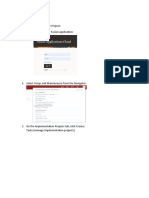
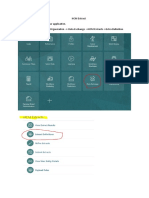
Você também pode gostar
- ID 2235545.1 Oracle HCM Cloud Checklists For Upgrading From Release 11 To Release 12 v3Documento30 páginasID 2235545.1 Oracle HCM Cloud Checklists For Upgrading From Release 11 To Release 12 v3somefunbAinda não há avaliações
- PeopleSoft Human Capital Management 9.2 Through Update Image 23 Installation 072017Documento44 páginasPeopleSoft Human Capital Management 9.2 Through Update Image 23 Installation 072017ChakravarthiVeda100% (1)
- PeopleSoft Human Capital Management 9.2 Through Update Image 23 Installation 072017Documento44 páginasPeopleSoft Human Capital Management 9.2 Through Update Image 23 Installation 072017ChakravarthiVeda100% (1)
- HRX Uk HR Setup r12Documento50 páginasHRX Uk HR Setup r12ChakravarthiVedaAinda não há avaliações
- Fast Formula in Oracle Cloud HCMDocumento32 páginasFast Formula in Oracle Cloud HCMChakravarthiVeda100% (1)
- Electronic Health RecordsDocumento12 páginasElectronic Health RecordsSahar AlmenwerAinda não há avaliações
- Displaying Current Logged User in A OTBI Report in Oracle Fusion HCM Cloud ApplicationDocumento5 páginasDisplaying Current Logged User in A OTBI Report in Oracle Fusion HCM Cloud ApplicationBala SubramanyamAinda não há avaliações
- Security Rules in HRMS (Restrict Users)Documento7 páginasSecurity Rules in HRMS (Restrict Users)zafariqbal_scribdAinda não há avaliações
- Watan Investment Erp Project Irecruitment: Te.040 S T SDocumento21 páginasWatan Investment Erp Project Irecruitment: Te.040 S T SlistoAinda não há avaliações
- Oracle Fusion - HR Setup by Mariam Hamdy Mohamed - TEQNYAT Consulting KSADocumento46 páginasOracle Fusion - HR Setup by Mariam Hamdy Mohamed - TEQNYAT Consulting KSAhamdy20017121Ainda não há avaliações
- Automating HCM Data Loader R11 (October 2017) White PaperDocumento30 páginasAutomating HCM Data Loader R11 (October 2017) White Paperjeffrey_m_sutton100% (1)
- Using Extract Criteria Fast Formula in Oracle HCM Cloud Application A Sample ExampleDocumento2 páginasUsing Extract Criteria Fast Formula in Oracle HCM Cloud Application A Sample ExampleBala SubramanyamAinda não há avaliações
- Setup and User Manual of Online PayslipDocumento8 páginasSetup and User Manual of Online PayslipMohamed Hosny ElwakilAinda não há avaliações
- HCM Extract DMOneDocumento19 páginasHCM Extract DMOnepadma gaddeAinda não há avaliações
- Integrating With HCMDocumento588 páginasIntegrating With HCMbalabalabala123Ainda não há avaliações
- OIC To HCMDocumento23 páginasOIC To HCMDeepak AroraAinda não há avaliações
- HCM Extracts FAQ For Release 5: AnswerDocumento4 páginasHCM Extracts FAQ For Release 5: Answernarendra pAinda não há avaliações
- How To Setup Employee DirectoryDocumento3 páginasHow To Setup Employee DirectoryjosephbijoyAinda não há avaliações
- How To Replace Seeded Saudi Payslip With A Custom OneDocumento64 páginasHow To Replace Seeded Saudi Payslip With A Custom Onehamdy20017121Ainda não há avaliações
- Using A Custom Payroll Flow Pattern To Submit A Parameterized Report in Oracle Cloud ApplicationDocumento9 páginasUsing A Custom Payroll Flow Pattern To Submit A Parameterized Report in Oracle Cloud ApplicationBala SubramanyamAinda não há avaliações
- Oracle Fusion HRMS For UAE Absence Setup White Paper 20.10-1Documento34 páginasOracle Fusion HRMS For UAE Absence Setup White Paper 20.10-1G FernandoAinda não há avaliações
- Oracle HR For Non-HR PeopleDocumento41 páginasOracle HR For Non-HR PeoplenthackAinda não há avaliações
- Fusion Applications PresentationDocumento48 páginasFusion Applications PresentationSridhar YerramAinda não há avaliações
- Oracle Fusion OTBI Reports by Ravinder Reddy: Udem yDocumento7 páginasOracle Fusion OTBI Reports by Ravinder Reddy: Udem yKasiviswanathan MuthiahAinda não há avaliações
- Automating HCM Data Loader PDFDocumento18 páginasAutomating HCM Data Loader PDFpurnachandra426Ainda não há avaliações
