Você também pode gostar
- Tables of Weber Functions: Mathematical Tables, Vol. 1No EverandTables of Weber Functions: Mathematical Tables, Vol. 1Ainda não há avaliações
- Tables of the Function w (z)- e-z2 ? ex2 dx: Mathematical Tables Series, Vol. 27No EverandTables of the Function w (z)- e-z2 ? ex2 dx: Mathematical Tables Series, Vol. 27Ainda não há avaliações
- ME 4061 Compressible Flow Unsteady Wave MotionDocumento27 páginasME 4061 Compressible Flow Unsteady Wave MotionFatih İnalAinda não há avaliações
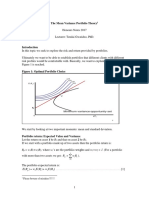
- Mean Variance Portfolio TheoryDocumento85 páginasMean Variance Portfolio TheoryEbenezerAinda não há avaliações
- Formula Sheet For MidtermDocumento1 páginaFormula Sheet For MidtermrawanelayusAinda não há avaliações
- The Mean Variance Portfolio TheoryDocumento32 páginasThe Mean Variance Portfolio TheoryEbenezerAinda não há avaliações
- H SQP Physics-Relationships-DQPDocumento4 páginasH SQP Physics-Relationships-DQPAaronAinda não há avaliações
- p1200 Lecture21Documento21 páginasp1200 Lecture21Crow NachorAinda não há avaliações
- Electromagnetic Theory II: 2 2 2 P 2 P 2 P R R 2 P 2 2 R 2 P 2 2 R eDocumento7 páginasElectromagnetic Theory II: 2 2 2 P 2 P 2 P R R 2 P 2 2 R 2 P 2 2 R enicecountAinda não há avaliações
- JWCh07 PDFDocumento29 páginasJWCh07 PDF007featherAinda não há avaliações
- Ae 2303 AerodynamicsDocumento10 páginasAe 2303 AerodynamicsShanmuganathanAinda não há avaliações
- EquationSheet TestB 2023Documento2 páginasEquationSheet TestB 20231218doyoungAinda não há avaliações
- Subjects: Hyperbolic Orbits. Interplanetary TransferDocumento5 páginasSubjects: Hyperbolic Orbits. Interplanetary TransferAdven TuresAinda não há avaliações
- Hydro 1 Module 2Documento13 páginasHydro 1 Module 2Jericho Alfred Rullog Sapitula100% (1)
- Markowitz Models and CAPMDocumento17 páginasMarkowitz Models and CAPMVinay DuttaAinda não há avaliações
- SS2 Pre-Prac (1) (Repaired)Documento18 páginasSS2 Pre-Prac (1) (Repaired)Lenny NdlovuAinda não há avaliações
- 4.0 Stability Analysis TechniquesDocumento21 páginas4.0 Stability Analysis TechniquesKristi GjokaAinda não há avaliações
- Chapter 7 Portfolio Theory: 1 Introduction and OverviewDocumento38 páginasChapter 7 Portfolio Theory: 1 Introduction and OverviewEbenezerMebrateAinda não há avaliações
- (2 π) σ (w) θ 1− ρ − − 1− p + 1−ρ exp −∁ 2 1−ρ 2 ρw + 1 1 2Documento2 páginas(2 π) σ (w) θ 1− ρ − − 1− p + 1−ρ exp −∁ 2 1−ρ 2 ρw + 1 1 2Bazanye BoscoAinda não há avaliações
- Sasi Institute of Technology EnineeringDocumento6 páginasSasi Institute of Technology EnineeringHamu NalaAinda não há avaliações
- Flow Measurement in Pipes: Objective: To Study The Applications of The Bernoulli's EquationDocumento9 páginasFlow Measurement in Pipes: Objective: To Study The Applications of The Bernoulli's EquationAyub Ali WehelieAinda não há avaliações
- Fall 2012 - EE423 First Midterm Exam SolutionDocumento2 páginasFall 2012 - EE423 First Midterm Exam SolutionAqAinda não há avaliações
- Document 1Documento1 páginaDocument 1fxAinda não há avaliações
- FIN B385F Formula Book Unit 1Documento3 páginasFIN B385F Formula Book Unit 1Cheng Chi HongAinda não há avaliações
- 2 4 1 2 4 N N N S N N : Q S U U U P UU U T U U U S Uq T S P TDocumento1 página2 4 1 2 4 N N N S N N : Q S U U U P UU U T U U U S Uq T S P TTANITOSAinda não há avaliações
- Thien My HW 9 Random ProcessDocumento1 páginaThien My HW 9 Random ProcessMỹ NgôAinda não há avaliações
- Quantum Mechanics: The Hydrogen Atom: 12th April 2008Documento5 páginasQuantum Mechanics: The Hydrogen Atom: 12th April 2008TIMOTHY JAMESONAinda não há avaliações
- SM1 HW1Documento7 páginasSM1 HW1Vaughan PngAinda não há avaliações
- Old Thermo Exam Formula SheetDocumento1 páginaOld Thermo Exam Formula SheetjonahAinda não há avaliações
- Microwave EngineeringDocumento55 páginasMicrowave EngineeringSáçhîñAinda não há avaliações
