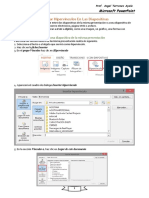
Você também pode gostar
- Eje 3 SGSI UltimoDocumento7 páginasEje 3 SGSI UltimoSodimac HomecenterAinda não há avaliações
- Prueba Excel IntermedioDocumento16 páginasPrueba Excel IntermedioYenny RiveraAinda não há avaliações
- Manual de HydraccesDocumento27 páginasManual de HydraccessusanAinda não há avaliações
- Control Semana7Documento9 páginasControl Semana7Joyas Mar Pau100% (1)
- Listas en JavaDocumento4 páginasListas en JavaJoyas Mar PauAinda não há avaliações
- Control4 Analisis Algoritmo IACCDocumento5 páginasControl4 Analisis Algoritmo IACCJoyas Mar PauAinda não há avaliações
- Imágenes en Documentos HTMLDocumento6 páginasImágenes en Documentos HTMLJoyas Mar PauAinda não há avaliações
- Formatos de Texto en HTMLDocumento6 páginasFormatos de Texto en HTMLJoyas Mar PauAinda não há avaliações
- Etapas Principales de La AuditoriaDocumento4 páginasEtapas Principales de La AuditoriaJoyas Mar PauAinda não há avaliações
- Hipervínculos, Links o Enlaces en HTMLDocumento6 páginasHipervínculos, Links o Enlaces en HTMLJoyas Mar PauAinda não há avaliações
- Características Del Sistema Operativo WindowsDocumento9 páginasCaracterísticas Del Sistema Operativo WindowsJoyas Mar PauAinda não há avaliações
- Fechas Con MySQLDocumento5 páginasFechas Con MySQLJoyas Mar PauAinda não há avaliações
- Funciones SQLDocumento15 páginasFunciones SQLJoyas Mar PauAinda não há avaliações
- Checklist para Auditoría de Seguridad InformaticaDocumento8 páginasChecklist para Auditoría de Seguridad InformaticaJoyas Mar PauAinda não há avaliações
- Consultas MultitablaDocumento6 páginasConsultas MultitablaJoyas Mar PauAinda não há avaliações
- 5615 PDFDocumento279 páginas5615 PDFJohanaAinda não há avaliações
- KSG1 U3 A2 EfraDocumento6 páginasKSG1 U3 A2 EfraEfra RinconAinda não há avaliações
- Manual Vegas Pro 17 (Español)Documento637 páginasManual Vegas Pro 17 (Español)Andrea100% (3)
- Modelos de FabricasDocumento9 páginasModelos de FabricasJuan Carlos Fiallos RodasAinda não há avaliações
- Linux - Leccion 5.1.6 Determinacion Tipo de ArchivosDocumento2 páginasLinux - Leccion 5.1.6 Determinacion Tipo de ArchivosSergio SanchezAinda não há avaliações
- Curvas Protección 3Documento3 páginasCurvas Protección 3Santiago Mejía RAinda não há avaliações
- Desarrollo de Soluciones de Movilidad en WM5y 6 y VS NETDocumento182 páginasDesarrollo de Soluciones de Movilidad en WM5y 6 y VS NETlroqcorAinda não há avaliações
- Reverse ShellDocumento17 páginasReverse ShellRbn NavarroAinda não há avaliações
- ISO DiferenciasDocumento2 páginasISO DiferenciasFrancisco Sampedro GilerAinda não há avaliações
- Taller de Tecnologia e Informatica 7-3Documento3 páginasTaller de Tecnologia e Informatica 7-3julian andres RodriguezAinda não há avaliações
- Instalacion Windows 10 - 2019 - VOL2 PDFDocumento4 páginasInstalacion Windows 10 - 2019 - VOL2 PDFWilson FernandezAinda não há avaliações
- Introduccion A La Tecnologia Digital Ii PDFDocumento5 páginasIntroduccion A La Tecnologia Digital Ii PDFCarlos PinedaAinda não há avaliações
- Instalación y Configuración de Postfix y SquirrelDocumento15 páginasInstalación y Configuración de Postfix y SquirrelnkmorenoAinda não há avaliações
- INSTALAR EL CUSTOM FIRMWARE (4.01 M33-2) RainFArtyDocumento16 páginasINSTALAR EL CUSTOM FIRMWARE (4.01 M33-2) RainFArtyNeowatch EvansAinda não há avaliações
- Tecnicas de FragmentacionDocumento8 páginasTecnicas de FragmentacionMelvin CusmeAinda não há avaliações
- 5e57f-Procedimiento de Actualizacion Konka-Kdl32kt627Documento3 páginas5e57f-Procedimiento de Actualizacion Konka-Kdl32kt627Oscar Rafael Ochoa MariñoAinda não há avaliações
- Power - HipervinculosDocumento4 páginasPower - HipervinculosMaster DavidtecAinda não há avaliações
- Trabajo de Base de Datos 3 PracticaDocumento11 páginasTrabajo de Base de Datos 3 Practicaeduardo luis cajaleon floresAinda não há avaliações
- Qué Es El Software Libre y Dónde Puedes EncontrarloDocumento4 páginasQué Es El Software Libre y Dónde Puedes EncontrarloLaura CamilaAinda não há avaliações
- Taller de Tablas en WordDocumento1 páginaTaller de Tablas en WordSaraVallejoAinda não há avaliações
- Mapa Conceptual Metricas Dario PeinadoDocumento1 páginaMapa Conceptual Metricas Dario PeinadoDariio Jose Guakneme MarquezAinda não há avaliações
- HOJA DE VIDA MilenaDocumento6 páginasHOJA DE VIDA MilenaCarina GarzonAinda não há avaliações
- Java BasicoDocumento141 páginasJava BasicoEduardo GarciaAinda não há avaliações
- UD4 UT8 Clase 4 Comandos Diagnostico RedesDocumento10 páginasUD4 UT8 Clase 4 Comandos Diagnostico RedesAntonio Fuster MonzoAinda não há avaliações
- Ksop - U2 - A1 - Elsr ComandosDocumento3 páginasKsop - U2 - A1 - Elsr ComandosELISARIAinda não há avaliações
- Sistemas Informacion TransaccionalDocumento24 páginasSistemas Informacion TransaccionalCarlos Colmenares AlcalaAinda não há avaliações
- Reporte de Investigaciónt - Tipos de Datos PLSQLDocumento10 páginasReporte de Investigaciónt - Tipos de Datos PLSQLdanallyAinda não há avaliações