Você também pode gostar
- Brinell Hardness Standard.Documento32 páginasBrinell Hardness Standard.Basker VenkataramanAinda não há avaliações
- Optimum Array Processing: Part IV of Detection, Estimation, and Modulation TheoryNo EverandOptimum Array Processing: Part IV of Detection, Estimation, and Modulation TheoryAinda não há avaliações
- Ebookdjj5113 Mechanics of Machines WatermarkDocumento272 páginasEbookdjj5113 Mechanics of Machines WatermarkXCarlZAinda não há avaliações
- FDMEE Vs Cloud Data ManagementDocumento20 páginasFDMEE Vs Cloud Data ManagementjeffconnorsAinda não há avaliações
- Digital Signal Processing Matlab ProgramsDocumento34 páginasDigital Signal Processing Matlab ProgramsAnuja BhakuniAinda não há avaliações
- 008 ArchitecturalDocumento45 páginas008 ArchitecturalPrashant SinghAinda não há avaliações
- Cs-101: Computer Systems: Introduction To Programming Using MatlabDocumento60 páginasCs-101: Computer Systems: Introduction To Programming Using MatlabnicksoldenAinda não há avaliações
- Full Text 01Documento60 páginasFull Text 01Sijo Mathew100% (1)
- Placing DatumsDocumento29 páginasPlacing Datumssaravind120% (1)
- Latex WikiDocumento310 páginasLatex WikiDiamond PlanetAinda não há avaliações
- OCR Wiley - Kleinrock - Queueing Systems (1975)Documento426 páginasOCR Wiley - Kleinrock - Queueing Systems (1975)lcallesar100% (3)
- VLSI LAB Manual 2014 PDFDocumento67 páginasVLSI LAB Manual 2014 PDFraghvendrmAinda não há avaliações
- Model and Simulation PDFDocumento253 páginasModel and Simulation PDFRobert GoAinda não há avaliações
- Industry Insights Blogs: Richard Goering (/members/rgoering)Documento5 páginasIndustry Insights Blogs: Richard Goering (/members/rgoering)hello860Ainda não há avaliações
- RoboticsDocumento579 páginasRoboticsDaniel Milosevski83% (6)
- Artificial Neural Networks - Methodological Advances and Bio Medical ApplicationsDocumento374 páginasArtificial Neural Networks - Methodological Advances and Bio Medical ApplicationsMustafa DgnAinda não há avaliações
- Philosophy of Mind (Jenkins & Sullivan) (2012)Documento199 páginasPhilosophy of Mind (Jenkins & Sullivan) (2012)Claudenicio Ferreira100% (2)
- ECC - Cyclic Group Cryptography With EllipticDocumento21 páginasECC - Cyclic Group Cryptography With EllipticMkumAinda não há avaliações
- Regression Analysis in Machine LearningDocumento26 páginasRegression Analysis in Machine Learningvepowo LandryAinda não há avaliações
- Mean Life Time of Cosmic Ray MuonDocumento16 páginasMean Life Time of Cosmic Ray Muontaimur_usna100% (1)
- Radial Basis FunctionDocumento35 páginasRadial Basis FunctionNicolas De NadaiAinda não há avaliações
- Asic CH13Documento30 páginasAsic CH13Vivek100% (2)
- Digital PLLDocumento6 páginasDigital PLLPeter Podhoranský100% (1)
- Weiner FilterDocumento35 páginasWeiner FilterSreekanth PagadapalliAinda não há avaliações
- DBMS Course OutlineDocumento14 páginasDBMS Course OutlineMohammed NouhAinda não há avaliações
- Recurrent Neural Networks For PredictionDocumento297 páginasRecurrent Neural Networks For PredictionHWAinda não há avaliações
- A Reversible Design of BCD MultiplierDocumento6 páginasA Reversible Design of BCD MultiplierJournal of ComputingAinda não há avaliações
- S Functions in Matlab R2013Documento594 páginasS Functions in Matlab R2013Naveen Gupta100% (1)
