Você também pode gostar
- A. Desplat: Godzilla (2014) - Film Score AnalysisDocumento18 páginasA. Desplat: Godzilla (2014) - Film Score AnalysisR.PercacciAinda não há avaliações
- V + V Plus - EN1Documento6 páginasV + V Plus - EN1james.anitAinda não há avaliações
- LLM01v5 0Documento12 páginasLLM01v5 0Alan LeungAinda não há avaliações
- Rule 8. Fire Safety Enforcers Chapter 1. Qualifications of Fire Safety Enforcers Division 1. Minimum RequirementsDocumento13 páginasRule 8. Fire Safety Enforcers Chapter 1. Qualifications of Fire Safety Enforcers Division 1. Minimum Requirementspatitay036817Ainda não há avaliações
- Semmler 2005Documento16 páginasSemmler 2005Anonymous sGLwiwMA4Ainda não há avaliações
- FandI CT4 200704 ReportDocumento19 páginasFandI CT4 200704 ReportTuff BubaAinda não há avaliações
- Factor Models For Portfolio Selection in Large Dimensions: The Good, The Better and The UglyDocumento28 páginasFactor Models For Portfolio Selection in Large Dimensions: The Good, The Better and The Ugly6doitAinda não há avaliações
- K-Medoids For K-Means SeedingDocumento9 páginasK-Medoids For K-Means Seedingphuc2008Ainda não há avaliações
- Mth601 Final Term Solved Mcqs FileDocumento12 páginasMth601 Final Term Solved Mcqs FileEver GreenAinda não há avaliações
- Economic Growth Lecture 4 2023Documento35 páginasEconomic Growth Lecture 4 2023rribeiro70Ainda não há avaliações
- Solow y DataDocumento7 páginasSolow y DataVanessa Carlos morianoAinda não há avaliações
- Cs Masters Thesis TopicsDocumento6 páginasCs Masters Thesis Topicsamhtnuwff100% (2)
- An Algorithm For Fast Optimal Latin Hypercube Design of ExperimentsDocumento27 páginasAn Algorithm For Fast Optimal Latin Hypercube Design of ExperimentsermkermkAinda não há avaliações
- Topic Notes Stats QMDocumento18 páginasTopic Notes Stats QMmickAinda não há avaliações
- MTH601-MidTerm-solved MCQ Mega File 2Documento14 páginasMTH601-MidTerm-solved MCQ Mega File 2kiranAinda não há avaliações
- Economics 2009 22Documento18 páginasEconomics 2009 22Love KhandalAinda não há avaliações
- Principles of Program Analysis:: A Sampler of ApproachesDocumento98 páginasPrinciples of Program Analysis:: A Sampler of Approachesverma_avni7Ainda não há avaliações
- MIT14 452F16 Lec4Documento43 páginasMIT14 452F16 Lec4PatrickAinda não há avaliações
- 2023 1stMidTerm Test Preparation 2Documento5 páginas2023 1stMidTerm Test Preparation 2alejandroalvballinesAinda não há avaliações
- ECON4040 1 Advanced Macroeconomics 201912Documento6 páginasECON4040 1 Advanced Macroeconomics 201912Junjing MaoAinda não há avaliações
- Lecture Notes On Optimization TechniquesDocumento140 páginasLecture Notes On Optimization TechniquesUmer AzharAinda não há avaliações
- Ss-KmeanDocumento16 páginasSs-KmeanHaythem MzoughiAinda não há avaliações
- No. of PagesDocumento3 páginasNo. of PagesDonaldAinda não há avaliações
- Exercise Sheet 1 The Multiple Regression ModelDocumento5 páginasExercise Sheet 1 The Multiple Regression ModelIgnacio Díez LacunzaAinda não há avaliações
- Critical Values For Cointegration Tests: February 1990Documento20 páginasCritical Values For Cointegration Tests: February 1990Cuty ShopAinda não há avaliações
- Ecole Polytechnique: Centre de Math Ematiques Appliqu EES Umr Cnrs 7641Documento19 páginasEcole Polytechnique: Centre de Math Ematiques Appliqu EES Umr Cnrs 7641Ryan KephartAinda não há avaliações
- Genetic Algorithm: Artificial Neural Networks (Anns)Documento10 páginasGenetic Algorithm: Artificial Neural Networks (Anns)Partth VachhaniAinda não há avaliações
- Econometrics Professor Seppo Pynn Onen Department of Mathematics and Statistics University of VaasaDocumento11 páginasEconometrics Professor Seppo Pynn Onen Department of Mathematics and Statistics University of VaasaajayikayodeAinda não há avaliações
- Econometrics IiDocumento5 páginasEconometrics IiRorisangAinda não há avaliações
