Você também pode gostar
- Operaciones Entre Conjuntos y Zonas RayadasDocumento2 páginasOperaciones Entre Conjuntos y Zonas RayadasGuillermo Geovanny Lozada Pinta100% (1)
- Preguntas Autónomo 1Documento3 páginasPreguntas Autónomo 1Vanessa GuillenAinda não há avaliações
- Explicación Ley de HookeDocumento2 páginasExplicación Ley de HookeXimena Acosta MesaAinda não há avaliações
- SEPARATA 1-Estadistica Descriptiva-2018Documento48 páginasSEPARATA 1-Estadistica Descriptiva-2018enrique100% (1)
- Ficha 2do Física Semana 04Documento6 páginasFicha 2do Física Semana 04Jonathan DiazAinda não há avaliações
- Quién Encontró Los Cráneos de Paltacalo y en Qué Provincia Del EcuadorDocumento12 páginasQuién Encontró Los Cráneos de Paltacalo y en Qué Provincia Del EcuadorWendy GarciaAinda não há avaliações
- Tarea Unidad 4 FisicaDocumento1 páginaTarea Unidad 4 FisicaVerónica GarcíaAinda não há avaliações
- Taller EstequiometriaDocumento1 páginaTaller EstequiometriaAdrian Guevara PerezAinda não há avaliações
- Progresiones y Sucesiones Aritméticas y GeométricasDocumento60 páginasProgresiones y Sucesiones Aritméticas y GeométricasAntonio Danilo Mendoza CabreraAinda não há avaliações
- BI - ProgresionesDocumento13 páginasBI - Progresionesagarci28Ainda não há avaliações
- 18.5. Atmósferas Planetarias. (A) Calcule La Densidad de LaDocumento3 páginas18.5. Atmósferas Planetarias. (A) Calcule La Densidad de LaPaola Castro ValenzuelaAinda não há avaliações
- Deber 1 - LógicaDocumento5 páginasDeber 1 - LógicajcakbocAinda não há avaliações
- AlgoritmosDocumento74 páginasAlgoritmosJuan Andres PabonAinda não há avaliações
- 5.3-Solicitud Retiro de Asignaturas Caso FortuitoDocumento1 página5.3-Solicitud Retiro de Asignaturas Caso FortuitoSebas PerezAinda não há avaliações
- Trabajo de Cálculo - Aplicacion de La DerivadaDocumento38 páginasTrabajo de Cálculo - Aplicacion de La DerivadaDavid AtalayaAinda não há avaliações
- Metodologia - Problema 11 1Documento2 páginasMetodologia - Problema 11 1karyn15Ainda não há avaliações
- Arreglo SDocumento5 páginasArreglo SmarylujanoAinda não há avaliações
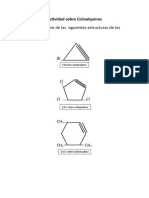
- CICLOALQUINOSDocumento2 páginasCICLOALQUINOSChelsy Andrea100% (1)
- Ejercicio 40 CalvacheDocumento2 páginasEjercicio 40 CalvacheNando Guaman100% (1)
- Ejercicios de Regla de TresDocumento1 páginaEjercicios de Regla de Tresevelyn chicaizaAinda não há avaliações
- EJERCICIO 3 AlcanosDocumento2 páginasEJERCICIO 3 AlcanosyuriAinda não há avaliações
- Taller - 7 Cargas - Fuerzas y Campos EléctricoDocumento2 páginasTaller - 7 Cargas - Fuerzas y Campos EléctricoMilton Duque Cano0% (1)
- El Brazo Hidraulico EjercicioDocumento1 páginaEl Brazo Hidraulico EjercicioFernando HerediaAinda não há avaliações
- Ejercicio 6Documento4 páginasEjercicio 6SILVIOCUMBALAinda não há avaliações
- Conjuntos Sebastian LazoDocumento33 páginasConjuntos Sebastian LazoUn limónAinda não há avaliações
- EeeeeeDocumento6 páginasEeeeeeSergio Miguel PSAinda não há avaliações
- Unidad 2 - Cinematica Unidimensional y Bidimensional de La Particula Pag 19 - 51Documento33 páginasUnidad 2 - Cinematica Unidimensional y Bidimensional de La Particula Pag 19 - 51paukAinda não há avaliações
- EVALUACIÓN FEM y POTENCIA ELECTRICA 13 DE MAYO 2021Documento3 páginasEVALUACIÓN FEM y POTENCIA ELECTRICA 13 DE MAYO 2021Toño PerafanAinda não há avaliações
- Cinemática 2Documento28 páginasCinemática 2Yahveh VehuiahAinda não há avaliações
- Consulta de Matrices IndividualDocumento5 páginasConsulta de Matrices IndividualCalderon QuezadaAinda não há avaliações
- Fisica Cap 02Documento25 páginasFisica Cap 02Victor Altamirano Muñoz0% (2)
- Taller de ConjuntosDocumento25 páginasTaller de ConjuntospepeAinda não há avaliações