- DSP CEN352 ch4 DFTDocumento59 páginasDSP CEN352 ch4 DFTTewodros100% (1)
- Iec 1131-3Documento5 páginasIec 1131-3Jaziel CabralAinda não há avaliações
- Gpu, Cuda and PycudaDocumento11 páginasGpu, Cuda and PycudaHugo ContrerasAinda não há avaliações
- QueueingDocumento50 páginasQueueingJagan RajendiranAinda não há avaliações
- Parallela Cluster by Michael Johan KrugerDocumento56 páginasParallela Cluster by Michael Johan KrugerGiacomo Marco ToigoAinda não há avaliações
- Difference Between DFS and BFS?Documento14 páginasDifference Between DFS and BFS?ranadip dasAinda não há avaliações
- Course Guide Big Data University College Groningen: Academic Year 2020/2021, Semester Ib 1. General InformationDocumento6 páginasCourse Guide Big Data University College Groningen: Academic Year 2020/2021, Semester Ib 1. General InformationD.C. LykowskaAinda não há avaliações
- Lec02 FilterDocumento64 páginasLec02 FiltermuucoolAinda não há avaliações
- Seminar Report Format For PBSDocumento13 páginasSeminar Report Format For PBSAjay VaidyaAinda não há avaliações
- Harr Wavelet AnalysisDocumento47 páginasHarr Wavelet AnalysisGaurav KhantwalAinda não há avaliações
- Ai QBDocumento3 páginasAi QBJyotsna SuraydevaraAinda não há avaliações
- Z TransformDocumento9 páginasZ TransformKiran Googly JadhavAinda não há avaliações
- Dynamic Optimization - BookDocumento84 páginasDynamic Optimization - Bookpijus_kuzmaAinda não há avaliações
- Dz09usermanual 161003123921Documento13 páginasDz09usermanual 161003123921tamuztechAinda não há avaliações
- Unit 4 - Neural Networks PDFDocumento12 páginasUnit 4 - Neural Networks PDFflorinciriAinda não há avaliações
- Sed and AwkDocumento13 páginasSed and AwkVamsi KrishnaAinda não há avaliações
- AN002 Application Note: What Is A Quaternion?Documento3 páginasAN002 Application Note: What Is A Quaternion?kirancallsAinda não há avaliações
- (#R) How To Convert Lat-Long Coordinates To UTM (Easting-Northing)Documento4 páginas(#R) How To Convert Lat-Long Coordinates To UTM (Easting-Northing)Ahmad ZaenalAinda não há avaliações
- Introduction To Spi Interface PDFDocumento5 páginasIntroduction To Spi Interface PDFNeha BarothiyaAinda não há avaliações
- Breaking The Coppersmith-Winograd Barrier For Matrix Multiplication AlgorithmsDocumento73 páginasBreaking The Coppersmith-Winograd Barrier For Matrix Multiplication AlgorithmsAWhAinda não há avaliações
- M7-Logic AGENT WUMPUS PEASDocumento75 páginasM7-Logic AGENT WUMPUS PEASchitraAinda não há avaliações
- Hoare 2600Documento65 páginasHoare 2600Robert BoyAinda não há avaliações
- Introduction To PDF Programming: Leonard Rosenthol LazerwareDocumento33 páginasIntroduction To PDF Programming: Leonard Rosenthol LazerwareBieliūnaitė KarolinaAinda não há avaliações
- Handouts RealAnalysis IIDocumento168 páginasHandouts RealAnalysis IIbareera gulAinda não há avaliações
- Rotation MatrixDocumento22 páginasRotation MatrixchessgeneralAinda não há avaliações
- Sallen Key Low Pass FilterDocumento4 páginasSallen Key Low Pass FilterPhilip Caesar EbitAinda não há avaliações
- VHDL FaqDocumento6 páginasVHDL FaqRavindra Mathanker100% (2)
- EE 4314 - Control Systems: Inverse Laplace TransformDocumento8 páginasEE 4314 - Control Systems: Inverse Laplace TransformNick NumlkAinda não há avaliações
