Você também pode gostar
- 100+ SQL Queries Jet SQL for Microsoft Office AccessNo Everand100+ SQL Queries Jet SQL for Microsoft Office AccessNota: 5 de 5 estrelas5/5 (1)
- Complex Queries in SQLDocumento15 páginasComplex Queries in SQLVibhor JainAinda não há avaliações
- Complex SQLDocumento127 páginasComplex SQLlokeshscribd186100% (6)
- SQL Interview QuestionsDocumento8 páginasSQL Interview Questionssaurav560100% (1)
- Graphs with MATLAB (Taken from "MATLAB for Beginners: A Gentle Approach")No EverandGraphs with MATLAB (Taken from "MATLAB for Beginners: A Gentle Approach")Nota: 4 de 5 estrelas4/5 (2)
- SQL Notes PDFDocumento15 páginasSQL Notes PDFAAinda não há avaliações
- MATLAB for Beginners: A Gentle Approach - Revised EditionNo EverandMATLAB for Beginners: A Gentle Approach - Revised EditionNota: 3.5 de 5 estrelas3.5/5 (11)
- Matrices with MATLAB (Taken from "MATLAB for Beginners: A Gentle Approach")No EverandMatrices with MATLAB (Taken from "MATLAB for Beginners: A Gentle Approach")Nota: 3 de 5 estrelas3/5 (4)
- SQL Interview QuestionDocumento22 páginasSQL Interview Questionrenakumari100% (3)
- DLTSoul DrinkersDocumento7 páginasDLTSoul DrinkersIgnacio Burón García100% (1)
- SQL TuningDocumento53 páginasSQL TuningAmit Kasana100% (1)
- Chapter 3: SelectingDocumento1 páginaChapter 3: SelectingMsd TrpkovićAinda não há avaliações
- Step 13: Each NUMBER ( ) Call in The Select List Is Computed For Each Row andDocumento1 páginaStep 13: Each NUMBER ( ) Call in The Select List Is Computed For Each Row andMsd TrpkovićAinda não há avaliações
- SQL NotesDocumento12 páginasSQL Notesspeedmail71Ainda não há avaliações
- SQL Alias:: To Make Selected Columns More Readable.Documento17 páginasSQL Alias:: To Make Selected Columns More Readable.Ankit NischalAinda não há avaliações
- SQL Queries 1688182703Documento127 páginasSQL Queries 1688182703PadmaAinda não há avaliações
- Retrieve 2nd Highest Salary in Each Department Using GROUP BYDocumento15 páginasRetrieve 2nd Highest Salary in Each Department Using GROUP BYAlok KumarAinda não há avaliações
- Complex SQL QueriesDocumento127 páginasComplex SQL Queriessahu.aashish03Ainda não há avaliações
- EXISTS Conditions: An Condition Tests For Existence of Rows in A SubqueryDocumento5 páginasEXISTS Conditions: An Condition Tests For Existence of Rows in A Subqueryyalamandu4358Ainda não há avaliações
- SQL Interview Q&ADocumento12 páginasSQL Interview Q&ASiddharth TripathiAinda não há avaliações
- SQL JoinsDocumento5 páginasSQL JoinschalamgAinda não há avaliações
- SQL and MapInfoDocumento16 páginasSQL and MapInfoUmar Abbas Babar100% (1)
- Delete:It's An DML Command Which Is Used For Deleting Particular Table in TheDocumento6 páginasDelete:It's An DML Command Which Is Used For Deleting Particular Table in TheArya SumeetAinda não há avaliações
- Oracle Sumarry Chapters 4,6,7 and 8Documento15 páginasOracle Sumarry Chapters 4,6,7 and 8zakiabdulahi2022Ainda não há avaliações
- Reference For Ece320: Quine-Mccluskey'S MethodDocumento4 páginasReference For Ece320: Quine-Mccluskey'S MethodAviral AgarwalAinda não há avaliações
- Group by & Having ClauseDocumento2 páginasGroup by & Having ClauseManjunatha KAinda não há avaliações
- Introduction To Aggregate FunctionsDocumento24 páginasIntroduction To Aggregate FunctionsIvan Foy FlorentinoAinda não há avaliações
- Manipulating DataDocumento5 páginasManipulating DatamascarudaAinda não há avaliações
- GR Ouping D Ata: GROUP BY ClauseDocumento11 páginasGR Ouping D Ata: GROUP BY Clauseapi-3759101Ainda não há avaliações
