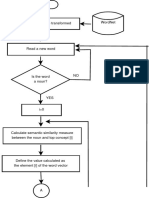
Você também pode gostar
- Tokenising and Regular Expressions - L11Documento6 páginasTokenising and Regular Expressions - L11Shilpy VermaAinda não há avaliações
- Chapter 2 - Lexical AnalyserDocumento40 páginasChapter 2 - Lexical Analyserbekalu alemayehuAinda não há avaliações
- 7.CD Lab ManualDocumento35 páginas7.CD Lab ManualBHARTI RAWATAinda não há avaliações
- VMKV Engineering College Department of Computer Science & Engineering Principles of Compiler Design Unit I Part-ADocumento80 páginasVMKV Engineering College Department of Computer Science & Engineering Principles of Compiler Design Unit I Part-ADular ChandranAinda não há avaliações
- Chapter 2 - Lexical AnalyserDocumento39 páginasChapter 2 - Lexical AnalyserAbrham EnjireAinda não há avaliações
- Chapter 2 - Lexical AnalyserDocumento38 páginasChapter 2 - Lexical AnalyserYitbarek MurcheAinda não há avaliações
- Co DataDocumento76 páginasCo DataTarun BeheraAinda não há avaliações
- CompilerDocumento31 páginasCompilerxgnoxcnisharklasersAinda não há avaliações
- Chapter 3 Lexical AnalysisDocumento5 páginasChapter 3 Lexical AnalysisAmal AhmadAinda não há avaliações
- Computer Programming-C FundamentalsDocumento38 páginasComputer Programming-C FundamentalsKamaru ZamanAinda não há avaliações
- Lexical AnalysisDocumento6 páginasLexical AnalysisTuhin ChandraAinda não há avaliações
- Lexical Analysis Using Jflex: TokensDocumento39 páginasLexical Analysis Using Jflex: TokensCarlos MaldonadoAinda não há avaliações
- 003chapter 3 - Syntax AnalysisDocumento171 páginas003chapter 3 - Syntax AnalysisEyoabAinda não há avaliações
- CC QuestionsDocumento9 páginasCC QuestionsjagdishAinda não há avaliações
- Module 5 Lexical AnalyserDocumento10 páginasModule 5 Lexical AnalyserJeevanAinda não há avaliações
- Chapter 2 - Lexical AnalysisDocumento56 páginasChapter 2 - Lexical AnalysisYenatu Lij BayeAinda não há avaliações
- The Different Phases of A CompilerDocumento9 páginasThe Different Phases of A CompilerPriyanka PariharAinda não há avaliações
- SE Compiler Chapter 2Documento16 páginasSE Compiler Chapter 2mikiberhanu41Ainda não há avaliações
- Compiler LexicalDocumento14 páginasCompiler LexicalCLASS WORKAinda não há avaliações
- Lexing and TokensDocumento6 páginasLexing and TokensricardoescuderorrssAinda não há avaliações
- Lesson 16Documento36 páginasLesson 16sdfgedr4tAinda não há avaliações
- Compiler Design - Lexical Analysis: University of Salford, UKDocumento1 páginaCompiler Design - Lexical Analysis: University of Salford, UKAmmar MehmoodAinda não há avaliações
- rkCD-Chapter 2 - LEXICAL ANALYSISDocumento9 páginasrkCD-Chapter 2 - LEXICAL ANALYSISsale msgAinda não há avaliações
- CSC 318 Class NotesDocumento21 páginasCSC 318 Class NotesYerumoh DanielAinda não há avaliações
- Lexer.: Chapter Two: Lexical AnalysisDocumento17 páginasLexer.: Chapter Two: Lexical Analysisኃይለ ማርያም አዲሱAinda não há avaliações
- Compiler Design 1Documento30 páginasCompiler Design 1Laptop StorageAinda não há avaliações
- Unit 6Documento109 páginasUnit 6Jay ShahAinda não há avaliações
- Chapter 3 Lexical AnalyserDocumento29 páginasChapter 3 Lexical AnalyserkalpanamcaAinda não há avaliações
- Chapter 3 - Syntax AnalysisDocumento160 páginasChapter 3 - Syntax Analysissamlegend2217Ainda não há avaliações
- Chapter 3 Syntax Analysis (Parsing)Documento29 páginasChapter 3 Syntax Analysis (Parsing)Feraol NegeraAinda não há avaliações
- CD Unit 2Documento20 páginasCD Unit 2ksai.mbAinda não há avaliações