- Publisher: Pearson IndiaDocumento5 páginasPublisher: Pearson IndiaDarshan M MAinda não há avaliações
- Progress in Electromagnetics Research, PIER 98, 33-52, 2009Documento20 páginasProgress in Electromagnetics Research, PIER 98, 33-52, 2009brij_astraAinda não há avaliações
- RNNDocumento16 páginasRNNSourabh AttriAinda não há avaliações
- UNIT I, II, III, IV, V Notes PDFDocumento93 páginasUNIT I, II, III, IV, V Notes PDFThiagu RajivAinda não há avaliações
- Interview QuestionsDocumento4 páginasInterview QuestionsValakonda NikithaAinda não há avaliações
- Recurrent Neural Networks: CSC2535 2013: Advanced Machine LearningDocumento57 páginasRecurrent Neural Networks: CSC2535 2013: Advanced Machine Learningjijo123408Ainda não há avaliações
- Recurrent Neural Networks: Prof. Harshawardhan P. AhireDocumento56 páginasRecurrent Neural Networks: Prof. Harshawardhan P. AhirePRATIK GANGAPURWALAAinda não há avaliações
- Neural Networks For Machine Learning Lecture 7a Modeling Sequences: A Brief OverviewDocumento34 páginasNeural Networks For Machine Learning Lecture 7a Modeling Sequences: A Brief OverviewAdmissionofficer kbgAinda não há avaliações
- Lecture 11Documento55 páginasLecture 11roboganowo24Ainda não há avaliações
- AML 03 Dense Neural NetworksDocumento20 páginasAML 03 Dense Neural NetworksVaibhavAinda não há avaliações
- Deep Belief Nets: 2007 NIPS Tutorial OnDocumento100 páginasDeep Belief Nets: 2007 NIPS Tutorial OnFiromsa TesfayeAinda não há avaliações
- Classical Decomposition - Forecasting - Principles and PracticeDocumento4 páginasClassical Decomposition - Forecasting - Principles and PracticejeffconnorsAinda não há avaliações
- Understanding Cult Ual ContextDocumento1 páginaUnderstanding Cult Ual ContextjeffconnorsAinda não há avaliações
- Jump DiscontinuitiesDocumento6 páginasJump DiscontinuitiesjeffconnorsAinda não há avaliações
- Probability Theory For Machine Learning: Chris Cremer September 2015Documento40 páginasProbability Theory For Machine Learning: Chris Cremer September 2015jeffconnorsAinda não há avaliações
- Implicit Differentiation Equation of The Tangent LineDocumento9 páginasImplicit Differentiation Equation of The Tangent LinejeffconnorsAinda não há avaliações
- Ijfs 06 00030 PDFDocumento26 páginasIjfs 06 00030 PDFjeffconnorsAinda não há avaliações
- Logarithmic DifferentiationDocumento6 páginasLogarithmic DifferentiationjeffconnorsAinda não há avaliações
- Observer and The AirplaneDocumento12 páginasObserver and The AirplanejeffconnorsAinda não há avaliações
- Matrix Computations (3rd Ed.,1996) - 2Documento723 páginasMatrix Computations (3rd Ed.,1996) - 2Surendra SwamiAinda não há avaliações
- Area Under or Enclosed by The CurveDocumento11 páginasArea Under or Enclosed by The CurvejeffconnorsAinda não há avaliações
- Calculus 3.formulasDocumento49 páginasCalculus 3.formulasjeffconnorsAinda não há avaliações
- Critical PointsDocumento7 páginasCritical PointsjeffconnorsAinda não há avaliações
- Riemann Sums Left EndpointsDocumento10 páginasRiemann Sums Left EndpointsjeffconnorsAinda não há avaliações
- Ladder Sliding Down The WallDocumento11 páginasLadder Sliding Down The WalljeffconnorsAinda não há avaliações
- Applied OptimizationDocumento12 páginasApplied OptimizationjeffconnorsAinda não há avaliações
- Basic LinuxDocumento65 páginasBasic LinuxjeffconnorsAinda não há avaliações
