Você também pode gostar
- Understanding Machine LearningDocumento416 páginasUnderstanding Machine Learningdeepakdodo100% (60)
- Machine Learning AlgorithmsDocumento353 páginasMachine Learning AlgorithmsAditya Aggarwal100% (34)
- Machine Learning Absolute Beginners Introduction 2ndDocumento128 páginasMachine Learning Absolute Beginners Introduction 2ndud90% (62)
- Mathematics For Machine LearningDocumento417 páginasMathematics For Machine LearningLê Mạnh93% (29)
- Machine Learning For HumansDocumento97 páginasMachine Learning For Humansaakash30jan100% (2)
- TensorFlow in 1 Day: Make your own Neural NetworkNo EverandTensorFlow in 1 Day: Make your own Neural NetworkNota: 4 de 5 estrelas4/5 (8)
- Deep Learning With PyTorch (Packt) - 2018 262pDocumento255 páginasDeep Learning With PyTorch (Packt) - 2018 262palex torres100% (12)
- Tensorflow 2 Tutorial PDFDocumento66 páginasTensorflow 2 Tutorial PDFVuk Krepusco100% (2)
- ML Basics 02 (Statistics)Documento438 páginasML Basics 02 (Statistics)Rishabh chaudhary100% (6)
- Machine Learning ParadigmsDocumento336 páginasMachine Learning ParadigmsBac Bia100% (3)
- Python Deep Learning Cookbook - Indra Den BakkerDocumento439 páginasPython Deep Learning Cookbook - Indra Den BakkerWilmer Moncada95% (20)
- The Nervous System MCQ'sDocumento6 páginasThe Nervous System MCQ'sTahir Aziz100% (4)
- Nerve RegenerationDocumento2 páginasNerve RegenerationHajar BakiAinda não há avaliações
- Machine Learning Projects in PythonDocumento135 páginasMachine Learning Projects in Pythonsin som100% (6)
- Handbook of Practical NeurophysiotherapyDocumento379 páginasHandbook of Practical NeurophysiotherapyAlbert Manimtim100% (2)
- Practical Machine Learning - Sample ChapterDocumento46 páginasPractical Machine Learning - Sample ChapterPackt Publishing82% (17)
- Machine Learning MasterclassDocumento108 páginasMachine Learning MasterclassOlivier De Ridder100% (6)
- Deep Learning in Natural Language Processing PDFDocumento338 páginasDeep Learning in Natural Language Processing PDF大谷昭成100% (3)
- Deep LearningDocumento540 páginasDeep Learningnidar94% (31)
- Mathematics For Machine LearningDocumento248 páginasMathematics For Machine Learningub3rn3o100% (4)
- Physiology of PainDocumento25 páginasPhysiology of PainAsim NawazAinda não há avaliações
- Algorithms and Architectures of Artificial IntelligenceDocumento185 páginasAlgorithms and Architectures of Artificial IntelligenceEnrique Guillén Álvarez100% (2)
- Machine Learning: Adaptive Behaviour Through Experience: Thinking MachinesNo EverandMachine Learning: Adaptive Behaviour Through Experience: Thinking MachinesNota: 4.5 de 5 estrelas4.5/5 (5)
- Deep Learning by Example - Ahmed MenshawyDocumento442 páginasDeep Learning by Example - Ahmed MenshawySharaf Hussain100% (6)
- 9781838640859-Deep Learning For BeginnersDocumento416 páginas9781838640859-Deep Learning For Beginnerssanti100% (6)
- Interpretable Machine Learning PDFDocumento251 páginasInterpretable Machine Learning PDFAxel Straminsky100% (1)
- TensorFlow 1.x Deep Learning Cookbook - Over 90 Unique Recipes To Solve Artificial-Intelligence Driven Problems With PythonDocumento526 páginasTensorFlow 1.x Deep Learning Cookbook - Over 90 Unique Recipes To Solve Artificial-Intelligence Driven Problems With PythonArun A S PillaiAinda não há avaliações
- Deep Learning with TensorFlow 2 and Keras - Second Edition: Regression, ConvNets, GANs, RNNs, NLP, and more with TensorFlow 2 and the Keras API, 2nd EditionNo EverandDeep Learning with TensorFlow 2 and Keras - Second Edition: Regression, ConvNets, GANs, RNNs, NLP, and more with TensorFlow 2 and the Keras API, 2nd EditionAinda não há avaliações
- Machine Learning with Clustering: A Visual Guide for Beginners with Examples in PythonNo EverandMachine Learning with Clustering: A Visual Guide for Beginners with Examples in PythonAinda não há avaliações
