Você também pode gostar
- 1 E 2401 Expansion Joint Stability Analaysis Report - Rev0 inDocumento141 páginas1 E 2401 Expansion Joint Stability Analaysis Report - Rev0 inFelipeAinda não há avaliações
- Quality Control - Works Inspection: Modular False CeilingDocumento2 páginasQuality Control - Works Inspection: Modular False CeilingParasAinda não há avaliações
- SF - RE500 + G500 Rebar (Sep2015)Documento88 páginasSF - RE500 + G500 Rebar (Sep2015)Wesleykit WongAinda não há avaliações
- Guidelines For Excavation Works in The Vicinity of MV and LV CablesDocumento9 páginasGuidelines For Excavation Works in The Vicinity of MV and LV CablesNehal Aladdin Ibrahim100% (1)
- Plastering Check ListDocumento1 páginaPlastering Check ListSherma WagayeAinda não há avaliações
- CSMP Itr - ADocumento37 páginasCSMP Itr - ARozh SammedAinda não há avaliações
- 2013-2014 ADMITTED BATCH: 1 & 2 Year Course StructureDocumento58 páginas2013-2014 ADMITTED BATCH: 1 & 2 Year Course StructureGanesh PeketiAinda não há avaliações
- No. of Rebars: 1/3 of Clear Span 1/3 of Clear SpanDocumento2 páginasNo. of Rebars: 1/3 of Clear Span 1/3 of Clear SpanNelAinda não há avaliações
- DomasDocumento3 páginasDomasPOC TELKOMSELAinda não há avaliações
- Ramp CalculationDocumento15 páginasRamp CalculationHerlina KartikaAinda não há avaliações
- QC Dept Organization Chart R2Documento3 páginasQC Dept Organization Chart R2kiran144Ainda não há avaliações
- Division 1 - General RequirementsDocumento2 páginasDivision 1 - General RequirementsHOFFERAinda não há avaliações
- Shobha DevelopersDocumento212 páginasShobha DevelopersJames TownsendAinda não há avaliações
- DAR 2021 Vol 2 CompressedDocumento1.710 páginasDAR 2021 Vol 2 Compresseder.ankitnegi1988Ainda não há avaliações
- Load Sheet 1Documento14 páginasLoad Sheet 1kapilAinda não há avaliações
- Form J - Item 4 - Quality Control PlanDocumento10 páginasForm J - Item 4 - Quality Control PlanBALARISI ENGINEERAinda não há avaliações
- Quality Manual RS QMS 002Documento11 páginasQuality Manual RS QMS 002WayneAinda não há avaliações
- 2 Job Procedure For IMIRDocumento6 páginas2 Job Procedure For IMIRShubham ShuklaAinda não há avaliações
- Quality Function DeploymentDocumento53 páginasQuality Function DeploymentLuis Angel LegariaAinda não há avaliações
- Assessment Validation TemplateDocumento4 páginasAssessment Validation TemplateUmesh Banga100% (1)
- Road EstimateDocumento2 páginasRoad EstimateCarlos Valverde PortillaAinda não há avaliações
- Chemrite - 520 M NEWDocumento2 páginasChemrite - 520 M NEWghazanfarAinda não há avaliações
- 1.MS For Blasting WorksDocumento7 páginas1.MS For Blasting WorksRakeshAinda não há avaliações
- Lot 1 - Expansion Civil WorksDocumento6 páginasLot 1 - Expansion Civil WorksJethro AbanadorAinda não há avaliações
- Drip Irrigation SheetDocumento2 páginasDrip Irrigation Sheetnarasimma8313Ainda não há avaliações
- Chemical Anchor Re500Documento3 páginasChemical Anchor Re500Pratheesh PrasannanAinda não há avaliações
- Construction Site Organisation ChartDocumento1 páginaConstruction Site Organisation ChartsubhaschandraAinda não há avaliações
- RE500 Fastening With Rebar (SEP 2011)Documento60 páginasRE500 Fastening With Rebar (SEP 2011)Homer DongAinda não há avaliações
- 5.e) E-20 Final 1st Floor e RoomDocumento23 páginas5.e) E-20 Final 1st Floor e RoomRakesh SharmaAinda não há avaliações
- Labour Out Put ConstantDocumento7 páginasLabour Out Put ConstantMadhuBabu Chinnamsetti0% (1)
- Site Photos For Treatment To Expansion Joint PDFDocumento4 páginasSite Photos For Treatment To Expansion Joint PDFRohil JulaniyaAinda não há avaliações
- Material TestingDocumento7 páginasMaterial TestingMahmoud OssamaAinda não há avaliações
- C1 - Checklist For EarthworksDocumento46 páginasC1 - Checklist For EarthworksPetals ParadiseAinda não há avaliações
- Field Quality Plan-ADocumento10 páginasField Quality Plan-AcharibackupAinda não há avaliações
- National Institute of Construction Management and ResearchDocumento14 páginasNational Institute of Construction Management and Researchsimple_aniAinda não há avaliações
- Cost of QualityDocumento30 páginasCost of QualityrkshpanchalAinda não há avaliações
