Você também pode gostar
- Inverse Trigonometric Functions (Trigonometry) Mathematics Question BankNo EverandInverse Trigonometric Functions (Trigonometry) Mathematics Question BankAinda não há avaliações
- Bisection Method (11 Files Merged)Documento52 páginasBisection Method (11 Files Merged)hammadqayyom006Ainda não há avaliações
- Math 2011-Introduction To Multivariable Calculus (Edited by Dr. Hon-Ming HO) Practice Exercises 10: Gradient Vectors and Directional DerivativesDocumento5 páginasMath 2011-Introduction To Multivariable Calculus (Edited by Dr. Hon-Ming HO) Practice Exercises 10: Gradient Vectors and Directional DerivativesKritiAinda não há avaliações
- Data Description: - Measures of Central Location - Measures of Variation - Measures of PositionDocumento30 páginasData Description: - Measures of Central Location - Measures of Variation - Measures of PositionGrace RoseteAinda não há avaliações
- Module 5 PDFDocumento17 páginasModule 5 PDFyoonginismAinda não há avaliações
- Ms 08Documento4 páginasMs 08kvrajan6Ainda não há avaliações
- Group 10 - Inclusion Exclusion-1Documento7 páginasGroup 10 - Inclusion Exclusion-1SafaAgritaAinda não há avaliações
- Math 320 Real Analysis I Midterm SolutionsDocumento10 páginasMath 320 Real Analysis I Midterm SolutionsmandilipAinda não há avaliações
- 11.test of SignificanceDocumento7 páginas11.test of SignificanceTasbir HasanAinda não há avaliações
- LAPLACE DEVELOPMENT OF DETERMINANTSDocumento10 páginasLAPLACE DEVELOPMENT OF DETERMINANTSNeil Carlo OcampoAinda não há avaliações
- Numericals ReviewerDocumento17 páginasNumericals ReviewerJeremy MacalaladAinda não há avaliações
- Week 1 Lesson For 4TH Q.Documento24 páginasWeek 1 Lesson For 4TH Q.Desiree Anne NerviolAinda não há avaliações
- Daniel Kenneth Villanueva: ProblemDocumento7 páginasDaniel Kenneth Villanueva: ProblemJBFPAinda não há avaliações
- Analysis With An Introduction To Proof 5Th Edition Lay Solutions Manual Full Chapter PDFDocumento35 páginasAnalysis With An Introduction To Proof 5Th Edition Lay Solutions Manual Full Chapter PDFmarcia.tays151100% (16)
- Exponentsexponents The Mathematicians ShorthandDocumento29 páginasExponentsexponents The Mathematicians ShorthandJhon Ryan AlmendarezAinda não há avaliações
- CH2. Locating Roots of Nonlinear EquationsDocumento17 páginasCH2. Locating Roots of Nonlinear Equationsbytebuilder25Ainda não há avaliações
- VectorDocumento3 páginasVectorsaiahabderazak02Ainda não há avaliações
- Chapter 4 DETERMINANT_6a672457-8acb-439c-9b30-2a69e08c3198Documento59 páginasChapter 4 DETERMINANT_6a672457-8acb-439c-9b30-2a69e08c3198Jasmine KaurAinda não há avaliações
- Circuits Module 03Documento19 páginasCircuits Module 03Glenn VirreyAinda não há avaliações
- GE 03.BM - .B.L June 2018 SolutionDocumento10 páginasGE 03.BM - .B.L June 2018 SolutionMd. Zakir HossainAinda não há avaliações
- 6_SlidesDocumento19 páginas6_Slidesxiaxiner8Ainda não há avaliações
- Mid-Term-Exam Sample Solutions S2 2020 PDFDocumento4 páginasMid-Term-Exam Sample Solutions S2 2020 PDFThuraga LikhithAinda não há avaliações
- M9 - Q1 W3 - Equations Transformable To Quadratic Equations PDFDocumento32 páginasM9 - Q1 W3 - Equations Transformable To Quadratic Equations PDFmark hernandezAinda não há avaliações
