Você também pode gostar
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNo EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeNota: 4 de 5 estrelas4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)No EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Nota: 4 de 5 estrelas4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNo EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryNota: 3.5 de 5 estrelas3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNo EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceNota: 4 de 5 estrelas4/5 (895)
- The Little Book of Hygge: Danish Secrets to Happy LivingNo EverandThe Little Book of Hygge: Danish Secrets to Happy LivingNota: 3.5 de 5 estrelas3.5/5 (400)
- Never Split the Difference: Negotiating As If Your Life Depended On ItNo EverandNever Split the Difference: Negotiating As If Your Life Depended On ItNota: 4.5 de 5 estrelas4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNo EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureNota: 4.5 de 5 estrelas4.5/5 (474)
- The Emperor of All Maladies: A Biography of CancerNo EverandThe Emperor of All Maladies: A Biography of CancerNota: 4.5 de 5 estrelas4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnNo EverandTeam of Rivals: The Political Genius of Abraham LincolnNota: 4.5 de 5 estrelas4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNo EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaNota: 4.5 de 5 estrelas4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNo EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersNota: 4.5 de 5 estrelas4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyNo EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyNota: 3.5 de 5 estrelas3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNo EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreNota: 4 de 5 estrelas4/5 (1090)
- The Unwinding: An Inner History of the New AmericaNo EverandThe Unwinding: An Inner History of the New AmericaNota: 4 de 5 estrelas4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)No EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Nota: 4.5 de 5 estrelas4.5/5 (121)
- Check Disbursement4Documento24 páginasCheck Disbursement4Jeff Jeansen BagcatAinda não há avaliações
- Class 12 Project EcoDocumento18 páginasClass 12 Project EcoKunal GuptaAinda não há avaliações
- Planning and Economic DevelopmentDocumento9 páginasPlanning and Economic DevelopmentGurleen KaurAinda não há avaliações
- Haier CompanyDocumento11 páginasHaier CompanyPriyanka Kaveria0% (1)
- RVU Distribution - New ChangesDocumento5 páginasRVU Distribution - New Changesmy indiaAinda não há avaliações
- Legal Issues in RetailDocumento17 páginasLegal Issues in RetailArunoday Singh100% (5)
- Assignment 3 - Financial Case StudyDocumento1 páginaAssignment 3 - Financial Case StudySenura SeneviratneAinda não há avaliações
- Adm ANI 2005Documento15 páginasAdm ANI 2005Paul GalanAinda não há avaliações
- Liu Shaoqi - How To Be A Good CommunistDocumento2 páginasLiu Shaoqi - How To Be A Good CommunistAnonymous MWc2SnBb100% (1)
- Certificate of OriginDocumento2 páginasCertificate of Originvanessa30Ainda não há avaliações
- Paramount InvoiceDocumento4 páginasParamount InvoiceDipak KotkarAinda não há avaliações
- Boliden Kokkola Oy enDocumento31 páginasBoliden Kokkola Oy enjoescribd55Ainda não há avaliações
- Managerial. EcoDocumento15 páginasManagerial. EcomohitharlaniAinda não há avaliações
- RDO No. 32 - Quiapo-Sampaloc-San Miguel-Sta MesaDocumento713 páginasRDO No. 32 - Quiapo-Sampaloc-San Miguel-Sta MesaJasmin Regis Sy50% (6)
- Ikhlas P.A Permata Takaful Pds - Eng RevisedDocumento4 páginasIkhlas P.A Permata Takaful Pds - Eng RevisedShafiq HakimiAinda não há avaliações
- Singapore IncDocumento7 páginasSingapore IncGinanjarSaputraAinda não há avaliações
- Facts About FASBDocumento8 páginasFacts About FASBvssvaraprasadAinda não há avaliações
- Creative 12 Business MathsDocumento14 páginasCreative 12 Business MathsKrupali ChothaniAinda não há avaliações
- 1 Croucher S. L.. Globalization and Belonging: The Politics of Identity in A Changing World. Rowman & Littlefield. (2004) - p.10 1Documento10 páginas1 Croucher S. L.. Globalization and Belonging: The Politics of Identity in A Changing World. Rowman & Littlefield. (2004) - p.10 1Alina-Elena AstalusAinda não há avaliações
- Informe Semestral PDFDocumento164 páginasInforme Semestral PDFantoniotohotAinda não há avaliações
- 07 Opportunities For PoA in Energy Efficiency by Konrad Von RitterDocumento11 páginas07 Opportunities For PoA in Energy Efficiency by Konrad Von RitterThe Outer MarkerAinda não há avaliações
- Mitutoyo India, Mitutoyo Japan, Mitutoyo Bangalore, Mitutoyo Branches in India, Mitutoyo Global Branches, Mitutoyo Mumbai, Mitutoyo Delhi, Mitutoyo M3 Center, MitutoyoIndiaDocumento1 páginaMitutoyo India, Mitutoyo Japan, Mitutoyo Bangalore, Mitutoyo Branches in India, Mitutoyo Global Branches, Mitutoyo Mumbai, Mitutoyo Delhi, Mitutoyo M3 Center, MitutoyoIndiaRajan KumarAinda não há avaliações
- Airports in Cities and RegionsDocumento192 páginasAirports in Cities and RegionsMarlar Shwe100% (2)
- FM QuizDocumento3 páginasFM QuizSheila Mae AramanAinda não há avaliações
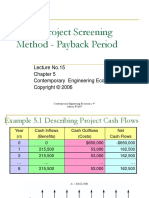
- Initial Project Screening Method - Payback Period: Lecture No.15 Contemporary Engineering EconomicsDocumento32 páginasInitial Project Screening Method - Payback Period: Lecture No.15 Contemporary Engineering EconomicsAfiq de WinnerAinda não há avaliações
- BHIM ABPB FAQsDocumento6 páginasBHIM ABPB FAQsLenovo Zuk z2plusAinda não há avaliações
- Jittipat Poonkham - Russia's Pivot To Asia: Visionary or Reactionary?Documento8 páginasJittipat Poonkham - Russia's Pivot To Asia: Visionary or Reactionary?Jittipat PoonkhamAinda não há avaliações
- 1592-Article Text-3929-1-10-20220401Documento8 páginas1592-Article Text-3929-1-10-20220401Rizqi SBSAinda não há avaliações
- Apm E170Documento130 páginasApm E170FigueiredoAinda não há avaliações
- Công nghệ Hybrid trên xe KIA Optima 2011Documento306 páginasCông nghệ Hybrid trên xe KIA Optima 2011auhut100% (3)