- GEH-6839 Mark VIe Control Systems Secure Deployment GuideDocumento2 páginasGEH-6839 Mark VIe Control Systems Secure Deployment Guideeaston zhang100% (1)
- HRX UK HR Setup R12Documento101 páginasHRX UK HR Setup R12Srinivasa Rao AsuruAinda não há avaliações
- Business Architecture A Practical Guide (Jonathan Whelan, Graham Meaden)Documento304 páginasBusiness Architecture A Practical Guide (Jonathan Whelan, Graham Meaden)Shahjahan MohammedAinda não há avaliações
- A HCM Responsive User Experience Setup Whitepaper 18B - 20A PDFDocumento164 páginasA HCM Responsive User Experience Setup Whitepaper 18B - 20A PDFFerasHamdanAinda não há avaliações
- Automation of HCM ExtractDocumento8 páginasAutomation of HCM ExtractyurijapAinda não há avaliações
- Payroll Tables and Views For Oracle HCM CloudDocumento14 páginasPayroll Tables and Views For Oracle HCM CloudChakravarthiVedaAinda não há avaliações
- PHP Hyper Text PreprocessorDocumento35 páginasPHP Hyper Text PreprocessorHimanshu Sharma100% (2)
- EBS R12.1 HCM Bootcamp Datasheet ReDocumento3 páginasEBS R12.1 HCM Bootcamp Datasheet ReUzair ArainAinda não há avaliações
- Generate Load and Report Data Using Custom Payroll Flow PatternDocumento20 páginasGenerate Load and Report Data Using Custom Payroll Flow PatternBala SubramanyamAinda não há avaliações
- Administering Fast FormulasDocumento110 páginasAdministering Fast Formulasnykgupta21Ainda não há avaliações
- R12 Oracle Hrms Implement and Use Fastformula: DurationDocumento2 páginasR12 Oracle Hrms Implement and Use Fastformula: DurationAlochiousDassAinda não há avaliações
- HCM Data Loader in FusionDocumento35 páginasHCM Data Loader in FusionmurliramAinda não há avaliações
- How To Import WBS From Excel To Primavera P6 Using The P6 SDKDocumento15 páginasHow To Import WBS From Excel To Primavera P6 Using The P6 SDKmvkenterprisesAinda não há avaliações
- ATS Timecom Deployment Guide For Time and Labor ApplicationDocumento5 páginasATS Timecom Deployment Guide For Time and Labor ApplicationyurijapAinda não há avaliações
- Case Study - How To Create and Modify FFDocumento8 páginasCase Study - How To Create and Modify FFKiran NambariAinda não há avaliações
- Bind Variables Work For SQL Statements That Are Exactly The Same, Where TheDocumento1 páginaBind Variables Work For SQL Statements That Are Exactly The Same, Where TheAnjali PatelAinda não há avaliações
- HCM Data Loader - Loading Payroll Interface Inbound Records (Doc ID 2141697.1)Documento1 páginaHCM Data Loader - Loading Payroll Interface Inbound Records (Doc ID 2141697.1)iceyrosesAinda não há avaliações
- Workforce Deployment ImplementationDocumento16 páginasWorkforce Deployment ImplementationsailushaAinda não há avaliações
- 05.oracle HCM Cloud R11 Loading WorkersDocumento28 páginas05.oracle HCM Cloud R11 Loading WorkersAshive MohunAinda não há avaliações
- Oracle HRMS Functional Document: Jobs and Positions Setup's (SIT's & EIT's)Documento20 páginasOracle HRMS Functional Document: Jobs and Positions Setup's (SIT's & EIT's)Dhina KaranAinda não há avaliações
- WFM Ter Compare WRKR Holiday To Reported Hours ApDocumento5 páginasWFM Ter Compare WRKR Holiday To Reported Hours ApYonny Isidro RendonAinda não há avaliações
- Create Functiong PartDocumento11 páginasCreate Functiong Partprasad_431Ainda não há avaliações
- Lesson1-HDL Introduction NotesDocumento38 páginasLesson1-HDL Introduction NotesShravanUdayAinda não há avaliações
- HCM Using Person Synchronization ESS JobDocumento13 páginasHCM Using Person Synchronization ESS JobAadii GoyalAinda não há avaliações
- Create Work Schedule in Fusion HCMDocumento4 páginasCreate Work Schedule in Fusion HCMRavish Kumar SinghAinda não há avaliações
- HCM Data Loader Support Diagnostic PDFDocumento9 páginasHCM Data Loader Support Diagnostic PDFsjawadAinda não há avaliações
- Delete Entity in FusionDocumento4 páginasDelete Entity in FusionBick KyyAinda não há avaliações