- Module5 Measures of Central Tendency Grouped Data Business 1Documento13 páginasModule5 Measures of Central Tendency Grouped Data Business 1Donna Mia CanlomAinda não há avaliações
- Module5 Measures of Central Tendency Grouped Data Business 1Documento13 páginasModule5 Measures of Central Tendency Grouped Data Business 1Donna Mia CanlomAinda não há avaliações
- Measures of PositionsadasDocumento11 páginasMeasures of PositionsadasBen Bash SarapuddinAinda não há avaliações
- Work 1Documento19 páginasWork 1Shiva ShankarAinda não há avaliações
- Analyzing Variance Using a Completely Randomized DesignDocumento10 páginasAnalyzing Variance Using a Completely Randomized DesignJevelyn Mendoza FarroAinda não há avaliações
- Analyzing vertical loads on building framesDocumento6 páginasAnalyzing vertical loads on building framesYena CabaluAinda não há avaliações
- Describing Data With Numerical Measures: Robability and TatisticsDocumento46 páginasDescribing Data With Numerical Measures: Robability and TatisticsVan TranAinda não há avaliações
- AnovaDocumento3 páginasAnovapawiiikaaaanAinda não há avaliações
- Lecture 9 & 10 (Preliminaries of Vectors)Documento11 páginasLecture 9 & 10 (Preliminaries of Vectors)Proshenjit BaruaAinda não há avaliações
- Solution Manual For Differential Equations and Linear Algebra 4Th Edition by Goode Isbn 0321964675 9780321964670 Full Chapter PDFDocumento36 páginasSolution Manual For Differential Equations and Linear Algebra 4Th Edition by Goode Isbn 0321964675 9780321964670 Full Chapter PDFsandra.montelongo651100% (12)
- Solution Manual For Differential Equations and Linear Algebra 4th Edition by Goode ISBN 0321964675 9780321964670Documento36 páginasSolution Manual For Differential Equations and Linear Algebra 4th Edition by Goode ISBN 0321964675 9780321964670jenniferwatersgbrcixdmzt100% (21)
- Calculus 1: ANTIDERIVATIVESDocumento40 páginasCalculus 1: ANTIDERIVATIVESMa Lorraine PerezAinda não há avaliações
- Unit XIV - Session 35Documento23 páginasUnit XIV - Session 35prasadAinda não há avaliações
- Calculate standard deviation for ungrouped dataDocumento8 páginasCalculate standard deviation for ungrouped dataDynna Marie VeraAinda não há avaliações
- Gauss-Seidel Iteration MethodDocumento7 páginasGauss-Seidel Iteration MethodLawson SangoAinda não há avaliações
- Hemh 112Documento8 páginasHemh 112Younus JalilAinda não há avaliações
- Math9 Q1 M9 FinalDocumento15 páginasMath9 Q1 M9 FinalRachelleAinda não há avaliações
- EE321-Lab 8 - Netwon Raphson (N-R) MethodDocumento15 páginasEE321-Lab 8 - Netwon Raphson (N-R) MethodTerence CheonAinda não há avaliações
- Quartiles For Grouped DataDocumento21 páginasQuartiles For Grouped DataTheKnow04Ainda não há avaliações
- Math10 Q4 Week 5-SSLMDocumento4 páginasMath10 Q4 Week 5-SSLMJumar MonteroAinda não há avaliações
- IGNOU MBA MS-08 Solved Assignment 2011Documento12 páginasIGNOU MBA MS-08 Solved Assignment 2011Manoj SharmaAinda não há avaliações
- Daa 4 Unit DetailsDocumento14 páginasDaa 4 Unit DetailsSathyendra Kumar VAinda não há avaliações
- LTNMCV unit 2.1Documento41 páginasLTNMCV unit 2.1Muskula yashwanthAinda não há avaliações
- 04 Handout 1Documento11 páginas04 Handout 1Christian UmpadAinda não há avaliações