- Structured Query Language 1Documento117 páginasStructured Query Language 1k200562 Abdul WasayAinda não há avaliações
- MapBasic - Lists of Tables and WindowsDocumento3 páginasMapBasic - Lists of Tables and WindowsDrio RioAinda não há avaliações
- Introduction To Oracle Functions and Group by ClauseDocumento62 páginasIntroduction To Oracle Functions and Group by Clauseeumine100% (2)
- Analyze order details and employee data using window functions and CTEsDocumento32 páginasAnalyze order details and employee data using window functions and CTEsHafizullah MahmudiAinda não há avaliações
- SQL (DQL, DDL, DML) : Prof. Sin-Min Lee Alina Vikutan CS 157A - Fall 2005Documento42 páginasSQL (DQL, DDL, DML) : Prof. Sin-Min Lee Alina Vikutan CS 157A - Fall 2005Anju Renjith100% (1)
- SQL PractiseDocumento9 páginasSQL Practisesonal sethAinda não há avaliações
- 2nd - SQL HelpbookDocumento31 páginas2nd - SQL HelpbookMeenal GuptaAinda não há avaliações
- SQL Interview QuestionsDocumento5 páginasSQL Interview QuestionsvenkateshgaviniAinda não há avaliações
- Quine Mccluskey HandoutDocumento15 páginasQuine Mccluskey HandoutLeoAinda não há avaliações
- SQL TaskDocumento7 páginasSQL TaskmalikmcaamitAinda não há avaliações
- SQL commands and JOIN typesDocumento12 páginasSQL commands and JOIN typesAnh ChauAinda não há avaliações
- DB2 SQL QueriesDocumento23 páginasDB2 SQL Queriesamarrai07Ainda não há avaliações
- Reporting Aggregated Data Using The Group FunctionsDocumento6 páginasReporting Aggregated Data Using The Group FunctionsFlorin NedelcuAinda não há avaliações
- SQL CommandsDocumento10 páginasSQL Commandshappykumarsharma450Ainda não há avaliações
- Backup of DB2Documento1.297 páginasBackup of DB2Kamakshigari SureshAinda não há avaliações
- Syntax: Select (Columns List) From Tablename Group by Column NameDocumento2 páginasSyntax: Select (Columns List) From Tablename Group by Column Nametab12345Ainda não há avaliações
- SpecBAS Reference ManualDocumento91 páginasSpecBAS Reference ManualPaulDunn67% (3)
- 4 Group by Clause, Having Clause, Multiple Row (Or Group or Aggregate) FunctionsDocumento17 páginas4 Group by Clause, Having Clause, Multiple Row (Or Group or Aggregate) FunctionsAditya PandeyAinda não há avaliações
- SQL Tutorial Part 1Documento26 páginasSQL Tutorial Part 1montoshAinda não há avaliações
- SQL Interview Questions For Software TestersDocumento8 páginasSQL Interview Questions For Software TesterskotichallengesAinda não há avaliações
- SQL TuningDocumento51 páginasSQL Tuningarumugam1977Ainda não há avaliações
- Data Manipulation Language-DMLDocumento5 páginasData Manipulation Language-DMLManjunatha KAinda não há avaliações
- Summary of DDL and DML CommandsDocumento7 páginasSummary of DDL and DML CommandsI am going toAinda não há avaliações
- SQL TutorialDocumento44 páginasSQL Tutorialkittu606Ainda não há avaliações
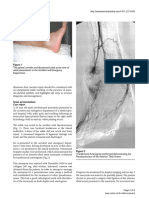
- Pseudo-Aneurysm of The Anterior Tibial Artery 4Documento1 páginaPseudo-Aneurysm of The Anterior Tibial Artery 4Msd TrpkovićAinda não há avaliações
- Pseudo-Aneurysm of The Anterior Tibial Artery 1Documento1 páginaPseudo-Aneurysm of The Anterior Tibial Artery 1Msd TrpkovićAinda não há avaliações
- Pseudo-Aneurysm of The Anterior Tibial Artery 3Documento1 páginaPseudo-Aneurysm of The Anterior Tibial Artery 3Msd TrpkovićAinda não há avaliações
- Pseudo-Aneurysm of The Anterior Tibial Artery 2Documento1 páginaPseudo-Aneurysm of The Anterior Tibial Artery 2Msd TrpkovićAinda não há avaliações