- Unit - 2 Lexical AnalysisDocumento11 páginasUnit - 2 Lexical Analysismdumar umarAinda não há avaliações
- Flowgorithm DocumentationDocumento6 páginasFlowgorithm DocumentationNehal AhmedAinda não há avaliações
- Lexical Analysis: Risul Islam RaselDocumento148 páginasLexical Analysis: Risul Islam RaselRisul Islam RaselAinda não há avaliações
- Chapter 3Documento42 páginasChapter 3angawAinda não há avaliações
- Lexical and Code GenerationDocumento6 páginasLexical and Code GenerationAks KreyAinda não há avaliações
- Chap 11Documento28 páginasChap 11stepaAinda não há avaliações
- Additional Note CSC 409Documento11 páginasAdditional Note CSC 409SadiqAinda não há avaliações
- CS8602 CD Unit 2Documento43 páginasCS8602 CD Unit 2Dr. K. Sivakumar - Assoc. Professor - AIDS NIETAinda não há avaliações
- Compiler 18700220055 PrathamraiDocumento12 páginasCompiler 18700220055 PrathamraiPratham RaiAinda não há avaliações
- Lex and YaccDocumento8 páginasLex and YaccBalaji LoyisettiAinda não há avaliações
- Compiler Construction Lecture NotesDocumento27 páginasCompiler Construction Lecture NotesFidelis GodwinAinda não há avaliações
- Exercises For Section 3.3Documento8 páginasExercises For Section 3.3Mule Won TegeAinda não há avaliações
- SemanticanalysisDocumento14 páginasSemanticanalysisMohammad Yaseen PashaAinda não há avaliações
- Chapter 2Documento56 páginasChapter 2Ermias MesfinAinda não há avaliações
- 5.CD Lab ManualDocumento35 páginas5.CD Lab Manualprachi patelAinda não há avaliações
- Compiler Construction and Formal Languages: 1 Static or Dynamic?Documento15 páginasCompiler Construction and Formal Languages: 1 Static or Dynamic?breakzAinda não há avaliações
- Ss Lab Viva QuestionsDocumento3 páginasSs Lab Viva QuestionsCharlie Choco67% (3)
- Ch6 Getting Started With C++Documento33 páginasCh6 Getting Started With C++Sanskruti NamjoshiAinda não há avaliações
- ElementsDocumento3 páginasElementskj201992Ainda não há avaliações
- Compiler Construction Lecture Notes: Why Study Compilers?Documento16 páginasCompiler Construction Lecture Notes: Why Study Compilers?jaseregAinda não há avaliações
- Chapter 06 Regular Expression: ConclusionDocumento16 páginasChapter 06 Regular Expression: ConclusionCristian CosteaAinda não há avaliações
- Parsing PDFDocumento6 páginasParsing PDFAwaisAinda não há avaliações
- Phases of CompilerDocumento9 páginasPhases of Compilerankita3031Ainda não há avaliações
- Practical File: Be (Cse) 6 SemesterDocumento54 páginasPractical File: Be (Cse) 6 SemesterOm Prakash SharmaAinda não há avaliações
- SI 413, Unit 4: Scanning and Parsing: 1 Syntax & SemanticsDocumento12 páginasSI 413, Unit 4: Scanning and Parsing: 1 Syntax & SemanticsAditya Roy karmakarAinda não há avaliações
- Compiler 2Documento10 páginasCompiler 2Jabin Akter JotyAinda não há avaliações
- 02 Syntax SemanticsDocumento47 páginas02 Syntax SemanticsYahye AbdillahiAinda não há avaliações
- Coding for beginners The basic syntax and structure of codingNo EverandCoding for beginners The basic syntax and structure of codingAinda não há avaliações
- Yoshida Kyodai - HishoeDocumento1 páginaYoshida Kyodai - HishoelikufaneleAinda não há avaliações
- 3 s2.0 B9780124406513500055 MainDocumento1 página3 s2.0 B9780124406513500055 MainlikufaneleAinda não há avaliações
- Advisory Board: Gerard Alberts, Hans Van Der Meer, Donn Parker, Martin RudnerDocumento1 páginaAdvisory Board: Gerard Alberts, Hans Van Der Meer, Donn Parker, Martin RudnerlikufaneleAinda não há avaliações
