Você também pode gostar
- Big Data Analytics: LAB 4: - Dynamic ProgrammingDocumento7 páginasBig Data Analytics: LAB 4: - Dynamic ProgrammingPrathamesh MoreAinda não há avaliações
- Project Logistic RegressionDocumento14 páginasProject Logistic RegressionCalo Soft100% (1)
- Laporan Titanic Survival Prediction - 132021012Documento6 páginasLaporan Titanic Survival Prediction - 132021012kevinAinda não há avaliações
- MainDocumento8 páginasMainbwqsouza.cicAinda não há avaliações
- EDA Pipeline FinalDocumento7 páginasEDA Pipeline FinalShrikant BadheAinda não há avaliações
- Import As Import As: Passengerid Survived Pclass Name Sex Age Sibsp Parch Ticket Fare Cabin 0Documento5 páginasImport As Import As: Passengerid Survived Pclass Name Sex Age Sibsp Parch Ticket Fare Cabin 0testAinda não há avaliações
- Logistic RegDocumento8 páginasLogistic RegMithila RAinda não há avaliações
- Passengerid Survived Pclass Name Sex Age Sibsp Parch TicketDocumento16 páginasPassengerid Survived Pclass Name Sex Age Sibsp Parch Ticketrutik9321Ainda não há avaliações
- Lab4-IDA - Ipynb - ColaboratoryDocumento8 páginasLab4-IDA - Ipynb - ColaboratoryUditAinda não há avaliações
- Arboles y K-NN - Ipynb - ColaboratoryDocumento17 páginasArboles y K-NN - Ipynb - ColaboratoryCharles MaldonadoAinda não há avaliações
- 01-Logistic Regression With PythonDocumento12 páginas01-Logistic Regression With PythonHellem BiersackAinda não há avaliações
- Titanic EdaDocumento14 páginasTitanic EdaDeepak SemwalAinda não há avaliações
- 7 8 - Missing Value HandlingDocumento4 páginas7 8 - Missing Value HandlingKhan RafiAinda não há avaliações
- Quiz Coding Question 1Documento9 páginasQuiz Coding Question 1Jay PatelAinda não há avaliações
- Titanic DataDocumento5 páginasTitanic DataDhanasekarAinda não há avaliações
- Ahamed 123Documento7 páginasAhamed 123jbalapragashpathi2005100% (1)
- EDA On Titanic DatasetDocumento39 páginasEDA On Titanic DatasetSoumya Saha100% (1)
- Pyt Manual 1Documento85 páginasPyt Manual 1Hrithik KumarAinda não há avaliações
- Aiml Lab5Documento6 páginasAiml Lab5testAinda não há avaliações
- 7 Questions To Ask Before EDADocumento2 páginas7 Questions To Ask Before EDAYajur Agarwal100% (1)
- ML Assignment 4Documento10 páginasML Assignment 4Prashil JainAinda não há avaliações
- ML File 211173Documento19 páginasML File 211173NANDINI AGGARWAL 211131Ainda não há avaliações
- 10 - Eda To Prediction DietanicDocumento21 páginas10 - Eda To Prediction DietanicKhan RafiAinda não há avaliações
- ML Lab FileDocumento19 páginasML Lab FilesonuAinda não há avaliações
- What Are Decision Trees?Documento9 páginasWhat Are Decision Trees?eng_mahesh1012Ainda não há avaliações
- Eda and Prediction On Titanic Dataset: Import LibrariesDocumento15 páginasEda and Prediction On Titanic Dataset: Import LibrariesRUSHIRAJ DASU100% (1)
- PandasDocumento49 páginasPandassubodhaade2Ainda não há avaliações
- 1.1 Objective: 2. Data Preparation and Exploratory AnalysisDocumento11 páginas1.1 Objective: 2. Data Preparation and Exploratory Analysisk767Ainda não há avaliações
- Titanic ClassificationDocumento7 páginasTitanic Classificationsidrah100% (1)
- Python 5,6,7Documento15 páginasPython 5,6,7Ayush pachoriAinda não há avaliações
- Instructions:: Mltest2question - Jupyter NotebookDocumento6 páginasInstructions:: Mltest2question - Jupyter NotebookAniruddha TrivediAinda não há avaliações
- Import As: Pandas PD Titanic - Data PD - Read - CSV Titanic - Data - HeadDocumento12 páginasImport As: Pandas PD Titanic - Data PD - Read - CSV Titanic - Data - HeadJuniorFerreiraAinda não há avaliações
