações
- Raiz Cuadrada de La VarianzaDocumento12 páginasRaiz Cuadrada de La VarianzaDanielIgnacioLuengoCordovaAinda não há avaliações
- QCtool - Charts TrainingDocumento65 páginasQCtool - Charts TrainingRaajha MunibathiranAinda não há avaliações
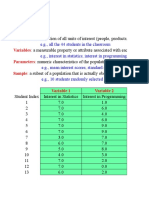
- Population: Variables: Parameters: SampleDocumento15 páginasPopulation: Variables: Parameters: SampleAbdu AbdoulayeAinda não há avaliações
- IE-431, Assignment-6, TEAM-10Documento26 páginasIE-431, Assignment-6, TEAM-10Mohammad KashifAinda não há avaliações
- Chapter 9 Multiple Regression AnalysisDocumento15 páginasChapter 9 Multiple Regression AnalysisShahir ImanAinda não há avaliações
- Role of Statistics in PhysicsDocumento9 páginasRole of Statistics in PhysicsAlif100% (1)
- Ohms Law and Resistance Virtual Lab PHET Lesson 9 and 10Documento5 páginasOhms Law and Resistance Virtual Lab PHET Lesson 9 and 10Ghala AlHarmoodiAinda não há avaliações
- Manova IrisDocumento12 páginasManova IrisNadiaAinda não há avaliações
- EM 521 Study Set 1 SolutionsDocumento10 páginasEM 521 Study Set 1 SolutionseragornAinda não há avaliações
- Unit 1 - Activity 15 - Graphical Representation of Data TestDocumento6 páginasUnit 1 - Activity 15 - Graphical Representation of Data TestNidhi VyasAinda não há avaliações
- AP Bio Math and StatisticsDocumento8 páginasAP Bio Math and StatisticsJuan Carlos Mejia MaciasAinda não há avaliações
- Control ChartsDocumento11 páginasControl ChartsHasler Machaca ParedesAinda não há avaliações
- Stacey Dittmer Project 2 FinalDocumento16 páginasStacey Dittmer Project 2 Finalapi-583715062Ainda não há avaliações
- FinalDocumento14 páginasFinalapi-443631703Ainda não há avaliações
- Duty 16Documento6 páginasDuty 16ScribdTranslationsAinda não há avaliações
- Chi Square Test Excel TemplateDocumento18 páginasChi Square Test Excel TemplatefortunapartnershipAinda não há avaliações
- Che485 - Lab 6 - Mac2023 - Ceeh220f - Group 5Documento26 páginasChe485 - Lab 6 - Mac2023 - Ceeh220f - Group 5Wan AfiqAinda não há avaliações
- Raiza Nery Project 2Documento17 páginasRaiza Nery Project 2api-585198860Ainda não há avaliações
- Asm 1Documento4 páginasAsm 1Hằng TốngAinda não há avaliações
- Electric Fields ExperimentDocumento5 páginasElectric Fields ExperimentEmily Gatlin100% (3)
- Assignment 4Documento14 páginasAssignment 4Mcleo MoonAinda não há avaliações
- Task 1Documento9 páginasTask 1Dương Vũ MinhAinda não há avaliações
- (Velda Rifka Almira) Statistical AnalysisDocumento13 páginas(Velda Rifka Almira) Statistical Analysis22098713Ainda não há avaliações
- Month Data 0 1-33 34-66 67-100Documento34 páginasMonth Data 0 1-33 34-66 67-100sagarAinda não há avaliações
- Pract08 Chi SquareDocumento9 páginasPract08 Chi SquareRinzualaAinda não há avaliações
- Aimee Lamont Project 2Documento16 páginasAimee Lamont Project 2api-507550747Ainda não há avaliações
- Ohms Law and Resistance Virtual Lab PHET (Lab 3)Documento9 páginasOhms Law and Resistance Virtual Lab PHET (Lab 3)Diana Grace Quiñones0% (1)
- Meta-Mar Free Online Meta-Analysis Service!Documento8 páginasMeta-Mar Free Online Meta-Analysis Service!Onny KhaeroniAinda não há avaliações
- Estad Istica II Chapter 4: Simple Linear RegressionDocumento46 páginasEstad Istica II Chapter 4: Simple Linear RegressionJuanAinda não há avaliações
- Statistical Inference Point Estimators Estimating The Population Mean Using Confidence IntervalsDocumento40 páginasStatistical Inference Point Estimators Estimating The Population Mean Using Confidence IntervalsJuanAinda não há avaliações
- Unit 3Documento28 páginasUnit 3JuanAinda não há avaliações
