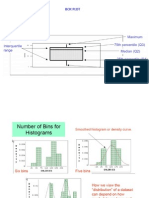
Você também pode gostar
- Interval Estimation: ASW, Chapter 8Documento23 páginasInterval Estimation: ASW, Chapter 8justinepaz1984Ainda não há avaliações
- Stat Handout 2Documento11 páginasStat Handout 2cmacblue42Ainda não há avaliações
- Properties of A Normal DistributionDocumento8 páginasProperties of A Normal DistributionCarmelle BahadeAinda não há avaliações
- Normal Distribution HomeworkDocumento7 páginasNormal Distribution HomeworkInam Ullah JoharAinda não há avaliações
- Chapter 6Documento11 páginasChapter 6Raymond KilangiAinda não há avaliações
- Tests of SignificanceDocumento40 páginasTests of SignificanceRahul Goel100% (1)
- Business Statistics Estimates and Confidence IntervalsDocumento63 páginasBusiness Statistics Estimates and Confidence Intervalspkj009Ainda não há avaliações
- Fstats ch2 PDFDocumento0 páginaFstats ch2 PDFsound05Ainda não há avaliações
- Confidence Intervals and Hypothesis Tests For MeansDocumento40 páginasConfidence Intervals and Hypothesis Tests For MeansJosh PotashAinda não há avaliações
- Estimating Confidence Intervals and Sample SizesDocumento40 páginasEstimating Confidence Intervals and Sample SizesDonald YumAinda não há avaliações
- Confidence IntervalsDocumento2 páginasConfidence IntervalsEugene BorysenkoAinda não há avaliações
- PROSTAT Lecture10 HandoutsDocumento3 páginasPROSTAT Lecture10 HandoutsJubillee MagsinoAinda não há avaliações
- Population sampling techniques & statistical inferenceDocumento45 páginasPopulation sampling techniques & statistical inferenceDan RadaAinda não há avaliações
- IntervalsDocumento43 páginasIntervalsHarySetiyawanAinda não há avaliações
- 9 16042019Documento45 páginas9 16042019محمد خيري بن اسماءيلAinda não há avaliações
- Group 7Documento44 páginasGroup 7Twe3k KunAinda não há avaliações
- Lecture 8 Statitical InferenceDocumento54 páginasLecture 8 Statitical InferenceSomia ZohaibAinda não há avaliações
- Continuous ProbabilitiesDocumento9 páginasContinuous ProbabilitiesCharles QuahAinda não há avaliações
- Case StudyDocumento9 páginasCase StudyAyoade Tobi DanielAinda não há avaliações
- Examples Biostatistics. FinalDocumento90 páginasExamples Biostatistics. FinalabdihakemAinda não há avaliações
- Sampling Distribution of The Sample Mean UsingDocumento4 páginasSampling Distribution of The Sample Mean UsingHanna GalatiAinda não há avaliações
- Biostatistics For Academic3Documento28 páginasBiostatistics For Academic3Semo gh28Ainda não há avaliações
- Lecture6 Normal Probability Distribution PDFDocumento6 páginasLecture6 Normal Probability Distribution PDFnauliAinda não há avaliações
- IB Studies - The Normal DistributionDocumento11 páginasIB Studies - The Normal DistributionfreddieAinda não há avaliações
- Notes On Medical StatisticsDocumento10 páginasNotes On Medical StatisticsCalvin Yeow-kuan ChongAinda não há avaliações
- Chapter8 NewDocumento30 páginasChapter8 NewNick GoldingAinda não há avaliações
- UDEC1203 - Topic 6 Analysis of Experimental DataDocumento69 páginasUDEC1203 - Topic 6 Analysis of Experimental DataA/P SUPAYA SHALINIAinda não há avaliações
- Continuous Probability Distribution PDFDocumento47 páginasContinuous Probability Distribution PDFDipika PandaAinda não há avaliações
- Stat ch2Documento12 páginasStat ch2Solomon MeleseAinda não há avaliações
- Confidence Interval Estimation for Unknown Population MeanDocumento20 páginasConfidence Interval Estimation for Unknown Population MeanSyed M MusslimAinda não há avaliações