- Big Bang - Big Crunch Learning Method For Fuzzy Cognitive MapsDocumento10 páginasBig Bang - Big Crunch Learning Method For Fuzzy Cognitive MapsenginyesilAinda não há avaliações
- Stochastic AlgorithmsDocumento19 páginasStochastic Algorithmsfls159Ainda não há avaliações
- Exercise 1 (25 Points) : Econometrics IDocumento10 páginasExercise 1 (25 Points) : Econometrics IDaniel MarinhoAinda não há avaliações
- Summer Course: Data Mining: Regression AnalysisDocumento34 páginasSummer Course: Data Mining: Regression Analysis叶子纯Ainda não há avaliações
- Myung Ohio State Model Selection MethodsDocumento76 páginasMyung Ohio State Model Selection MethodsSouparna MukhopadhyayAinda não há avaliações
- Economic Growth Lectures 5 and 6 2023Documento71 páginasEconomic Growth Lectures 5 and 6 2023rribeiro70Ainda não há avaliações
- KMeansPP SodaDocumento9 páginasKMeansPP Sodaalanpicard2303Ainda não há avaliações
- Time Series Analysis DissertationDocumento7 páginasTime Series Analysis DissertationScientificPaperWritingServicesCanada100% (1)
- Topic 1: The Solow Model of Economic GrowthDocumento17 páginasTopic 1: The Solow Model of Economic GrowthSimran SharmaAinda não há avaliações
- Algorithms For The Masses: Robert Sedgewick Princeton UniversityDocumento73 páginasAlgorithms For The Masses: Robert Sedgewick Princeton UniversityMuhammad AliAinda não há avaliações
- Education and Out of The Box Thinking - Linearization of Graham's Scan Algorithm Complexity As Fruit of Education PolicyDocumento9 páginasEducation and Out of The Box Thinking - Linearization of Graham's Scan Algorithm Complexity As Fruit of Education PolicyUbiquitous Computing and Communication JournalAinda não há avaliações
- MSC Economics Ec413 Macroeconomics: Real Business Cycles IiDocumento21 páginasMSC Economics Ec413 Macroeconomics: Real Business Cycles Iikokibonilla123Ainda não há avaliações
- 13 NicoaraDocumento8 páginas13 Nicoaraمحمد بندرAinda não há avaliações
- 2326 - EC2020 - Main EQP v1 - FinalDocumento19 páginas2326 - EC2020 - Main EQP v1 - FinalAryan MittalAinda não há avaliações
- Demand ForecastingDocumento12 páginasDemand ForecastingimrancenakkAinda não há avaliações
- EC4051 Project and Introductory Econometrics: Dudley CookeDocumento23 páginasEC4051 Project and Introductory Econometrics: Dudley Cookeabhay dwivediAinda não há avaliações
- A Simplicial Homology Algorithm For Lipschitz Optimisation: Stefan C. Endres Carl Sandrock Walter W. FockeDocumento37 páginasA Simplicial Homology Algorithm For Lipschitz Optimisation: Stefan C. Endres Carl Sandrock Walter W. FockeA BAinda não há avaliações
- Nbti ThesisDocumento7 páginasNbti Thesisangiejorgensensaltlakecity100% (2)
- A Linear Programming Approach To Solving Stochastic Dynamic ProgramsDocumento39 páginasA Linear Programming Approach To Solving Stochastic Dynamic ProgramskcvaraAinda não há avaliações
- Computational Fluid Dynamics : February 5Documento31 páginasComputational Fluid Dynamics : February 5Tatenda NyabadzaAinda não há avaliações
- MTH601 MidTerm SovledbyRanaDocumento11 páginasMTH601 MidTerm SovledbyRanakiran100% (1)
- SGFilter - A Stand-Alone Implementation of The Savitzky-Golay Smoothing FilterDocumento42 páginasSGFilter - A Stand-Alone Implementation of The Savitzky-Golay Smoothing FilterFredrik JonssonAinda não há avaliações
- Demand ForecastingDocumento22 páginasDemand ForecastingvishnugopalSAinda não há avaliações
- Final f18Documento17 páginasFinal f18Sheng HuangAinda não há avaliações
- Industrial Engineering 2009 by S K Mondal PDFDocumento217 páginasIndustrial Engineering 2009 by S K Mondal PDFAshok DargarAinda não há avaliações
- Mixed Model Selection Information TheoreticDocumento7 páginasMixed Model Selection Information TheoreticJesse Albert CancholaAinda não há avaliações
- MSC Macro Problemsets 2016Documento15 páginasMSC Macro Problemsets 2016Davissen MoorganAinda não há avaliações