- Encinas ZM PDFDocumento163 páginasEncinas ZM PDFEmerson Aly Ramirez SarmientoAinda não há avaliações
- Ejemplos ArrayDocumento30 páginasEjemplos ArrayZamoOritaRamirezOmarciitoAinda não há avaliações
- Angulo Entre Dos CurvasDocumento8 páginasAngulo Entre Dos CurvasSebastian RamosAinda não há avaliações
- Ejemplos de Cálculos de Distancias Con Números ComplejosDocumento2 páginasEjemplos de Cálculos de Distancias Con Números ComplejosErika MedinnaAinda não há avaliações
- LM03 - Relaciones LógicasDocumento20 páginasLM03 - Relaciones Lógicasiris cajasAinda não há avaliações
- Libreria Math y StringDocumento4 páginasLibreria Math y StringIvan PesantezAinda não há avaliações
- Trabajo Autonomo de Libro de TermodinamicaDocumento19 páginasTrabajo Autonomo de Libro de TermodinamicaCARLOS MANUEL BONES ORTEGAAinda não há avaliações
- Ecuaciones Diferenciales de Variables Ordinarias Con DeriveDocumento5 páginasEcuaciones Diferenciales de Variables Ordinarias Con DeriveClaudio AldanaAinda não há avaliações
- Sistema Nervioso Central y Sistema Nervioso PeriféricoDocumento3 páginasSistema Nervioso Central y Sistema Nervioso PeriféricoDayling JaramilloAinda não há avaliações
- 3 Ejercicios de Equilibrio de Una Particula 2DDocumento3 páginas3 Ejercicios de Equilibrio de Una Particula 2DVivian RodríguezAinda não há avaliações
- Laboratorio N 5Documento7 páginasLaboratorio N 5AliCiaAinda não há avaliações
- Fisica Parte 1 Ejercicios 9-15Documento5 páginasFisica Parte 1 Ejercicios 9-15Ian MateoAinda não há avaliações
- Clase 8 - McuDocumento3 páginasClase 8 - McuDiego JimenezAinda não há avaliações
- S11.s2 Poner en Práctica CAF1Documento1 páginaS11.s2 Poner en Práctica CAF1Maria Fernanda VMAinda não há avaliações
- Listado4calculoiii PDFDocumento2 páginasListado4calculoiii PDFKarla GuerreroAinda não há avaliações
- Guia1 (Segundoperiodo) Mruaparte2Documento2 páginasGuia1 (Segundoperiodo) Mruaparte2carolina pava0% (1)
- Guion Sucesiones Con RespDocumento7 páginasGuion Sucesiones Con RespRosa Isela Santillan RaveloAinda não há avaliações
- Maquina Estado FinitoDocumento10 páginasMaquina Estado FinitoAleksis HavjersAinda não há avaliações
- Quimica General Examen EPNDocumento6 páginasQuimica General Examen EPNdavincidatariAinda não há avaliações
- MCU y EstaticaDocumento2 páginasMCU y EstaticaMarco Cabrejos Yarleque100% (10)
- Algoritmo 091027154146 Phpapp02Documento88 páginasAlgoritmo 091027154146 Phpapp02Pool Ankori QuilcaAinda não há avaliações
- Taller Matematicas FinancieraDocumento3 páginasTaller Matematicas FinancieraMöniKalexa Caicedo BenavidsAinda não há avaliações
- Taller Física OndasDocumento7 páginasTaller Física OndasMelissa VargasAinda não há avaliações
- Tema 3 Sistemas de Coordenadas LinealesDocumento21 páginasTema 3 Sistemas de Coordenadas LinealesCristopher Jimenez JaramilloAinda não há avaliações
- Informe-6 Implementacion de Algoritmos en PseintDocumento7 páginasInforme-6 Implementacion de Algoritmos en PseintMajitoRodriguezAinda não há avaliações
- Problemas de Calculo (Listo)Documento5 páginasProblemas de Calculo (Listo)Nori Fuentes MezaAinda não há avaliações
- Codigo Fuente de Analisis Matricial de Porticos en PythonDocumento32 páginasCodigo Fuente de Analisis Matricial de Porticos en PythonAlex Huaraca YuyaliAinda não há avaliações
- Sustitutorio MB545 2020 IDocumento6 páginasSustitutorio MB545 2020 ILeo CTAinda não há avaliações
- Proyectos PROLOGDocumento3 páginasProyectos PROLOGtuAinda não há avaliações
- Lambda PDFDocumento34 páginasLambda PDFtuAinda não há avaliações
- Practica PrologDocumento5 páginasPractica PrologtuAinda não há avaliações
- Lambda PDFDocumento34 páginasLambda PDFtuAinda não há avaliações