- Chapter 8 - Sampling DistributionDocumento34 páginasChapter 8 - Sampling DistributionMir Md. Mofachel HossainAinda não há avaliações
- Sampling and Sampling DistributionDocumento28 páginasSampling and Sampling DistributionBuetAinda não há avaliações
- TUGAS2 - Ratu Aam Amaliyah - BIDocumento7 páginasTUGAS2 - Ratu Aam Amaliyah - BIamongRTAinda não há avaliações
- SamplingDistributions LectureDocumento13 páginasSamplingDistributions LectureJeanpierre AklAinda não há avaliações
- Continuous Probability DistributionDocumento22 páginasContinuous Probability DistributionMusa AmanAinda não há avaliações
- Ch08 3Documento59 páginasCh08 3sukhmandhawan88Ainda não há avaliações
- IISER BiostatDocumento87 páginasIISER BiostatPrithibi Bodle GacheAinda não há avaliações
- Answers To Practice Exam 2Documento3 páginasAnswers To Practice Exam 2monerch JoserAinda não há avaliações
- Bus 173 - 1Documento28 páginasBus 173 - 1Mirza Asir IntesarAinda não há avaliações
- BSCHAPTER - (Theory of Estimations)Documento39 páginasBSCHAPTER - (Theory of Estimations)kunal kabraAinda não há avaliações
- Standard Deviation - Wikipedia, The Free EncyclopediaDocumento12 páginasStandard Deviation - Wikipedia, The Free EncyclopediaManoj BorahAinda não há avaliações
- A Confidence Interval Provides Additional Information About VariabilityDocumento14 páginasA Confidence Interval Provides Additional Information About VariabilityShrey BudhirajaAinda não há avaliações
- Lecture Notes 7.2 Estimating A Population MeanDocumento5 páginasLecture Notes 7.2 Estimating A Population MeanWilliam DaughertyAinda não há avaliações
- Confidence Interval EstimationDocumento62 páginasConfidence Interval EstimationVikrant LadAinda não há avaliações
- Statistical Tests and Confidence Intervals in Data AnalysisDocumento77 páginasStatistical Tests and Confidence Intervals in Data AnalysisAndrina Ortillano100% (2)
- Confidence Interval - Notes - UpdateDocumento4 páginasConfidence Interval - Notes - UpdateGodfred AbleduAinda não há avaliações
- 3 Confidence IntervalsDocumento16 páginas3 Confidence IntervalsAkash SrivastavaAinda não há avaliações
- How To Find Confidence IntervalDocumento5 páginasHow To Find Confidence Intervalapi-126876773Ainda não há avaliações
- LectureNote - Interval EstimationDocumento27 páginasLectureNote - Interval Estimationminhhunghb789Ainda não há avaliações
- Normal Distribution Nov 2021 - FinalDocumento36 páginasNormal Distribution Nov 2021 - FinalmussaAinda não há avaliações
- Basic StatisticsDocumento106 páginasBasic StatisticsSudhanshu Kumar Satyanveshi100% (1)
- Coefficient of Variation and Areas Under Normal CurveDocumento5 páginasCoefficient of Variation and Areas Under Normal CurvemochiAinda não há avaliações
- CN 6Documento44 páginasCN 6Metal deptAinda não há avaliações
- Unit 3 Z-Scores, Measuring Performance: Learning OutcomeDocumento10 páginasUnit 3 Z-Scores, Measuring Performance: Learning OutcomeCheska AtienzaAinda não há avaliações
- ch10 ConfidenceIntervals - Z DistDocumento4 páginasch10 ConfidenceIntervals - Z DistdavidAinda não há avaliações
- Chapter 7Documento15 páginasChapter 7Khay OngAinda não há avaliações
- Interpreting Standard DeviationsDocumento8 páginasInterpreting Standard DeviationsCatherine PingAinda não há avaliações
- C - Normal DistributionDocumento196 páginasC - Normal DistributionRi chalAinda não há avaliações