- 3a Data Frame - Jupyter NotebookDocumento5 páginas3a Data Frame - Jupyter Notebookvenkatesh mAinda não há avaliações
- Tutorial Data Visualization Pandas Matplotlib SeabornDocumento32 páginasTutorial Data Visualization Pandas Matplotlib Seabornbida22-016Ainda não há avaliações
- Pandas: Import As Import AsDocumento40 páginasPandas: Import As Import Asacaro222Ainda não há avaliações
- Pandas Profiling Library For EDADocumento1 páginaPandas Profiling Library For EDAYajur AgarwalAinda não há avaliações
- Fake News Classification - Ipynb - ColaboratoryDocumento6 páginasFake News Classification - Ipynb - ColaboratoryAYAAN SatkutAinda não há avaliações
- Pandas Day 4Documento7 páginasPandas Day 4Ali KhokharAinda não há avaliações
- Unstructured Data Classification HandsonDocumento4 páginasUnstructured Data Classification Handsonmohamed yasinAinda não há avaliações
- Audio ClassificationDocumento1 páginaAudio Classification1MV19ET014 Divya TAAinda não há avaliações
- Titanic Dataset 1677256844Documento27 páginasTitanic Dataset 1677256844Mariappan RAinda não há avaliações
- TITANIC - ColaboratoryDocumento18 páginasTITANIC - ColaboratoryMG Limited 17Ainda não há avaliações
- Titanic Survival Prediction 1692609491Documento15 páginasTitanic Survival Prediction 1692609491Tirthankar GhoshAinda não há avaliações
- From Import Import As From Import From Import From Import Import Import From Import From Import From ImportDocumento3 páginasFrom Import Import As From Import From Import From Import Import Import From Import From Import From ImportNguyen Trung ThinhAinda não há avaliações
- From Import Import As From Import From Import From Import Import Import From Import From Import From ImportDocumento3 páginasFrom Import Import As From Import From Import From Import Import Import From Import From Import From ImportNguyen Trung ThinhAinda não há avaliações
- Decision Tree Algorithm 1677030641Documento9 páginasDecision Tree Algorithm 1677030641juanAinda não há avaliações
- Pandas 1Documento89 páginasPandas 1Ledoux NgabaAinda não há avaliações
- Experiment 5Documento13 páginasExperiment 5anjanisvecw2004Ainda não há avaliações
- Assignment 11Documento7 páginasAssignment 11ankit mahto100% (1)
- Hands On Seaborn?Documento57 páginasHands On Seaborn?pratik choudhariAinda não há avaliações
- ML 2Documento4 páginasML 2yefigoh133Ainda não há avaliações
- Python - Basics - Dr. CHADIDocumento11 páginasPython - Basics - Dr. CHADIm.shaggyspringerAinda não há avaliações
- Lab - 3Documento5 páginasLab - 3Bharath Krishna BezawadaAinda não há avaliações
- MLT Exp 09Documento3 páginasMLT Exp 09Sec ArcAinda não há avaliações
- PythonNotesV1 0Documento3 páginasPythonNotesV1 0murthygrsAinda não há avaliações
- Lab Assignment 2Documento22 páginasLab Assignment 22K19/CO/179 JITESH KUMARAinda não há avaliações
- 6.datawrangling: Data VisulationDocumento27 páginas6.datawrangling: Data VisulationAnish pandeyAinda não há avaliações
- Java For SeleniumDocumento9 páginasJava For SeleniumJoe1Ainda não há avaliações
- Selenium Testing ProcessDocumento9 páginasSelenium Testing ProcessJoe1Ainda não há avaliações
- Selenium Java Environment SetupDocumento7 páginasSelenium Java Environment SetupJoe1Ainda não há avaliações
- Selenium Class 3 Selenium Testing Process Part 2 PDFDocumento7 páginasSelenium Class 3 Selenium Testing Process Part 2 PDFJoe1Ainda não há avaliações
- Employees Mod DB PDFDocumento1 páginaEmployees Mod DB PDFJoe1Ainda não há avaliações