- Algebraic ExpressionDocumento99 páginasAlgebraic ExpressionRyan BuboAinda não há avaliações
- Solomon B MS - C3 EdexcelDocumento4 páginasSolomon B MS - C3 EdexcelThamina AktherAinda não há avaliações
- Gomory's CutsDocumento7 páginasGomory's Cutsgladiator001Ainda não há avaliações
- Data Mining With Weka: Ian H. WittenDocumento33 páginasData Mining With Weka: Ian H. WittenQuân PhạmAinda não há avaliações
- Equilibrium and Elasticity: Powerpoint Lectures ForDocumento26 páginasEquilibrium and Elasticity: Powerpoint Lectures Forbarre PenroseAinda não há avaliações
- Ngspice ManualDocumento564 páginasNgspice ManualLalan JoshiAinda não há avaliações
- Express LibraryDocumento24 páginasExpress LibraryPrakhar SikarwarAinda não há avaliações
- PTM Phy F.4.Ch.2.4Documento13 páginasPTM Phy F.4.Ch.2.4Bazil BoliaAinda não há avaliações
- Cse PDFDocumento33 páginasCse PDFSha Nkar JavleAinda não há avaliações
- Spe 163492 Pa PDFDocumento17 páginasSpe 163492 Pa PDFsanty222Ainda não há avaliações
- 6 Prosiding ICM2E 2017Documento434 páginas6 Prosiding ICM2E 2017Andinuralfia syahrirAinda não há avaliações
- Algorithm: Computer Science: A Modern Introduction. The Algorithm "Is The Unifying ConceptDocumento7 páginasAlgorithm: Computer Science: A Modern Introduction. The Algorithm "Is The Unifying ConceptMaria ClaraAinda não há avaliações
- Richardson 2007Documento20 páginasRichardson 2007Badri VrsnprasadAinda não há avaliações
- STA642 Handouts Topic 1 To 187 by Mahar Afaq Safdar MuhammadDocumento1.739 páginasSTA642 Handouts Topic 1 To 187 by Mahar Afaq Safdar Muhammadhumairamubarak2001Ainda não há avaliações
- Engineering Economy 3Documento37 páginasEngineering Economy 3Steven SengAinda não há avaliações
- Contemporary Business Mathematics Canadian 11th Edition Hummelbrunner Test Bank 1Documento63 páginasContemporary Business Mathematics Canadian 11th Edition Hummelbrunner Test Bank 1jonathan100% (39)
- PQ - With - Id - PDF fkj1 PDFDocumento17 páginasPQ - With - Id - PDF fkj1 PDFWorse To Worst SatittamajitraAinda não há avaliações
- Playing With Blends in CoreldrawDocumento12 páginasPlaying With Blends in CoreldrawZubairAinda não há avaliações
- Data Analytics Kit 601Documento2 páginasData Analytics Kit 601Mayank GuptaAinda não há avaliações
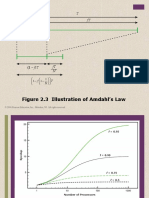
- Figure 2.3 Illustration of Amdahl's Law: © 2016 Pearson Education, Inc., Hoboken, NJ. All Rights ReservedDocumento10 páginasFigure 2.3 Illustration of Amdahl's Law: © 2016 Pearson Education, Inc., Hoboken, NJ. All Rights ReservedAhmed AyazAinda não há avaliações
- Benchmarking in B.Tech Mechanical Program of MNIT and NITT (As Benchmarking Partner)Documento13 páginasBenchmarking in B.Tech Mechanical Program of MNIT and NITT (As Benchmarking Partner)Kartik ModiAinda não há avaliações
- Solving Cubic Equations Roots Trough Cardano TartagliaDocumento2 páginasSolving Cubic Equations Roots Trough Cardano TartagliaClóvis Guerim VieiraAinda não há avaliações
- Practical Process Control System Questions & Answers - 15 - NEWSDocumento3 páginasPractical Process Control System Questions & Answers - 15 - NEWSebenazzouzAinda não há avaliações
- James Bird Centrality and The Cities Chapters 2-4Documento28 páginasJames Bird Centrality and The Cities Chapters 2-4Humberto DelgadoAinda não há avaliações