- Solutions Manual to accompany Introduction to Linear Regression AnalysisNo EverandSolutions Manual to accompany Introduction to Linear Regression AnalysisNota: 1 de 5 estrelas1/5 (1)
- New Product Development Process and Innovative Project ManagementDocumento2 páginasNew Product Development Process and Innovative Project ManagementAslan AlpAinda não há avaliações
- Flat Stawki 4BDocumento2 páginasFlat Stawki 4BAslan AlpAinda não há avaliações
- NDMA GuidelinesDocumento42 páginasNDMA GuidelinesAslan AlpAinda não há avaliações
- E CommerceDocumento2 páginasE CommerceAslan AlpAinda não há avaliações
- LeadershipDocumento2 páginasLeadershipAslan AlpAinda não há avaliações
- Mergers & Acquisitions - FinanceDocumento2 páginasMergers & Acquisitions - FinanceAslan AlpAinda não há avaliações
- Mergers & AcquisitionsDocumento2 páginasMergers & AcquisitionsAslan AlpAinda não há avaliações
- Advanced Corporate FinanceDocumento2 páginasAdvanced Corporate FinanceAslan AlpAinda não há avaliações
- Tel Aviv Pricing Policy 2017Documento8 páginasTel Aviv Pricing Policy 2017Aslan AlpAinda não há avaliações
- International Business LawDocumento2 páginasInternational Business LawAslan AlpAinda não há avaliações
- International MarketingDocumento2 páginasInternational MarketingAslan AlpAinda não há avaliações
- Big Data AnalysisDocumento2 páginasBig Data AnalysisAslan AlpAinda não há avaliações
- Psychology of Financial MarketsDocumento1 páginaPsychology of Financial MarketsAslan AlpAinda não há avaliações
- Taxes and Corporate StrategyDocumento1 páginaTaxes and Corporate StrategyAslan AlpAinda não há avaliações
- 15mge20079 Monetisation of Customer ValueDocumento13 páginas15mge20079 Monetisation of Customer ValueAslan AlpAinda não há avaliações
- Asset Management - BekaertDocumento10 páginasAsset Management - BekaertAslan AlpAinda não há avaliações
- Why All Takeovers Aren't Created Equal, Roger LowensteinDocumento2 páginasWhy All Takeovers Aren't Created Equal, Roger LowensteinAslan AlpAinda não há avaliações
- Sampa Video SpreadsheetDocumento4 páginasSampa Video SpreadsheetVarsha ShirsatAinda não há avaliações
- Harvard - Investment Banking (Fall 2015) PDFDocumento8 páginasHarvard - Investment Banking (Fall 2015) PDFAslan AlpAinda não há avaliações
- Chapter 12 AppDocumento3 páginasChapter 12 AppDaniel Hanry SitompulAinda não há avaliações
- Industrial Corporates: Rating MethodologyDocumento14 páginasIndustrial Corporates: Rating MethodologyAslan AlpAinda não há avaliações
- Decision Making ModelDocumento1 páginaDecision Making ModelAslan AlpAinda não há avaliações
- Framework For Risk ManagementDocumento11 páginasFramework For Risk ManagementKomal SharmaAinda não há avaliações
- FINC 448 0 80 - Spring2018Documento90 páginasFINC 448 0 80 - Spring2018Aslan AlpAinda não há avaliações
- Kislan PDFDocumento2 páginasKislan PDFSankalan GhoshAinda não há avaliações
- Coal News Letter 05-10-2017Documento15 páginasCoal News Letter 05-10-2017Aslan AlpAinda não há avaliações
- Dividend Policy at FPL Group, Inc. (A)Documento16 páginasDividend Policy at FPL Group, Inc. (A)Aslan Alp0% (1)
- Excel Spreadsheet Sampa VideoDocumento5 páginasExcel Spreadsheet Sampa VideoFaith AllenAinda não há avaliações
- Advanced Portfolio Management - Summer '18Documento2 páginasAdvanced Portfolio Management - Summer '18Aslan AlpAinda não há avaliações
- A New Era in Japan's Retailing MarketDocumento2 páginasA New Era in Japan's Retailing MarketAslan AlpAinda não há avaliações