- Worksheet 2Documento3 páginasWorksheet 2Joe1Ainda não há avaliações
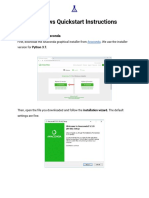
- Windows Quickstart Instructions: Step 1: Download AnacondaDocumento7 páginasWindows Quickstart Instructions: Step 1: Download AnacondaJoe1Ainda não há avaliações
- Regular Expressions in PythonDocumento16 páginasRegular Expressions in PythonJoe1Ainda não há avaliações
- Hive and ImpalaDocumento46 páginasHive and ImpalaJoe1Ainda não há avaliações
- HDFS and YARNDocumento91 páginasHDFS and YARNJoe1Ainda não há avaliações
- SELECT From NobelDocumento13 páginasSELECT From NobelJoe1Ainda não há avaliações
- SELECT From WORLD TutorialDocumento13 páginasSELECT From WORLD TutorialJoe1Ainda não há avaliações
- Knn1 HouseVotesDocumento2 páginasKnn1 HouseVotesJoe1Ainda não há avaliações
- Decision Tree and EDA With Functions: Import Pandas As PDDocumento9 páginasDecision Tree and EDA With Functions: Import Pandas As PDJoe1Ainda não há avaliações
- Knn1 MinMaxScalarDocumento13 páginasKnn1 MinMaxScalarJoe1Ainda não há avaliações
- Digits Recognition DatasetDocumento4 páginasDigits Recognition DatasetJoe1Ainda não há avaliações
- Random Forest: Random Forest Has Classifier For Classification and Regressor For RegressionDocumento9 páginasRandom Forest: Random Forest Has Classifier For Classification and Regressor For RegressionJoe1Ainda não há avaliações
- # Import Plotting Libraries: in (1) : Import Pandas As PDDocumento13 páginas# Import Plotting Libraries: in (1) : Import Pandas As PDJoe1Ainda não há avaliações
- How To Analyze Data Using The Average: Link ForDocumento1 páginaHow To Analyze Data Using The Average: Link ForJoe1Ainda não há avaliações
- Multilpe RegressionDocumento17 páginasMultilpe RegressionArnette Joy BachillerAinda não há avaliações
- Management Science L5Documento11 páginasManagement Science L5Santos JewelAinda não há avaliações
- Harvard Ec 1123 Econometrics Problem Set 6 - Tarun Preet SinghDocumento3 páginasHarvard Ec 1123 Econometrics Problem Set 6 - Tarun Preet Singhtarun singhAinda não há avaliações
- Kernel PCADocumento6 páginasKernel PCAशुभमपटेलAinda não há avaliações
- Chapter Seven: Preparation For Data Analysis: Qualitative & Quantitative DataDocumento43 páginasChapter Seven: Preparation For Data Analysis: Qualitative & Quantitative DataBiruk yAinda não há avaliações
- Statistics For Dummies, 2nd EditionDocumento3 páginasStatistics For Dummies, 2nd EditionEmilynBernardoAinda não há avaliações
- Covariance - Correlation and Regression (Lecture)Documento11 páginasCovariance - Correlation and Regression (Lecture)Emerson ButynAinda não há avaliações
- Econ 251 PS1 SolutionsDocumento5 páginasEcon 251 PS1 SolutionsPeter ShangAinda não há avaliações
- MISY 631 Final Review Calculators Will Be Provided For The ExamDocumento9 páginasMISY 631 Final Review Calculators Will Be Provided For The ExamAniKelbakianiAinda não há avaliações
- Dsilytc Group 3 Final Paper 2Documento20 páginasDsilytc Group 3 Final Paper 2Gian Carlo RamonesAinda não há avaliações
- Econometricstrix Meeting 2020 DecemberDocumento5 páginasEconometricstrix Meeting 2020 DecembersifarAinda não há avaliações
- Confounding VariableDocumento5 páginasConfounding VariableAtul GaurAinda não há avaliações
- T-Test in ThesisDocumento7 páginasT-Test in Thesiskvpyqegld100% (2)
- An Introduction To Bootstrap Methods With Applications To RDocumento236 páginasAn Introduction To Bootstrap Methods With Applications To RJonas SprindysAinda não há avaliações