- PS2 International Macroconomics SolutionsDocumento6 páginasPS2 International Macroconomics SolutionsGhazi Ben JaballahAinda não há avaliações
- 2-Single Vs Multi Polarization Interferometry PDFDocumento24 páginas2-Single Vs Multi Polarization Interferometry PDFadre traAinda não há avaliações
- ECE 550 Lecture Notes 1Documento181 páginasECE 550 Lecture Notes 1haroutuonAinda não há avaliações
- 2015 BFnature15750 MOESM58 ESMDocumento9 páginas2015 BFnature15750 MOESM58 ESMmacheng yangAinda não há avaliações
- N N N N: Example 8.15: The Iqs (Intelligence Quotients) of 16 Students From One Area of A City Showed A MeanDocumento2 páginasN N N N: Example 8.15: The Iqs (Intelligence Quotients) of 16 Students From One Area of A City Showed A MeannithinAinda não há avaliações
- Rapidly Varied Flow (RVF) : Majid Mirzaei University of MalayaDocumento64 páginasRapidly Varied Flow (RVF) : Majid Mirzaei University of MalayaaboodAinda não há avaliações
- 3 8 Solved Problems PDFDocumento1 página3 8 Solved Problems PDFEli m. paredesAinda não há avaliações
- Faculty Etsu EduDocumento7 páginasFaculty Etsu EduFidelis MathiasAinda não há avaliações
- Laboratory Report 2 - CarpioDocumento16 páginasLaboratory Report 2 - Carpiojm1382708Ainda não há avaliações
- Heat Transfer 2nd Ed. by Cengel-647Documento1 páginaHeat Transfer 2nd Ed. by Cengel-647Gifted MouhcineAinda não há avaliações
- Cap 5 SuministroDocumento59 páginasCap 5 SuministroEmyleth PeraltaAinda não há avaliações
- Modulator Basics: Special Topics in Optical Comm.: Si Photonics (11/1)Documento6 páginasModulator Basics: Special Topics in Optical Comm.: Si Photonics (11/1)ashutosh199625Ainda não há avaliações
- Formula List and Stats TablesDocumento11 páginasFormula List and Stats TablessulistyokuAinda não há avaliações
- Ch.7 Entropy Change For An Ideal Gas (Reversible Process)Documento3 páginasCh.7 Entropy Change For An Ideal Gas (Reversible Process)Iam A gnoomAinda não há avaliações
- Ejercicio Edp ExpoDocumento1 páginaEjercicio Edp Exposantiago floresAinda não há avaliações
- EE5103/ME5403 Lecture Two Computer Control and Discrete-Time SystemsDocumento49 páginasEE5103/ME5403 Lecture Two Computer Control and Discrete-Time SystemsFeiAinda não há avaliações
- Formula Sheet For Exam #1: R X X R Z Z J Z JX R ZDocumento1 páginaFormula Sheet For Exam #1: R X X R Z Z J Z JX R ZNguyễn TàiAinda não há avaliações
- Financial Market Analysis (Fmax) : "Asset Allocation and Diversification"Documento52 páginasFinancial Market Analysis (Fmax) : "Asset Allocation and Diversification"Beka GurgenidzeAinda não há avaliações
- JEE Main 2023 6 April Shift 2Documento39 páginasJEE Main 2023 6 April Shift 2Madhu RathAinda não há avaliações
- Bode, Polar & Nyquist Plot NotesDocumento47 páginasBode, Polar & Nyquist Plot NotesMitul YadavAinda não há avaliações
- Method of MomentsDocumento28 páginasMethod of MomentsAbduljabbar AbdulAinda não há avaliações
- Mathematical Constants-Errata - Steven R. Finch PDFDocumento69 páginasMathematical Constants-Errata - Steven R. Finch PDFAndrés GranadosAinda não há avaliações
- Unit 2Documento42 páginasUnit 2Kalai Selvan BaskaranAinda não há avaliações
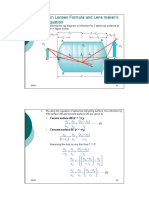
- 1.5 Thin Lenses Formula and Lens Maker's Equation: U V V R R N V TDocumento2 páginas1.5 Thin Lenses Formula and Lens Maker's Equation: U V V R R N V TNivegad HerAinda não há avaliações
- E Rathakrishnan Gas Dynamics SolutionsDocumento216 páginasE Rathakrishnan Gas Dynamics SolutionsVigneshVickey67% (15)
- Math 213a: Homework 2: Vinh-Kha Le September 2018Documento10 páginasMath 213a: Homework 2: Vinh-Kha Le September 2018vinhkhaleAinda não há avaliações
- Physics RulesDocumento19 páginasPhysics RulesAhmed GhanamAinda não há avaliações
- International Portfolio DiversificationDocumento34 páginasInternational Portfolio DiversificationGaurav KumarAinda não há avaliações