- CS 740 - Computational Complexity and Algorithm Analysis: Spring Quarter 2011Documento32 páginasCS 740 - Computational Complexity and Algorithm Analysis: Spring Quarter 2011shivelsAinda não há avaliações
- StudyQuestions Regression (Logarithms)Documento21 páginasStudyQuestions Regression (Logarithms)master8875Ainda não há avaliações
- Use of GDCDocumento64 páginasUse of GDCMoloy GoraiAinda não há avaliações
- Computational Error and Complexity in Science and Engineering: Computational Error and ComplexityNo EverandComputational Error and Complexity in Science and Engineering: Computational Error and ComplexityAinda não há avaliações
- Modeling and Optimization in Space Engineering: State of the Art and New ChallengesNo EverandModeling and Optimization in Space Engineering: State of the Art and New ChallengesAinda não há avaliações
- Historical Currency Crises (After WWII)Documento74 páginasHistorical Currency Crises (After WWII)Mandar Priya PhatakAinda não há avaliações
- Financial 1Documento41 páginasFinancial 1Mandar Priya PhatakAinda não há avaliações
- IFM Slides Part 3Documento37 páginasIFM Slides Part 3Mandar Priya PhatakAinda não há avaliações
- IFM Part2 UpdatedDocumento61 páginasIFM Part2 UpdatedMandar Priya PhatakAinda não há avaliações
- Chapter 1Documento42 páginasChapter 1Mandar Priya PhatakAinda não há avaliações
- Strategies For Causal Inference Part 0: Introduction: CAU Kiel Summer Term 2019Documento18 páginasStrategies For Causal Inference Part 0: Introduction: CAU Kiel Summer Term 2019Mandar Priya PhatakAinda não há avaliações
- ThesisDocumento82 páginasThesisMandar Priya PhatakAinda não há avaliações
- I.,Qi) ' LL, /L: Al N+1 ?y" N-L Yl''Documento2 páginasI.,Qi) ' LL, /L: Al N+1 ?y" N-L Yl''Mandar Priya PhatakAinda não há avaliações
- Lyons 1997Documento24 páginasLyons 1997Mandar Priya PhatakAinda não há avaliações
- Cba Presentation SgpeDocumento44 páginasCba Presentation SgpeMandar Priya PhatakAinda não há avaliações
- Abn AmroDocumento14 páginasAbn AmroMandar Priya PhatakAinda não há avaliações
- Please Answer Questions Tlie With: w:AG), RüDocumento2 páginasPlease Answer Questions Tlie With: w:AG), RüMandar Priya PhatakAinda não há avaliações
- EcoI Exam WS1415!1!5creditsDocumento5 páginasEcoI Exam WS1415!1!5creditsMandar Priya PhatakAinda não há avaliações
- EcoI Exam Ws1415!2!5creditsDocumento5 páginasEcoI Exam Ws1415!2!5creditsMandar Priya PhatakAinda não há avaliações
- Formulary Eco IIDocumento47 páginasFormulary Eco IIMandar Priya PhatakAinda não há avaliações
- Likelihood Ratio, Wald, and Lagrange Multiplier (Score) TestsDocumento23 páginasLikelihood Ratio, Wald, and Lagrange Multiplier (Score) TestsMandar Priya PhatakAinda não há avaliações
- Advmai Ws1718 IIDocumento25 páginasAdvmai Ws1718 IIMandar Priya PhatakAinda não há avaliações
- Sarno Schmeling PaperDocumento48 páginasSarno Schmeling PaperMandar Priya PhatakAinda não há avaliações
- Advmai Ws1718 IDocumento44 páginasAdvmai Ws1718 IMandar Priya PhatakAinda não há avaliações
- Lecture 4Documento128 páginasLecture 4Mandar Priya PhatakAinda não há avaliações
- Dynamic Macro Basic Macro Frameworks Summer 2016 1Documento90 páginasDynamic Macro Basic Macro Frameworks Summer 2016 1Mandar Priya PhatakAinda não há avaliações
- Formulary Eco IIDocumento47 páginasFormulary Eco IIMandar Priya PhatakAinda não há avaliações
- Dynamic Macro HistoryversusExpectations Summer2016 1Documento71 páginasDynamic Macro HistoryversusExpectations Summer2016 1Mandar Priya PhatakAinda não há avaliações
- 1 ProbabilityDocumento56 páginas1 ProbabilityMandar Priya PhatakAinda não há avaliações
- 908 Lecture 6Documento51 páginas908 Lecture 6Mandar Priya PhatakAinda não há avaliações
- Theoretical Statistics. Lecture 15.: M-Estimators. Consistency of M-Estimators. Nonparametric Maximum LikelihoodDocumento20 páginasTheoretical Statistics. Lecture 15.: M-Estimators. Consistency of M-Estimators. Nonparametric Maximum LikelihoodMandar Priya PhatakAinda não há avaliações