- Cap 16 Construccion de ModelosDocumento25 páginasCap 16 Construccion de ModelosJorge EnriquezAinda não há avaliações
- Quadratic RegressionDocumento9 páginasQuadratic RegressionFloRhyda DahinoAinda não há avaliações
- Comparative Analysis of Grade 10 in Their PerformanceDocumento19 páginasComparative Analysis of Grade 10 in Their PerformanceFrancisco, John Eiyen D.Ainda não há avaliações
- Sheet 1Documento3 páginasSheet 1Menna Elsaoudy100% (1)
- 7 NonlinearDocumento48 páginas7 NonlinearWilliamAinda não há avaliações
- Session - 20-Problem Set-Solution - PKDocumento43 páginasSession - 20-Problem Set-Solution - PKPANKAJ PAHWAAinda não há avaliações
- Updated+delivery+schedule+-+PGPDSBA O APR23 ADocumento3 páginasUpdated+delivery+schedule+-+PGPDSBA O APR23 AStocknEarnAinda não há avaliações
- English and Stastics SAT 1Documento5 páginasEnglish and Stastics SAT 1Kassahun TerechaAinda não há avaliações
- Clarke An International Comparative Study of PracticumDocumento14 páginasClarke An International Comparative Study of Practicummirela scortescuAinda não há avaliações
- Normal ProbabilityDocumento14 páginasNormal ProbabilityRon Robert M. PecanaAinda não há avaliações
- Calidad Muscular y DEMFDocumento56 páginasCalidad Muscular y DEMFChristian Álvarez RodríguezAinda não há avaliações
- KR20 & Coefficient Alpha: Their Equivalence For Binary Scored ItemsDocumento7 páginasKR20 & Coefficient Alpha: Their Equivalence For Binary Scored ItemsOtro Fracasado MásAinda não há avaliações
- DT-0 (3 Files Merged)Documento143 páginasDT-0 (3 Files Merged)Qasim AbidAinda não há avaliações
- HW 17 - MLRDocumento5 páginasHW 17 - MLRSwapan Kumar SahaAinda não há avaliações
- Assignment No 1Documento5 páginasAssignment No 1AnkitGhildiyalAinda não há avaliações
- Forecasting ProblemsDocumento2 páginasForecasting ProblemsMuhammad Naveed IkramAinda não há avaliações
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)No EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)Ainda não há avaliações
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsNo EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsNota: 4.5 de 5 estrelas4.5/5 (3)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.No EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Nota: 5 de 5 estrelas5/5 (1)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeNo EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeNota: 4 de 5 estrelas4/5 (2)
- Math Workshop, Grade K: A Framework for Guided Math and Independent PracticeNo EverandMath Workshop, Grade K: A Framework for Guided Math and Independent PracticeNota: 5 de 5 estrelas5/5 (1)
- Limitless Mind: Learn, Lead, and Live Without BarriersNo EverandLimitless Mind: Learn, Lead, and Live Without BarriersNota: 4 de 5 estrelas4/5 (6)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormNo EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormNota: 5 de 5 estrelas5/5 (5)
- Images of Mathematics Viewed Through Number, Algebra, and GeometryNo EverandImages of Mathematics Viewed Through Number, Algebra, and GeometryAinda não há avaliações
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingNo EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingNota: 4.5 de 5 estrelas4.5/5 (21)
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldNo EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldNota: 3 de 5 estrelas3/5 (80)
- ParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)No EverandParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)Ainda não há avaliações