Você também pode gostar
- Six Sigma EjerciciosDocumento52 páginasSix Sigma EjerciciosOliver Cuadros VeraAinda não há avaliações
- Ejercicios de Estimacion Inferencia EstadisticaDocumento6 páginasEjercicios de Estimacion Inferencia EstadisticaJuAn SanchezAinda não há avaliações
- Se Tienen Dos Proveedores de Una Pieza Metálica - OdtDocumento11 páginasSe Tienen Dos Proveedores de Una Pieza Metálica - OdtJoel100% (2)
- Deber de TraaaaaaaaaaaaaaaasdfghjkDocumento6 páginasDeber de TraaaaaaaaaaaaaaaasdfghjkJuanita Arcoiris100% (1)
- Control Estadístico de CalidadDocumento12 páginasControl Estadístico de CalidadMireya Zambrano50% (2)
- Todo Tipo de ArchivoDocumento4 páginasTodo Tipo de ArchivoDavid Huayana HurtadoAinda não há avaliações
- A) ¿Qué Proveedor Parece Mejor? B) ¿Hay Una Diferencia Significativa Entre Los Dos Proveedores? Pruebe La HipótesisDocumento3 páginasA) ¿Qué Proveedor Parece Mejor? B) ¿Hay Una Diferencia Significativa Entre Los Dos Proveedores? Pruebe La HipótesisPaul100% (1)
- Taller Calidad 28,29,30Documento8 páginasTaller Calidad 28,29,30So Boring80% (5)
- Semillas germinación confianzaDocumento4 páginasSemillas germinación confianzaDaniel Gonzales Zayas100% (2)
- Inspector verifica peso de cajas de cereal con distribución normalDocumento2 páginasInspector verifica peso de cajas de cereal con distribución normalQuique Ar33% (3)
- Seminario de Estadística TAREADocumento5 páginasSeminario de Estadística TAREACarlos Muñoz50% (4)
- Ejercicios ResueltosDocumento7 páginasEjercicios ResueltosLuis Felipe Mera GrandasAinda não há avaliações
- Análisis de varianza de la resistencia del cemento portland con diferentes técnicas de mezcladoDocumento14 páginasAnálisis de varianza de la resistencia del cemento portland con diferentes técnicas de mezcladoJesQaa VarGas100% (1)
- Efecto de la temperatura en el encogimiento de materialesDocumento4 páginasEfecto de la temperatura en el encogimiento de materialesCarlos Arias100% (3)
- Tarea 3 Grupo 2 Aa Diseño ExperimentalDocumento8 páginasTarea 3 Grupo 2 Aa Diseño Experimentallidy huaracaAinda não há avaliações
- Luis AllaucaDocumento22 páginasLuis AllaucaLuis Miguel Allauca100% (2)
- Trabajo Diseño ExperimentalDocumento20 páginasTrabajo Diseño ExperimentalJulián GalindoAinda não há avaliações
- Ejercicios GrupalesDocumento2 páginasEjercicios GrupalesSoleMeza86% (7)
- 12,20,33,36Documento4 páginas12,20,33,36Daniel Gonzales ZayasAinda não há avaliações
- Ejercicios Pruebas de Hipotesis Pareadas e IndependientesDocumento12 páginasEjercicios Pruebas de Hipotesis Pareadas e IndependientesBuns Dws43% (7)
- Análisis de experimento BIB para comparar formulaciones de detergentesDocumento17 páginasAnálisis de experimento BIB para comparar formulaciones de detergentesLeandro Zambrano VelezAinda não há avaliações
- Prueba de HipotesisDocumento21 páginasPrueba de HipotesisMisael Cardona Esquivel75% (12)
- Deber Grupal #2 SGCDocumento2 páginasDeber Grupal #2 SGCVinicio Astudillo50% (2)
- Ejercicios Prueba de HipotesisDocumento7 páginasEjercicios Prueba de HipotesisAlejandro Loza80% (5)