- NH Sor 6TH Revision 2018 Combine PDFDocumento170 páginasNH Sor 6TH Revision 2018 Combine PDFM/s Gogoi AssociatesAinda não há avaliações
- QAQCDocumento15 páginasQAQCflawlessy2k100% (1)
- Focus Dimension Target Purpose Action Persons Involve Estimate Budget Time Frame Production ResultsDocumento4 páginasFocus Dimension Target Purpose Action Persons Involve Estimate Budget Time Frame Production ResultsEsh YoAinda não há avaliações
- PPAP Fourth Edition 2006Documento5 páginasPPAP Fourth Edition 2006Đại Hữu Tuấn MaiAinda não há avaliações
- IGBC Green Homes Rating System Ver 3.0Documento172 páginasIGBC Green Homes Rating System Ver 3.0architectmanoAinda não há avaliações
- Example ITPDocumento1 páginaExample ITPPaulSwinbankAinda não há avaliações
- Data BookDocumento66 páginasData Bookvishnukesavieam10% (1)
- Resume Karthik QaDocumento3 páginasResume Karthik QaYuvan Karthik MechAinda não há avaliações
- Check ListDocumento25 páginasCheck Listrombi aritonangAinda não há avaliações
- Rate Analysis of Super StructureDocumento8 páginasRate Analysis of Super StructureaqhammamAinda não há avaliações
- Anchr Bolt RefDocumento9 páginasAnchr Bolt ReferleosAinda não há avaliações
- Product Manual For Pressed Ceramic Tiles ACCORDING TO IS 15622: 2017Documento13 páginasProduct Manual For Pressed Ceramic Tiles ACCORDING TO IS 15622: 2017Abhijit KarpeAinda não há avaliações
- Sample QAPDocumento3 páginasSample QAPsniperiAinda não há avaliações
- Est&Cost PDFDocumento11 páginasEst&Cost PDFNagaraj PAinda não há avaliações
- S.No DIA Unit WT of Bar WT (Act) WT (The) Differ Weight (KG) Incrg (DIA) % of WT IncrgDocumento2 páginasS.No DIA Unit WT of Bar WT (Act) WT (The) Differ Weight (KG) Incrg (DIA) % of WT IncrgAtulJainAinda não há avaliações
- Elcometer 456 User Manual PDFDocumento76 páginasElcometer 456 User Manual PDFchaparal100% (1)
- Cop On Vehicle Parking Provision in Development Proposals 2019 Edition PDFDocumento97 páginasCop On Vehicle Parking Provision in Development Proposals 2019 Edition PDFShumei ZhouAinda não há avaliações
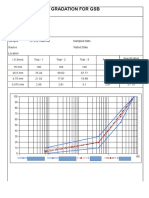
- GSB Test FormatsDocumento4 páginasGSB Test FormatsGaurav TripathiAinda não há avaliações
- ECA KPIs and Quality MetricsDocumento4 páginasECA KPIs and Quality MetricsDayanaAinda não há avaliações
- 2BHK Contract Estimate Template Version 1.1Documento12 páginas2BHK Contract Estimate Template Version 1.1himmatchavanAinda não há avaliações
- Data Quality ChallengesDocumento45 páginasData Quality Challengesabreddy2003Ainda não há avaliações
- Data Quality ChallengesDocumento9 páginasData Quality Challengesabreddy2003Ainda não há avaliações
- DQ InvestigationDocumento4 páginasDQ Investigationabreddy2003Ainda não há avaliações
- Quality StageDocumento3 páginasQuality StageSethumk007Ainda não há avaliações
- Bhaskar ReddyDocumento7 páginasBhaskar Reddyabreddy2003Ainda não há avaliações
- S.No Emp - No Emp - Name Designation Department DOJ Current - Location Mobile NoDocumento16 páginasS.No Emp - No Emp - Name Designation Department DOJ Current - Location Mobile Noabreddy2003Ainda não há avaliações
- Reference ResidualDocumento150 páginasReference Residualabreddy2003Ainda não há avaliações
- Data Stage Course Content: Unit-1 Data Warehousing ConceptsDocumento3 páginasData Stage Course Content: Unit-1 Data Warehousing Conceptsabreddy2003Ainda não há avaliações
- IA RulesDocumento120 páginasIA Rulesabreddy2003Ainda não há avaliações
- Bhaskar Datastage Profile2Documento7 páginasBhaskar Datastage Profile2abreddy2003Ainda não há avaliações
- Data Stage Scenarios: Scenario1. Cummilative SumDocumento13 páginasData Stage Scenarios: Scenario1. Cummilative Sumabreddy2003Ainda não há avaliações
- Git ExtDocumento1 páginaGit Extabreddy2003Ainda não há avaliações
- Datastage ArchitectureDocumento4 páginasDatastage Architecturenithinmamidala999Ainda não há avaliações
- Ds QuestionsDocumento11 páginasDs Questionsabreddy2003Ainda não há avaliações
- Git ExtensionDocumento1 páginaGit Extensionabreddy2003Ainda não há avaliações
- DataStage XML and Web Services Packs OverviewDocumento71 páginasDataStage XML and Web Services Packs Overviewnithinmamidala999Ainda não há avaliações