- 3 s2.0 B9780124045767099871 MainDocumento1 página3 s2.0 B9780124045767099871 MainlikufaneleAinda não há avaliações
- 3 s2.0 B9780124047020050011 MainDocumento1 página3 s2.0 B9780124047020050011 MainlikufaneleAinda não há avaliações
- 3 s2.0 B9780124055315000237 MainDocumento2 páginas3 s2.0 B9780124055315000237 MainlikufaneleAinda não há avaliações
- 3 s2.0 B9780124047020100308 MainDocumento1 página3 s2.0 B9780124047020100308 MainlikufaneleAinda não há avaliações
- 3 s2.0 B978012416602809988X MainDocumento1 página3 s2.0 B978012416602809988X MainlikufaneleAinda não há avaliações
- Information Retrieval: Documents That Contain The Information WeDocumento4 páginasInformation Retrieval: Documents That Contain The Information WelikufaneleAinda não há avaliações
- Trigram Eps Converted ToDocumento1 páginaTrigram Eps Converted TolikufaneleAinda não há avaliações
- 3 s2.0 B9781843340454500046 MainDocumento1 página3 s2.0 B9781843340454500046 MainlikufaneleAinda não há avaliações
- Web Site: Conference Program Management byDocumento1 páginaWeb Site: Conference Program Management bylikufaneleAinda não há avaliações
- Postdoctoral Fellow Positions 2010.9.6Documento3 páginasPostdoctoral Fellow Positions 2010.9.6likufaneleAinda não há avaliações
- 3 s2.0 B9780124055315000213 MainDocumento1 página3 s2.0 B9780124055315000213 MainlikufaneleAinda não há avaliações
- PACLIC23 Incover2Documento1 páginaPACLIC23 Incover2likufaneleAinda não há avaliações
- Conflict of InterestDocumento1 páginaConflict of InterestlikufaneleAinda não há avaliações
- 3 s2.0 B978012800744000018X MainDocumento1 página3 s2.0 B978012800744000018X MainlikufaneleAinda não há avaliações
- Preface: Conference ChairDocumento4 páginasPreface: Conference ChairlikufaneleAinda não há avaliações
- Templates and KeywordsDocumento8 páginasTemplates and KeywordslikufaneleAinda não há avaliações
- Uni Gram Ass in TresDocumento1 páginaUni Gram Ass in TreslikufaneleAinda não há avaliações
- Binary Entropy PlotDocumento1 páginaBinary Entropy PlotlikufaneleAinda não há avaliações
- PACLIC23 Incover2Documento1 páginaPACLIC23 Incover2likufaneleAinda não há avaliações
- Ciarp AttachmentDocumento1 páginaCiarp AttachmentlikufaneleAinda não há avaliações
- Natural Language Processing II (SC674: Contents of CourseDocumento4 páginasNatural Language Processing II (SC674: Contents of CourselikufaneleAinda não há avaliações
- Response To ReviewersDocumento1 páginaResponse To ReviewerslikufaneleAinda não há avaliações
- PDF Format For PaperDocumento1 páginaPDF Format For Paperal6ayebAinda não há avaliações
- Vec CreationDocumento1 páginaVec CreationlikufaneleAinda não há avaliações
- BlankDocumento1 páginaBlanklikufaneleAinda não há avaliações
- A New Methodology For Criminal-Analysis, Based On Inductive Learning TechniquesDocumento1 páginaA New Methodology For Criminal-Analysis, Based On Inductive Learning TechniqueslikufaneleAinda não há avaliações
- TESAURO - SE1 Eps Converted ToDocumento1 páginaTESAURO - SE1 Eps Converted TolikufaneleAinda não há avaliações
- Pivot Tables in Excel (In Easy Steps)Documento6 páginasPivot Tables in Excel (In Easy Steps)Jabatan Hal Ehwal Kesatuan SekerjaAinda não há avaliações
- Assignment # 07 of C-Language On MS-WordDocumento7 páginasAssignment # 07 of C-Language On MS-WordNuman khanAinda não há avaliações
- Homework 1: You Are Allowed To Have at Most 4 CollaboratorsDocumento3 páginasHomework 1: You Are Allowed To Have at Most 4 CollaboratorsmahAinda não há avaliações