- S7-300 Profibus PracticaDocumento43 páginasS7-300 Profibus PracticaEspinoza EstebanAinda não há avaliações
- SD Trabajo 1Documento17 páginasSD Trabajo 1sebastian herediaAinda não há avaliações
- Compiladores ParalelosDocumento4 páginasCompiladores ParalelosDavid MoralesAinda não há avaliações
- Libro La ComputadoraDocumento419 páginasLibro La ComputadoraAlan Rafael GaribayAinda não há avaliações
- Arquitectura SMP, MPP, SPPDocumento4 páginasArquitectura SMP, MPP, SPPZuzan PeñaAinda não há avaliações
- Pasaje de Mensajes y Algoritmos ParalelosDocumento10 páginasPasaje de Mensajes y Algoritmos ParalelosValeria HernandezAinda não há avaliações
- Procesamiento ParaleloDocumento35 páginasProcesamiento ParaleloJEFFERSON MUÑOZ PARDOAinda não há avaliações
- Big Data y Algoritmos Genéticos Distribuidos en El Aprendizaje de Reglas de ClasificaciónDocumento11 páginasBig Data y Algoritmos Genéticos Distribuidos en El Aprendizaje de Reglas de ClasificaciónDanielaAinda não há avaliações
- Algoritmos Paralelos para La Multiplicación de MatricesDocumento14 páginasAlgoritmos Paralelos para La Multiplicación de MatricesAlonso TenorioAinda não há avaliações
- LAB01 - Red MPIDocumento10 páginasLAB01 - Red MPIjesusAinda não há avaliações
- Bloques SFCDocumento17 páginasBloques SFCMaricela Guadalupe Donjuán EspinozaAinda não há avaliações
- Unuidad III EjerciciosDocumento22 páginasUnuidad III EjerciciosCaryulyt RosalesbAinda não há avaliações
- Mbeepr MPXH MpiDocumento2 páginasMbeepr MPXH MpiEzequiel CoronesAinda não há avaliações
- Faqs para La Redundancia Software Con Plcs de SiemensDocumento14 páginasFaqs para La Redundancia Software Con Plcs de SiemensFernandoJoseRomeroAinda não há avaliações
- PelicanHPC - Una Distribución de Clúster de Linux para Informática Paralela Basada en MPIDocumento5 páginasPelicanHPC - Una Distribución de Clúster de Linux para Informática Paralela Basada en MPIIvan Elias Carrasco LupintaAinda não há avaliações
- Guia 8 PLC Discreto Diagnostico S7 300Documento15 páginasGuia 8 PLC Discreto Diagnostico S7 300rihana rodriguez garciaAinda não há avaliações
- Mpi Com20 MPXHDocumento56 páginasMpi Com20 MPXHewaigeAinda não há avaliações
- Actas JCC&BD 2018.pdf-PDFA PDFDocumento164 páginasActas JCC&BD 2018.pdf-PDFA PDFcarolina vargasAinda não há avaliações
- IyCnet Siemens Protool 01 Primeros PasosDocumento42 páginasIyCnet Siemens Protool 01 Primeros PasosRaul Guevara TorresAinda não há avaliações
- infoPLC - Net - Configuracic3b3n y Puesta en Marcha de Una Red Mpi PDFDocumento15 páginasinfoPLC - Net - Configuracic3b3n y Puesta en Marcha de Una Red Mpi PDFSergio Mudarra ChavezAinda não há avaliações
- CPU-Daten SDocumento148 páginasCPU-Daten SLeyner RamyrezAinda não há avaliações
- Computación ParalelaDocumento57 páginasComputación ParalelaJuan NietoAinda não há avaliações
- Mpi 1 PDFDocumento19 páginasMpi 1 PDFAquiles Andy Cacho RicoAinda não há avaliações
- Tipos de Comunicacion de Sistemas Distribuidos 1Documento45 páginasTipos de Comunicacion de Sistemas Distribuidos 1Jhoan Alexis Bustamante Santos100% (1)
- Pract 1Documento4 páginasPract 1Cristian Bueno GonzálezAinda não há avaliações
- Semana 1 Parallel Clase 1 VisionglobaldelcursoDocumento14 páginasSemana 1 Parallel Clase 1 VisionglobaldelcursoALVARO HENRY MAMANI ALIAGAAinda não há avaliações
- STEP 7 - de S5 A S7Documento152 páginasSTEP 7 - de S5 A S7humbertocanales_chAinda não há avaliações
- Cluster HPC LinuxDocumento89 páginasCluster HPC LinuxDavid GRAinda não há avaliações
- Entrega 3 Sistemas DistribuidosDocumento9 páginasEntrega 3 Sistemas DistribuidosOrlando Alcala Vargas100% (1)
- Topología de Redes IndustrialesDocumento35 páginasTopología de Redes IndustrialesNestor Gutierrez67% (3)