- Analisis Ejercicio 12 NovaDocumento4 páginasAnalisis Ejercicio 12 NovaYuliAinda não há avaliações
- Ejercicio de Bloques IncompletosDocumento13 páginasEjercicio de Bloques IncompletosDamian Reyes100% (1)
- Ejercicios CalidadDocumento3 páginasEjercicios CalidadAleja Delgado100% (1)
- Diseño de Experimentos-Cap - Tres Parte 3Documento26 páginasDiseño de Experimentos-Cap - Tres Parte 3neyco100% (3)
- CAPITULO 4 Control Estadistico Seis SigmaDocumento4 páginasCAPITULO 4 Control Estadistico Seis Sigmamaximal25Ainda não há avaliações
- CusiDocumento119 páginasCusiluzvid alejo ochoaAinda não há avaliações
- Prueba de dureza con bolas de aceroDocumento15 páginasPrueba de dureza con bolas de aceroErik CorralesAinda não há avaliações
- Solucion FinalDocumento24 páginasSolucion FinalDante Palacios Valdiviezo100% (1)
- Deber Capitulo 5 (Autoguardado)Documento61 páginasDeber Capitulo 5 (Autoguardado)maribel50% (4)
- Preguntas 14 15 16 y 21Documento9 páginasPreguntas 14 15 16 y 21Ruben CortezAinda não há avaliações
- Taller de ANOVA para Diseño de ExperimentosDocumento6 páginasTaller de ANOVA para Diseño de ExperimentosAndrés Camilo100% (1)
- Estimación de porcentajes de anomalías en facturas con intervalos de confianzaDocumento7 páginasEstimación de porcentajes de anomalías en facturas con intervalos de confianzaJuan JacomeAinda não há avaliações
- Propuesto 47Documento2 páginasPropuesto 47Naik M. Calsina100% (1)
- Ejercicios 15, 23, 30Documento10 páginasEjercicios 15, 23, 30Daniel Gonzales ZayasAinda não há avaliações
- A) Esta Variable, Forzosamente Tiene Que Evaluarse Mediante Muestreo y No Al 100%, ¿Por Qué?Documento7 páginasA) Esta Variable, Forzosamente Tiene Que Evaluarse Mediante Muestreo y No Al 100%, ¿Por Qué?Daniel Gonzales Zayas100% (1)
- Ejercicios - Taller - Parcial 1 - DEDocumento14 páginasEjercicios - Taller - Parcial 1 - DELuis Felipe Mera GrandasAinda não há avaliações
- Universidad Tecnológica de Honduras: Campus CholutecaDocumento11 páginasUniversidad Tecnológica de Honduras: Campus CholutecaErik CorralesAinda não há avaliações
- Ejercico1 2Documento1 páginaEjercico1 2Gabriel PilcoAinda não há avaliações
- Ejercicio 15Documento4 páginasEjercicio 15GUESS0% (1)
- Trabajo de Metodos EstadisticosDocumento3 páginasTrabajo de Metodos EstadisticosCcaccya Navarro Walber AdalidAinda não há avaliações
- Ejercicios 18 y 19.Documento4 páginasEjercicios 18 y 19.Juan ReyesAinda não há avaliações
- Anova TareaDocumento27 páginasAnova TareaCristina Merino Rojas75% (4)
- Estadistica Inferencial Parte 2Documento14 páginasEstadistica Inferencial Parte 2Daniela Pozo100% (1)
- ParcialDocumento2 páginasParcialAngelly Paola Rocha RivasAinda não há avaliações
- Cabezas OdtDocumento11 páginasCabezas OdtJoelAinda não há avaliações
- 12 y 15Documento4 páginas12 y 15Claudio Gerardo Cervera100% (1)
- Pruebas Verificación ModeloDocumento29 páginasPruebas Verificación ModeloTatiana GarayAinda não há avaliações
- Capitulo 2 32 - 37Documento4 páginasCapitulo 2 32 - 37Jonathán Pérez González67% (3)
