Você também pode gostar
- Concise Guide to OTN optical transport networksNo EverandConcise Guide to OTN optical transport networksNota: 4 de 5 estrelas4/5 (2)
- Mikaeiljocn 9 11 984Documento11 páginasMikaeiljocn 9 11 984Pedro Henrique DauannyAinda não há avaliações
- IEEE ACCESS PaperDocumento13 páginasIEEE ACCESS PaperAbdullah HossainAinda não há avaliações
- Integrated Access Backhauled Networks: NtroductionDocumento5 páginasIntegrated Access Backhauled Networks: NtroductionRoshan RajuAinda não há avaliações
- REF - 102 - Fronthaul Evolution From CPRI To EthernetDocumento9 páginasREF - 102 - Fronthaul Evolution From CPRI To EthernetSourabh BAinda não há avaliações
- REF 197 Performance Evaluation of Mobile Front-Haul Employing Ethernet - Based TDM-PON With IQ Data Compression Invited PDFDocumento7 páginasREF 197 Performance Evaluation of Mobile Front-Haul Employing Ethernet - Based TDM-PON With IQ Data Compression Invited PDFSourabh BAinda não há avaliações
- 2016 - Study On Protocol and Required Bandwidth For 5G Mobile Fronthaul in C-RAN Architecture With MAC-PHY SplitDocumento5 páginas2016 - Study On Protocol and Required Bandwidth For 5G Mobile Fronthaul in C-RAN Architecture With MAC-PHY SplitArmando VargasAinda não há avaliações
- Next Generation 5G OFDM-Based Modulations For Intensity Modulation-Direct Detection (IM-DD) Optical FronthaulingDocumento5 páginasNext Generation 5G OFDM-Based Modulations For Intensity Modulation-Direct Detection (IM-DD) Optical FronthaulingTommy Asselin0% (1)
- A Survey of The Functional Splits Proposed For5g Mobile Crosshaul NetworksDocumento27 páginasA Survey of The Functional Splits Proposed For5g Mobile Crosshaul NetworksPaulo TadeuAinda não há avaliações
- A Pragmatic Industrial Road Map For Shifting The Existing Fronthaul From CPRI To 5G Compatible eCPRIDocumento6 páginasA Pragmatic Industrial Road Map For Shifting The Existing Fronthaul From CPRI To 5G Compatible eCPRISourabh BAinda não há avaliações
- 2 - Performance - Analysis - of - Fog-Based - Radio - Access - NetworksDocumento9 páginas2 - Performance - Analysis - of - Fog-Based - Radio - Access - NetworksElectro ElkoranyAinda não há avaliações
- Next Generation Ethernet Access Networks: GPON vs. Epon: T. Orphanoudakis, H.-C. Leligou, J. D. AngelopoulosDocumento5 páginasNext Generation Ethernet Access Networks: GPON vs. Epon: T. Orphanoudakis, H.-C. Leligou, J. D. AngelopoulosdamlopAinda não há avaliações
- Backhaul RequirementsDocumento25 páginasBackhaul RequirementsChetan BhatAinda não há avaliações
- Cloud RAN For Mobile Networks - A Technology OverviewDocumento25 páginasCloud RAN For Mobile Networks - A Technology OverviewIbtihej HamdiAinda não há avaliações
- Applied Sciences: Latency-Aware DU/CU Placement in Convergent Packet-Based 5G Fronthaul Transport NetworksDocumento21 páginasApplied Sciences: Latency-Aware DU/CU Placement in Convergent Packet-Based 5G Fronthaul Transport NetworksKyeong-gu JeongAinda não há avaliações
- Cloud RAN For Mobile Networks - A Technology OverviewDocumento25 páginasCloud RAN For Mobile Networks - A Technology OverviewTelco-Indonesia ParaKonTel RebornAinda não há avaliações
- Soft-Stacked PON For Soft C-RANDocumento9 páginasSoft-Stacked PON For Soft C-RANSiva Rama KrishnaAinda não há avaliações
- Isolation-Aware 5G RAN Slice Mapping Over WDMDocumento13 páginasIsolation-Aware 5G RAN Slice Mapping Over WDMvasikasAinda não há avaliações
- C RanDocumento10 páginasC RanFrensel PetronaAinda não há avaliações
- White Paper: 5G Ethernet X-HaulDocumento7 páginasWhite Paper: 5G Ethernet X-HaulSeema ChauhanAinda não há avaliações