- Jai BanglaDocumento4 páginasJai BanglaDebjaniDasAinda não há avaliações
- Teldat SD Wan Features Description April 2018 180413Documento35 páginasTeldat SD Wan Features Description April 2018 180413casinaroAinda não há avaliações
- Ans Key ND20Documento17 páginasAns Key ND20jgjeslinAinda não há avaliações
- Emotionally Adaptive Driver Voice Alert System For Advanced Driver Assistance System (ADAS) ApplicationsDocumento4 páginasEmotionally Adaptive Driver Voice Alert System For Advanced Driver Assistance System (ADAS) ApplicationsBaptist LAinda não há avaliações
- Nehru Place CTC PricelistDocumento7 páginasNehru Place CTC PricelistAnonymous nqIC9a8BIAinda não há avaliações
- Choco SolverDocumento47 páginasChoco SolverHenne PopenneAinda não há avaliações
- Types of Computer NetworksDocumento9 páginasTypes of Computer Networksthet.htar.oo442Ainda não há avaliações
- Word MemosDocumento7 páginasWord MemosMuhammad AhmedAinda não há avaliações
- General Information: Shutdown SISDocumento5 páginasGeneral Information: Shutdown SISwagner_guimarães_1Ainda não há avaliações
- Cisco Firepower NGIPS Deployment GuideDocumento21 páginasCisco Firepower NGIPS Deployment GuideMohcine OubadiAinda não há avaliações
- Panther VDocumento4 páginasPanther VFelipe Fantinel100% (1)
- Encrypted TerrorismDocumento62 páginasEncrypted TerrorismUlisesodisseaAinda não há avaliações
- 4-20mA Radar Level Sensor Spec SheetDocumento2 páginas4-20mA Radar Level Sensor Spec SheetShrikant KambleAinda não há avaliações
- FGD PDS M21 Gas Detection Transmitter PDFDocumento4 páginasFGD PDS M21 Gas Detection Transmitter PDFVictor Hugo Alvarez RicoAinda não há avaliações
- FS1530C CNC Router Technical SpecsDocumento7 páginasFS1530C CNC Router Technical SpecsAutomotive AlbacaAinda não há avaliações
- S.No: 1 Exp. Name: DateDocumento3 páginasS.No: 1 Exp. Name: DateSai KiranAinda não há avaliações
- White PaperDocumento13 páginasWhite PapercrissalahAinda não há avaliações
- Encore and Eclipse pump calibration guideDocumento3 páginasEncore and Eclipse pump calibration guideMarjorie AlexandraAinda não há avaliações
- PCM 1718Documento14 páginasPCM 1718isaiasvaAinda não há avaliações
- ID161011033 Nandita Thakur BUS304 Sec1 MIDDocumento9 páginasID161011033 Nandita Thakur BUS304 Sec1 MIDhillol laptop100% (1)
- Controlador CQ 2001Documento156 páginasControlador CQ 2001Martin Raynoldi GutierrezAinda não há avaliações
- Lecture 7Documento28 páginasLecture 7Nkugwa Mark WilliamAinda não há avaliações
- SAP CloudDocumento512 páginasSAP CloudyabbaAinda não há avaliações
- StressFree Sketching Week 1 Assignment LTDocumento2 páginasStressFree Sketching Week 1 Assignment LTMariana BelhamAinda não há avaliações
- Re-Prog3113 Progg (Oracle Database) Nciiip1Documento48 páginasRe-Prog3113 Progg (Oracle Database) Nciiip1Jaydine Davis0% (1)
- Meditaciones Diarias THOMAS PRINTZDocumento100 páginasMeditaciones Diarias THOMAS PRINTZCristian Andres Araya CisternasAinda não há avaliações
- Lindell V Dominion Smartmatic Exhibit 2Documento21 páginasLindell V Dominion Smartmatic Exhibit 2UncoverDCAinda não há avaliações
- Three-Dimensional Static and Dynamic Analysis of Structures: Edward L. WilsonDocumento20 páginasThree-Dimensional Static and Dynamic Analysis of Structures: Edward L. WilsonManuel FloresAinda não há avaliações
- 7800 Series Burner ControlDocumento27 páginas7800 Series Burner Controlrizky ListyawanAinda não há avaliações
- User ExperienceDocumento5 páginasUser ExperienceSidharthAinda não há avaliações