- Git DocDocumento1 páginaGit Docabreddy2003Ainda não há avaliações
- Introduction To DataStageDocumento111 páginasIntroduction To DataStageabreddy2003Ainda não há avaliações
- How To Start SQL Assistant Using Batch Mode or Using Command Prompt?Documento9 páginasHow To Start SQL Assistant Using Batch Mode or Using Command Prompt?abreddy2003Ainda não há avaliações
- How To Start SQL Assistant Using Batch Mode or Using Command Prompt?Documento9 páginasHow To Start SQL Assistant Using Batch Mode or Using Command Prompt?abreddy2003Ainda não há avaliações
- Linear Search and Binary SearchDocumento24 páginasLinear Search and Binary SearchADityaAinda não há avaliações
- Compiler Design DagDocumento7 páginasCompiler Design DagAman RajAinda não há avaliações
- EvalExam2 Geometry SET ADocumento2 páginasEvalExam2 Geometry SET AEngr. HLDCAinda não há avaliações
- Derrida, Language Games, and TheoryDocumento18 páginasDerrida, Language Games, and TheoryMariana HoefelAinda não há avaliações
- Week 01 - Assignments CSE115 (SAM)Documento11 páginasWeek 01 - Assignments CSE115 (SAM)Fake PrioAinda não há avaliações
- Computer Science, 9618 Home Assignment (35 Marks)Documento5 páginasComputer Science, 9618 Home Assignment (35 Marks)Saurya PandeyAinda não há avaliações
- YouTube Video Summariser Using NLPDocumento27 páginasYouTube Video Summariser Using NLPbagriharsh37Ainda não há avaliações
- Livecache MonitoringDocumento107 páginasLivecache MonitoringKavitha GanesanAinda não há avaliações
- Framework Development of FTP Programs Mini Project - ReportDocumento13 páginasFramework Development of FTP Programs Mini Project - ReportBaburam KumaraswaranAinda não há avaliações
- Exit Exam Student GuideDocumento10 páginasExit Exam Student GuideAfrican Tech87% (23)
- Jurisprudence Notes - Nature and Scope of JurisprudenceDocumento11 páginasJurisprudence Notes - Nature and Scope of JurisprudenceMoniruzzaman Juror100% (4)
- Irish PlacenamesDocumento24 páginasIrish PlacenamesKate A. RoseAinda não há avaliações
- Dissseniorhighschool q1 m13 Filipinosindigenoussocialideas v1Documento19 páginasDissseniorhighschool q1 m13 Filipinosindigenoussocialideas v1Christian Rodriguez Gagal100% (1)
- Framemaker - Help 2019 PDFDocumento908 páginasFramemaker - Help 2019 PDFMayur100% (1)
- Disc HandoutDocumento38 páginasDisc HandoutTesfu HettoAinda não há avaliações
- Lirik Christian BautistaDocumento3 páginasLirik Christian Bautistahandri03061989Ainda não há avaliações
- Assembly Language ProgrammingDocumento25 páginasAssembly Language ProgrammingAdithya R AnandAinda não há avaliações
- Word Formation - Revised Past Papers (2014) (Grade 9) KEYDocumento3 páginasWord Formation - Revised Past Papers (2014) (Grade 9) KEYkhoaAinda não há avaliações
- ONSITE Resources: Total Project CostDocumento3 páginasONSITE Resources: Total Project Costsunil sakriAinda não há avaliações
- m0 - 61544122s BlogDocumento11 páginasm0 - 61544122s BlogRAZAinda não há avaliações
- Lecture 1 Anglo Saxon Literature Periods of the English Literature (Копія)Documento44 páginasLecture 1 Anglo Saxon Literature Periods of the English Literature (Копія)VikA LevenetsAinda não há avaliações
- Chapter 3. Program Example: 3.1 How To Make Project and Open ProgramDocumento21 páginasChapter 3. Program Example: 3.1 How To Make Project and Open Programjhon hernanAinda não há avaliações
- Literature Review For DummiesDocumento7 páginasLiterature Review For Dummiesea44a6t7100% (1)
- Getting Started MC 10Documento25 páginasGetting Started MC 10quochungkdAinda não há avaliações
- Lesson Relative PronouneDocumento2 páginasLesson Relative Pronounedaloulasud30Ainda não há avaliações
- Oral Comm Di Ko AlamDocumento4 páginasOral Comm Di Ko AlamJustine PunoAinda não há avaliações
- CMS Web App User Guide 3 2Documento42 páginasCMS Web App User Guide 3 2రవి కిరణ్ పూలAinda não há avaliações
- Young Learners My Family Level 3Documento2 páginasYoung Learners My Family Level 3Farhan Muhammad IrhamAinda não há avaliações
- Imaginea Pascala La EvIOAN PAcifica 2012Documento16 páginasImaginea Pascala La EvIOAN PAcifica 2012CinevaAinda não há avaliações
- STM 32 WL 55 JCDocumento147 páginasSTM 32 WL 55 JCDaniel Gustavo Martinez MartinezAinda não há avaliações