- New Transport Network Architectures For 5G RAN PDFDocumento11 páginasNew Transport Network Architectures For 5G RAN PDFLambertchaoAinda não há avaliações
- Report ch3Documento13 páginasReport ch3raniatayel806960Ainda não há avaliações
- Ethernet PON (ePON) : Design and Analysis of An Optical Access NetworkDocumento25 páginasEthernet PON (ePON) : Design and Analysis of An Optical Access NetworkLý Tiểu LongAinda não há avaliações
- Net 2018 07 026Documento29 páginasNet 2018 07 026Chakri ChakradharAinda não há avaliações
- Steinar Ondm2018Documento6 páginasSteinar Ondm2018Ghallab AlsadehAinda não há avaliações
- WP Sync IP Mobile NetworksDocumento13 páginasWP Sync IP Mobile NetworksanushtaevAinda não há avaliações
- 2018 - Fronthaul Network Modeling and Dimensioning Meeting Ultra-Low Latency Requirements For 5GDocumento9 páginas2018 - Fronthaul Network Modeling and Dimensioning Meeting Ultra-Low Latency Requirements For 5GArmando VargasAinda não há avaliações
- OFC2017 5G JimZDocumento3 páginasOFC2017 5G JimZgreffeuille julienAinda não há avaliações
- Modulation Compression in Next Generation RAN Air Interface and Fronthaul Trade-OffsDocumento7 páginasModulation Compression in Next Generation RAN Air Interface and Fronthaul Trade-OffsMihia KassiAinda não há avaliações
- 2018 Garcia-Saavedra Infocom FluidranDocumento9 páginas2018 Garcia-Saavedra Infocom FluidranPhelipe Alves de SouzaAinda não há avaliações
- An XG-PON Module For The NS-3 Network Simulator: The Manual: (xw2, K.brown, CJS) @cs - Ucc.ie, (Jerome) @4c.ucc - IeDocumento51 páginasAn XG-PON Module For The NS-3 Network Simulator: The Manual: (xw2, K.brown, CJS) @cs - Ucc.ie, (Jerome) @4c.ucc - IeWISMAN MGAinda não há avaliações
- Fronthaul Evolution: From CPRI To Ethernet: Optical Fiber Technology August 2015Documento17 páginasFronthaul Evolution: From CPRI To Ethernet: Optical Fiber Technology August 2015Seema ChauhanAinda não há avaliações
- Cloud RAN For Mobile NetworksDocumento39 páginasCloud RAN For Mobile Networksremovable0% (1)
- NXT Generation CellularDocumento17 páginasNXT Generation Cellularreynaldo12Ainda não há avaliações
- Design, Implementation, and Evaluation of An XG-PON Module For ns-3 Network SimulatorDocumento15 páginasDesign, Implementation, and Evaluation of An XG-PON Module For ns-3 Network SimulatordwiaryantaAinda não há avaliações
- Towards Bandwidth-Efficient Ethernet-Based 5G Mobile Fronthaul NetworksDocumento19 páginasTowards Bandwidth-Efficient Ethernet-Based 5G Mobile Fronthaul NetworksHabib MohammedAinda não há avaliações
- Research Article: Prioritising Redundant Network Component For HOWBAN Survivability Using FMEADocumento14 páginasResearch Article: Prioritising Redundant Network Component For HOWBAN Survivability Using FMEAPhuong Trieu DinhAinda não há avaliações
- 5g-Ready Mobile Fronthaul: Key To Building The Best-In-Class 5G Transport InfrastructureDocumento7 páginas5g-Ready Mobile Fronthaul: Key To Building The Best-In-Class 5G Transport InfrastructurebaluvelpAinda não há avaliações
- Paper 1 - O-RAN-Minimum-DelayDocumento8 páginasPaper 1 - O-RAN-Minimum-DelayAna Caroline Silveira da PenhaAinda não há avaliações
- Removing The PDCCH Bottleneck and Enhancing The Capacity of 4G Massive MIMO SystemsDocumento8 páginasRemoving The PDCCH Bottleneck and Enhancing The Capacity of 4G Massive MIMO SystemsD Harish KumarAinda não há avaliações
- Publi-4995 1Documento7 páginasPubli-4995 1Mihia KassiAinda não há avaliações
- Applsci 09 02823 v2Documento17 páginasApplsci 09 02823 v2firmansAinda não há avaliações
- Optimization in Fronthaul and Backhaul Network For Cloud RAN (C-RAN) : Design and Deployment ChallengesDocumento7 páginasOptimization in Fronthaul and Backhaul Network For Cloud RAN (C-RAN) : Design and Deployment ChallengesAhmed MontaserAinda não há avaliações