- Aviation MathsDocumento94 páginasAviation MathsyihesakAinda não há avaliações
- AL1 Week 9Documento4 páginasAL1 Week 9Reynante Louis DedaceAinda não há avaliações
- Cal 11 Q3 0305 FinalDocumento22 páginasCal 11 Q3 0305 FinalbakaonggoyAinda não há avaliações
- BALANGUE ALLEN JOHN Lesson 5Documento21 páginasBALANGUE ALLEN JOHN Lesson 5James ScoldAinda não há avaliações
- MODULE 3 - Data ManagementDocumento24 páginasMODULE 3 - Data ManagementROMEL RIMANDO0% (1)
- The Inclusion-Exclusion Principle Admits An Elegant Gen-Eralization ToDocumento2 páginasThe Inclusion-Exclusion Principle Admits An Elegant Gen-Eralization Tonaruto noharaAinda não há avaliações
- PRELIMDocumento22 páginasPRELIMMarshall james G. RamirezAinda não há avaliações
- Understanding Measures of Central Tendency and VariationDocumento17 páginasUnderstanding Measures of Central Tendency and Variationleyn sanburgAinda não há avaliações
- Bisection Method Root FindingDocumento6 páginasBisection Method Root FindingRusickAinda não há avaliações
- Section 1Documento3 páginasSection 1ahmed waheedAinda não há avaliações
- Vedic MathsDocumento8 páginasVedic Mathsamankapoor31Ainda não há avaliações
- Bcic Recruitment Question 27-06-2014Documento3 páginasBcic Recruitment Question 27-06-2014Anonymous XWTgry0% (1)
- Recent Bank Written Math Solution 2017 by Musfik Alam 1Documento20 páginasRecent Bank Written Math Solution 2017 by Musfik Alam 1Ataush SabujAinda não há avaliações
- New SAT Critical Reading WorkbookDocumento262 páginasNew SAT Critical Reading Workbookvmsgr100% (7)
- Bangladesh A Legacy of Blood Anthony Mascarenhas Banglapdf Bengali VersionDocumento215 páginasBangladesh A Legacy of Blood Anthony Mascarenhas Banglapdf Bengali VersionAtaush SabujAinda não há avaliações
- Lecture 1 First Order Logic MajorDocumento15 páginasLecture 1 First Order Logic MajorAtaush SabujAinda não há avaliações
- Planning PDFDocumento50 páginasPlanning PDFAtaush SabujAinda não há avaliações
- Bill of Rights - Bill of Rights InstituteDocumento3 páginasBill of Rights - Bill of Rights InstituteAtaush SabujAinda não há avaliações
- HW3 Solutions 2017 SpringDocumento4 páginasHW3 Solutions 2017 SpringAtaush Sabuj100% (1)
- TOC DFA EgDocumento9 páginasTOC DFA EgAtaush SabujAinda não há avaliações
- HW3 Solutions 2017 SpringDocumento4 páginasHW3 Solutions 2017 SpringAtaush Sabuj100% (1)
- Soal B Inggris Uas KLS X OllaDocumento25 páginasSoal B Inggris Uas KLS X OllaRidwan, S.Pd.,M.SiAinda não há avaliações
- Using ABAQUS to Reduce Tire Belt Edge StressesDocumento10 páginasUsing ABAQUS to Reduce Tire Belt Edge StressesGautam SharmaAinda não há avaliações
- BS en 01062-3-2008 PDFDocumento12 páginasBS en 01062-3-2008 PDFjohnAinda não há avaliações
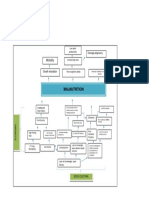
- Problem Tree Analysis MalnutritionDocumento1 páginaProblem Tree Analysis MalnutritionMho Dsb50% (6)
- Health Teaching Plan - AttitudeDocumento2 páginasHealth Teaching Plan - AttitudeFaller TrixieAinda não há avaliações
- A Celebration of John Wesley in Word and Song On The Anniversary of His BirthDocumento5 páginasA Celebration of John Wesley in Word and Song On The Anniversary of His BirthJonatan_NAinda não há avaliações