- Artificial Neural Networks: System That Can Acquire, Store, and Utilize Experiential KnowledgeDocumento40 páginasArtificial Neural Networks: System That Can Acquire, Store, and Utilize Experiential KnowledgeKiran Moy Mandal100% (1)
- Artificial Neural Network - ..Documento15 páginasArtificial Neural Network - ..Nidhish G100% (1)
- Principle of Animal Physiology (Christopher D. Moyes, Patricia Schulte) Principle ofDocumento763 páginasPrinciple of Animal Physiology (Christopher D. Moyes, Patricia Schulte) Principle ofKing Amv88% (8)
- Therapeutic Exercise NotesDocumento110 páginasTherapeutic Exercise Notesnmahpbooks82% (17)
- Introduction To TensorflowDocumento87 páginasIntroduction To TensorflowGomathivinayagam Muthuvinayagam100% (4)
- The Nervous SystemDocumento39 páginasThe Nervous SystemReizel Mae Noel Laurente100% (1)
- TensorFlow For Machine IntelligenceDocumento305 páginasTensorFlow For Machine IntelligenceManash Mandal100% (24)
- Andriy Burkov - The Hundred-Page Machine Learning Book (2019, Andriy Burkov) PDFDocumento152 páginasAndriy Burkov - The Hundred-Page Machine Learning Book (2019, Andriy Burkov) PDFmuradagasiyev100% (2)
- Neural Networks From Scratch in PythonDocumento658 páginasNeural Networks From Scratch in PythonZé Felipe100% (2)
- Neural Networks: An Essential Beginners Guide to Artificial Neural Networks and their Role in Machine Learning and Artificial IntelligenceNo EverandNeural Networks: An Essential Beginners Guide to Artificial Neural Networks and their Role in Machine Learning and Artificial IntelligenceAinda não há avaliações
- Deep Learning - Fundamentals, Theory and Applications 2019 PDFDocumento168 páginasDeep Learning - Fundamentals, Theory and Applications 2019 PDFismake31100% (2)
- Deep Learning With Python Illustrated Guide For Beginners & Intermediates: The Future Is Here!: The Future Is Here!, #2No EverandDeep Learning With Python Illustrated Guide For Beginners & Intermediates: The Future Is Here!: The Future Is Here!, #2Nota: 1 de 5 estrelas1/5 (1)
- MML Book 2 PDFDocumento421 páginasMML Book 2 PDFAndrés Torres Rivera100% (2)
- Neural Networks: A Practical Guide for Understanding and Programming Neural Networks and Useful Insights for Inspiring ReinventionNo EverandNeural Networks: A Practical Guide for Understanding and Programming Neural Networks and Useful Insights for Inspiring ReinventionAinda não há avaliações
- Neural NetworksDocumento26 páginasNeural NetworksphreedomAinda não há avaliações
- Deep Learning With PyTorch Guide For Beginners and IntermediateDocumento120 páginasDeep Learning With PyTorch Guide For Beginners and Intermediatedvsd100% (3)
- Nervous System CompleteDocumento21 páginasNervous System CompleteChris Deinielle Marcoleta SumaoangAinda não há avaliações
- 9781788293594-Tensorflow 1X Deep Learning Cookbook PDFDocumento526 páginas9781788293594-Tensorflow 1X Deep Learning Cookbook PDFfuzzy_slugAinda não há avaliações
- Nature Inspired Algorithms Big Data FrameworksDocumento436 páginasNature Inspired Algorithms Big Data FrameworksHolaq Ola OlaAinda não há avaliações
- Hands-On Deep Learning Algorithms with Python: Master deep learning algorithms with extensive math by implementing them using TensorFlowNo EverandHands-On Deep Learning Algorithms with Python: Master deep learning algorithms with extensive math by implementing them using TensorFlowAinda não há avaliações
- Trends - 2125Documento41 páginasTrends - 2125Justin Rafael Rodrigo93% (14)
- Machine LearningDocumento135 páginasMachine LearningBlack Sat100% (2)
- Neural Networks and Genome InformaticsNo EverandNeural Networks and Genome InformaticsNota: 4.5 de 5 estrelas4.5/5 (3)
- Advanced Deep Learning with Python: Design and implement advanced next-generation AI solutions using TensorFlow and PyTorchNo EverandAdvanced Deep Learning with Python: Design and implement advanced next-generation AI solutions using TensorFlow and PyTorchAinda não há avaliações
- 2015 Book AdvancedModelsOfNeuralNetworksDocumento296 páginas2015 Book AdvancedModelsOfNeuralNetworksXandre Dmitri Clementsmith100% (2)