- Evolution of UTRAN ArchitectureDocumento5 páginasEvolution of UTRAN ArchitectureAhmad FrazAinda não há avaliações
- System Architecture and Key Technologies For 5G Heterogeneous Cloud Radio Access NetworksDocumento20 páginasSystem Architecture and Key Technologies For 5G Heterogeneous Cloud Radio Access NetworksAli EsmaeilyAinda não há avaliações
- Nokia 4A0 240 Exam Mobile Services Practice Questions Document enDocumento6 páginasNokia 4A0 240 Exam Mobile Services Practice Questions Document enNo Bi TaAinda não há avaliações
- Modulation Compression in Next Generation RAN: Air Interface and Fronthaul Trade-OffsDocumento7 páginasModulation Compression in Next Generation RAN: Air Interface and Fronthaul Trade-Offsfalcon032Ainda não há avaliações
- A Data-Rate Adaptable Modem SolutionDocumento6 páginasA Data-Rate Adaptable Modem Solutionpayam79bAinda não há avaliações
- Himank 2019 J1Documento15 páginasHimank 2019 J1sayondeepAinda não há avaliações
- An Advanced Energy Efficient and High Performance Routing Protocol For MANET in 5GDocumento7 páginasAn Advanced Energy Efficient and High Performance Routing Protocol For MANET in 5GM MovAinda não há avaliações
- Commcores. Open-Ran RU. Part 1Documento6 páginasCommcores. Open-Ran RU. Part 1Pavel Schukin100% (1)
- 5G Transport Network Requirements, Architecture and Key TechnologiesDocumento27 páginas5G Transport Network Requirements, Architecture and Key TechnologiesFreedomAinda não há avaliações
- Design Considerations For Multihop Relay Broadband Wireless Mesh NetworksDocumento8 páginasDesign Considerations For Multihop Relay Broadband Wireless Mesh NetworksnavinrkAinda não há avaliações
- An Internet Infrastructure For Cellular CDMA Networks Using Mobile IPDocumento12 páginasAn Internet Infrastructure For Cellular CDMA Networks Using Mobile IPMilan Raj RanjitkarAinda não há avaliações
- I Jcs It 2016070167Documento4 páginasI Jcs It 2016070167Anup PandeyAinda não há avaliações
- 4G Planning Optimization PDFDocumento7 páginas4G Planning Optimization PDFOrlando MondlaneAinda não há avaliações
- Netework Architecture of 5G Mobile TechnologyDocumento21 páginasNetework Architecture of 5G Mobile Technologymadhunath0% (1)
- LTE Part IIDocumento3 páginasLTE Part IIThanh Nguyen VpAinda não há avaliações
- DSP Enabled Next Generation 50G TDM-PONDocumento8 páginasDSP Enabled Next Generation 50G TDM-PONElsaid SayedAhmedAinda não há avaliações
- Homework #3 - Solution1Documento13 páginasHomework #3 - Solution1shahroozAinda não há avaliações
- Assignment#04 Subject:: Renewable Energy SystemDocumento5 páginasAssignment#04 Subject:: Renewable Energy SystemshahroozAinda não há avaliações
- Question # 01: (CLO 1, PLO 12) Explain Employment Creation and Training Reference To Entrepreneurship & EconomicDocumento2 páginasQuestion # 01: (CLO 1, PLO 12) Explain Employment Creation and Training Reference To Entrepreneurship & EconomicshahroozAinda não há avaliações
- Assignment #02Documento1 páginaAssignment #02shahroozAinda não há avaliações
- Assignment 03Documento2 páginasAssignment 03shahrooz100% (1)
- 60W Load: Current ValuesDocumento4 páginas60W Load: Current ValuesshahroozAinda não há avaliações
- A Smoke Detector Is A Smoke Sensing Device That Indicates FireDocumento4 páginasA Smoke Detector Is A Smoke Sensing Device That Indicates FireshahroozAinda não há avaliações
- Individual Career Plan: DIRECTIONS: Answer The Following Questions in Paragraph Form (3-4 Sentences) Per QuestionDocumento2 páginasIndividual Career Plan: DIRECTIONS: Answer The Following Questions in Paragraph Form (3-4 Sentences) Per Questionapi-526813290Ainda não há avaliações