- Formulário - Mecânica Dos Fluidos (MEE210/MEE620/MEE630)Documento2 páginasFormulário - Mecânica Dos Fluidos (MEE210/MEE620/MEE630)Victor TavaresAinda não há avaliações
- Introduction To Cavitation in Pumps and Their TypesDocumento12 páginasIntroduction To Cavitation in Pumps and Their TypesMujadid Khawaja100% (1)
- 2017 Lecture 3 Metal Carbonyls PDFDocumento28 páginas2017 Lecture 3 Metal Carbonyls PDFMahnoor FatimaAinda não há avaliações
- Coca-Cola BeverageDocumento17 páginasCoca-Cola BeverageMahmood SadiqAinda não há avaliações
- Income Tax - MidtermDocumento9 páginasIncome Tax - MidtermThe Second OneAinda não há avaliações
- SPR, RCS-9627CN, NoDocumento5 páginasSPR, RCS-9627CN, NoAmaresh NayakAinda não há avaliações
- FTec 150 - Intro To Meat ProcessingDocumento51 páginasFTec 150 - Intro To Meat ProcessingJessa Silvano ArgallonAinda não há avaliações
- Public Economics - All Lecture Note PDFDocumento884 páginasPublic Economics - All Lecture Note PDFAllister HodgeAinda não há avaliações
- Intern JanataDocumento59 páginasIntern JanataKhairul IslamAinda não há avaliações
- Irshad KamilDocumento11 páginasIrshad Kamilprakshid3022100% (1)
- Ed508-5e-Lesson-Plan-Severe Weather EventsDocumento3 páginasEd508-5e-Lesson-Plan-Severe Weather Eventsapi-526575993Ainda não há avaliações
- Bird Beak Adaptations: PurposeDocumento9 páginasBird Beak Adaptations: PurposelilazrbAinda não há avaliações
- Prayer For Protection PDFDocumento3 páginasPrayer For Protection PDFtim100% (1)
- FeCl3 Msds - VISCOSITYDocumento9 páginasFeCl3 Msds - VISCOSITYramkesh rathaurAinda não há avaliações
- Ekoplastik PPR Catalogue of ProductsDocumento36 páginasEkoplastik PPR Catalogue of ProductsFlorin Maria ChirilaAinda não há avaliações
- Stock Trak AssignmentDocumento4 páginasStock Trak AssignmentPat ParisiAinda não há avaliações
- Proposal Mini Project SBL LatestDocumento19 páginasProposal Mini Project SBL Latestapi-310034018Ainda não há avaliações
- ACCA Strategic Business Reporting (SBR) Workbook 2020Documento840 páginasACCA Strategic Business Reporting (SBR) Workbook 2020Azba Nishath0% (1)
- Study - Id23039 - Travel and Tourism in India Statista Dossier PDFDocumento60 páginasStudy - Id23039 - Travel and Tourism in India Statista Dossier PDFaashmeen25Ainda não há avaliações
- VtmsDocumento2 páginasVtmsLorenz YatcoAinda não há avaliações
- Harmonica IntroDocumento5 páginasHarmonica Introapi-26593142100% (1)
- Fluid Mechanics and Machinery Laboratory Manual: by Dr. N. Kumara SwamyDocumento4 páginasFluid Mechanics and Machinery Laboratory Manual: by Dr. N. Kumara SwamyMD Mahmudul Hasan Masud100% (1)
- MMG 302Documento164 páginasMMG 302piyush patilAinda não há avaliações
- 2 Issues in Language LearningDocumento30 páginas2 Issues in Language LearningEva JakupcevicAinda não há avaliações
- Thermo Exam QuestionsDocumento4 páginasThermo Exam QuestionssiskieoAinda não há avaliações
- Basic Customer Service SkillsDocumento90 páginasBasic Customer Service SkillsGillian Delos ReyesAinda não há avaliações
- Harvester Main MenuDocumento3 páginasHarvester Main MenuWonderboy DickinsonAinda não há avaliações
- 1 - CV - SwarupaGhosh-Solutions Account ManagerDocumento2 páginas1 - CV - SwarupaGhosh-Solutions Account ManagerprabhujainAinda não há avaliações
- Adherence Tradeoff To Multiple Preventive Therapies and All-Cause Mortality After Acute Myocardial InfarctionDocumento12 páginasAdherence Tradeoff To Multiple Preventive Therapies and All-Cause Mortality After Acute Myocardial InfarctionRoberto López MataAinda não há avaliações
- Introduction To Plant Physiology!!!!Documento112 páginasIntroduction To Plant Physiology!!!!Bio SciencesAinda não há avaliações
- Osssc JR Clerk Odia Paper 2015 - 20171207 - 0001Documento7 páginasOsssc JR Clerk Odia Paper 2015 - 20171207 - 0001songspk100Ainda não há avaliações