- Unit 2Documento36 páginasUnit 2JuanAinda não há avaliações
- Does Adding Salt To Water Makes It Boil FasterDocumento1 páginaDoes Adding Salt To Water Makes It Boil Fasterfelixcouture2007Ainda não há avaliações
- Transportation of CementDocumento13 páginasTransportation of CementKaustubh Joshi100% (1)
- Scrum Exam SampleDocumento8 páginasScrum Exam SampleUdhayaAinda não há avaliações
- FS-1040 FS-1060DN: Parts ListDocumento23 páginasFS-1040 FS-1060DN: Parts List1980cvvrAinda não há avaliações
- SDS ERSA Rev 0Documento156 páginasSDS ERSA Rev 0EdgarVelosoCastroAinda não há avaliações
- Test On Real NumberaDocumento1 páginaTest On Real Numberaer.manalirathiAinda não há avaliações
- Project Name: Repair of Afam Vi Boiler (HRSG) Evaporator TubesDocumento12 páginasProject Name: Repair of Afam Vi Boiler (HRSG) Evaporator TubesLeann WeaverAinda não há avaliações
- ISO Position ToleranceDocumento15 páginasISO Position ToleranceНиколай КалугинAinda não há avaliações
- Installation Instructions INI Luma Gen2Documento21 páginasInstallation Instructions INI Luma Gen2John Kim CarandangAinda não há avaliações
- SievesDocumento3 páginasSievesVann AnthonyAinda não há avaliações
- Dec 2-7 Week 4 Physics DLLDocumento3 páginasDec 2-7 Week 4 Physics DLLRicardo Acosta Subad100% (1)
- 1188 2665 1 SMDocumento12 páginas1188 2665 1 SMRita BangunAinda não há avaliações
- Radio Ac DecayDocumento34 páginasRadio Ac DecayQassem MohaidatAinda não há avaliações
- Hitachi Vehicle CardDocumento44 páginasHitachi Vehicle CardKieran RyanAinda não há avaliações
- Keeping Track of Your Time: Keep Track Challenge Welcome GuideDocumento1 páginaKeeping Track of Your Time: Keep Track Challenge Welcome GuideRizky NurdiansyahAinda não há avaliações
- Six Sigma PresentationDocumento17 páginasSix Sigma PresentationDhular HassanAinda não há avaliações
- 5.0008786 Aluminum GrapheneDocumento11 páginas5.0008786 Aluminum GrapheneBensinghdhasAinda não há avaliações
- L GSR ChartsDocumento16 páginasL GSR ChartsEmerald GrAinda não há avaliações
- E7d61 139.new Directions in Race Ethnicity and CrimeDocumento208 páginasE7d61 139.new Directions in Race Ethnicity and CrimeFlia Rincon Garcia SoyGabyAinda não há avaliações
- 147 Amity Avenue Nampa, ID 81937 (999) 999-9999 William at Email - ComDocumento4 páginas147 Amity Avenue Nampa, ID 81937 (999) 999-9999 William at Email - ComjeyesbelmenAinda não há avaliações
- Service Quality Dimensions of A Philippine State UDocumento10 páginasService Quality Dimensions of A Philippine State UVilma SottoAinda não há avaliações
- G.Devendiran: Career ObjectiveDocumento2 páginasG.Devendiran: Career ObjectiveSadha SivamAinda não há avaliações
- Analisis Kebutuhan Bahan Ajar Berbasis EDocumento9 páginasAnalisis Kebutuhan Bahan Ajar Berbasis ENur Hanisah AiniAinda não há avaliações
- MATM1534 Main Exam 2022 PDFDocumento7 páginasMATM1534 Main Exam 2022 PDFGiftAinda não há avaliações
- Executive Summary: 2013 Edelman Trust BarometerDocumento12 páginasExecutive Summary: 2013 Edelman Trust BarometerEdelman100% (4)
- Manhole Head LossesDocumento11 páginasManhole Head Lossesjoseph_mscAinda não há avaliações
- PTW Site Instruction NewDocumento17 páginasPTW Site Instruction NewAnonymous JtYvKt5XEAinda não há avaliações
- Philo Q2 Lesson 5Documento4 páginasPhilo Q2 Lesson 5Julliana Patrice Angeles STEM 11 RUBYAinda não há avaliações
- Saflex-Dg - 41 Data SheetDocumento5 páginasSaflex-Dg - 41 Data SheetrasheedgotzAinda não há avaliações
- Topic One ProcurementDocumento35 páginasTopic One ProcurementSaid Sabri KibwanaAinda não há avaliações