- Oracle Fusion HRMS SA Payroll BalancesDocumento58 páginasOracle Fusion HRMS SA Payroll BalancesFeras AlswairkyAinda não há avaliações
- Oracle Payroll India User ManualDocumento100 páginasOracle Payroll India User Manualnikhilburbure100% (1)
- SIT and EITDocumento8 páginasSIT and EITJoshua MeyerAinda não há avaliações
- HCM Extract Development in Fusion HCM: Shweta BapatDocumento42 páginasHCM Extract Development in Fusion HCM: Shweta Bapatanushasidagonde100% (1)
- Online Payslip For International LocalizationDocumento19 páginasOnline Payslip For International LocalizationPradeepRaghavaAinda não há avaliações
- Payroll InternationalDocumento20 páginasPayroll InternationalSridhar YerramAinda não há avaliações
- Oracle - Oracle HCM Cloud: Configure Enterprise and Workforce StructuresDocumento5 páginasOracle - Oracle HCM Cloud: Configure Enterprise and Workforce StructuresVishalAinda não há avaliações
- Oracle 1Z0-337 PDF Questions - 1Z0-337 Latest Questions 2018Documento5 páginasOracle 1Z0-337 PDF Questions - 1Z0-337 Latest Questions 2018Pass4 Leads0% (1)
- Applies To:: Apr 10, 2015 HowtoDocumento8 páginasApplies To:: Apr 10, 2015 HowtokottamramreddyAinda não há avaliações
- Fusion HCMDocumento39 páginasFusion HCMPrabhu SubramaniamAinda não há avaliações
- Loading Element Entries Using HCM Data Loader PDFDocumento11 páginasLoading Element Entries Using HCM Data Loader PDFYousef AsadiAinda não há avaliações
- HCM Setup For Non HCM CustomersDocumento6 páginasHCM Setup For Non HCM CustomersMark JaneAinda não há avaliações
- HDL Error Report: (BI Publisher)Documento10 páginasHDL Error Report: (BI Publisher)Gopinath NatAinda não há avaliações
- Oracle Cloud Applications A Complete Guide - 2019 EditionNo EverandOracle Cloud Applications A Complete Guide - 2019 EditionAinda não há avaliações
- Oracle E-Business Suite The Ultimate Step-By-Step GuideNo EverandOracle E-Business Suite The Ultimate Step-By-Step GuideAinda não há avaliações
- EntityDocumento115 páginasEntityChakravarthiVedaAinda não há avaliações
- PeopleSoft Human Capital Management 9.2 Through Update Image 23 Installation 072017Documento2 páginasPeopleSoft Human Capital Management 9.2 Through Update Image 23 Installation 072017ChakravarthiVedaAinda não há avaliações
- PSFTDocumento32 páginasPSFTChakravarthiVedaAinda não há avaliações
- PSFT Extraction Toolkit For HDL White Paper PDFDocumento45 páginasPSFT Extraction Toolkit For HDL White Paper PDFChakravarthiVedaAinda não há avaliações
- Oracle Fusion HCM Data Conversion - Key Notes: An Oracle White Paper September 2014Documento15 páginasOracle Fusion HCM Data Conversion - Key Notes: An Oracle White Paper September 2014ChakravarthiVedaAinda não há avaliações
- HCMDocumento90 páginasHCMChakravarthiVedaAinda não há avaliações
- OracleDocumento54 páginasOracleChakravarthiVedaAinda não há avaliações
- Earnings CodesDocumento249 páginasEarnings CodesChakravarthiVedaAinda não há avaliações
- Oracle Fusion HCM Data Conversion - Key Notes: An Oracle White Paper September 2014Documento15 páginasOracle Fusion HCM Data Conversion - Key Notes: An Oracle White Paper September 2014ChakravarthiVedaAinda não há avaliações
- Applies To:: Oracle Fusion Benefits Plan Design Troubleshooting Guide (Doc ID 1413906.1)Documento3 páginasApplies To:: Oracle Fusion Benefits Plan Design Troubleshooting Guide (Doc ID 1413906.1)ChakravarthiVedaAinda não há avaliações
- Template Builder For Word TutorialDocumento9 páginasTemplate Builder For Word TutorialtemesgenAinda não há avaliações
- PS Maintenance Best PracticesDocumento21 páginasPS Maintenance Best PracticesChakravarthiVedaAinda não há avaliações
- PeopleSoft Upgrade and Onsite Vs Offsite UpgradeDocumento13 páginasPeopleSoft Upgrade and Onsite Vs Offsite UpgradeChakravarthiVedaAinda não há avaliações
- Taleo - How To Set Up A Candidate Selection Workflow v2Documento9 páginasTaleo - How To Set Up A Candidate Selection Workflow v2Carlos AlmeidaAinda não há avaliações