- Step 7: All GROUPING Calls Are Evaluated For Each Group and Appended ToDocumento1 páginaStep 7: All GROUPING Calls Are Evaluated For Each Group and Appended ToMsd TrpkovićAinda não há avaliações
- SelectingDocumento1 páginaSelectingMsd TrpkovićAinda não há avaliações
- Chapter 2: InsertingDocumento1 páginaChapter 2: InsertingMsd TrpkovićAinda não há avaliações
- 1, 'Hello, World', 67.89, 2003-09-30 02:15PM, 999: Chapter 2: InsertingDocumento1 página1, 'Hello, World', 67.89, 2003-09-30 02:15PM, 999: Chapter 2: InsertingMsd TrpkovićAinda não há avaliações
- Logical Execution of A SELECT: Chapter 3: SelectingDocumento1 páginaLogical Execution of A SELECT: Chapter 3: SelectingMsd TrpkovićAinda não há avaliações
- Chapter 2: InsertingDocumento1 páginaChapter 2: InsertingMsd TrpkovićAinda não há avaliações
- Chapter 2: InsertingDocumento1 páginaChapter 2: InsertingMsd TrpkovićAinda não há avaliações
- 79Documento1 página79Msd TrpkovićAinda não há avaliações
- Chapter 2: InsertingDocumento1 páginaChapter 2: InsertingMsd TrpkovićAinda não há avaliações
- Chapter 2: Inserting: INSERT Select Column ListDocumento1 páginaChapter 2: Inserting: INSERT Select Column ListMsd TrpkovićAinda não há avaliações
- Inserting Data and Recording Transactions in SQL ServerDocumento1 páginaInserting Data and Recording Transactions in SQL ServerMsd TrpkovićAinda não há avaliações
- N N N N: Chapter 2: InsertingDocumento1 páginaN N N N: Chapter 2: InsertingMsd TrpkovićAinda não há avaliações
- PSD Tutorial Linked 30 PDFDocumento29 páginasPSD Tutorial Linked 30 PDFNishki GejmerAinda não há avaliações
- Chapter 2: InsertingDocumento1 páginaChapter 2: InsertingMsd TrpkovićAinda não há avaliações
- 79Documento1 página79Msd TrpkovićAinda não há avaliações
- PW Unit 3 PDFDocumento3 páginasPW Unit 3 PDFMsd TrpkovićAinda não há avaliações
- PSD Tutorial Linked 15Documento19 páginasPSD Tutorial Linked 15Msd TrpkovićAinda não há avaliações
- SelectingDocumento1 páginaSelectingMsd TrpkovićAinda não há avaliações
- INSERT Select All Columns: Chapter 2: InsertingDocumento1 páginaINSERT Select All Columns: Chapter 2: InsertingMsd TrpkovićAinda não há avaliações
- Insert Named Values in SQLDocumento1 páginaInsert Named Values in SQLAjversonAinda não há avaliações
- PSD Tutorial Linked 30 PDFDocumento29 páginasPSD Tutorial Linked 30 PDFNishki GejmerAinda não há avaliações
- Tutorial PSDtoHTMLCSS30 PDFDocumento20 páginasTutorial PSDtoHTMLCSS30 PDFMsd TrpkovićAinda não há avaliações
- PSD Tutorial Linked 72Documento17 páginasPSD Tutorial Linked 72Msd TrpkovićAinda não há avaliações
- Steam Circulation SystemDocumento36 páginasSteam Circulation Systemjkhan_724384100% (1)
- 574-Article Text-1139-1-10-20170930Documento12 páginas574-Article Text-1139-1-10-20170930Jhufry GhanterAinda não há avaliações
- Bursting and Collapsing Pressures of ASTM A312 Stainless Steel PipesDocumento1 páginaBursting and Collapsing Pressures of ASTM A312 Stainless Steel PipesManuKumarMittalAinda não há avaliações
- The Ultimate Guide to Building an Engaged CommunityDocumento24 páginasThe Ultimate Guide to Building an Engaged CommunityCarla UttermanAinda não há avaliações
- Nb7040 - Rules For Pipe Connections and Spools: Acc. Building Specification. Rev. 2, November 2016Documento4 páginasNb7040 - Rules For Pipe Connections and Spools: Acc. Building Specification. Rev. 2, November 201624142414Ainda não há avaliações
- 330 Computer Reset AddendumDocumento75 páginas330 Computer Reset AddendumA WongAinda não há avaliações
- Sem2 NanoparticlesDocumento35 páginasSem2 NanoparticlesgujjugullygirlAinda não há avaliações