- Draft JV Agreement (La Mesa Gardens Condominiums - Amparo Property)Documento13 páginasDraft JV Agreement (La Mesa Gardens Condominiums - Amparo Property)Patrick PenachosAinda não há avaliações
- ZygalDocumento22 páginasZygalShubham KandiAinda não há avaliações
- Myanmar 1Documento3 páginasMyanmar 1Shenee Kate BalciaAinda não há avaliações
- TraceDocumento5 páginasTraceNorma TellezAinda não há avaliações
- Midi Pro Adapter ManualDocumento34 páginasMidi Pro Adapter ManualUli ZukowskiAinda não há avaliações
- Chapter 1Documento6 páginasChapter 1Grandmaster MeowAinda não há avaliações
- Predator U7135 ManualDocumento36 páginasPredator U7135 Manualr17g100% (1)
- Agency Canvas Ing PresentationDocumento27 páginasAgency Canvas Ing Presentationkhushi jaiswalAinda não há avaliações
- Native VLAN and Default VLANDocumento6 páginasNative VLAN and Default VLANAaliyah WinkyAinda não há avaliações
- EKRP311 Vc-Jun2022Documento3 páginasEKRP311 Vc-Jun2022dfmosesi78Ainda não há avaliações
- BSBITU314 Assessment Workbook FIllableDocumento51 páginasBSBITU314 Assessment Workbook FIllableAryan SinglaAinda não há avaliações
- Gomez-Acevedo 2010 Neotropical Mutualism Between Acacia and Pseudomyrmex Phylogeny and Divergence TimesDocumento16 páginasGomez-Acevedo 2010 Neotropical Mutualism Between Acacia and Pseudomyrmex Phylogeny and Divergence TimesTheChaoticFlameAinda não há avaliações
- Low Budget Music Promotion and PublicityDocumento41 páginasLow Budget Music Promotion and PublicityFola Folayan100% (3)
- Research 093502Documento8 páginasResearch 093502Chrlszjhon Sales SuguitanAinda não há avaliações
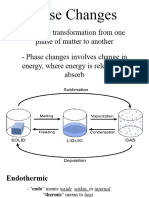
- General Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveDocumento19 páginasGeneral Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveJolo Allexice R. PinedaAinda não há avaliações
- ETAP Power Station ErrorDocumento5 páginasETAP Power Station ErroryogacruiseAinda não há avaliações
- A Hybrid Genetic-Neural Architecture For Stock Indexes ForecastingDocumento31 páginasA Hybrid Genetic-Neural Architecture For Stock Indexes ForecastingMaurizio IdiniAinda não há avaliações
- Regional Manager Business Development in Atlanta GA Resume Jay GriffithDocumento2 páginasRegional Manager Business Development in Atlanta GA Resume Jay GriffithJayGriffithAinda não há avaliações
- Epreuve Anglais EG@2022Documento12 páginasEpreuve Anglais EG@2022Tresor SokoudjouAinda não há avaliações
- P 348Documento196 páginasP 348a123456978Ainda não há avaliações
- PE MELCs Grade 3Documento4 páginasPE MELCs Grade 3MARISSA BERNALDOAinda não há avaliações
- Cam 18 Test 3 ListeningDocumento6 páginasCam 18 Test 3 ListeningKhắc Trung NguyễnAinda não há avaliações
- Editan - Living English (CD Book)Documento92 páginasEditan - Living English (CD Book)M Luthfi Al QodryAinda não há avaliações
- Codan Rubber Modern Cars Need Modern Hoses WebDocumento2 páginasCodan Rubber Modern Cars Need Modern Hoses WebYadiAinda não há avaliações
- Project Document EiDocumento66 páginasProject Document EiPrathap ReddyAinda não há avaliações
- Conservation Assignment 02Documento16 páginasConservation Assignment 02RAJU VENKATAAinda não há avaliações
- Implications of A Distributed Environment Part 2Documento38 páginasImplications of A Distributed Environment Part 2Joel wakhunguAinda não há avaliações
- 1916 South American Championship Squads - WikipediaDocumento6 páginas1916 South American Championship Squads - WikipediaCristian VillamayorAinda não há avaliações
- Data Asimilasi Untuk PemulaDocumento24 páginasData Asimilasi Untuk PemulaSii Olog-olog PlonkAinda não há avaliações