- Resolucion Ejercicios I Taller Diseno deDocumento28 páginasResolucion Ejercicios I Taller Diseno deAndres VictorAinda não há avaliações
- 690214.DDE Ejercicio Prueba T PareadasDocumento8 páginas690214.DDE Ejercicio Prueba T PareadasmarianrmAinda não há avaliações
- Cuestionario 2 Análisis de ExperimentosDocumento6 páginasCuestionario 2 Análisis de ExperimentosAlexis GOAinda não há avaliações
- A II Ciencias Administrativas 07-01-12Documento79 páginasA II Ciencias Administrativas 07-01-12Andrea BlancoAinda não há avaliações
- Sesión 4. Errores de Datos Analiticos y Evaluación de Resultados 2Documento24 páginasSesión 4. Errores de Datos Analiticos y Evaluación de Resultados 2victor rojas cardenasAinda não há avaliações
- 03 Estadistica - TestDocumento75 páginas03 Estadistica - TestCristian LaraAinda não há avaliações
- 12 13 14Documento6 páginas12 13 14JavierAinda não há avaliações
- Proyecto Final BioestadisticaDocumento25 páginasProyecto Final BioestadisticaPaloma GutiérrezAinda não há avaliações
- ORGANIZACIÓNDocumento3 páginasORGANIZACIÓNJavierAinda não há avaliações
- ORGANIZACIÓNDocumento3 páginasORGANIZACIÓNJavierAinda não há avaliações
- GrafcetDocumento19 páginasGrafcetAndrés MercadoAinda não há avaliações
- Organigrama y DOPDocumento3 páginasOrganigrama y DOPJavierAinda não há avaliações
- TESIS Propuesta para El Mejoramiento de Los Procesos Productivos de La Empresa SERVIOPTICA PDFDocumento116 páginasTESIS Propuesta para El Mejoramiento de Los Procesos Productivos de La Empresa SERVIOPTICA PDFDonek SantanderAinda não há avaliações
- Punto III y IV - Gestión PúblicaDocumento13 páginasPunto III y IV - Gestión PúblicaJavierAinda não há avaliações
- EmbutidoDocumento7 páginasEmbutidoJavier100% (1)
- 12 13 14Documento6 páginas12 13 14JavierAinda não há avaliações
- Machinarĭus) Al Conjunto de MáquinasDocumento1 páginaMachinarĭus) Al Conjunto de MáquinasJavierAinda não há avaliações
- TornoDocumento3 páginasTornoJavierAinda não há avaliações
- Proced I Mien ToDocumento9 páginasProced I Mien ToJavierAinda não há avaliações
- Cualquier DocumentoDocumento1 páginaCualquier DocumentoJavierAinda não há avaliações
- Cualquier DocumentoDocumento1 páginaCualquier DocumentoJavierAinda não há avaliações
- 2do Seminario Virtual 2020-2Documento4 páginas2do Seminario Virtual 2020-2Kevin JaldinAinda não há avaliações
- Ejemplo Semana 4 ParcialDocumento10 páginasEjemplo Semana 4 ParcialdayarucaAinda não há avaliações
- Prueba de hipótesis para la media poblacionalDocumento42 páginasPrueba de hipótesis para la media poblacionalBarrantes Gómez Pamela BarbaritaAinda não há avaliações
- Configuracion ElectronicaDocumento21 páginasConfiguracion ElectronicaPaty JamaicaAinda não há avaliações
- Esperanza MatemáticaDocumento3 páginasEsperanza Matemáticanilson mesias torres julianAinda não há avaliações
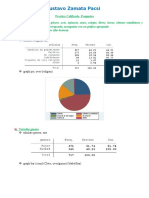
- Practica Calificada - Gilmer Gustavo Zamata PacsiDocumento12 páginasPractica Calificada - Gilmer Gustavo Zamata PacsiGilmer Gustavo EzamAinda não há avaliações
- EconometríaDocumento20 páginasEconometríaKevin Christian Quenaya AlferezAinda não há avaliações