- Unified LSG Code 1Documento12 páginasUnified LSG Code 1Kerby Kent RetazoAinda não há avaliações
- 10 1 1 125Documento456 páginas10 1 1 125Radu GrumezaAinda não há avaliações
- Test Tenses en AnswersDocumento4 páginasTest Tenses en AnswersAmit Kumar LalAinda não há avaliações
- PBA Physics SSC-I FinalDocumento7 páginasPBA Physics SSC-I Finalrayyanhashmi93Ainda não há avaliações
- Highway Construction Production Rates and Estimated Contracct TimesDocumento95 páginasHighway Construction Production Rates and Estimated Contracct TimesLTE002Ainda não há avaliações
- AOE 5104 Class Notes and ScheduleDocumento26 páginasAOE 5104 Class Notes and ScheduleverbicarAinda não há avaliações
- Indesign: A How-To Guide For Creating A Professional Resumé Using IndesignDocumento14 páginasIndesign: A How-To Guide For Creating A Professional Resumé Using IndesignmadpancakesAinda não há avaliações
- Daftar Lowongan Kerja Teknik IndustriDocumento21 páginasDaftar Lowongan Kerja Teknik IndustriYusuf BachtiarAinda não há avaliações
- Revit For Presentations Graphics That Pop - Class HandoutDocumento15 páginasRevit For Presentations Graphics That Pop - Class HandoutAutodesk University100% (1)
- Classroom Management and DisciplineDocumento2 páginasClassroom Management and DisciplineMonaida Umpar IbrahimAinda não há avaliações
- Competition Commission of India Economics Study Material Amp NotesDocumento3 páginasCompetition Commission of India Economics Study Material Amp NotesRaghav DhillonAinda não há avaliações
- (2019) 7 CLJ 560 PDFDocumento12 páginas(2019) 7 CLJ 560 PDFhuntaAinda não há avaliações
- Guardian Reading - Avon Cosmetics Sellers Prosper in AfricaDocumento4 páginasGuardian Reading - Avon Cosmetics Sellers Prosper in Africamiguelillo84eireAinda não há avaliações
- Strict Liability Offences ExplainedDocumento7 páginasStrict Liability Offences ExplainedJoseph ClarkAinda não há avaliações
- Assessment 2 Stat20053 Descriptive Statistics - CompressDocumento2 páginasAssessment 2 Stat20053 Descriptive Statistics - CompressDon RatbuAinda não há avaliações
- Assignment 1 - CIEDocumento28 páginasAssignment 1 - CIEmarshall mingguAinda não há avaliações
- Anthony Andreas Vass, Barbara Harrison Social Work Competences Core Knowledge, Values and SkillsDocumento248 páginasAnthony Andreas Vass, Barbara Harrison Social Work Competences Core Knowledge, Values and SkillsAhmad Syifa100% (2)
- Thalassemia SyndromesDocumento29 páginasThalassemia SyndromesIsaac MwangiAinda não há avaliações
- Public Service Commission, West Bengal: Notice Inviting Expression of Interest For Enlistment As LawyersDocumento3 páginasPublic Service Commission, West Bengal: Notice Inviting Expression of Interest For Enlistment As LawyersITI JobAinda não há avaliações
- 10th Magnetic Effects of Currents MCQ-1Documento1 página10th Magnetic Effects of Currents MCQ-1jots2100% (1)
- JurnalDocumento10 páginasJurnalIca PurnamasariAinda não há avaliações
- Ferdinand Marcos BiographyDocumento4 páginasFerdinand Marcos BiographyteacherashleyAinda não há avaliações
- Complete Oh Atlas PDFDocumento63 páginasComplete Oh Atlas PDFCarmen GaborAinda não há avaliações
- Official ResumeDocumento2 páginasOfficial Resumeapi-385631007Ainda não há avaliações