- Zhiyuan L. Introduction To Graph Neural Networks 2020Documento129 páginasZhiyuan L. Introduction To Graph Neural Networks 2020naveen441Ainda não há avaliações
- Mastering Machine Learning Algorithms - Second Edition: Expert techniques for implementing popular machine learning algorithms, fine-tuning your models, and understanding how they work, 2nd EditionNo EverandMastering Machine Learning Algorithms - Second Edition: Expert techniques for implementing popular machine learning algorithms, fine-tuning your models, and understanding how they work, 2nd EditionAinda não há avaliações
- Tensorflow Machine Learning Complete Self-Assessment GuideNo EverandTensorflow Machine Learning Complete Self-Assessment GuideAinda não há avaliações
- Deep Learning for Computer Vision with SAS: An IntroductionNo EverandDeep Learning for Computer Vision with SAS: An IntroductionAinda não há avaliações
- Machine Reading Comprehension: Algorithms and PracticeNo EverandMachine Reading Comprehension: Algorithms and PracticeAinda não há avaliações
- State-of-the-Art Deep Learning Models in TensorFlow: Modern Machine Learning in the Google Colab EcosystemNo EverandState-of-the-Art Deep Learning Models in TensorFlow: Modern Machine Learning in the Google Colab EcosystemAinda não há avaliações
- ANNDocumento5 páginasANNSafi Ullah KhanAinda não há avaliações
- Pain Control TheoriesDocumento26 páginasPain Control TheoriesGwen AmoureAinda não há avaliações
- The Biology of The BrainDocumento34 páginasThe Biology of The BrainTakis VasilopoulosAinda não há avaliações
- Phyp211 - Week 1Documento3 páginasPhyp211 - Week 1KHRIZZA PAULETTE ANTIFORDA VEGAAinda não há avaliações
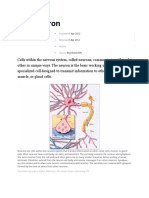
- The Neuron: Published Reviewed Author SourceDocumento10 páginasThe Neuron: Published Reviewed Author SourceJennie KimAinda não há avaliações
- Activity 2.2.2: The Secret To SignalsDocumento2 páginasActivity 2.2.2: The Secret To SignalsSelma SabriAinda não há avaliações
- Ncert Solution Cbse Class 10 Sci Chap 7Documento11 páginasNcert Solution Cbse Class 10 Sci Chap 7Sneegdha DubeyAinda não há avaliações
- Question Chapter 6 Cerebellum and Its ConnectionsDocumento13 páginasQuestion Chapter 6 Cerebellum and Its ConnectionsTrang BuiAinda não há avaliações
- 11 12 13 MergedDocumento150 páginas11 12 13 Mergedsrinaath092002Ainda não há avaliações
- Pain ManagementDocumento17 páginasPain Managementa bAinda não há avaliações
- Myelination: Paring BackDocumento1 páginaMyelination: Paring Backsaja143Ainda não há avaliações
- Neuromuscular Control SystemDocumento6 páginasNeuromuscular Control SystemNidhi SharmaAinda não há avaliações
- Artificial Neural Network: Introduction: Debasis Samanta (IIT Kharagpur)Documento19 páginasArtificial Neural Network: Introduction: Debasis Samanta (IIT Kharagpur)Farnain MattooAinda não há avaliações
- Aqa Byb4 W QP Jan08 PDFDocumento20 páginasAqa Byb4 W QP Jan08 PDFCindyVortexAinda não há avaliações
- Structure of NeuronsDocumento6 páginasStructure of NeuronsMusdiqJavedAinda não há avaliações
- SECA4002Documento65 páginasSECA4002SivaAinda não há avaliações
- Biological Basis of Behavior: Presented By: Dr. Saima ShaheenDocumento31 páginasBiological Basis of Behavior: Presented By: Dr. Saima ShaheenSana FatimaAinda não há avaliações
- Organ Systems Practice TestDocumento8 páginasOrgan Systems Practice TestChristine RomanillosAinda não há avaliações
- Science BiologyCompleteDocumento11 páginasScience BiologyCompleteJohanis Galaura EngcoAinda não há avaliações
- Allen CONTROL AND CO-ORDINATIONS IOQJSDocumento14 páginasAllen CONTROL AND CO-ORDINATIONS IOQJSAtharv Aggarwal100% (1)
- Mindmap Bio621 Chapter1Documento3 páginasMindmap Bio621 Chapter1MizahAinda não há avaliações
- Robbins Ch. 27 Peripheral Nerve and Skeletal Muscle Review QuestionsDocumento2 páginasRobbins Ch. 27 Peripheral Nerve and Skeletal Muscle Review QuestionsPA2014100% (1)