- BSC SyllabusDocumento11 páginasBSC SyllabusMandar Priya PhatakAinda não há avaliações
- EC908 Lecture 2Documento53 páginasEC908 Lecture 2Mandar Priya PhatakAinda não há avaliações
- Questions To Lecture 7 - IS-LM Model and Aggregate DemandDocumento6 páginasQuestions To Lecture 7 - IS-LM Model and Aggregate DemandMandar Priya Phatak100% (2)
- JNTU Old Question Papers 2007Documento8 páginasJNTU Old Question Papers 2007Srinivasa Rao GAinda não há avaliações
- Castlegar & Slocan Valley Pennywise Dec. 9, 2014Documento49 páginasCastlegar & Slocan Valley Pennywise Dec. 9, 2014Pennywise PublishingAinda não há avaliações
- HINO Dutro Fault Codes List PDFDocumento4 páginasHINO Dutro Fault Codes List PDFANH LÊAinda não há avaliações
- Metal-Tek Electric Contact Cleaner Spray - TDS (2021)Documento1 páginaMetal-Tek Electric Contact Cleaner Spray - TDS (2021)metal-tek asteAinda não há avaliações
- Woodcock 1987Documento37 páginasWoodcock 1987Rodrigo MachadoAinda não há avaliações
- User Manual For Emvólio: WWW - Blackfrog.InDocumento22 páginasUser Manual For Emvólio: WWW - Blackfrog.InmariaAinda não há avaliações
- Marshall Abby - Chess Cafe - The Openings Explained - 1-63, 2015-OCR, 682pDocumento682 páginasMarshall Abby - Chess Cafe - The Openings Explained - 1-63, 2015-OCR, 682pArtur MałkowskiAinda não há avaliações
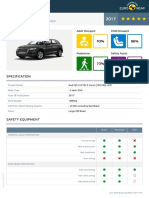
- Euroncap 2017 Audi q5 DatasheetDocumento13 páginasEuroncap 2017 Audi q5 DatasheetCosmin AnculiaAinda não há avaliações
- Synthesis of Sentences Is The Opposite ofDocumento9 páginasSynthesis of Sentences Is The Opposite ofSpsc AspirantsAinda não há avaliações
- School of Chemical Engineering - 20Documento372 páginasSchool of Chemical Engineering - 20biroutiAinda não há avaliações
- Ovonic Unified Memory OR Phase Change MemoryDocumento37 páginasOvonic Unified Memory OR Phase Change Memoryrockstar_69Ainda não há avaliações
- Nature Generator (Emtech Concept Paper)Documento3 páginasNature Generator (Emtech Concept Paper)Min SugaAinda não há avaliações
- Risk Assesment FOR PIPING WORKDocumento1 páginaRisk Assesment FOR PIPING WORKsunil100% (2)
- RAJPUT - Gokul IndustryDocumento76 páginasRAJPUT - Gokul IndustryrajputvjAinda não há avaliações
- Jurnal Praktikum Dasar-Dasar Pemisahan Kimia Pembuatan Membran Polysulfon (PSF)Documento9 páginasJurnal Praktikum Dasar-Dasar Pemisahan Kimia Pembuatan Membran Polysulfon (PSF)Rizki AuAinda não há avaliações
- Rama Varma Anagha Research PaperDocumento12 páginasRama Varma Anagha Research Paperapi-308560676Ainda não há avaliações
- Midi Fighter Twister - User Guide 2016Documento25 páginasMidi Fighter Twister - User Guide 2016moxmixAinda não há avaliações
- P1 - Duct Design IntroductionDocumento30 páginasP1 - Duct Design IntroductionAndryx MartinezAinda não há avaliações
- Proposed Revisions To Usp Sterile Product - Package Integrity EvaluationDocumento56 páginasProposed Revisions To Usp Sterile Product - Package Integrity EvaluationDarla Bala KishorAinda não há avaliações
- 017 - Chapter 3 - L13Documento6 páginas017 - Chapter 3 - L13nanduslns07Ainda não há avaliações
- 23 - Eave StrutsDocumento2 páginas23 - Eave StrutsTuanQuachAinda não há avaliações
- Tuesday 12 January 2021: ChemistryDocumento24 páginasTuesday 12 January 2021: Chemistryuchi haAinda não há avaliações
- 13 - Oxygen Removal From Boiler WaterDocumento12 páginas13 - Oxygen Removal From Boiler Waterarunkumar23101100% (1)
- PVC Duct DesignDocumento10 páginasPVC Duct DesigncitramuaraAinda não há avaliações
- Ultrafast Lasers Technology and Applications (Optical Science and CRC 1st Ed., 2002) (ISBN 0824708415), Martin E. Fermann, Almantas Galvanauskas Gregg SuchaDocumento797 páginasUltrafast Lasers Technology and Applications (Optical Science and CRC 1st Ed., 2002) (ISBN 0824708415), Martin E. Fermann, Almantas Galvanauskas Gregg SuchaRokas DanilevičiusAinda não há avaliações