- Floor Heating Controls Wiring Instructions for FS and BA Master Weather CompensationDocumento12 páginasFloor Heating Controls Wiring Instructions for FS and BA Master Weather Compensationjamppajoo2Ainda não há avaliações
- Kadvani Forge Limitennnd3Documento133 páginasKadvani Forge Limitennnd3Kristen RollinsAinda não há avaliações
- ZEISS CALYPSO 2021 Flyer Action Software Options ENDocumento2 páginasZEISS CALYPSO 2021 Flyer Action Software Options ENnaveensirAinda não há avaliações
- Investment Banking Interview Strengths and Weaknesses PDFDocumento15 páginasInvestment Banking Interview Strengths and Weaknesses PDFkamrulAinda não há avaliações
- Calibration Procedure Crowcon Xgard Gas Detectors - 5720273 - 01Documento16 páginasCalibration Procedure Crowcon Xgard Gas Detectors - 5720273 - 01Daniel Rolando Gutierrez FuentesAinda não há avaliações
- 5100 Series Gas Analyzer: Product Data SheetDocumento2 páginas5100 Series Gas Analyzer: Product Data SheetSai KamalaAinda não há avaliações
- Adolescent InterviewDocumento9 páginasAdolescent Interviewapi-532448305Ainda não há avaliações
- Brent Academy of Northern Cebu, Inc: Talisay, Daanbantayan, Cebu First Periodical TestDocumento2 páginasBrent Academy of Northern Cebu, Inc: Talisay, Daanbantayan, Cebu First Periodical TestKristine RosarioAinda não há avaliações
- Career Development Plan: Career Navigation at UBC WebsiteDocumento10 páginasCareer Development Plan: Career Navigation at UBC WebsiteKty Margaritta MartinezAinda não há avaliações
- Guide To Preparing Tax Research MemosDocumento2 páginasGuide To Preparing Tax Research MemoscglaskoAinda não há avaliações
- Despiece Des40330 Fagor Sr-23Documento45 páginasDespiece Des40330 Fagor Sr-23Nữa Đi EmAinda não há avaliações
- Tester Sursa Gembird CHM 03 ManualDocumento15 páginasTester Sursa Gembird CHM 03 Manualzavaidoc70Ainda não há avaliações
- Department of Mechanical Engineering Polytechnic Sultan Haji Ahmad Shah Kuantan, Pahang DJJ 30122-CADDocumento2 páginasDepartment of Mechanical Engineering Polytechnic Sultan Haji Ahmad Shah Kuantan, Pahang DJJ 30122-CADAbdul MalikAinda não há avaliações
- Hydraulic Accumulator - Test and Charge: Cerrar SIS Pantalla AnteriorDocumento9 páginasHydraulic Accumulator - Test and Charge: Cerrar SIS Pantalla AnteriorHomer Yoel Nieto Mendoza100% (1)
- Boyut AnaliziDocumento65 páginasBoyut AnaliziHasan Kayhan KayadelenAinda não há avaliações
- Cognitive TheoryDocumento18 páginasCognitive TheoryshaelynAinda não há avaliações
- Critical Regionalism in ArchitectureDocumento75 páginasCritical Regionalism in ArchitecturebranishAinda não há avaliações
- Writing Theory DraftDocumento18 páginasWriting Theory Draftapi-488391657Ainda não há avaliações
- Grade 7 holiday assignment anagrams numbers analogiesDocumento4 páginasGrade 7 holiday assignment anagrams numbers analogies360MaRko oo.Ainda não há avaliações
- MD - Huzzatul Islam Contact Address: 01, International Airport Road, "Joar Sahara Bajar", APT # 13-F, Uttar Badda, Dhaka-1213, Bangladesh. Cell: +8801722223574Documento4 páginasMD - Huzzatul Islam Contact Address: 01, International Airport Road, "Joar Sahara Bajar", APT # 13-F, Uttar Badda, Dhaka-1213, Bangladesh. Cell: +8801722223574Huzzatul Islam NisarAinda não há avaliações
- Stanley I. Sandler: Equations of State For Phase Equilibrium ComputationsDocumento29 páginasStanley I. Sandler: Equations of State For Phase Equilibrium ComputationscsandrasAinda não há avaliações
- SAP MM Purchase Info Record GuideDocumento3 páginasSAP MM Purchase Info Record GuidevikneshAinda não há avaliações