- General Deduction CodesDocumento6 páginasGeneral Deduction CodesChakravarthiVedaAinda não há avaliações
- ExcelToCI TestDocumento7 páginasExcelToCI TestVenkatesh MAinda não há avaliações
- Absence Accrual - Extended Child Care Leave FFDocumento2 páginasAbsence Accrual - Extended Child Care Leave FFChakravarthiVedaAinda não há avaliações
- Using Manager Self - PeopleBooksDocumento26 páginasUsing Manager Self - PeopleBooksChakravarthiVedaAinda não há avaliações
- Call Secondary Page For A Main PageDocumento2 páginasCall Secondary Page For A Main PageChakravarthiVedaAinda não há avaliações
- New Features 9.2 Payroll and TL RECONNECT 2013 Emtec IncDocumento22 páginasNew Features 9.2 Payroll and TL RECONNECT 2013 Emtec IncChakravarthiVedaAinda não há avaliações
- Dasaratha Shani Stotra From Padma PuranaDocumento27 páginasDasaratha Shani Stotra From Padma PuranaChakravarthiVedaAinda não há avaliações
- A Informative Study On Big Data in Present Day WorldDocumento8 páginasA Informative Study On Big Data in Present Day WorldInternational Journal of Innovative Science and Research TechnologyAinda não há avaliações
- 0bqj3ybp4 - What Is Project ManagementDocumento24 páginas0bqj3ybp4 - What Is Project ManagementMughni SamaonAinda não há avaliações
- Digital Base1 - HandbookDocumento23 páginasDigital Base1 - HandbookKeerthi SenthilAinda não há avaliações
- Curriculum Vitae - I Gusti Agung Kartika ShantiDocumento1 páginaCurriculum Vitae - I Gusti Agung Kartika ShantiI Gusti Agung Kartika ShantiAinda não há avaliações
- EXT Read Me For Customers Service Bureau SWIFT CSP 2021 For Kyriba CusDocumento2 páginasEXT Read Me For Customers Service Bureau SWIFT CSP 2021 For Kyriba Cusgautam_86Ainda não há avaliações
- Ccna 1 Module 3 v4.0Documento4 páginasCcna 1 Module 3 v4.0ccnaexploration4Ainda não há avaliações
- Reset The Password of The Admin User On A Cisco Firepower SystemDocumento7 páginasReset The Password of The Admin User On A Cisco Firepower SystemWafikAinda não há avaliações
- Wait EventsDocumento5 páginasWait EventsfaisalwasimAinda não há avaliações
- Web Publishing Test CasesDocumento3 páginasWeb Publishing Test CasesJafar BhattiAinda não há avaliações
- The Ultimate C - C - THR86 - 2011 - SAP Certified Application Associate - SAP SuccessFactors Compensation 2H2020Documento2 páginasThe Ultimate C - C - THR86 - 2011 - SAP Certified Application Associate - SAP SuccessFactors Compensation 2H2020KirstingAinda não há avaliações
- Netapp MAX DataDocumento4 páginasNetapp MAX Datamanasonline11Ainda não há avaliações
- Assembler Module 1-1Documento23 páginasAssembler Module 1-1arunlaldsAinda não há avaliações
- Module 2Documento21 páginasModule 2efrenAinda não há avaliações
- LogDocumento109 páginasLogMerechell MisterioAinda não há avaliações
- Probation Evaluation FlowchartDocumento8 páginasProbation Evaluation FlowchartAdid RachmadiansyahAinda não há avaliações
- Unit 8 - Week 6: Assignment 6Documento3 páginasUnit 8 - Week 6: Assignment 6Manju Sk17Ainda não há avaliações
- Multitenant Database ArchitectureDocumento70 páginasMultitenant Database ArchitectureSaifur RahmanAinda não há avaliações
- Gsmme Admin Guide: G Suite Migration For Microsoft ExchangeDocumento54 páginasGsmme Admin Guide: G Suite Migration For Microsoft ExchangeadminakAinda não há avaliações
- Webp - Case Study - 601Documento15 páginasWebp - Case Study - 601Prateek KumarAinda não há avaliações
- 4 A Study of Encryption AlgorithmsDocumento9 páginas4 A Study of Encryption AlgorithmsVivekAinda não há avaliações
- Soa Interview1Documento18 páginasSoa Interview1anilandhraAinda não há avaliações
- Overview of Sap ModulesDocumento10 páginasOverview of Sap ModulesRAJLAXMI THENGDIAinda não há avaliações
- Getting Started With PdiDocumento38 páginasGetting Started With Pdider_teufelAinda não há avaliações
- SRM Mod 3 SRM PlanDocumento23 páginasSRM Mod 3 SRM PlanKedar Vishnu LadAinda não há avaliações