- (Dec 2011)Documento2 páginas(Dec 2011)Amit ThoriyaAinda não há avaliações
- @ITBooks4U SQL - 2 - Books - in - 1 PDFDocumento92 páginas@ITBooks4U SQL - 2 - Books - in - 1 PDFMuleAinda não há avaliações
- Raksha Shakti University, AhmedabadDocumento2 páginasRaksha Shakti University, AhmedabadAmitesh TejaswiAinda não há avaliações
- Computer Programming (JNTUH R13) : Jawaharlal Nehru Technological University Hyderabad I Year B.Tech. L T/P/D C 3 - /-/-6Documento7 páginasComputer Programming (JNTUH R13) : Jawaharlal Nehru Technological University Hyderabad I Year B.Tech. L T/P/D C 3 - /-/-6Kishor PeddiAinda não há avaliações
- Operating SystemDocumento2 páginasOperating SystemDreamtech PressAinda não há avaliações
- Chandra Ponnekanti ResumeDocumento5 páginasChandra Ponnekanti Resumep venkataAinda não há avaliações
- Lecture 3 - FPL - LISP and HaskellDocumento53 páginasLecture 3 - FPL - LISP and HaskellEna EnicAinda não há avaliações
- The Ultimate Guide To Successful Algorithmic TradingDocumento10 páginasThe Ultimate Guide To Successful Algorithmic TradingJoe DAinda não há avaliações
- Dynamic Selective Deletion From InfocubesDocumento12 páginasDynamic Selective Deletion From InfocubesSai SrinivasAinda não há avaliações
- Compiler-Design Lab Assignment SolutionDocumento20 páginasCompiler-Design Lab Assignment SolutionKapil Panwar33% (3)
- Gxworks 2 Simple ProjectDocumento106 páginasGxworks 2 Simple ProjectRobinson Velasco NavalesAinda não há avaliações
- 20 Python Concepts I Wish I Knew Way Earlier - by Liu Zuo Lin - Apr, 2023 - Level Up CodingDocumento24 páginas20 Python Concepts I Wish I Knew Way Earlier - by Liu Zuo Lin - Apr, 2023 - Level Up Codingchidiebere onwuchekwaAinda não há avaliações
- Opti ProjectDocumento1 páginaOpti ProjectTanishqAinda não há avaliações
- What Is JDBC?Documento23 páginasWhat Is JDBC?priyaAinda não há avaliações
- NCS Dummy - Taking The Expert Out of NCS Expert: FSW - PSW - TRC Nettodat - TRCDocumento37 páginasNCS Dummy - Taking The Expert Out of NCS Expert: FSW - PSW - TRC Nettodat - TRCadimaio_3dAinda não há avaliações
- Crating Web Forms Applications: by Ms. Madhura KutreDocumento47 páginasCrating Web Forms Applications: by Ms. Madhura KutreAjit PatilAinda não há avaliações
- Course Instructor: Nausheen ShoaibDocumento70 páginasCourse Instructor: Nausheen ShoaibafnanAinda não há avaliações
- OVS Input HelpDocumento2 páginasOVS Input Helplathap2007Ainda não há avaliações
- University College Cork Exam, Questions and Answers - SQL Exam 2016Documento23 páginasUniversity College Cork Exam, Questions and Answers - SQL Exam 2016jeferson.ordonioAinda não há avaliações
- Internals of Operating SystemsDocumento59 páginasInternals of Operating SystemsprogrammerAinda não há avaliações
- Kernel Configuration and Building in Linux PDFDocumento18 páginasKernel Configuration and Building in Linux PDFShah ShujaatAinda não há avaliações
- SAS Certification Practice Exam - Base ProgrammingDocumento18 páginasSAS Certification Practice Exam - Base ProgrammingArvind Shukla100% (1)
- JSP Advance JavaDocumento18 páginasJSP Advance Javareduanullah nawshadAinda não há avaliações
- TheresumeDocumento1 páginaTheresumeapi-330906952Ainda não há avaliações
- Developing Met A Web AppsDocumento164 páginasDeveloping Met A Web Appsdivyang_99Ainda não há avaliações
- SAP IDOC Tutorial PDFDocumento14 páginasSAP IDOC Tutorial PDFمحمد شعيب100% (1)
- SQLRDD ManualDocumento38 páginasSQLRDD ManualltspbrAinda não há avaliações