- Teoría conflicto socialDocumento2 páginasTeoría conflicto socialAndrea CASTRO CORTESAinda não há avaliações
- Educación y Estructural-FuncionalismoDocumento3 páginasEducación y Estructural-Funcionalismogatogobolino100% (10)
- Apuntes Estadistica AplicadaDocumento12 páginasApuntes Estadistica AplicadaIvan GomezAinda não há avaliações
- Modelo Atómico de Sommerfeld CDDocumento7 páginasModelo Atómico de Sommerfeld CDCaro GutierrezAinda não há avaliações
- 02 Variables Aleatorias y Distribuciones de ProbabilidadDocumento68 páginas02 Variables Aleatorias y Distribuciones de ProbabilidadOmar Alvarado CorteganaAinda não há avaliações
- Problemas Estadísticos de Dos PoblacionesDocumento11 páginasProblemas Estadísticos de Dos PoblacionesMiguel_gtAinda não há avaliações
- Deber BioestadisticaDocumento18 páginasDeber BioestadisticaEmily Camila Cordova CoralAinda não há avaliações
- 5 Ejercicios de Chi CuadradoDocumento13 páginas5 Ejercicios de Chi CuadradoDavid SiguenzaAinda não há avaliações
- Modelo Atomico ActualDocumento18 páginasModelo Atomico ActualDiegoAinda não há avaliações
- Distribuciones Discretas de ProbabilidadDocumento2 páginasDistribuciones Discretas de ProbabilidadRaul MelchorAinda não há avaliações
- Aumento ventas bolsas brócoliDocumento17 páginasAumento ventas bolsas brócoliPaula Alejandra Tobacía HuertasAinda não há avaliações
- Analisis de Datos: ACTIVIDAD 1: Ejercicios Fecha de Entrega: 14 de Noviembre Del 2022Documento10 páginasAnalisis de Datos: ACTIVIDAD 1: Ejercicios Fecha de Entrega: 14 de Noviembre Del 2022eduard luaAinda não há avaliações
- CalculoProbErrorTipoIIDocumento9 páginasCalculoProbErrorTipoIICarolina GiraldoAinda não há avaliações
- Prueba de HipotesisDocumento33 páginasPrueba de HipotesisVla Mor MarAinda não há avaliações
- Problemas Resueltos de EstadisticaDocumento10 páginasProblemas Resueltos de Estadisticaalvacar5390% (1)
- Técnicas de Procesamiento y Análisis de Datos La Investigación CientíficaDocumento17 páginasTécnicas de Procesamiento y Análisis de Datos La Investigación CientíficaJuan SMAinda não há avaliações
- Ejercicio 2Documento30 páginasEjercicio 2andrea davila alvarezAinda não há avaliações
- Ejemplo 4.4:: Solución: Por El Teorema 4.1, El Operador Puede Esperar RecibirDocumento1 páginaEjemplo 4.4:: Solución: Por El Teorema 4.1, El Operador Puede Esperar Recibirhernan ccorimanya sopantaAinda não há avaliações
- Ejercicios de Ji-Cuadrada Como Prueba de Independencia y Bondad de Ajuste. I 2021Documento7 páginasEjercicios de Ji-Cuadrada Como Prueba de Independencia y Bondad de Ajuste. I 2021Walter SalinasAinda não há avaliações
- Formulario ProbDocumento49 páginasFormulario ProbMonica SAinda não há avaliações
- Albert - No Localidad - IYC0509 - 014Documento8 páginasAlbert - No Localidad - IYC0509 - 014Pherj-jhane CortesAinda não há avaliações
- Estadística I - Guía #2 del tercer parcialDocumento16 páginasEstadística I - Guía #2 del tercer parcialPablo LopezAinda não há avaliações
- Niveles de SignificanciaDocumento10 páginasNiveles de SignificanciaMARIO MANUEL JIMÈNEZ GARCÌAAinda não há avaliações